
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 데이터셋
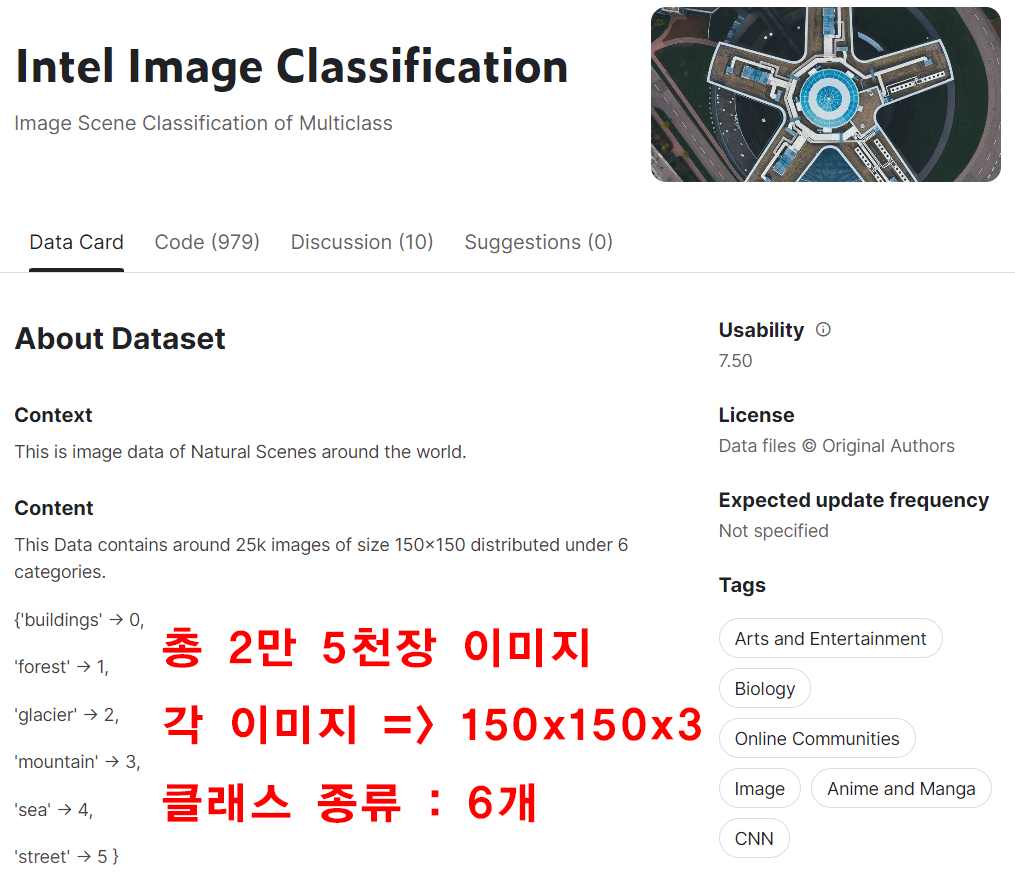 이미지 데이터셋은 https://www.kaggle.com/datasets/puneet6060/intel-image-classification/data
이미지 데이터셋은 https://www.kaggle.com/datasets/puneet6060/intel-image-classification/data
에 업로드 되어 있는 Intel Image Classification을 사용했다.
해당 데이터셋은 총 2만5천장의 이미지이고
개당 이미지의 크기는 [150x150x3]이고
클래스 종류는 buildings, forest, glacier,
mountaion, sea, street이나 일부 깨진 이미지 파일 등이 포함되어 있다.
아무튼 해당 파일을 다운받고 폴더 구조를 살펴보면 아래와 같다.
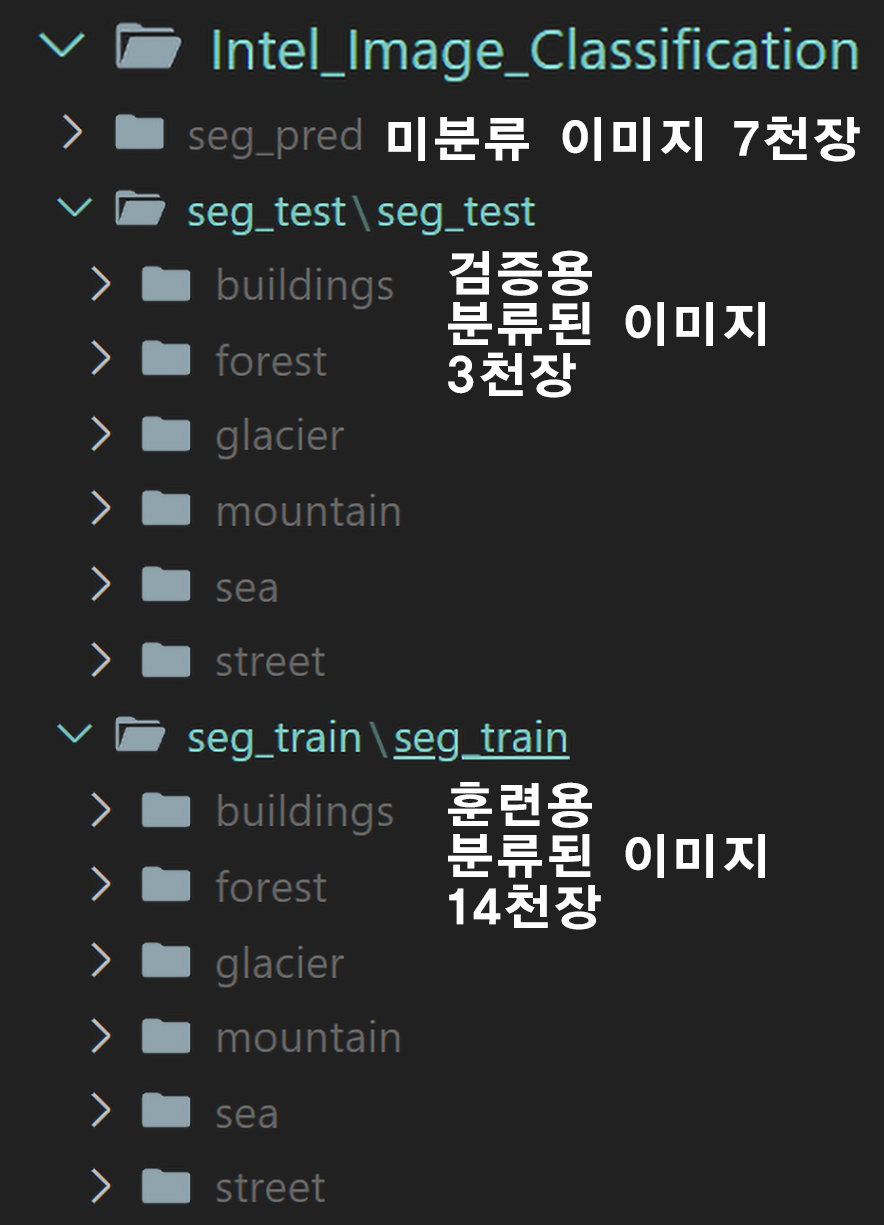 폴더는 3개에 각각 클래명으로 맞춘 서브폴더가 있으며,
폴더는 3개에 각각 클래명으로 맞춘 서브폴더가 있으며,
이중 seg_pred는 분류되지 않은 이미지 7천장이 포함된 구조로 되어있다.
2만 5천장이라고 했는데 1천장 빠지고.. 그중 7천장은 못쓰는 데이터라.. 흠...
뭐 데이터셋을 이걸 쓰기로 했으니
커스텀 데이터셋을 만들어서 관리하도록 하자
1.1 Customdatsset 클래스 설계하기

from torch.utils.data import Dataset
from PIL import Image
import osINTEL_IMG_CLASSES = [
'buildings', 'forest', 'glacier', 'mountain', 'sea', 'street'
]
len(INTEL_IMG_CLASSES)class CustomDataset(Dataset):
def __init__(self, root, train=True, transform=None):
self.root = root #intel_img_classification의 메인 경로
self.train = train #훈련모드/test모드 설정
self.transform = transform
#해당 모드 내 이미지 리스트를 저장할 변수
self.img_list = self._img_mode()
def _img_mode(self):
if self.train:
path = "seg_train/seg_train"
else :
path = "seg_test/seg_test"
img_path = os.path.join(self.root, path)
img_listes = []
for subdir in INTEL_IMG_CLASSES:
subdir_path = os.path.join(img_path, subdir)
if os.path.exists(subdir_path):
image_files = [f for f in os.listdir(subdir_path) if os.path.isfile(os.path.join(subdir_path, f))]
img_listes.extend([os.path.join(subdir_path, f) for f in image_files])
else:
print(f"경로 검색 실패 : {subdir_path}")
return img_listes
def __str__(self):
# img_mode메서드 함수가 동작 후에도 해당 리스트가 비어 있으면 실패로 간주
if not self.img_list:
return "오류가 났으니 확인하시오"
else:
return f"찾은 이미지 개수 : {len(self.img_list)}"
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
img_path = self.img_list[idx]
image = Image.open(img_path).convert('RGB')
# 라벨 정보 추출
for label, class_name in enumerate(INTEL_IMG_CLASSES):
if class_name in img_path:
break
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.int64)
return image, label커스텀 클래스 데이터셋 설계와 관련된 항목은 이전 포스트
인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (3) 데이터셋 : Pascal VOC 2007를 참조해주기 바란다.
요약을 하자면 train=True/False에 따라
seg_train, seg_test폴더를 참조하여 해당 폴더 내 이미지 데이터를 추출하고
폴더 내 서브폴더의 폴더명을 활용하여
각 이미지에 라벨링을 을 부여했다
라고 보면 된다.
# Custom Dataset 생성
train_dataset = CustomDataset(root = '[폴더경로]',
train = True)
test_dataset = CustomDataset(root = '[폴더경로]',
train = False)찾은 이미지 개수 : 14034 찾은 이미지 개수 : 30001.1.1 커스텀 데이터셋 Normalization
이미지 데이터셋을 정규화하기 위해서면 해당 이미지 데이터셋의 평균(mean), 표준편차(std)를 구해내야한다.
이는 모든 반복연산작업에 속하기에 아래의 그림처럼
GPU를 사용하고자 한다.
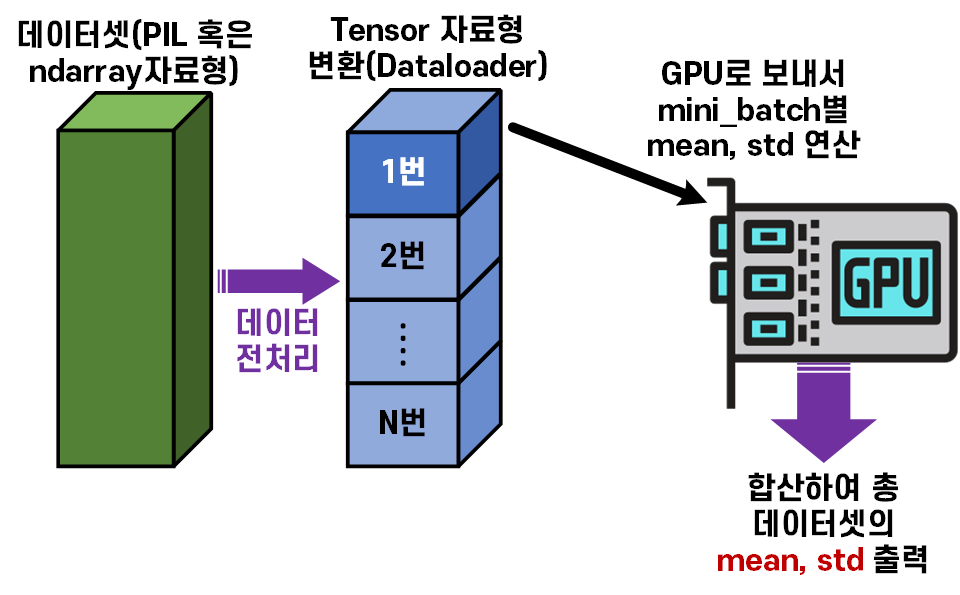
Dataset Dataloader 생성 과정을 응용하면 GPU연산 기능을 통해
손쉽게 전체 데이터셋에 대한 mean, std를 구해낼 수 있다
#훈련 데이터셋의 mean, std를 구하는 코드
from torch.utils.data import DataLoader
from torchvision.transforms import v2
from tqdm import tqdm # Progress bar for loops
transforamtion = v2.Compose([
v2.Resize((150,150)), #대부분 이미지가 150이지만 다른게 있음..
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True)
#텐서 자료형변환 + [0~1]사이로 졍규화 해줘야함
])
ex_train.transform = transforamtion
dataloader = DataLoader(train_dataset, batch_size=256, shuffle=False)
# GPU 사용 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 이미지의 총 개수 및 각 채널별 합계를 저장할 변수 초기화
mean = torch.zeros(3).to(device)
std = torch.zeros(3).to(device)
nb_samples = 0
# 데이터셋을 순회하며 mean과 std를 계산
for images, _ in tqdm(dataloader):
images = images.to(device)
batch_samples = images.size(0) # 배치 내 이미지 수
# (batch_size, num_channels, H * W)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0) # 각 채널별 평균
std += images.std(2).sum(0) # 각 채널별 표준편차
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
# mean과 std를 numpy 배열로 변환하여 소수점 4자리로 출력
mean_np = mean.cpu().numpy()
std_np = std.cpu().numpy()
print(f"Mean: {mean_np[0]:.4f}, {mean_np[1]:.4f}, {mean_np[2]:.4f}")
print(f"Std: {std_np[0]:.4f}, {std_np[1]:.4f}, {std_np[2]:.4f}")100%|██████████| 55/55 [00:11<00:00, 4.59it/s]
Mean: 0.4302, 0.4575, 0.4538
Std: 0.2355, 0.2345, 0.2429해당 과정은 CPU상에서 mean, std를 구하는 것보다 훨씬 더 빠르게 연산이 가능할 것이다.
GPU를 적극 활용하도록 하자
#계산 완료 후 GPU 캐시 데이터 클리어
torch.cuda.empty_cache()연산이 완료된 후에는 위 코드를 구동하여 GPU의 VRAM에 상주하고 있는 잔여 데이터를 제거하자.
GPU로 전송된 데이터는 CPU메모리와 다르게
Garge collection기능이 없기에
명시적으로 연산기능을 활용하고 나면 VRAM의 잔여 데이이터를 소각해야 한다.
1.2 데이터로더 생성
from torchvision.transforms import v2
intel_val = [[0.4302, 0.4575, 0.4538], [0.2355, 0.2345, 0.2429]]
#전처리 방법론 설계 -> 데이터 증강기법 다 적용한다.
train_transformation = v2.Compose([
#훈련데이터용 데이터 증강기법
#이미지를 랜덤크기로 자른 후 리사이징
v2.RandomResizedCrop((299,299)),
#이미지를 임의비율로 자른 후 리사이징
v2.ScaleJitter((299, 299), scale_range=(0.8, 1.2)),
#이미지의 색상 변조
v2.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4,
hue=0.1),
#이미지 좌우반전
v2.RandomHorizontalFlip(p=0.5),
#이미지 각도 조정
v2.RandomRotation(degrees=15),
v2.Resize((299, 299)), #이미지 크기를 229x229로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=intel_val[0], std=intel_val[1]) #데이터셋 표준화
])
test_transformation = v2.Compose([
v2.Resize((299, 299)), #이미지 크기를 229x229로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=intel_val[0], std=intel_val[1]) #데이터셋 표준화
])
#전처리 방법론 적용
train_dataset.transform = train_transformation
test_dataset.transform = test_transformation데이터 전처리 방법론에는
Data Argumentation(데이터증강)을 좀 빡세게 적용했다
아무래도 훈련 데이터셋의 크기가 14k이다 보니 데이터를 강제적으로 많이 만들 필요성이 있었다.
from torch.utils.data import DataLoader
BATCH_SIZE = 96
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)데이터로더의 배치사이즈는 실험결과
필자의 Local PC에서는 96으로 설정하여 구동하니
딱 19.0GB를 소모했다.
학습기를 돌리면서 유투브도 봐야하니
적절하게 타협햇다...
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
class_name = INTEL_IMG_CLASSES
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"첫 번째 이미지의 라벨: {labels[0].item()}, ", end='')
print(class_name[labels[0].item()])
print(f'라벨의 데이터타입 : {labels.dtype}')
else:
print(f"첫 번째 이미지의 파일명: {labels[0]}")
print(f'파일명의 데이터타입 : {type(labels)}')
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break
# train_loader 정보 출력
print_dataloader_info(train_loader, "Train Loader")
# test_loader 정보 출력
print_dataloader_info(test_loader, "Test Loader")Train Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 299, 299])
첫 번째 이미지의 라벨: 5, street
라벨의 데이터타입 : torch.int64
Test Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 299, 299])
첫 번째 이미지의 라벨: 0, buildings
라벨의 데이터타입 : torch.int64
데이터로더의 설계가 완료된 후에는 항상 예의바르게
잘 만들어졌는지 확인하도록 하자
2. 하이퍼 파라미터 설정
이전 포스트 인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (1) Inception-v3,v4 모델설명
에서 사용한 'Backbone'네트워크가 Inception-Resnet-v2이니
해당 네트워크에 대한 논문 하이퍼 파라미터와
실제 적용 하이퍼 파라미터 두가지를 기재하겠다
2.1 논문 하이퍼 파라미터
learning_rate = 0.045
weight_decay = 4e-5
momentum = 0.9
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=momentum, alpha=0.9)
scheduler = StepLR(optimizer, step_size=2, gamma=0.94)
criterion = nn.CrossEntropyLoss()2.2 실습 하이퍼 파라미터
실습 하이퍼 파라미터 적용 전
딥러닝 모델은 GPU로 올려놔야 한다.
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Inception_ResNet_V2(in_channels=3, num_classes=len(INTEL_IMG_CLASSES))
model.to(device)
summary(model, input_size=(3, 229, 229), device=device.type)import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
#스케쥴러는 이름이 기니까 아에 이런식으로 코드를 작성하네
#LossFn, Optimizer, scheduler 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = CosineAnnealingLR(optimizer, T_max=150, eta_min=1e-7)3. 훈련/검증/실행
모델 설계
입력 데이터 처리
위 두 과정을 수행했으니
이제 결과물 산출의 시간이다.
from tqdm import tqdm #훈련 진행상황 체크
#tqdm 시각화 도구 출력 사이즈 조절 변수
epoch_step = 10def model_train(model, data_loader,
loss_fn, optimizer_fn, scheduler_fn,
processing_device, epoch):
model.train() # 모델을 훈련 모드로 설정
global epoch_step
# loss와 accuracy를 계산하기 위한 임시 변수를 생성
run_size, run_loss, correct = 0, 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar:
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 전사 과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
# 스케줄러 업데이트
scheduler_fn.step()
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
#tqdm bar에 추가 정보 기입
if (epoch + 1) % epoch_step == 0 or epoch == 0:
desc = (f"[훈련중]로스: {run_loss / run_size:.4f}, "
f"정확도: {correct / run_size:.4f}")
progress_bar.set_description(desc)
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracydef model_evaluate(model, data_loader, loss_fn,
processing_device, epoch):
model.eval() # 모델을 평가 모드로 전환 -> dropout 기능이 꺼진다
# batchnormalizetion 기능이 꺼진다.
global epoch_step
# gradient 업데이트를 방지해주자
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar: # 이때 사용되는 데이터는 평가용 데이터
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 평가 결과를 도출하자
output = model(image)
pred = output.argmax(dim=1) #예측값의 idx출력
# 모델의 평가 결과 도출 부분
# 배치의 실제 크기에 맞추어 정확도와 손실을 계산
correct += torch.sum(pred.eq(label)).item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_accuracy = []
num_epoch = 100
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = model_train(model, train_loader,
criterion, optimizer, scheduler,
device, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = model_evaluate(model, test_loader,
criterion, device, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d} ", end=' ')
print(f"훈련 로스: {train_loss:.4f}", end=' ')
print(f"훈련 정확도: {train_acc:.4f}")
print(f"검증 로스: {test_loss:.4f}", end=' ')
print(f"검증 정확도: {train_acc:.4f}")[훈련중]로스: 1.9291, 정확도: 0.3663: 100%|██████████| 147/147 [03:44<00:00, 1.52s/it]
100%|██████████| 32/32 [00:09<00:00, 3.34it/s]
epoch 001 훈련 로스: 1.9291 훈련 정확도: 0.3663
검증 로스: 1.2336 검증 정확도: 0.3663
[훈련중]로스: 0.6960, 정확도: 0.7464: 100%|██████████| 147/147 [03:37<00:00, 1.48s/it]
100%|██████████| 32/32 [00:09<00:00, 3.53it/s]
epoch 010 훈련 로스: 0.6960 훈련 정확도: 0.7464
검증 로스: 0.5965 검증 정확도: 0.7464
[훈련중]로스: 0.5308, 정확도: 0.8054: 100%|██████████| 147/147 [03:29<00:00, 1.43s/it]
100%|██████████| 32/32 [00:08<00:00, 3.66it/s]
epoch 020 훈련 로스: 0.5308 훈련 정확도: 0.8054
검증 로스: 0.4444 검증 정확도: 0.8054
[훈련중]로스: 0.4807, 정확도: 0.8246: 100%|██████████| 147/147 [03:28<00:00, 1.42s/it]
100%|██████████| 32/32 [00:08<00:00, 3.70it/s]
epoch 030 훈련 로스: 0.4807 훈련 정확도: 0.8246
검증 로스: 0.2925 검증 정확도: 0.8246
[훈련중]로스: 0.4446, 정확도: 0.8351: 100%|██████████| 147/147 [03:30<00:00, 1.43s/it]
100%|██████████| 32/32 [00:08<00:00, 3.68it/s]
epoch 040 훈련 로스: 0.4446 훈련 정확도: 0.8351
검증 로스: 0.2679 검증 정확도: 0.8351
[훈련중]로스: 0.4408, 정확도: 0.8400: 100%|██████████| 147/147 [03:29<00:00, 1.43s/it]
100%|██████████| 32/32 [00:08<00:00, 3.66it/s]
epoch 050 훈련 로스: 0.4408 훈련 정확도: 0.8400
검증 로스: 0.2537 검증 정확도: 0.8400
[훈련중]로스: 0.4372, 정확도: 0.8409: 100%|██████████| 147/147 [03:29<00:00, 1.43s/it]
100%|██████████| 32/32 [00:08<00:00, 3.67it/s]
epoch 060 훈련 로스: 0.4372 훈련 정확도: 0.8409
검증 로스: 0.2577 검증 정확도: 0.8409
[훈련중]로스: 0.3916, 정확도: 0.8571: 100%|██████████| 147/147 [03:29<00:00, 1.42s/it]
100%|██████████| 32/32 [00:08<00:00, 3.68it/s]
epoch 070 훈련 로스: 0.3916 훈련 정확도: 0.8571
검증 로스: 0.2468 검증 정확도: 0.8571
[훈련중]로스: 0.3658, 정확도: 0.8682: 100%|██████████| 147/147 [03:30<00:00, 1.43s/it]
100%|██████████| 32/32 [00:08<00:00, 3.65it/s]
epoch 080 훈련 로스: 0.3658 훈련 정확도: 0.8682
검증 로스: 0.2751 검증 정확도: 0.8682
[훈련중]로스: 0.3447, 정확도: 0.8719: 100%|██████████| 147/147 [03:28<00:00, 1.42s/it]
100%|██████████| 32/32 [00:08<00:00, 3.66it/s]
epoch 090 훈련 로스: 0.3447 훈련 정확도: 0.8719
검증 로스: 0.2579 검증 정확도: 0.8719
[훈련중]로스: 0.3128, 정확도: 0.8872: 100%|██████████| 147/147 [03:46<00:00, 1.54s/it]
100%|██████████| 32/32 [00:09<00:00, 3.36it/s]epoch 100 훈련 로스: 0.3128 훈련 정확도: 0.8872
검증 로스: 0.2968 검증 정확도: 0.8872훈련/검증/실행까지 완료했으니
마지막은 예의있게 Loss, Train Accuracy 그래프도 그려주자
import matplotlib.pyplot as plt
# 손실 그래프
train_losses, val_losses = zip(*his_loss)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='train')
plt.plot(val_losses, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# 정확도 그래프
train_accuracies, val_accuracies = zip(*his_accuracy)
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='train')
plt.plot(val_accuracies, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Train-Val Accuracy')
plt.tight_layout()
plt.show()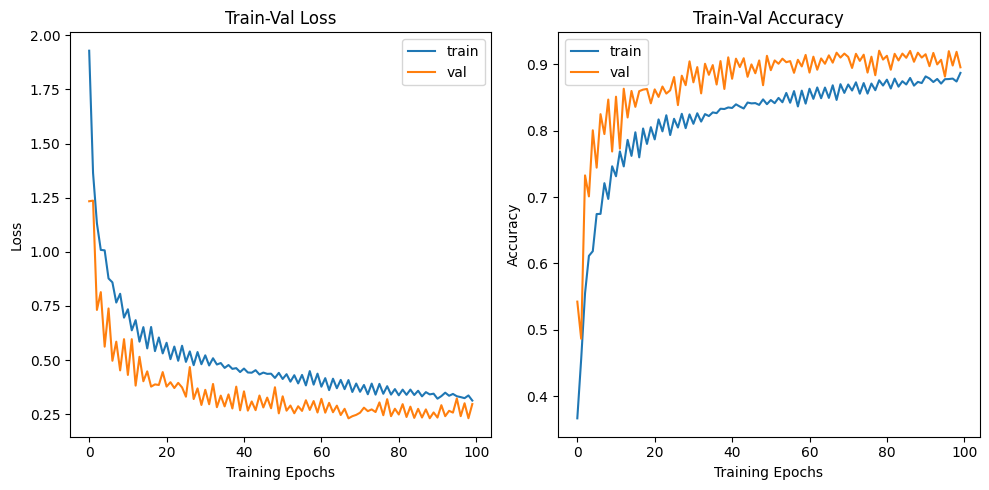 데이터 증강기법이 빡세게 적용되었기에
데이터 증강기법이 빡세게 적용되었기에
그에 따른 epoch별 성능 진동은 더 많이 발생하지만
이것을 상쇄시킬 정도로 epoch를 늘려놔서 작업을 수행했기에
최종 성능은 90%정도 적절하게 학습된 것을 확인할 수 있다.
이제 여기서 끝내지 말고
API를 설계해 보도록 하자
중요 작업
#학습 완료된 모델 저장하기
MODEL_NAME='Inception_resenet_v2'
torch.save(model.state_dict(), f'{MODEL_NAME}.pth')API설계 전 꼭 학습이 완료된 모델을 저장하자
바로 다음포스트에서 API설계를 진행하겠다.
