
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. transforms.Normalize
Torchvision라이브러리를 통하여 데이터셋의 전처리 방법론
Transforming and augmenting images document를 살펴본다면 데이터셋의 전처리를 수행하는데 거의 필수적으로 사용하는 메서드가 있으니 Normalize 이다.
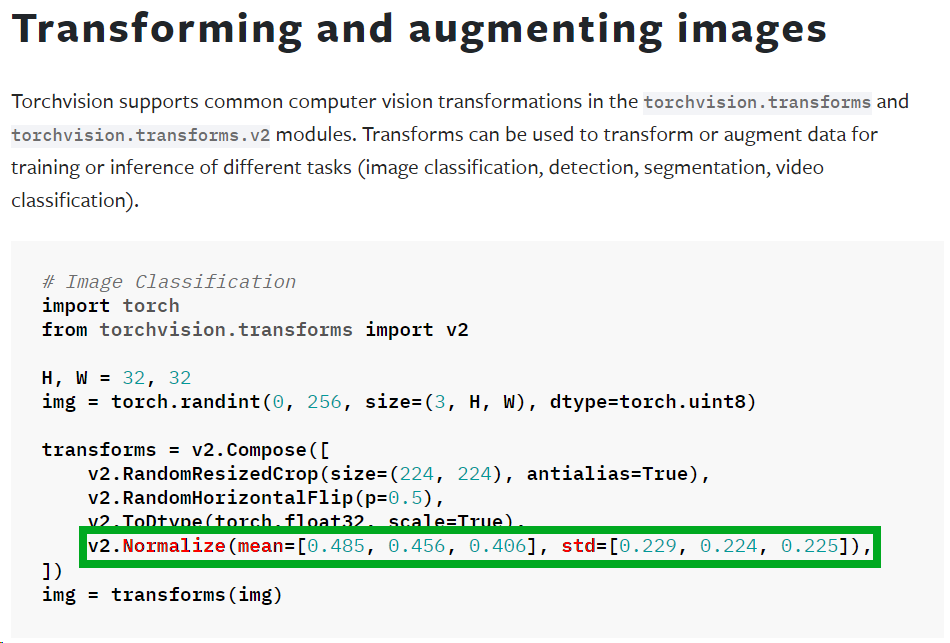
해당 메서드는 데이터 정규화(Data Normalization)에 속하는 과정으로 모든 데이터의 동일한 단위로 비교하기 위해 값을 변환하는 과정이라 보면 된다.
이 데이터 정규화 방법론으로는
1) Min-Max Scalling
2) Z-Score Normalization = Standardization(표준화)
3) Robust Scaling
4) Max Absolute Scaling
4가지 방법론이 존재하는데
Normalize 메서드는 이 중 2번 Standardization(표준화)에 속하는 방법론으로 데이터를 정규화한다.
여기서 중요한 것은 데이터셋을 정규화 하는데 있어
mean, std 값이 필요하다는 것이다.
이는 Standardization(표준화)수식이 위와 같으니 당연히 적용되는 것인데...
이것에 관하여 normalize메서드를 좀 더 살펴보도록 하자
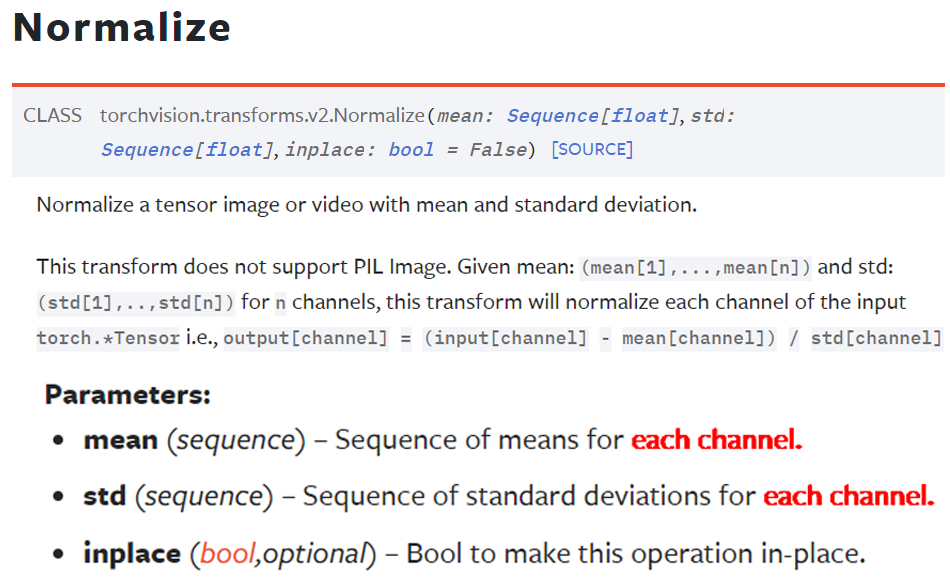
여기서 중요한 것은 붉은색으로 표기한 것처럼 each channel항목으로
데이터셋의 채널별로 따로따로 mean, std를 적용하라는 뜻이다.
이미지 데이터셋의 경우 R, G, B 3개의 채널이 존재하니까 mean, std는 각각 3개의 데이터를 갖는 리스트 값이어야 한다.
이때 통상적으로 사용되는 값이
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) 두개의 값이 주로 많이 쓰인다.
첫번째 인자값의 경우 그냥 편하게 mean=0.5, std=0.5로 가정하고 이미지 데이터셋을 Standardization(표준화) 하는 것이고
두번째 인자값은 흔히 이미지 데이터셋으로 쓴다면 가장 널리 쓰이는 ImageNet에 포함되어 있는 수백만장의 이미지 RGB 각 채널에 대한 mean, std값이다.

위 ImageNet 인식 대회에서 사용되는 대용량 데이터셋이라 보면 된다.
2. 직접 데이터셋의 mean, std구하기
위 과정말고 커스텀 데이터셋이 주어졌을 때
해당 데이터셋의 mean, std값을 구해야 하는 경우가 존재한다.
물론 대다수의 경우는 ImageNet의
mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]
을 그냥 써도 충분히 들어맞는다.
그래도 이왕 할거 데이터셋별로 mean, std를 구해보도록 하자
import os
import torch
from torchvision import datasets
#dataset.ImageFolder을 사용한 데이터셋 생성
root = './data/Animals-10'
img_dataset = {} #서브폴더('train', 'val', test')를 딕셔너리 형태로 관리하려고 이렇게 변수를 초기화함
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'train'))
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'val'))우선 임의의 데이터에 대하여 datasets.ImageFolder메서드를 통해 데이터셋으로 전처리를 수행하자.
from torch.utils.data import DataLoader
from torchvision.transforms import v2
from tqdm import tqdm
import gc#GPU사용 가능여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")다음으로 GPU사용 여부 확인이랑 기타 라이브러리를 import 한 후
class CalMeanStd():
def __init__(self, dataset, batch_size, ch=3, device='cuda'):
self.dataset = dataset
self.batch_size = batch_size #GPU연산 가능한 최대 bs로 설정
self.device = device #GPU로 설정 권장
self.ch = ch #해당 데이터셋의 채널 개수
transforamtion = v2.Compose([
v2.Resize((224,224)), #VGG19용 input_img로 리사이징
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True)
#텐서 자료형변환 + [0~1]사이로 졍규화 해줘야함
])
self.dataset.transform = transforamtion
self.dataloader = DataLoader(dataset=self.dataset,
batch_size=self.batch_size,
shuffle=False)
# 객체 생성과 동시에 연산 수행
self.res = self.cal_func()
def cal_func(self):
mean = torch.zeros(self.ch).to(self.device)
std = torch.zeros(self.ch).to(self.device)
nb_sample = 0
#데이터셋을 순회하며 mean, std 계산
for images, _ in tqdm(self.dataloader):
images = images.to(self.device)
batch_samples = images.size(0) # 배치 내 이미지 수
#(batch_size, channel, H, W) -> (batch_size, channel, H * W)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0) # (H*W)에 대한 평균 계산
std += images.std(2).sum(0) # (H*W)에 대한 표준편차 계산
nb_sample += batch_samples
del images # 연산이 끝난 변수(이미지)는 명시적으로 삭제
gc.collect()
mean /= nb_sample
std /= nb_sample
# mean과 std를 numpy 배열로 변환하여 소수점 4자리로 출력
mean_np = mean.cpu().numpy()
std_np = std.cpu().numpy()
#결과물을 출력시켜주는 코드
print(f"Mean: {[f'{x:.4f}' for x in mean_np]}")
print(f"Std: {[f'{x:.4f}' for x in std_np]}")
#최종 결과물은 딕셔너리로 저장한다.
value_dict = {'mean' : mean_np, 'std' : std_np}
return value_dict데이터셋의 mean, std를 계산하고
이를딕셔너리형태의 데이터로 출력하는 코드를 작성하자.
animals_val = CalMeanStd(img_dataset['train'], 256)다음으로 위 코드처럼 mean, std를 구하고자 하는 데이터셋, 그리고 GPU연산이 허용하는 batch_size 인자값을 입력하면
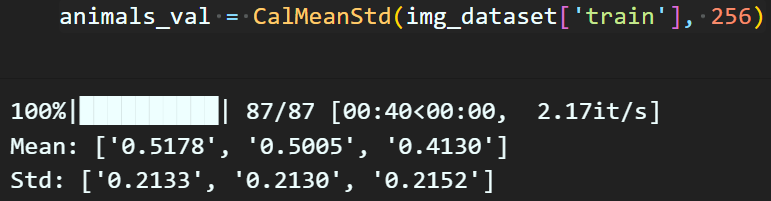
이렇게 편리하게 mean, std를 구할 수 있다.

결과물에 대한 접근은 위와 같이 접근할 수 있다.
3. 그래서 포스트 이유?

https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/cal_normal_value.py
해당 깃 허브에 위 데이터셋에 대한 mean, std를 GPU를 써서 편하게 구하는 클래스를 *.py로 만들었으니
이를 홍보하려고 포스팅했다;;;
사용방법은 간단하다
from cal_normal_value import CalMeanStd
animals_val = CalMeanStd(img_dataset['train'], 256)아니... 뭐.. 그냥.. 많이 이용해달라고...

츄라이 츄라이
