
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. Yolo v1 Loss_fn
인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (1) 모델 설계
이전포스트에 이어 Loss Function을 설계하고자 한다.
우선 설계한 Loss Function은 전체 Yolo v1 API 코드로 본다면
criterion = YoloLoss() -> 어디선가 선언된 YoloLoss()
loss = loss_fn(output, label) -> 훈련/검증코드에서 출력되는 값은 'Loss'단 하나!로 되어 있고
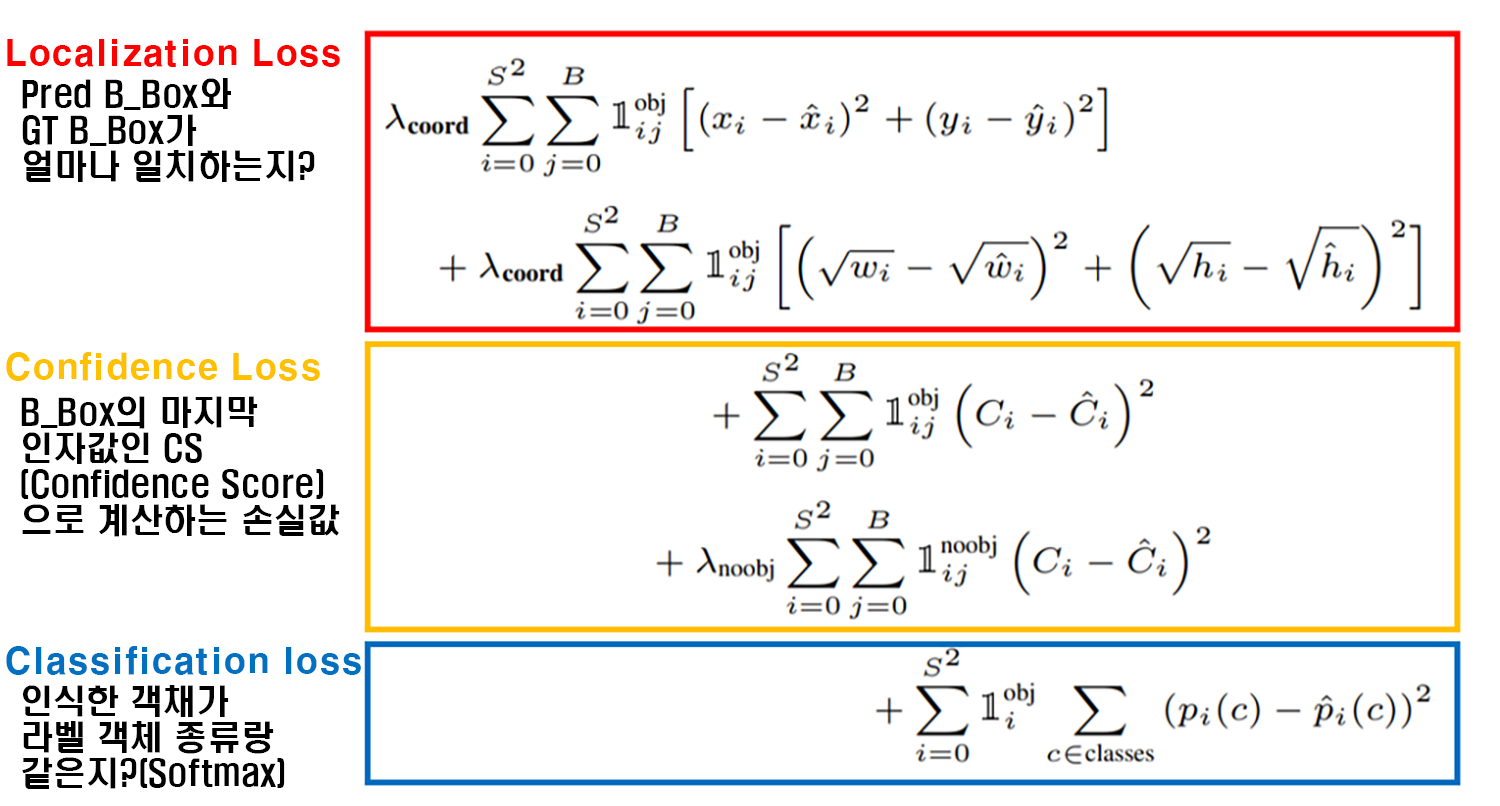 다른 Yolo v1논문을 보면 흔히 접하는 Loss Function에 대한 수식이고 대략 3개의 파트로 나뉘는데
다른 Yolo v1논문을 보면 흔히 접하는 Loss Function에 대한 수식이고 대략 3개의 파트로 나뉘는데
1) 위치 손실 (Localization Loss) : 모델이 예측한 Bounding Box(B_Box)가 데이터셋의 Annotation에 기재된 객체의 Boinding Box(GT B_Box)랑 일치하는 정도 IOU 지표로 계산
2) 신뢰도 손실(Confidence Loss) : 바운딩박스 정보에 포함되어 있는 CS(Conficdece_Score)에 대한 예측 CS와 라벨CS간 일치하는 정도
3) 분류 손실(Classification Loss) : 인식한 객체가 데이터셋의 Annotation에 기재된 객체는 어느 종류이다 라는 것에 대한 일치 정도 일반적인 Image Classification 작업을 수행할 때 계산하는 Loss값
으로 나뉘는데 사실 이게 중요한 것이 아니다
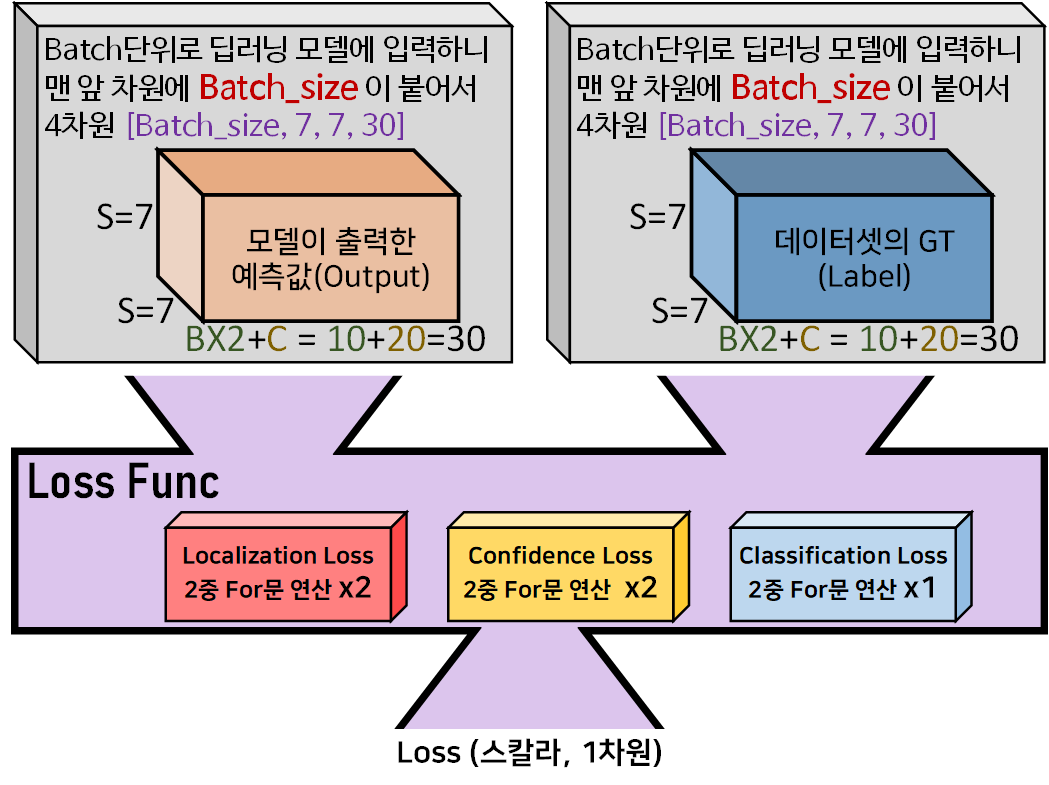
Loss Func에 입력되는 차원이
[Batch_size, S, S, (B x 2 + C)]에 해당하는 4차원 데이터셋이고
Loss Func내부에서 연산되는 항목도 이 기호가 두번 연달아 붙어있으니
2중 For 구문 으로 연산을 수행해야 하며, 이 연산도 총 5번을 수행해야 한다.
따라서 입력 텐서 차원 4차원(차원당 1개의 for문) + 2중 for문 연산 = 6중 for문
을 만들어서 수행해야 할 수도 있다.
 (이렇게 다중 차원 + 다중for문을 요구하는 수식을 코드화 하기란 매우 어렵다)
(이렇게 다중 차원 + 다중for문을 요구하는 수식을 코드화 하기란 매우 어렵다)
그래서 다른 사람이 구현한 Yolo v1 코드를 리뷰하면
진짜 못알아 먹는 경우가 태반이다...
어떤 코드는 for문이 다닥다닥 붙어서
 이런 식의 Arrow코드가 만들어 지는 경우가 있고 그게 아니면
이런 식의 Arrow코드가 만들어 지는 경우가 있고 그게 아니면
위 영상처럼 천재 코딩 개발자의 Pythonic한 코드에 대략 정신이 멍해지는 코드도 많다.
따라서 실패한 Yolo Loss()함수와
성공한 Yolo Loss() 함수
두가지 버전을 같이 소개하면서 코드 리뷰를 진행하고자 한다.
2. 실패한 YoloLoss()
1) 클래스 도입부
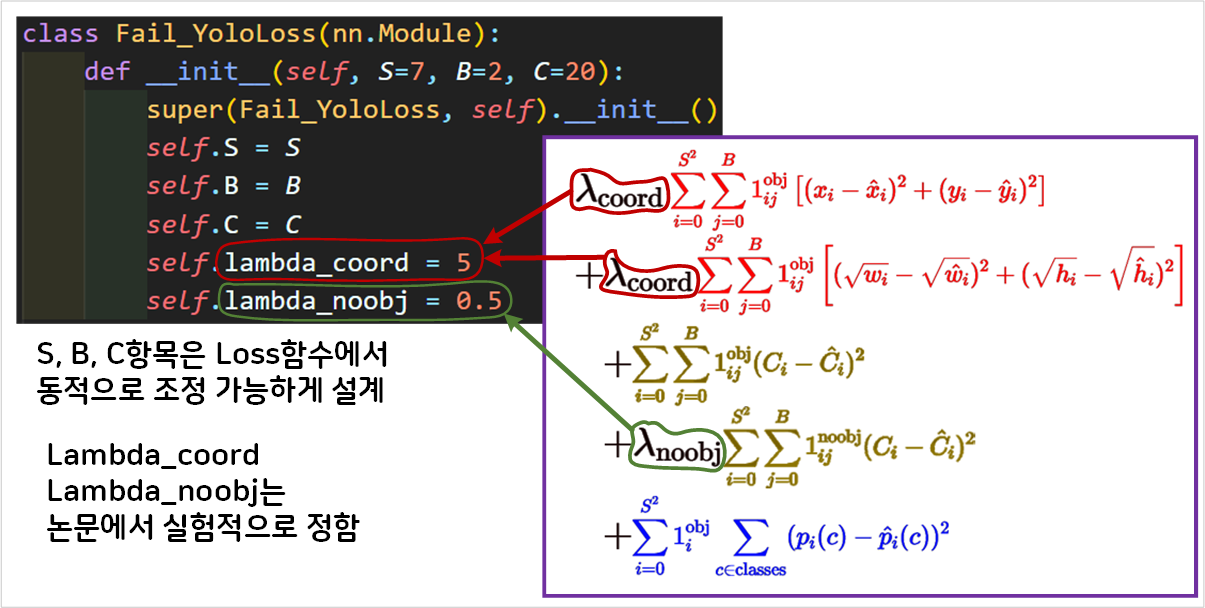 Yolo Loss함수의
Yolo Loss함수의 __init__부분에서는 인자값 조정에 동적으로 대응하기 위해 S, B, C를 클래스 변수로 선언하였다.
Lambda_coord, Lambda_noobj는 Yolov1 논문에 나와있는 실험 계수값이다.
2) B_Box추출 밎 차원전환
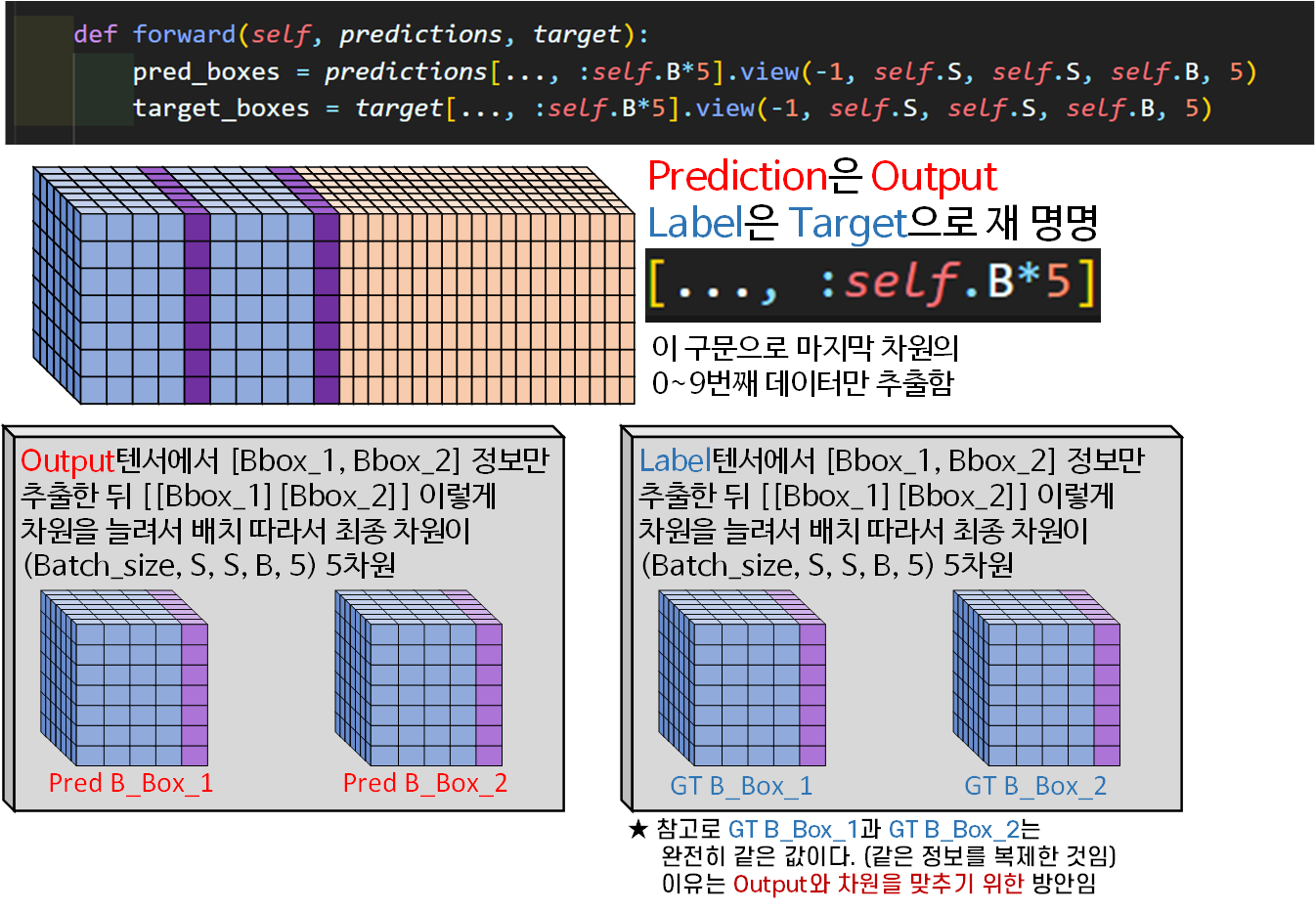 forward 함수의 맨 앞에서는 입력받은 Pred 정보랑 Label 정보에서
forward 함수의 맨 앞에서는 입력받은 Pred 정보랑 Label 정보에서
첫번째 Localization Loss를 계산하기 위해 B_Box 정보를 추출한다.
그리고 B_Box_1, B_Box_2를 독립적으로 다루기 위하여
.view메서드로 차원형상변환을 수행
최종적으로 (Batch_size, S, S, B, 5)의 5차원으로 만들고
B = 0이면 B_Box_1
B = 1이면 B_Box_2에 접근하는 것을 의미한다.
여기서 중요한 구문은
[..., :self.B*5] #ellipsis 라는 명칭구문이다.
이거는 위 영상을 시청하자
아무튼 ... 이거는 ellipsis이라 부르며,
앞에 차원은 어떻게 되든 관계없이
라고 생각하면 될거 같다. 이걸 같은 코드로 표현하면
[:, :, :, :self.B*5]인데 저 :개 1개만 붙어도 필자는 해석이 잘 안되는데 2개 이상되면 머리가 아파오니 ...를 적극적으로 활용하려 노력하고 있다.
그리고 GT B_Box_1 == GT B_Box_2을 잊지 말자
이건 당연하게도 1개의 객체에 Ground Truth는 1개의 Bounding Box가 매핑되어야 하기 때문이다.
그러면 왜 동일한 값을 가진 GT B_Box_1, GT B_Box_2를 만들어서 메모리 아깝게 사용하냐는 논리가 발생하는데
이는 Output의 차원과 Target의 차원을 일치시키기 위해서 차원복제를 수행한 것이라서 그렇다.
차원복제를 수행안하면
Output의 차원 = (Batch_size, 7, 7, 30)
Target의 차원 = (Batch_size, 7, 7, 25)로 차원이 맞지 않는다.
3) B_Box추출 밎 차원전환
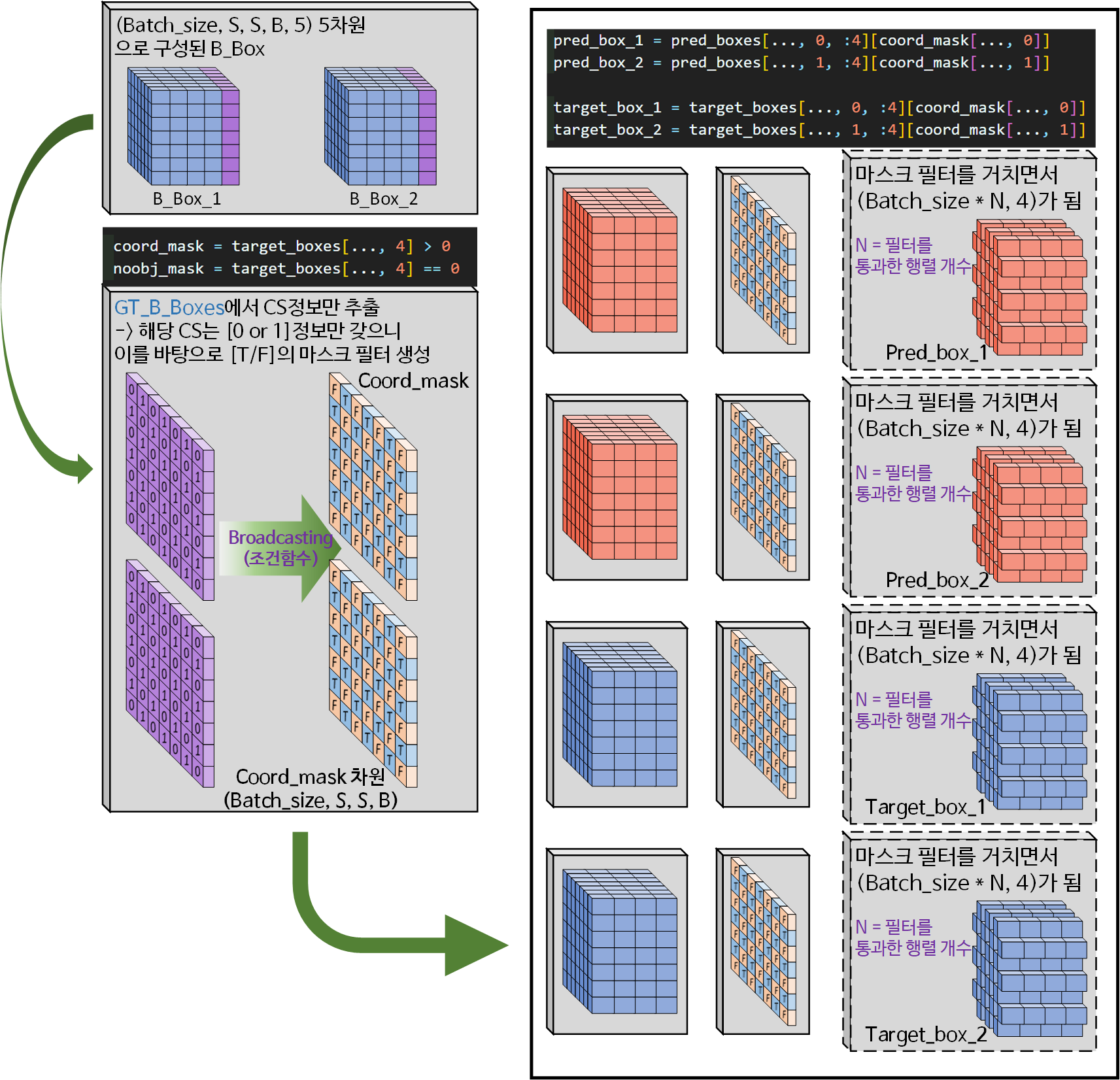
다음으로는 B_Box의 [CS] 정보를 활용하여 마스크 필터
coord_mask, noobj_mask를 생성하는 것이다.
coord_mask = target_boxes[..., 4] > 0
noobj_mask = target_boxes[..., 4] == 0코드를 보면 target_boxes는 Tensor자료형이고,
[..., 4]구문으로 차원 슬라이싱이 이뤄졌다 하지만
엄연히 (batch_size, S, S, B)로 이뤄진 4차원 데이터이다.
이게 > 0, == 0과 같은 스칼라 차원의 변수와 조건연산을 수행했는디 이는 Numpy, Tensor 자료형이 제공하는 기능인 Broadcasting 기능을 사용하여
for문 없이 빠르게 필터 행렬을 생성했다 보면 된다.
이 Broadcasting기능도 잘 알아두면 for문 없이
Pythonic하게 코드를 만들 수 있다.

아무튼 Broadcasting-조건연산자를 통해 생성한 coord_mask, noobj_mask 두 마스크는 Boolean타입의 [True / False]값만 갖는 행렬이 되는데
이 행렬을
pred_box_1 = pred_boxes[..., 0, :4][coord_mask[..., 0]]
pred_box_2 = pred_boxes[..., 1, :4][coord_mask[..., 1]]
target_box_1 = target_boxes[..., 0, :4][coord_mask[..., 0]]
target_box_2 = target_boxes[..., 1, :4][coord_mask[..., 1]]위 코드처럼 pred_boxes, target_boxes 텐서를
마스크 필터를 통과시켜서
살아남은 자료형 pred_box_1, pred_box_2, target_box_1, target_box_2 4개의 변수를 만든다.
이 변수 자료형의 차원은 필터링 과정을 통해 기존의 4, 5차원을 유지할 수 없기에
(Batch_size X N, 4) 2차원 텐서 자료형이 되며
이때 N은 필터를 통과해 살아남은 행렬의 개수 라고 보면 된다.
4) iou 계산 및 Pred_box 선택
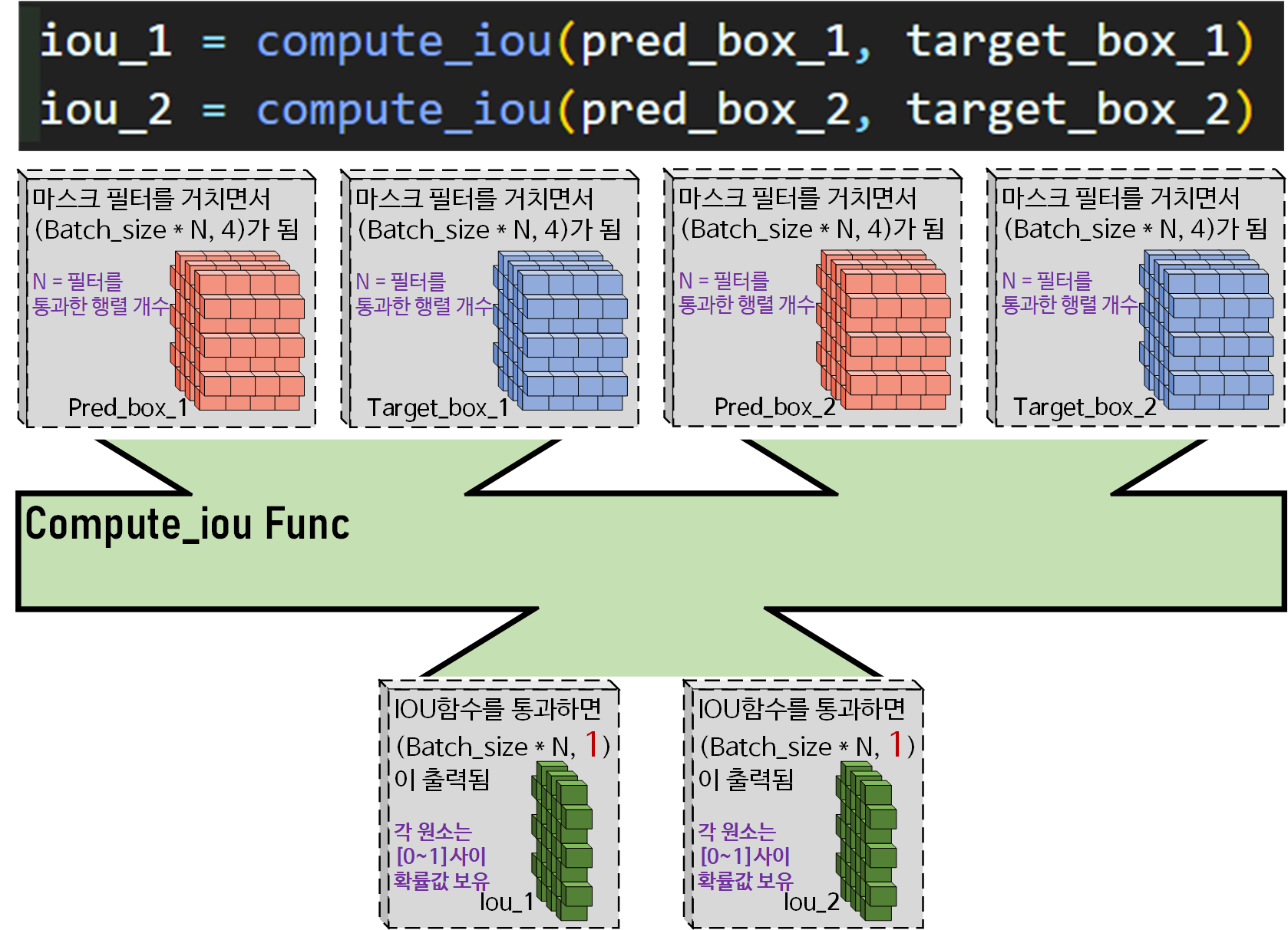
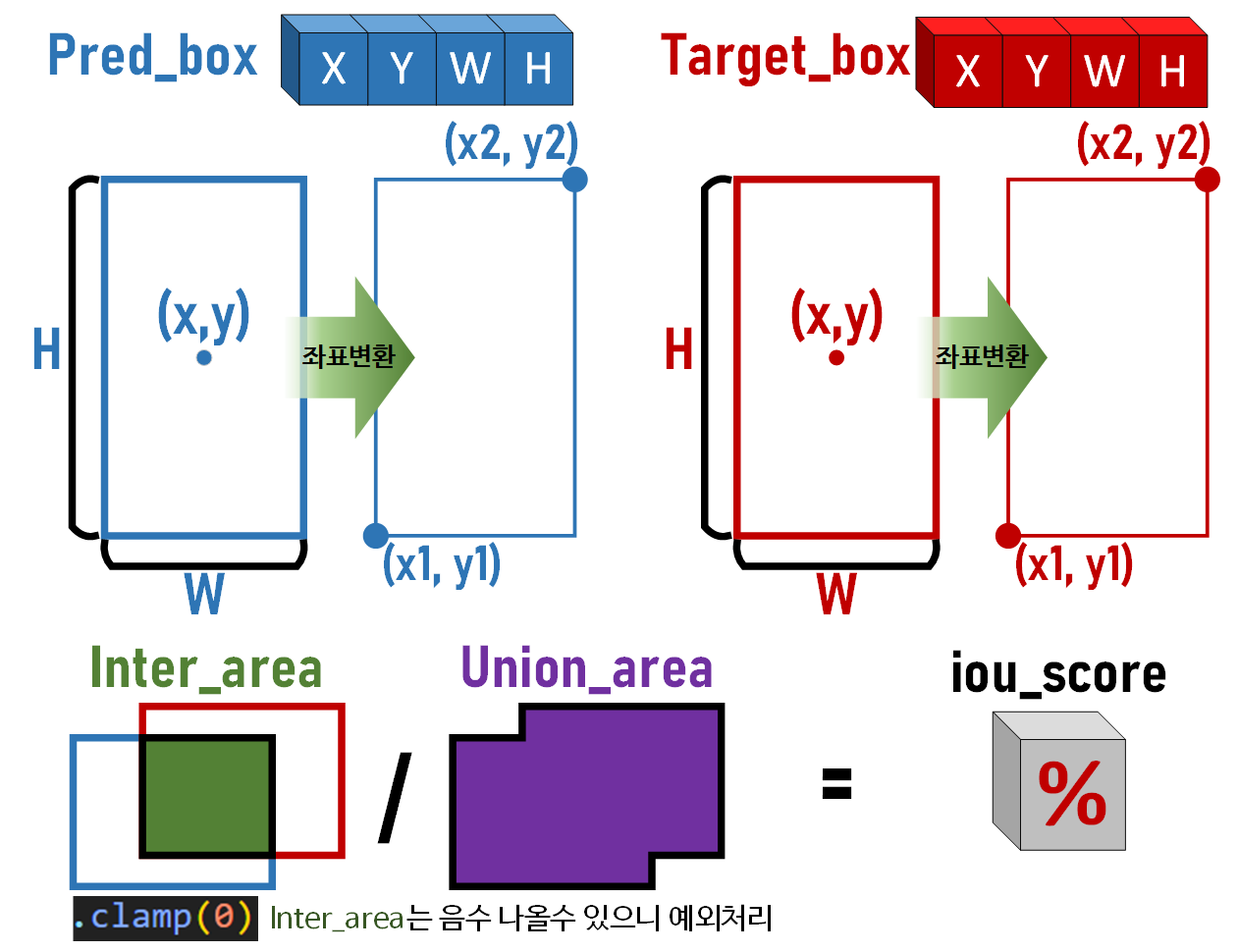
compute_iou 함수는 위 사진처럼 (batch_sizeN, 4)차원을 갖는
각각의 B_Box 텐서를 입력으로 받아
(batch_size,M, 1)차원 형태의 iou 결과값을 출력하며,
이때 iou 결과 텐서의 각 원소값은
[0~1] 사이의 값을 갖는 확률 값이라 보면 된다.
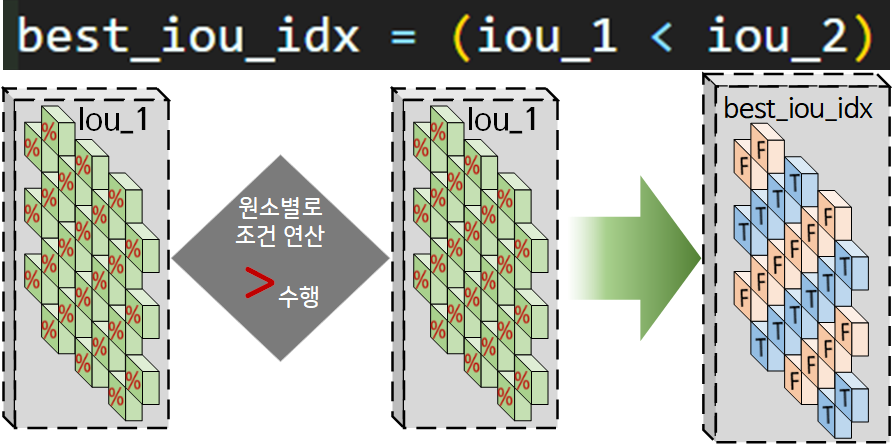 다음으로
다음으로 iou_1, iou_2의 각 원소별 확률값을 비교하여
큰 값, 작은값에 따라 [True or False]이 배정된
새로운 행렬 Best_iou idx를 생성한다.
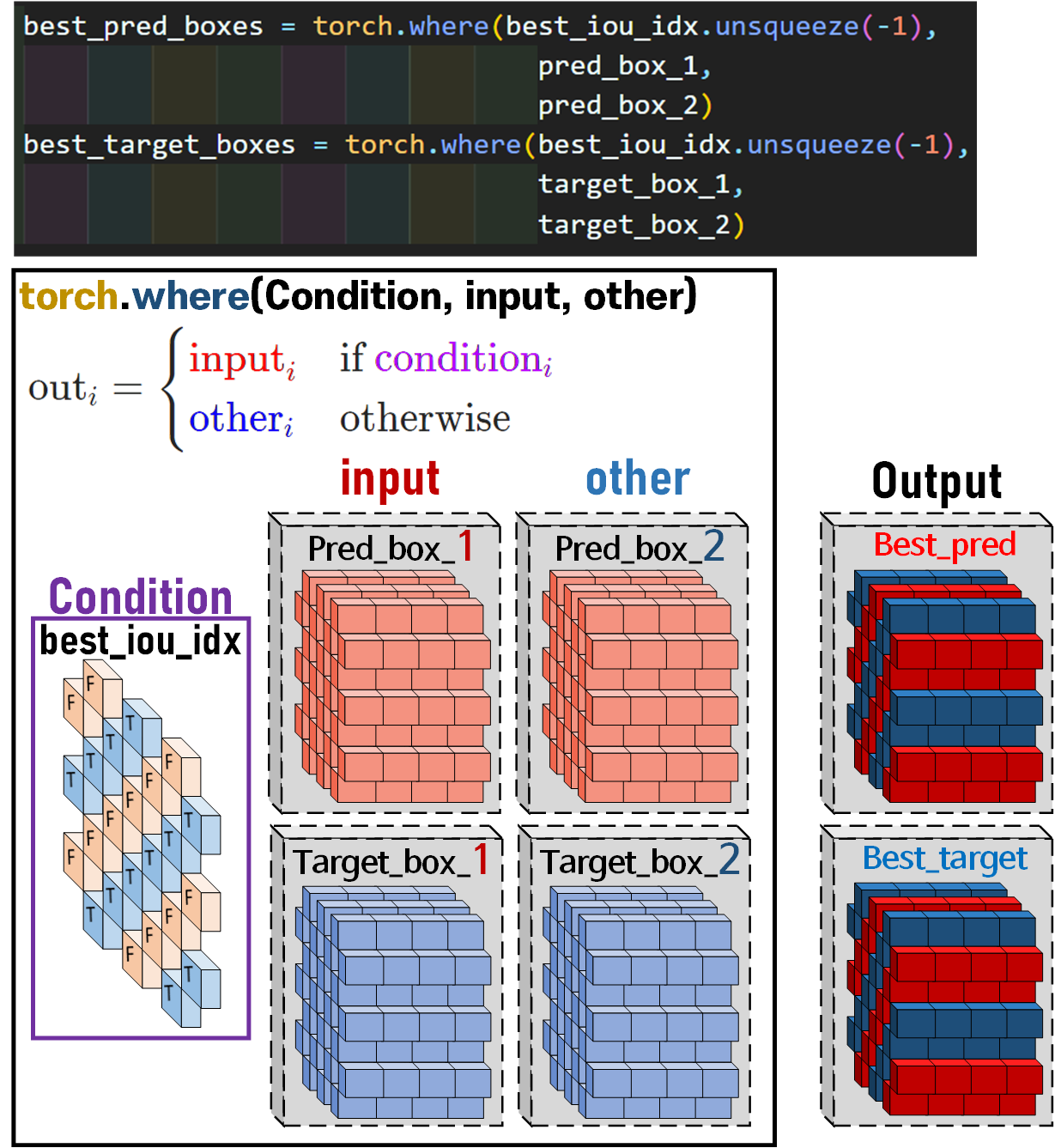
이를 위 그림에서 설명하고 있는 torch.where()메서드를 활용하여
iou_1이 큰 경우에는 input에 해당하는 원소가
iou_2이 큰 경우에는 other에 해당하는 원소를 불러와서
새로운 Tensor 자료형 Best_pred_box, Best_target_box 를 생성한다.
4-1) compute_iou 함수 소개
이 함수의 경우 지금까지 설명한 ...연산 + Broadcasting에 대한 충실한 이해가 있다면 아래의 함수는 무리 없이
해석이 가능할 것이다.
def compute_iou(box1, box2):
# 각 바운딩 박스의 좌표값 [x_1, y_1, x_2, y_2] 생성
box1_x1 = box1[..., 0] - box1[..., 2] / 2
box1_y1 = box1[..., 1] - box1[..., 3] / 2
box1_x2 = box1[..., 0] + box1[..., 2] / 2
box1_y2 = box1[..., 1] + box1[..., 3] / 2
box2_x1 = box2[..., 0] - box2[..., 2] / 2
box2_y1 = box2[..., 1] - box2[..., 3] / 2
box2_x2 = box2[..., 0] + box2[..., 2] / 2
box2_y2 = box2[..., 1] + box2[..., 3] / 2
# 교차 영역의 좌표 계산
inter_x1 = torch.max(box1_x1, box2_x1)
inter_y1 = torch.max(box1_y1, box2_y1)
inter_x2 = torch.min(box1_x2, box2_x2)
inter_y2 = torch.min(box1_y2, box2_y2)
# 교차 영역의 면적계산 -> 교차가 없을 때는 0으로 음수값 방지
inter_area = (inter_x2 - inter_x1).clamp(0) * (inter_y2 - inter_y1).clamp(0)
# 각 바운딩 박스의 면적 계산
box1_area = (box1_x2 - box1_x1) * (box1_y2 - box1_y1)
box2_area = (box2_x2 - box2_x1) * (box2_y2 - box2_y1)
# 합집합 영역 계산
union_area = box1_area + box2_area - inter_area
return inter_area / union_area그래도 코드만 찍 넣으면 예의에 어긋나니
그림으로 표현하도록 하겠다.
5) Localization Loss 계산하기
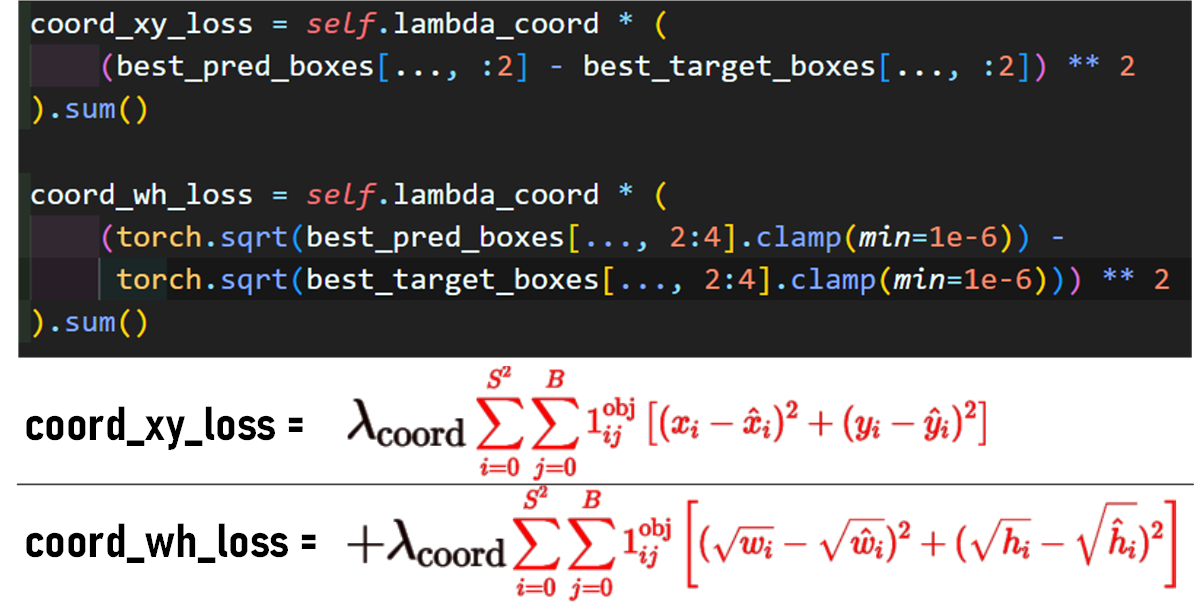
Localization Loss의 계산은 위 코드로 유려하게 수식을 구현할 수 있다.
위 1~4)과정으로 필터링한
pred_box의 [x, y, w, h]좌표정보와
target_box의 [x, y, w, h]좌표정보가 틀어진 정도만
비교하는 함수이다.
필터링이 어려운거지 수식은 어려운게 아니다....
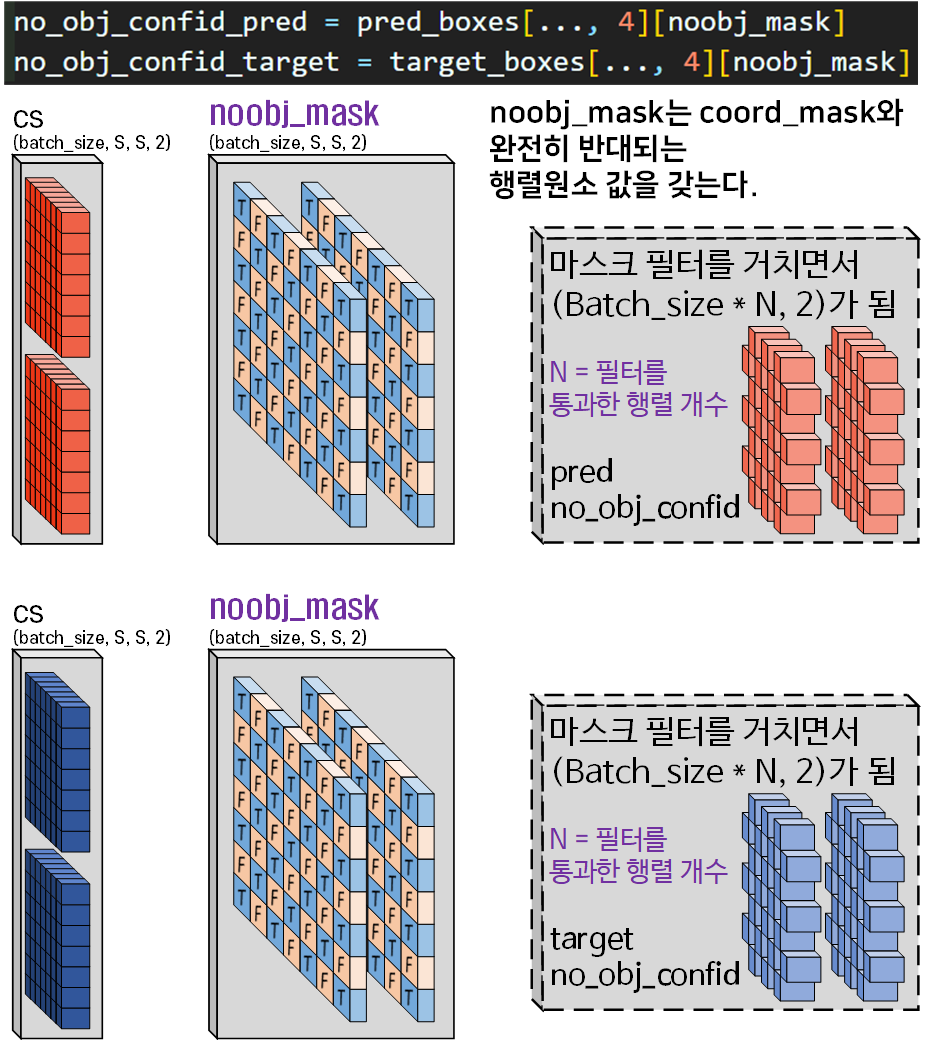
6) Confidence Score 정보 필터링
 앞서 마스크필터
앞서 마스크필터 coord_mask, best_iou_idx 2종에 대해 신나게 생성하는 원리에 대해 설명했고
이것으로 Pred_boxes와 Target_boxes의 [x, y, w, h]정보를 필터링하는 과정에 대해서도
설명이 진행됬으니
동일한 2중의 필터를 [cs]에 적용한다
라고 이해하면 된다.
그리고 (Confidence Loss)를 계산하기 위해서는 한가지 정보가 더 필요한데 위 obj_confid_pred, obj_confid_target가 2중의 필터를 거쳐 승리한 데이터 군 이라면
아에 첫번째 필터인 coord_mask도 통과못한 패배자 데이터 군이 있다.
이 패배자 데이터는 버리는게 아니라
모아서 패자부활전을 한번 한다 생각하면 된다.
그게 아래의 코드다
7) Confidence Loss 계산하기

2종의 필터를 거친 값들 obj_confid, no_obj_confid에 대한 값들을 Confidence Loss을 정의한 수식에 맞춰서
코드구현하면 끝난다.
8) 마스크 필터 합치기 + 적용하기
Classification Loss을 계산하는 것 또한 Confidence Loss, Localization Loss와 동일하게 해당 연산을 수행하는데 필요한
Argument인자를
원시 데이터 마스크 필터 적용 필터링 된 데이터
위 과정을 거쳐서 생성해 내는 과정을 반복하여 수행한다.
이번에는 마스크필터 2개가 사전에 이미 제작이 완료되었으니
편하게 2개의 마스크필터를 합쳐서
새로운 마스크 필터를 만들고
그것으로 한번에 필터링된 데이터를 생성하고자 한다.
 위 사진처럼
위 사진처럼 best_iou_idx 마스크 필터와 coord_mask를 합치는 작업을 수행하며,
필터의 합산 작업에는 torch.where()메서드를 활용하였다.
그리고 이미지를 자세하게 살펴보면 알 수 있겠지만
왜 이 YoloLoss() 클래스가 실패한 함수인지 알 수 있을 것이다.
아무튼 설계 과정에서는 오류를 탐지하지 못했고
오류탐지를 건너 뛴 채로 아무튼
합산된 마스크 필터인 class_mask가 생성되었다.
 이제 위 이미지의 코드처럼
이제 위 이미지의 코드처럼
pred의 클래스 정보 추출 = (Batch_size, S, S, C)
target의 클래스 정보 추출 = (Batch_size, S, S, C)를 수행하고
class_mask를 위 두 데이터셋과 차원일치를 시키기 위해
torch.expand()메서드로 차원확장을 수행한다.
이때 차원확장과 관련된 메서드로
torch.repeat()와 torch.expand()두가지가 있는데
torch.repeat()는 차원확장 + 확장된 차원에 실제 데이터를 복사해서 채워넣음
torch.expand()는 차원을 확장하나, 데이터를 복사하지 않고 메모리 주소만 공유함
의 차이가 있다.
현재의 Task를 수행하는데는 메모리 효율성의 이점을 가져올 수 있는 torch.expand()를 적용했다 보면 된다.
9) Classification Loss 계산하기

여기까지 수행했으니 이제 본격적으로 해당 함수의 실패 사유에 대해 고찰해 보도록 하자
2-1. YoloLoss() 코드오류 고찰
우선 설계한 YoloLoss함수가 재대로 동작하는지?
안 하는지 확인하기 위해서 예제 데이터셋을 만들고
연산 과정 중간중간에 print()구문을 입력하여
차원변환, 필터링이 잘 되고 있는지를 추적했다.
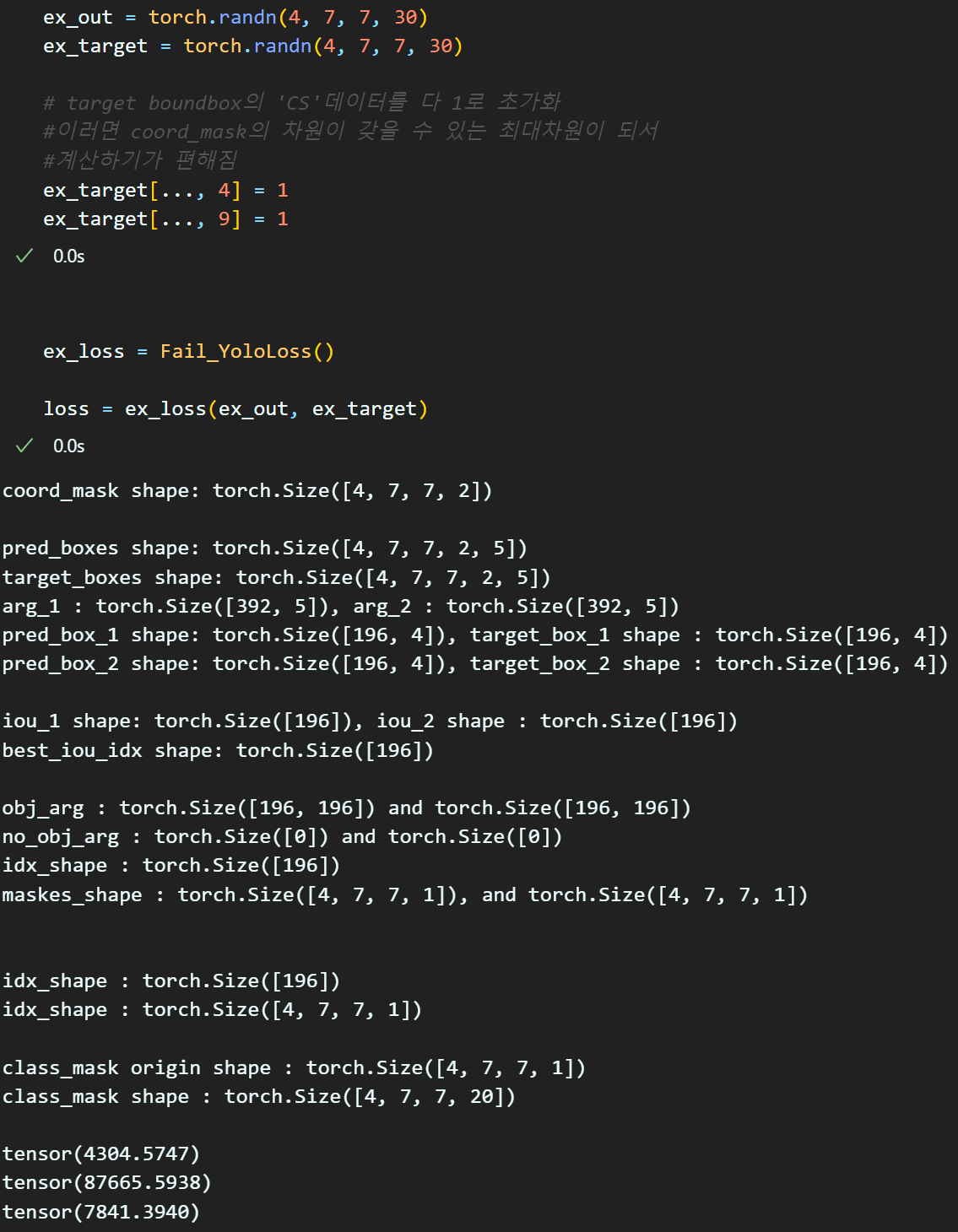
Loss 함수 설계를 하면서 맨 처음 생성하는
coord_mask의 필터링이 진행되면 나머지 필터링 과정에서 차원 연산을 추적하기가 어려운 부분이 있어서
해당 필터를 비활성화 시키는 방법론으로
target의 CS정보를 모두 1로 고정했다.
이상태에서 코드를 설계하고
coord_mask를 활성화 시키기 위해
target의 CS정보를 모두 1로 고정 구문을 비활성화면
아래와 같은 오류가 발생한다.
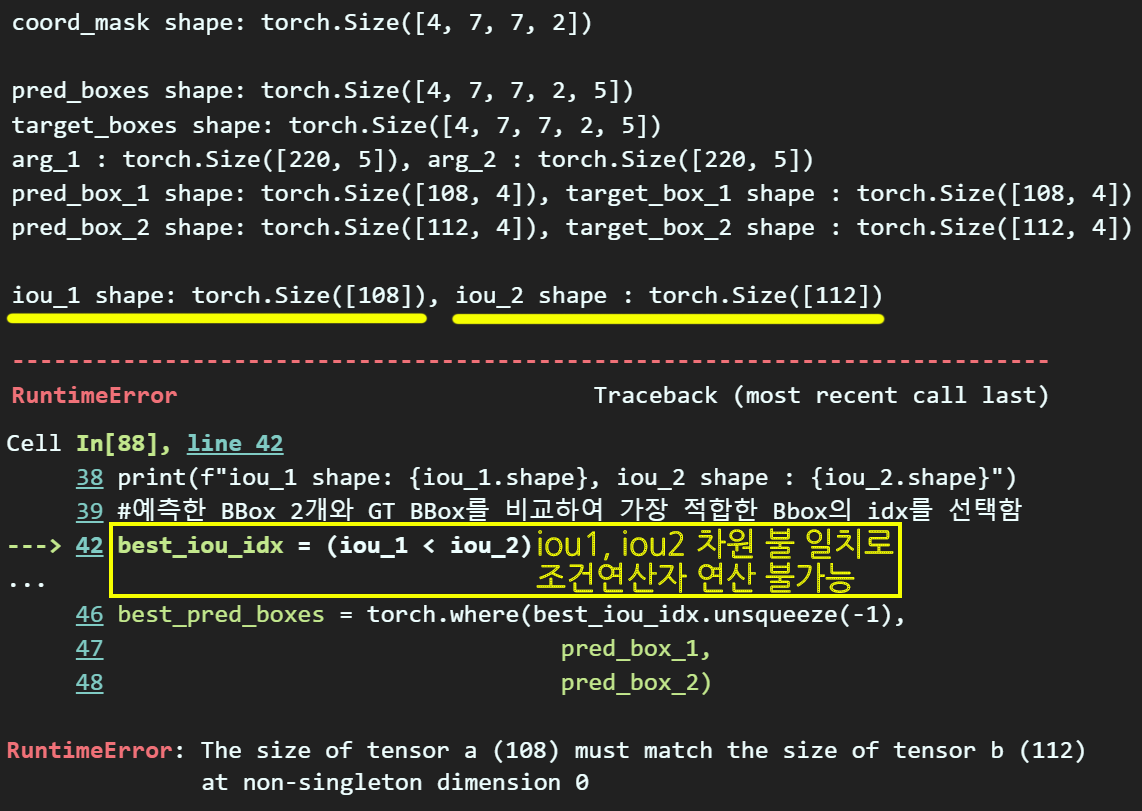
iou_1과 iou_2의 차원이 다르기에 그 이후의 연산이 모두 깨져버리는 것인데
이건 어찌 생각해보면 당연한 것이다.
Yolo v1은 2개의 pred_B_Box 후보군을 만들고
이를 GT_B_Box와 매칭하여
가장 적합한 pred_B_Box를 고르는 것인데
이 선택된 Best_pred_B_Box의 출처가 1번 Pred_B_Box인지 2번 Pred_B_Box인지까지 알 필요가 없다
언제는 1번 Pred_B_Box에서 전부 Best_pred_B_Box로 넘어갈 수도 있고
또 언제는 2번 Pred_B_Box에서 전부 Best_pred_B_Box로 넘어갈 수도 있다.
따라서
best_iou_idx = (iou_1 < iou_2)이 연산으로 idx 정보를 추출한 필터를 만드는 것은 굉장이 위험한 행위라고 볼 수 있다.
그러면 이 문제를 어떻게 해결해야 할까?
필자가 Chat GPT한테 배운 가르침은
iou를 계산하지 말라였다.

3. 성공한 YoloLoss()
Chat GPT가 제시한 아이디어는 다음과 같다.
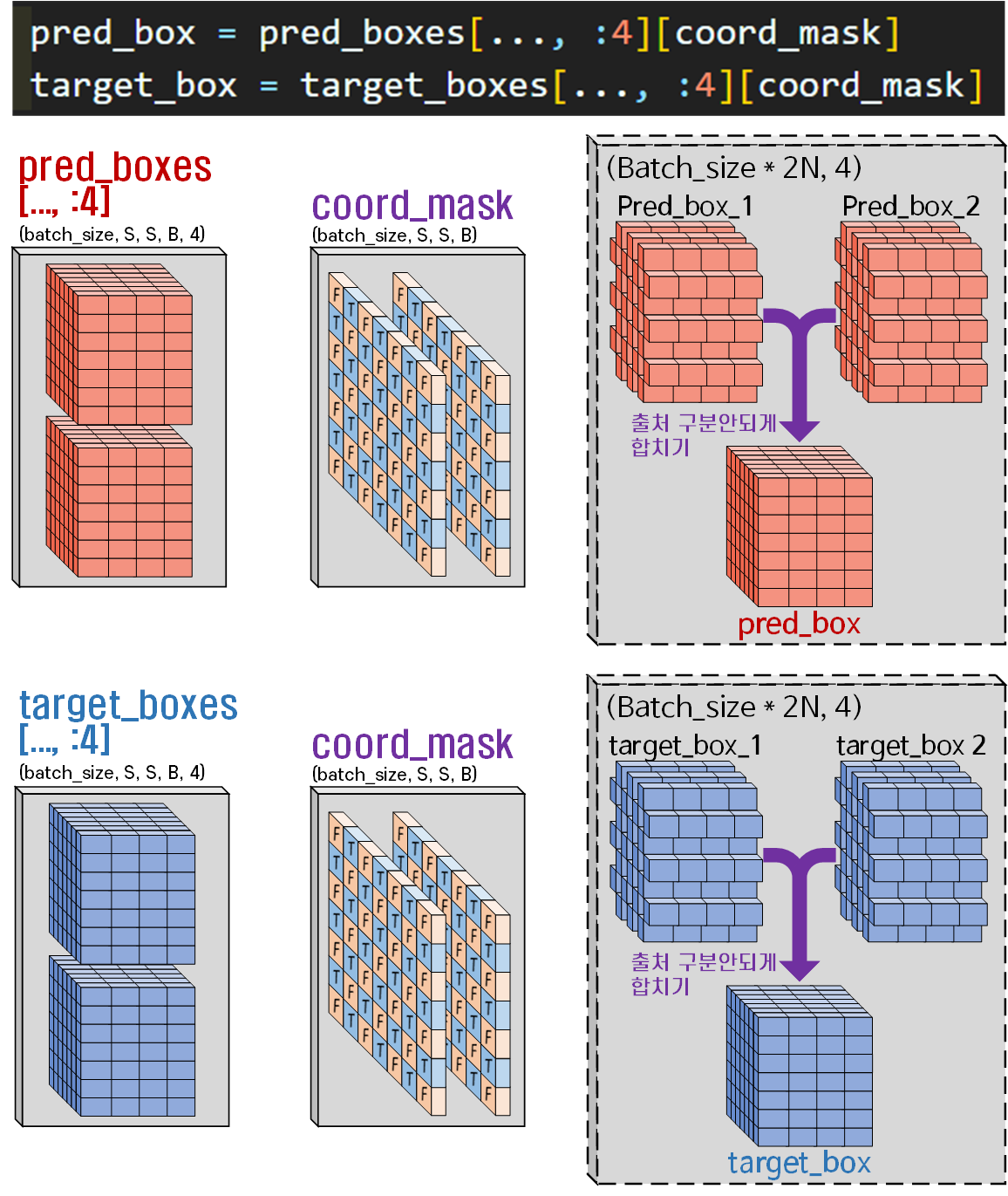 첫번째로 번잡하게 pred_boxes에서 pred_box_1, pred_box_2를 만들지 말고
첫번째로 번잡하게 pred_boxes에서 pred_box_1, pred_box_2를 만들지 말고
출처를 알아볼 수 없게 그냥 섞여버린 pred_box를 만들어 버린다.
같은 내용을 target_boxes targte_box에도 수행한다.
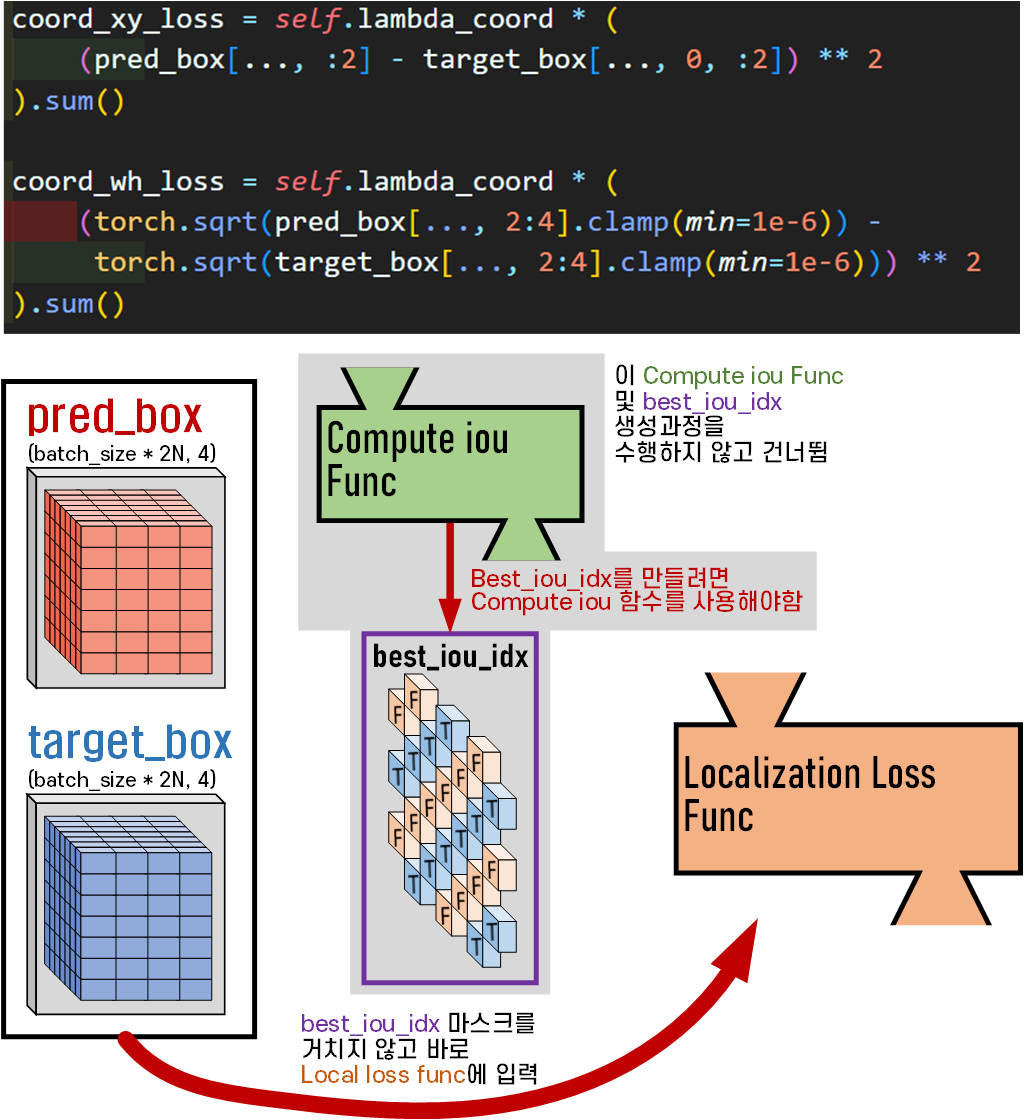 그리고 위 사진처럼
그리고 위 사진처럼 best_iou_idx 마스크를 통해서 가장 최적의 B_Box정보만 Localization Loss 함수에 넘기지 말고 후보군의 B_Box도 Localization Loss함수에 같이 넘겨버리는 방식으로 Loss값을 계산한다.
이렇게 하면 단순하게 생각했을 때 Localization Loss의 값이 2배 늘어나는 단점이 있지만
마스크 필터 2개 쓰는 것을 1개만 쓰게 과정을 축소하면서
발생하는 연산 이점이 많고
어차피 Loss Function은 옵티마이저를 통해 Global Mininum Point(GMP)로 수렴하게 될 것이니
이 B_Box선별 과정 자체를 날려버리자는 제안인 것이다.
 어쨋든 Sequential하게 수행해야 하는 과정을 없애버리고 바로 다음단계로 직행하는 아이디어를 제시받았으니
어쨋든 Sequential하게 수행해야 하는 과정을 없애버리고 바로 다음단계로 직행하는 아이디어를 제시받았으니
이를 그대로 구현을 하고자 한다.
이 best_iou_idx필터를 거치는 과정은 Localization Loss 뿐만 아니라 Confidence Loss를 계산하는 과정에서도 발생하는데
마찬가지로 해당 과정에서도 best_iou_idx필터를 스킵하고 바로 데이터를 입력하는 식으로 코드를 개선한다.
따라서 YoloLoss()의 전체 코드를 붙여넣는다면 아래와 같다.
class YoloLoss(nn.Module):
def __init__(self, S=7, B=2, C=20):
super(YoloLoss, self).__init__()
self.S = S
self.B = B
self.C = C
self.lambda_coord = 5 # 실험적으로 구한 계수값
self.lambda_noobj = 0.5 # 실험적으로 구한 계수값
def forward(self, predictions, target):
# 2) B_Box 추출 및 차원전환
# [Batch_size, S, S, B*5+C] -> [B*2]만 추출 -> [Batch_size, S, S, B, 5]로 차원전환
pred_boxes = predictions[..., :self.B*5].view(-1, self.S, self.S, self.B, 5)
target_boxes = target[..., :self.B*5].view(-1, self.S, self.S, self.B, 5)
# 3) 마스크 필터 생성 [Batch_size, S, S, B]
coord_mask = target_boxes[..., 4] > 0
noobj_mask = target_boxes[..., 4] <= 0
# 예외처리 : coord_mask가 모두 False가 있는 이미지가 존재함
if coord_mask.sum() == 0:
return torch.tensor(0.0, requires_grad=True)
# 3) 마스크 필터를 적용해 데이터 필터링
# pred_box, target_box는 [Batch_size * 2N, 4] 차원을 가짐
# N = 마스크 필터를 통과한 벡터의 개수
pred_box = pred_boxes[..., :4][coord_mask]
target_box = target_boxes[..., :4][coord_mask]
# 더이상 사용하지 않는 compute_iou 함수
iou = compute_iou(pred_box, target_box)
# 5) Localization Loss 계산하기
coord_xy_loss = self.lambda_coord * (
(pred_box[..., :2] - target_box[..., 0, :2]) ** 2
).sum()
coord_wh_loss = self.lambda_coord * (
(torch.sqrt(pred_box[..., 2:4].clamp(min=1e-6)) -
torch.sqrt(target_box[..., 2:4].clamp(min=1e-6))) ** 2
).sum()
# 6) CS(Confidence Score)의 마스크 필터를 활용한 필터링
# obj_confid_pred, obj_confid_target -> [Batch_size * 2N, 1]
obj_confid_pred = pred_boxes[..., 4][coord_mask]
obj_confid_target = target_boxes[..., 4][coord_mask]
# no_obj_confid_pred, no_obj_confid_target -> [Batch_size * 2M, 1]
no_obj_confid_pred = pred_boxes[..., 4][noobj_mask]
no_obj_confid_target = target_boxes[..., 4][noobj_mask]
# 참고로 2N + 2M = S X S 이다.
# 7) Confidence Loss 계산하기
obj_loss = (
(obj_confid_pred - obj_confid_target) ** 2
).sum()
no_obj_loss = self.lambda_noobj * (
(no_obj_confid_pred - no_obj_confid_target) ** 2
).sum()
# 8) CP(Class Probabilities)에 대한 필터링 작업
# [Batch_size, S, S C]으로 추출
pred_classes = predictions[..., self.B*5:].view(-1, self.S, self.S, self.C)
target_classes = target[..., self.B*5:].view(-1, self.S, self.S, self.C)
# expand()메서드를 사용하기 위하여
# [Batch_size, S, S, B] -> [Batch_size, S, S, 1] -> [Batch_size, S, S, C]
# 위 3단계 과정으로 차원 축소 후 차원 확장
# coord_mask[..., 0:1] == coord_mask[..., 1:2] 임을 잊지말자
class_mask = coord_mask[..., 0:1]
class_mask = class_mask.expand(-1, -1, -1, self.C)
# Classification Loss 계산하기
Classification_loss = (
(pred_classes[class_mask] - target_classes[class_mask]) ** 2
).sum()
Localization_loss = coord_xy_loss + coord_wh_loss
Confidence_loss = obj_loss + no_obj_loss
return Classification_loss + Localization_loss + Confidence_loss실패한 YoloLoss()에서 수행한 대부분의 Task는 그대로 대입하여 사용하였으며,
삭제한 절차 + 코드 안정성을 확보하기 위한 예외처리
의 일부 수정이 있고
각 주요 절차는
# 1), 2), 3), 4)......와 같이 각 작업별 라벨링을 붙여놓았다.
이로써 YoloLoss()에 대한 코드구현을 완료했으니
다음 챕터인
Yolo v1용 데이터 전처리 : Pascal VOC 2007
에 대하여 포스팅을 진행하도록 하겠다.
