
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. Pascal VOC 2007 데이터셋
인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (2) Loss 함수 설계 이전 포스트에 이어
Yolo v1논문이 작성된 시점에서 사용된 데이터셋인 PASCAL VOC 2007 데이터셋에 대해 탐구하고 해당 데이터셋을 Yolo v1 모델이 요구하는 입력 요구사항에 맞게 전처리 하는 과정에 대해 포스팅을 이어나가도록하겠다.
먼저 코드 부터 딸깍거리자면
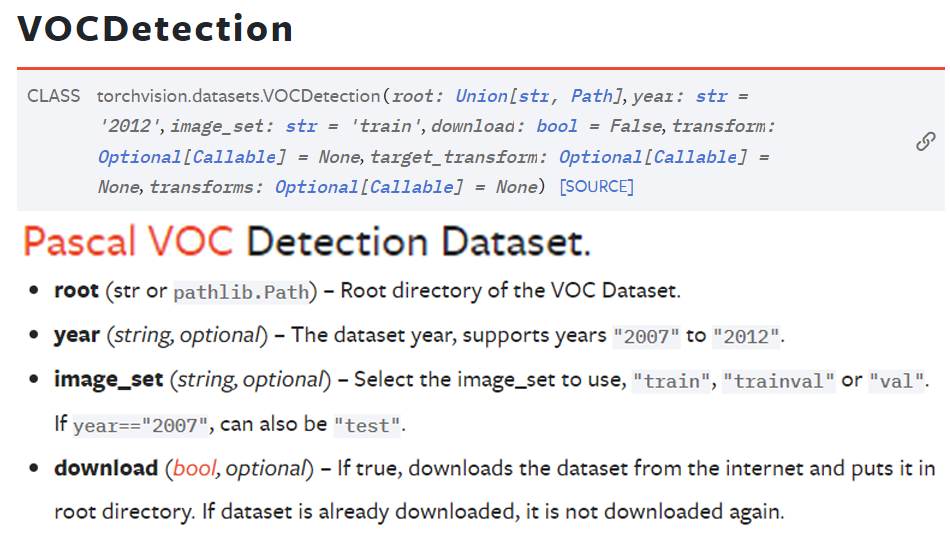 Pytorch의 Torvision API에서
Pytorch의 Torvision API에서 VOCDetection이라는 모듈로 Pascal VOC 2007 데이터셋을 받아서 사용할 수 있으니
해당 모듈을 사용하여
from torchvision import datasets
#Pascal데이터 가져오기
train_dataset = datasets.VOCDetection(root='./data/VOC',
year='2007',
image_set='train',
download=True)
test_dataset = datasets.VOCDetection(root='./data/VOC',
year='2007',
image_set='test',
download=True)from torchvision.transforms import v2
transformation = v2.Compose([
v2.Resize((448, 448)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])from torch.utils.data import DataLoader
BATCH_SIZE = 8
train_loader = DataLoader(proc_train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(proc_test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)이렇게 이전에 사용한 코드처럼
torchvision 데이터셋 다운 전처리 데이터 로더 생성
을 수행하면
모델은 동작하지 않는다.

Torchvision에서 제공하는 기본 데이터셋의 전처리 형태로는
Yolo v1의 입력 요구사항을 만족시킬 수 없는 문제가 있다
그래도 그나마 다행인건
datasets.VOCDetection메서드로 코드가 실행되면 Pascal VOC 데이터셋은 다운로드가 되긴 한다.
그럼 해당 데이터셋을 제공하는 공식 홈페이지에 들어가서 자료를 더 살펴보도록 하자
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html
 홈페이지의 설명에서 이것저것 내용이 있어서 이를 발췌했는데 여기서 중요한 구문은
홈페이지의 설명에서 이것저것 내용이 있어서 이를 발췌했는데 여기서 중요한 구문은
each image has an annotation file giving a bounding box and object class label for each object
으로
각각의 이미지에 있는 객체에 대해서는 Bounding box 정보와 해당 객체의 클레스 레이블을 제공하는데 이것이 Annotation file형태로 제공된다는 점이다.
이를 좀 더 자세하게 알아보자면
해당 데이터셋의 폴더 및 폴더 내 파일 리스트에 대한 구조를 알아야 한다.
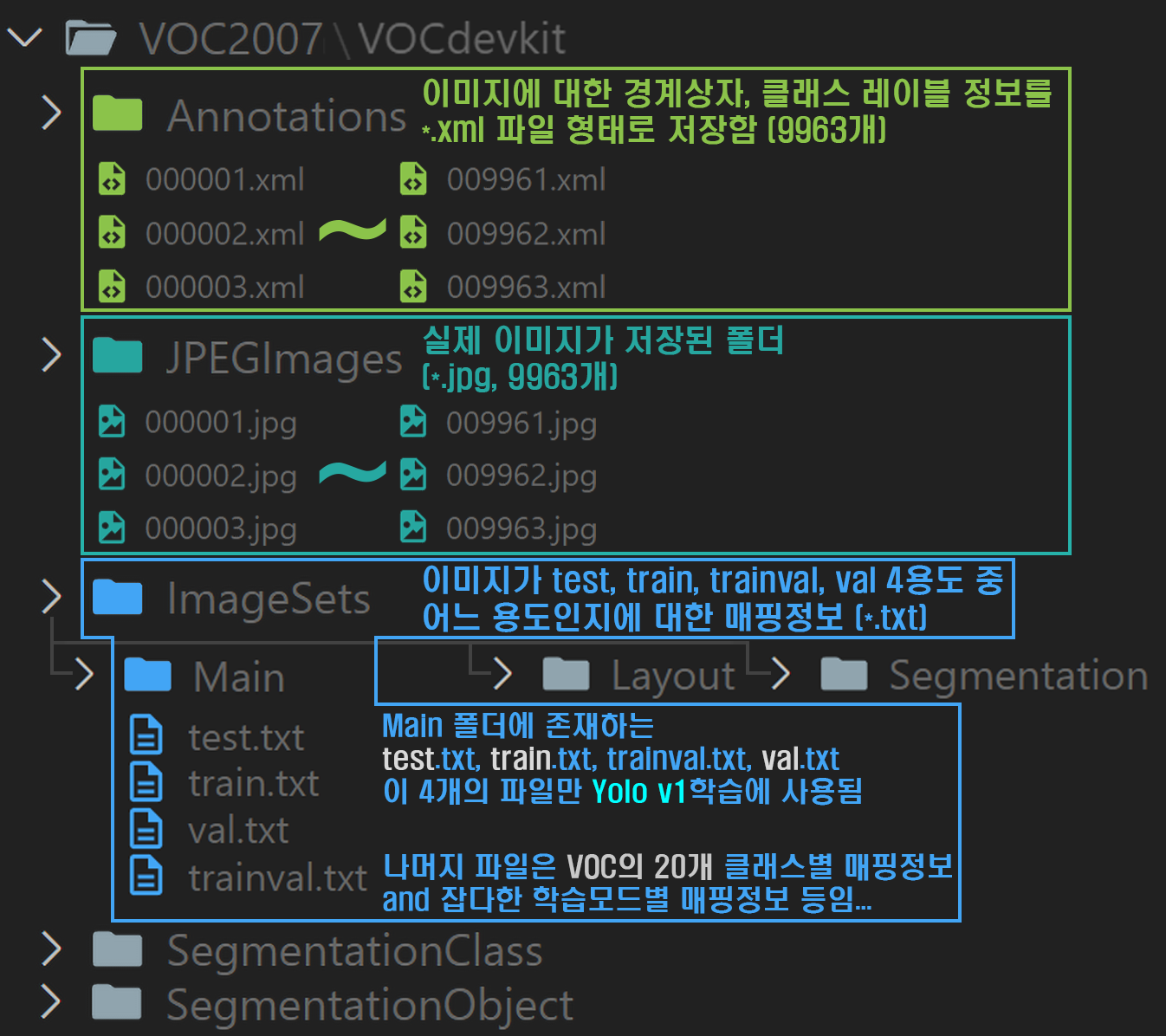 폴더 구성을 Tree형태로 중요한 내용을 나름대로 정리하자면 아래와 같다.
폴더 구성을 Tree형태로 중요한 내용을 나름대로 정리하자면 아래와 같다.
1) JPEGImages
Pascal VOC 2007의 이미지 파일이 담겨있는데 총 파일이 1만장이 안된다. 단순하게 Image Classification만을 수행하는 모델을 훈련/검증 하는 용도로만 사용하기에는
꽤 적은 양이라고 볼 수 있다.
2) Annotations
Pascal VOC 2007의 이미지 파일 수는 적지만 해당 데이터셋이 Computer Vision분야에서 널리 사용되는 주 이유라 볼 수 있는 폴더이다.
약 1만장의 이미지에 포함되어 있는 객체(object)에 대한 주석정보이 담겨있는데 이것이 문서 형식으로 되어 있다.
해당 문서에는 매칭되는 이미지 파일의 기본정보 뿐만 아니라 이미지 파일에 담겨저 있는 Object에 대한 Bounding Box를 생성할 수 있도록 좌표정보가 함께 포함되어 있다.
3) ImageSet
Pascal VOC 2007은 해당 데이터셋을 활용하고자 하는 딥러닝 모델이 요구하는 용도에 맞춰 데이터셋의 '모드'를 설정하는데 관련된 파일이 담겨저 있는 폴더로
크게 3개의 하위 폴더(Main, Layout, Segmentation)로 각각 객체 탐지, 객체 레이아웃, 이미지 분할 작업에 적합한 훈련 성능을 낼 수 있도록 이미지 ID리스트 추천 및 클래스별 데이터 관리 정보를 담고 있다.
설명이 조금 어려운 감이 있는데 현재 포스팅 하고 있는 Yolo v1을 활용한 API설계는 객체 탐지작업에 속하며,
이 작업에 맞는 데이터셋을Pascal VOC 2007을 기반으로 생성하려면 Main폴더의 자료를 참조해야 한다.
Main폴더에는 크게 4개의 파일 text.txt, train.txt, val.txt, trainval.txt이 존재하며 해당 파일을 참조해
각 모드 별로 불러와하는 이미지의 이름 리스트를 알아내야 한다.
예를 들어 Yolo v1의 훈련+검증을 동시에 수행하고 싶다면, trainval.txt 자료를 참조해야 하고
해당 파일에는 약 5000여개의 이미지 ID리스트가 담겨져 있어 이 리스트에 해당하는 이미지를 로드하여 데이터셋을 만들어야 한다.
타 데이터셋의 경우 Test, Val, Train같이 데이터셋 폴더 내부에 서브폴더를 두고 그 아래에 클래스별 서브폴더가 있는 2중구조를 띄는데Pascal VOC 2007는 영리하게 이미지파일을 하나의 폴더에서 관리하고(JPEGImages)이를 모드 별로 적합한 이미지 풀의 생성을 ImageSet폴더 내 *.txt파일의 참조를 통해 수행하게끔 설계되었다
라고 보면 될 듯 하다.
2. CusttomDataset 생성하기
train_dataset = datasets.VOCDetection(root='./data/VOC',
year='2007',
image_set='train',
download=True)
test_dataset = datasets.VOCDetection(root='./data/VOC',
year='2007',
image_set='test',
download=True)torchvision.dataset에서 제공하는 기본 데이터셋 처리 알고리즘으로는 Yolo v1의 입력 요구사항을 준수할 수 없으니
입력 요구사항에 맞는 CustomDataset을 새로이 설계해야 한다.
이때 설계하는 CustomDataset은 3개의 인자값이 꼭 필요한데 이는 아래와 같다.
1) 파일 경로 : root
2) 데이터셋의 모드 설정 : image_set
3) 데이터 전처리 방법론 : transform
그리고 데이터셋의 설계에는 무조건 2개의 매직 메서드 __len__, __getitem__를 정의해줘야 한다.
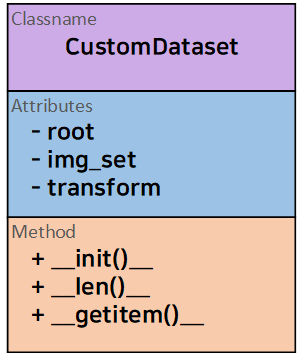 따라서 설계하고자 하는 CustomDatset는 다이어그램으로 표현했을 때 위 구조를 필히 준수해야 한다.
따라서 설계하고자 하는 CustomDatset는 다이어그램으로 표현했을 때 위 구조를 필히 준수해야 한다.
1)
__init__메서드
def __init__(self, root, img_set=None, transform=None, S=7, B=2, C=20):
self.root = root #PascalVOC 메인폴더의 경로
#Main폴더의 4개 텍스트 파일로 설정할 모드(test, train, val, trainval)
self.img_set = img_set
self.transform = transform
self.S = S #Yolo v1의 output feature map dim을 맞추기 위한 계수_1
self.B = B #Yolo v1의 output feature map dim을 맞추기 위한 계수_2
self.C = C #클래스 갯수(VOC2007은 20개)
# 경로 변수
self.anno_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'Annotations')
self.img_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'JPEGImages')
self.filter_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'ImageSets', 'Main')
# 파일 열람시 에러가 나면 이를 저장할 변수
self.annotation_error = None
self.image_error = None
#Yolo v1은 `Annotation`폴더와 `JPEGImages` 두개의 폴더만 참조한다.
try:
self.annotations = os.listdir(self.anno_path)
except Exception as e:
self.annotations = []
self.annotation_error = str(e)
try:
self.images = os.listdir(self.img_path)
except Exception as e:
self.images = []
self.image_error = str(e)
# 모드에 따라 필터링한 anno, image 변수 설정
if img_set is not None:
self.annotations, self.images = self.img_set_mode()코드를 위에서부터 설명하자면
Attribute항목으로 필히 갖추어야 할root, img_set, transform을 선언하고
데이터셋 또한 동적으로 동작할 수 있게끔
S, B, C 항목을 인자값으로 받는다
그리고 경로변수로
anno_path, img_path, filter_path를 받아서
해당 경로변수에 경로명이 재대로 전달된다면
anno_path : ./data/VOC/VOCdevkit/VOC2007/Annoattions
img_path : ./data/VOC/VOCdevkit/VOC2007/JPEGImages
filter_path : ./data/VOC/VOCdevkit/VOC2007/ImageSets/Main
의 경로가 각각 입력될 것이다.
그리고 각 경로에서 필요한 파일 리스트를 서치할 텐데
이때 예의 있게 예외처리 코드를 작성하여
파일 리스트 서치가 실패했을 때
annotation_error, image_error에서 실패사유에 대한 문자열을 출력하도록 하자
마지막으로 파일경로 설정 및 경로 내 파일 리스트를 불러오는 것이 성공하였다면
annotations, images 변수에 호출한 img_set_mode의 결과값을 입력한다.
2) 클래스 함수 : img_set_mode
def img_set_mode(self): #ImageSets에 있는 4개의 txt파일에 기재되어 있는 목록만 필터링 하는 함수
# img_set에 해당하는 txt 파일 열기
img_set_path = os.path.join(self.filter_path, f'{self.img_set}.txt')
try:
with open(img_set_path, 'r') as f:
file_ids = f.read().strip().split()
except Exception as e:
print(f"{self.img_set}.txt 파일을 열 수 없습니다: {e}")
file_ids = []
filtered_annotations = []
for file_id in file_ids:
if f'{file_id}.xml' in self.annotations:
filtered_annotations.append(os.path.join(self.anno_path, f'{file_id}.xml'))
filtered_images = []
for file_id in file_ids:
if f'{file_id}.jpg' in self.images:
filtered_images.append(os.path.join(self.img_path, f'{file_id}.jpg'))
return filtered_annotations, filtered_images이 함수의 작동원리는 그림으로 설명하도록 하겠다.
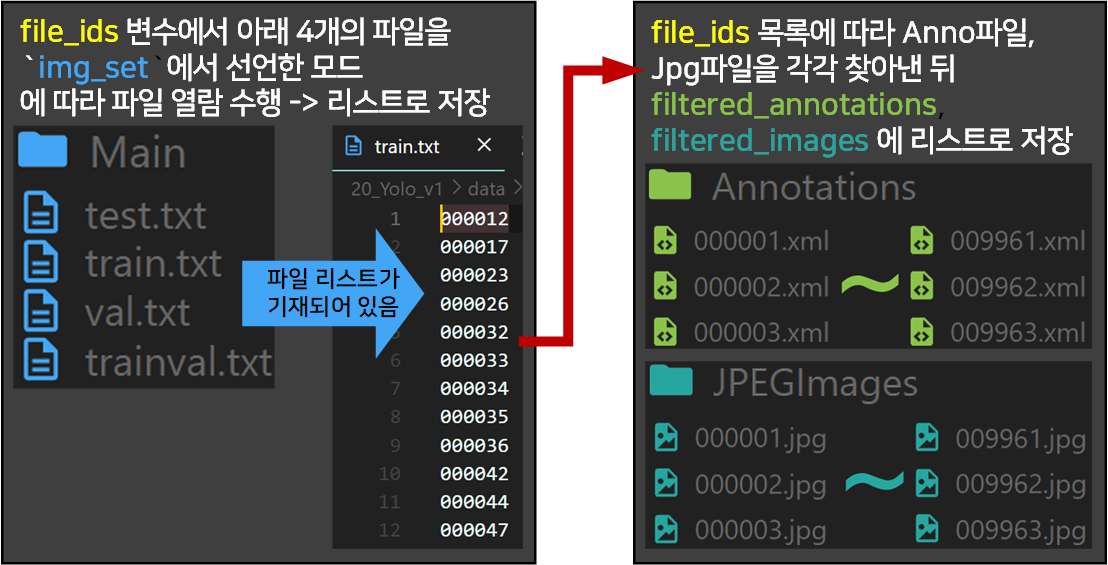
위 함수에는
with open(img_set_path, 'r') as f:구문이 있는데
이해하기 어려운 코드는 아니지만 상세한 원리는 알아두면 편하다
왜냐면 이 with구문은 딥러닝의 평가모드 시 사용되는 코드이기 때문이다.
3) 클래스 함수 : parse_voc_xml 와 ElementTree
이 함수는 __getitem__ 메서드에서
import xml.etree.ElementTree as ET
#XML 데이터 처리용 라이브러리로 뭔가 하기 -> 공부해야함
tree = ET.parse(annotation_path)
root = tree.getroot()
#xml라벨 정보로부터 Boundbox(GT)정보 추출
boxes = self.parse_voc_xml(root)을 통해 호출되는 함수이고, 해당 함수의 기능에 대해 먼저 설명해야 포스팅이 매끄럽게 진행되기에 먼저 설명한다.
def parse_voc_xml(self, node):
boxes = []
for obj in node.findall('object'):
cls_name = obj.find('name').text
if cls_name in VOC_CLASSES:
cls_idx = VOC_CLASSES.index(cls_name)
xml_box = obj.find('bndbox')
x1 = int(xml_box.find('xmin').text)
y1 = int(xml_box.find('ymin').text)
x2 = int(xml_box.find('xmax').text)
y2 = int(xml_box.find('ymax').text)
boxes.append((x1, y1, x2, y2, cls_idx))
return boxes우선 parse_voc_xml를 알기 전 이 함수의 사용에 지대한 영향을 끼치는
xml.etree.ElementTree 라이브러리에 대해 공부를 하자
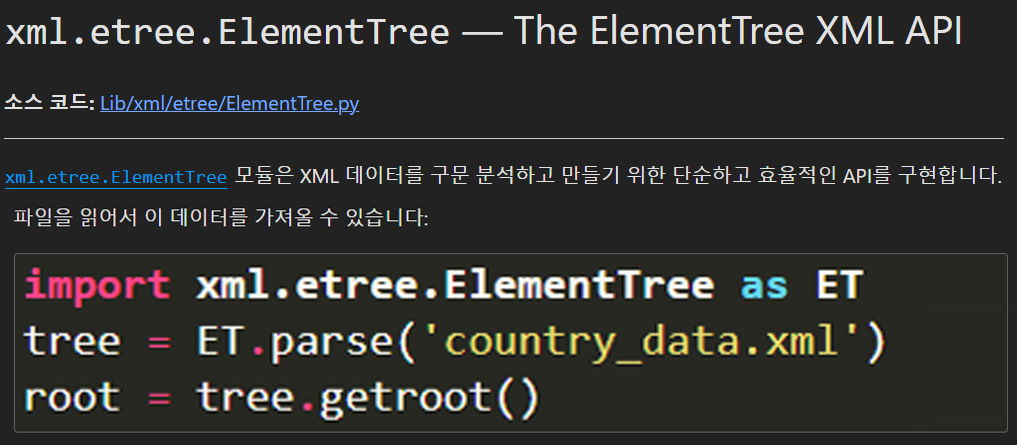 사용방법은 위 코드처럼 xml파일을 불러와서
사용방법은 위 코드처럼 xml파일을 불러와서 .parse를 통해
파일의 파싱 정보를 tree에 저장하고 이걸 다시 .getroot() 메서드로 root에 저장한다.
말이 조금 어려운데...
아무튼 위 코드대로 xml파일을 불러와서 root변수까지 왓으면
불러온 xml파일에 대한 모든 정보가 root변수에 담기는데
이것이 'xml.etree.ElementTree.Element' 자료형으로 담기며, 해당 자료형에서 적절하게 xml의 요소별 접근을 가능하게 해준다...
라고 이해하면 될 것 같다.
이제 이 root로 전처리가 완료됬으니
boxes = self.parse_voc_xml(root)위 코드를 통해 필요한 정보만 필터링해서 boxes에 저장한다 보면 된다.
그러면
def parse_voc_xml(self, node):함수가 수행하는 역할을 예제 파일을 기반으로 확인해보자

parse_voc_xml함수는 xml파일에 기재된 정보에서
Object, name태그를 찾은 뒤
각 태그 내 존재하는 이름정보 및 Bounding box를 그리기 위한 xy 좌표정보를 추출하는 함수라 보면 된다.
여기서 VOC_CLASSES라는 변수를 참조하는데
cls_idx 변수가 찾은 Name정보는 'train'라는 '범주형 데이터이다.
이것을 사전에 선언한
VOC_CLASSES = [
"aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat",
"chair", "cow", "diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
]변수와 매칭하여 정수형 데이터로 전환해준다.
지금의 예시라면 18이란 정수형 데이터로 전환될 것이다.
4)
__getitem__메서드
def __getitem__(self, idx):
#모드에 맞춰 필터링된 이미지, Anno정보를 불러오기
image_path = self.images[idx]
annotation_path = self.annotations[idx]
# 1. 이미지 불러오기 및 변환 적용
image = Image.open(image_path).convert("RGB")
if self.transform:
image = self.transform(image)
# 2. XML 파일에서 어노테이션 정보 불러오기
#비어있는 라벨 메트릭스 만들기
label_matrix = torch.zeros((self.S, self.S, self.C + 5 * self.B))
#xml 처리용 라이브러리로 root에 xml 정보를 저장함
tree = ET.parse(annotation_path)
root = tree.getroot()
#root로 처리된 xml정보로부터 [B_Box용 xy좌표 + 클래스 종류]추출
boxes = self.parse_voc_xml(root)
#root로 처리된 xml정보로부터 이미지의 크기정보 추출
image_width = int(root.find("size/width").text)
image_height = int(root.find("size/height").text)
# 3. 데이터셋을 Tensor자료형으로 전환하기
#바운딩 박스의 좌표 정보를 이미지의 픽셀 단위가 아닌
#이미지의 비율로 해석해서 좌표변환
#[640(w), 480(h)] -> [0~1, 0~1]로 놓고 B_Box를 비율로 표시한다는 뜻
for box in boxes:
xmin, ymin, xmax, ymax, class_idx = box
x_center = (xmin + xmax) / 2 / image_width
y_center = (ymin + ymax) / 2 / image_height
box_width = (xmax - xmin) / image_width
box_height = (ymax - ymin) / image_height
#비율정보로 변환한 center point가 위치하는 그리드셀 탐색
grid_x = int(self.S * x_center)
grid_y = int(self.S * y_center)
# 탐색한 그리드셀이 값이 비어있으면 아래의 정보를 기입함
if label_matrix[grid_y, grid_x, 5*self.B:].sum() == 0:
#class_idx는 0~19의 값을 가지니 해당 idx에 `1`을 넣음
label_matrix[grid_y, grid_x, class_idx+(5*self.B)] = 1
label_matrix[grid_y, grid_x, 0:5] = torch.tensor(
[x_center, y_center, box_width, box_height, 1]
)
label_matrix[grid_y, grid_x, 5:10] = torch.tensor(
[x_center, y_center, box_width, box_height, 1]
)
return image, label_matrix1) 이미지 불러오기 및 변환적용이랑
2) XML파일의 어노테이션 정보 불러오기는
대략 이해가 될 것이다.
문제는 3) 데이터셋을 Tensor 자료형으로 전환하기
이 부분인데 여기는 그림으로 이해하도록 하자.
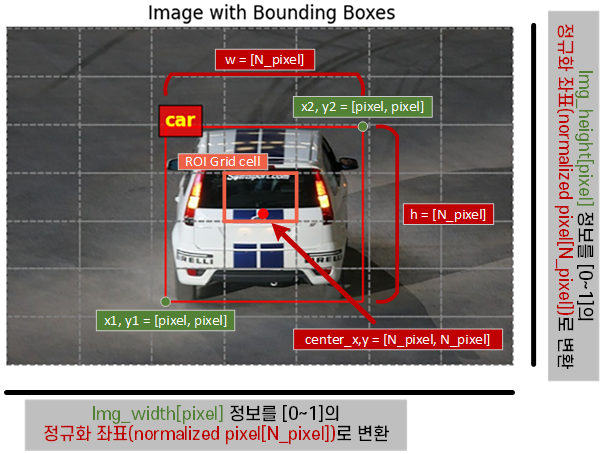 우선 첫번째로 수행하는 작업은 위 사진처럼
우선 첫번째로 수행하는 작업은 위 사진처럼
Annotations 정보로부터 추출한 x1, y1, x2, y2 픽셀 좌표정보를
[0~1]로 정규화한 뒤 이를 바탕으로
[x_center, y_center, w, h]을 채워넣을 때 Normalized pexel정보로 좌표변환을 하여 데이터를 기입한다.
이렇게 B_box 정보를 정규화 하는 이유는 이미지에 transform을 수행할 때 이미지의 크기정보가 변화하기 때문이다.
따라서 변화된 이미지 크기정보에 맞춰 B_Box의 좌표정보도 새롭게 갱신되어야 하니
이 과정에 유연하게 대처하기 위해 정규화 과정을 수행한다.
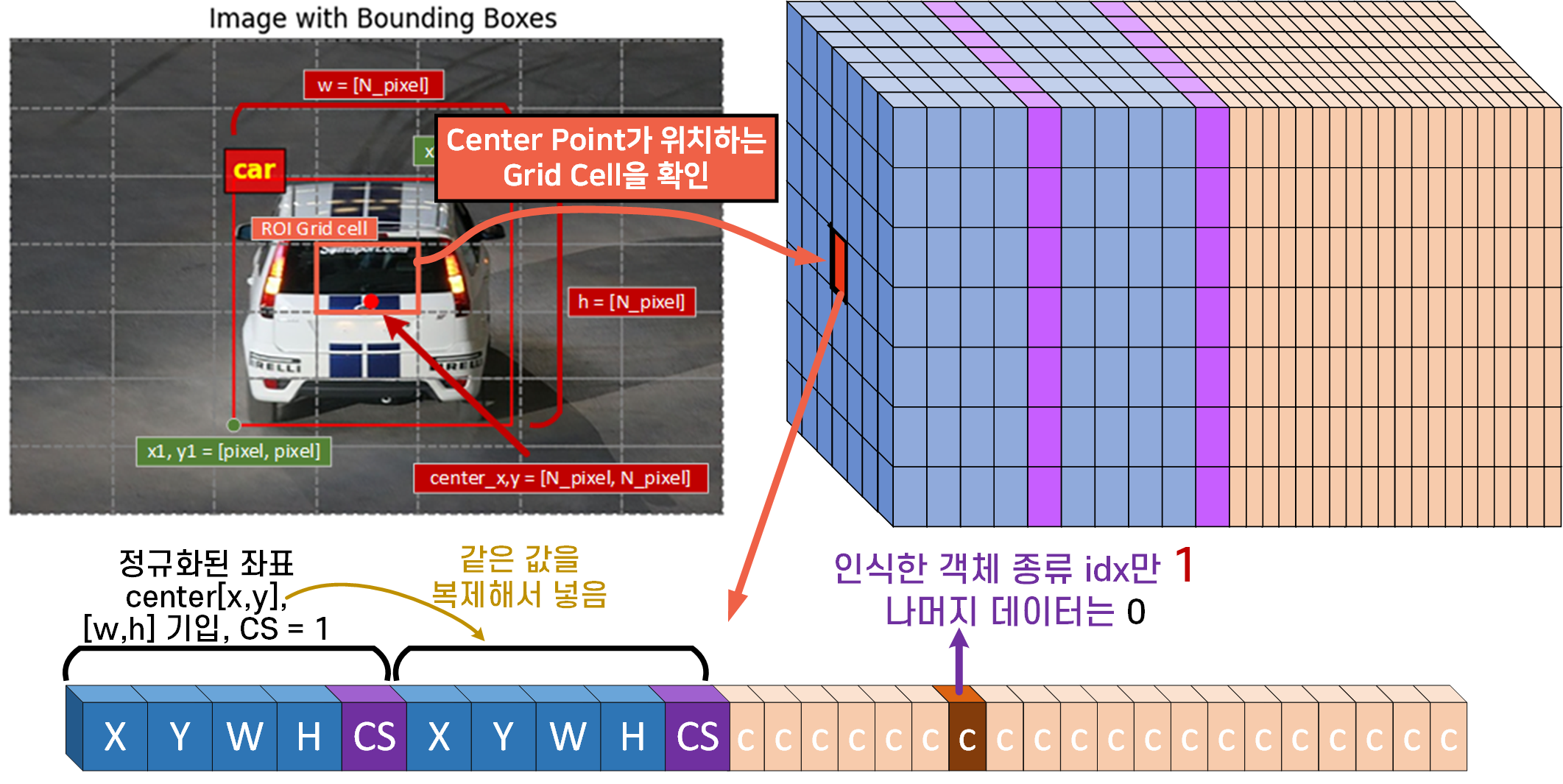 좌표변환을 수행한 뒤에는
좌표변환을 수행한 뒤에는 Center Point가 위치하고
있는 Grid Cell을 불러와서 해당 행렬에
B_Box의 정보를 2번 반복해서 기입
Class 정보가 담기는 cell에 해당 객체 종류의
idx 정수 데이터를 기입한다.
2.1 Customdataset 클래스 전체 코드
중요한 항목들은 모두 설명을 했으니 전체 코드를 첨부하도록 하겠다.
import torch
from torch.utils.data import Dataset
#XML 데이터 처리용 라이브러리
import xml.etree.ElementTree as ET
from PIL import Image
import osVOC_CLASSES = [
"aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat",
"chair", "cow", "diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
]class CustomDataset(Dataset):
def __init__(self, root, img_set=None, transform=None, S=7, B=2, C=20):
self.root = root #PascalVOC 메인폴더의 경로
#Main폴더의 4개 텍스트 파일로 설정할 모드(test, train, val, trainval)
self.img_set = img_set
self.transform = transform
self.S = S #Yolo v1의 output feature map dim을 맞추기 위한 계수_1
self.B = B #Yolo v1의 output feature map dim을 맞추기 위한 계수_2
self.C = C #클래스 갯수(VOC2007은 20개)
# 경로 변수
self.anno_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'Annotations')
self.img_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'JPEGImages')
self.filter_path = os.path.join(root, 'VOCdevkit', 'VOC2007', 'ImageSets', 'Main')
# 파일 열람시 에러가 나면 이를 저장할 변수
self.annotation_error = None
self.image_error = None
#Yolo v1은 `Annotation`폴더와 `JPEGImages` 두개의 폴더만 참조한다.
try:
self.annotations = os.listdir(self.anno_path)
except Exception as e:
self.annotations = []
self.annotation_error = str(e)
try:
self.images = os.listdir(self.img_path)
except Exception as e:
self.images = []
self.image_error = str(e)
# 모드에 따라 필터링한 anno, image 변수 설정
if img_set is not None:
self.annotations, self.images = self.img_set_mode()
def img_set_mode(self): #ImageSets에 있는 4개의 txt파일에 기재되어 있는 목록만 필터링 하는 함수
# img_set에 해당하는 txt 파일 열기
img_set_path = os.path.join(self.filter_path, f'{self.img_set}.txt')
try:
with open(img_set_path, 'r') as f:
file_ids = f.read().strip().split()
except Exception as e:
print(f"{self.img_set}.txt 파일을 열 수 없습니다: {e}")
file_ids = []
# img_set의 텍스트 파일에 기재된 파일 리스트와 매칭되는 anno, img 파일 리스트 불러오기
filtered_annotations = []
for file_id in file_ids:
if f'{file_id}.xml' in self.annotations:
filtered_annotations.append(os.path.join(self.anno_path, f'{file_id}.xml'))
filtered_images = []
for file_id in file_ids:
if f'{file_id}.jpg' in self.images:
filtered_images.append(os.path.join(self.img_path, f'{file_id}.jpg'))
return filtered_annotations, filtered_images
def __len__(self):
return len(self.images)
#예의 바르게 해당 클래스의 실행 결과를 불러오자
def __str__(self):
if self.annotation_error:
anno_cnt = f"Anno폴더 열람 실패 : {self.annotation_error}"
else:
anno_cnt = f"Anno폴더에서 찾은 *.xml파일 개수 : {len(self.annotations)}"
if self.image_error:
img_cnt = f"Img폴더 열람 실패 : {self.image_error}"
else:
img_cnt = f"Img폴더 찾은 *.JPG파일 개수 : {len(self.images)}"
return f"{anno_cnt}\n{img_cnt} "
def parse_voc_xml(self, node):
boxes = []
for obj in node.findall('object'):
cls_name = obj.find('name').text
if cls_name in VOC_CLASSES:
cls_idx = VOC_CLASSES.index(cls_name)
xml_box = obj.find('bndbox')
x1 = int(xml_box.find('xmin').text)
y1 = int(xml_box.find('ymin').text)
x2 = int(xml_box.find('xmax').text)
y2 = int(xml_box.find('ymax').text)
boxes.append((x1, y1, x2, y2, cls_idx))
return boxes
def __getitem__(self, idx):
#모드에 맞춰 필터링된 이미지, Anno정보를 불러오기
image_path = self.images[idx]
annotation_path = self.annotations[idx]
# 1. 이미지 불러오기 및 변환 적용
image = Image.open(image_path).convert("RGB")
if self.transform:
image = self.transform(image)
# 2. XML 파일에서 어노테이션 정보 불러오기
#비어있는 라벨 메트릭스 만들기
label_matrix = torch.zeros((self.S, self.S, self.C + 5 * self.B))
#xml 처리용 라이브러리로 root에 xml 정보를 저장함
tree = ET.parse(annotation_path)
root = tree.getroot()
#root로 처리된 xml정보로부터 [B_Box용 xy좌표 + 클래스 종류]추출
boxes = self.parse_voc_xml(root)
#root로 처리된 xml정보로부터 이미지의 크기정보 추출
image_width = int(root.find("size/width").text)
image_height = int(root.find("size/height").text)
# 3. 데이터셋을 Tensor자료형으로 전환하기
#바운딩 박스의 좌표 정보를 이미지의 픽셀 단위가 아닌
#이미지의 정규화 좌표로 변환함
#[640(w), 480(h)] -> [0~1, 0~1]로 놓고 B_Box를 비율로 표시한다는 뜻
for box in boxes:
xmin, ymin, xmax, ymax, class_idx = box
x_center = (xmin + xmax) / 2 / image_width
y_center = (ymin + ymax) / 2 / image_height
box_width = (xmax - xmin) / image_width
box_height = (ymax - ymin) / image_height
#정규화좌표평면에서 center point가 위치하는 그리드셀 탐색
grid_x = int(self.S * x_center)
grid_y = int(self.S * y_center)
# 탐색한 그리드셀이 값이 비어있으면 아래의 정보를 기입함
if label_matrix[grid_y, grid_x, 5*self.B:].sum() == 0:
#class_idx는 0~19의 값을 가지니 해당 idx에 `1`을 넣음
label_matrix[grid_y, grid_x, class_idx+(5*self.B)] = 1
label_matrix[grid_y, grid_x, 0:5] = torch.tensor(
[x_center, y_center, box_width, box_height, 1]
)
label_matrix[grid_y, grid_x, 5:10] = torch.tensor(
[x_center, y_center, box_width, box_height, 1]
)
return image, label_matrix위 클래스에서 __str__메서드가 존재하는데 해당 클래스의 결과를 출력할 때 사용하는 예의 바른 코드라 보면 된다.
이 메서드에 대한 자세한 설명은 아래의 영상을 참조하자
이제 설계를 완료한 Customdataset 클래스에 대한 diagram을 업데이트하면 아래와 같아진다

train_dataset = CustomDataset(root='./data/VOC', img_set='trainval')
test_dataset = CustomDataset(root='./data/VOC', img_set='val')
print(train_dataset)
print(test_dataset)Anno폴더에서 찾은 *.xml파일 개수 : 5011
Img폴더 찾은 *.JPG파일 개수 : 5011
Anno폴더에서 찾은 *.xml파일 개수 : 2510
Img폴더 찾은 *.JPG파일 개수 : 2510 모드설정은 train모드로 하려다가 해당 모드의 이미지 리스트가 2500개밖에 안되서 좀 더 많은 리스트가 담긴 trainval로 설정하고 데이터셋의 전처리를 수행한다.
3. Dataloader 생성
사실 위 2. Customdataset 과정을 완료했다면
다 끝난 이야기이긴 하다.
from torchvision.transforms import v2
VOC_VAL = [[0.485, 0.456, 0.406], [0.229, 0.224, 0.225]]
transforamtion = v2.Compose([
v2.Resize((448, 448)), #이미지 크기를 448, 448로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=VOC_VAL[0], std=VOC_VAL[1]) #데이터셋 정규화
])
#전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtion이렇게 전처리 방법론 적용시켜주고
from torch.utils.data import DataLoader
BATCH_SIZE = 16
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)데이터로더까지 만들어주는 과정은
이전 코드와 똑같기 때문이다.
참고로 Yolo v1의 Backbone인 DarkNet은 이전 포스트에서도 밝혔다 싶이 파라미터가 개수가 2억7천만개 정도 되기에
필자의 Local PC는 대략 16개의 배치사이즈로 설정해야 가장 뽑아먹을 수 잇는 성능으로 학습/검증이 가능햇다.
마지막으로 데이터로더가 잘 설계됫는지
예의 바르게 검토를 수행하자
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"라벨 크기: {labels.size()}")
print(f"첫 번째 이미지의 라벨: {labels[0].shape}")
print(f'라벨의 데이터타입 : {labels[0].dtype}')
else:
print(f"라벨 크기: {len(labels)}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
print(f'라벨의 데이터타입 : {type(labels[0])}')
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break
# train_loader 정보 출력
print_dataloader_info(train_loader, "Train Loader")
# test_loader 정보 출력
print_dataloader_info(test_loader, "Test Loader")Train Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([8, 3, 448, 448])
라벨 크기: torch.Size([8, 7, 7, 30])
첫 번째 이미지의 라벨: torch.Size([7, 7, 30])
라벨의 데이터타입 : torch.float32
Test Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([8, 3, 448, 448])
라벨 크기: torch.Size([8, 7, 7, 30])
첫 번째 이미지의 라벨: torch.Size([7, 7, 30])
라벨의 데이터타입 : torch.float32이제 [입력처리 [백본 모델 정의] 까지 완료했다.
이제 마지막 [출력처리]를 향해 나아가도록 하자.

