
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. DenseNet 배경
ResNet이 발표되면서 제안한 Residual Connection 방법론은 모델을 깊게 쌓으면서도 Shallow Layer의 특징정보가 소실되는 문제를 획기적으로 개선했지만, 모델의 Depth가 증가할 수록 효율성이 낮아지고, Vanshing Gradient 문제를 완전히 해결하지 못한 한계점이 존재한다.
이를 DenseNet은 Dense Connectivity라는 더 조밀한 연결 패턴을 제안함으로써 효율적으로 Model Parameter을 사용하고, 네트워크 전체에서 Output Feature의 재사용률을 높여 ResNet 대비 더 적은 연산과 메모리 사용으로 높은 Accuracy을 달성했다.
1.1 Dense Connectivity
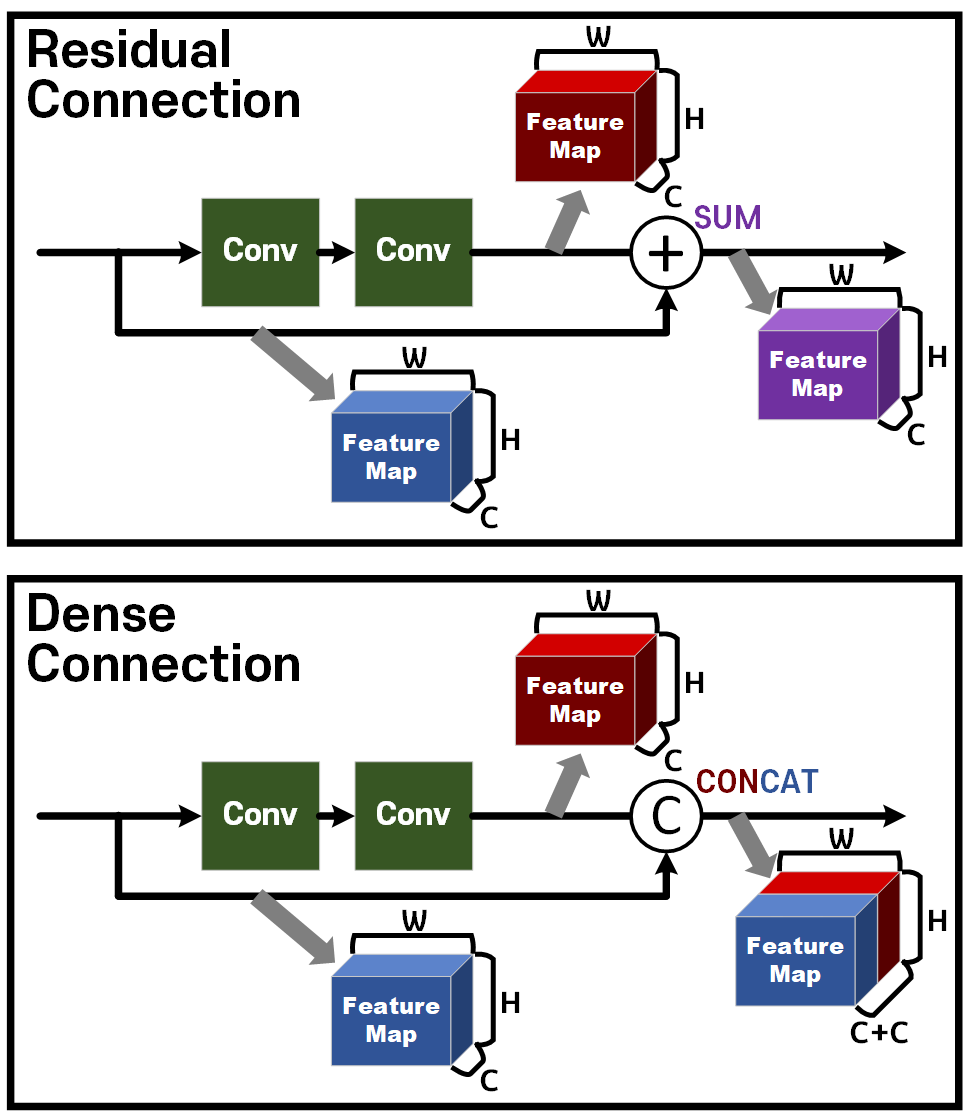
DenseNet이 제안하는 Dense Coneectivity의 기본 아이디어는 위 사진처럼 기존 ResNet의 Residual Connection이 이전 레이어의 출력과 현재 레이어의 출력을 SUM하여 후속 레이어로 전달한다면,
이를 이전 레이어의 출력과 현재 레이어의 출력을 Concat하여 후속 레이어로 전달하는 방식을 통해 네트워크 전체에서 Feature out의 재사용성과 무결성을 높였다.
Concat연결을 기본으로 위 사진처럼 Dense Connectivity연결망을 구성하여 Layer를 깊게 쌓더라도 Feature out의 재사용성이 강화되고, Vanshing Gradient문제도 ResNet보다 더 강하게 억제하는 효과를 얻어 낼 수 있다.
위 Dense Connectivity로 서로 연결된 Layer을 한데 묶어 Dense Block를 생성하며,
아래의 그림처럼 DenseNet은 몇개의 Dense Block을 쌓아 만든 구조가 핵심인 모델이다.

Growth Rate
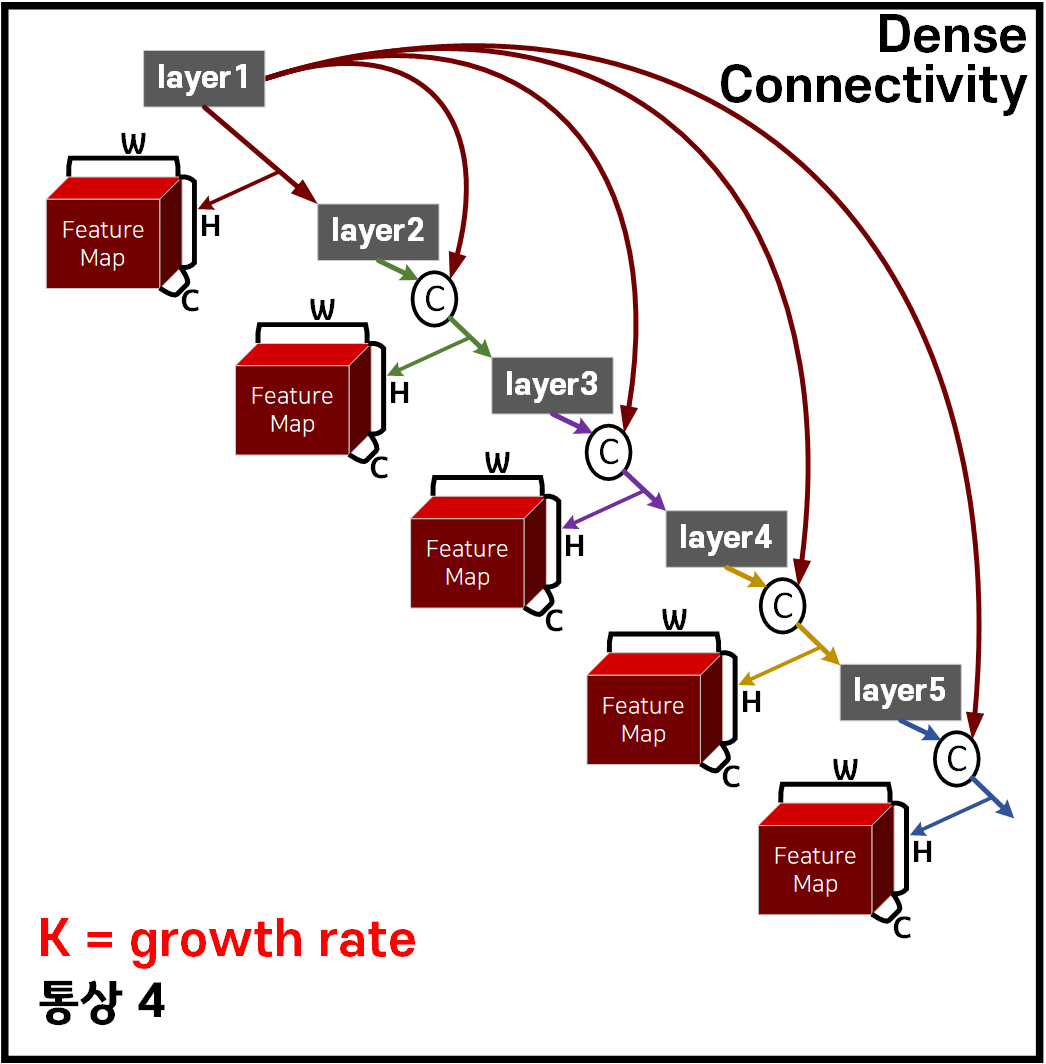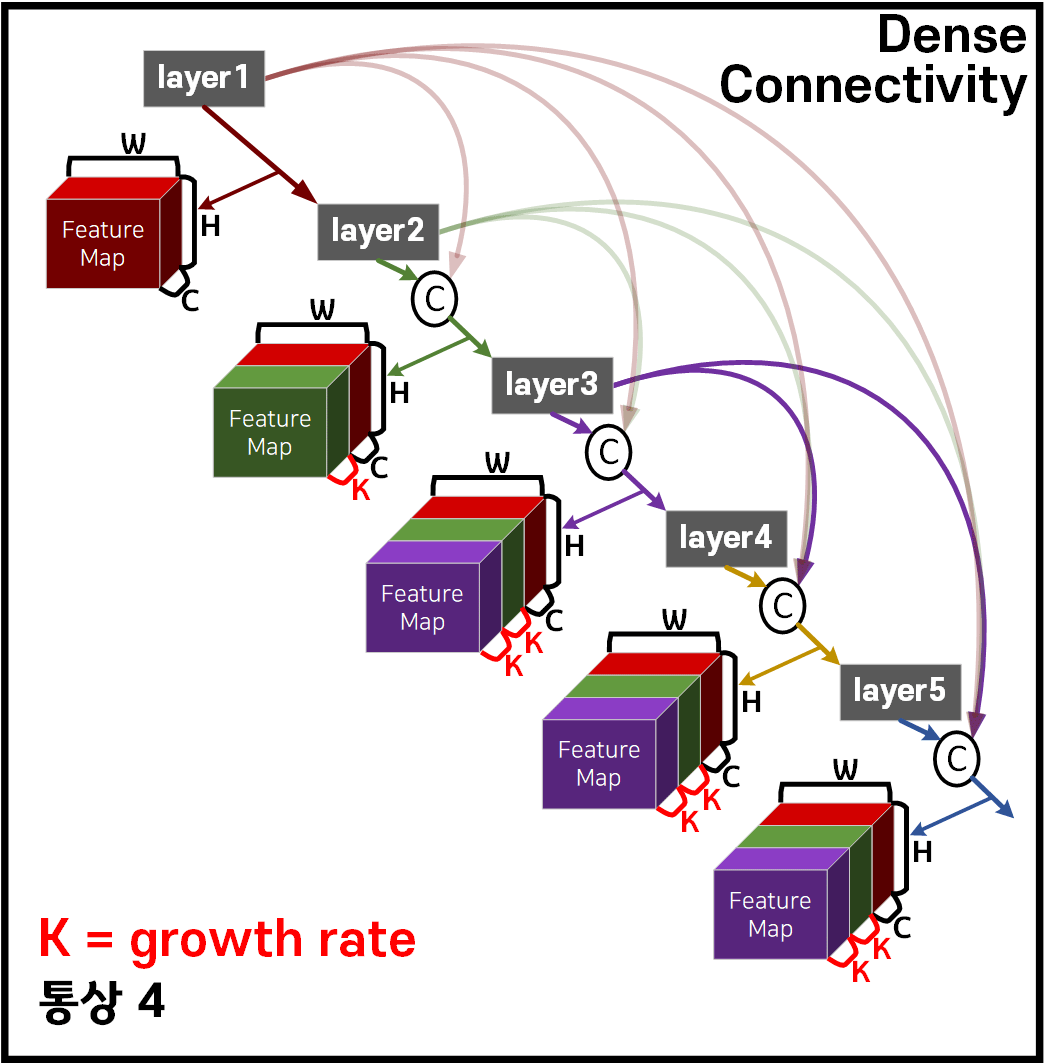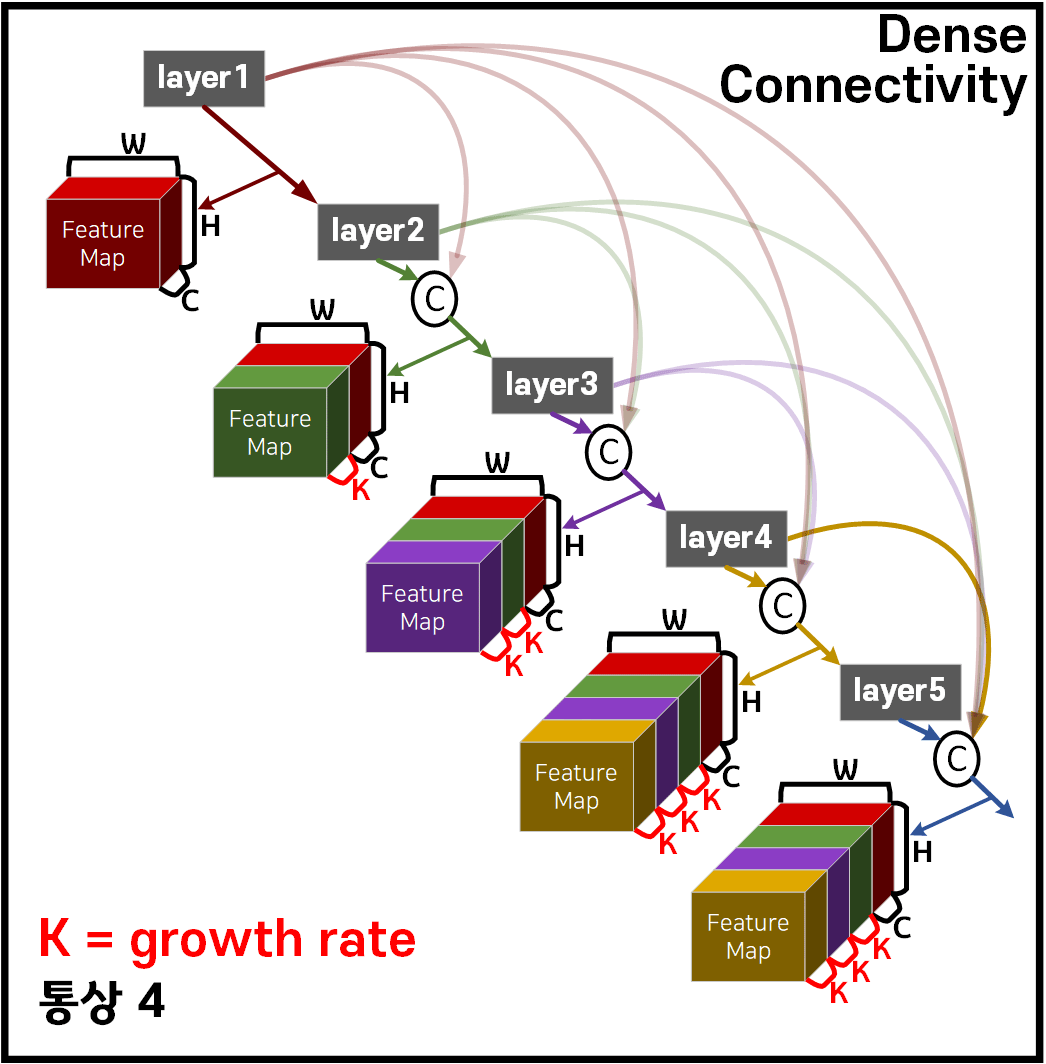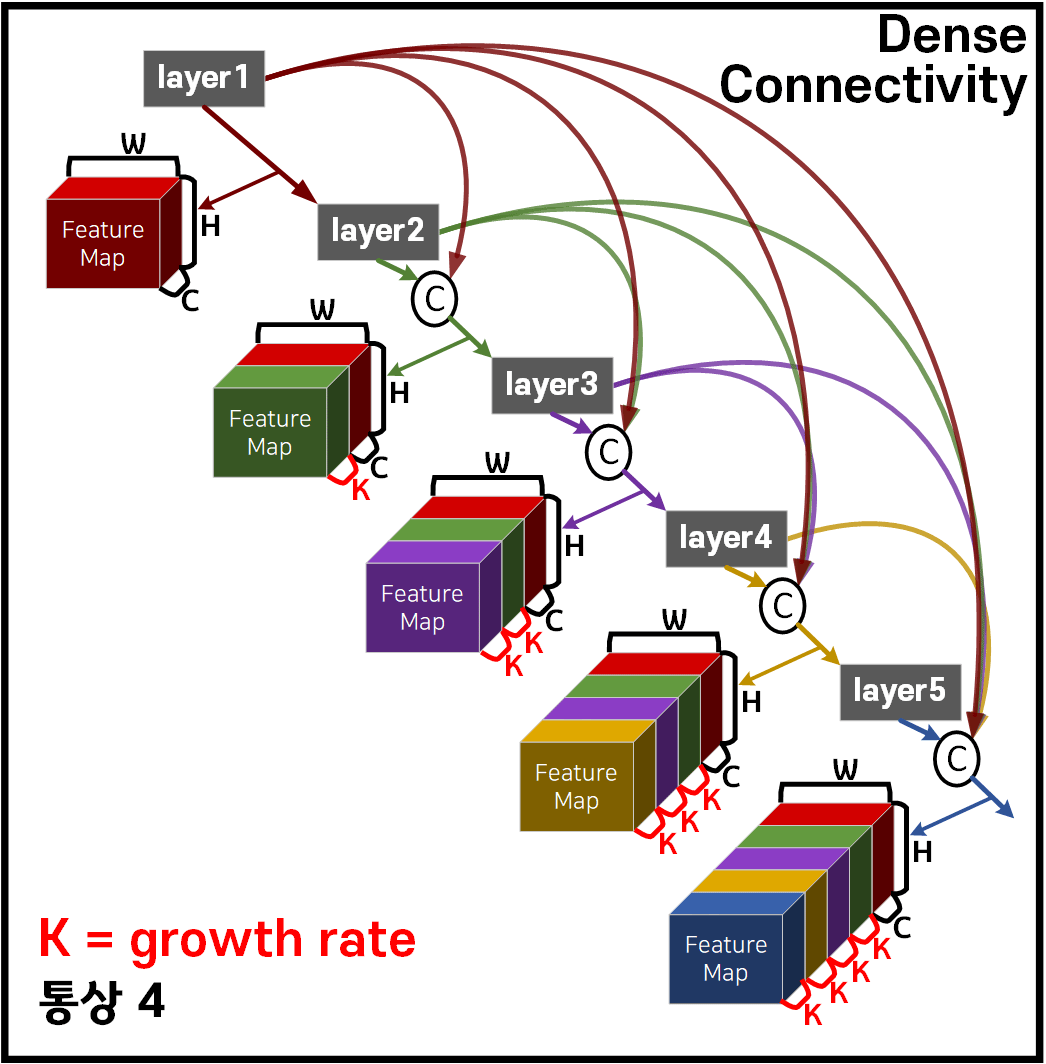
이 Dense Block을 구성하면 이전 레이어들의 Feature out이 현재 레이어의 Feature out에 누적하여 concat하기에 말단 레이어에는 Feature out의 channel을 아래와 같은 수식으로 계산할 수 있다.
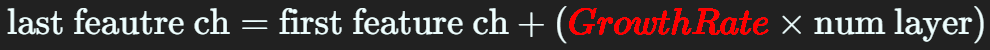
이때 Growth Rate는 Dense Block 내 각 레이어가 추가하는 Feature out이다.
Bottle Neck Module

위 사진처럼 Dense Block의 구성 Layer은
BottleNeck Module로 되어 있으며, 해당 모듈에 입력되는 shape를 갖는 Feature는
의 shaep를 갖는 Feature로 출력된다.
Compositie Function
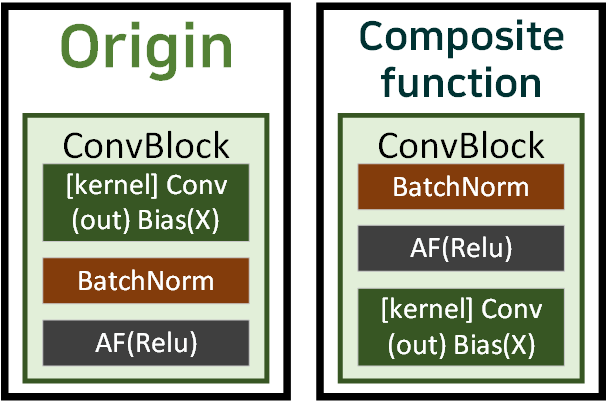 위 사진처럼 기본
위 사진처럼 기본 ConvBlock를 생성할 때는 모듈의 순서가 ConvBNAF로 진행되는 것이 일반적이나
Identity mappings in deep residual networks논문에서
BNAFConv 이 순서가 더 좋다고 한다.
그래서 DenseNet도 위 구조를 차용한다.
1.2 Trasition Layer
 위 그림처럼
위 그림처럼 Dense Block 사이에 Transition Layer을 삽입하여 그림과 같이 이전 Dense Block의 Feature out을
차원+크기를 축소하여 다음 Dense Block에 전달하는 역할을 수행한다.
즉, Down Sampling을 수행하는 레이어라 보면 된다.
2. DenseNet 아키텍쳐
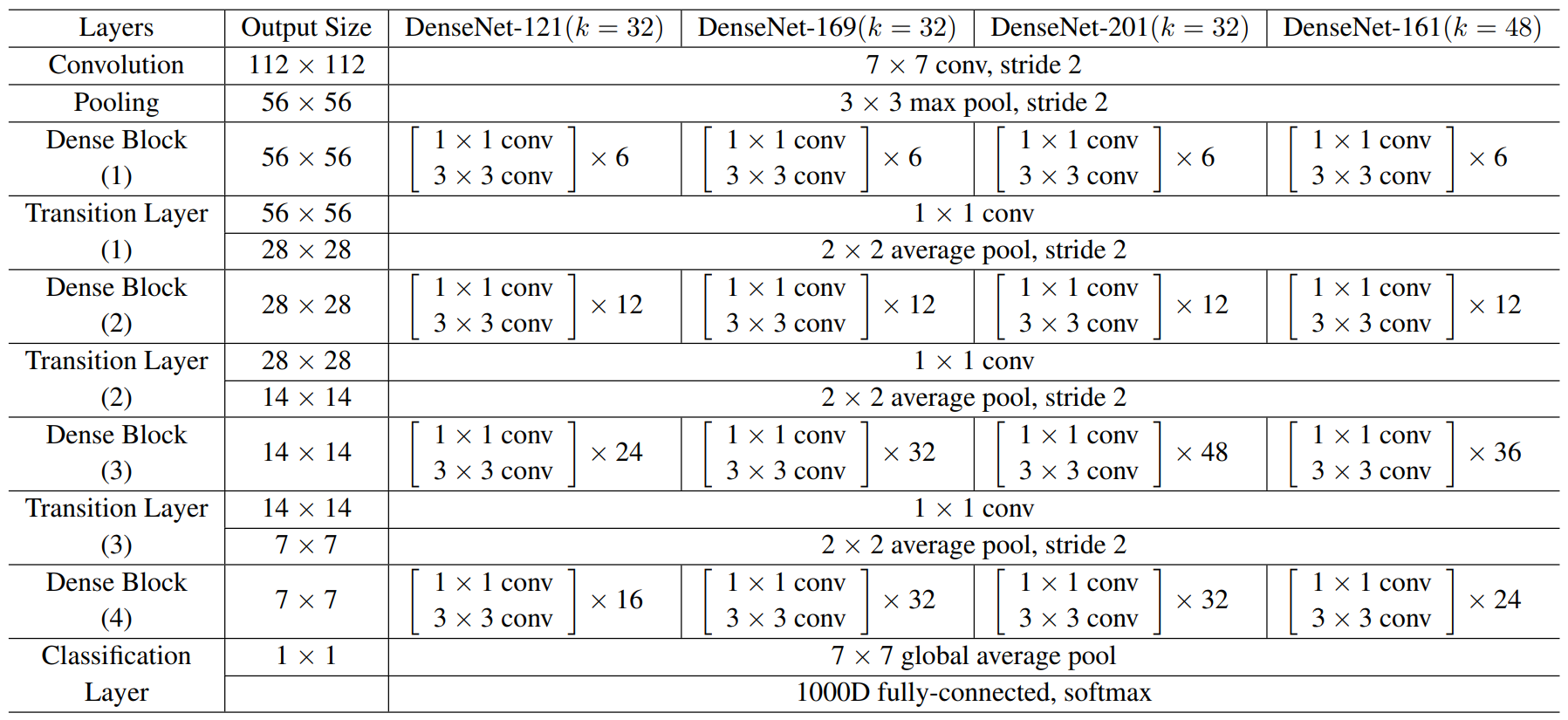
논문에 기재되어 있는 DenseNet의 일반적인 아키텍쳐를 도식화 한다면 아래와 같다.
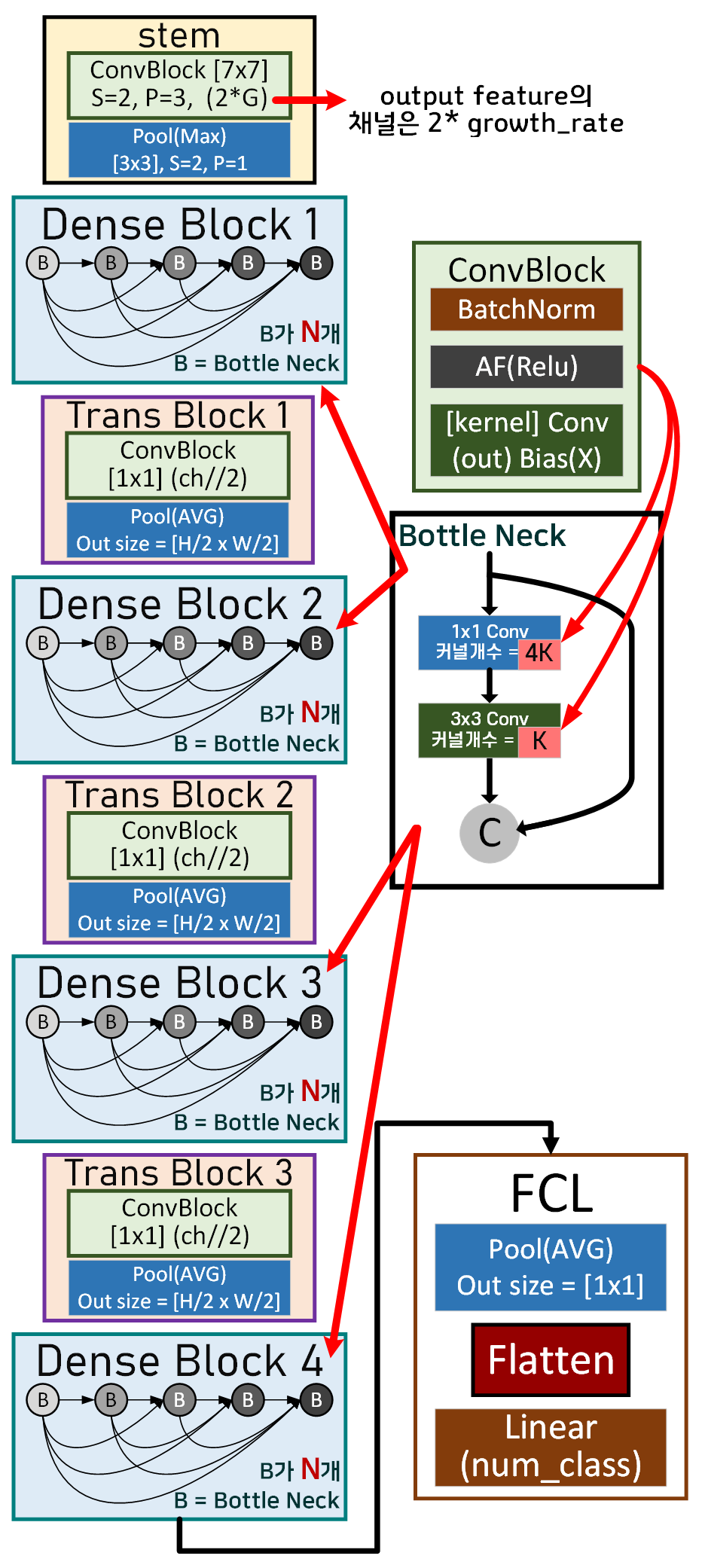
기본블럭인 Conv Block이 Bottle Neck Module에 들어가고
이 Bottle Neck Module 여러개 모여서 하나의 Dense Block를 구성하는 구조이다.
Dense Block는 총 4개, 사이에 Trans Block(Transition Layer)이 끼어있고
마지막 FCL은 Classifier이다.
위 네트워크 구조를 각각 코드로 구현하면 아래와 같다.
import torch
import torch.nn as nnclass Trastion_module(nn.Module):
def __init__(self, in_ch):
super(Trastion_module, self).__init__()
# Composition Function을 적용하여 BN -> AF -> Conv순
self.tr_layer = nn.Sequential(
nn.BatchNorm2d(in_ch),
nn.ReLU(),
nn.Conv2d(in_ch, in_ch//2, kernel_size=1, stride=1, bias=False)
)
# Feature Map 크기 감소
self.ave_pool = nn.AvgPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.tr_layer(x)
x = self.ave_pool(x)
return xclass Botteleneck(nn.Module):
# Dense block의 레이어들이 출력하는 FeatureMap 크기: K = Growh_rate
def __init__(self, in_ch, growth_rate):
super(Botteleneck, self).__init__()
self.conv1x1 = nn.Sequential(
nn.BatchNorm2d(in_ch),
nn.ReLU(),
nn.Conv2d(in_ch, out_channels=4*growth_rate, kernel_size=1, bias=False)
)
self.conv3x3 = nn.Sequential(
nn.BatchNorm2d(4*growth_rate),
nn.ReLU(),
nn.Conv2d(in_channels=4*growth_rate, out_channels=growth_rate,
kernel_size=3, padding=1, bias=False)
)
def forward(self, x):
identy = x
x = self.conv1x1(x)
x = self.conv3x3(x)
x = torch.cat([identy, x], dim=1)
return xclass DenseBlock(nn.Module):
def __init__(self, num_block, in_ch, growth_rate, last_stage=False):
super(DenseBlock, self).__init__()
self.dense_ch = in_ch
self.layers = nn.ModuleList() #리스트 처럼 레이어를 선언
for _ in range(num_block):
layer = Botteleneck(self.dense_ch, growth_rate)
self.layers.append(layer) #선언한 레이어를 리스트에 삽입
self.dense_ch += growth_rate
if last_stage:
self.layers.append(nn.BatchNorm2d(self.dense_ch))
self.layers.append(nn.ReLU())
else:
self.layers.append(Trastion_module(self.dense_ch))
assert self.dense_ch % 2 == 0, "채널 오류남"
self.dense_ch //= 2
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x위 DenseBlock은 자세히 보면 알겠지만
상황에 따라 Trastion_module도 함께 포함하여 모듈을 완성하기에
코드상으로만 본다면 설계한 DenseNet은 4개의 Dense Block로만 구성된 형태가 된다.
class DenseNet(nn.Module):
def __init__(self, block_list, growth_rate, n_classes=1000):
super(DenseNet, self).__init__()
assert len(block_list) == 4, "블럭 개수 확인 요"
self.growth_rate = growth_rate
self.stem = nn.Sequential( # DenseNet의 헤드 레이어
nn.Conv2d(in_channels=3, out_channels=2*self.growth_rate,
kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(2*self.growth_rate),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.dense_ch = 2*self.growth_rate
dense_blocks = []
for i, num_block in enumerate(block_list):
last_stage = (i == len(block_list) - 1)
dense_blocks.append(DenseBlock(num_block, self.dense_ch,
self.growth_rate,
last_stage=last_stage))
self.dense_ch = dense_blocks[-1].dense_ch
self.dense_blocks = nn.Sequential(*dense_blocks)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(self.dense_ch, n_classes)
)
def forward(self, x):
x = self.stem(x)
x = self.dense_blocks(x)
x = self.classifier(x)
return x이제 위 설계한 모델로 DenseNet의 파생버전을 생성하는 것이 가능한데 아래의 코드로 파생버전을 간편하게 설계할 수 있다.
def DenseNet121(n_classes=1000):
return DenseNet(block_list=[6, 12, 24, 16], growth_rate=32, n_classes=n_classes)
def DenseNet169(n_classes=1000):
return DenseNet(block_list=[6, 12, 32, 32], growth_rate=32, n_classes=n_classes)
def DenseNet201(n_classes=1000):
return DenseNet(block_list=[6, 12, 48, 32], growth_rate=32, n_classes=n_classes)
def DenseNet264(n_classes=1000):
return DenseNet(block_list=[6, 12, 64, 48], growth_rate=32, n_classes=n_classes)# 커스텀 모델 인스턴스화
cus_model_1 = DenseNet121()
cus_model_2 = DenseNet169()
cus_model_3 = DenseNet201()
cus_model_4 = DenseNet264()from torchsummary import summary
#cus_model_1~4까지 넣어서 레이어 구성을 확인하자!~
summary(cus_model_4, input_size=(3, 224, 224), device='cpu')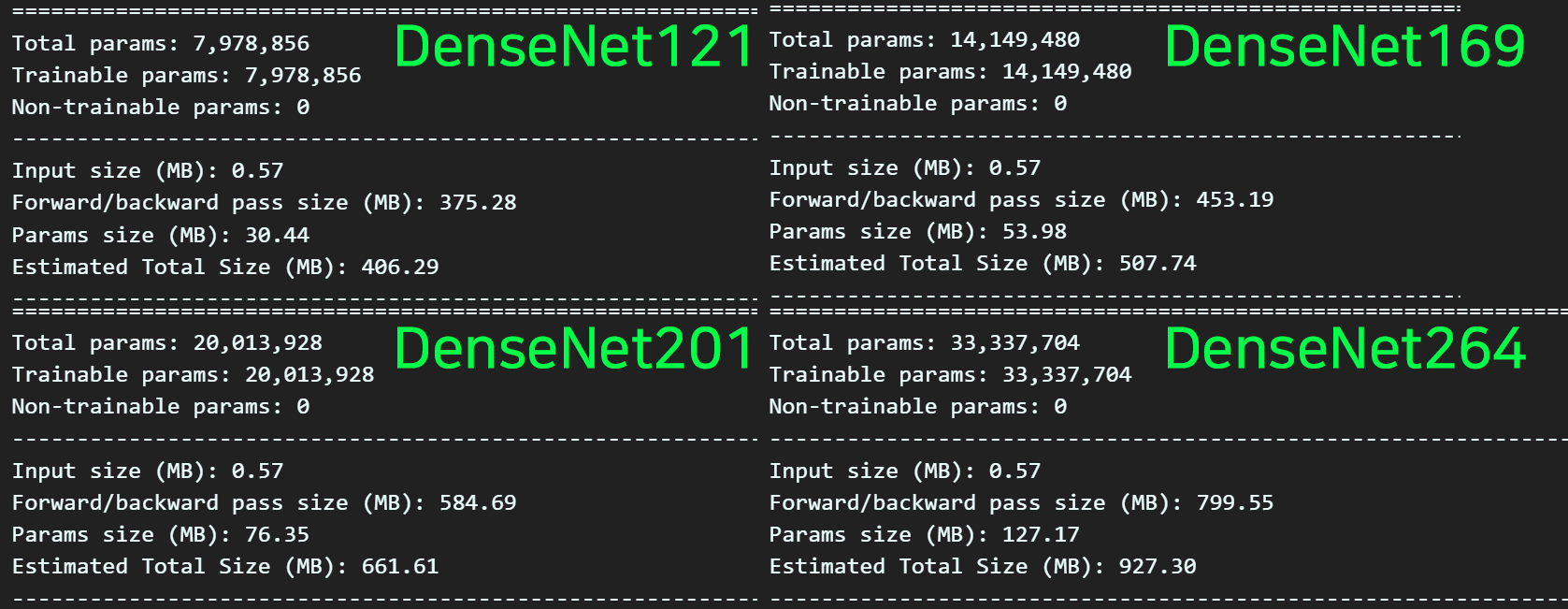
파생 버전별로 전체 Parm의 개수가 7백만에서 3천3백만까지 인 것을보면 꽤 가벼운 모델에 속한다 볼 수 있다.
3. Torchvision 사전학습모델
그동안 필자가 인공지능 고급(시각) 강의 복습 - 주요 CNN알고리즘 구현 포스트를 보면
모델을 설계한 후 임의의 이미지 데이터셋을 통해서
Image Classification Task을 수행했었지만
이번에는 Torchvision 라이브러리를 통해 Pre-trained Model을 불러오고자 한다
https://pytorch.org/vision/stable/models.html

해당 사이트의 자료를 요약하자면
Torchvision에서는 다양한 Pre-trained Model을 제공하고 있으며, 이번 포스트의 주제 모델인
DenseNet도 제공하고 있음을 확인할 수 있다.

위 4종의 DenseNet을 불러오고 이를 Pre-trained Model 사용하려면 아래의 코드를 작성하면 된다.
from torchvision import models # 사전학습 모델 다운로드
pr_model_1 = models.densenet121(weights=models.DenseNet121_Weights.IMAGENET1K_V1)
pr_model_2 = models.densenet161(weights=models.DenseNet161_Weights.IMAGENET1K_V1)
pr_model_3 = models.densenet169(weights=models.DenseNet169_Weights.IMAGENET1K_V1)
pr_model_4 = models.densenet201(weights=models.DenseNet201_Weights.IMAGENET1K_V1)원래 사전학습 모델은 인자값으로 pretrained=True를 받았으나, Torchvision라이브러리가 업데이트 되면서 위 코드처럼 weights라는 인자로 값을 받으며, 이때 해당 모델을 훈련시키는데 사용한 데이터셋의 정보를 유추해 볼 수 있다.
모두 ImageNet데이터셋으로 훈련이 이뤄진 것으로 보이며, 아마 이후에 Torchvision라이브러리가 업데이트 되면 좀 더 다양한 데이터셋으로 학습된 가중치 파일을 제공하기 위해 위와 같은 방식으로 Pre-trained Model를 불러오게끔 만들었다.
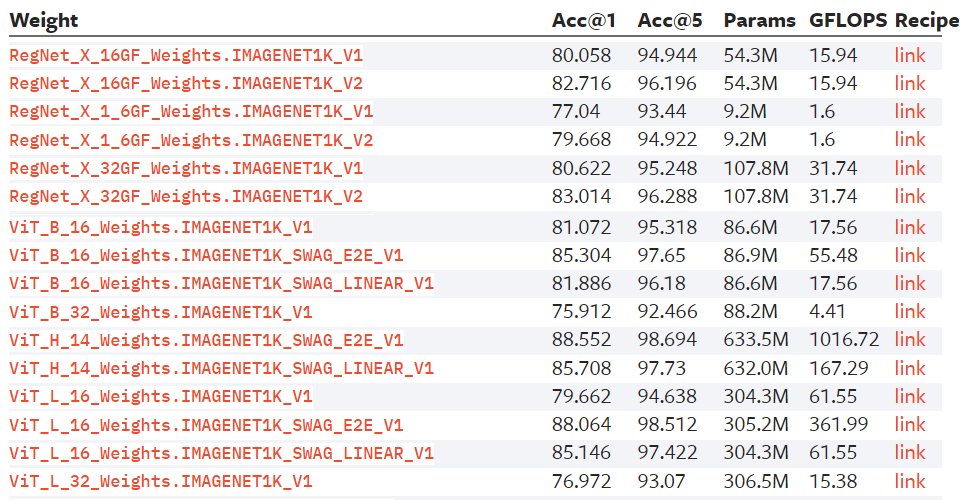
실제로도 Torchvision 홈페이지를 살펴보면 동일한 모델이라도 해당모델을 훈련시키는데 사용된
Huge Dataset이 IMAGENET1K_V1, IMAGENET1K_V2 두가지 버전이 있으며, ViT 모델의 경우에는 더 다양한 데이터셋으로 학습시킨 가중치 파일을 제공함을 알 수 있다.

근데 이쯤 하면 왜 이전포스트랑 다르게
모델을 설계해 놓고서 Torchvision라이브러리의 Pre-trained Model을 불러오는지 맥락에 안맞는 행동을 하는데 의문이 생긴 독자들이 있으리라 생각한다.
그 이유는인공지능 고급(시각) 강의 예습 - 22. (0) Yolo v3 사전 학습 모델 이 포스트에 기재했었던
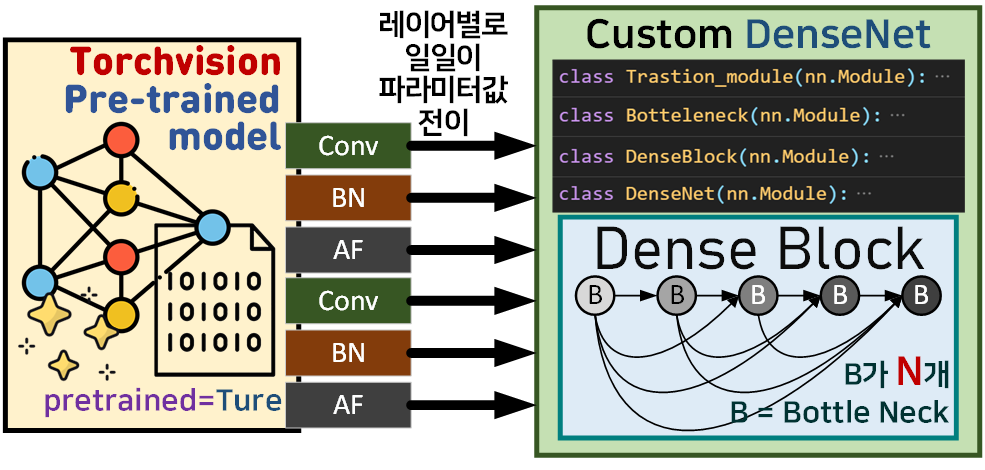
Torchvision라이브러리의 Pre-trained Model모델의 각 레이어 파라미터를
필자가 설계한 custom DenseNet Model에 붙여넣는 작업을 수행하는 것이며, 이를 수행하면 크게 2가지 효과를 기대할 수 있다.
1) 설계한 custom DenseNet Model이 논문에 나와있는 대로 잘 설계함
2) custom DenseNet Model을 빠르게 Pre-trained Model로 전환할 수 있으니 모델의 검증 작업(Downstream Task)도 간편하게 수행할 수 있다.
이 과정을 수행하는 함수는 아래와 같다
# 사전 학습된 모델의 파라미터를 커스텀 모델로 전이
def transfer_weights(cus_model, pr_model):
cus_parms = list(cus_model.named_parameters())
pr_parms = list(pr_model.named_parameters())
for (cus_name, cus_parm), (pr_name, pr_parm) in zip(cus_parms, pr_parms):
if cus_parm.data.shape == pr_parm.data.shape:
cus_parm.data = pr_parm.data.clone()
print(f"{pr_name}의 파라미터를 {cus_name}로 전이")
else:
print(f"{pr_name}의 파라미터를 {cus_name}로 전이 실패")# 모델의 파라미터 전이가 잘 되었는지 사후분석 함수
def compare_model_parm(cus_model, pr_model):
cus_parms = list(cus_model.named_parameters())
pr_parms = list(pr_model.named_parameters())
print(f"커스텀모델 총 층: {len(cus_parms)}층")
print(f"사전학습모델 총 층: {len(pr_parms)}층")
if len(cus_parms) != len(pr_parms):
print("모델의 층이 맞지 않음")
else:
for i, ((cus_name, cus_parm), (pr_name, pr_parm)) in enumerate(zip(cus_parms, pr_parms)):
if torch.equal(cus_parm.data, pr_parm.data):
print(f"{i:3d}번째 층 파라미터 일치")
else:
print(f"{i:3d}번째 층 파라미터 불일치")
print(f"전이되지 않은 층 : {cus_name}, {pr_name}")
print("모든 층의 파라미터 비교 완료")# pretrained_model의 weight정보를 custom model로 전이
transfer_weights(cus_model, pr_model)
# 전이가 잘 되었는지 다시한번 확인
compare_model_parm(cus_model, pr_model)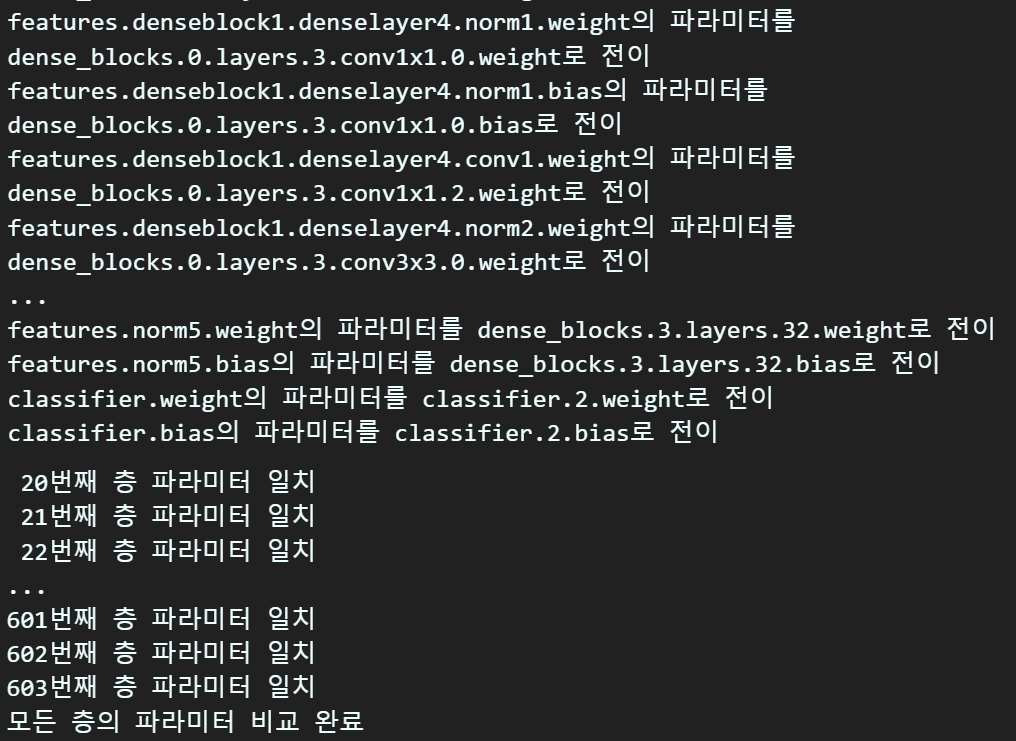 정상적으로 파라미터가 전이됬다면 위 사진처럼 전이 및 일치 항목이 출력된다.
정상적으로 파라미터가 전이됬다면 위 사진처럼 전이 및 일치 항목이 출력된다.
4. 모델검증 - DownstreamTask

이 Downstream Task 작업 수행을 통해 파라미터 전이가 수행된 custom DenseNet Model의 검증작업을 진행하고자 한다.
검증작업에 사용할 Fine-Turning Dataset으로는 아래의 Cats and Dogs 데이터셋을 사용하고자 한다.
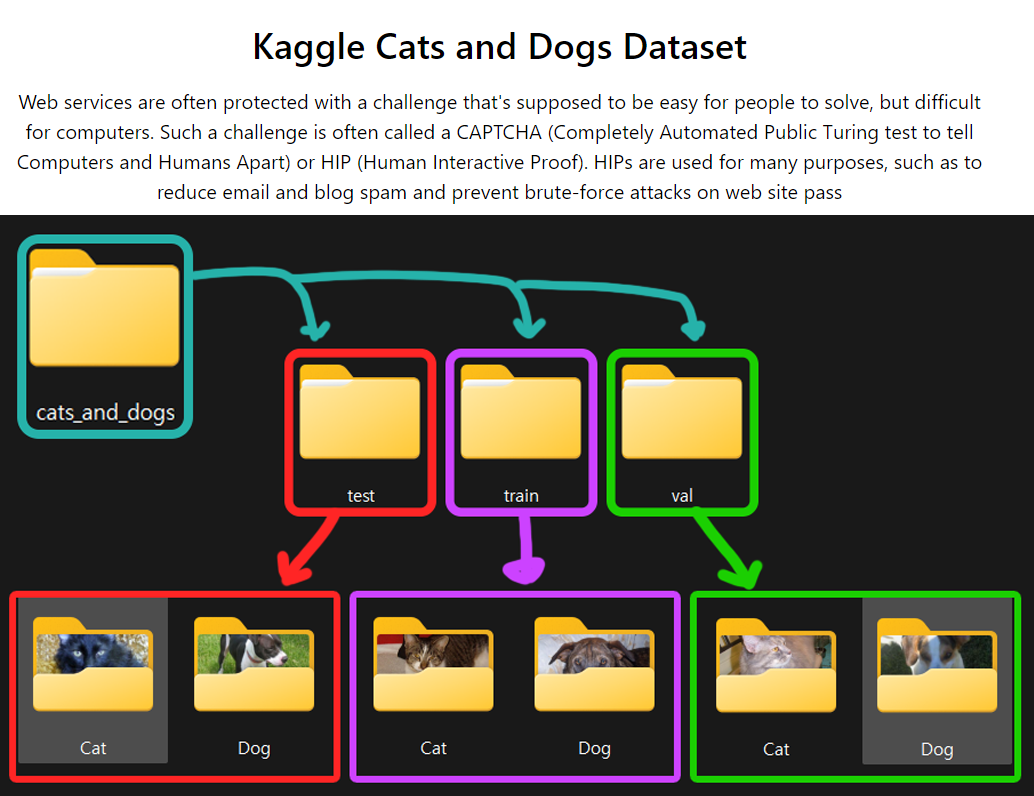
Fine-Turning Dataset 전처리 작업
import os
from torchvision import datasets
#dataset.ImageFolder을 사용한 데이터셋 생성
root = './data/cats_and_dogs'
img_dataset = {} #서브폴더('train', 'val', test')를 딕셔너리 형태로 관리하려고 이렇게 변수를 초기화함
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'train'))
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'val'))from torchvision.transforms import v2
# 데이터 로더 생성하기
CAD_val = [[0.4884, 0.4554, 0.4172], [0.2261, 0.2215, 0.2218]]
transformation = v2.Compose([
v2.Resize((224, 224)), #VGG19 -> [224, 224]
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=CAD_val[0], std=CAD_val[1]) #데이터셋 표준화
])
# 전처리 방법론을 데이터셋에 적용하기
img_dataset['train'].transform = transformation
img_dataset['val'].transform = transformationfrom torch.utils.data import DataLoader
BATCH_SIZE = 128
train_loader = DataLoader(img_dataset['train'],
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(img_dataset['val'],
batch_size=BATCH_SIZE,
shuffle=False)Downstream Task 수행을 위한 레이어 재설계
# 두 모델의 classifier 형상 확인
print(cus_model_1.classifier)
print(pr_model_1.classifier)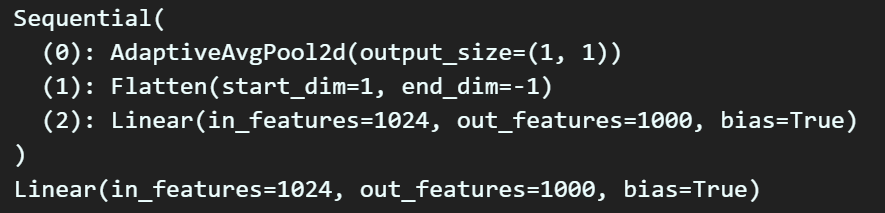
num_features = cus_model_1.classifier[2].in_features
print(num_features)
# 이진분류이기에 출력노드 개수를 1로 설정
cus_model_1.classifier[2] = nn.Linear(num_features, 1)
print(cus_model_1.classifier)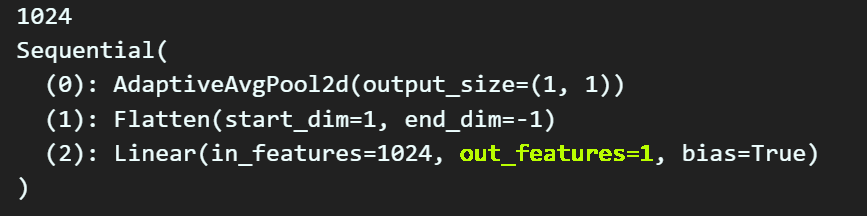
Downstream Task 하이퍼 파라미터
# 모든 레이어의 파라미터를 Freeze
for param in cus_model_1.parameters():
param.requires_grad = False
# 변경한레이어(classifier)만 학습 가능하도록 설정
for param in cus_model_1.classifier.parameters():
param.requires_grad = True# GPU 사용 가능 확인 후 모델을 GPU로 이전
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cus_model = cus_model_1.to(device)# GPU 사용 가능 확인 후 모델을 GPU로 이전
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cus_model_1 = cus_model_1.to(device)import torch.optim as optim
# 손실 함수와 옵티마이저 설정
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(cus_model_1.classifier.parameters(), lr=1e-5, momentum=0.9)훈련/검증용 라이브러리
https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/C_ModelTrainer.py
해당 git 저장소에 접속하면
필자가 model_train, model_evaluate를 간편하게
수행하기 위한 C_ModelTrainer.py파일을 업로드 했다.
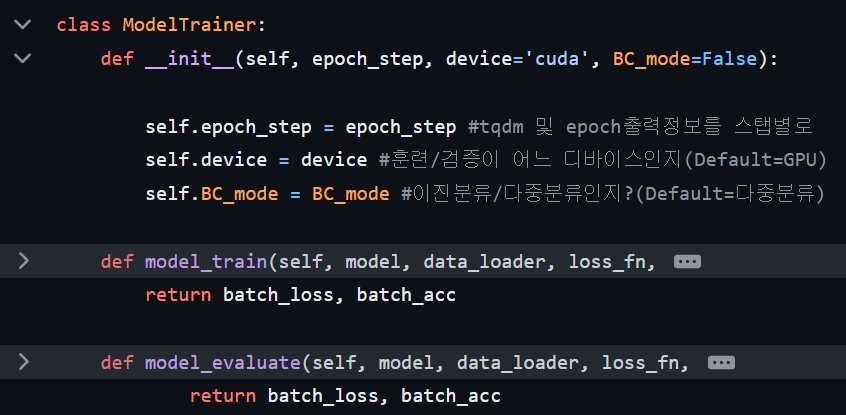
간단하게 설명하자면 모델이 훈련/검증을 수행하는데 있어
Forward / Backward 과정을 수행하고
수행하면서 해당 모델의 Classification Metrics 정보를 특정 epoch 마다 출력하는 클래스라 보면 된다.
이 model_train, model_evaluate 함수가 너무 길어서
라이브러리로 따로 분리를 했다.
사용방법은 간단하다.
# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
epoch_step = 1 #특정 epoch마다 모델의 훈련/검증 정보 출력
# BC_mode = True : 이진분류 문제 풀이 , BC_mode = False : 다중분류 문제 풀이
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type, BC_mode=True)위 코드처럼 trainer 로 객체화를 수행하고
모델을 훈련시킬 때는
trainer.model_train(모델, 훈련데이터로더, 로스함수, 옵티마이저, 스케줄러(선택), epoch)
모델 검증 시에는
trainer.model_evaluate(모델, 검증데이터로더, 로스함수, epoch)를 너어주면 된다.
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss, his_accuracy = [], []
num_epoch = 7
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = trainer.model_train(cus_model_1, train_loader,
criterion, optimizer, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = trainer.model_evaluate(cus_model_1, test_loader,
criterion, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {test_loss:.3f}, " +
f"Acc: {test_acc*100:.2f}%]")
Downstream Task을 통한 모델의 검증 결과는 충분히 의미있는 결과가 나왔음을 확인할 수 있다.
5. nn.ModuleDict
이제 설계한 DenseNet을 자세하게 살펴보도록 하자
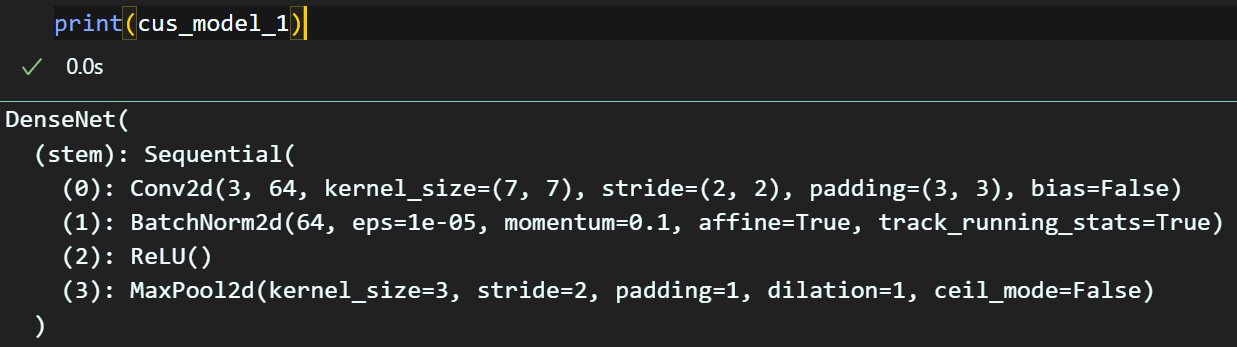
stem 블럭은 나름 깔끔하게 레이어가 nn.Sequential로 묶여있음을 확인이 가능하나
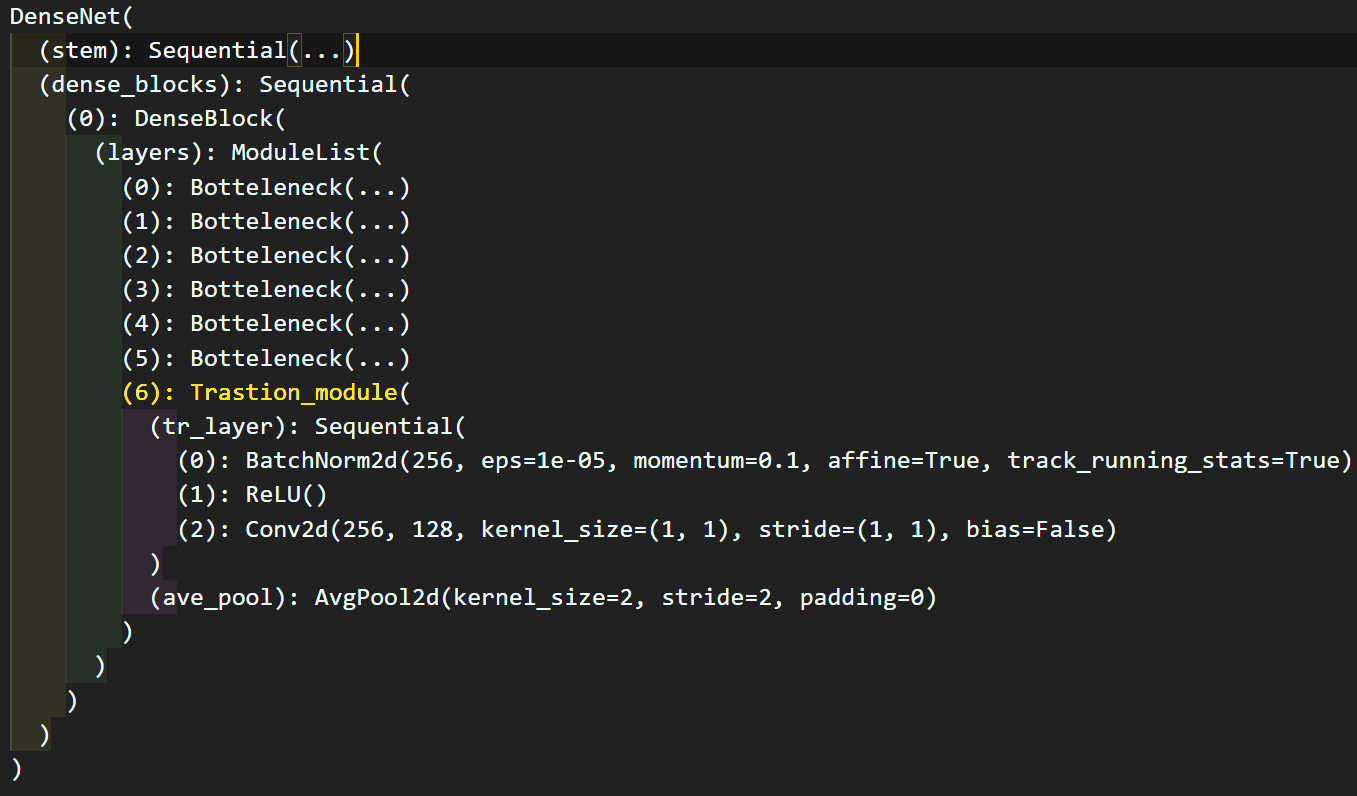 도식도와 맞지 않게
도식도와 맞지 않게 Dense block의 하위 모듈에 Transition_module이 담겨있다.
이 부분이 마음에 들지 않아 DenseNet의 레이어를 좀 더 명확하게 수정을 가하고자 한다.
이 두개의 모듈은 그대로 재사용하고
class DenseBlock(nn.Module):
def __init__(self, num_block, in_ch, growth_rate):
super(DenseBlock, self).__init__()
self.dense_ch = in_ch
self.layers = nn.ModuleList() #리스트 처럼 레이어를 선언
for _ in range(num_block):
layer = Botteleneck(self.dense_ch, growth_rate)
self.layers.append(layer) #선언한 레이어를 리스트에 삽입
self.dense_ch += growth_rate
def forward(self, x):
for layer in self.layers:
x = layer(x)
return xDenseBlock클래스는 좀 더 간편하게 수정했으며,
class DenseNet(nn.Module):
def __init__(self, block_list, growth_rate, n_classes=1000):
super(DenseNet, self).__init__()
assert len(block_list) == 4, "블럭 개수 확인 요"
self.growth_rate = growth_rate
self.stem = nn.Sequential( # DenseNet의 헤드 레이어
nn.Conv2d(in_channels=3, out_channels=2*self.growth_rate,
kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(2*self.growth_rate),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
dense_ch = 2*self.growth_rate
trans_ch_list = []
self.dense_blocks = nn.ModuleDict()
for i, num_block in enumerate(block_list):
block_name = f'dense_block{i+1}'
dense_block = DenseBlock(num_block, dense_ch, self.growth_rate)
self.dense_blocks[block_name] = dense_block
trans_ch_list.append(dense_block.dense_ch)
dense_ch = dense_block.dense_ch // 2
self.trans_blocks = nn.ModuleDict()
for i, trans_ch in enumerate(trans_ch_list[:-1]):
block_name = f'trans_block{i+1}'
self.trans_blocks[block_name] = TransitionModule(trans_ch)
last_module = nn.Sequential(
nn.BatchNorm2d(trans_ch_list[-1]),
nn.ReLU()
)
self.trans_blocks['trans_block4'] = last_module
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(trans_ch_list[-1], n_classes)
)
def forward(self, x):
x = self.stem(x)
for i in range(4):
dense_block = self.dense_blocks[f'dense_block{i+1}']
trans_block = self.trans_blocks[f'trans_block{i+1}']
x = dense_block(x)
x = trans_block(x)
x = self.classifier(x)
return xDenseNet클래스는 나름의 코드개선이 이뤄졌는데
주요하게 변경된 부분이
 위 사진처럼
위 사진처럼 nn.ModuleDict()메서드로
dense_blocks와 trans_blocks를 관리하는 것으로 코드가 개선된 부분이다.
nn.ModuleDict() 메서드는 nn.Sequential(), nn.ModuleList() 처럼 내부에 포함되는 레이어를 리스트 형태로 관리하는 기능을 제공하지만
nn.ModuleDict()는 리스트가 아니라 딕셔너리 형태로 내부의 element를 {key}:{value}로 관리할 수 있는 기능을 제공한다.
위 코드로 개선한 DenseNet를 출력하면 아래와 같다.
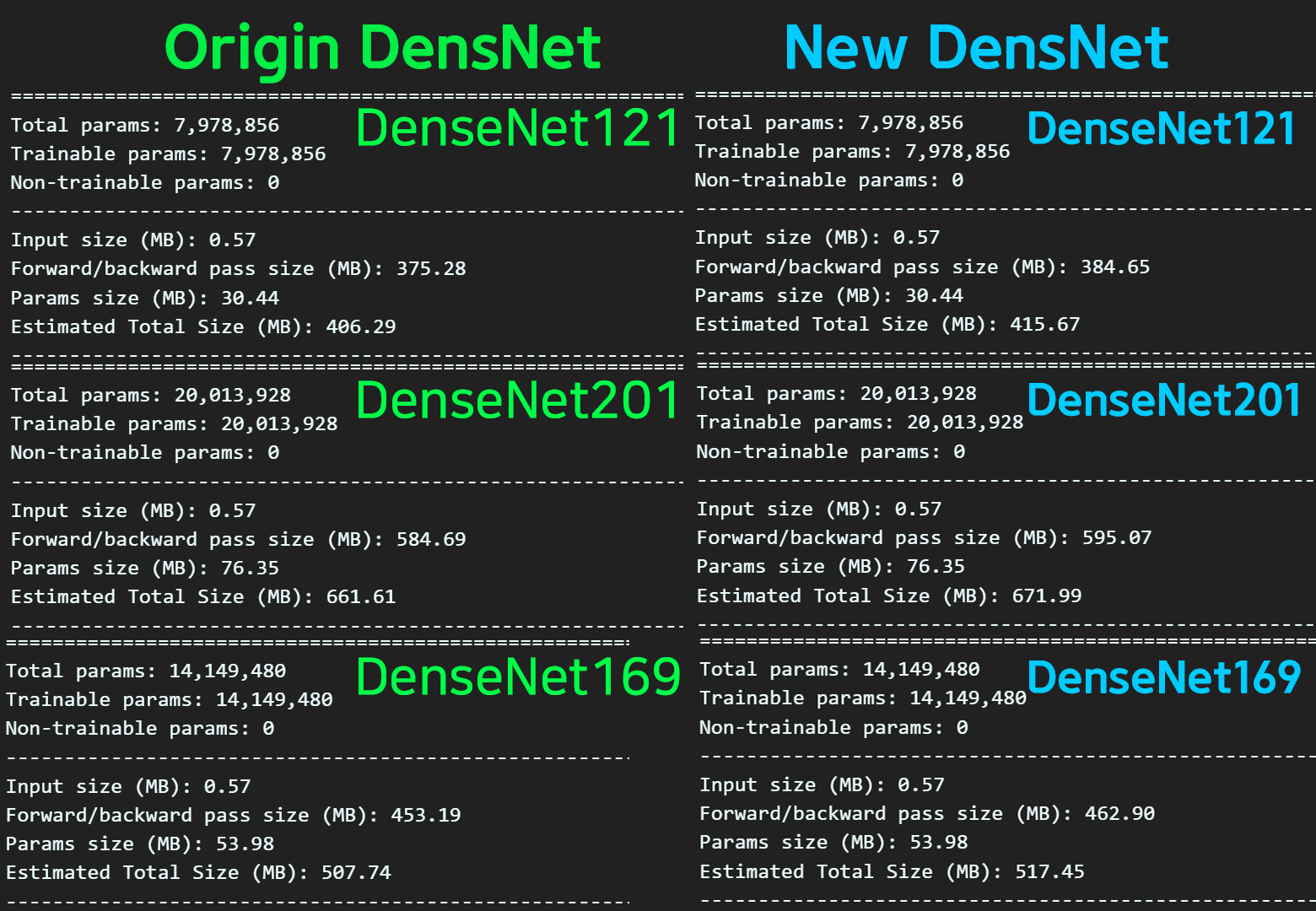 레이어의 구성이랑 파라미터의 개수를살펴보면 기존
레이어의 구성이랑 파라미터의 개수를살펴보면 기존 DenseNet과 코드를 개선한 DenseNet모두 동일한 파리미터, 레이어 구성을 갖고 있음을 확인했다.
그러나 해당 모델을 print하면 좀 다른 레이어 구성이 나오게 되는데
print(cusmodel)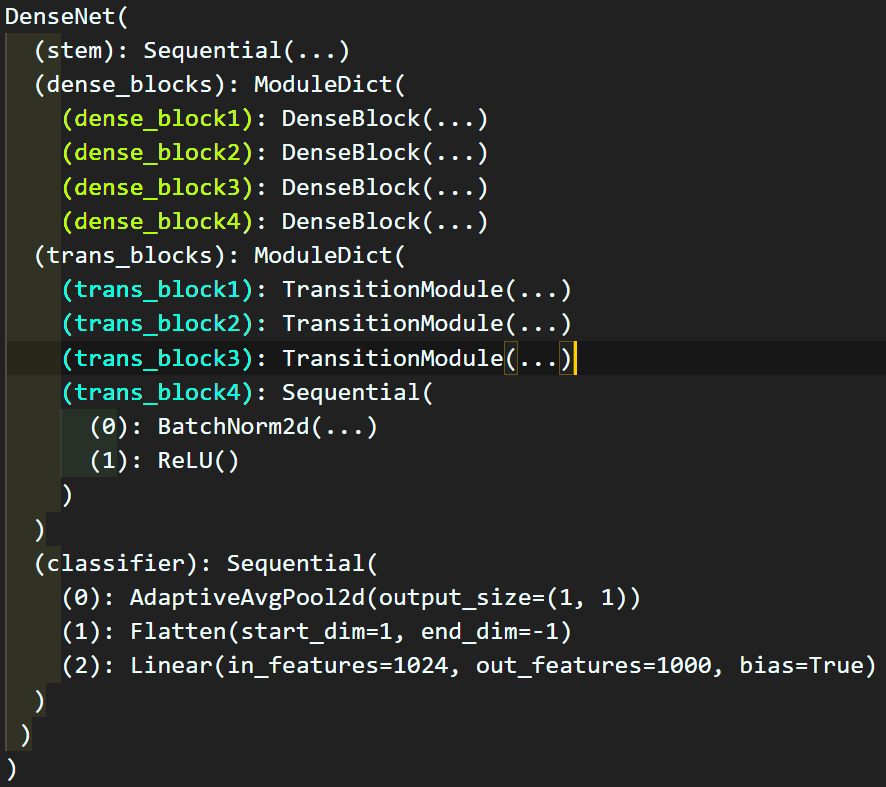
보이는 것처럼 레이어 출력이 레이어가 쌓인 순서가 아니라
nn.ModuleDict()으로 묶인 순서가 먼저 나오게 된다.
즉, 관리는 쉬워지게 코드가 설계되긴 했으나
print시 모듈이 쌓인 순서대로 출력되는 것이 아니어서
이 과정을 원활하게 수행하기 어려운 문제가 발생한다.
이 꼬인 레이어 순번을 찾아서 정리를 하다보니
레이어 별로 파라미터를 전이하는 transfer_weights와 compare_model_parm 함수를 수정할 필요성이 발생했고...
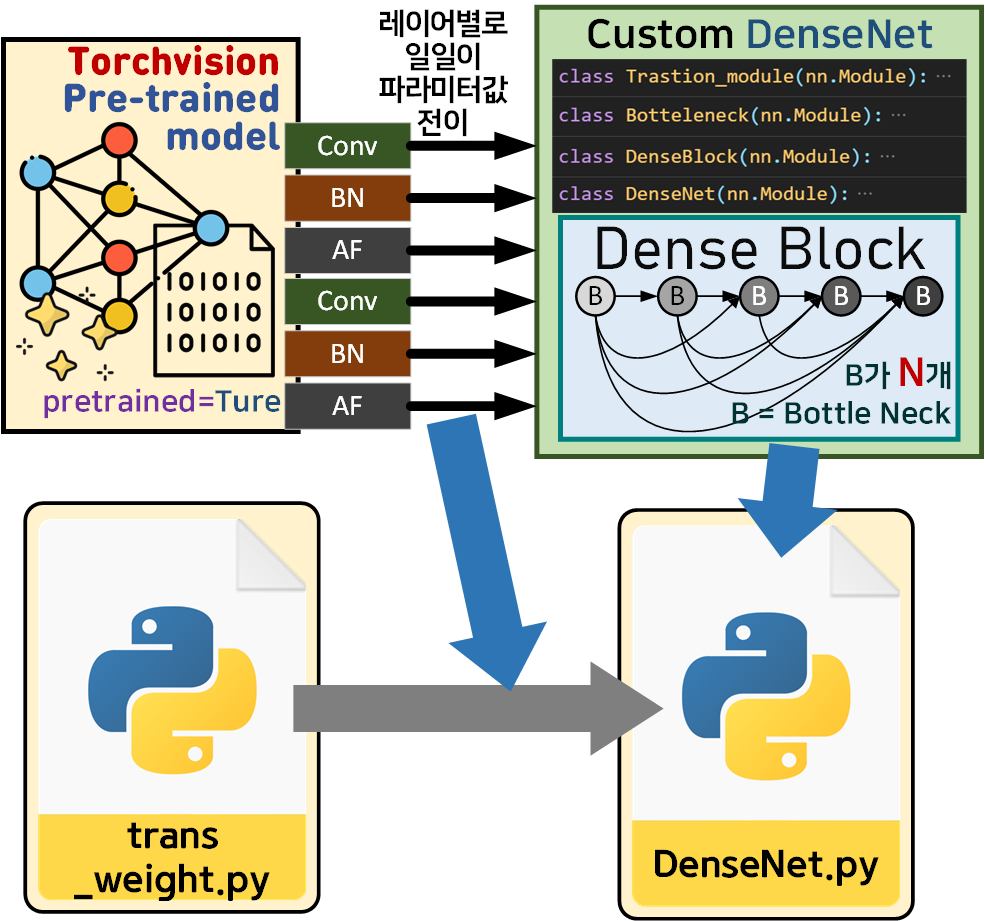 위 사진처럼 2개의
위 사진처럼 2개의 *.py파일을 생성해서 모듈로 만들고 편리하게 관리하기로 결정했다.
코드 만드는 과정은 넘어가자...

이건 너무 길고... 코드도 많이 중복되고... DenseNet에만 그리고 필자가 설계한 custom DenseNet에만 특화되어 있는것이라서 확장성이 부족하다.
이에 대한 코드는
https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/DenseNet.py
https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/trans_weight.py
에 업로드를 하였다.
DenseNet.py
모델설계는 앞서 설명한 내용과 같으며
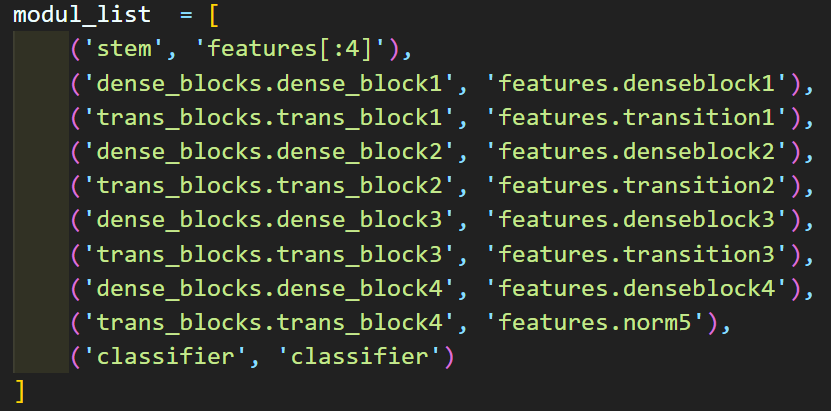
위 사진처럼 Torchvision라이브러리의 Pre-trained Model의 레이어와 필자가 설계한 custom DenseNet을 비교하여 엉킨 레이어 순번을 찾아내
위 사진처럼 레이어 순번에 따른 정보를 리스트로 정리한다.

이를 위 custom DenseNet을 생성하고, Torchvision Pre-trained Model의 파라미터를 전이하는 메서드를 실행시킨다
trans_weight.py
레이어의 파라미터를 전이하는 함수는 trans_parm, 전이가 잘 되었는지 검증하는 함수는 val_parn함수로
전부 묶어서 TransWeight라는 클래스로 새로이 관리를 수행한다.
그래서 사용법?
import torch
from DenseNet import DenseNet, DenseNet121, DenseNet169, DenseNet201, DenseNet161# 모델을 인스턴스화 하고, Pretrained Model로 전환
cusmodel_1 = DenseNet121(pretrained=True)
cusmodel_2 = DenseNet169(pretrained=True)
cusmodel_3 = DenseNet201(pretrained=True)
cusmodel_4 = DenseNet161(pretrained=True)모듈화한 DenseNet.py파일을 import한 뒤
해당 파일이 지원하는 DenseNet121, DenseNet169, DenseNet201, DenseNet161 4개의 파생DenseNet를 불러올 수 있으며,
이때 pretrained=True 옵션을 주면
Torchvision Pre-trained Model의 파라미터 정보를 전이하는 과정이 동작한다
라고 보면 된다.
필자는 그간 작성한 포스트를 본다면
주요한 CNN 모델은 거의 다 다루었다.
이제부터 다루는 CNN은 지금의 DenseNet 포스트처럼
단순하게 모델설계 -> Image Classification 으로 검증
만 수행하는 것이 아니라
더 확장된 기능을 수행하는 Backbone으로 활용하고자 하기에
이를 준비하는 포스트를 작성했다
라고 보면 될 듯 하다.
