
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Image Transform Net 개요
이전 포스트 인공지능 고급(시각) 강의 복습 - 24. Fast Neural Style Transfer (5) 에서
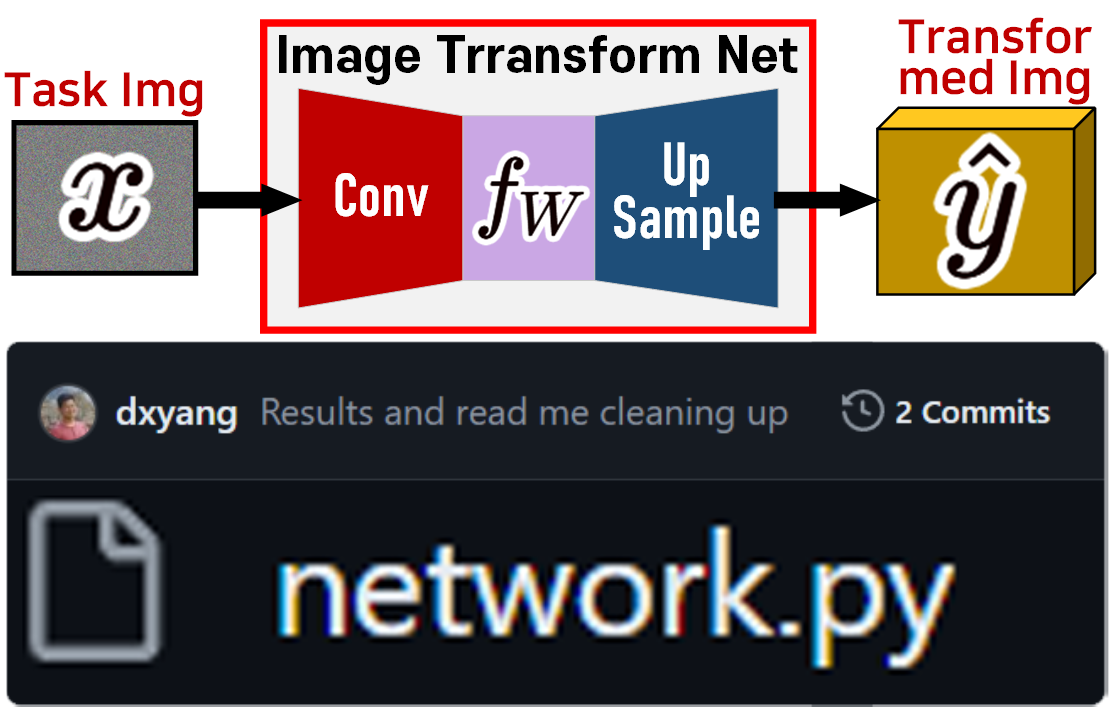 Image Transform Net에 대한 코드 리뷰 및 구조에 대한 설명은 스킵하고 넘어갔다.
Image Transform Net에 대한 코드 리뷰 및 구조에 대한 설명은 스킵하고 넘어갔다.
이 모델에 대한 설명까지 진행하면서 수행하는 실습을 포함하면 포스트 길이가 터져나가기에
우선은 깃허브에서 Fast Neural Style Transfer를 구현한 코드 중 리뷰와 Star을 높은 것 중 구현이 잘되고 설명하기 쉬운 Image Transform Net를 마침 찾아내서 이 TR Net를 사용하고 넘어간 것이다.
이제 Image Transform Net의 구조 및 코드기법에 대해 살펴보자
1.1 TR Net 코드리뷰
1) Encoder : Conv
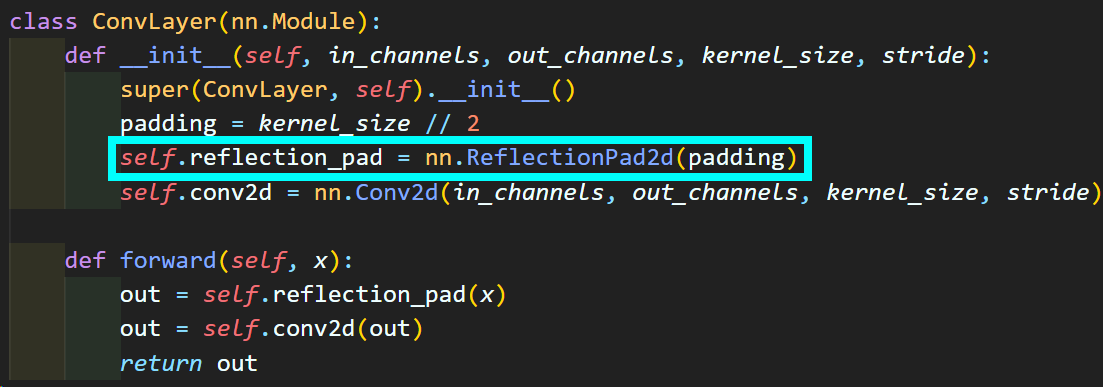
첫번째로 Image Transform Net의 encoder블럭에 해당하는 ConvLayer이다.
뭐 아주 간단한 코드지만 처음보는 레이어
nn.ReflectionPad2d가
발생했으니 작동원리를 알아 둘 필요성이 있다.
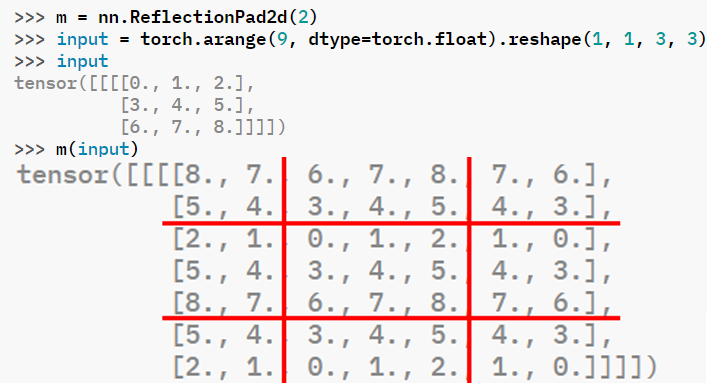
숫자만 나와서 좀 어지러울 수 있는데 선 그어놓고 보면
반사패딩을 적용하는 레이어 모듈이라는걸 알 수 있다.
그러니까 conv레이어를 설계할 때 pad 옵션이 발생하면
반사패딩을 걸어라
이렇게 보면 될거 같다.
2) ResidualBlock
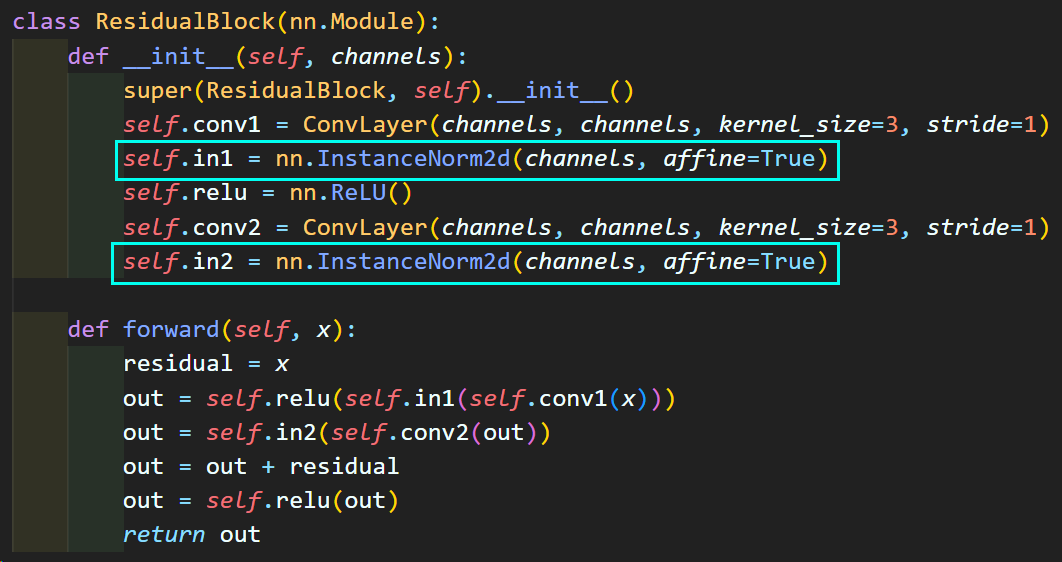
다음으로 Image Transform Net의 몸통에 해당하는
Residual Block에 해당하는 코드이다.
In channel과 Out channel의 변화 없이
표현력 유지를 위해 레이어를 쌓으려고 만든 블럭임은 알 것이다.
그런데 여기 또 처음보는 레이어 nn.InstanceNorm2d가 존재한다.
해당 레이어에 대한 설명을 하려면
 이 Instance Normalization: The Missing Ingredient for Fast Stylization을 볼 필요성이 있다.
이 Instance Normalization: The Missing Ingredient for Fast Stylization을 볼 필요성이 있다.
간단하게 요약을 하자면, Image Transform Net을 설계 시 normalization 레이어를 삽입한다면
Batch Normalization이 아닌 Instance Normalization레이어를 삽입하는게 성능이 더 좋게 나온다
이렇게 요약할 수 있다.
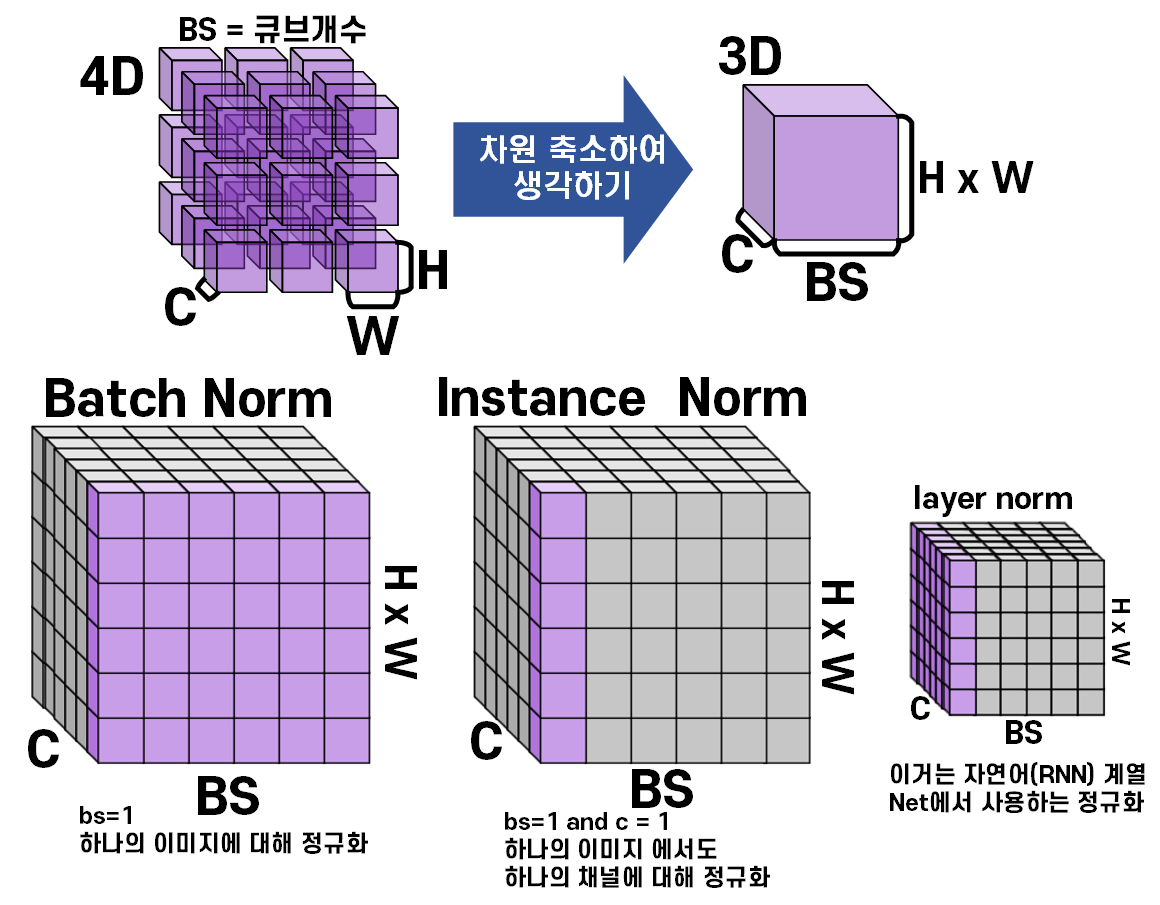
이거를 Tensor 자료형에서 종류별 Normalization의 방식에 대해 설명하자면
Instance Normalization는 하나의 이미지에 대한 Feature
거기서도 Feature 내 하나의 채널에 대한 정규화
를 수행한다 보면 된다.
그러니까 이미지 내 채널 항목으로만 정규화를 수행한다
논문에서는 스타일 전이 작업을 할 때는 BN대비 IN이 더 좋은 이유에 대해 설명하고 있지만

역시 결과물로 보는게 제일 직관적이다.
마지막으로 affine=True은 적용한 IN 레이어도
학습 가능한 레이어로 파라미터를 추가한다는 뜻이다.
3) UpsampleConv
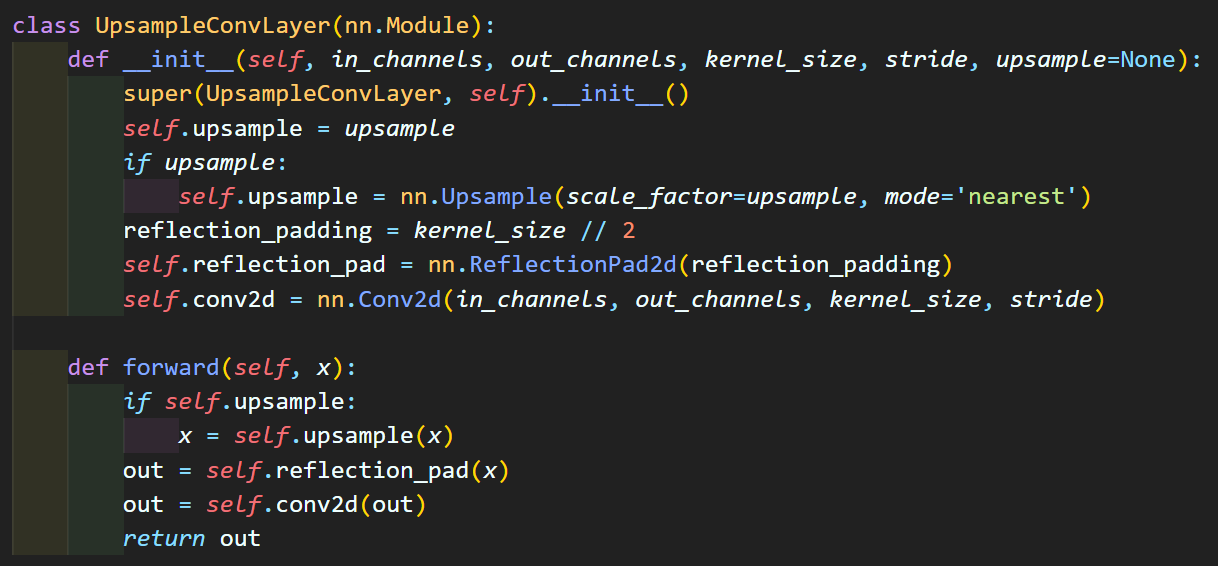
마지막으로 Upsample 레이어는
nn.Upsample를 적용하여 Faeture [H, W]를 업스케일링 하고
conv블럭으로 업샘플 레이어도 Trainable하게 적용했다
라고 볼 수 있다.
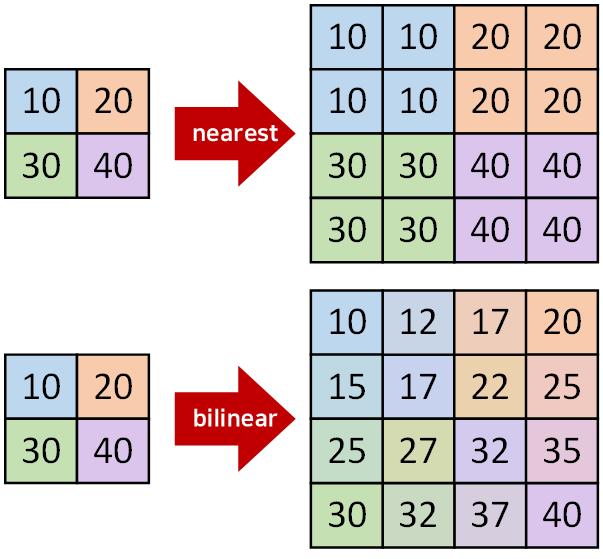
이때 nn.Upsample의 방법론은 nearest방법론을 사용한 것이라 보면 된다.
그런데 이렇게 Upsample -> Conv 로 수행하는 것 말고
한번에 Upsample하면서 해당 Upsample이 Trainable한 레이어로 만드는 방식이 존재한다.
ConvTranspose2d가 그러한데
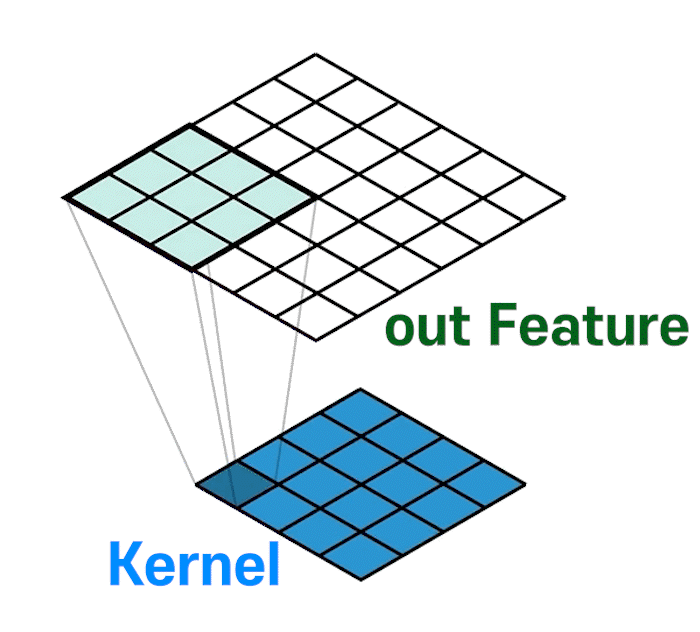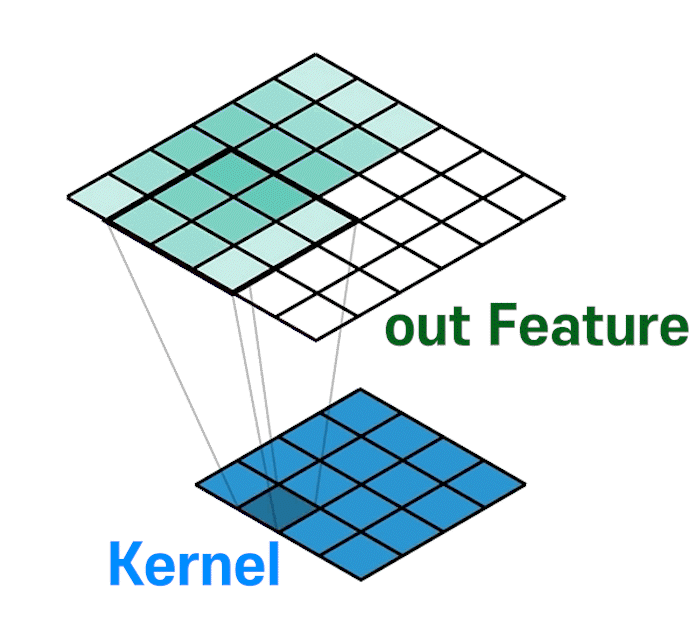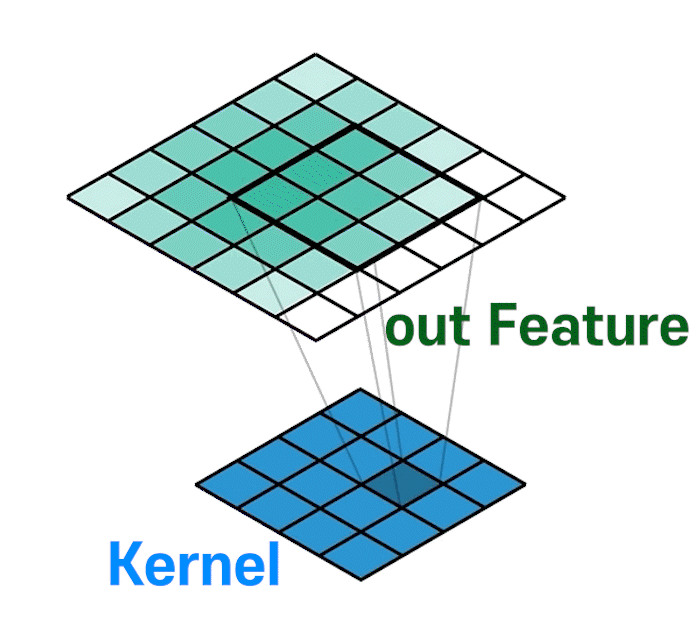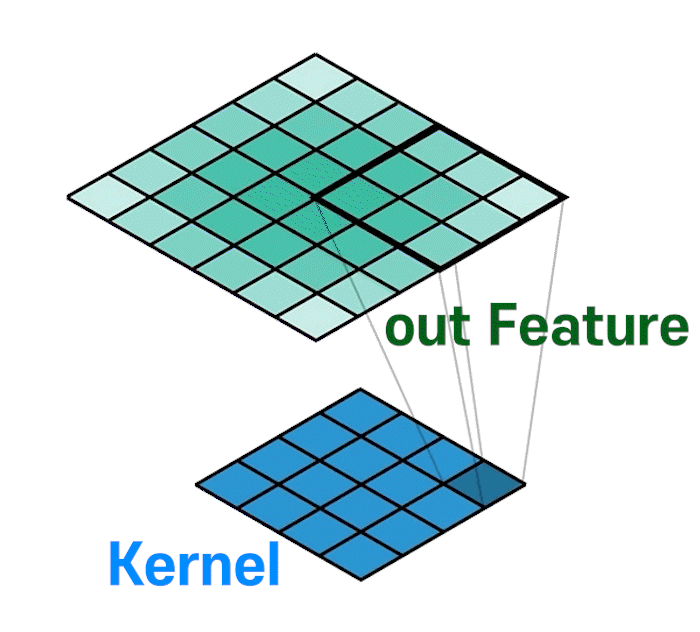
위 gif처럼 Upsample + Trainable 레이어가 만들어진다
1.2 TR Net 설계 정리
Image Transform Net코드 리뷰를 하면서 어떤 설계철학이 필요한지 정리해보자
- pad를 적용할 때는 zero pad가 아닌 reflect pad로
- BN이 아닌 IN사용
- 채널변화가 없는 레이어 Residual connection 적용
- Upsample 레이어도 Trainable하게
이제 이 정리된 방법론으로
인공지능 고급(시각) 강의 복습 - 24. 주요 CNN알고리즘 구현 : (1) MobileNet
인공지능 고급(시각) 강의 복습 - 24. 주요 CNN알고리즘 구현 : (3) SENet
에 사용된 MobileNet를 SEblock를 적용하여
Image Transform Net를 만들어보자
1) MobileNet + SEblock 버전 Image Transform Net 코드 구현
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, **kwargs):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size, bias=False, **kwargs),
# BN에서 IN오로 교체 + IN이 Trainable하게 변경
nn.InstanceNorm2d(out_ch, affine=True),
nn.ReLU()
)
def forward(self, x):
x = self.conv_block(x)
return xclass DepthSep(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super(DepthSep, self).__init__()
# depthwise에는 pad = 1옵션이 있는 것을 ReflectionPad2d(pad=1)옵션으로 변경
self.ref_pad = nn.ReflectionPad2d(padding=1)
self.depthwise = BasicConv(in_ch, in_ch, kernel_size=3, stride=stride,
groups = in_ch)
self.pointwise = BasicConv(in_ch, out_ch, kernel_size=1, stride=1)
def forward(self, x):
x = self.ref_pad(x)
x = self.depthwise(x)
x = self.pointwise(x)
return xclass DepthSepRes(nn.Module): #채널변동이 없는 레이어는 모두 Residual block로 처리
def __init__(self, in_ch):
super(DepthSepRes, self).__init__()
self.ref_pad = nn.ReflectionPad2d(padding=1)
self.depthwise = BasicConv(in_ch, in_ch, kernel_size=3, stride=1,
groups = in_ch)
self.pointwise = nn.Sequential(
nn.Conv2d(in_ch, in_ch, kernel_size=1, stride=1, bias=False),
# BN에서 IN오로 교체 + IN이 Trainable하게 변경
nn.InstanceNorm2d(in_ch, affine=True),
)
self.relu = nn.ReLU()
def forward(self, x):
identity = x
out = self.ref_pad(x)
out = self.depthwise(x)
out = self.pointwise(x)
out += identity #residual_connection
out = self.relu(out)
return outclass SEBlock(nn.Module):
def __init__(self, channel, reduction=16):
super(SEBlock, self).__init__()
self.ch = channel # Featuer의 channel값 추출
self.DS = reduction #연산량 감소를 위한 DownScale값
self.squeeze_path = nn.AdaptiveAvgPool2d((1, 1))
self.excitation_path = nn.Sequential(
nn.Linear(self.ch, self.ch//self.DS, bias=False),
nn.ReLU(),
nn.Linear(self.ch//self.DS, self.ch, bias=False),
nn.Sigmoid()
)
def forward(self, x):
bs, ch, _, _ = x.size()
y = self.squeeze_path(x).view(bs, ch)
y = self.excitation_path(y).view(bs, ch, 1, 1)
Recalibration = x * y.expand_as(x)
return Recalibrationclass UpSample(nn.Module):
#Upsample는 ConvTranspose2d를 사용하기
def __init__(self, channel):
super(UpSample, self).__init__()
# self.ref_pad = nn.ReflectionPad2d(padding=1)
self.up_conv = nn.ConvTranspose2d(channel, channel//2,
kernel_size=2, stride=2,)
self.IN = nn.InstanceNorm2d(channel//2, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
# x = self.ref_pad(x)
x = self.up_conv(x)
x = self.IN(x)
x = self.relu(x)
return xclass SEMobileNetTR(nn.Module):
def __init__(self, width_multiplier=1):
super(SEMobileNetTR, self).__init__()
self.alpha = width_multiplier #네트워크 각 층의 필터 개수를 조정
self.head = nn.Sequential(
nn.ReflectionPad2d(padding=1),
BasicConv(3, int(32*self.alpha), kernel_size=3, stride=2)
)
self.M_DepthSep = nn.ModuleDict()
self.M_SEBlock = nn.ModuleDict()
self.M_DepthSep['ds1'] = nn.Sequential(
DepthSep(int(32*self.alpha), int(64*self.alpha)),
DepthSep(int(64*self.alpha), int(128*self.alpha), stride=2),
)
self.M_SEBlock['se1'] = SEBlock(int(128*self.alpha))
self.M_DepthSep['ds2'] = nn.Sequential(
DepthSepRes(int(128*self.alpha)),
DepthSep(int(128*self.alpha), int(256*self.alpha), stride=2),
)
self.M_SEBlock['se2'] = SEBlock(int(256*self.alpha))
self.M_DepthSep['ds3'] = nn.Sequential(
DepthSepRes(int(256*self.alpha)),
DepthSep(int(256*self.alpha), int(512*self.alpha), stride=2),
)
self.M_SEBlock['se3'] = SEBlock(int(512*self.alpha))
self.M_DepthSep['ds4'] = nn.Sequential(
DepthSepRes(int(512*self.alpha)),
DepthSepRes(int(512*self.alpha)),
DepthSepRes(int(512*self.alpha)),
DepthSepRes(int(512*self.alpha)),
DepthSepRes(int(512*self.alpha)),
)
self.M_SEBlock['se4'] = SEBlock(int(512*self.alpha))
self.upsample = nn.Sequential(
UpSample(int(512 * self.alpha)),
UpSample(int(256 * self.alpha)),
UpSample(int(128 * self.alpha)),
UpSample(int(64 * self.alpha)),
# UpSample(int(32 * self.alpha)),
)
self.tail = nn.Sequential(
BasicConv(int(32*self.alpha), 3, kernel_size=1)
)
def forward(self, x):
x = self.head(x)
for i in range(1, 5):
DWS_block = self.M_DepthSep[f'ds{i}']
for DWS_layer in DWS_block:
x = DWS_layer(x)
x = self.M_SEBlock[f'se{i}'](x)
x = self.upsample(x)
x = self.tail(x)
return x설계한 SEMobileNetTR의 주요 구조를 정리하면 아래와 같다.
-
모든
BN레이어는IN레이어로 변경 및 Trainable하게 (affine=True) -
MobileNet v1에서 Inch = Outch 인 블럭이 있는 지점은 모두
Residual connection이 적용된DepthSepRes블럭 사용 -
Out Featuer의 size(
H, W)이 감소되는 DownSample 지점에는SE Block삽입 -
UpSmaple 과정에서는
ConvTranspose2d적용 -
Head 모듈은 기존 MobileNet v1의 Stem블럭과 거의 같으며, Tail 모듈은
1x1 conv에 차원축소용
이렇게 정리할 수 있을 듯 하다.
2) MobileNet + SEblock 버전 Image Transform Net 검증
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device='cpu')----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ReflectionPad2d-1 [-1, 3, 226, 226] 0
Conv2d-2 [-1, 32, 112, 112] 864
InstanceNorm2d-3 [-1, 32, 112, 112] 64
ReLU-4 [-1, 32, 112, 112] 0
BasicConv-5 [-1, 32, 112, 112] 0
ReflectionPad2d-6 [-1, 32, 114, 114] 0
Conv2d-7 [-1, 32, 112, 112] 288
InstanceNorm2d-8 [-1, 32, 112, 112] 64
ReLU-9 [-1, 32, 112, 112] 0
BasicConv-10 [-1, 32, 112, 112] 0
Conv2d-11 [-1, 64, 112, 112] 2,048
InstanceNorm2d-12 [-1, 64, 112, 112] 128
ReLU-13 [-1, 64, 112, 112] 0
BasicConv-14 [-1, 64, 112, 112] 0
DepthSep-15 [-1, 64, 112, 112] 0
ReflectionPad2d-16 [-1, 64, 114, 114] 0
Conv2d-17 [-1, 64, 56, 56] 576
InstanceNorm2d-18 [-1, 64, 56, 56] 128
ReLU-19 [-1, 64, 56, 56] 0
BasicConv-20 [-1, 64, 56, 56] 0
Conv2d-21 [-1, 128, 56, 56] 8,192
InstanceNorm2d-22 [-1, 128, 56, 56] 256
ReLU-23 [-1, 128, 56, 56] 0
BasicConv-24 [-1, 128, 56, 56] 0
DepthSep-25 [-1, 128, 56, 56] 0
AdaptiveAvgPool2d-26 [-1, 128, 1, 1] 0
Linear-27 [-1, 8] 1,024
ReLU-28 [-1, 8] 0
Linear-29 [-1, 128] 1,024
Sigmoid-30 [-1, 128] 0
SEBlock-31 [-1, 128, 56, 56] 0
ReflectionPad2d-32 [-1, 128, 58, 58] 0
Conv2d-33 [-1, 128, 54, 54] 1,152
InstanceNorm2d-34 [-1, 128, 54, 54] 256
ReLU-35 [-1, 128, 54, 54] 0
BasicConv-36 [-1, 128, 54, 54] 0
Conv2d-37 [-1, 128, 56, 56] 16,384
InstanceNorm2d-38 [-1, 128, 56, 56] 256
ReLU-39 [-1, 128, 56, 56] 0
DepthSepRes-40 [-1, 128, 56, 56] 0
ReflectionPad2d-41 [-1, 128, 58, 58] 0
Conv2d-42 [-1, 128, 28, 28] 1,152
InstanceNorm2d-43 [-1, 128, 28, 28] 256
ReLU-44 [-1, 128, 28, 28] 0
BasicConv-45 [-1, 128, 28, 28] 0
Conv2d-46 [-1, 256, 28, 28] 32,768
InstanceNorm2d-47 [-1, 256, 28, 28] 512
ReLU-48 [-1, 256, 28, 28] 0
BasicConv-49 [-1, 256, 28, 28] 0
DepthSep-50 [-1, 256, 28, 28] 0
AdaptiveAvgPool2d-51 [-1, 256, 1, 1] 0
Linear-52 [-1, 16] 4,096
ReLU-53 [-1, 16] 0
Linear-54 [-1, 256] 4,096
Sigmoid-55 [-1, 256] 0
SEBlock-56 [-1, 256, 28, 28] 0
ReflectionPad2d-57 [-1, 256, 30, 30] 0
Conv2d-58 [-1, 256, 26, 26] 2,304
InstanceNorm2d-59 [-1, 256, 26, 26] 512
ReLU-60 [-1, 256, 26, 26] 0
BasicConv-61 [-1, 256, 26, 26] 0
Conv2d-62 [-1, 256, 28, 28] 65,536
InstanceNorm2d-63 [-1, 256, 28, 28] 512
ReLU-64 [-1, 256, 28, 28] 0
DepthSepRes-65 [-1, 256, 28, 28] 0
ReflectionPad2d-66 [-1, 256, 30, 30] 0
Conv2d-67 [-1, 256, 14, 14] 2,304
InstanceNorm2d-68 [-1, 256, 14, 14] 512
ReLU-69 [-1, 256, 14, 14] 0
BasicConv-70 [-1, 256, 14, 14] 0
Conv2d-71 [-1, 512, 14, 14] 131,072
InstanceNorm2d-72 [-1, 512, 14, 14] 1,024
ReLU-73 [-1, 512, 14, 14] 0
BasicConv-74 [-1, 512, 14, 14] 0
DepthSep-75 [-1, 512, 14, 14] 0
AdaptiveAvgPool2d-76 [-1, 512, 1, 1] 0
Linear-77 [-1, 32] 16,384
ReLU-78 [-1, 32] 0
Linear-79 [-1, 512] 16,384
Sigmoid-80 [-1, 512] 0
SEBlock-81 [-1, 512, 14, 14] 0
ReflectionPad2d-82 [-1, 512, 16, 16] 0
Conv2d-83 [-1, 512, 12, 12] 4,608
InstanceNorm2d-84 [-1, 512, 12, 12] 1,024
ReLU-85 [-1, 512, 12, 12] 0
BasicConv-86 [-1, 512, 12, 12] 0
Conv2d-87 [-1, 512, 14, 14] 262,144
InstanceNorm2d-88 [-1, 512, 14, 14] 1,024
ReLU-89 [-1, 512, 14, 14] 0
DepthSepRes-90 [-1, 512, 14, 14] 0
ReflectionPad2d-91 [-1, 512, 16, 16] 0
Conv2d-92 [-1, 512, 12, 12] 4,608
InstanceNorm2d-93 [-1, 512, 12, 12] 1,024
ReLU-94 [-1, 512, 12, 12] 0
BasicConv-95 [-1, 512, 12, 12] 0
Conv2d-96 [-1, 512, 14, 14] 262,144
InstanceNorm2d-97 [-1, 512, 14, 14] 1,024
ReLU-98 [-1, 512, 14, 14] 0
DepthSepRes-99 [-1, 512, 14, 14] 0
ReflectionPad2d-100 [-1, 512, 16, 16] 0
Conv2d-101 [-1, 512, 12, 12] 4,608
InstanceNorm2d-102 [-1, 512, 12, 12] 1,024
ReLU-103 [-1, 512, 12, 12] 0
BasicConv-104 [-1, 512, 12, 12] 0
Conv2d-105 [-1, 512, 14, 14] 262,144
InstanceNorm2d-106 [-1, 512, 14, 14] 1,024
ReLU-107 [-1, 512, 14, 14] 0
DepthSepRes-108 [-1, 512, 14, 14] 0
ReflectionPad2d-109 [-1, 512, 16, 16] 0
Conv2d-110 [-1, 512, 12, 12] 4,608
InstanceNorm2d-111 [-1, 512, 12, 12] 1,024
ReLU-112 [-1, 512, 12, 12] 0
BasicConv-113 [-1, 512, 12, 12] 0
Conv2d-114 [-1, 512, 14, 14] 262,144
InstanceNorm2d-115 [-1, 512, 14, 14] 1,024
ReLU-116 [-1, 512, 14, 14] 0
DepthSepRes-117 [-1, 512, 14, 14] 0
ReflectionPad2d-118 [-1, 512, 16, 16] 0
Conv2d-119 [-1, 512, 12, 12] 4,608
InstanceNorm2d-120 [-1, 512, 12, 12] 1,024
ReLU-121 [-1, 512, 12, 12] 0
BasicConv-122 [-1, 512, 12, 12] 0
Conv2d-123 [-1, 512, 14, 14] 262,144
InstanceNorm2d-124 [-1, 512, 14, 14] 1,024
ReLU-125 [-1, 512, 14, 14] 0
DepthSepRes-126 [-1, 512, 14, 14] 0
AdaptiveAvgPool2d-127 [-1, 512, 1, 1] 0
Linear-128 [-1, 32] 16,384
ReLU-129 [-1, 32] 0
Linear-130 [-1, 512] 16,384
Sigmoid-131 [-1, 512] 0
SEBlock-132 [-1, 512, 14, 14] 0
ConvTranspose2d-133 [-1, 256, 28, 28] 524,544
InstanceNorm2d-134 [-1, 256, 28, 28] 512
ReLU-135 [-1, 256, 28, 28] 0
UpSample-136 [-1, 256, 28, 28] 0
ConvTranspose2d-137 [-1, 128, 56, 56] 131,200
InstanceNorm2d-138 [-1, 128, 56, 56] 256
ReLU-139 [-1, 128, 56, 56] 0
UpSample-140 [-1, 128, 56, 56] 0
ConvTranspose2d-141 [-1, 64, 112, 112] 32,832
InstanceNorm2d-142 [-1, 64, 112, 112] 128
ReLU-143 [-1, 64, 112, 112] 0
UpSample-144 [-1, 64, 112, 112] 0
ConvTranspose2d-145 [-1, 32, 224, 224] 8,224
InstanceNorm2d-146 [-1, 32, 224, 224] 64
ReLU-147 [-1, 32, 224, 224] 0
UpSample-148 [-1, 32, 224, 224] 0
Conv2d-149 [-1, 3, 224, 224] 96
InstanceNorm2d-150 [-1, 3, 224, 224] 6
ReLU-151 [-1, 3, 224, 224] 0
BasicConv-152 [-1, 3, 224, 224] 0
================================================================
Total params: 2,386,758
Trainable params: 2,386,758
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 282.65
Params size (MB): 9.10
Estimated Total Size (MB): 292.33
----------------------------------------------------------------입력 Tensor이 (1, 3, 224, 224)일 때
out Feature도 (1, 3, 224, 224)로 제대로
Image Transform Net을 설계한 듯 하다.
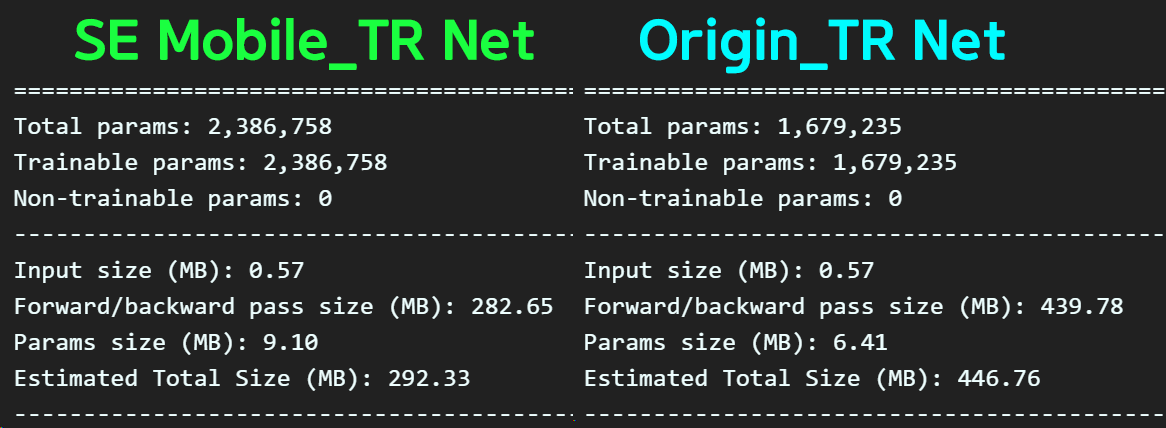
기존에 사용한 TR_net 대비 새로 설계한 SE Mobile_TR Net와 무게를 비교한다면 Param개수는 더 무거워진 것을 알 수있다.
그런데 연산 cost를 줄이는 방법이 적용되서 인지 F/B pass 사이즈는 줄은것인가?
이거는 필자도 잘 모르겟다.
코드실행(훈련)은 Fast_NST_train.ipynb에서
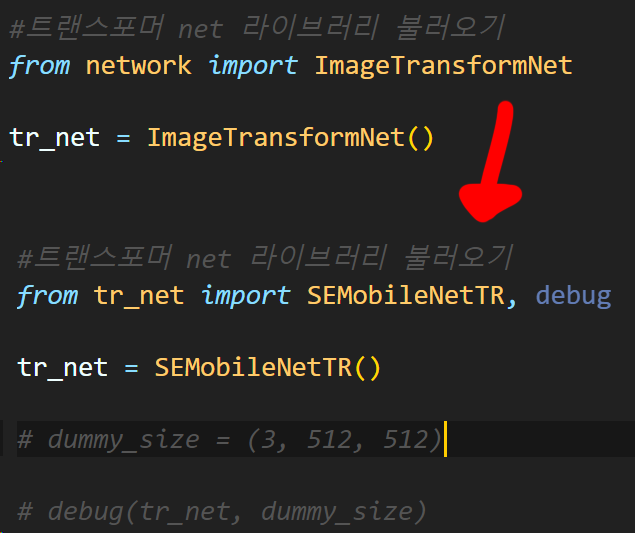
Image Transform Net을 불러오는 부분만 변경하면 된다.
물론 이때 사용한 tr_net.py
(SE Mobile_TR Net을 모듈화 한 코드)
https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/tr_net.py
에 업로드 하였다.
3) 훈련결과


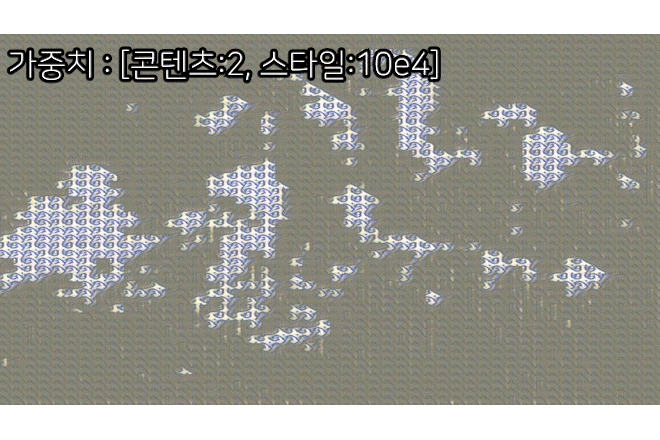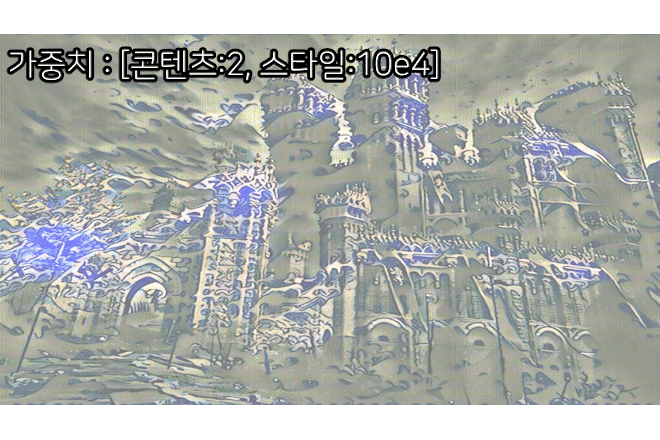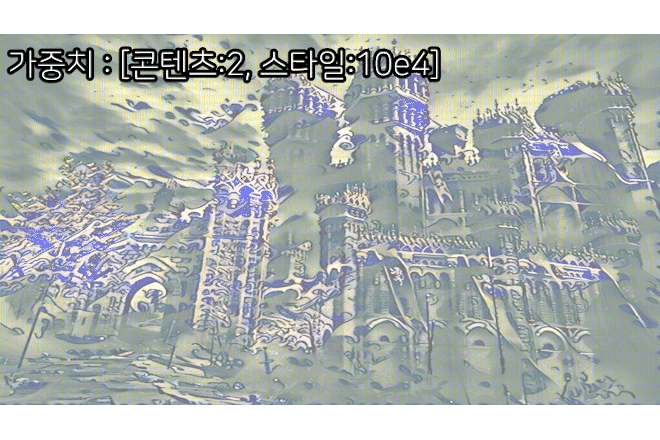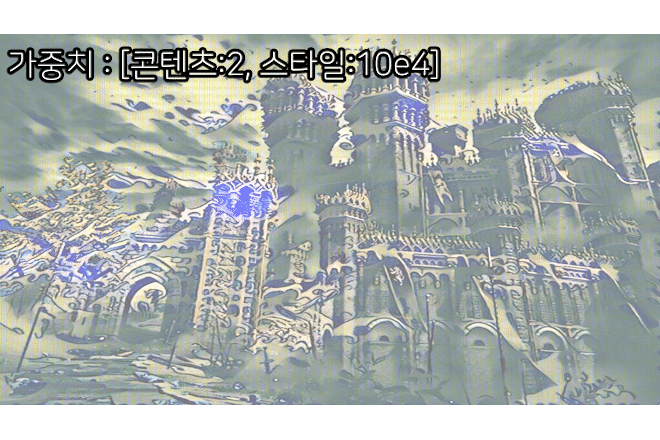
음... Image Transform Net는 단순하게 만드는게 베스트구나...
이건 뭐 이것저것 tr_net.py의 구조를 변경도 해봣는데
왜 색상이 날아가는지는 잘 모르겟다...
