
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Fast Neural Style Transfer 논문

Fast Neural Style Transfer의 대표 기법에 해당하는 논문인
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
대해 소개하려 한다.
이 논문은 TransformerNet설계와 지각적 손실(Perceptual loss) 라는 개념을 도입하여 Style Transfer외에도
Denoising(잡음 제거)
Super Resolution(해상도 변환)
Colorization(흑백 사진 컬러와)와 같이
Image trasforamtion Task에 두루두루 사용이 가능한 모델을 만드는 것을 목표로 하고 있다.
1.1 Feed-forward Net 설계
논문에서는 해당 논문이 기여하는 작업 범주로 Image trasforamtion Task 전체를 언급 하고 있으며, 그 중 주요하게 다루는 항목이
Style Transfer(스타일 전이), Super Resolution(해상도 변환) 이다.
 여기서 Super resolution은 위 사진처럼 저 해상도 이미지를 고 해상도로 업스케일링을 하는 이미지 변환 작업을 의미한다.
여기서 Super resolution은 위 사진처럼 저 해상도 이미지를 고 해상도로 업스케일링을 하는 이미지 변환 작업을 의미한다.
필자는 이번 포스트에서는 Super Resolution(해상도 변환)에서는 다루지 않을 예정이기에 Perceptual Losses for Real-Time Style Transfer and Super-Resolution논문의 Style Transfer(스타일 전이)부분만 집중해서 설명하겠다.
아무튼, 이 Style Transfer(스타일 전이)를 수행하는데 논문에서는
Feed-Forwad Net을 설계하여 이를 본 작업에 사용한다
라고 정리를 할 수 있다.
그러면 이 Feed-Forwad Net이 무엇이냐면
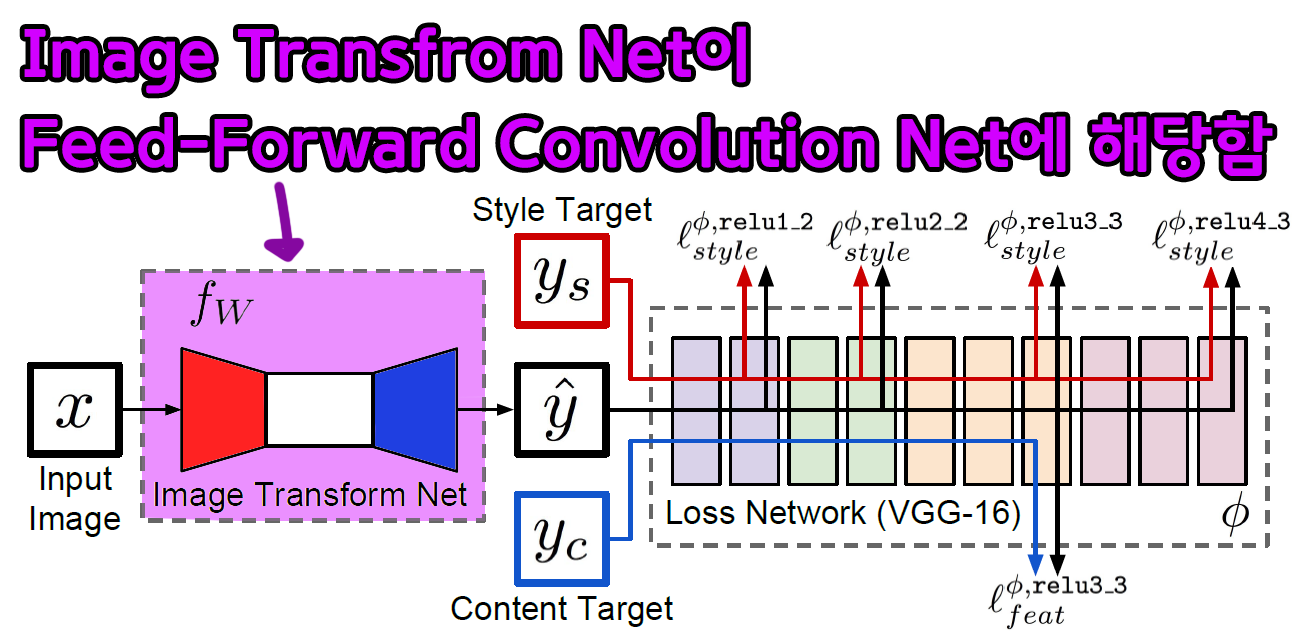
논문의 전체 workflow를 설명하는 부분에서 언급하는
Image Transform Net을 의미한다.
해당 Net의 구조는
Conv Layer부 Upsample Layer 부
이렇게 나눠서 볼 수 있으며, 전체적으로
Feature이 다운샘플링이 진행 후 다시 업샘플링이 진행되고
중요한 점은 원본 이미지()가 입력되어 나오는 출력 은 동일한 크기를 갖는다. 인 것이다.
그러니까 쉽게 설명하면
x.size = torch(1, 3, 224, 224)
y_hat.size = torch(1, 3, 224, 224)위 처럼 같은 크기의 결과물()이 나온다는 것이다.
이렇게 이미지의 공간정보가 동일하고, 여기에 작업의 목표인 Style Transfer(스타일 전이)를 수행하게 설계한 Net이 Image Transform Net 라는 것이다.
이 전체과정이 단방향 Feed-Foward에 속하기에 해당 Net을 다른 이름으로 Feed-Forwad Net이라 부르는 것이다.
1.2 Perceptual Loss
논문에서 또 주요하게 소개하고 있는 지각적 손실(Perceptual Loss)은 해당 논문이 다양한 Image trasforamtion Task를 다루기에 주요하게 다루는 것일 뿐
기본적으로 Style Transfer(스타일 전이)작업에서는 모두 지각적 손실(Perceptual Loss)을 기반으로 최적화를 수행한다.
이것이 무슨 말이냐면
이전의 Super-Resolution을 수행한 논문들에서는
최적화 기법을 수행하기 위한 Loss를 정의할 때
Pixel-wise Loss(픽셀 기반 손실)로 Loss를 정의했었다
물론 그에 따른 단점이 발생했고, 이를 개선하는데 지각적 손실(Perceptual Loss)로 정의된 최적화를 수행한다는 것이다.
그럼 이전 포스트 인공지능 고급(시각) 강의 복습 - 24. Neural Style Transfer (4)에서 지각적 손실(Perceptual Loss)은 무엇인가?
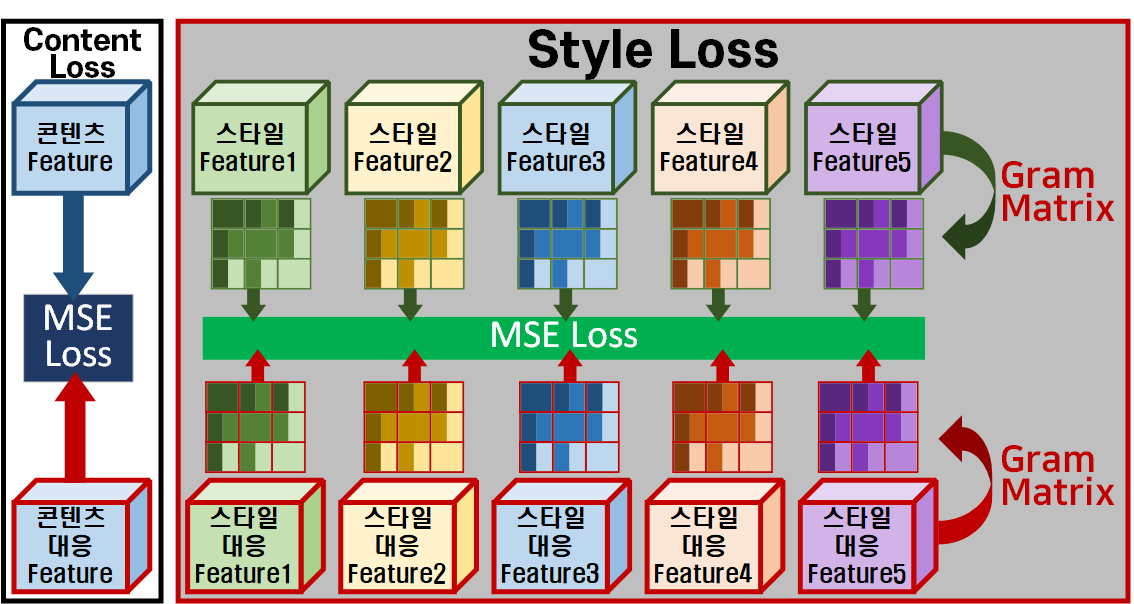 이게 지각적 손실을 의미한다.
이게 지각적 손실을 의미한다.
이미지를 Net에 통과시켜서 그것에 대한 특징(Feature)로 손실을 정의한 것이 지각적 손실(Perceptual Loss)이다.
갑자기 어려운 단어가 튀어나와서 살짝 헤멨었다...
2. Fast Style Transfer Workflow
Perceptual Losses for Real-Time Style Transfer and Super-Resolution 논문에서 제시하는 전체적인 Fast Style Transfer의 Workflow를 표현하면 아래와 같다.
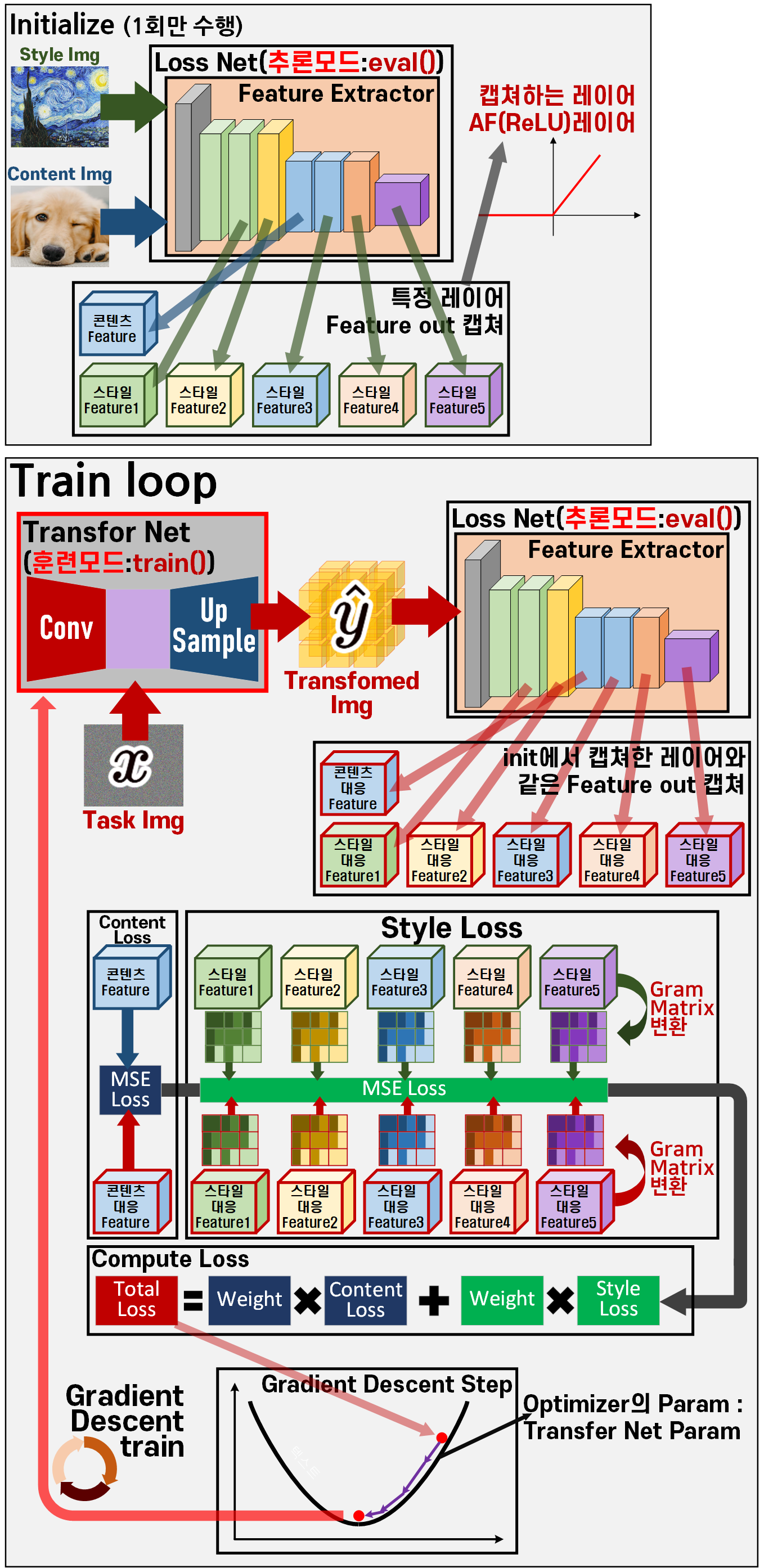
전체 workflow는 인공지능 고급(시각) 강의 복습 - 24. Neural Style Transfer (4)에서 Image Transform Net가 추가된 차이점만 존재해서
오히려 성능이 하락하는건가?
라는 생각이 들 수 있다
하지만 이전포스트의 Main Loop가 Train Loop로 이름이 변경된 것에 집중해야 한다.
이 말은 훈련이 끝난 다음에는
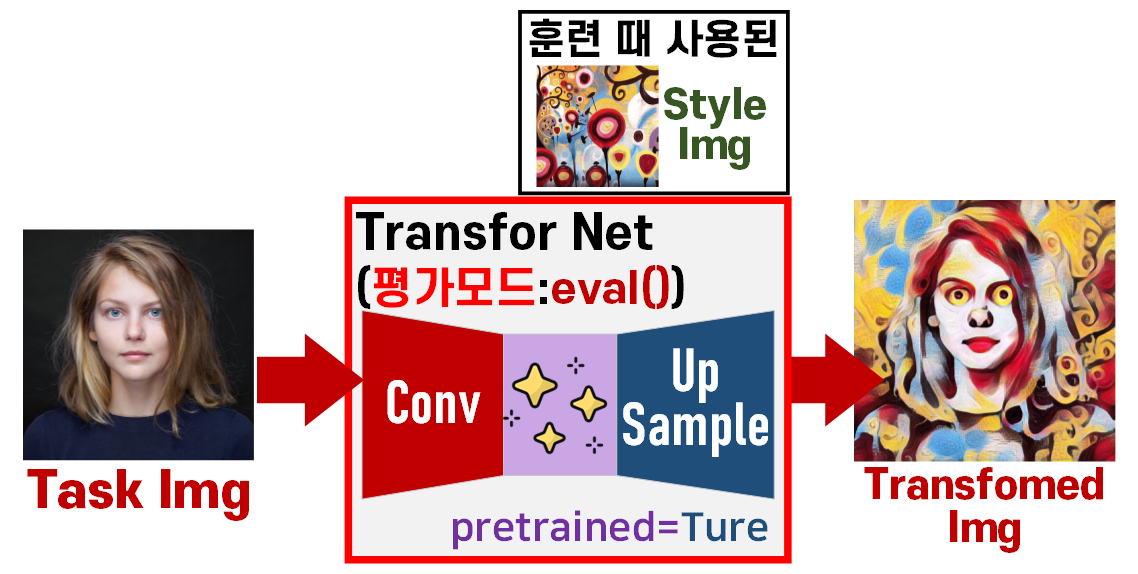
위 전체 workflow의 대부분의 과정을 드러내고 위 사진처럼 Image Transform Net딱 하나만 추론모드로 변경해서 사용하면 끝나게 된다.
2.1 Image Transform Net 다운로드
https://github.com/dxyang/StyleTransfer/tree/master 깃허브에 접속하면
적절하게 encoder decoder 구조로 되어있는Image Transform Net를 다운로드 할 수 있다.
https://github.com/dxyang/StyleTransfer/blob/master/network.py
해당 Net에 대한 구조 설명은 스킵하고 넘어도록 하겠다
2.2 Fast_NST 훈련코드
인공지능 고급(시각) 강의 복습 - 24. Neural Style Transfer (4)에서 살짝 변경된 부분이 있으니 해당 부분만 하이라이트로 설명하고 코드 전문을 첨부하도록 하겠다.
1) 데이터 전처리
import torch
import torch.nn as nn
from torchvision.transforms import v2
from PIL import Image
import numpy as npfrom img_utils import * #필자가 따로 만든 데이터 전처리 라이브러리
content_img = './Stormveil Castle.png'
style_img = './Great Wave of Kanagawa.png'
tensor_size = 1024 #이미지를 텐서 자료형으로 변환 시 크기 통일을 위해 변수 설정
content_tensor, img_shape = preprocess_img(content_img, tensor_size, imgNet_val, device)
style_tensor, _ = preprocess_img(style_img, tensor_size, imgNet_val, device)
# 콘텐츠 이미지의 사본으로 작업 수행
task_tensor = content_tensor.clone()2) 사전학습된 Loss Net 리 모델링
from torchvision import models
# 뉴럴 스타일 트랜스퍼에 사용할 백본 모델 불러오기 # torchvision에 있는 VGG19모델을 사용
pr_model = models.vgg19(weights=models.VGG19_Weights.IMAGENET1K_V1).to(device)class ReModelVGG19(nn.Module): #기존vgg19모델을 인덱싱하기 편하게 블럭화
def __init__(self, origin_model):
super(ReModelVGG19, self).__init__()
origin_modeul = origin_model.features
self.module = nn.ModuleDict()
block = []
block_idx = 0
for layer in origin_modeul.children():
if isinstance(layer, nn.Conv2d) and block: #블럭이 비어있지 않은 경우
# 새로운 conv2d가 나오면 기존 블록을 저장하고 초기화
block_name = f"conv_{block_idx}_block"
self.module[block_name] = nn.Sequential(*block)
#블록 리스트 초기화
block = []
block_idx += 1
if isinstance(layer, nn.ReLU):
#in-place기능을 off -> 이렇게 해야 연산오류 발생 안함
layer = nn.ReLU(inplace=False)
#레이어를 계속 블럭 리스트에 넣기
block.append(layer)
if block: #가장 마지막 블록을 추가
block_name = f"conv_{block_idx}_block"
self.module[block_name] = nn.Sequential(*block)
def forward(self, x):
for block in self.module.values():
x = block(x)
return xbackbone = ReModelVGG19(pr_model)
#backbone는 평가 모드로 설정
backbone.eval()변경된 부분
#캡쳐할 블럭은 콘텐츠, 스타일별로 다르니 이걸 한번에 딕셔너리로 관리하자
block_setting = {'content' : ['conv_3_block'],
'style' : ['conv_1_block',
'conv_3_block',
'conv_7_block',
'conv_11_block',
'conv_15_block', ]}block_setting에서 캡쳐 대상 블럭의 위치가 변경되었다.
특히 Style쪽 캡쳐 부분의 블럭 위치가 대대적으로 개편되었는데
캡쳐하는 5개 블럭의 공통점은
 위 사진에서 볼 수 있듯이 모두
위 사진에서 볼 수 있듯이 모두 MaxPool이 포함된 블럭이다.
따라서 Feature의 size(H,W)가 축소되기 바로 직전 블럭의 레이어 Feature out를 캡쳐한다 볼 수 있으며,
캡쳐 블럭의 순번을 따져보면 VGG19의 전 영역
Feature 정보를 다 사용한다
이렇게 볼 수 있다.
변경된 부분
class LossNet(nn.Module): #백본 모델에서 활성화 레이어를 캡쳐하는 Net를 따로설계
def __init__(self, backbone, block_setting):
super(LossNet, self).__init__()
self.backbone = backbone #백본 모델의 인스턴스화
#block_setting이 복잡한 딕셔너리 형태이니 여기서 필요 정보만 추출하는 함수 실행
self.block_setting = self.extract_list(block_setting)
self.outputs = {} #캡쳐할 feature out 저장
def hook_fn(module, input, output, name):
#캡쳐한 블럭 이름이 outputs 딕셔너리에 없을 경우
#블럭의 출력feature이랑 block이름을 key,value로 묶어서 outputs에 저장
if name not in self.outputs:
self.outputs[name] = output
for name, module in backbone.named_modules():
if any(block in name for block in self.block_setting):
#여기까지 수행하면 block_setting에 기재된 이름이 포함된 레이어+블럭이 추출됨
#논문에서 nn.ReLU를 캡쳐하니 Conv2d에서 nn.ReLU로 변경
#그리고 ReLU를 통과한 Feature를 사용하는게 성능이 좀 더 좋았음
if isinstance(module, nn.ReLU): #해당 레이어가 conv2d인지 확인
self._register_hook(name, module, hook_fn)
#위 _register_hook는 특정 블럭이 아니라 특정 블럭 내 레이어로 캡쳐해야한다
#블럭으로 캡쳐할 시 향후 outfeature로 loss계산 후 backward 수행할 때
#블럭 내 레이어까지 순회하게 되면서 backward가 2회 이상 반복되는 오류가 발생함
# 콘텐츠, 스타일 항목별로 캡쳐하는 모든 유니크 블록명을 추출하는 함수
def extract_list(self, block_setting):
value = list()
for k, v in block_setting.items():
for element in v:
value.append(element)
return sorted(set(value))
def _register_hook(self, name, module, hook_fn):
def hook(module, input, output): #여기서 name = 캡쳐한 모듈(블럭)의 이름
return hook_fn(module, input, output, name)
module.register_forward_hook(hook)
def forward(self, x):
self.outputs = {} # 매번 호출될 때마다 초기화
#init 에서 한번 초기화 했다고 forward에서 outputs를 초기화 안하면 낭패가 발생함
_ = self.backbone(x)
return self.outputs
#해당 클래스가 nn.Module를 상속하니 parameters메서드 사용가능
@property #이 데코레이터를 쓰면 클래스 함수를 클래스 변수처럼 쓰는게 가능
def device(self):
return next(self.parameters()).device위 캡쳐를 수행하는 LossNet의 주요 변경점은

캡쳐 레이어가 nn.Conv2d에서 nn.ReLU로 변경된 부분이다.
이전 포스트 인공지능 고급(시각) 강의 복습 - 24. Neural Style Transfer (4)의 메인 논문인
Image style transfer using convolutional neural network에서도
캡쳐하는 레이어는 nn.ReLU였으나
https://tutorials.pytorch.kr/advanced/neural_style_tutorial.html
파이토치 스타일 전이 튜토리얼을 보면

캡쳐 레이어가 nn.Conv2d로 되어 있다.
이것은 튜토리얼이 잘못된 부분이며, 실험결과
nn.Conv2d보다는 활성화 계층인 nn.ReLU를 통과한 Feature out을 사용하는게 더 스타일 전이가 잘 된다.
nn.ReLU의 Feature out를 캡쳐한 버전

기존 nn.Conv2D의 Feature out를 캡쳐한 버전

솔직히 뭐가 더 낫냐는 주관이긴 하지만
그 이후 논문들에서도 nn.ReLU의 Feature out를 사용하기에
논문의 규정을 준수하도록 하자
3) Transformer Net 불러오기
#트랜스포머 net 라이브러리 불러오기
from network import ImageTransformNet
tr_net = ImageTransformNet()여기는 나중에 설명하겠다.
4) Perceptual Loss함수 정의
import torch.nn.functional as F
# 항목별로 lossfn 설계
class TransferLoss(nn.Module):
def __init__(self, block_setting):
super(TransferLoss, self).__init__()
self.block_setting = block_setting
self.item_list = list(block_setting.keys())
# 그람 행렬(Gram matrix) 함수 정의
def gram_matrix(self, data_tensor):
bs, c, h, w = data_tensor.size() #여기서 bs는 1이다.
#Feature Map에서 채널별로 분리 (Features)
#그 다음 이 features는 3차원이니 H*W를 곱해서 2D로 차원축소
features = data_tensor.view(bs*c, h*w)
#모든 Features별로 내적을 땡겨버리자 -> 모든 instance pair값 계산
#torch.mm은 행렬곱 메서드임
G = torch.mm(features, features.t())
#gram matrix의 값을 정규화 수행
return G.div(bs*c*h*w)
#nn.Module를 상속받아서 forward함수를 선언하면 메서드함수명 안써도 됨
def forward(self, target_feature, pred_feature, item):
if item not in self.item_list:
raise Exception("item 종류 잘못 입력")
#계산할 target, pred feature를 리스트로 추출
target = [v for k, v in target_feature.items()
if any(block in k for block in self.block_setting[item])]
pred = [v for k, v in pred_feature.items()
if any(block in k for block in self.block_setting[item])]
device = pred[0].device
loss = torch.zeros(1, device=device)
# 콘텐츠 로스는 1개의 output_feature에 대해서 loss계산
if item == 'content':
loss += F.mse_loss(target[0], pred[0])
# 스타일 로스는 여러개의 output_feature를 그람 매트릭스 해서 Loss계산
elif item == 'style':
for e_target, e_pred in zip(target, pred):
G_target = self.gram_matrix(e_target)
G_pred = self.gram_matrix(e_pred)
loss += F.mse_loss(G_target, G_pred)
return loss5) Style Transfer Net 훈련 시키기
from tqdm import tqdm
class StyleTransferNetTrain: #transform_net을 훈련시키기 위한 클래스
def __init__(self, transform_net, loss_net,
loss_fn, block_setting,
learning_rate = 0.001,
weight_c = 1, weight_s = 1e4):
#Loss_Net는 사전학습된 모델(ex:vgg19)이며, 항상 평가모드
self.loss_net = loss_net.eval()
#Image Transform Net을 훈련시키는게 본 코드의 목적
self.tr_net = transform_net
self.block_setting = block_setting #캡쳐할 block 정보가 담긴 딕셔너리
self.item_list = list(block_setting.keys())
self.loss_fn = loss_fn #항목별 로스 함수를 계산하는 클래스
self.weight = [weight_c, weight_s] #loss항목별 추가 가중치
self.lr = learning_rate #Transform Net을 훈련시키는데 사용되는 러닝레이트
self.optimizer_fn = None #옵티마이저는 set_optimizer 함수로 초기화한다.
#초기화 메서드 -> 1회만 수행한다.
def initialize(self, content_tensor, style_tensor):
#loss Net에 콘텐츠, 스타일 이미지 입력 후 feature out를 캡쳐
with torch.no_grad():
self.content_feature = self.loss_net(content_tensor)
self.style_feature = self.loss_net(style_tensor)
#초기화는 content, style를 최초로 한번 입력하여 그 결과(feature)를 저장해둔다.
#옵티마이저는 Tr모델의 레이어 파라미터이니 이니셜라이즈로 넘어가서 선언
self.optimizer_fn = self.set_optimizer()
def compute_loss(self, outputs): #작업이미지가 모델을 통과한 결과물로 로스 계산
content_loss = self.loss_fn(self.content_feature, outputs, self.item_list[0])
style_loss = self.loss_fn(self.style_feature, outputs, self.item_list[1])
#콘텐츠 로스랑, 스타일로스에 사전에 정의한 로스 가중치를 곱해서 합산 -> 토탈 로스 계산
total_loss = content_loss * self.weight[0] + style_loss * self.weight[1]
loss_component = [content_loss.item(), style_loss.item()]
return total_loss, loss_component
def set_optimizer(self): #코드 구성을 비슷하게 하려고 궂이 이 함수를 살린다.
params = self.tr_net.parameters()
return torch.optim.Adam(params, lr=self.lr)
#딥드림 함수 설계 방법론을 바탕으로 Gradient Descent Step 함수 설계
def gradient_descent_step(self, img_tensor):
self.tr_net.train() #트랜스포머 Net을 훈련모드로 설정
self.optimizer_fn.zero_grad() # 옵티마이저의 기울기를 0으로 초기화
#tr_net에 img_tensor입력하여 tr_feature를 생성
tr_feature = self.tr_net(img_tensor)
#그리고 tr_feature를 loss_net에 입력하여 task_pred를 만든다.
task_pred = self.loss_net(tr_feature)
#task_pred(이게 이전에는 outputs)로 loss계산
total_loss, loss_component= self.compute_loss(task_pred)
#closer함수 없애고 loss 중간결과값이랑 tot_loss를 반환하려고 이케 씀
loss_component.append(total_loss.item())
total_loss.backward() #설계한 loss를 바탕으로 역전파 수행
self.optimizer_fn.step() #경사하강법을 옵티마이저 step으로 수행
return img_tensor, loss_component
def gradient_descent_train(self, task_tensor,
content_tensor, style_tensor,
epoch = 40000, epoch_step = 1000):
self.initialize(content_tensor, style_tensor)
pbar = tqdm(range(epoch)) #tqdm라이브러리로 훈련 진행상황 체크
his_metrics = list() #Loss, grad값을 향후 분석그래프 그리려고 저장
for step in pbar: #epoch 반복 횟수만큼 훈련 수행
task_tensor, loss = self.gradient_descent_step(task_tensor)
#매 스탭마다 loss, grad를 저장
his_metrics.append(loss)
#tqdm에 추가 정보 표시하기
desc = (f"훈련중 {step+1:05d}, "
f"[콘텐츠:{loss[0]*self.weight[0]:.3f}, "
f"스타일:{loss[1]*self.weight[1]:.3f}, "
f"Total:{loss[2]*self.weight[1]:.1f}]")
pbar.set_description(desc)
if (step+1) % epoch_step == 0: #훈련 진행상황 체크
#진행상황 체크는 tr_net를 훈련모드로 바꾼 뒤 산출물을 만들어내는 방식
self.tr_net.eval() #모델을 훈련모드로
#그래디언트 업데이트 방지
with torch.no_grad():
tr_feature = self.tr_net(task_tensor)
res_img = deprocess_img(tr_feature, img_shape, imgNet_val)
name = f'combine_{step+1}'
res_img.save(f"{name}.jpg")
return his_metrics
주요 변경사항이라면
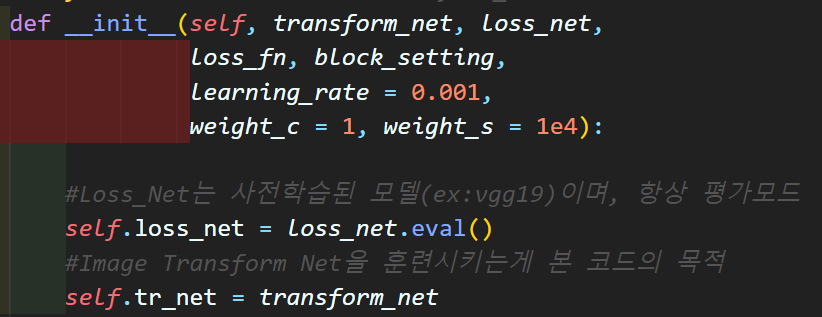
생성자 메서드에서 Loss Net, Tr Net 두개가 인스턴스화 진행되고

옵티마이저는 Tr Net의 레이어 파라미터로 등록
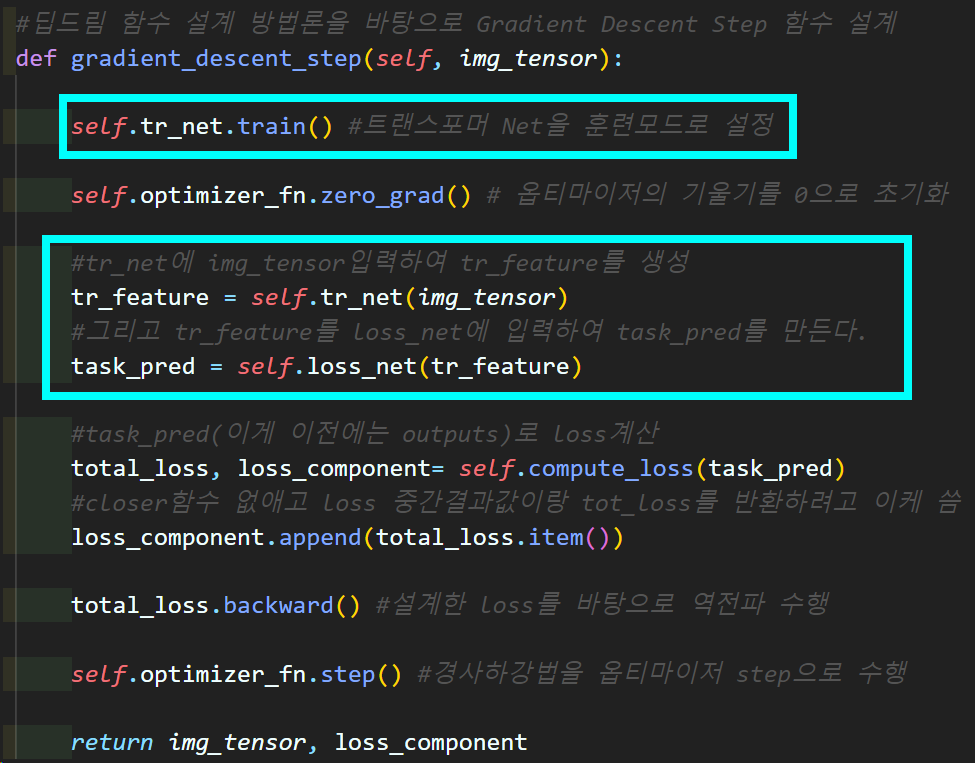
Tr net이 훈련모드로 설정됨괴 더불어
전사과정이 따지고본다면 Net를 두번 통과하게 바뀐 점
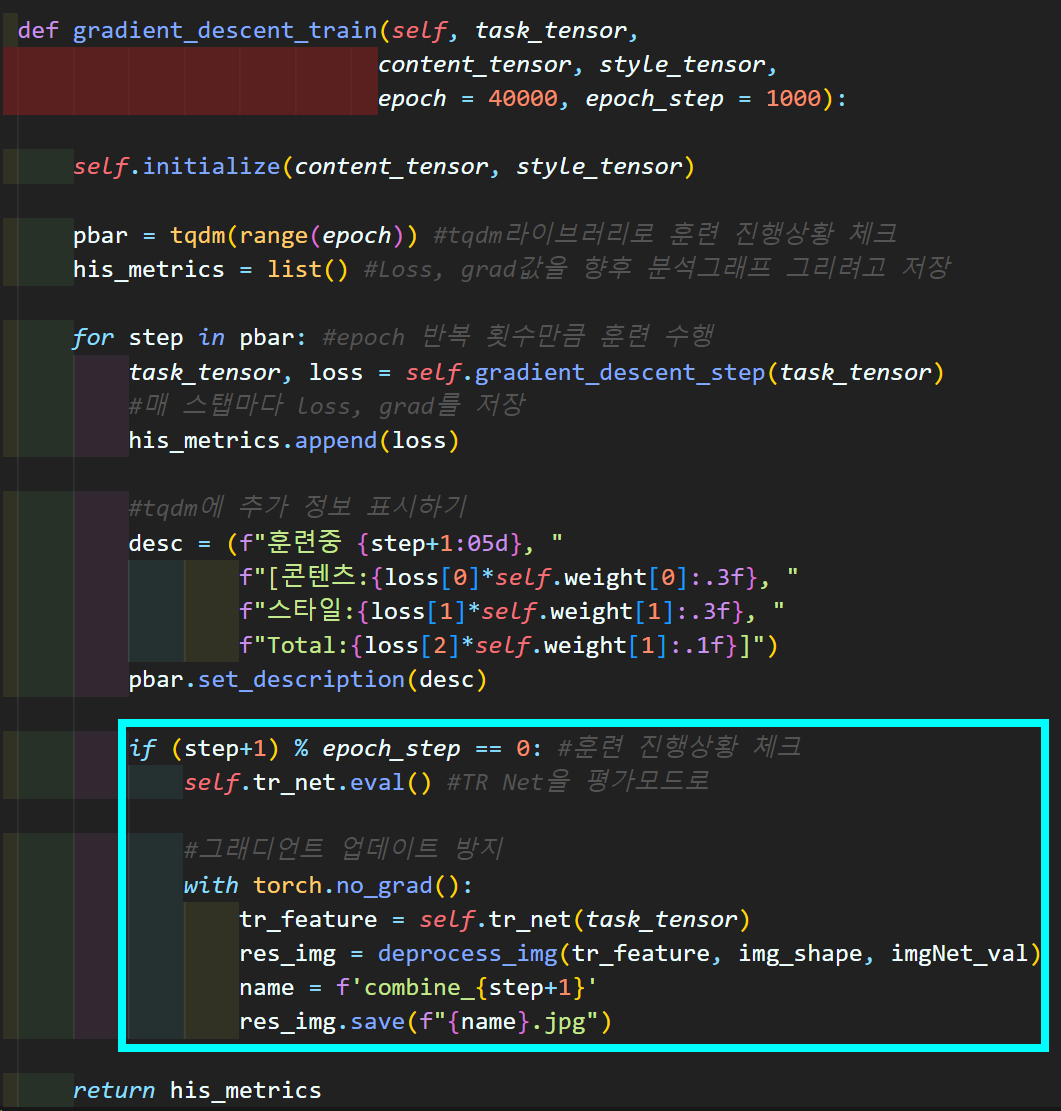
마지막으로 훈련이 진행되는 중간중간 산출물 출력은
TR net의 평가모드 전환 후 수행된다는 점이다.
#훈련시킬 네트워크
tr_net = ImageTransformNet().to(device)
#로스함수 계산을 위한 네트워크(VGG19)
loss_net = LossNet(backbone, block_setting)
loss_fn = TransferLoss(block_setting)
tr_net_train = StyleTransferNetTrain(tr_net, loss_net, loss_fn, block_setting,
weight_s=1e5)his_metrics = tr_net_train.gradient_descent_train(task_tensor, content_tensor, style_tensor,
epoch = 40000, epoch_step = 1000)import matplotlib.pyplot as plt
def plot_metrics(his_metrics):
content_loss = [metric[0] for metric in his_metrics]
style_loss = [metric[1] for metric in his_metrics]
total_loss = [metric[2] for metric in his_metrics]
# 스텝 수
steps = range(len(his_metrics))
# 그래프 그리기
plt.figure(figsize=(14, 7))
plt.subplot(1, 2, 1)
plt.plot(steps, content_loss, label='Content Loss', color='orange')
plt.title('Content Loss over Steps')
plt.xlabel('Steps')
plt.ylabel('Content Loss')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(steps, style_loss, label='Style Loss', color='green')
plt.title('Style Loss over Steps')
plt.xlabel('Steps')
plt.ylabel('Style Loss')
plt.grid(True)
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 6))
plt.plot(steps, total_loss, label='Total Loss')
plt.title('Total Loss over Steps')
plt.xlabel('Steps')
plt.ylabel('Total Loss')
plt.grid(True)
plt.tight_layout()
plt.show()plot_metrics(his_metrics)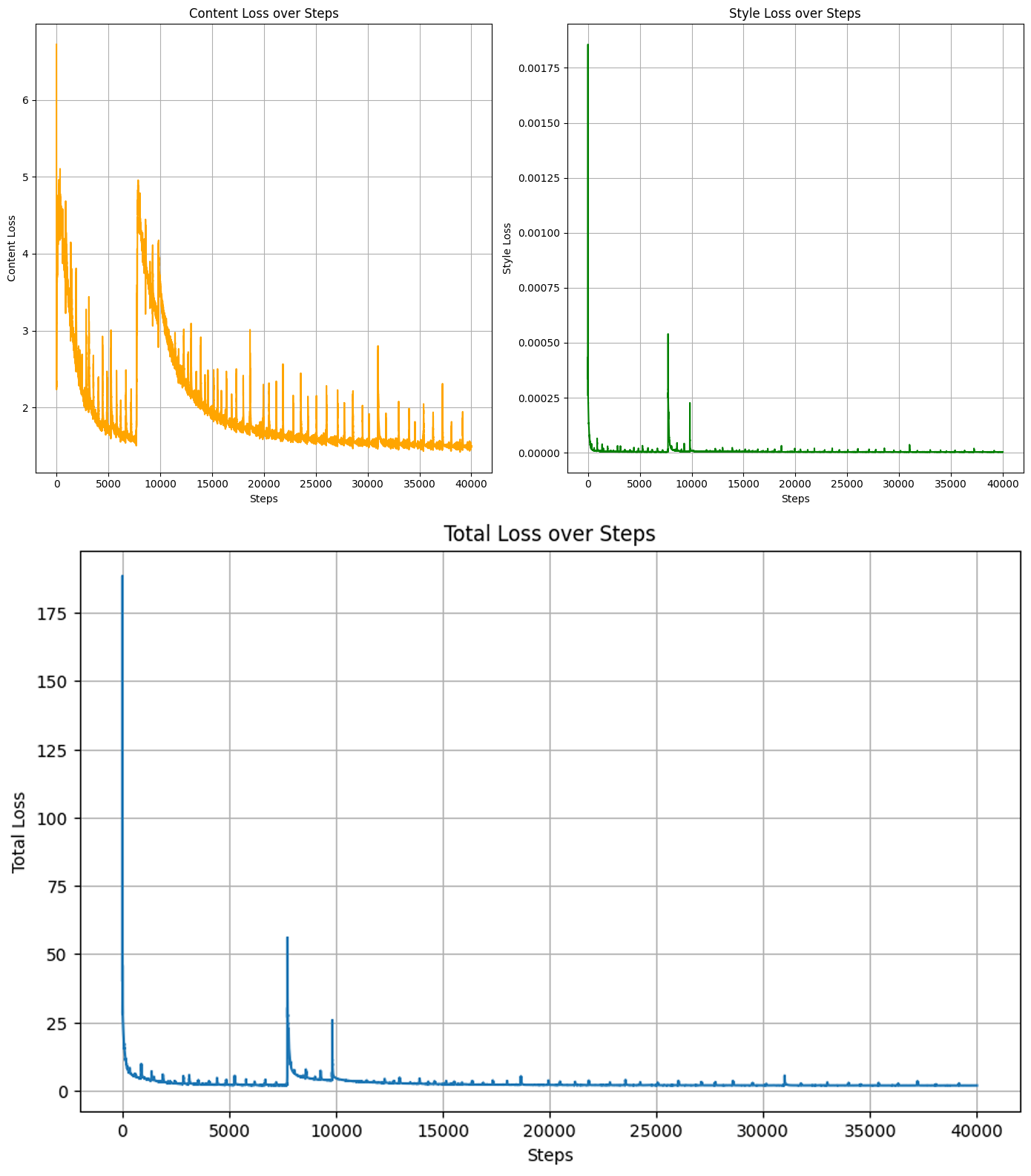
훈련이 진행되면서 Loss 항목별 변동상황은 체크를 해주고


훈련 과정이 수행되면서 이미지가 어떻게 학습되는지 그 양상도 확인해보자
참고로 훈련시킬때는 GPU온도를 좀 생각할 필요성이 있다.
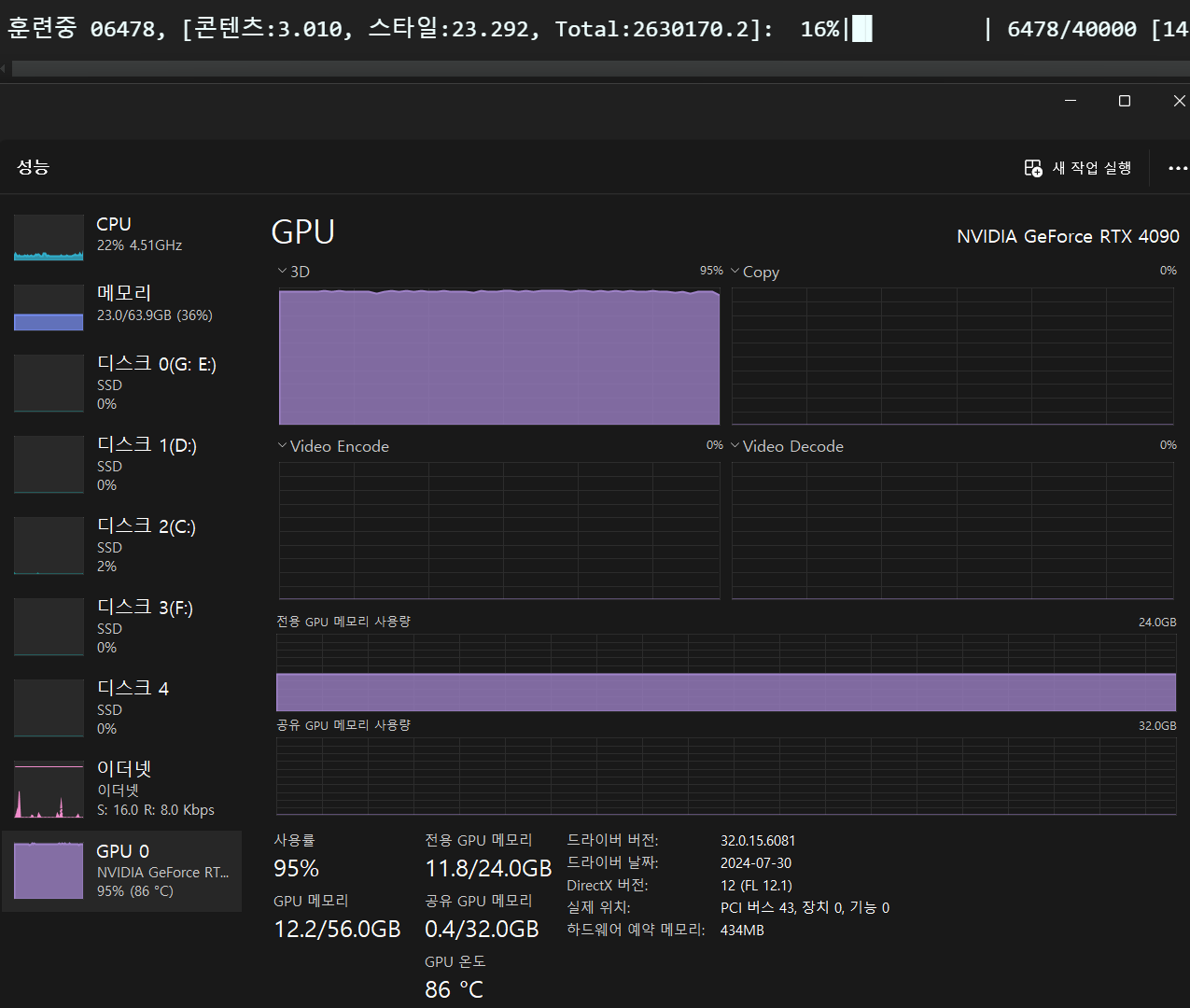 VRAM소비야 어차피 1개의 이미지만 쓰는거니까 뭐.. 용량부하는 걱정 안해도 되긴하는데
VRAM소비야 어차피 1개의 이미지만 쓰는거니까 뭐.. 용량부하는 걱정 안해도 되긴하는데
3D 연산 성능을 미친듯이 필요로 한다.
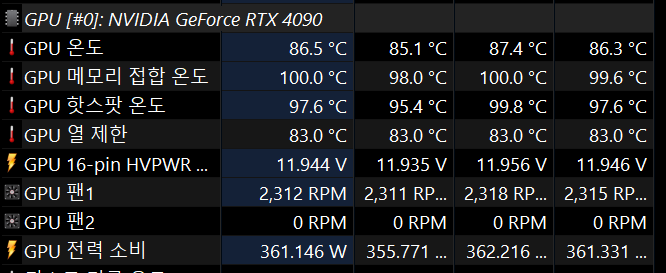 음.. 왠만한 그래픽카드 벤치마크 프로그램도 이렇게 GPU를 혹사시키지는 않는데...
음.. 왠만한 그래픽카드 벤치마크 프로그램도 이렇게 GPU를 혹사시키지는 않는데...
6) 학습 완료된 모델 저장
#학습 완료된 모델 저장하기
MODEL_NAME='FastTRNet'
torch.save(tr_net.state_dict(), f'{MODEL_NAME}.pth')여기까지 수행했다면 할 일은 다했다 볼 수 있다.
이제 훈련된 TR Net을 사용하여 발할라로 떠나보자
3. TR Net으로 스타일 전이
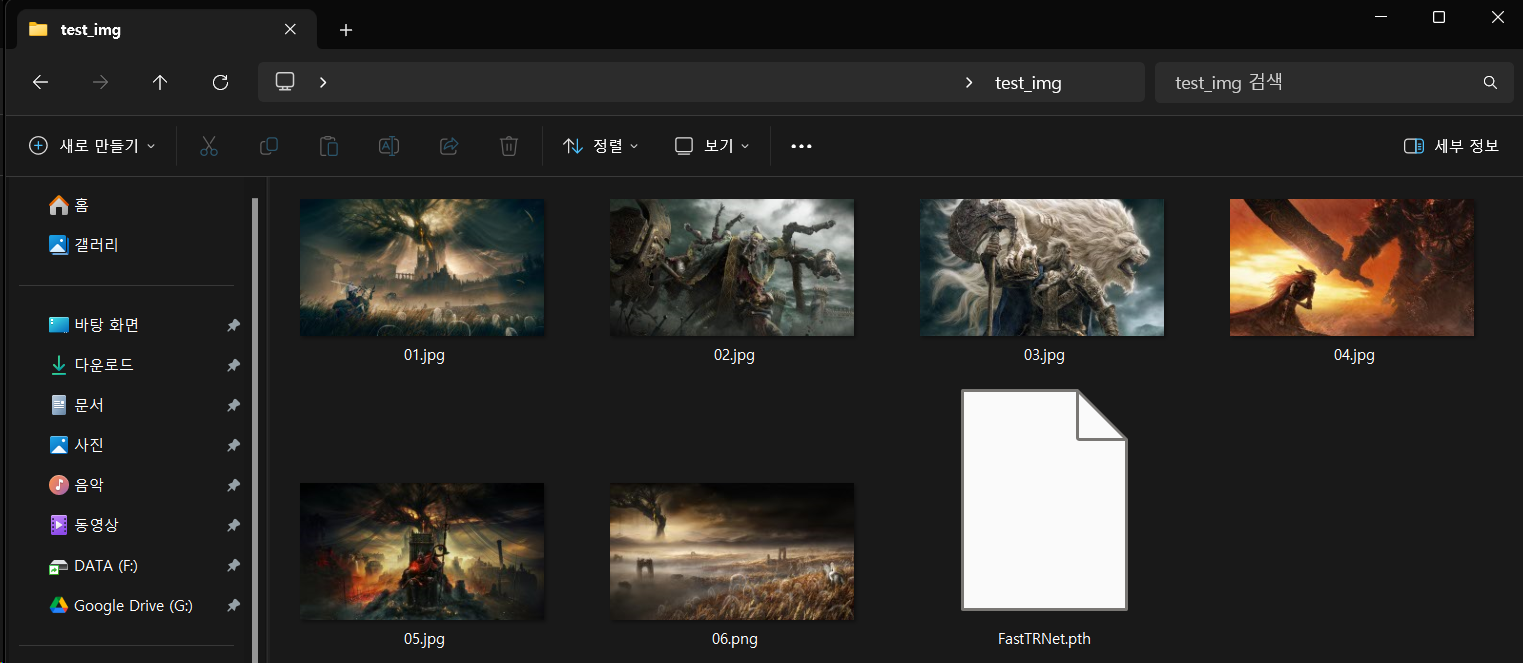
위 사진처럼 6개의 스타일 전이를 시킬 이미지와
TR_net의 학습된 가중치 파일 FastTRNet.path을 준비하자
그리고 새로운 파일 Fast_NST_inference.ipynb을 생성하고
아래의 코드를 작성하도록 하자
import torch
from img_utils import * #필자가 따로 만든 데이터 전처리 라이브러리
from network import ImageTransformNet #트랜스포머 net 라이브러리 불러오기
from PIL import Image
import numpy as np#GPU 사용 가능 여부 확인
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 데이터셋 표준화를 위한 기본정보 # 이게 이미지 정규화임
imgNet_val = {'mean' : [0.485, 0.456, 0.406], 'std' : [0.229, 0.224, 0.225]}import glob
img_dir = './test_img/' #이미지가 저장된 경로
img_paths = glob.glob(img_dir + '*.jpg') + glob.glob(img_dir + '*.png')
tas_tensor_list = list()
tensor_size = 1024
img_shape = [1080, 1920] #모든 이미지는 다 1080p임
for img_path in img_paths:
task_tensor, _ = preprocess_img(img_path, tensor_size, imgNet_val, device)
tas_tensor_list.append(task_tensor)
#리스트 내 이미지 텐서를 배치 텐서로 결합
batch_task_tensor = torch.cat(tas_tensor_list, dim=0)
print(batch_task_tensor.size())
여기까지 수행하면 6개의 이미지를 텐서 자료형으로 변환한 뒤
한번에 묶어서 배치 텐서로 변경한다.
tr_net = ImageTransformNet() #모델 인스턴스화
weight_file = './test_img/FastTRNet.pth' #weight파일 경로입력
state_dict = torch.load(weight_file, weights_only=True) #weight파일 불러오기
tr_net.load_state_dict(state_dict) #불러온 weight파일을 모델에 붙이기
tr_net.to(device) #tr모델을 GPU로 이전
print()tr_net.eval() #이미지를 평가모드로 전환
with torch.no_grad(): #그래디언트 추적금지
#배치 이미지를 한번에 Style transfer
result_tensor = tr_net(batch_task_tensor)
for i in range(result_tensor.size(0)):
# 배치 텐서에서 개별 이미지 추출
img_tensor = result_tensor[i].unsqueeze(0)
print(img_tensor.size())
res_img = deprocess_img(img_tensor, img_shape, imgNet_val)
#res_img는 PIL 이미지로 변환까지 수행되게 deprocess_img를 설계함
res_img.save(f"res_{i+1:02d}.jpg") #이미지 저장다음으로 6개 이미지 묶음 배치를 한번에 모델에 입력해서
추론을 한 뒤
한개씩 떼어네서 텐서 이미지 변환 후 저장한다.






음.. 훈련이 덜됫나?
아무튼 이 스타일 전이가 잘 되게끔 하는건
하이퍼 파라미터 튜닝의 영역이라
깊게 건드려봐야 시간만 낭비할거 같다
(TR_net 훈련시키는데 1시간 정도 소요된다...)

뭐 개념은 다 이해했잖아~ 한잔해~
https://github.com/tbvjvsladla/Neural_Style_Transfer
인공지능 고급(시각) 강의 복습 - 24. Neural Style Transfer (4)
에서 수행한
Nerual_style_transfer.ipynb
파일과
이번 포스트 작성에 사용된
Fast_NST_train.ipynb
Fast_NST_inference.ipynb
그리고 관련 py파일(img_utils.py, network.py)
등은 위 깃허브 저장소에 업로드 하였으며,
TR_net의 학습된 가중치 파일 FastTRNet.pth는
https://drive.google.com/file/d/1bul8yFXxpGTooZAtKW_L5Gl99-HvL9hO/view?usp=drive_link
에 업로드 하였다.
다음 포스트에서는
Image Transform Net에 대한 분석 및 설계를 수행하고자 한다.
