
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 딥드림(DeepDream) 개요
https://www.tensorflow.org/tutorials/generative/deepdream?hl=ko
https://research.google/blog/inceptionism-going-deeper-into-neural-networks/

DeepDream은 위 사진처럼 인공신경망(CNN모델)에 이미지를 입력했을 때 그 결과물이 오른쪽의 그림처럼 마치 사람이 꿈꾸는 이미지처럼 출력하게 만드는 과정을 의미한다.
이것은 인공신경망이 학습한 패턴에 대해 과잉해석을 진행하고, 그 결과물을 입력한 이미지에 붙이면서 이미지를 변조하는 과정을 말한다.
이 작업을 좀 심화시키면
 위 gif처럼 CNN모델이 이미지를 과잉해석하여 변조하는 과정을 영상으로 만들 수도 있다.
위 gif처럼 CNN모델이 이미지를 과잉해석하여 변조하는 과정을 영상으로 만들 수도 있다.
물론 필자는 저것까지는 수행할 생각은 없고...
아무튼 요즘은 생성형 AI도 많이 발전했고
AI가 이미지 해석을 어떻게 하는지?
AI모델 자체도 많이 발전해서 모델 구조 해석 자체도 어려워 졌기에
DeepDream은 잠깐 흥미를 끌고 요즘은 사장된 기술이긴 하다.
(돈이 안되서...)
이 한철 지난DeepDream에 대해 포스팅을 하는 이유는
인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (3) Intel Image Classification 추론하기
인공지능 고급(시각) 강의 복습 - 11. CNN 모델 중간 출력물 알아보기
위 두개의 포스팅에서 진행한
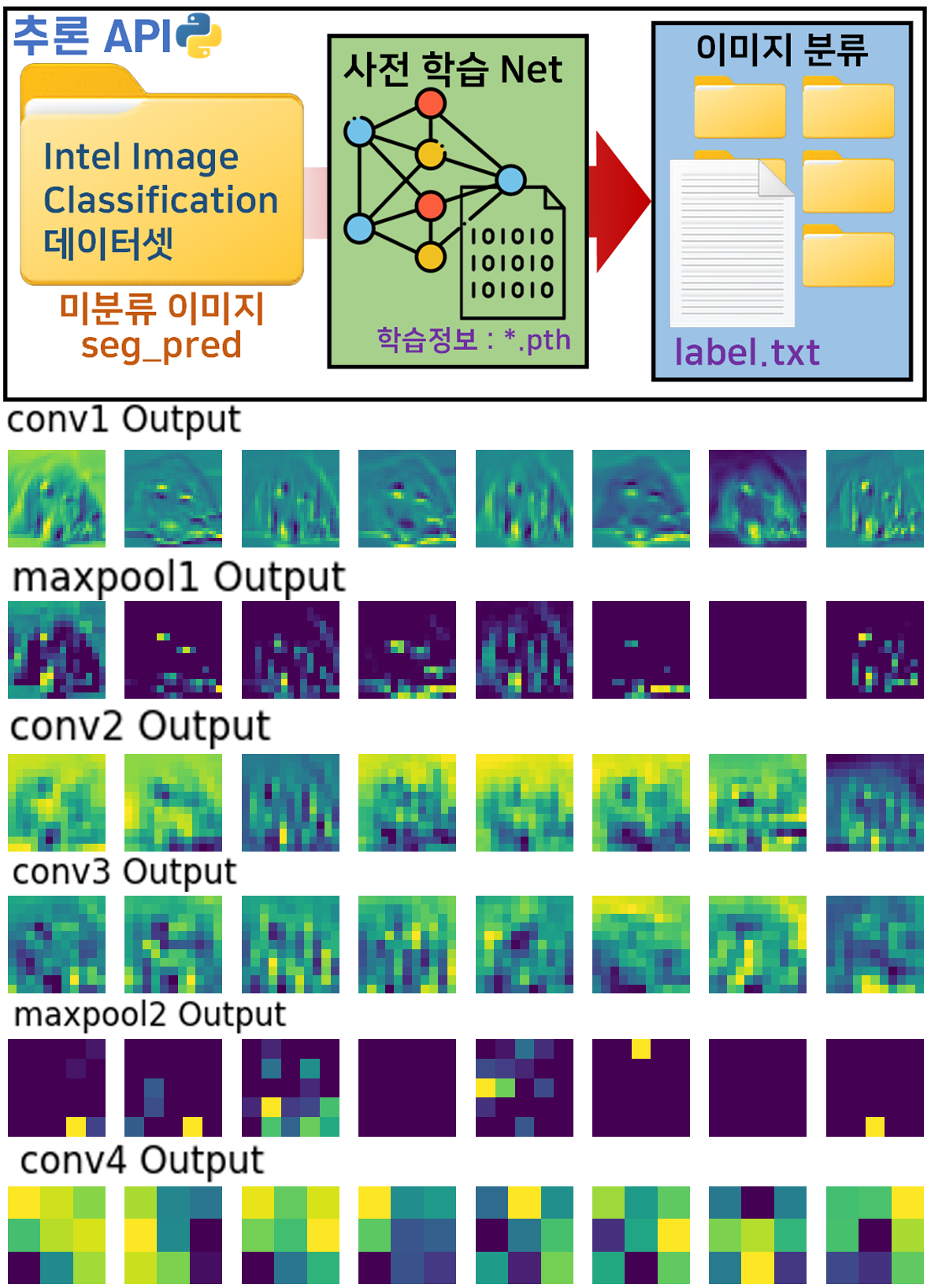
이미지 추론 + 모델의 중간 출력
과정에 대한 심화가 DeepDream이어서 이다.
즉, DeepDream을 잘 익혀두면
인공신경망(AI)가 어떤식으로 동작하는지?
또 이걸 코드로 어떻게 핸들링 하는지?
에 대한 좋은 교보재가 된다 라고 보면 된다.
1.2 딥드림 Work Flow
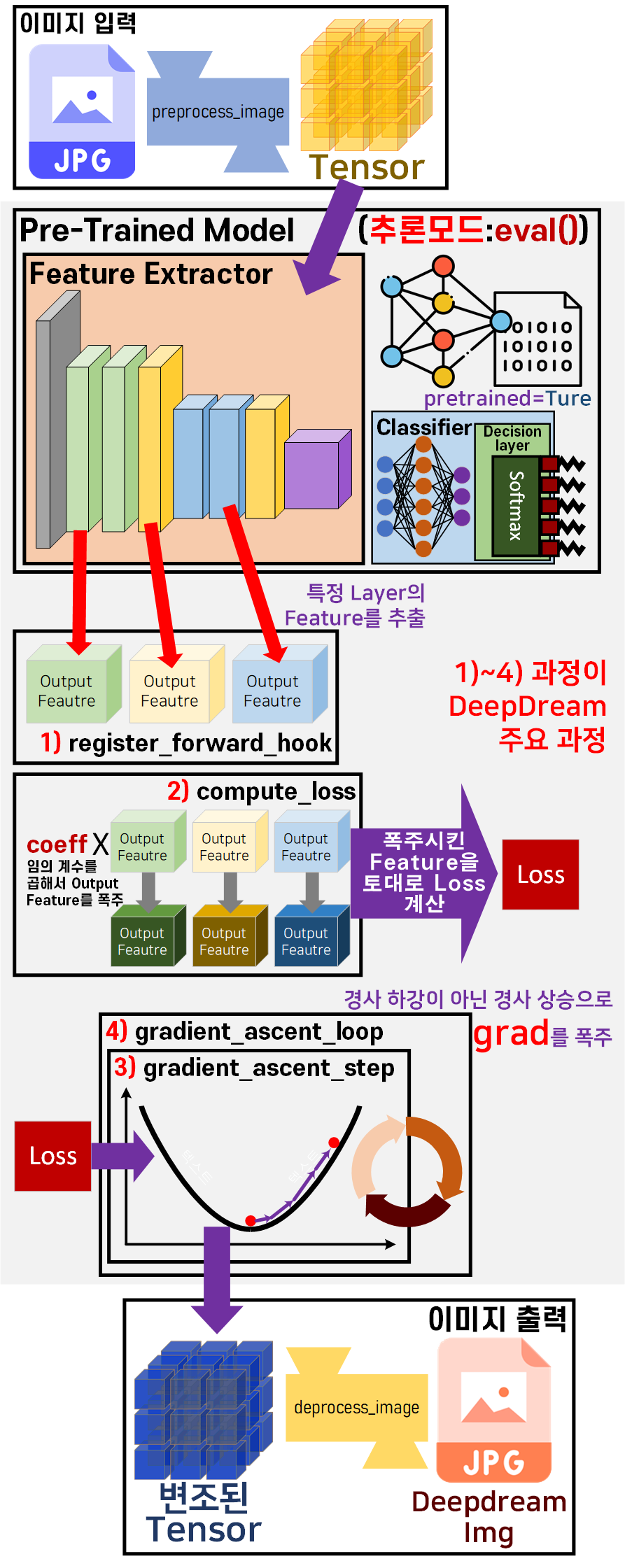
음... 이건 진짜
 내가 도식화 했지만 진자 잘만든거 같다
내가 도식화 했지만 진자 잘만든거 같다
아무튼 위 사진이 DeepDream의 기본 WorkFlow이다.
0) 입력 이미지를 Tensor 자료형으로 변환
1) Pre-trained Model의 특정 레이어에서 Feature out 추출
2) 추출한 Feature out에 특정 계수(coeff)를 곱한 뒤 이를 근거로 Loss_fn 정의 출력되는 Loss는 변조된 폭주한 Loss이다.
3) 폭주한 Loss를 바탕으로 Gradient Descent(경사하강법) 이 아닌
Gradient Ascent(경사상승법) 을 적용하여
최적화된 방향에서 멀어짐
이 멀어지는 과정으로 모델에 입력된 Tensor이 변조됨
4) Gradient Ascent를 반복수행하여 입력된 Tensor를 변조 시킴
5) 변조된 Tensor을 이미지 자료형으로 원복
위 1~4)과정이 DeepDream 과정이라 보면 된다.
이때 backbone이 되는 Pre-trained Model이 이곳저곳을 찾아보니까
Inception v3이 가장 많이 쓰이고, VGG, AlexNet등의 CNN 아키텍쳐 중 초기 모델이 주로 많이 쓰인다.
이에 필자는 Inception v3와 이전 포스트
인공지능 고급(시각) 강의 복습 - 23. 주요 CNN알고리즘 구현 : (1) DenseNet 에 사용한 DenseNet 121을 활용하여
DeepDream을 실습하고자 한다.
2. DeepDream 코드 구현
0) preprocess_img, 5) deprocess_img

메인 프레임인 DeepDream의 전 후 과정에 속하는
Image Tensor : preprocess_img
Tensor Image : deprocess_img
함수에 대한 설계이다.
import torch
import torch.nn as nn
from PIL import Image
import numpy as np
from torchvision.transforms import v2# 데이터셋 표준화를 위한 기본정보
imgNet_val = {'mean' : [0.485, 0.456, 0.406], 'std' : [0.229, 0.224, 0.225]}
def preprocess_img(img_path, device):
img = Image.open(img_path).convert('RGB')
width, height = img.size
img_shape = [height, width] #원본 이미지의 크기정보를 따로 저장
transformation = v2.Compose([
v2.Resize((224, 224)), #VGG19 -> [224, 224]
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=imgNet_val['mean'], std=imgNet_val['std']) #데이터셋 표준화
])
img_tensor = transformation(img).unsqueeze(0).to(device)
return img_tensor, img_shape
# 텐서 자료형의 이미지를 원복하는 함수
def deprocess_img(img_tensor, img_shape):
#텐서 자료형을 원본 이미지 크기로 리사이징
img_tensor = v2.functional.resize(img_tensor, img_shape)
#np 자료형으로 변환
img_np = img_tensor.cpu().numpy().squeeze().transpose(1, 2, 0)
# 이미지에 표준화 되어 있던걸 원복
img_np = img_np * np.array(imgNet_val['std']) + np.array(imgNet_val['mean'])
img_np = np.clip(img_np, 0, 1)
img = (img_np * 255).astype(np.uint8)
return img이 자료형의 변환을 수행하는 함수는
모두 Backbone model이 Pre-trained Model이며, 해당 모델들은 학습하는데 사용된 데이터셋이 ImageNet이다.
이 ImageNet의 평균 및 분산값을 사용하여 데이터를 표준화 한다.
deprocess_img 함수에서는
v2.functional.resize메서드를 활용하여
텐서 이미지의 크기변환을 수행하며 이때 shape(H, W)를 받아
해당 크기로 리사이징을 진행한다.
두 함수의 사용방법은 아래와 같다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_path = '[이미지 파일 경로]' #불러올 이미지의 경로
#이미지를 Tensor 자료형으로 변환
img_tensor, shape = preprocess_img(img_path, device)
# Tensor 이미지를 원래 상태로 변환
restore_img = deprocess_img(img_tensor, shape)사전학습 모델 및 block 계수(cofficient) 설정
from torchvision.models import inception_v3, Inception_V3_Weights
backbone = inception_v3(weights=Inception_V3_Weights.IMAGENET1K_V1).to(device)
backbone.eval() #모델을 평가모드로 전환
# 특정 모듈에 곱할 coefficieint를 {모듈 이름} : {coeff} 딕셔너리 형태로 저장
block_setting = {
"Mixed_5d": 1.0,
"Mixed_6a": 1.5,
"Mixed_6e": 2.0,
"Mixed_7a": 2.5,
}위 block_setting은 특정 모듈(레이어)에 계수(coefficient)를 곱해서
이를 DeepDream의 Loss을 폭주시키는 용도로 사용되는 딕셔너리이며,
이때, 계수를 조정해서 모듈별 폭주의 정도를 차등적용한다.
이 block_setting를 설정하려면 우선 Pre-trained Model인 inception_v3 모델의 레이어 구성에 대해 알아야 한다.
for name, module in backbone.named_modules():
print(f"모듈의 이름: {name}")
print(f"모듈의 구성: {module}")위 코드를 수행하면
 모듈과 해당 모듈 내 레이어의 구성 정보를 확인할 수 있다.
모듈과 해당 모듈 내 레이어의 구성 정보를 확인할 수 있다.
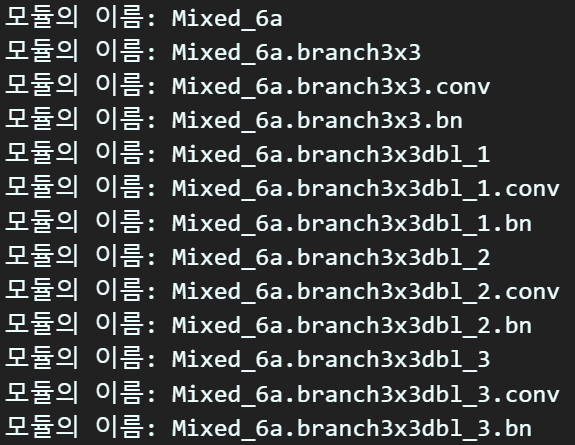 이때 name 정보만 자세하게 추출해보면
이때 name 정보만 자세하게 추출해보면
inception_v3는 [mixed5b~mixed7c]이렇게 다양한 모듈 블럭이 있음을 확인할 수 있다.
그 중 Mixed_5d, Mixed_6a, Mixed_6e, Mixed_7a 4개의 모듈을 선택하고
해당 모듈 내 모든 레이어의 출력에 특정 계수(coefficient)를 곱하는 식으로 Loss를 폭주시킨다 볼 수 있다.
1) 레이어의 특징 추출
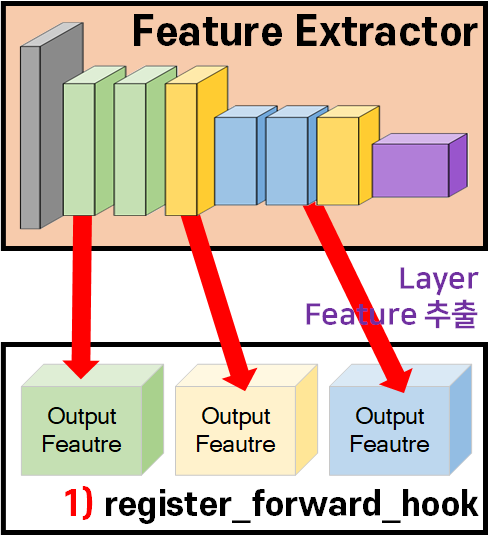
위 사진의 과정을 수행하는 것인데 이게 조금 어려운 부분이 있다.
먼저 코드를 첨부하고 설명하도록 하겠다.
class DeepDreamNet(nn.Module):
def __init__(self, backbone, block_setting, device):
super(DeepDreamNet, self).__init__()
self.backbone = backbone.to(device) # backbone인스턴스화 + 디바이스지정
self.block_setting = block_setting # 폭주시킬 블럭명 리스트 가져오기
self.device = device # 모델이 위치한 디바이스 정보 저장
self.outputs = {} #backbone의 캡쳐한 Feature out을 저장
def hook_fn(moduls, input, output, layer_name):
if layer_name not in self.outputs:
# for block in self.block_setting : 사전 설정한 블럭세팅 리스트에서 요소 추출
# if block in layer_name : 현재 '블럭 명'이 '레이어 이름'에 포함되었는지 확인
# 포함되어 있으면 -> block_name에 리스트의 첫번째 값을 반환해 문자열 전송
block_name = [block for block in self.block_setting if block in layer_name][0]
if block_name not in self.outputs:
self.outputs[block_name] = {} #1차 디렉토리 생성
# outputs를 2차 디렉토리화 -> value에 레이어의 feature_out을 저장
self.outputs[block_name][layer_name] = output
for name, module in self.backbone.named_modules():
# 아래 조건문은 name이 block리스트에 있는
# block 문자열을 포함하는지를 확인하는 코드
# 여기서 name = 특정 레이어의 이름
if any(block in name for block in self.block_setting):
# print(f"찾은 블록의 이름: {name}")
# print(f"해당 블록의 구성: {module}")
self._register_hook(module, name, hook_fn)
def _register_hook(self, module, layer_name, hook_fn):
def hook(module, input, output):
return hook_fn(module, input, output, layer_name)
module.register_forward_hook(hook)
def get_device(self): # DeepDreamNet의 디바이스 위치 확인하기
return self.device
def forward(self, x):
self.outputs = {} # 매번 호출될 때마다 초기화
_ = self.backbone(x)
return self.outputs생성자 메서드에 있는 hook_fn은 조건을 만족하는 block내 레이어의 출력 정보를 2차원 딕셔너리 형태로 저장하는 함수이고
두번째 for문은 조건에 맞는 모듈을 찾는 함수이다.
이 조건은 앞서 설정한 block_setting이다.
여기서 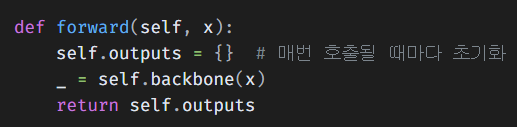
이 forward 함수에서
self.outputs = {}를 꼭 def __init__()에서 수행했다고
빼먹는 누 를 범하지 말자
안그러면 이미지를 새로 넣어도 출력이 고정되버리는 참사가 발생한다.
이 과정보다 중요한 것은 register_forward_hook 이다.
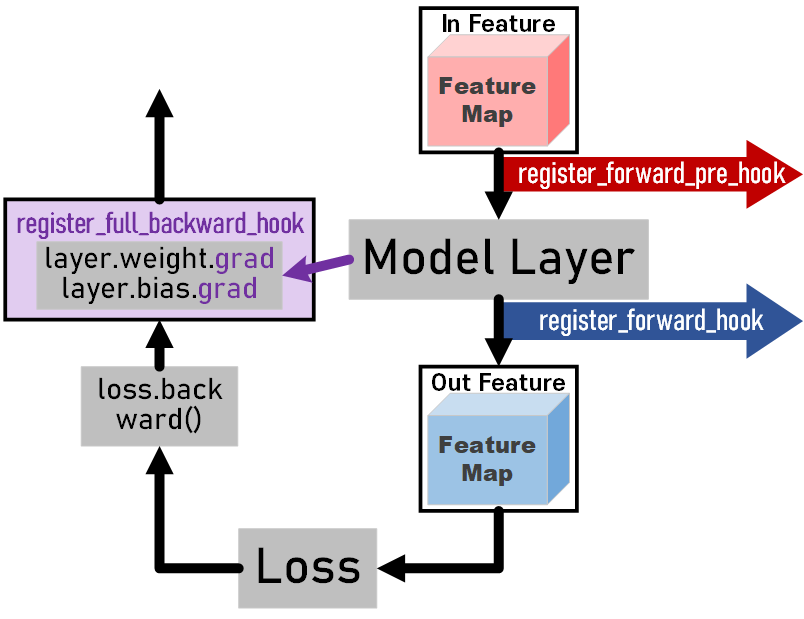
도식으로 설명을 한다면 모델에 임의의 레이어가 있을 때
1) 해당 레이어의 앞단에 입력되는 in_feature을 캡쳐하고 싶다
register_forward_pre_hook
2) 레이어의 출력 out_feature를 캡쳐하고 싶다.
register_forward_hook
3) 레이어가 backward(역전파) 수행으로 발생하는 레이어param의 gradient (layer.weight.grad, layer.bias.grad)를 캡쳐하고 싶다.
register_full_backward_hook
위 3가지 hook으로 모델이 연산하는 과정에서 발생하는 산출물들을 추출해 내는 것이라 보면 되며,
이 hook이란 개념은 지금처럼 특정 API가 있고, 이 API가 내부에 여러 단계에 해당하는 연산이 있을 때
그 단계별 연산 중간중간에 interrept 형태로 접근하여 특정 명령을 먼저 수행하게 하는 기능을 hook라고 볼 수 있다.
지금의 3가지 hook은 단순히 단계별 산출물을 따로 저장(capture) 하는 기능을 수행하는 메서드 라고 보면 된다.
(이 register_forward_pre_hook, register_forward_hook, register_full_backward_hook는 nn.Module 클래스에서 지원하는 메서드이다.)

설명이 잘 전달되었을지.. 모르겠지만 아무튼 위 클래스를 설계한 것은 아래의 코드로 실행을 해서 그 결과를 확인할 수 있다.
# 설계한 DeepDreamNet를 받아서 인스턴스화
dream_net = DeepDreamNet(backbone, block_setting.keys(), device)
# 인스턴스화 한 dream_net에 데이터를 입력하여 출력물을 생성
img_tensor, _ = preprocess_img(img_path=img_path, device=device.type)
outputs = dream_net(img_tensor)위 코드로 모델의 출력물을 생성해 낸뒤
for block_name, layers in outputs.items():
print(f"블럭이름: {block_name}, 블럭 내 캡쳐한 레이어 개수: {len(layers)}", end='\n\n')
for layer, output in layers.items():
layer_str = f" -레이어: {layer}".ljust(40) # 레이어 이름을 40자로 맞춤
print(f"{layer_str} 레이어 출력: {output.shape}")
print(end='\n\n')이 코드를 수행하면 block_setting에서 선언한
특정 모듈의 Feautr_out를 모두 확인할 수 있다.
블럭이름: Mixed_5d, 블럭 내 캡쳐한 레이어 개수: 21
-레이어: Mixed_5d.branch1x1.conv 레이어 출력: torch.Size([16, 64, 25, 25])
-레이어: Mixed_5d.branch1x1.bn 레이어 출력: torch.Size([16, 64, 25, 25])
...........
블럭이름: Mixed_6a, 블럭 내 캡쳐한 레이어 개수: 12
-레이어: Mixed_6a.branch3x3.conv 레이어 출력: torch.Size([16, 384, 12, 12])
-레이어: Mixed_6a.branch3x3.bn 레이어 출력: torch.Size([16, 384, 12, 12])
...........
블럭이름: Mixed_6e, 블럭 내 캡쳐한 레이어 개수: 30
-레이어: Mixed_6e.branch1x1.conv 레이어 출력: torch.Size([16, 192, 12, 12])
-레이어: Mixed_6e.branch1x1.bn 레이어 출력: torch.Size([16, 192, 12, 12])
...........
블럭이름: Mixed_7a, 블럭 내 캡쳐한 레이어 개수: 18
-레이어: Mixed_7a.branch3x3_1.conv 레이어 출력: torch.Size([16, 192, 12, 12])
-레이어: Mixed_7a.branch3x3_1.bn 레이어 출력: torch.Size([16, 192, 12, 12])
...........이런 식으로 각 모듈내 속해있는 Layer의 Feature_out를 캡쳐해서 저장한다.
2~4) Loss정의 및 경사상승법
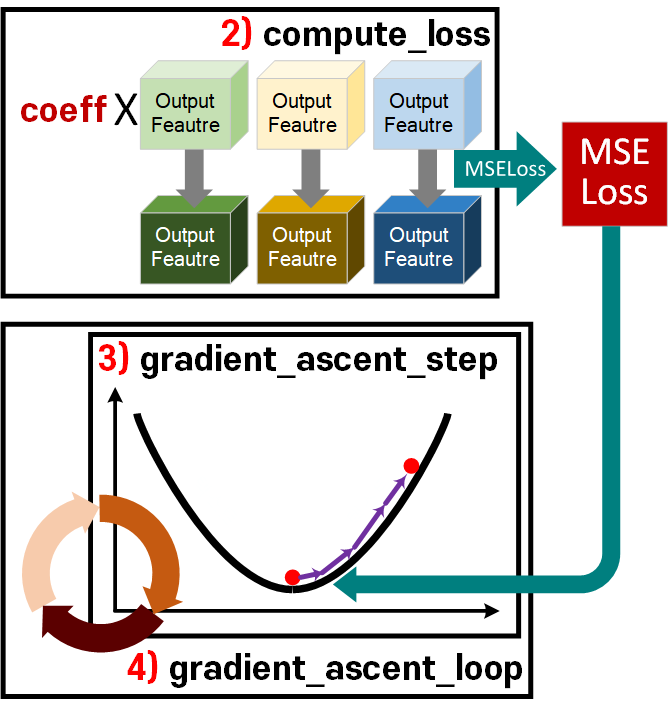
위 도식화의
2) Loss Fu 정의
3) 정의된 Loss Fn을 기반으로 gradient_ascent(경사상승법) 준비
4) 준비한 경사상승법을 반복수행
위 과정에 대한 코드는 한번에 class로 만들어서 관리하는게 훨씬 코드 작성에 유리하여 아래와 같이 작성한다.
import torch.nn.functional as F
class DeepDream():
def __init__(self, Net, block_setting,
learning_rate, iterations, max_loss=None):
self.net = Net
self.block_setting = block_setting
self.lr = learning_rate
self.iter = iterations
self.max_loss = max_loss
def compute_loss(self, outputs):
# outputs은 2차원 딕셔너리 -> value의 디바이스 위치 확인
first_value = next(iter(next(iter(outputs.values())).values()))
device = first_value.device
#loss변수의 선언은 1차원(스칼라), grad추적가능, 디바이스 정보 받음
loss = torch.zeros(1, requires_grad=True, device=device)
for block_name, layers in outputs.items():
# print(f"블럭이름: {block_name}, 블럭 내 캡쳐한 레이어 개수: {len(layers)}")
if block_name in self.block_setting:
coeff = self.block_setting[block_name]
#coeff를 곱할 레이어 out을 activation이라 재명기
for layer_name, activation in layers.items():
# cropped_activation = activation[:, :, 2:-2, 2:-2] # 가장자리를 제외한 활성화 값을 얻습니다.
layer_loss = coeff * F.mse_loss(activation, torch.zeros_like(activation))
#layer_loss = coeff * torch.mean(torch.square(activation)) 와 같은 연산
loss = loss + layer_loss # in-place 연산을 피하기 위해 + 연산을 사용합니다.
# 설계한 Loss Function은 Mean Square Error이다
return loss
def gradient_ascent_step(self, img_tensor):
img_tensor.requires_grad = True
# 최적화함수(optimizer)은 parm으로 img_tensor을 넣는다.
optimizer = torch.optim.SGD([img_tensor], lr=self.lr)
# 옵티마이저의 기울기를 0으로 초기화
optimizer.zero_grad()
outputs = self.net(img_tensor) #DeepDreamNet에 img_tensor입력
loss = self.compute_loss(outputs)
loss.backward() #설계한 loss를 바탕으로 역전파 수행
# 여기서 정상적인 경사하강법을 수행한다면 `optimizer.step()`
with torch.no_grad():
# 옵티마이저 파라미터가 [img_tensor] 단 하나니 [0]번째 리스트임
for param in optimizer.param_groups[0]['params']:
param.add_(self.lr * param.grad) #이게 경사 상승법의 코드임
grads_norm = param.grad.norm()
img_tensor = img_tensor.detach() # 그래디언트 추적 중단
return loss.item(), img_tensor, grads_norm
def gradient_ascent_loop(self, img_tensor):
for i in range(self.iter): #iter 반복 횟수만큼 경사상승 수행
loss, img_tensor, grads_norm = self.gradient_ascent_step(img_tensor)
if self.max_loss and loss > self.max_loss: #과도한 변형을 막기 위한 임계 설정
break
# 루프가 실행되는동안 중간값들 출력해보기
# print(f"Step {i}, loss: {loss:.4f}, grad: {grads_norm:.4f}")
return img_tensor먼저 첫번째로 수행하는 compute_loss함수는
1) 레이어의 특징 추출 파트에서 추출한 레이어의
Feature out에
block_setting에 각 모듈별로 설정한 폭주 계수(coeff)를 곱하여
Feature out를 폭주시킨 뒤 이에 대한 Loss를 계산한다.
이때
layer_loss = coeff * F.mse_loss(activation, torch.zeros_like(activation))
loss = loss + layer_loss경사 상승법으로 계속 Loss에 폭주시킨 Featur out를 재귀 가산하는 형식으로 Loss를 덧셈한다.
두번째 gradient_ascent_step 함수는
경사 상승법에 사용되는 최적화 함수 Optimizer의
대상 파라미터를 모델 레이어의 출력물이 아닌
이미지의 텐서 자료형인 img_tensor을 직접 받는 형식으로 최적화 함수를 설계한다.
이 img_tensor이 최적화 함수의 params가 되면서
아래 그림의 경사 상승법의 가산연산이 수행되는 것이다.
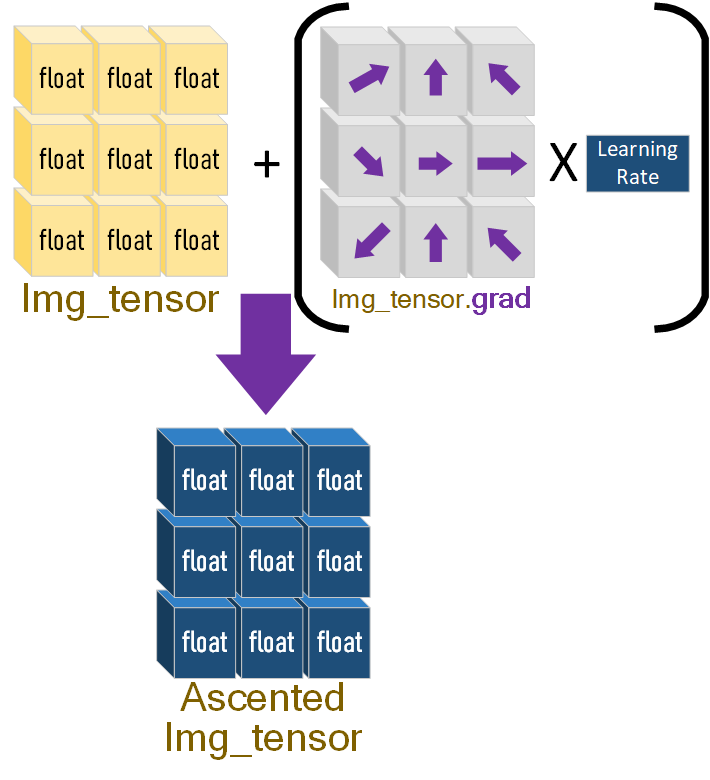
이 gradient_ascent_step를 작성하면서 느낀거지만 DeepDream기법을 개발한
 Alexander Mordvintsev는 인공신경망의 동작과정을 심도있게 탐구한 인물이라 생각한다.
Alexander Mordvintsev는 인공신경망의 동작과정을 심도있게 탐구한 인물이라 생각한다.

아무튼 위 Gradient Ascent에 Learning Rate를 곱하는 하나의 step을 완성했으니
이걸 loop를 돌리면서 반복적으로 원본 이미지에
변조를 가하는 것이 DeepDream의 workflow라 볼 수 있다.
2.1 Deepdream 코드 실행
이제 작성한 코드를 실행해보자
# 설계한 DeepDreamNet를 받아서 인스턴스화
dream_net = DeepDreamNet(backbone, block_setting.keys(), device)
img_tensor, origin_shape = preprocess_img(img_path, device)
lr = 0.5
iteration = 20
# deep_dream을 수행하기 위한 하이퍼 파라미터(Lr, 반복횟수(epoch랑 같은개념)) 설정 후 객체화
deep_dream = DeepDream(dream_net, block_setting, lr, iteration, max_loss=None)위 객체화 과정 및 준비작업만 먼저 수행한 후
outputs = dream_net(img_tensor)
loss = deep_dream.compute_loss(outputs)
print(f"정의한 Loss의 초기값: {loss.item():.4f}")정의한 MSE Loss의 초기값을 확인할 필요가 있다.
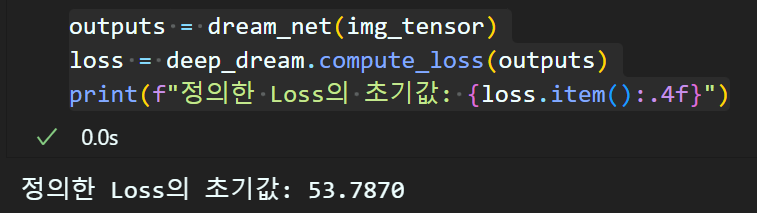
이 과정을 수행하는 이유는 초기 Loss가 향후 어디까지 값이 폭주하는지를 알 필요성이 있어서 이다.
또 Loss의 정의를 어떻게 하느냐에 따라 초기 Loss값이 천차만별이니 초기 Loss가 어느 값부터 시작하는지는 필히 알아둘 필요가 있다.
이제
gradient_ascent_loop 함수에서
print(f"Step {i}, loss: {loss:.4f}, grad: {grads_norm:.4f}")이 print구문을 활성화 시키고
img_tensor = deep_dream.gradient_ascent_loop(img_tensor)이 코드를 실행하자
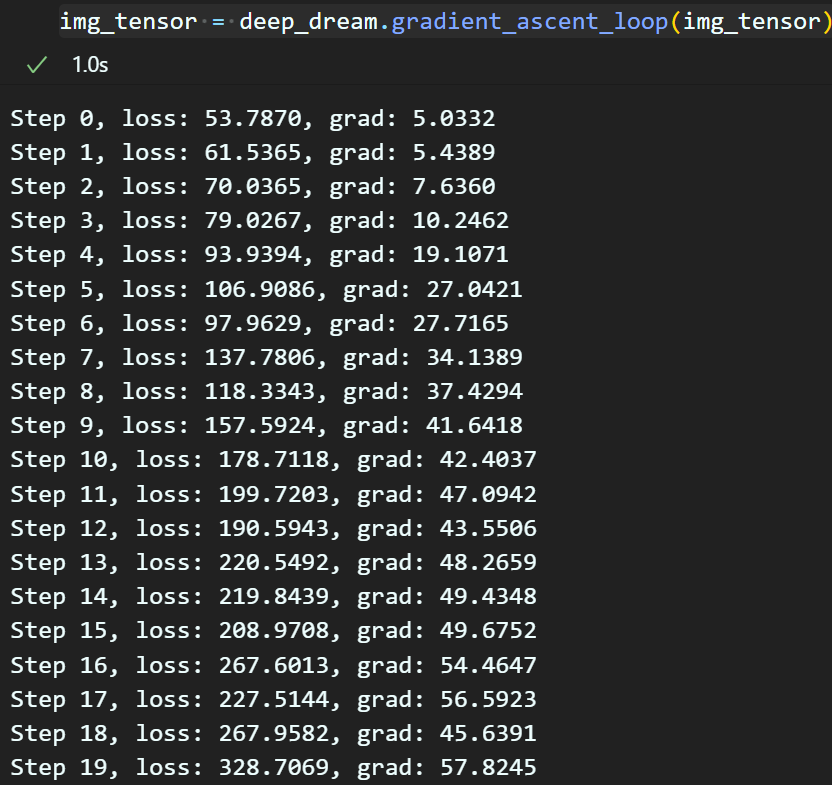
경사상승법이 반복 진행됨에 따라
Loss값이 폭주하고, 그에 따른 모든 Param에 걸리는 Gradient값도 같이 상승하는 것을 확인할 수 있다.
import matplotlib.pyplot as plt
res_img = deprocess_img(img_tensor, origin_shape)
res_img = Image.fromarray(res_img)
res_img.save("deep_dream.jpg")마지막으로 DeepDream을 수행한 이미지를 저장하고 비교해보자

음.. DeepDream의 블로그에서 봤던 그런 이미지가 출력될 것이라고는 기대하지 말자

이런 이미지 만들려면 다양한 튜닝기법이 필요하고
현재 시점에서는 튜닝을 잘 해야
 이런 이미지를 만들어 낼 수있다...
이런 이미지를 만들어 낼 수있다...
(이건 필자가 튜닝을 이것저것 열심히 해봐도.. 모르겟다..)
3. Octave
여기까지 수행하면 몇가지 문제점이 있다고 한다
1) 생성한 이미지에 Noise가 많음
2) 해상도가 낮음
3) 패턴이 균일한 입도(granularity) -> 그러니까 패턴이 배경이나, 이미지의 주요부분(객체)나 동일하게 찍힌다.. 뭐 이런뜻임...
이 3가지 문제점을 해결하기 위한 방법이 Octave이다.
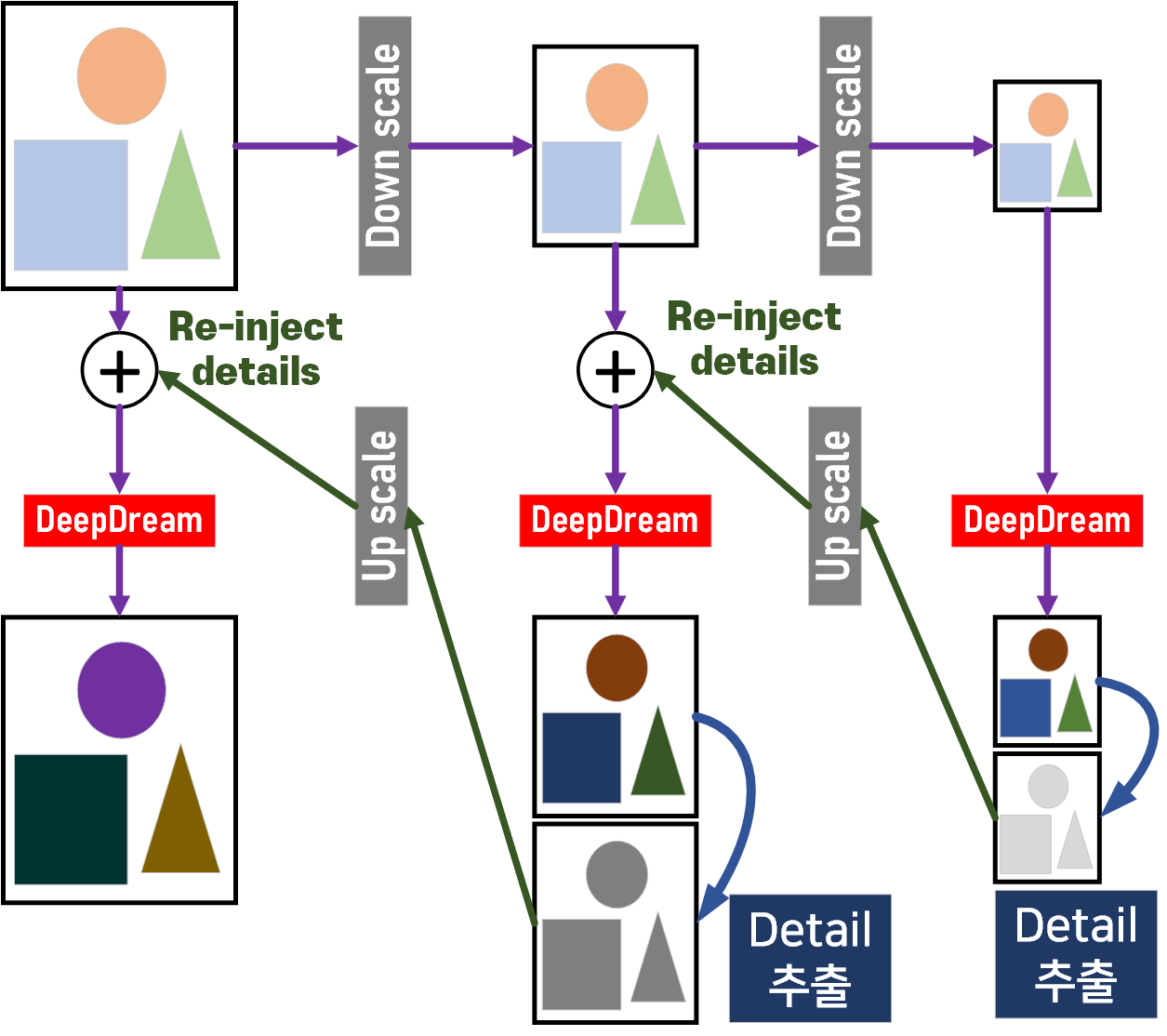
과정에 대한 도식도를 그리면 위와 같은데
설명을 하자면
1) 이미지를 여러 단계의 DownScale를 수행한다.
2) 수행한 DownScale 이미지 중 가장 작은 이미지부터
DeepDream을 적용한다.
3) 이 DeepDream이 적용된 가장 작은 DownScale와 원본이미지를 비교해서
변조된 항목 이것을 추출해 detail 로 저장한다.
4) detail을 Up scale한 후 이를 그 다음 DownScale 이미지와 합산한다 이게 Re-inject details
5) Re-inject details을 수행한 이미지에 대해 DeepDream을 적용한다.
6) 3~5 과정 반복
위 Octave를 수행한다면 좀 더 자연스러운 DeepDream결과물을 얻을 수 있다.
이것에 대한 코드는 아래와 같다.
def octave_fn(img_path, deep_dream, octave_scale, num_octaves):
img_tensor, origin_shape = preprocess_img(img_path, device)
octaves = [img_tensor] #원본이미지를 DownSample하면서 옥타브 리스트 생성
for _ in range(num_octaves - 1):
dscale_factor = octaves[-1].shape[2:] #텐서 이미지의 H, W 추출
# 리스트의 [H, W]에 octave_scale를 적용하여 Down Scale
dscale_factor = [round(scale_element / octave_scale) for scale_element in dscale_factor]
# v2.Resize는 A 이미지에 크기변환 적용 후 A이미지 반환이지만, functional는 변환된 A를 B이미지로 저장가능
# resized_img_2 = cv2.resize(img, dsize=(H,W) 이렇게 쓰는 용도라 보면 됨
scaled_img_tensor = v2.functional.resize(octaves[-1], dscale_factor)
octaves.append(scaled_img_tensor) # DownSampling된 텐서 이미지가 octaves에 담김
octaves.reverse() # 옥타브 리스트의 순서를 역순으로 (octaves = octaves[::-1])
detail = torch.zeros_like(octaves[0]) #딥드림을 수행한 후 디테일 정보만 담을 변수
#이 디테일의 크기는 옥타브가 진행되면서 계속 변화한다.
for i, octave in enumerate(octaves):
octave = octave + detail # 옥타브에 디테일을 더함(Re-inject detail)
octave = deep_dream.gradient_ascent_loop(octave) #옥타브 텐서를 딥드림함
#변형된 octave에서 변조된 항목만 추출 -> 이게 detail임
resize_origin = v2.functional.resize(img_tensor, detail.shape[2:])
detail = octave - resize_origin
# 수행한 detail 이미지를 출력해보자
# detail_img = deprocess_img(detail, origin_shape)
# detail_img = Image.fromarray(detail_img)
# detail_img.save(f"detail_{i}.jpg")
# 디테일을 다음 옥타브에 re-inject하기 위한 업 스케일링
uscale_factor = detail.shape[2:] #[H, W] 정보 추출
uscale_factor = [round(scale_element * octave_scale) for scale_element in uscale_factor]
detail = v2.functional.resize(detail, uscale_factor)
if i+1 == num_octaves:
result_img = deprocess_img(octave, origin_shape) #마지막 옥타브가 변형이 완료된 항목임
return result_img위 Octave를 적용하는 코드는 아래와 같다.
lr = 2
iteration = 30 #딥드림의 하이퍼 파라미터
deep_dream = DeepDream(dream_net, block_setting, lr, iteration, max_loss=None)
octave_scale = 1.4
num_octaves = 3 #Octave의 하이퍼 파라미터
result_img = octave_fn(img_path, deep_dream, octave_scale, num_octaves)
#최종 출력물 저장
result_img = Image.fromarray(result_img)
result_img.save(f"octave.jpg") 사진을 보면 알 수 있지만
사진을 보면 알 수 있지만
그냥 DeepDream을 적용한 이미지 보다는
OctaveDeepDream 이미지가 객체에 관해서 더 강하게 변조기 일어나고, 동시에 주변 배경에 대한 노이즈도 많이 감소했음을 확인할 수 있다.
4. Boundary effect
위 OctaveDeepDream 이미지
특히 Detail이미지를 본다면 문제점이 하나 발생함을 알 수 있다.

이 Boundary effet문제를 완화하기 위해서는
1) padding 추가
2) Tiling과 Overlap
3) Multiscale
4) Border correction
5) 이미지 확장 후 크롭
6) 이미지 반사 패딩(Reflect padding)
위 6가지 방법론이 존재하는데
필자는 이 중 Reflect padding를 적용하고자 한다.
이를 도식화 하면 아래와 같다.
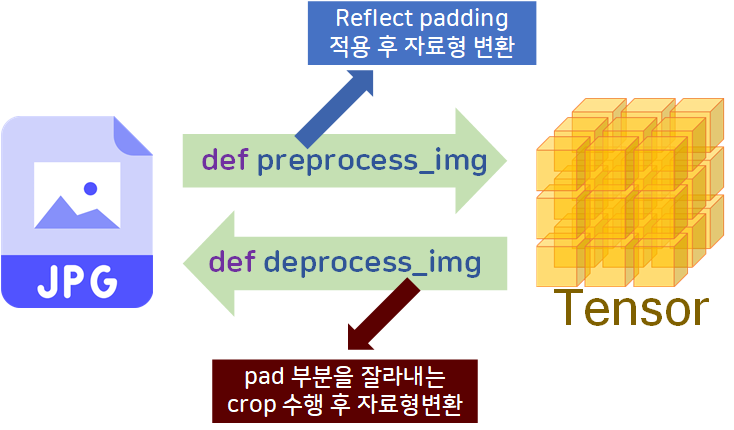
1) preprocess_img
# 데이터셋 표준화를 위한 기본정보
imgNet_val = {'mean' : [0.485, 0.456, 0.406], 'std' : [0.229, 0.224, 0.225]}
# 반사패딩을 적용하기 위한 설정값
pad_factor = [0.3, 0.3, 0.3, 0.3] #left, top, right, bottom
def preprocess_img(img_path, device, reflect_pad):
img = Image.open(img_path).convert('RGB')
width, height = img.size
img_shape = [height, width] #원본 이미지의 크기정보를 따로 저장
padding = [ # 비율에 따른 반사 패딩 값 계산
int(width * reflect_pad[0]), # left
int(height * reflect_pad[1]), # top
int(width * reflect_pad[2]), # right
int(height * reflect_pad[3]) # bottom
]
transformation = v2.Compose([
v2.Pad(padding, padding_mode='reflect'), #반사패딩 설정
v2.Resize((224, 224)), #VGG19 -> [224, 224]
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=imgNet_val['mean'], std=imgNet_val['std']) #데이터셋 표준화
])
img_tensor = transformation(img).unsqueeze(0).to(device)
return img_tensor, img_shape코드를 보면 알 수 있듯이
pad_factor = [0.3, 0.3, 0.3, 0.3] #left, top, right, bottom이렇게 왼쪽, 위, 오른쪽, 아래에 padding을 어느 비율까지 적용할지에 대한 pad_factor를 설계한다.
설계한 pad_factor를 원본 이미지의 크기에 맞춰서 픽셀 정보로 값을 변환해준 뒤
padding = [ # 비율에 따른 반사 패딩 값 계산
int(width * reflect_pad[0]), # left
int(height * reflect_pad[1]), # top
int(width * reflect_pad[2]), # right
int(height * reflect_pad[3]) # bottom
]마지막에
v2.Pad(padding, padding_mode='reflect'), #반사패딩 설정이렇게 Torchvision라이브러리에서 제공하는 Pad 메서드를 활용하면 끝난다.
 적용결과는 위 사진과 같다.
적용결과는 위 사진과 같다.
2) deprocess_img
# 텐서 자료형의 이미지를 원복하는 함수
def deprocess_img(img_tensor, img_shape, pad_factor):
tenser_size = img_tensor.shape[2:] #텐서 이미지의 H, W 추출
crop_pad = [int(pad_factor[1] / (1+ pad_factor[1]+pad_factor[3]) * tenser_size[0]), #top
int(pad_factor[0] / (1+ pad_factor[0]+pad_factor[2]) * tenser_size[1]), #left
int(1 / (1+ pad_factor[1]+pad_factor[3]) * tenser_size[0]), #height
int(1 / (1+ pad_factor[0]+pad_factor[2]) * tenser_size[1]) #width
]
#반사 패딩 항목을 제거
img_tensor = v2.functional.crop(img_tensor, crop_pad[0]+1, # top
crop_pad[1]+1, # left
crop_pad[2]+1, # height
crop_pad[3]+1) # width
#텐서 자료형을 원본 이미지 크기로 리사이징
img_tensor = v2.functional.resize(img_tensor, img_shape)
#np 자료형으로 변환
img_np = img_tensor.cpu().numpy().squeeze().transpose(1, 2, 0)
# 이미지에 표준화 되어 있던걸 원복
img_np = img_np * np.array(imgNet_val['std']) + np.array(imgNet_val['mean'])
img_np = np.clip(img_np, 0, 1)
img = (img_np * 255).astype(np.uint8)
return imgpreprocess_img 함수 설계는 그렇게 어려운 편이 아닌데 deprocess_img에서 crop 값 찾는게 좀 까다롭다.
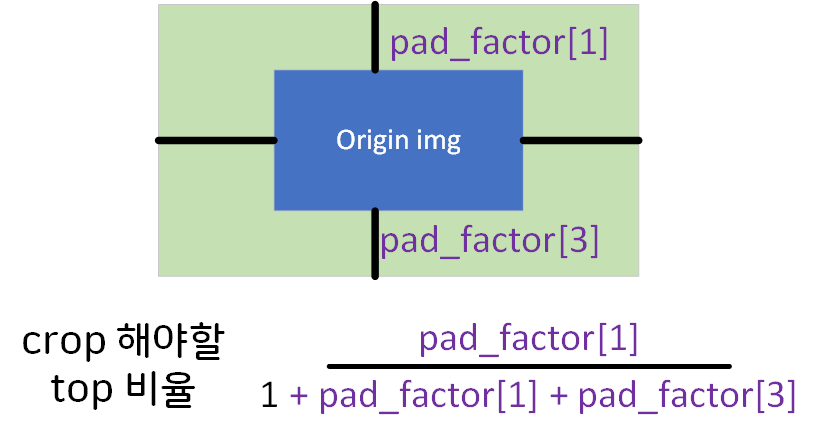 대략 위와 같은 계산식으로
대략 위와 같은 계산식으로
crop의 비율정보를 추출해 내야 한다.
또 Pad함수는 입력순서가 [Left, Top, Right, Bottom] 인데
crop는 [Top, Left, Height, Width]
으로 좀 꼬여있다...
아무튼 두 함수를 설계하고
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_path = '00100.jpg' #불러올 이미지의 경로img_tensor, shape = preprocess_img(img_path, device, pad_factor)
restore_img = deprocess_img(img_tensor, shape, pad_factor)
res_img = Image.fromarray(restore_img)
res_img.save("restore.jpg")
이미지 복원이 나름 잘 되는것을 확인할 수 있다.
이때 새로이 생성한 pad_factor은 Boundary effet효과를 없에면서 동시에DeepDream 성능을 드라마틱하게 개선하는 효과가 발생한다.
특히 OctaveDeepDream은 그 효과가 엄청나게 증가하기에
Octave을 적용할 때 learning_rate, iteration(epoch)는 기존보다 값을 많이 다운시켜야 한다.
참고로 pad_factor = [0.01, 0.01, 0.09, 0.09]이다.

5. 고해상도 DeepDream
이제 마지막 과정인
해상도를 높이는 작업을 진행하고자 한다.
https://www.tensorflow.org/tutorials/generative/deepdream?hl=ko
공식 홈페이지에서는 Tiling을 통해서 이미지 확장을 수행하라 했지만
필자는 이미지를 Patch단위로 분할한 뒤,
이를 mini_batch로 활용하여 병렬처리를 최대한 활용하고자 한다.
이를 도식화 하자면 아래와 같다.
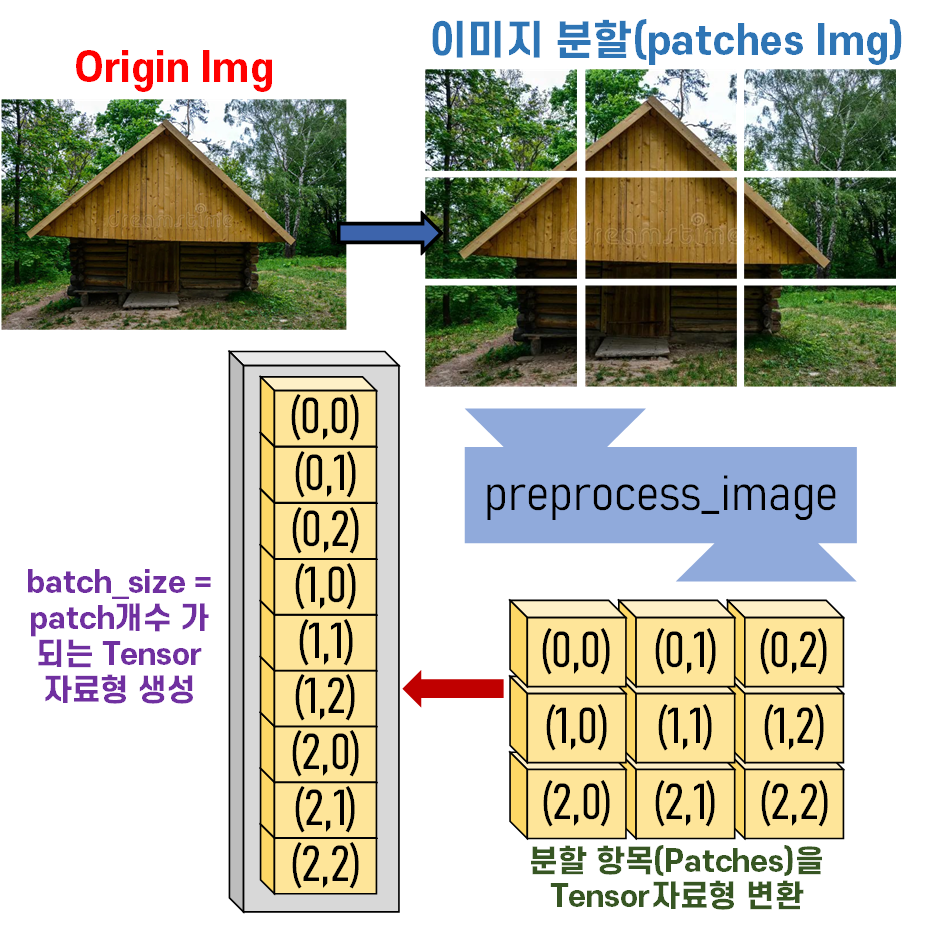
위 과정에 관한 코드는 아래와 같다.
# 데이터셋 표준화를 위한 기본정보 # 패치(반사패딩 추가해야함)
imgNet_val = {'mean' : [0.485, 0.456, 0.406], 'std' : [0.229, 0.224, 0.225]}
pad_factor = [0.01, 0.01, 0.09, 0.09] #left, top, right, bottom# 이미지를 받아서 텐서 자료형으로 변환하는 함수
def preprocess_img(img_path, device, pad_factor, patch=1):
assert int(patch ** 0.5) ** 2 == patch, "패치는 제곱수여야 함"
img = Image.open(img_path).convert('RGB')
width, height = img.size
img_shape = [height, width] #원본 이미지의 크기정보를 따로 저장
#이미지를 패치로 나누기
patches = []
patch_size = []
if patch != 1:
patch_side = int(patch ** 0.5)
patch_size = [height // patch_side, width // patch_side]
for n in range(patch):
i, j = divmod(n, patch_side) #몫, 나머지를 i, j로 활용
patch_img = img.crop((j * patch_size[1],
i * patch_size[0],
(j + 1) * patch_size[1],
(i + 1) * patch_size[0]))
patches.append(patch_img)
else:
patches.append(img)
patch_size = [height, width]
padding = [ # 비율에 따른 반사 패딩 값 계산
int(patch_size[1] * pad_factor[0]), # left
int(patch_size[0] * pad_factor[1]), # top
int(patch_size[1] * pad_factor[2]), # right
int(patch_size[0] * pad_factor[3]) # bottom
]
transformation = v2.Compose([
v2.Pad(padding, padding_mode='reflect'), #반사패딩 설정
v2.Resize((224, 224)), #[224, 224]로 리사이징
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=imgNet_val['mean'], std=imgNet_val['std']) #데이터셋 표준화
])
# img_tensor = transformation(img).unsqueeze(0).to(device)
# 각 패치별로 transformation을 적용 -> 텐서 자료형변환
patch_tensors = [transformation(patch) for patch in patches]
img_tensor = torch.stack(patch_tensors).to(device)
# 이렇게 하면 img_tensor의 shape는 (batch_size=patch, 3, 224, 224)가 됨
return img_tensor, img_shape# 텐서 자료형의 이미지를 원복하는 함수
def deprocess_img(img_tensor, img_shape, pad_factor):
tenser_size = img_tensor.shape[2:] #텐서 이미지의 H, W 추출
# 이미지가 패치로 나눠어진 경우 해당 정보를 추출
batch_size = img_tensor.size(0)
patch_side = int(batch_size ** 0.5)
patch_size = (img_shape[0] // patch_side, img_shape[1] // patch_side)
crop_pad = [int(pad_factor[1] / (1+ pad_factor[1]+pad_factor[3]) * tenser_size[0]), #top
int(pad_factor[0] / (1+ pad_factor[0]+pad_factor[2]) * tenser_size[1]), #left
int(1 / (1+ pad_factor[1]+pad_factor[3]) * tenser_size[0]), #height
int(1 / (1+ pad_factor[0]+pad_factor[2]) * tenser_size[1]) #width
]
#반사 패딩 항목을 제거
patches_tensor = [v2.functional.crop(img_tensor[i], crop_pad[0]+1, # top
crop_pad[1]+1, # left
crop_pad[2]+1, # height
crop_pad[3]+1) # width
for i in range(batch_size)]
#패치 텐서를 각 패치별 크기로 원복(리사이징)
patches_tensor = [v2.functional.resize(patches_tensor[i], patch_size) for i in range(batch_size)]
#np 자료형으로 변환
patches_np = [patch_tensor.cpu().numpy().squeeze().transpose(1, 2, 0) for patch_tensor in patches_tensor]
# 이미지에 표준화 되어 있던걸 원복
patches_np = [(patch_np * np.array(imgNet_val['std']) + np.array(imgNet_val['mean'])) for patch_np in patches_np]
patches_np = [np.clip(patch_np, 0, 1) for patch_np in patches_np]
# 패치를 하나의 이미지로 결합
rows = [np.concatenate(patches_np[i * patch_side:(i + 1) * patch_side], axis=1) for i in range(patch_side)]
full_img = np.concatenate(rows, axis=0)
img = (full_img * 255).astype(np.uint8)
return img뭐 지금까지 설명한 항목에서
batch_size를 병렬로 처리하는 코드만 추가된 부분이고
그 과정에서 몇개의 for문이 사용된 수준이라 보면 된다.

설명하기 너무 빡세고 어렵고... 뭐 그래도 잘 동작하니까 넘어갑시다
아무튼 설계한 함수의 사용방법은 아래와 같다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img_path = '99199.jpg' #불러올 이미지의 경로img_tensor, shape = preprocess_img(img_path, device, pad_factor, patch=16)
restore_img = deprocess_img(img_tensor, shape, pad_factor)
res_img = Image.fromarray(restore_img)
res_img.save("restore.jpg")
솔직히 복원이 이렇게 잘 될 거라고는 생각을 안했는데...
아무튼 최종 결과물을 확인해보자


이 정도면

6. Dense Net로 DeepDream
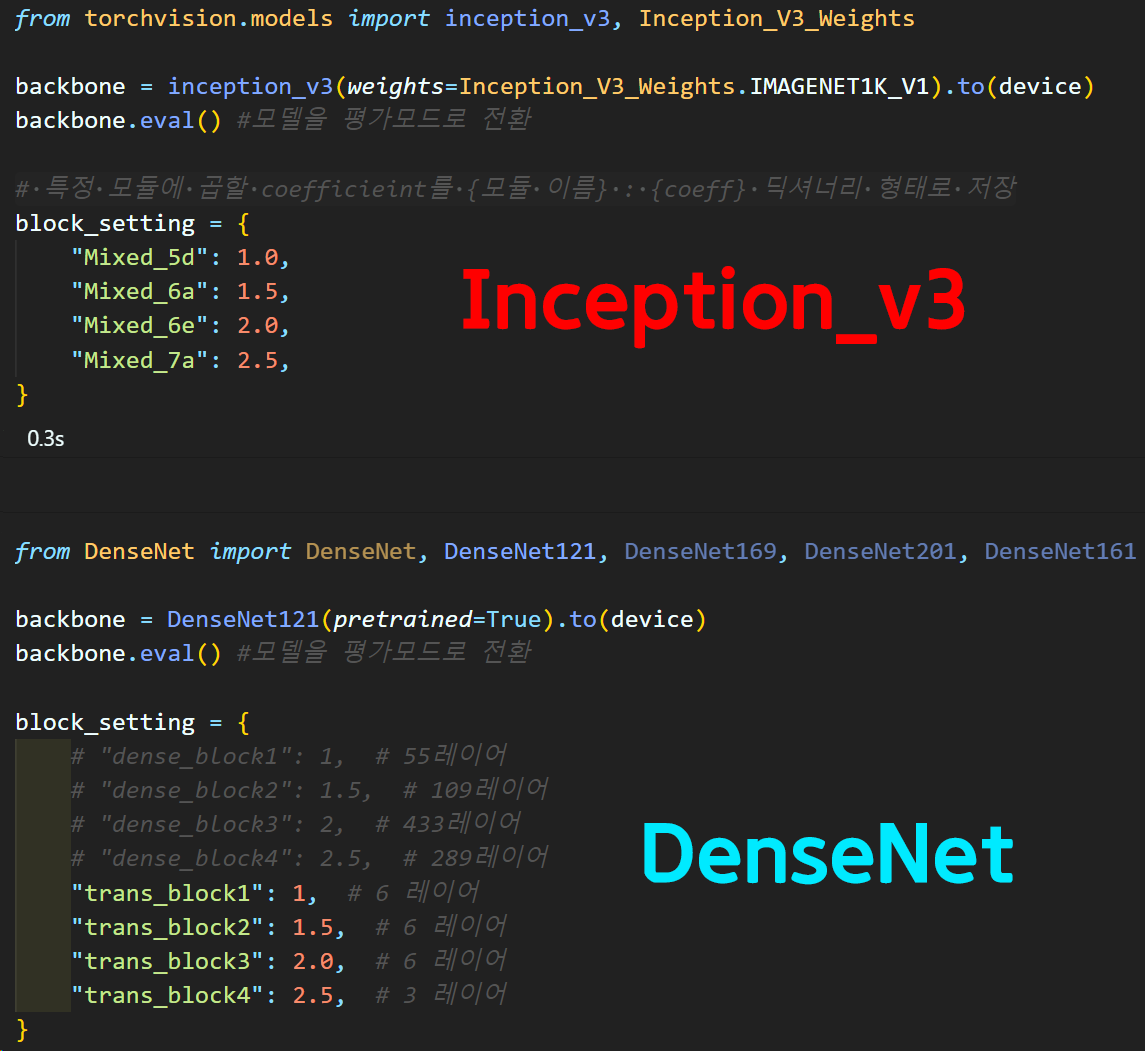
backbone이랑
block_setting만 바꾸면 아주 손쉽게
DenseNet으로
DeepDream을 수행할 수 있다.

결과를 보면DenseNet은 DeepDream이 아에 안된다.
그냥 안되는 모델이었다.

CNN모델별로 DeepDream을 수행하여 이미지 변조가 충분히 잘 되는 모델이 있고
거의 변조가 안되는 모델이 있다...
Dense Connectivity이 강하게 걸려서인지
아니면 기본 base block이 1x1conv, 3x3conv 만 있어서인지
뭐.. 잘 모르겠다
아무튼 모델별로 상이한 결과가 나온다는 것에 대해서
긍정적인 공부가 되었다
가 아니라 DenseNet로 DeepDream을 먼저 수행해서 왜 안되는지 그 이유를 파헤치는데 의미없이 2일 날림..

이 DeepDream과정의 경우 필자가 이해하고
코드를 개선하면서
동시에 블로그에 포스팅이 가능할 수준으로 다시 숙지를 하는데 너무 많은 시간이 소요됬다.
그리고 정말 어려운 내용이기도 했다.
따라서 최종 완성된 파일을
https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/deepdream_final.ipynb
에 업로드 한다.
학습 난이도는 꽤 있는 항목이었지만
그 나름대로 꽤 의미있는 기능들을 학습하는데
좋은 교보재라 생각하고 있다...
