
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Inception-v3,v4 배경
Inception-v3, v4 net은 이전 포스트 인공지능 고급(시각) 강의 복습 - 18. 주요 CNN알고리즘 구현 : GoogLeNet에서 언급한 Inception Module라는 기본 모듈을 도입한 네트워크인 GoogLeNet를 좀 더 발전 시킨 딥러닝 모델에 속하며,
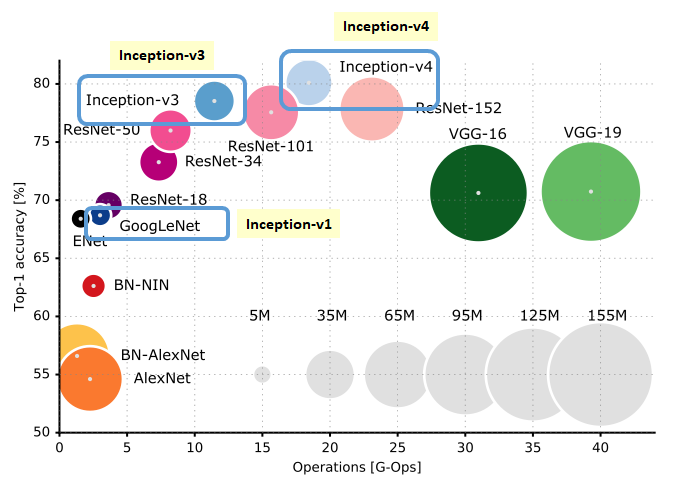 위 그래프에서도 알 수 있듯이
위 그래프에서도 알 수 있듯이
초기 모델인 GoogLeNet(Inception-v1)에 비해 Inception-v3, Inception-v4는 모두 필요 연산량(G-Ops)은 늘어났지만 그많금 Accuracy 성능이 향상된 모델이라 볼 수 있다.
각 논문의 주요 기여를 본다면
Inception v3
1) Factorized Convolutions(합성곱 분해) 기법을 적용하여 모델의 용량(표현력)을 유지하면서 연산 비용 감소
2) Efficient Grid Size Reduction(효율적인 그리드 축소) 기법을 통해 특징 추출의 손실을 줄이면서 연산 효율성을 향상
Inception v4
1) Residual connection 기법 도입을 통해 모델의 깊이를 높이고, 모듈 개선을 통한 성능 향상
으로 요약할 수 있다.
따라서 새로운 개념 도입을 통해 성능을 향상이킨 것이 Inception v3 이라면 Inception v4는 이를 안정화 했다. 이렇게 볼 수 있을 듯 하다.
1.1 Factorized Convolutions
인공지능 고급(시각) 강의 복습 - 14. 주요 CNN알고리즘 구현 : VGGNet에서 언급했던
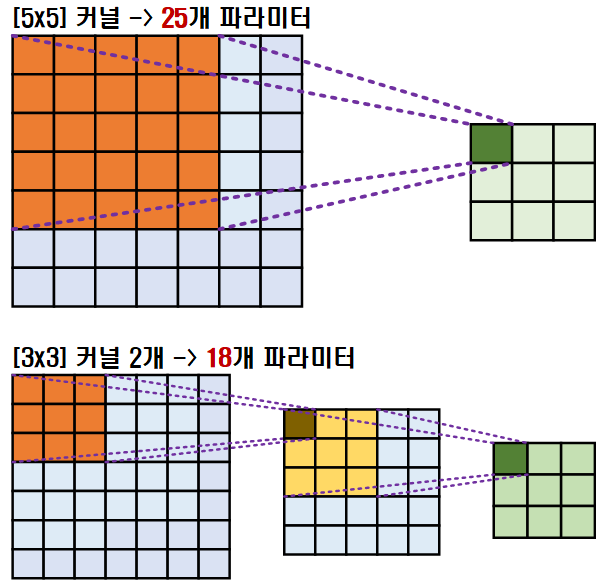 위 사진의 입력 Feature를 Big size Kernel을 적용하여 Conv연산을 수행하는 것이 아닌
위 사진의 입력 Feature를 Big size Kernel을 적용하여 Conv연산을 수행하는 것이 아닌
Small size Kenrnl을 다회 적용하여 Conv연산을 수행하는 기법을 말한다.
이 Factorizad Convolution을 Inception v3에서는 VGGNet에 적용된 기법에서 좀 더 발전시켰으며, 이는 아래의 그림으로 표현할 수 있다.
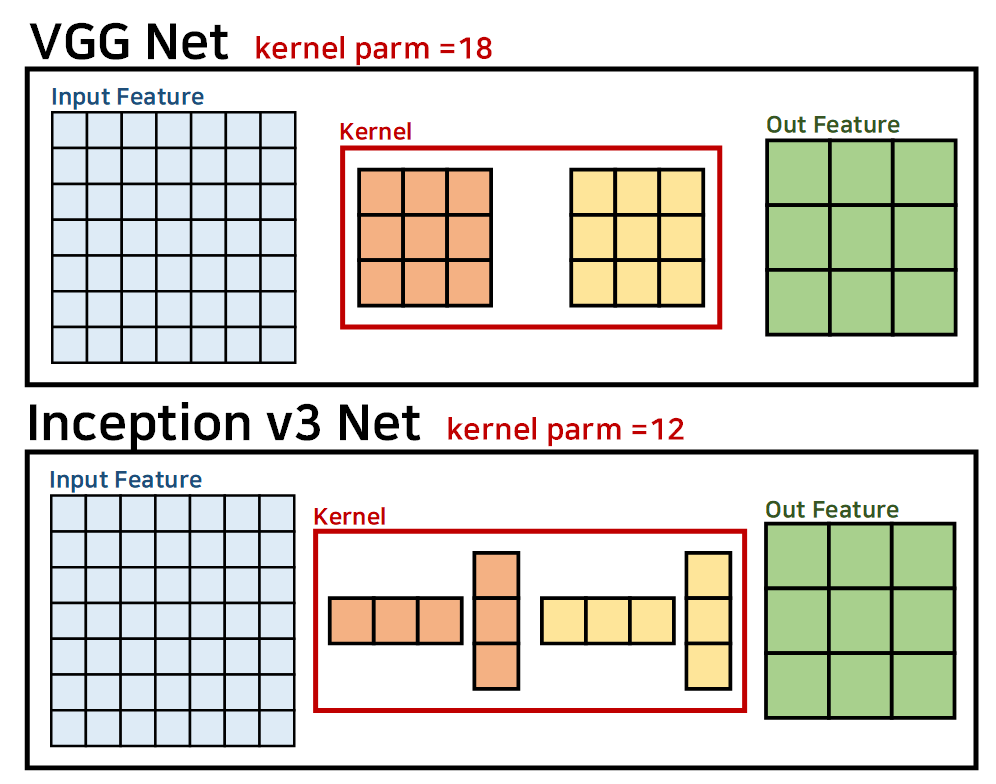 위 사전처럼, 정사각형의 커널(NxN)을 직사각형의 커널(1xN, Nx1)으로 한번 더 나누어 적용한 것으로 Inception v3은 VGGNet에 보다 더 적은 Parameter로 Conv연산을 수행, 더 높은 연산효율성을 달성했다.
위 사전처럼, 정사각형의 커널(NxN)을 직사각형의 커널(1xN, Nx1)으로 한번 더 나누어 적용한 것으로 Inception v3은 VGGNet에 보다 더 적은 Parameter로 Conv연산을 수행, 더 높은 연산효율성을 달성했다.
1.2 Efficient Grid Size Reduction
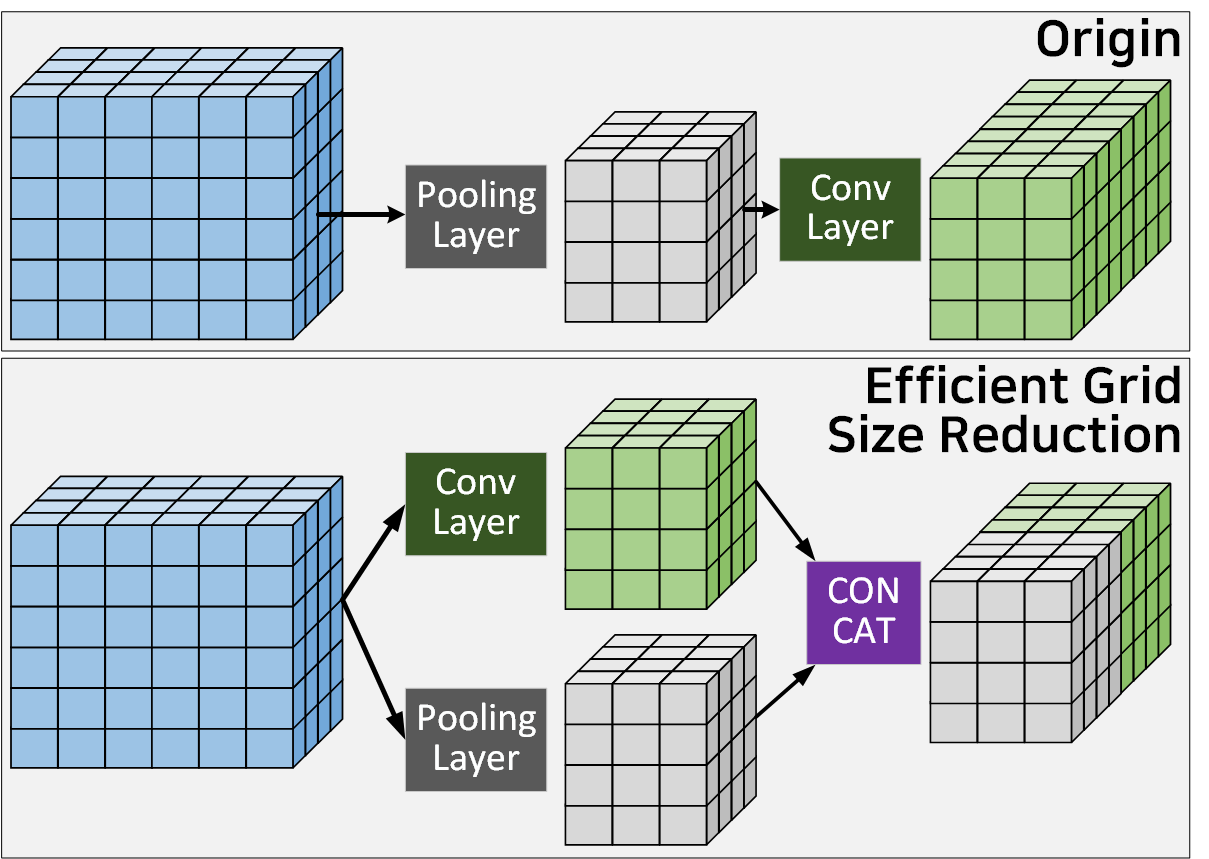 효율적인 그리드 축소 방식은 위 사진의
효율적인 그리드 축소 방식은 위 사진의 Origin방식처럼 Pool을 적용하여 Feature Map을 축소 했다면
그 이후 2배의 Kernel을 가진 Conv를 적용하여 Representational bottlenet 현상이 발생하는 것을 방지한다.
이를 Inception v3논문에서는 Conv와 Pool을 병렬로 적용한 뒤 이를 ConCat하는 방식으로 Origin방식 대비 정보 손실율이 덜 발생하면서, 동시에 연산 효율성을 달성한 기법이라 볼 수 있다.
1.3 Residual connection
Inception v4에 적용된 Residual Connection은 ResNet계열에 적용된 Residual block 방법론을 차용한 것이 해당 논문의 기여라고 볼 수 있지만
이 논문을 보면... Residual Connection이 적용된
Inception-ResNet-V1과 적용되지 않은
Inception-V4를 같은 선상에서 아키텍쳐를 설명하고 성능 비교평가를 수행하기에 조금 와닿지 않는 부분이 있다.
따라서 Inception v4는 ResNet방법론을 채용해서 성능향상을 꾀했다 이렇게 정리하는 것보다는
Inception v3 대비 더 단순하고 획일화된 구조로 만듦새를 조정함과 동시에 더 깊은 네트워크로 설계하여
전반적인 성능향상 및 안정화를 꾀했다.
이렇게 이해하는게 더 옳은 논문이긴 하다.
2. Inception V3 아키텍쳐
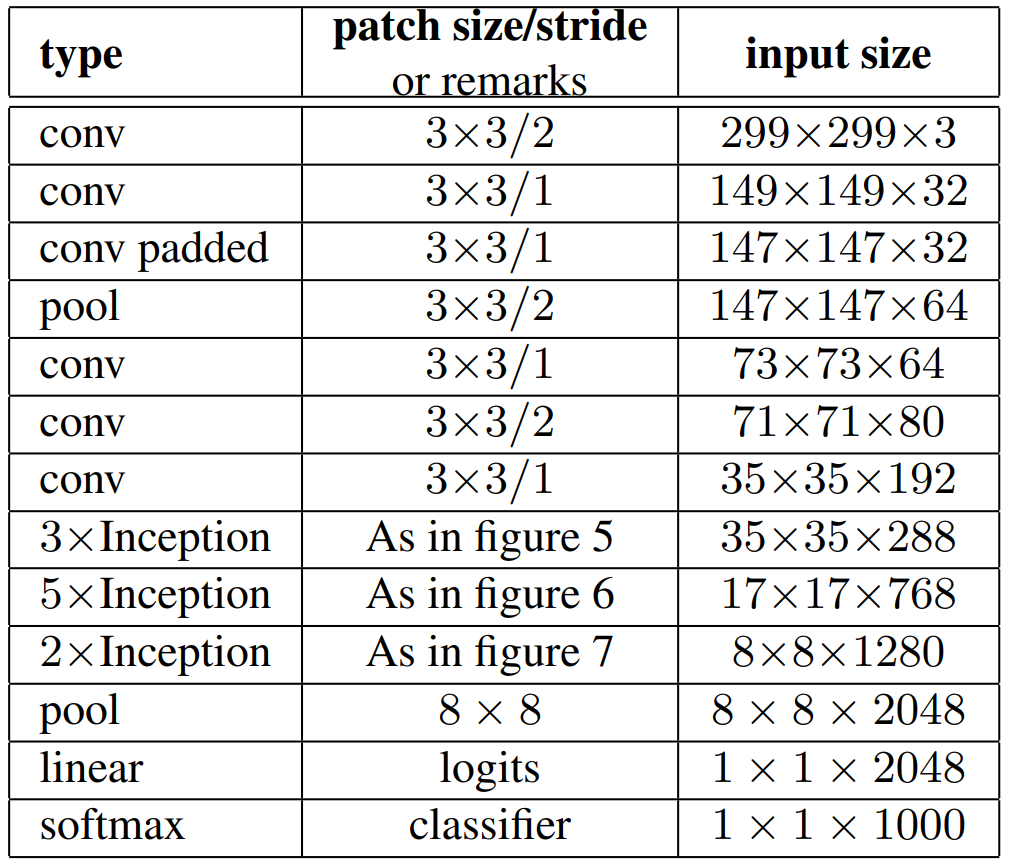 논문에서 언급한 아키텍처의 구성은 위 표로 확인이 가능한데
논문에서 언급한 아키텍처의 구성은 위 표로 확인이 가능한데 Auxiliary classifier(보조분류기)까지 구성되어 있어서
실제로 코드로 구현하면 좀 마음이 아파오는 구조긴 하다.
하나하나 설명하자면 아래와 같다.
1) BasicConv2d
앞으로 진행하는 왠만한 CNN은
Conv BatchNorm ReLU 이 3개의 레이어가 항상 붙어서
기본 블록이 되어 동작한다 라고 보면 된다.
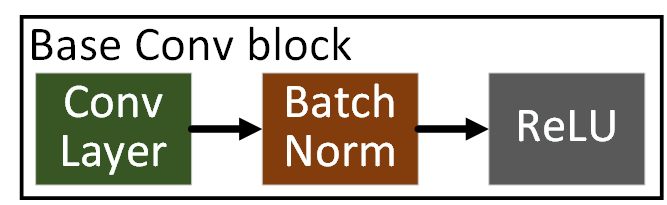
따라서 이 기본블록을 코드로 구현하면 아래와 같다.
import torch
import torch.nn as nnclass BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias = False, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels, eps = 0.001)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x기본 블록의 구조를 이해하면서
뇌를 아프게 하는 **kwargs 구문이 발생했는데
이는 아래의 영상을 시청하여 공부하자
결론만 말하자면 인자값을 뭉텅이로 쉽게 넘기려고 할 때 **kwargs를 쓴다 보면 된다.
2) Inception 5, 6, 7
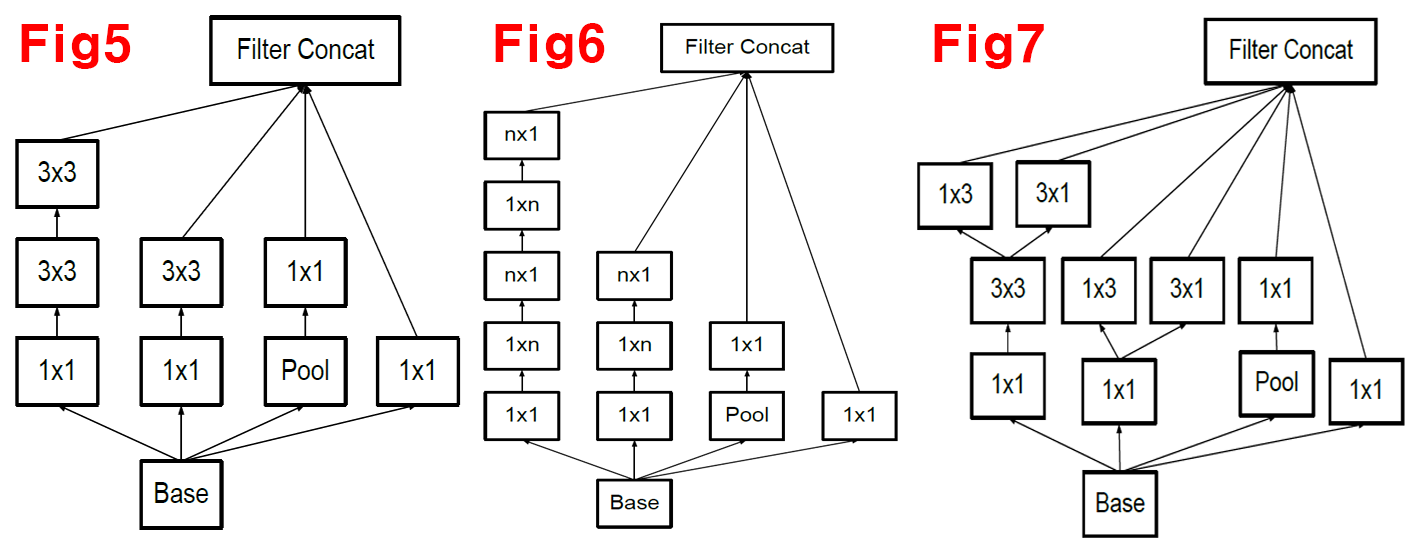 위 사진이
위 사진이 Factorized Convolutions이 본격적으로 적용된 모듈이라 보면 되며, 많은 Conv block가 (1xN), (Nx1)의
직사각형 Kernel이 적용되어 있다.
이를 각각 코드로 구현하면 아래와 같다.
class InceptionF5(nn.Module): # Figure 5
def __init__(self, in_channels):
super().__init__()
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size = 1),
BasicConv2d(64, 96, kernel_size = 3, padding = 1),
BasicConv2d(96, 96, kernel_size = 3, padding = 1),
)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 48, kernel_size = 1),
BasicConv2d(48, 64, kernel_size = 3, padding = 1),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1),
BasicConv2d(in_channels, 64, kernel_size = 1),
)
self.branch4 = BasicConv2d(in_channels, 64, kernel_size = 1)
def forward(self, x):
return torch.cat([self.branch1(x), self.branch2(x), self.branch3(x), self.branch4(x)], dim = 1)class InceptionF6(nn.Module): # Figure 6
def __init__(self, in_channels, f_7x7):
super().__init__()
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, f_7x7, kernel_size = 1),
BasicConv2d(f_7x7, f_7x7, kernel_size = (1, 7), padding = (0, 3)),
BasicConv2d(f_7x7, f_7x7, kernel_size = (7, 1), padding = (3, 0)),
BasicConv2d(f_7x7, f_7x7, kernel_size = (1, 7), padding = (0, 3)),
BasicConv2d(f_7x7, 192, kernel_size = (7, 1), padding = (3, 0)),
)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, f_7x7, kernel_size = 1),
BasicConv2d(f_7x7, f_7x7, kernel_size = (1, 7), padding = (0, 3)),
BasicConv2d(f_7x7, 192, kernel_size = (7, 1), padding = (3, 0)),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(3, stride = 1, padding = 1),
BasicConv2d(in_channels, 192, kernel_size = 1),
)
self.branch4 = BasicConv2d(in_channels, 192, kernel_size = 1)
def forward(self, x):
return torch.cat([self.branch1(x), self.branch2(x), self.branch3(x), self.branch4(x)], dim = 1)class InceptionF7(nn.Module): # Figure 7
def __init__(self, in_channels):
super().__init__()
self.branch1_stem = nn.Sequential(
BasicConv2d(in_channels, 448, kernel_size = 1),
BasicConv2d(448, 384, kernel_size = 3, padding = 1),
)
self.branch1_left = BasicConv2d(384, 384, kernel_size = (1, 3), padding = (0, 1))
self.branch1_right = BasicConv2d(384, 384, kernel_size = (3, 1), padding = (1, 0))
self.branch2_stem = BasicConv2d(in_channels, 384, kernel_size = 1)
self.branch2_left = BasicConv2d(384, 384, kernel_size = (1, 3), padding = (0, 1))
self.branch2_right = BasicConv2d(384, 384, kernel_size = (3, 1), padding = (1, 0))
self.branch3 = nn.Sequential(
nn.MaxPool2d(3, stride = 1, padding = 1),
BasicConv2d(in_channels, 192, kernel_size = 1)
)
self.branch4 = BasicConv2d(in_channels, 320, kernel_size = 1)
def forward(self, x):
branch1_stem = self.branch1_stem(x)
branch2_stem = self.branch2_stem(x)
branch1 = torch.cat([self.branch1_left(branch1_stem), self.branch1_right(branch1_stem)], dim = 1)
branch2 = torch.cat([self.branch2_left(branch2_stem), self.branch2_right(branch2_stem)], dim = 1)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
return torch.cat([branch1, branch2, branch3, branch4], dim = 1)3) Efficient Grid Size Reduction Module
아키텍쳐 표에서는 재대로 표현되어 있지 않지만
이 효율적인 그리드 축소 기법이 적용된 Inception Module이 존재한다.
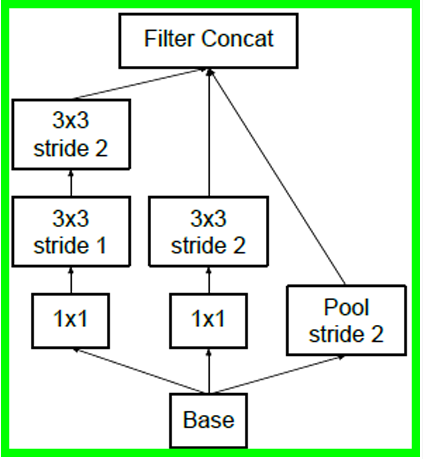
대략 위 사진처럼 Conv랑 Pool이 병렬로 연산된 뒤 마지막에 Concat이 진행되는 앞서 언급한 그리드 축소 기법이 재대로 적용된 모듈이며,
이 모듈이 A버전 B버전 2개가 존재하기에 각각 코드로 구현한다.
class Inception_ReduceA(nn.Module): # Figure 10 : conv (stride 2) -> pooling operation,
# 사람들 마다 코드가 조금씩 달라 pytorch source code를 이용.
def __init__(self, in_channels):
super().__init__()
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size = 1),
BasicConv2d(64, 96, kernel_size = 3, padding = 1),
BasicConv2d(96, 96, kernel_size = 3, stride = 2),
)
self.branch2 = BasicConv2d(in_channels, 384, kernel_size = 3, stride = 2)
self.branch3 = nn.MaxPool2d(3, stride = 2)
def forward(self, x):
return torch.cat([self.branch1(x), self.branch2(x), self.branch3(x)], dim = 1)class Inception_ReduceB(nn.Module): # Figure 10 : conv (stride 2) -> pooling operation
# 사람들 마다 코드가 조금씩 달라 pytorch source code를 이용.
def __init__(self, in_channels):
super().__init__()
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size = 1),
BasicConv2d(192, 192, kernel_size = (1, 7), padding = (0, 3)),
BasicConv2d(192, 192, kernel_size = (7, 1), padding = (3, 0)),
BasicConv2d(192, 192, kernel_size = 3, stride = 2)
)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size = 1),
BasicConv2d(192, 320, kernel_size = 3, stride = 2),
)
self.branch3 = nn.MaxPool2d(3, stride = 2)
def forward(self, x):
return torch.cat([self.branch1(x), self.branch2(x), self.branch3(x)], dim = 1)4) Auxiliary classifier(보조분류기)
Inception v3까지는 보조분류기가 적용되어 있고
Inception v4는 보조분류기가 빠지며
앞으로 설명하는 CNN은 왠만하면 보조분류기가 없는 모델이 대다수라 보면된다.
class Inception_Aux(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d((5, 5)) # paper에는 nn.AvgPool2d(kernel_size = 5, stride = 3)
self.conv = BasicConv2d(in_channels, 128, kernel_size = 1)
self.fc1 = nn.Linear(5 * 5 * 128, 1024)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.7)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.avgpool(x) # N x 768 x 17 x 17 -> N x 768 x 5 x 5
x = self.conv(x) # N x 768 x 5 x 5 -> N x 128 x 5 x 5
x = torch.flatten(x, 1) # N x 128 x 5 x 5 -> N x 3200
x = self.fc1(x) # N x 3200 -> N x 1024
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x) # N x 1024 -> N x 1000
return x5) Inception v3
위 1) ~ 4)항목을 모두 합쳐서 Inception v3을 생성하자
class Inception_V3(nn.Module):
def __init__(self, in_channels, num_classes, aux_logits = True, drop_p = 0.5):
super(Inception_V3, self).__init__()
assert aux_logits == True or aux_logits == False #aux_logits는 무조건 T/F값만 갖는다.
self.aux_logits = aux_logits
self.conv1a = BasicConv2d(in_channels, 32, kernel_size = 3, stride = 2)
self.conv1b = BasicConv2d(32, 32, kernel_size = 3)
self.conv1c = BasicConv2d(32, 64, kernel_size = 3, padding = 1)
self.pool1 = nn.MaxPool2d(3, stride = 2)
self.conv2a = BasicConv2d(64, 80, kernel_size = 3)
self.conv2b = BasicConv2d(80, 192, kernel_size = 3, stride = 2)
self.conv2c = BasicConv2d(192, 288, kernel_size = 3, padding = 1)
self.inception3a = InceptionF5(288)
self.inception3b = InceptionF5(288)
self.inception3c = InceptionF5(288)
self.inception_red1 = Inception_ReduceA(288)
self.inception4a = InceptionF6(768, f_7x7 = 128)
self.inception4b = InceptionF6(768, f_7x7 = 160)
self.inception4c = InceptionF6(768, f_7x7 = 160)
self.inception4d = InceptionF6(768, f_7x7 = 160)
self.inception4e = InceptionF6(768, f_7x7 = 192)
if aux_logits:
self.aux = Inception_Aux(768, num_classes = num_classes)
self.inception_red2 = Inception_ReduceB(768)
self.inception5a = InceptionF7(1280)
self.inception5b = InceptionF7(2048)
self.pool6 = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p = drop_p)
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.conv1a(x) # -> N x 32 x 149 x 149
x = self.conv1b(x) # -> N x 32 x 147 x 147
x = self.conv1c(x) # -> N x 64 x 147 x 147
x = self.pool1(x) # -> N x 64 x 73 x 73
x = self.conv2a(x) # -> N x 80 x 71 x 71
x = self.conv2b(x) # -> N x 192 x 35 x 35
x = self.conv2c(x) # -> N x 288 x 35 x 35
x = self.inception3a(x) # -> N x (96 + 64 * 3) x 35 x 35 = N x 288 x 35 x 35
x = self.inception3b(x) # -> N x 288 x 35 x 35
x = self.inception3c(x) # -> N x 288 x 35 x 35
x = self.inception_red1(x) # -> N x 768 x 17 x 17
x = self.inception4a(x) # -> N x (192 * 4) x 17 x 17 = N x 768 x 17 x 17
x = self.inception4b(x) # -> N x 768 x 17 x 17
x = self.inception4c(x) # -> N x 768 x 17 x 17
x = self.inception4d(x) # -> N x 768 x 17 x 17
x = self.inception4e(x) # -> N x 768 x 17 x 17
if self.aux is not None and self.training:
aux = self.aux(x)
else:
aux = None # Not defined error 방지
x = self.inception_red2(x) # -> N x 1280 x 8 x 8
x = self.inception5a(x) # -> N x (384 * 2 * 2 + 192 + 320) x 8 x 8 = N x 2048 x 8 x 8
x = self.inception5b(x) # -> N x 2048 x 8 x 8
x = self.pool6(x) # -> N x 2048 x 1 x 1
x = torch.flatten(x, 1) # -> N x 2048
x = self.dropout(x)
x = self.fc(x) # -> N x 1000
if self.training:
return [x, aux]
else:
return x모델 설계를 완료했으니
디버깅 과정을 수행하자
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
debug_model = Inception_V3(in_channels = 3, num_classes=1000, aux_logits=True)
summary(debug_model, input_size=(3, 229, 229), device='cpu')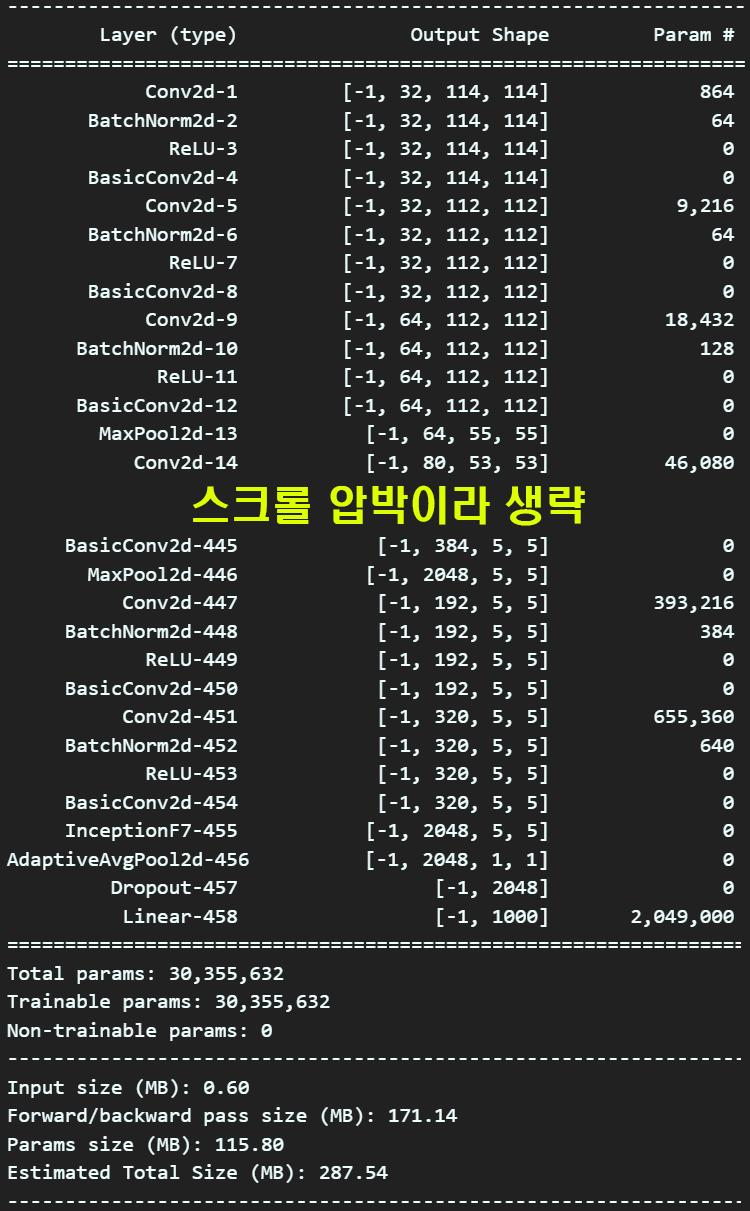 설계한 모델을 보면 총 파라미터의 개수는 3천만개로
설계한 모델을 보면 총 파라미터의 개수는 3천만개로
이정도면.. PC에서 돌려봐도 무리가 없을 수준이다.
3. Inception V4 아키텍쳐
Inception v3의 모델을 설계하고 설계한 모델에 대해 성능평가를 수행하지 않고 바로 Inception v4로 넘어가는 이유는
아무래도 둘 다 비슷한 개념을 공유하는 모델인데
안정화는 Inception v4모델에서 수행된?
다시 표현하자면 Inception Module의 완결 버전이 Inception v4라 볼 수 있으면서
동시에 논문에서 오탈자가 많아 코드구현은 상당히 난이도가 있는 모델이 Inception v4이어서 이 모델을 설명하고
코드구현 후 해당 모델로 성능평가를 수행하려 한다.
이게... Inception v4 논문을 보면 그림만 잔뜩 있는데
뭐 설명이 워낙 난해해서 참 머리아픈 모델이기도 하다.
참고로 Inception v4논문에서는
Inception-v4, Inception-ResNet-v1, Inception-Resnet-v2
총 3개의 파생 네트워크에 대해 비교분석을 수행한다.
이 중, 필자는 Inception-v4, Inception-Resnet-v2를 구현하고
Inception-Resnet-v2로 성능평가, API등을 설계하고자 한다.
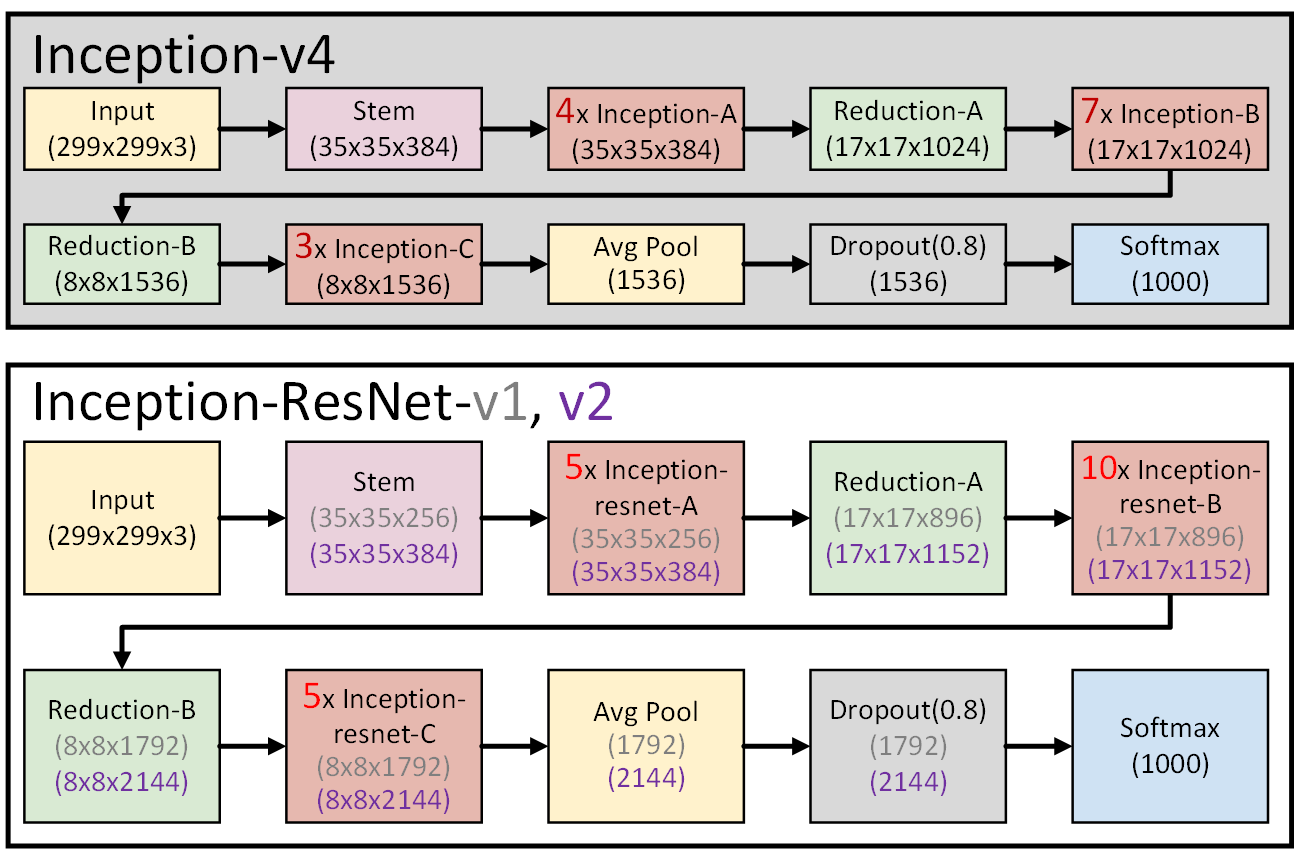
Inception-v4, Inception-ResNet-v1, Inception-Resnet-v2
위 3개의 Net에 대한 전반적인 모듈 아키텍쳐 흐름은 위 사진처럼 표현할 수 있다.
이 중 붉은색 박스로 되어 있는 블록은 반복해서 달라붙는 블록이라 보면 된다.
Inception-ResNet-v1에 대해서 구현하지 않는 이유는
논문에서도 그렇게 중요하게 다루는 모델도 아니고
음.. 딱 3형제가 있을 때 가장 존재감이 없어지는 둘째?
그런 느낌이다...
그리고 차별대우를 받는 다는 느낌을 확 받는것이
혼자만 Stem 모델의 머릿 부분이 다르게 설계되어 있다.
아 참고로 Inception v4도 똑같이 BaseConv블록기반으로 전체 모델을 풀어나간다
import torch
import torch.nn as nn## 가장 기본 모듈인 Conv2d 모듈 설계
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias = False, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels) #eps는 기본값이 있으니 안쓴다..
#분모가 0으로 되서 NaN방지하는게 eps값이니 신경쓰지말자.. 기본값 있음...
self.relu = nn.ReLU(inplace=True)
#inplace=True는 메모리 공간을 재사용해서 메모리 최적화를 하라는거임
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x1) stem 블록 (모델의 머리 부분)
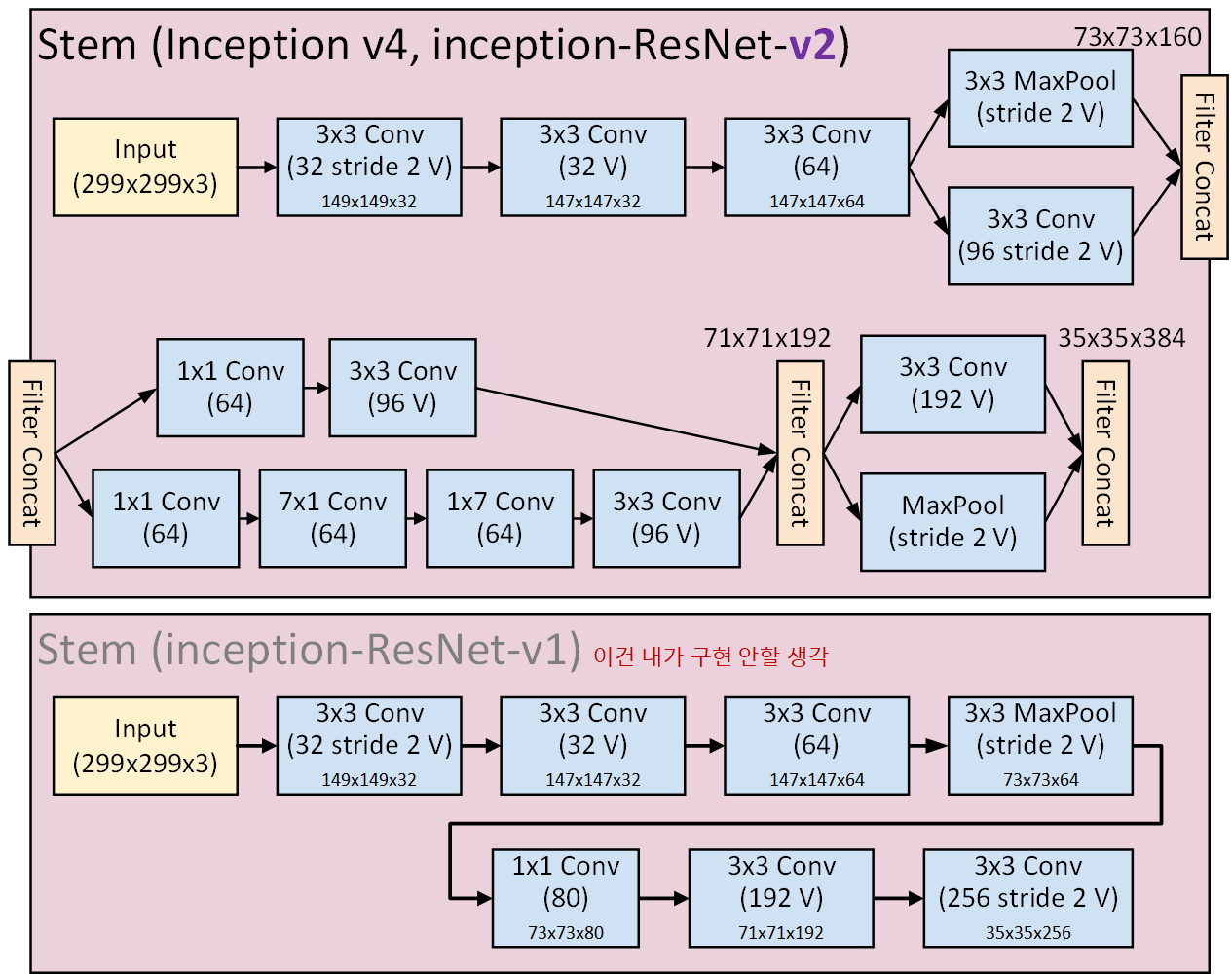 모델의 머리 부분에 해당하는 Stem은 복잡하게 생긴 위 Stem블록을
모델의 머리 부분에 해당하는 Stem은 복잡하게 생긴 위 Stem블록을
Inception-v4, Inception-Resnet-v2에 적용되어 있다.
이게 워낙 길게 되어 있어서
두줄로 나눠서 그림을 그리다 보니 Filter Concat부분을 꼼수로 두줄로 나누는 식으로 표현을 했다.
그리고 Inception v4는 모듈이 굉장히 많고 복잡하고, 내부 하이퍼 파라미터도 다 일일히 기재되어 있다보니
Inception-v4 : 검정색
Inception-Resnet-v2 : 보라색
으로 하이퍼 파라미터의 색상을 구분했다.
#코드 구현은 v4, resNet-v2 두개를 구현하자
class Stem(nn.Module):
def __init__(self, in_channels):
super(Stem, self).__init__()
self.conv1 = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size=3, stride=2, padding=0), #149x149x32
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=0), #147x147x32
BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1) #147x147x64
)
self.branch1_Pool = nn.MaxPool2d(3, stride=2, padding=0) #73x7xx64
self.branch1_Conv = BasicConv2d(64, 96, kernel_size=3, stride=2, padding=0)#73x73x96
self.branch2_Conv = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1, padding=0),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=0)
) #71x71x96
self.branch2_Conv_7x7 = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1, padding=0),
BasicConv2d(64, 64, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(64, 64, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=0)
) #71x71x96
self.branch3_Conv = BasicConv2d(192, 192, kernel_size=3, stride=2, padding=0) #35x35x192
self.branch3_Pool = nn.MaxPool2d(3, stride=2, padding=0) #35x35x192
def forward(self, x):
x = self.conv1(x)
x1 = self.branch1_Pool(x)
x2 = self.branch1_Conv(x)
x = torch.cat([x1, x2], dim=1)
x1 = self.branch2_Conv(x)
x2 = self.branch2_Conv_7x7(x)
x = torch.cat([x1, x2], dim=1)
x1 = self.branch3_Conv(x)
x2 = self.branch3_Pool(x)
x = torch.cat([x1, x2], dim=1)
return x2) Inception A 블록
이 블록은 반복해서 붙여넣는 블록이다.
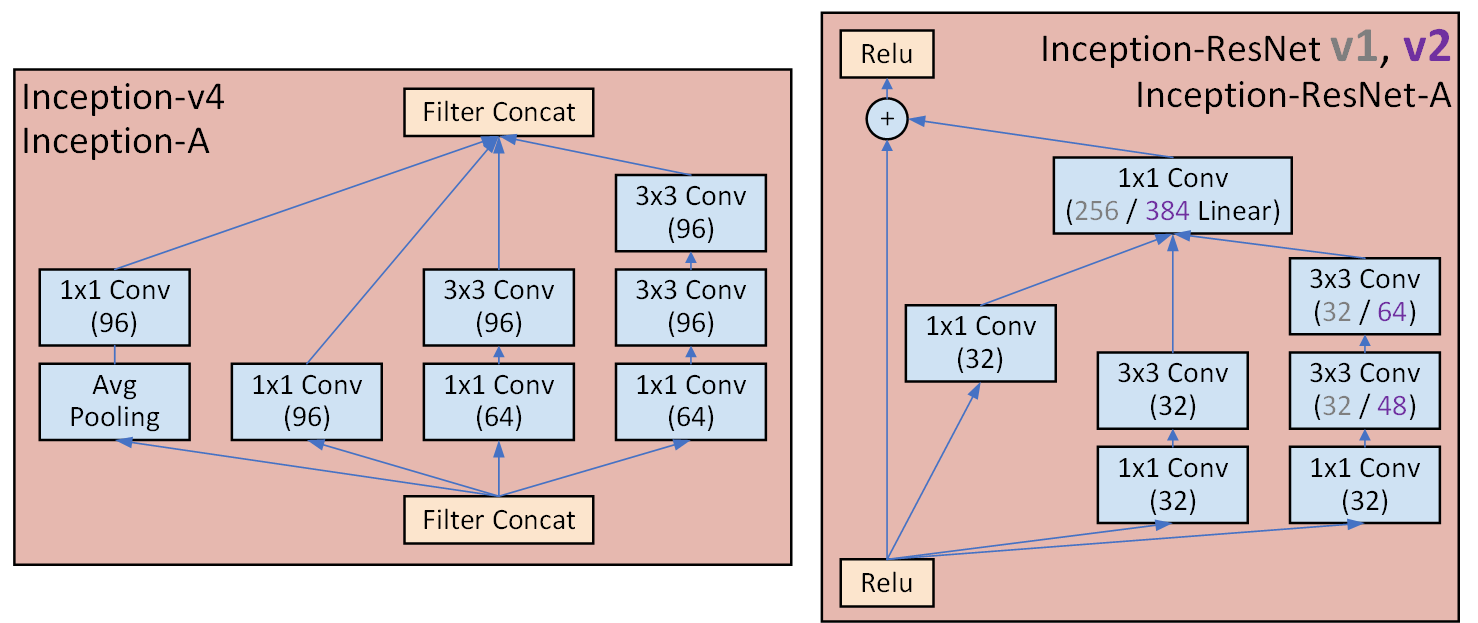
이 붉은색 블록들은
Inception-v4, Inception-Resnet-v2이 가장 주요한 차이를 보여주는데
Inception-Resnet-v2에서 ResNet이라 할 법한 Skip Connection이 적용됨을 확인할 수 있다.
#코드 구현은 v4, resNet-v2 두개를 구현하자
class InceptionA_v4(nn.Module):
def __init__(self, in_channels):
super(InceptionA_v4, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, 96, kernel_size=1, stride=1, padding=0)
)
self.branch2 = BasicConv2d(in_channels, 96, kernel_size=1, stride=1, padding=0)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size=1, stride=1, padding=0),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1)
)
self.branch4 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size=1, stride=1, padding=0),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
class InceptionA_ResNet_v2(nn.Module):
def __init__(self, in_channels):
super(InceptionA_ResNet_v2, self).__init__()
self.branch1 = BasicConv2d(in_channels, 32, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size=1, stride=1, padding=0),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size=1, stride=1, padding=0),
BasicConv2d(32, 48, kernel_size=3, stride=1, padding=1),
BasicConv2d(48, 64, kernel_size=3, stride=1, padding=1)
)
#여기서 128은 branch1~3의 아웃풋 출력 합산값이다.
self.conv1x1_linear = nn.Conv2d(128, in_channels, kernel_size=1, stride=1, padding=0)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat([x1, x2, x3], dim=1)
out = self.conv1x1_linear(out)
out = out + residual
out = self.relu(out)
return out3) Reduction A 블록
앞서 언급한 Inception v3의 Efficient Grid Size Reduction기법이 해당 블록에 적용되었다 보면 된다.
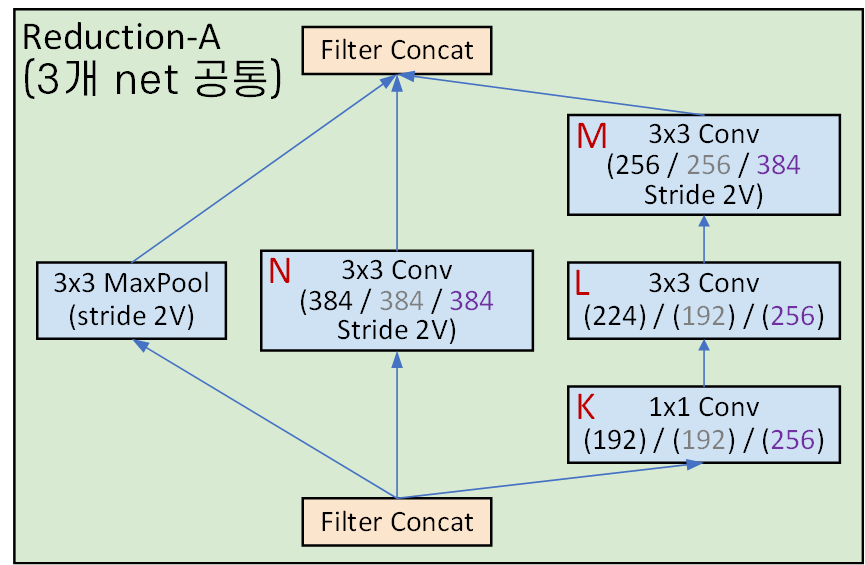
#코드 구현은 v4, resNet-v2 두개를 구현하자
# v4 : k=192, l=224, m=256, n=384
# resnet_v1 : k=192, l=192, m=256, n=384
# resnet_v2 : k=256, l=256, m=384, n=384
class ReductionA(nn.Module):
def __init__(self, in_channels, k, l, m, n):
super(ReductionA, self).__init__()
self.branch1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.branch2 = BasicConv2d(in_channels, n, kernel_size=3, stride=2, padding=0)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, k, kernel_size=1, stride=1, padding=0),
BasicConv2d(k, l, kernel_size=3, stride=1, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2, padding=0)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x = torch.cat([x1, x2, x3], dim=1)
return x여기서 사람 열받게 하는 [K, L, M, N]계수가 존재하는데
Inception-v4, Inception-ResNet-v1, Inception-Resnet-v2 각각 다른 값이 적용되어 있다.
이게 왜 열받는 계수나면... 해당 블록 모듈 사진이랑
이 계수에 해당하는 표가 다른 페이지에 기재되어 있다.

4) Inception B 블록
역시 이 블록도 반복해서 달라붙는다.
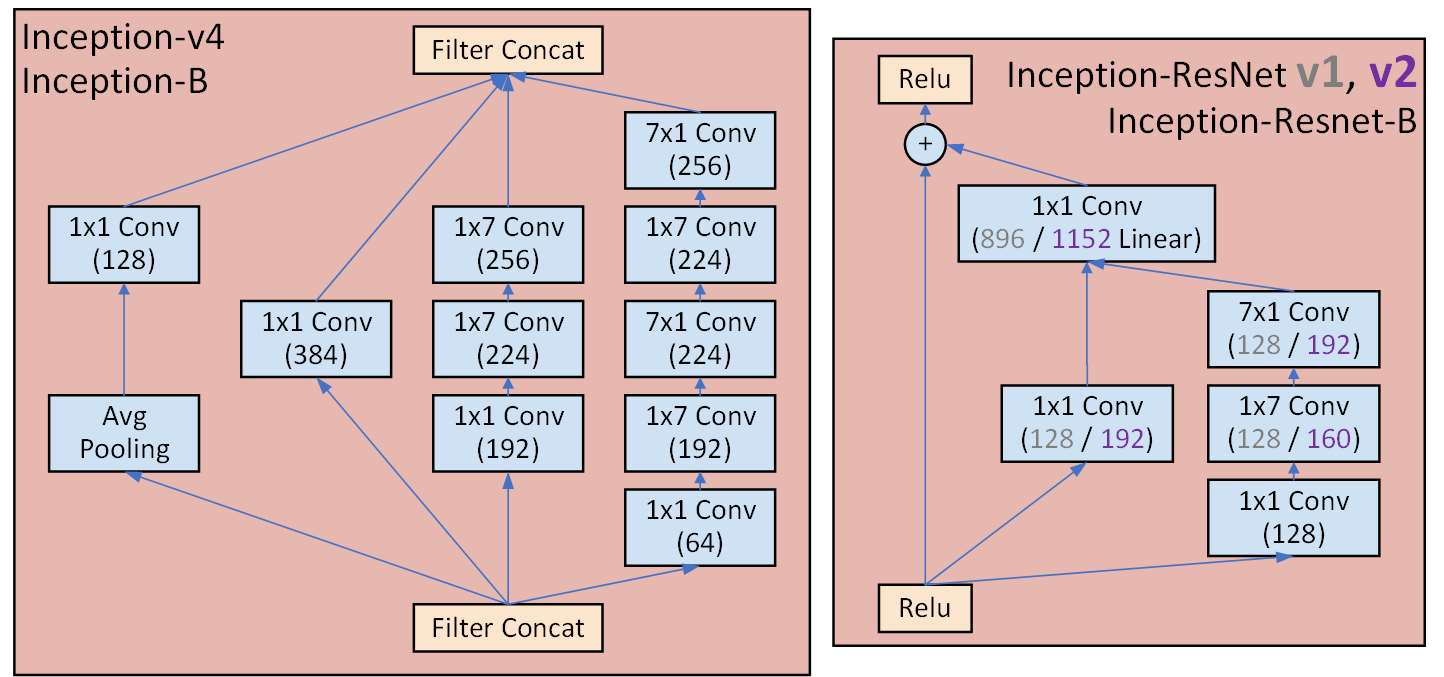
#코드 구현은 v4, resNet-v2 두개를 구현하자
class InceptionB_v4(nn.Module):
def __init__(self, in_channels):
super(InceptionB_v4, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, 128, kernel_size=1, stride=1, padding=0)
)
self.branch2 = BasicConv2d(in_channels, 384, kernel_size=1, stride=1, padding=0)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size=1, stride=1, padding=0),
BasicConv2d(192, 224, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(224, 256, kernel_size=(7,1), stride=1, padding=(3,0))
)
self.branch4 = nn.Sequential(
BasicConv2d(in_channels, 64, kernel_size=1, stride=1, padding=0),
BasicConv2d(64, 192, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(192, 224, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(224, 224, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(224, 256, kernel_size=(7,1), stride=1, padding=(3,0)),
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
class InceptionB_ResNet_v2(nn.Module):
def __init__(self, in_channels):
super(InceptionB_ResNet_v2, self).__init__()
self.branch1 = BasicConv2d(in_channels, 192, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 128, kernel_size=1, stride=1, padding=0),
BasicConv2d(128, 160, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(160, 192, kernel_size=(7,1), stride=1, padding=(3,0))
)
#여기서 384은 branch1~2의 아웃풋 출력 합산값이다.
self.conv1x1_linear = nn.Conv2d(384, in_channels, kernel_size=1, stride=1, padding=0)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat([x1, x2], dim=1)
out = self.conv1x1_linear(out)
out = out + residual
out = self.relu(out)
return out5) Reduction B 블록
이 블록은 또 Reduction A와 다르게 Inception-v4
Inception-ResNet-v1, Inception-Resnet-v2 이렇게 구조가 살짝 다르다
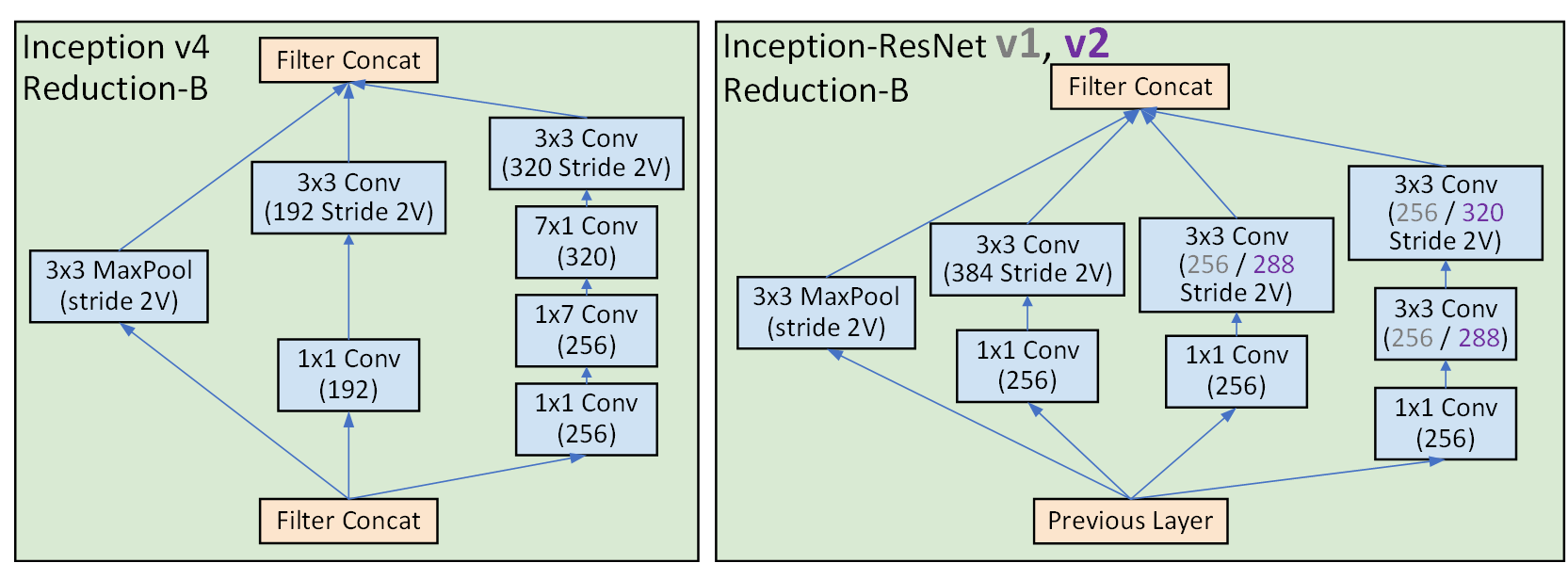
#코드 구현은 v4, resNet-v2 두개를 구현하자
class ReductionB_v4(nn.Module):
def __init__(self, in_channels):
super(ReductionB_v4, self).__init__()
self.branch1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size=1, stride=1, padding=0),
BasicConv2d(192, 192, kernel_size=3, stride=2, padding=0)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0),
BasicConv2d(256, 256, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(256, 320, kernel_size=(7,1), stride=1, padding=(3,0)),
BasicConv2d(320, 320, kernel_size=3, stride=2, padding=0)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
return torch.cat([x1, x2, x3], dim=1)
class ReductionB_ResNet_v2(nn.Module):
def __init__(self, in_channels):
super(ReductionB_ResNet_v2, self).__init__()
self.branch1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0),
BasicConv2d(256, 384, kernel_size=3, stride=2, padding=0)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0),
BasicConv2d(256, 288, kernel_size=3, stride=2, padding=0)
# BasicConv2d(256, 256, kernel_size=3, stride=2, padding=0)
)
self.branch4 = nn.Sequential(
BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0),
BasicConv2d(256, 288, kernel_size=3, stride=1, padding=1),
BasicConv2d(288, 320, kernel_size=3, stride=2, padding=0)
# BasicConv2d(256, 256, kernel_size=3, stride=1, padding=1),
# BasicConv2d(256, 256, kernel_size=3, stride=2, padding=0)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)6) Inception C 블록
마지막으로 반복되는 블록이다.
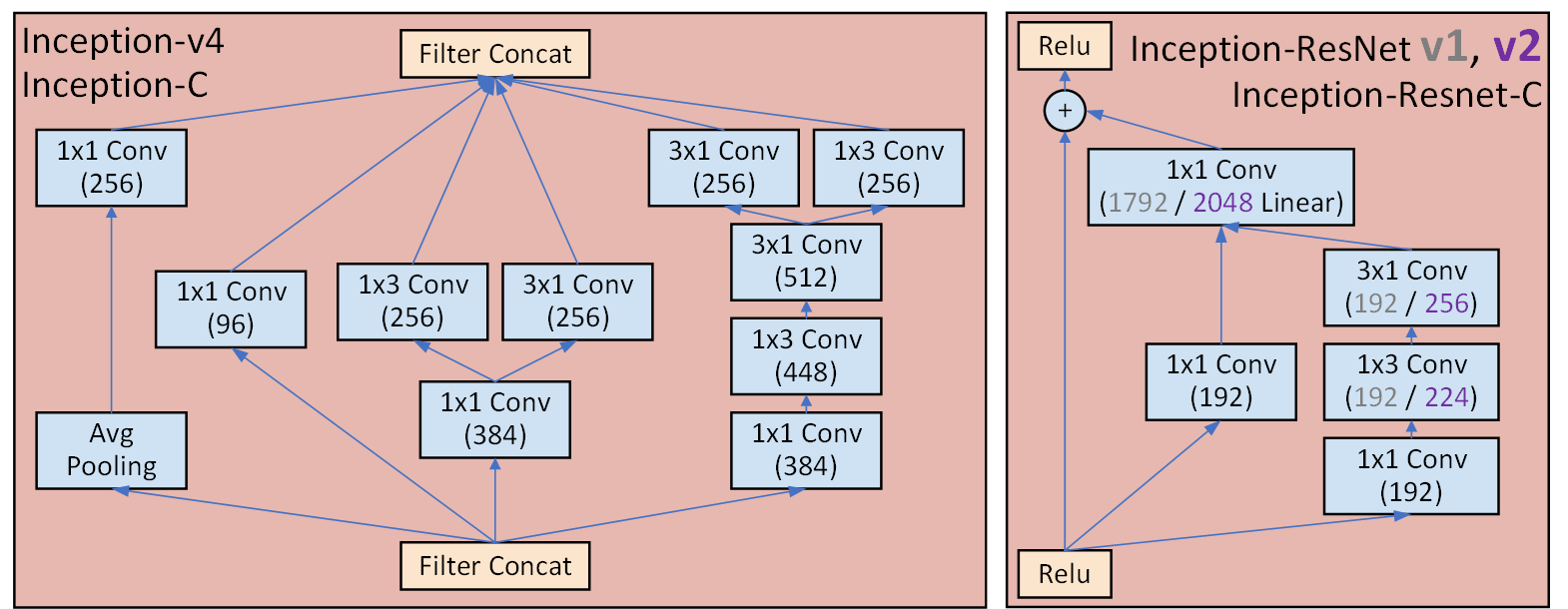
class InceptionC_v4(nn.Module):
def __init__(self, in_channels):
super(InceptionC_v4, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0)
)
self.branch2 = BasicConv2d(in_channels, 256, kernel_size=1, stride=1, padding=0)
self.branch3 = BasicConv2d(in_channels, 384, kernel_size=1, stride=1, padding=0)
self.branch3_1x3 = BasicConv2d(384, 256, kernel_size=(1,3), stride=1, padding=(0,1))
self.branch3_3x1 = BasicConv2d(384, 256, kernel_size=(3,1), stride=1, padding=(1,0))
self.branch4 = nn.Sequential(
BasicConv2d(in_channels, 384, kernel_size=1, stride=1, padding=0),
BasicConv2d(384, 448, kernel_size=(1,3), stride=1, padding=(0,1)),
BasicConv2d(448, 512, kernel_size=(3,1), stride=1, padding=(1,0))
)
self.branch4_1x3 = BasicConv2d(512, 256, kernel_size=(1,3), stride=1, padding=(0,1))
self.branch4_3x1 = BasicConv2d(512, 256, kernel_size=(3,1), stride=1, padding=(1,0))
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x3_1 = self.branch3_1x3(x3)
x3_2 = self.branch3_3x1(x3)
x4 = self.branch4(x)
x4_1 = self.branch4_1x3(x4)
x4_2 = self.branch4_3x1(x4)
x = torch.cat([x1, x2, x3_1, x3_2, x4_1, x4_2], dim=1)
return x
class InceptionC_ResNet_v2(nn.Module):
def __init__(self, in_channels):
super(InceptionC_ResNet_v2, self).__init__()
self.branch1 = BasicConv2d(in_channels, 192, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 192, kernel_size=1, stride=1, padding=0),
BasicConv2d(192, 224, kernel_size=(1,3), stride=1, padding=(0,1)),
BasicConv2d(224, 256, kernel_size=(3,1), stride=1, padding=(1,0))
# BasicConv2d(192, 192, kernel_size=(1,3), stride=1, padding=(0,1)),
# BasicConv2d(192, 256, kernel_size=(3,1), stride=1, padding=(1,0))
)
#여기서 448은 branch1~2의 아웃풋 출력 합산값이다.
self.conv1x1_linear = nn.Conv2d(448, in_channels, kernel_size=1, stride=1, padding=0)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat([x1, x2], dim=1)
out = self.conv1x1_linear(out)
out = out + residual
out = self.relu(out)
return out7) 모듈 통합 및 디버그
class Inception_v4(nn.Module):
def __init__(self, in_channels=3, num_classes=1000,
k=192, l=224, m=256, n=384):
super(Inception_v4, self).__init__()
blocks = []
blocks.append(Stem(in_channels))
for _ in range(4):
blocks.append(InceptionA_v4(384))
blocks.append(ReductionA(384, k, l, m, n))
for _ in range(7):
blocks.append(InceptionB_v4(1024))
blocks.append(ReductionB_v4(1024))
for _ in range(3):
blocks.append(InceptionC_v4(1536))
self.features = nn.Sequential(*blocks)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.dropout = nn.Dropout(0.8)
self.linear = nn.Linear(1536, num_classes)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = self.flatten(x)
x = self.dropout(x)
x = self.linear(x)
return xclass Inception_ResNet_V2(nn.Module):
def __init__(self, in_channels=3, num_classes=1000,
k=256, l=256, m=384, n=384,
A=5, B=10, C=5):
super(Inception_ResNet_V2, self).__init__()
blocks = []
blocks.append(Stem(in_channels))
for _ in range(A):
blocks.append(InceptionA_ResNet_v2(384))
blocks.append(ReductionA(384, k, l, m, n))
for _ in range(B):
blocks.append(InceptionB_ResNet_v2(1152))
blocks.append(ReductionB_ResNet_v2(1152))
for _ in range(C):
blocks.append(InceptionC_ResNet_v2(2144))
self.features = nn.Sequential(*blocks)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.flatten = nn.Flatten()
self.dropout = nn.Dropout(0.8)
self.linear = nn.Linear(2144, num_classes)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = self.flatten(x)
x = self.dropout(x)
x = self.linear(x)
return x여기까지 수행했다면
2개의 모델Inception-v4, Inception-Resnet-v2 의 설계가 완료되었다.
각각 모델이 잘 설계되었는지 확인해보자
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
debug_model = Inception_v4()
summary(debug_model, input_size=(3, 299, 299), device='cpu')
debug_model2 = Inception_ResNet_V2()
summary(debug_model2, input_size=(3, 299, 299), device='cpu')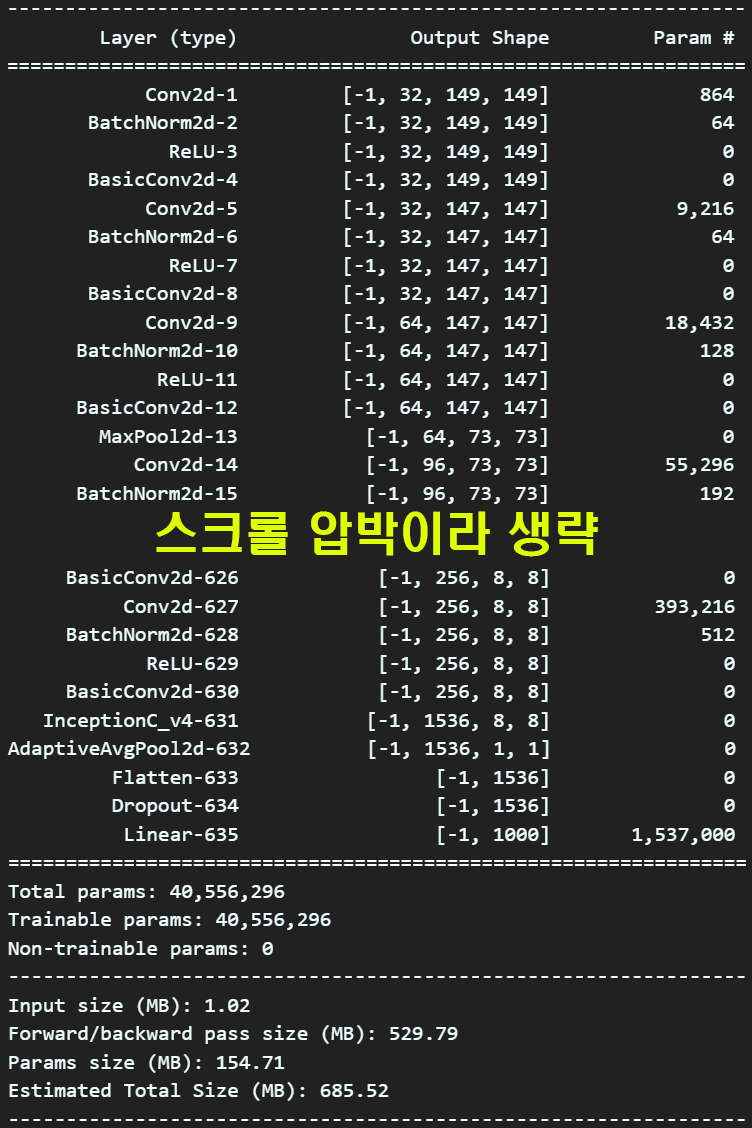
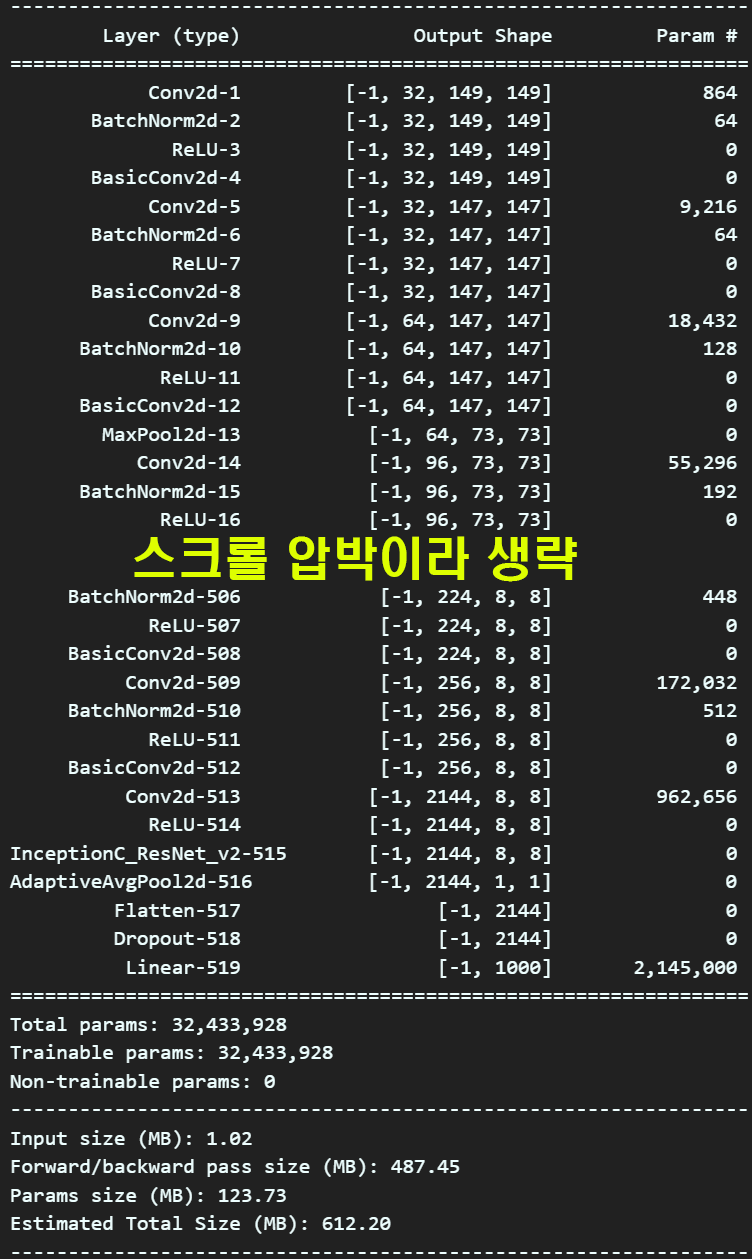
정보를 요약하자면 Inception-Resnet-v2이 Inception-v4보다 좀 더 가벼운 모델에 속한다.
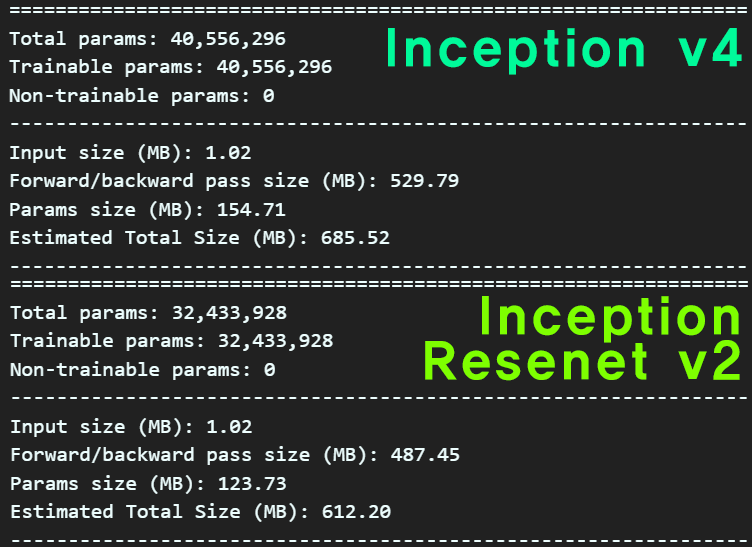
하지만 논문에 기재된 성능결과표를 본다면
 미세하긴 하지만
미세하긴 하지만 Inception-Resnet-v2이 더 좋은 성능을 댄다.
이를 통해서 알 수 있는것은 Inception-Resnet-v2이 최적화가 더 잘 되어있다?
이렇게 볼 수 있을 듯 하다.
바로 뒤 이어 다음포스트에서는
Inception-Resnet-v2을 학습/검증 후
추론 API를 생성하는 실습을 수행하는 과정에 대해
포스팅하겠다.

진짜 Inception-v4논문은... 너어는 진짜....
