
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. SENet 개요
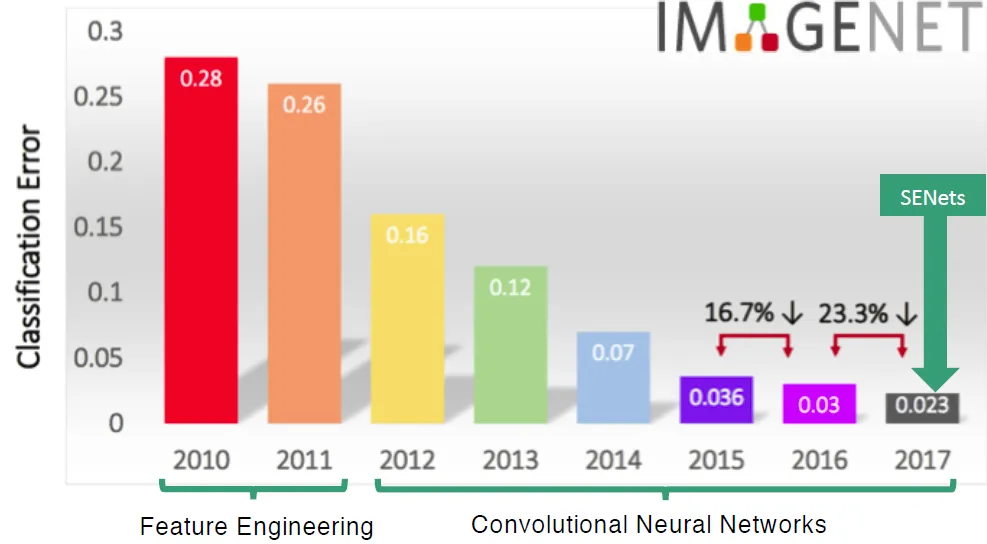
SENet는 2017년 마지막으로 열린 ImageNet 대회에서 우승을 차지한 Net으로 채널간의 상호 의존성(Interdependency)을 명확하게 모델링하여, 채널 간 중요도를 학습, 각 채널이 네트워크 출력에 기여하는 정도를 동적으로 조정하는 방법론을 제시한다.
여기서 상호 의존성(Interdependency)은 상관성(Correlation)보다 더 포괄적인 개념으로 아래의 표로 정리할 수 있다.
| 항목 | 상관성 (Correlation) | 상호 의존성(Interdependency) |
|---|---|---|
| 정의 | 두 변수 간의 선형 관계를 나타내는 통계적 개념 | 변수들 간의 복잡한 상호작용과 의존 관계 |
| 측정 방법 | 피어슨 상관계수, 스피어만 상관계수 등 | 다양한 방법 (비선형 모델, 피드백 루프 등) |
| 값의 범위 | -1 ~ 1 | 특정 값의 범위 없음 |
| 주요 특성 | 선형 관계의 강도와 방향 측정 | 복잡한 상호작용 및 의존 관계 모델링 |
| 예시 | 키와 몸무게 간의 상관관계 | 경제적 상호 의존성 (무역, 투자 등) |
| 계산 방법 | 수학적 공식에 기반한 단순 계산 | 다양한 모델링 기법 사용 |
| 단순성 | 상대적으로 단순 | 상대적으로 복잡 |
| 요구 데이터 유형 | 연속형 데이터 | 다양한 데이터 유형 가능 |
| 시간적 요소 포함 여부 | 일반적으로 시간적 요소 미포함 | 시간적 요소 포함 가능 |
이 SENet는 전체 Feature Map 내의 채널 간 복잡한 관계(상호의존성)을 모델링 한 것이고, 이를 통해 정량적 지표인 '중요도(Attention Score)'를 산출해 채널 간 기여도를 동적으로 조정한다.
SENet과 자연어 처리 계열과 Transformer model의 발전 및 기초를 제공한 어텐션 메커니즘(Attention Mechanism)과의 직접적인 관련성은 없으나,
기여도를 동적으로 조절하는 정량지표를 산출하는 과정이 두 논문이 매우 유사하기에 이 SENet에서 산출하는 정량지표를 충분히 Attention Score라 부르는 것이 가능하다 라고 볼 수 있다.
SENet는
상호의존성모델링 Attention Score 채널 간 기여도 조정
과정을 SE block으로 구현했으며, SE block은 ResNet의 Residual connection처럼 기존의 Net에 손쉽게 적용이 가능하여, 확장성이 높은 이점을 갖고 있다.
1.2 SE block
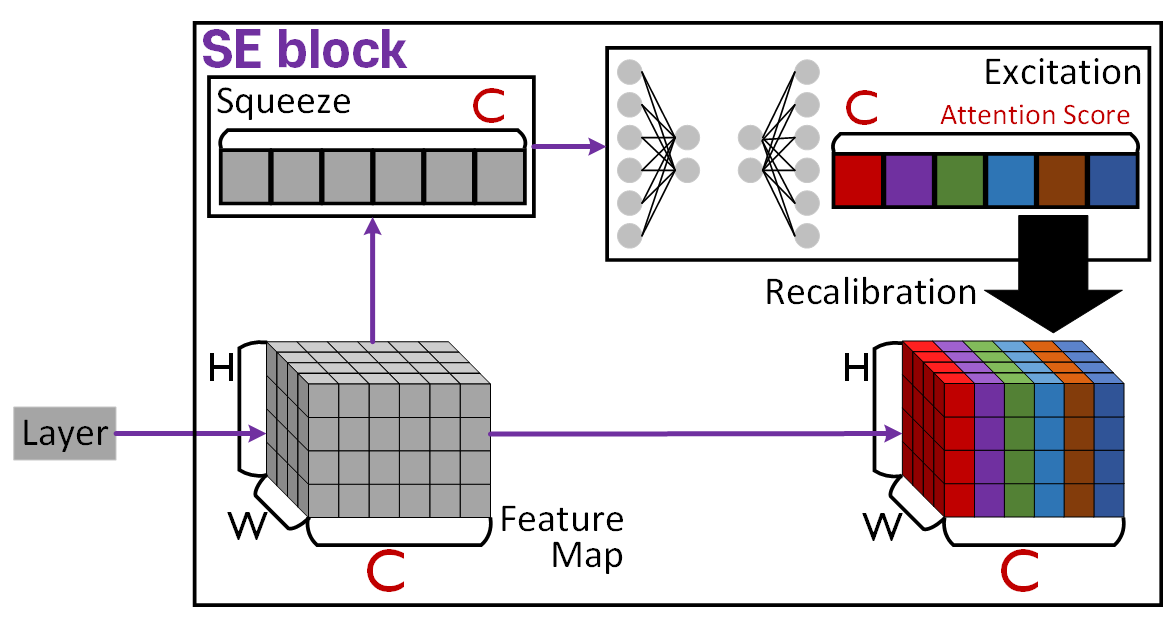
SE block(Squeeze-and-Excitation block)의 도식은 위와 같으며
크게 3가지 기능 : Squeeze, Excitation, Recalibration을 수행하여
Layer의 출력 Feature Map를 기여도가 조정된
recalibrated feature map으로 변환시킨다.
1) Squeeze
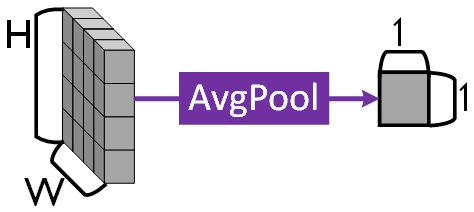
위 사진처럼 Feature Map을 Channel로 분리한 뒤 각 채널의 정보를 하나의 값으로 압축하는 과정을 의미한다.
이대 Global Avg Pool을 적용하면 위 사진처럼 손쉽게 (H, W) 정보를 하나의 Channel 평균값으로 Squeeze하는 것이 가능하다.
2) Excitation
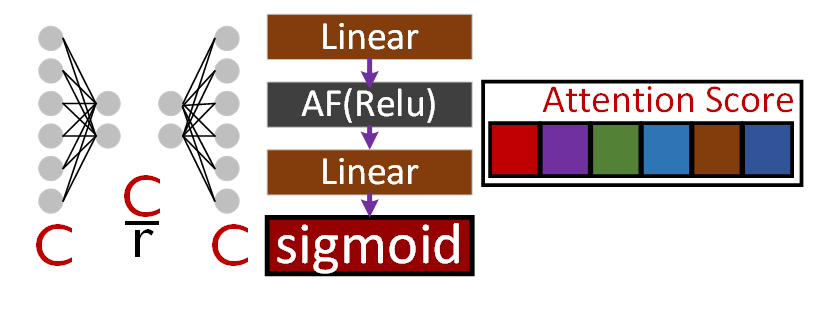
Squeeze에서 채널별 정보를 하나의 값으로 변경했으니,
이를 FC Layer로 구성된 Excitation path를 통과시켜 채널별 중요도 값인 Attention Score를 산출해낸다.
이때 연산 Cost를 감소시키는 reduction ratio를 적용해 중간 노드의 개수를 감소시키고, 다시 복원하는 과정을 수행한다.
3) Recalibration
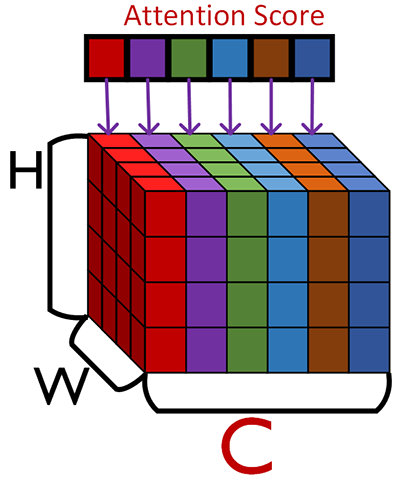
위 사진처럼 Excitation에서 계산된 Attention Score를 Feature Map의 채널별로 원소곱을 통해
recalibrated feature map으로 변환한다.
이렇게 3가지 과정을 통해서 산출되는
recalibrated feature map는 중요한 채널은 강조되고, 덜 중요한 채널은 억제됨에 따라 더 빠르고 정확하게 Image의 객체 정보를 학습할 수 있다.
2. SE Net 아키텍쳐
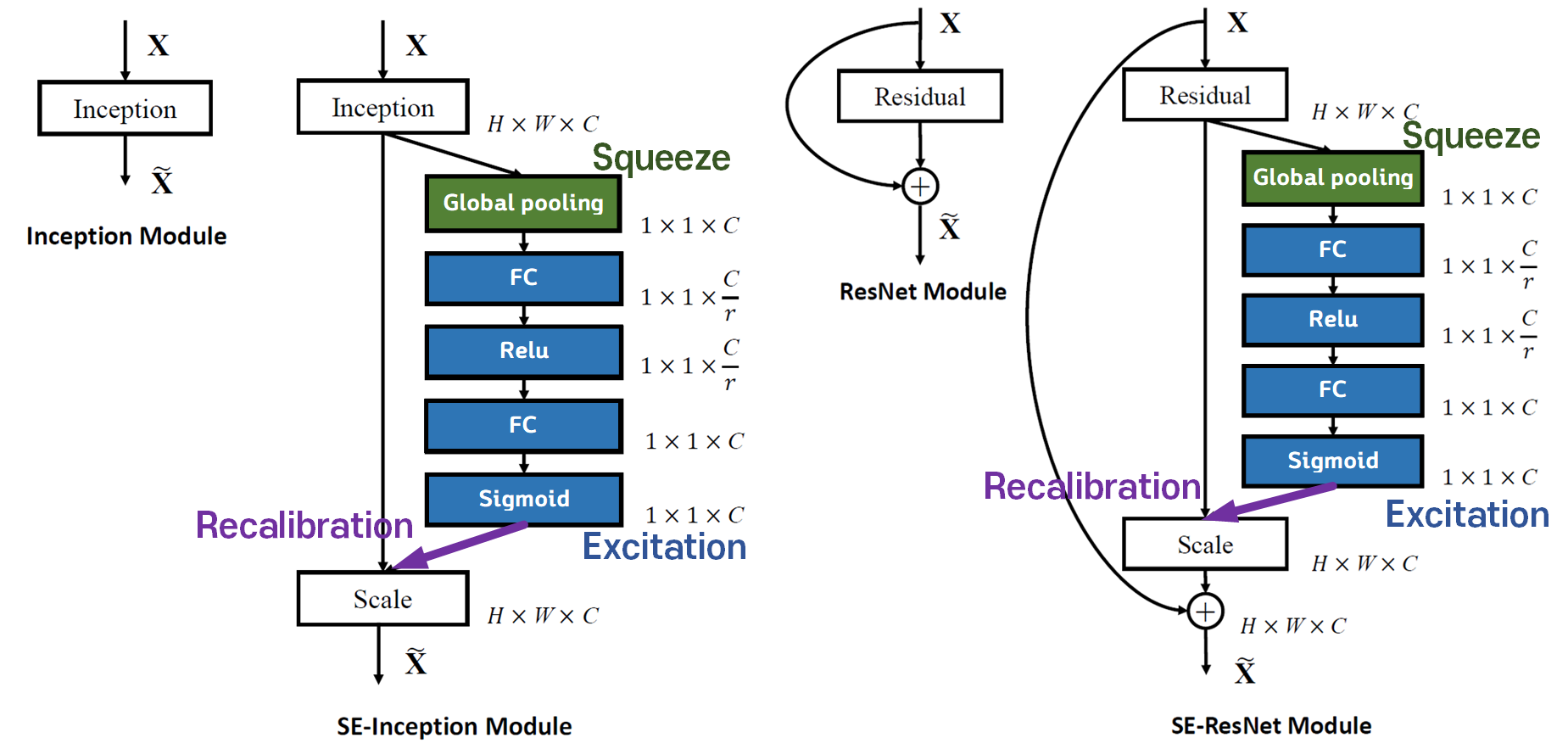
SENet은 앞서 설명했듯이 SE block이 가장 주요한 테마이고, 이 블럭의 장점은 다른 Net에 적용하기 쉽다는 것이다.
따라서 논문에서도 위 사진처럼 Inception 모델과 ResNet 모델에 SE block적용 예시를 설명하고 있다.
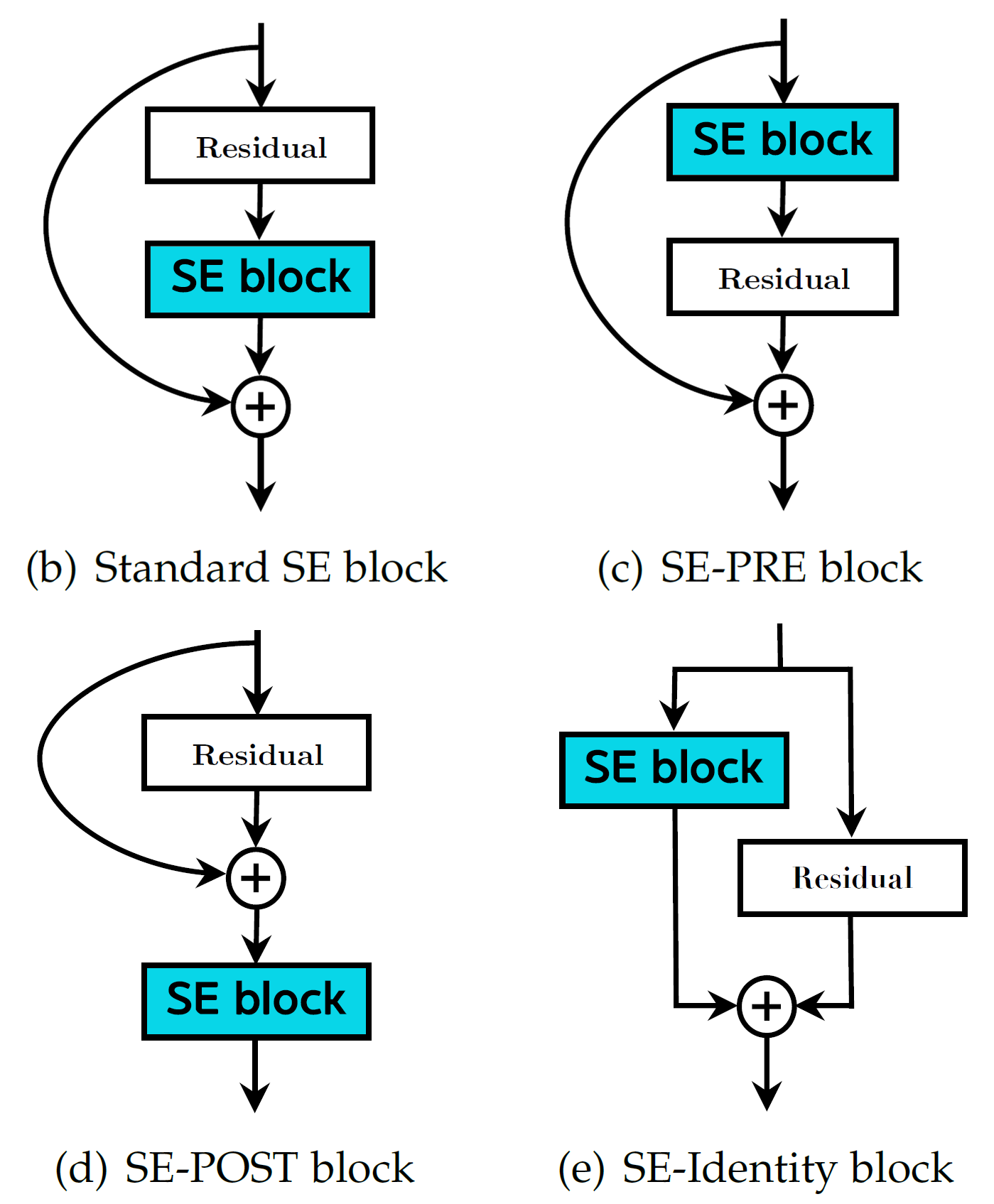
또한 위 사진처럼 SE block의 적용도 다양한 방법론으로 적용이 가능함을 논문에서 소개하고 있다.
우선 SE block에 대하여 먼저 코드로 구현을 진행하도록 하자
import torch
import torch.nn as nnclass SEBlock(nn.Module):
def __init__(self, channel, reduction=16):
super(SEBlock, self).__init__()
self.ch = channel # Featuer의 channel값 추출
self.DS = reduction #연산량 감소를 위한 DownScale값
# Faeture의 (C, H, W) -> (C, 1, 1)로 squeeze
self.squeeze_path = nn.AdaptiveAvgPool2d((1, 1))
self.excitation_path = nn.Sequential(
nn.Linear(self.ch, self.ch//self.DS, bias=False),
nn.ReLU(inplace=True),
nn.Linear(self.ch//self.DS, self.ch, bias=False),
nn.Sigmoid()
)
def forward(self, x):
bs, ch, _, _ = x.size() #입력된 feature의 bs, ch정보 추출
# (bs, ch, 1, 1)이 된것을 (bs, ch)로 줄이기
y = self.squeeze_path(x).view(bs, ch)
# excitation_path를 통해 계산된 Attention Score의 shape를
# (bs, ch)에서 (bs, ch, 1, 1)로 원복
y = self.excitation_path(y).view(bs, ch, 1, 1)
# expand_as를 써서 (bs, ch, H, W)로 늘리고 Attention Score를 곱함
Recalibration = x * y.expand_as(x)
return Recalibration위 블록을 기존 Net에 적용하는 방법을 실습하고자 하며 필자는
1) InceptionV3 - SE-POST block
2) ResNet - Standard SE block
두가지 방법론으로 각 모델에 SE block을 적용하고자 한다.
2.1 InceptionV3 - SE-POST block
이전 포스트 인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (2) Inception-v3,v4 훈련/검증에서 InceptionV3 모델 소개 및 아키텍쳐 소개까지 진행했으나
코드 구현은 하지 않았다.
그렇다고 해당 포스트에서 InceptionV3를 코드로 구현하고 설명을 진행하기에는 주제가 SENet이니 뭔가 좀 맞지 않는 느낌이 있다.

그래서 어떻게 하면 SENet을 잘 설명했다고 소문이 날까 고민하다가
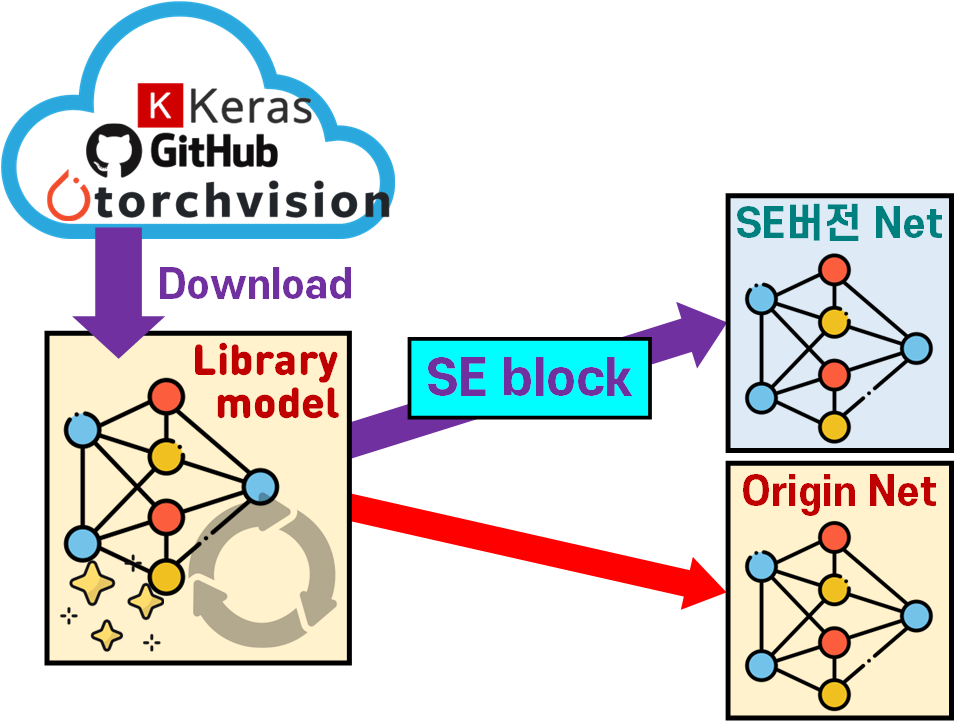
위 사진처럼 Torcivision에서 제공하는 Model을 다운로드 한 뒤, 해당 Model의 구조를 분석하고,
적합한 위치에 SE block를 삽입하여 SE버전 Net과 Origin Net과의 성능을 비교분석하고자 한다.
1) Torcivision에서 모델 다운로드
from torchvision import models
pr_model1 = models.inception_v3()
pr_model2 = torch.hub.load('pytorch/vision:v0.10.0', 'inception_v3', pretrained=False)모델을 다운로드 받는 방법은 두가지 방법이 있는데
첫번째 코드처럼 Torcivision라이브러리의 사용과
두번째 코드처럼 Pytorch.hub라이브러리를 사용하는 방법이다.
둘다 동일한 모델이고(코드도 거의 같다) 제공되는 weight 파일도 경로를 보니 같은 경로 파일이다.
2) 모듈 삽입위치 확인 + output Feature Map 캡쳐
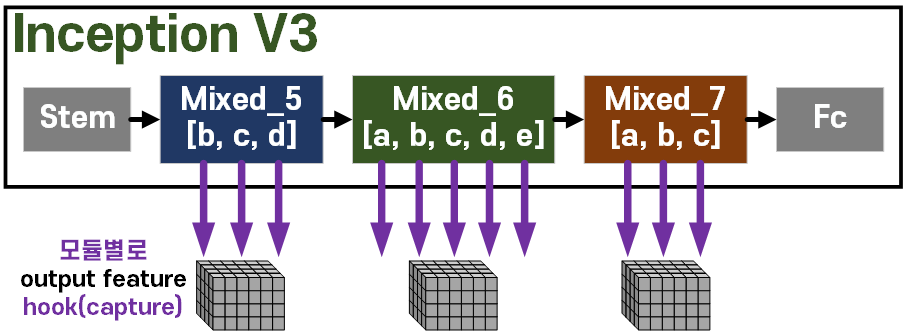
InceptionV3모델을 본다면 위 사진처럼 Stem, FC(classifier)사이에 총 11개의 inception block이 존재한다.
이 각각의 inception block 뒤에 SE-POST block 방식으로
SE block를 삽입하는 것이니 inception block의 블럭 output feature를 추출할 필요성이 있다.
이 과정은 인공지능 고급(시각) 강의 복습 - 23. 주요 CNN알고리즘 구현 : (2) DeepDream에서 설명한
register_forward_hook 메서드를 활용하고자 한다.
def module_output_shape(model, input_data):
model.eval()
model_info = {}
idx = 0
def forward_hook(name):
def hook(module, input, output):
nonlocal idx #idx가 함수 밖 변수라서 접근하려면 이렇게 해야함
idx += 1
key = str(idx) + ' ' + name
model_info[key] = output.shape #딕셔너리 형태로 저장
return hook
# 각 모듈의 최종 output feature를 캡쳐
for name, module in model.named_children():
module.register_forward_hook(forward_hook(name))
model(input_data) #모델에 입력데이터 통과
return model_info#inception_v3에 입력시킬 임의 데이터 생성
input_data = torch.randn(1, 3, 299, 299)
# 아래 함수를 사용하면 {idx 블럭이름} : {블럭 출력 feature.shaep}이 저장
model_info = module_output_shape(pr_model, input_data)for key, val in model_info.items():
print(key, val)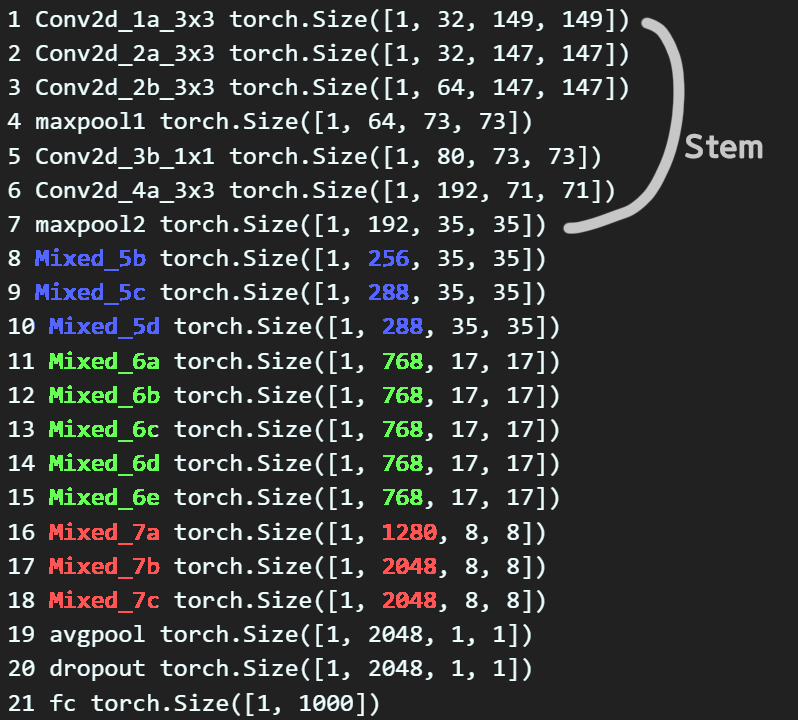
저장된 블럭별 output feature에서 필요정보는 각 inception block의 feature 채널 정보만 있으면 된다.
3) InceptionV3 - SE-POST block 버전 Net 생성
block_info = {
'Mixed_5b':256, 'Mixed_5c':288, 'Mixed_5d':288,
'Mixed_6a':768, 'Mixed_6b':768, 'Mixed_6c':768, 'Mixed_6d':768, 'Mixed_6e':768,
'Mixed_7a':1280, 'Mixed_7b':2048, 'Mixed_7c':2048,
}이 정보만 추출하여 위 코드처럼 딕셔너리 형태로 저장하자.
class SEInceptionV3(nn.Module):
def __init__(self, origin_model, block_info, reduction=16):
super(SEInceptionV3, self).__init__()
self.origin_model = origin_model
self.block_info = block_info
self.DS = reduction
# origin모델의 모듈 뒤에 se_block를 추가
for name, module in self.origin_model.named_children():
if name in self.block_info.keys():
# se_block의 채널정보는 block_info에서 찾아야함
channels = block_info[name]
# 수집한 채널정보를 바탕으로 se_block 인스턴스화
se_block = SEBlock(channels, self.DS)
self.origin_model._modules[name] = nn.Sequential(module, se_block)
def forward(self, x):
x = self.origin_model(x)
return xse_model = SEInceptionV3(pr_model2, block_info)이것을 위 설계한 클래스처럼 각 inception block을 찾아낸 뒤 해당 블럭의 뒤에다 SE block을
self.origin_model._modules[name] = nn.Sequential(module, se_block)이 코드로 삽입하면 InceptionV3 - SE-POST block 버전 Net이 완성된다.
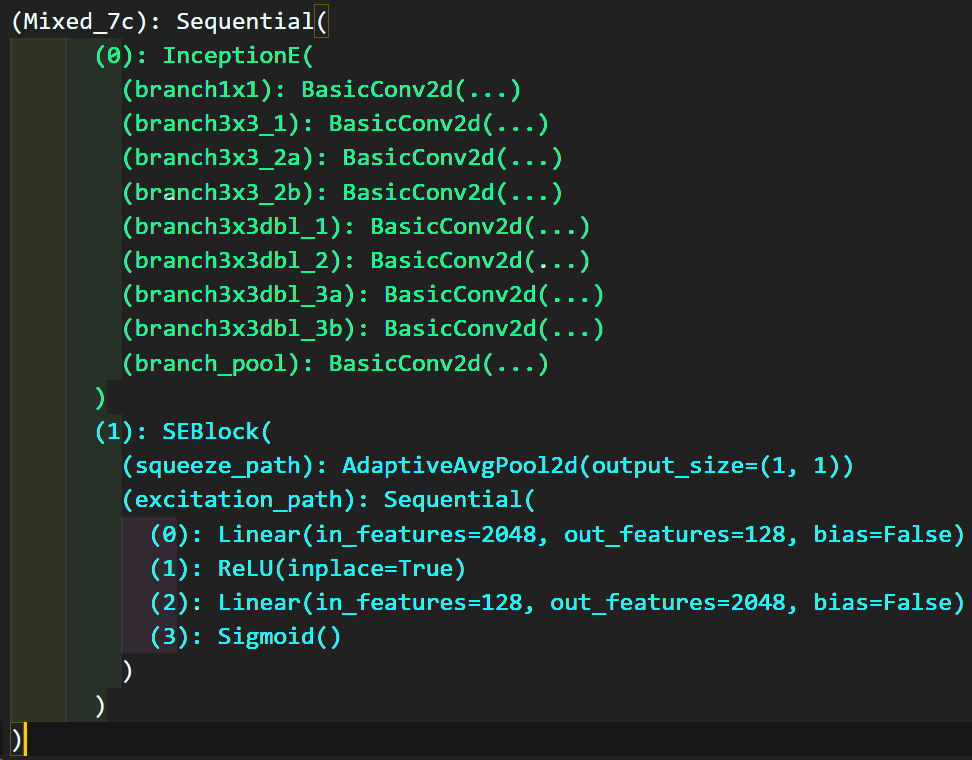 이 중 일부분만
이 중 일부분만 print 출력한다면 InceptionV3 - SE-POST block 구조가 정상적으로 적용됨을 알 수 있다.
4) Origin Net과의 성능 비교분석
성능 비교평가는 인공지능 고급(시각) 강의 복습 - 24. 주요 CNN알고리즘 구현 : (1) MobileNet에서 수행한 과정과 거의 동일한 과정으로 수행하고자 한다.
Image Dataset은 Animals-10
데이터셋 비율은 Train = 85%, Val = 15%
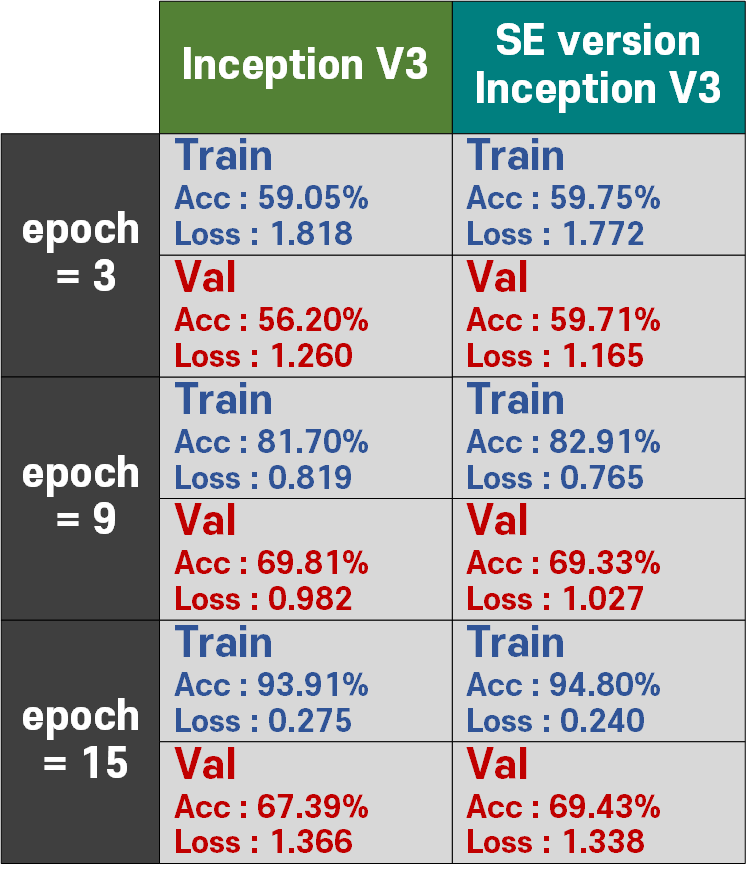
결과물을 본다면 InceptionV3 - SE-POST block이 전반적으로 조금 더 좋은 성능을 내는 것을 확인할 수 있다.
실험에 사용한 코드는 아래와 같다.
# 모델의 classifier 레이어 변경
pr_model1.fc = nn.Linear(2048, 10)
se_model.origin_model.fc = nn.Linear(2048, 10)# GPU 사용 가능 확인 후 모델을 GPU로 이전
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
m_keys = ['IncepV3', 'SE_incepV3']
Models = {
'IncepV3' : pr_model1.to(device),
'SE_incepV3' : se_model.to(device)
}데이터셋 전처리
import os
from torchvision import datasets
#dataset.ImageFolder을 사용한 데이터셋 생성
root = './data/Animals-10'
img_dataset = {} #딕셔너리로 선언
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'train'))
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'val'))# 데이터 전처리 방법론 정의
from torchvision.transforms import v2
animals_val = {'mean' : [0.5177, 0.5003, 0.4126],
'std' : [0.2133, 0.2130, 0.2149]}
transformation = v2.Compose([
v2.Resize((299, 299)), #Inceptin V3 -> [299, 299]
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=animals_val['mean'], std=animals_val['std']) #데이터셋 표준화
])
# 전처리 방법론을 데이터셋에 적용하기
img_dataset['train'].transform = transformation
img_dataset['val'].transform = transformationfrom torch.utils.data import DataLoader
BATCH_SIZE = 128
train_loader = DataLoader(img_dataset['train'],
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(img_dataset['val'],
batch_size=BATCH_SIZE,
shuffle=False)하이퍼 파라미터 설정
import torch.optim as optim
# 손실 함수와 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizers = {
'IncepV3' : optim.Adam(Models['IncepV3'].parameters(), lr=1e-4),
'SE_incepV3' : optim.Adam(Models['SE_incepV3'].parameters(), lr=1e-4)
}학습/검증용 라이브러리 다운로드 위치 : https://github.com/tbvjvsladla/metacodeM_pytorch_bootcamp/blob/main/C_ModelTrainer.py
# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
epoch_step = 3 #특정 epoch마다 모델의 훈련/검증 정보 출력
# BC_mode = True : 이진분류 문제 풀이 , BC_mode = False : 다중분류 문제 풀이, aux=다중분류기 유/무
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type, BC_mode=False, aux=True)# 학습과 검증 손실 및 정확도를 저장할 딕셔너리
history = {m_key: {'loss': [], 'accuracy': []} for m_key in m_keys}
num_epoch = 15for m_key in m_keys:
model = Models[m_key]
optimizer = optimizers[m_key]
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = trainer.model_train(model, train_loader,
criterion, optimizer, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = trainer.model_evaluate(model, test_loader,
criterion, epoch)
# 손실과 성능지표를 리스트에 저장
history[m_key]['loss'].append((train_loss, test_loss))
history[m_key]['accuracy'].append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"[{m_key}] epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"[{m_key}] epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {test_loss:.3f}, " +
f"Acc: {test_acc*100:.2f}%]")2.2 ResNet - Standard SE block
1) Torcivision에서 모델 다운로드 및 모델 분석
from torchvision import models
pr_model1 = models.resnet50()
pr_model1_1 = models.resnet50()
pr_model2 = models.resnet18()
pr_model2_1 = models.resnet18()Origin Net은 ResNet18, ResNet50을 선정했는데
인공지능 고급(시각) 강의 복습 - 16. 주요 CNN알고리즘 구현 : ResNet여기에서 설명했듯이
약간 구조의 차이가 있어서 두 모델을 선정했다.
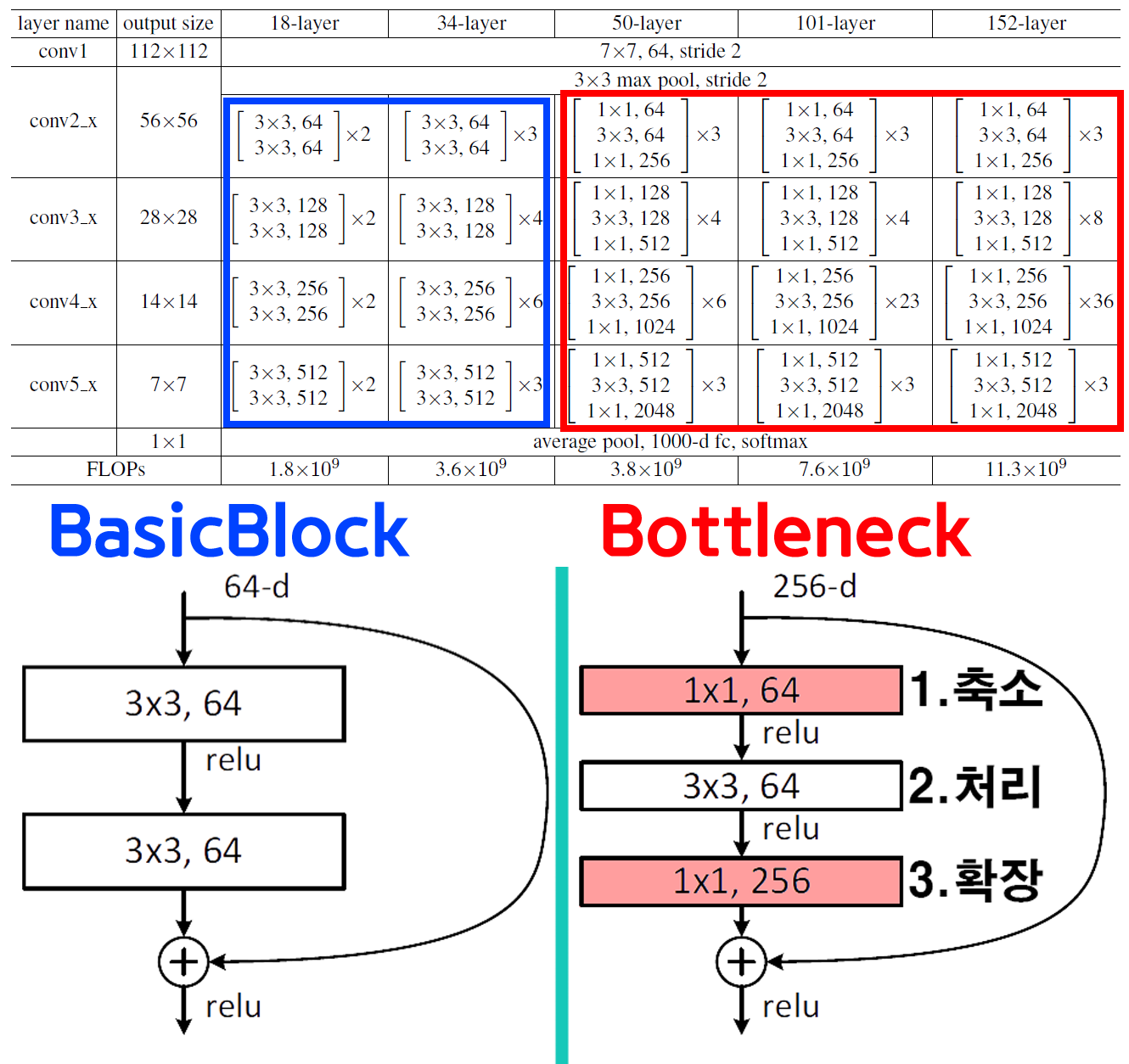
위 사진처럼 기본 block의 구조가 차이가 존재한다.

모델을 print하여 구조를 살펴본다면
sub_module에 BasicBlock, Bottleneck로 해당 모듈의 클래스 이름이 명기된 항목들이 존재한다.
이 sub_module내 포함된 여러 레이어 중에서
가장 마지막 Bn(batchnormalize) 모듈 뒤편에 SE block을 삽입해야
ResNet - Standard SE block 구조가 완성된다
이를 도식화 하면 아래와 같다.
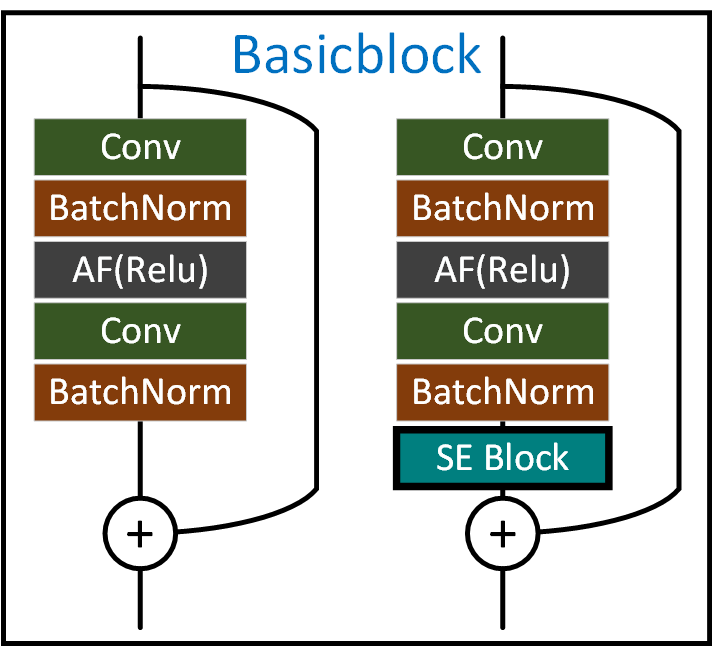

이제 위 과정을 코드로 구현하면 된다.
class SEResNet(nn.Module):
def __init__(self, origin_model, reduction=16):
super(SEResNet, self).__init__()
self.origin_model = origin_model
self.DS = reduction
# Standard SE block방식으로 residual block에 SE모듈 삽입
for modul_name, module in self.origin_model.named_children():
# 최 상단 main 모듈 중 nn.Sequential로 된 항목 찾기
if isinstance(module, nn.Sequential):
for idx, sub_module in module.named_children():
# 서브 모듈이 `Bottleneck` or `BasicBlock`을 찾은 뒤
# 해당 서브 모듈 내 레이어를 항목을 확인하기
for layer_name, layer in sub_module.named_children():
# 서브 모듈의 이름이 BasicBlock, Bottleneckd에 따라서
# 교체해야할 bn모듈의 위치가 달라짐
if sub_module.__class__.__name__ == 'BasicBlock':
if layer_name == 'bn2' and isinstance(layer, nn.BatchNorm2d):
# 레이어 변경 함수 호출
self.layer_change(sub_module, layer_name, layer)
elif sub_module.__class__.__name__ == 'Bottleneck':
if layer_name == 'bn3' and isinstance(layer, nn.BatchNorm2d):
# 레이어 변경 함수 호출
self.layer_change(sub_module, layer_name, layer)
def layer_change(self, sub_module, layer_name, layer):
if isinstance(layer, nn.BatchNorm2d):
channel = layer.num_features #BN의 채널 수 추출
se_block = SEBlock(channel, self.DS)
# 기존 BatchNorm2d 레이어를 BN + SE_Block로 교체
new_bn = nn.Sequential(
layer,
se_block
)
sub_module._modules[layer_name] = new_bn
def forward(self, x):
x = self.origin_model(x)
return xse_model1 = SEResNet(pr_model1_1) #ResNet 50의 SE버전
se_model2 = SEResNet(pr_model2_1) #ResNet 18의 SE버전2) Origin Net과의 성능 비교분석
성능 비교는 앞의 InceptionV3 - SE-POST block 성능 비교 분석과 동일하다.

이것도 ResNet - Standard SE block의 성능이
Origin Net(ResNet)보다 더 좋게 나왔으며,
특히 ResNet18보다 ResNet50에서 그 차이가 두드러지게 발생함을 확인할 수 있었고, ResNet18은 오히려 Origin Net의 성능이 더 좋게 나오는 것을 확인할 수 있다.
아무래도 SE block의 성능이 재대로 발현하려면 레이어의 깊이가 어느정도의 깊이를 갖춘 레이어에서 그 성능이 올라간다.. 이렇게 볼 수 있을 것 같다.
아래는 실험에 사용한 코드이다.
#ResNet50, SE-ResNet50의 DownStream Task 준비
pr_model1.fc = nn.Linear(2048, 10)
se_model1.origin_model.fc = nn.Linear(2048, 10)
#ResNet18, SE-ResNet18의 DownStream Task 준비
pr_model2.fc = nn.Linear(512, 10)
se_model2.origin_model.fc = nn.Linear(512, 10)# GPU 사용 가능 확인 후 모델을 GPU로 이전
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
m_keys = ['ResNet50', 'SE_ResNet50', 'ResNet18', 'SE_ResNet18']
Models = {
'ResNet50' : pr_model1.to(device),
'SE_ResNet50' : se_model1.to(device),
'ResNet18' : pr_model2.to(device),
'SE_ResNet18' : se_model2.to(device)
}import os
from torchvision import datasets
#dataset.ImageFolder을 사용한 데이터셋 생성
root = './data/Animals-10'
img_dataset = {} #딕셔너리로 선언
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'train'))
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'val'))# 데이터 전처리 방법론 정의
from torchvision.transforms import v2
animals_val = {'mean' : [0.5177, 0.5003, 0.4126],
'std' : [0.2133, 0.2130, 0.2149]}
transformation = v2.Compose([
v2.Resize((224, 224)), #ResNet -> [224, 224]
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=animals_val['mean'], std=animals_val['std']) #데이터셋 표준화
])
# 전처리 방법론을 데이터셋에 적용하기
img_dataset['train'].transform = transformation
img_dataset['val'].transform = transformationfrom torch.utils.data import DataLoader
BATCH_SIZE = 128
train_loader = DataLoader(img_dataset['train'],
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(img_dataset['val'],
batch_size=BATCH_SIZE,
shuffle=False)import torch.optim as optim
# 손실 함수와 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizers = {
'ResNet50' : optim.Adam(Models['ResNet50'].parameters(), lr=5e-5),
'SE_ResNet50' : optim.Adam(Models['SE_ResNet50'].parameters(), lr=5e-5),
'ResNet18' : optim.Adam(Models['ResNet18'].parameters(), lr=5e-5),
'SE_ResNet18' : optim.Adam(Models['SE_ResNet18'].parameters(), lr=5e-5),
}# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
epoch_step = 2 #특정 epoch마다 모델의 훈련/검증 정보 출력
# BC_mode = True : 이진분류 문제 풀이 , BC_mode = False : 다중분류 문제 풀이
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type, BC_mode=False)# 학습과 검증 손실 및 정확도를 저장할 딕셔너리
history = {m_key: {'loss': [], 'accuracy': []} for m_key in m_keys}
num_epoch = 10for m_key in m_keys:
model = Models[m_key]
optimizer = optimizers[m_key]
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = trainer.model_train(model, train_loader,
criterion, optimizer, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = trainer.model_evaluate(model, test_loader,
criterion, epoch)
# 손실과 성능지표를 리스트에 저장
history[m_key]['loss'].append((train_loss, test_loss))
history[m_key]['accuracy'].append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"[{m_key}] epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"[{m_key}] epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {test_loss:.3f}, " +
f"Acc: {test_acc*100:.2f}%]")아무튼
약간의 연산 cost가 상승하지만 그것을 충분히 상쇄할만큼 성능향상을 이끌어내는 방법론이 SENet이라 볼 수 있다.

이제 CNN 아키텍쳐는 몇개 안남은거 같다
