
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 데이터 증강
딥러닝 모델을 도입하여 추론(App) Task를 수행하고자 할 때 사용하는 모델의 성능을 높이기 위해서는 일반적으로 충분한 양의 학습 데이터셋을 이용한 학습을 사전에 수행해야 한다.
하지만 학습 데이터셋을 확보하는데는 여러 어려움이 발생하는 경우가 꽤 많이 있는데, 접근성, 프라이버시, 정보보안, 정제되지 않은 데이터, 저작권, 품질 등의 다양한 이유가 있다.
이렇게 학습 데이터셋의 수집이 충분히 이뤄지지 않은 상태에서 딥러닝 모델의 훈련이 진행된다면 과소적합(Underfiting)과 과적합(Overfiting)두 현상이 동시에 발생할 수 있으며, 이로 인해 성능하락이 발생하고 이미지 추론 Task의 목표 성능지표를 달성할 수 없게 된다.
이 문제를 해결하기 위해 Pre-training(사전학습), Dropout등의 여러 기법이 도입되었으며, 그 중 소개하고자 하는 기법은 데이터 증강(Data Augmentation)이다.
데이터 증강 기법은 아래의 그림처럼 원본 데이터셋에 노이즈 및 변형 효과를 적용한 데이터셋을 추가함으로써 전체적으로 더 많은 학습 데이터를 임의로 생성하는 것을 말한다.
 이렇게 데이터 증강깁버의 도입을 통해 데이터 부족문제 완화, 모델 성능 향상, 데이터 다양성 증가 등의 효과를 기대할 수 있다.
이렇게 데이터 증강깁버의 도입을 통해 데이터 부족문제 완화, 모델 성능 향상, 데이터 다양성 증가 등의 효과를 기대할 수 있다.
2. 데이터셋 선정
https://www.microsoft.com/en-us/download/details.aspx?id=54765
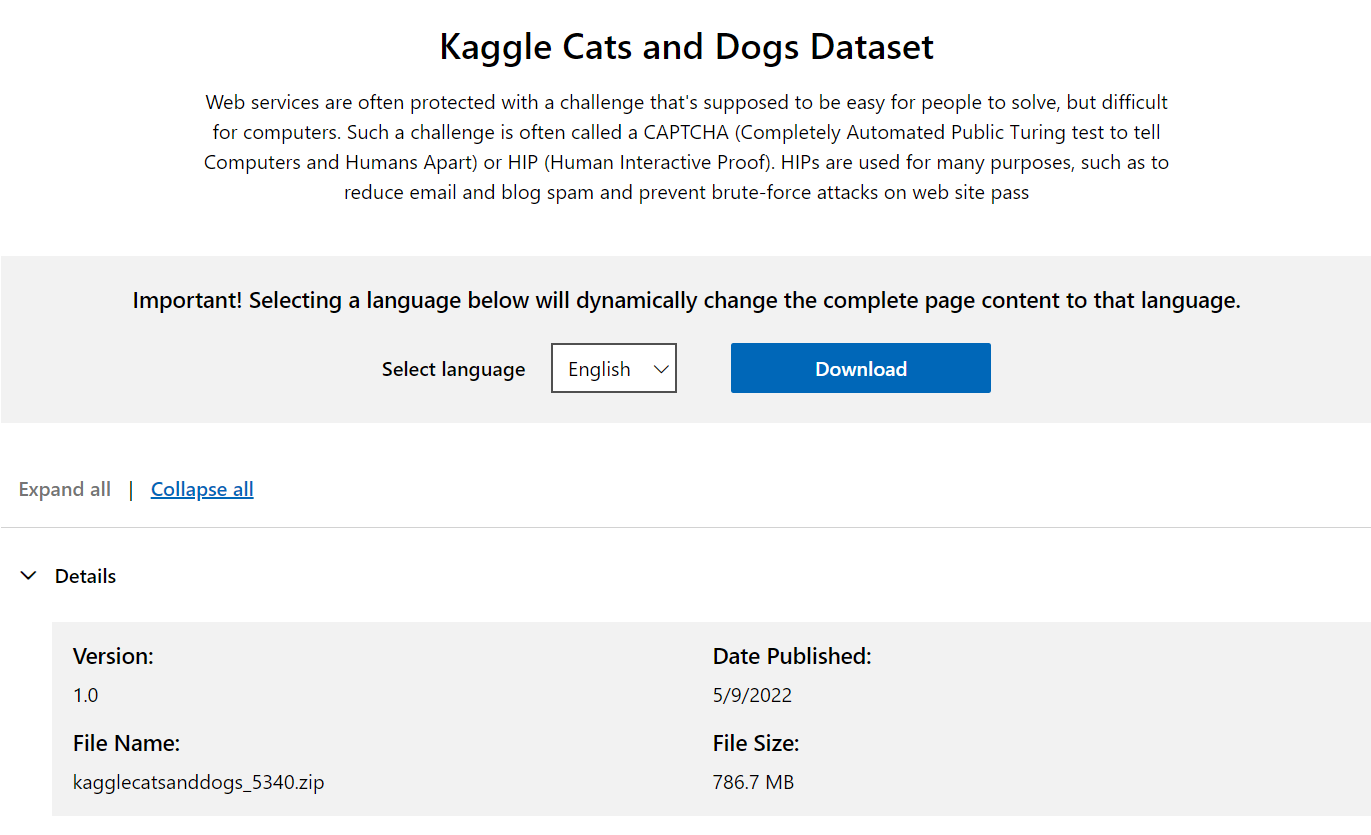 데이터셋은 Kaggle Cat and Dog Dataset을 사용했으며, 강아지/고양이에 각각 12,500장 씩 총 25,000장의 이미지가 있으며, 정제되지 않은 데이터가 포함되어 있다.
데이터셋은 Kaggle Cat and Dog Dataset을 사용했으며, 강아지/고양이에 각각 12,500장 씩 총 25,000장의 이미지가 있으며, 정제되지 않은 데이터가 포함되어 있다.
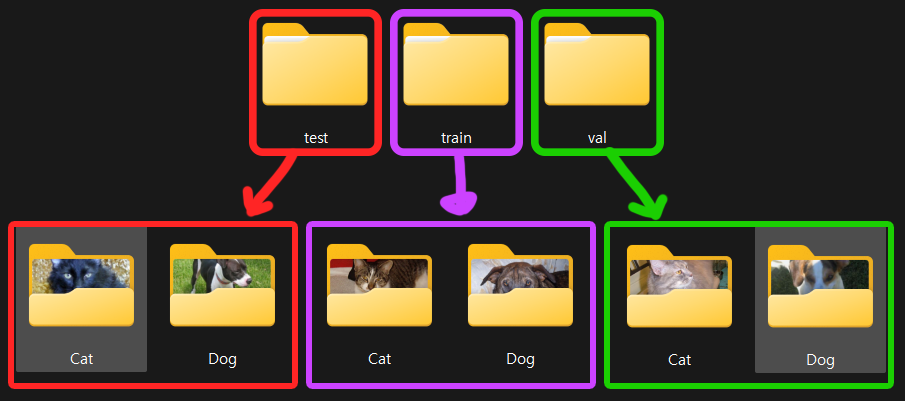
이제 이 데이터셋을 아래의 그림처럼 분리를 해야하는데
 파이썬의 다운가능한 라이브러리 중 Dataset폴더를 손쉽게
파이썬의 다운가능한 라이브러리 중 Dataset폴더를 손쉽게 train, val, test폴더로 나눠주는 라이브러리인 split-folder 모듈을 사용하고자 한다.
! pip install split-folders라이브러리의 설치는 위 명령어를 통해 수행하며
import splitfolders
input_folder = './PetImages' [원본 이미지 폴더 경로]
output_folder = './cats_and_dogs' [분할 후 생성할 폴더 경로]
# 데이터셋을 70% 훈련, 20% 검증, 10% 테스트 세트로 나눔
splitfolders.ratio(input_folder, output=output_folder, seed=1337, ratio=(.7, .2, .1))원본 Dataset 폴더 경로랑
분할하고 새로 생성할 폴더 경로(없으면 폴더 생성함)를 적어두고
splitfolders.ratio함수에 폴더 경로랑 train, val, test의 각 비율만 입력하면 끝난다.
아주 쉬운 데이터셋 분할 라이브러리라 보면 된다.
 폴더의 분할 및 이미지파일의 재 배치는 원본 데이터셋에서 복사하여 분할하는 형식으로 생성되며
폴더의 분할 및 이미지파일의 재 배치는 원본 데이터셋에서 복사하여 분할하는 형식으로 생성되며
 위 사진처럼 원본 Dataset의 라벨명인
위 사진처럼 원본 Dataset의 라벨명인 Cat, Dog가 자동으로 매칭되어 서브폴더명으로 사용된다.
2-1. 이상치 데이터 제거
분리된 데이터셋을 살펴보면
 1)
1) 9171.jpg와 같이 고양이가 아닌 전혀 뚱딴지 같은 파일
 2) 파일이 깨진 상태여서 열리지 않는 파일
2) 파일이 깨진 상태여서 열리지 않는 파일
2종류의 이상치에 속하는 데이터가 존재한다.
1) 항목에 속하는건 사람이 일일히 제거를 해주거나 사전에 학습된 모델로 검토해서 삭제하는게 정론이라 하고.. 머신러닝 기법으로 없애야 하지만
우선은 2) 항목에 속하는 데이터만을 먼저 삭제하고자 한다.
import os
path = '../00_pytest_img/cats_and_dogs'
# 폴더 경로 설정
train_path = os.path.join(path, "train")
val_path = os.path.join(path, "val")
test_path = os.path.join(path, "test")
# 하위 폴더 리스트
subdirs = ['Cat', 'Dog']from PIL import Image
#파일이 열리지 않는경우를 탐지하는 코드
def is_image_broken(image_path):
try:
with Image.open(image_path) as img:
img.verify() # Check if the image can be fully loaded
return False
except Exception as e:
print(f"깨진 이미지: {image_path}, error: {e}")
return True
def remove_broken_images(folder_path):
broken_images = []
for file in os.listdir(folder_path):
image_path = os.path.join(folder_path, file)
if os.path.isfile(image_path) and is_image_broken(image_path):
broken_images.append(image_path)
for image_path in broken_images:
os.remove(image_path)
print(f"제거한 이미지: {image_path}")
print(f"최종 제거한 이미지 {folder_path}: {len(broken_images)}")for dataset_path in [train_path, val_path, test_path]:
for subdir in subdirs:
folder_path = os.path.join(dataset_path, subdir)
remove_broken_images(folder_path) 위 코드를 수행하면 깨진 이미지파일
위 코드를 수행하면 깨진 이미지파일 666.jpg, 11702.jpg를 제거할 수 있을 것이다.
3. 증강기법 실습
다음으로는 PyTorch의 torcivision API에서
제공하는 이미지 변환과 관련된 모듈 transforms의
Data Argumentation 모듈을 적용하여
이미지 변환이 어떻게 이뤄지는지 확인해 보고자 한다.
import random
#train폴더의 모든 이미지 파일을 리스트로 저장하기
img_path_list = []
for subdir in subdirs:
folder_path = os.path.join(train_path, subdir)
for file in os.listdir(folder_path):
img_path = os.path.join(folder_path, file)
if os.path.isfile(img_path):
img_path_list.append(img_path)
random_image_path = random.choice(img_path_list)먼저 train 폴더에 있는 이미지 리스트에서
임의의 이미지 파일 하나를 선택한다.

다음으로 trochvision.transforms.v2 모듈로 데이터 증강 방법론 8개를 선정한다.
from torchvision.transforms import v2
augmentation_transforms = {
'원본' : v2.Compose([
v2.Resize((224, 224)), v2.ToTensor()]),
'랜덤 수평반전' : v2.Compose([
v2.RandomHorizontalFlip(p=1),
v2.Resize((224, 224)), v2.ToTensor()]),
'랜덤 회전' : v2.Compose([
v2.RandomRotation(degrees=45), #이미지를 -45~45사이로 회전
v2.Resize((224, 224)), v2.ToTensor()]),
'색상,밝기,채도' : v2.Compose([
v2.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4,
hue=0.1),
v2.Resize((224, 224)), v2.ToTensor()]),
'랜덤 크롭' : v2.Compose([
v2.RandomResizedCrop((224, 224)),
v2.Resize((224, 224)), v2.ToTensor()]),
'아핀 변환' : v2.Compose([
v2.RandomAffine(degrees=(30, 70),
translate=(0.1, 0.3),
scale=(0.5, 0.75)),
v2.Resize((224, 224)), v2.ToTensor()]),
'가우시안 블러' : v2.Compose([
v2.GaussianBlur(kernel_size=(5, 9),
sigma=(0.1, 5.)),
v2.Resize((224, 224)), v2.ToTensor()]),
'랜덤 회색조' : v2.Compose([
v2.RandomGrayscale(p=1),
v2.Resize((224, 224)), v2.ToTensor()]),
'랜덤 원근변환' : v2.Compose([
v2.RandomPerspective(distortion_scale=0.5, p=1),
v2.Resize((224, 224)), v2.ToTensor()]),
}
# 각 증강 기법을 적용한 이미지 생성
augmented_images = []
titles = []
for name, transform in augmentation_transforms.items():
transformed_image = transform(image)
augmented_images.append(transformed_image)
titles.append(name)이미지 증강기법 8가지와 원본 이미지를 한번에 출력하여 이미지가 어떻게 어떻게 변형되는지 각각 확인해보자
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 시스템에 설치된 폰트 경로
font_path = 'C:\Windows\Fonts\H2HDRM.TTF'
font_name = fm.FontProperties(fname=font_path).get_name()
plt.rc('font', family=font_name)
# 이미지 시각화
fig, axes = plt.subplots(3, 3, figsize=(12, 12))
axes = axes.flatten()
for ax, img, title in zip(axes, augmented_images, titles):
img = img.permute(1, 2, 0)
# Tensor에서 PIL 이미지로 변환 (C, H, W -> H, W, C)
ax.imshow(img)
ax.set_title(title, fontsize=20)
ax.axis('off')
plt.tight_layout()
plt.show()
대략 위 사진처럼 원본 이미지에 여러 이미지 변조가 이뤄지고, 자주 쓰이는 8개의 이미지 변조를 통한 데이터 증강을 이뤄냈으니
이를 사용하여 딥러닝 모델에
데이터 증강의 적용 유/무에 따른 성능 변화를 알아보고자 한다.
참고로데이터 증강(Data Augmentation)이 적용되어 딥러닝 모델에 입력되는 구조는 아래와 같다.
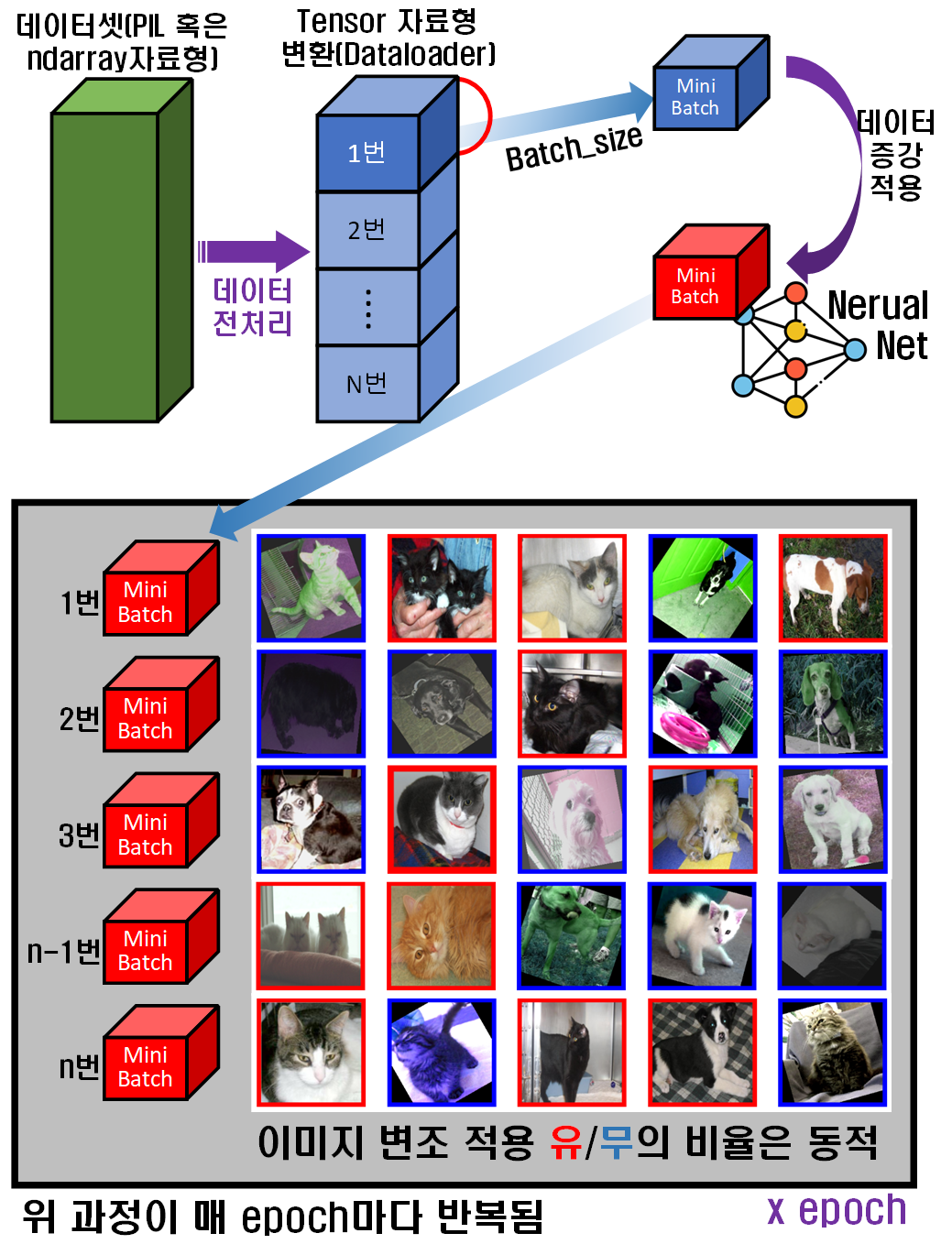 위 사진처럼 데이터 증강(Data Augmentation)이 적용되면 이미지 데이터셋이
위 사진처럼 데이터 증강(Data Augmentation)이 적용되면 이미지 데이터셋이 batch_size로 분할된 Mini_batch이 생성되면, 각 Mini_batch에 이미지가 랜덤하여 담길 것이다.
이 Mini_batch에 담겨진 이미지에 torchvision.transform 라이브러리로 이미지 변조가 적용 될 때, 모든 이미지에 적용되는 것이 아니며 랜덤하게 선택되어 이미지 변조가 적용된다.
이렇게 Mini_batch에 담긴 이미지에 랜덤하게 이미지 변조가 적용되니
[원본 이미지, 변조된 이미지] 세트가 딥러닝 모델의 입력 자료로 활용되는 것이다.
