
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. Yolo v3
이전 포스트 인공지능 고급(시각) 강의 예습 - 19. Yolo v1
에서 필자는 맨땅에 헤딩하는 방식으로
Yolo v1의 Backbone Net인 DarkNet을 설계하고 이를 활용하여 Yolo v1의 Image Detection Task를 수행하고자 했다.
하지만 학습/검증 후 평가지표에 따른 성능을 출력해본 결과
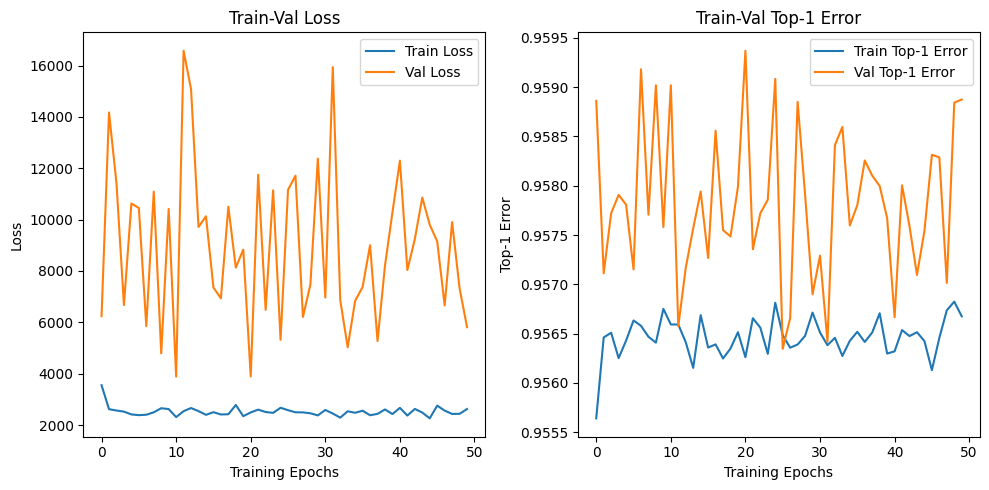
아에 학습이 진행되지 않음을 확인했고
논문에서도
 사용한
사용한 DarkNet의 경우 ImageNet데이터셋으로 사전학습이 된 모델을 사용했음을 명시하고 있다.
따라서 필자는 학습되지 않은 DarkNet을 활용해 Yolo v1을 활용하려 했으니 당연히 제 성능을 낼 수 없어서
추론 단계는 건너뛰었다.
이제
인공지능 고급(시각) 강의 복습 - 21. 주요 CNN알고리즘 구현 : (2) 전이학습과 미세조정 포스트를 통해
전이학습과 미세조정의 개념이 나름 사용가능한 수준으로 탑재가 되었기에
Yolo v3을 기반으로 재대로 된 Image Detection Task를 수행해 보고자 한다.

참으로 두렵지 아니하지 않을 수 없다.
일단 Yolo v3논문에 나와있는 Backbone Net이 무엇인지 확인해보자
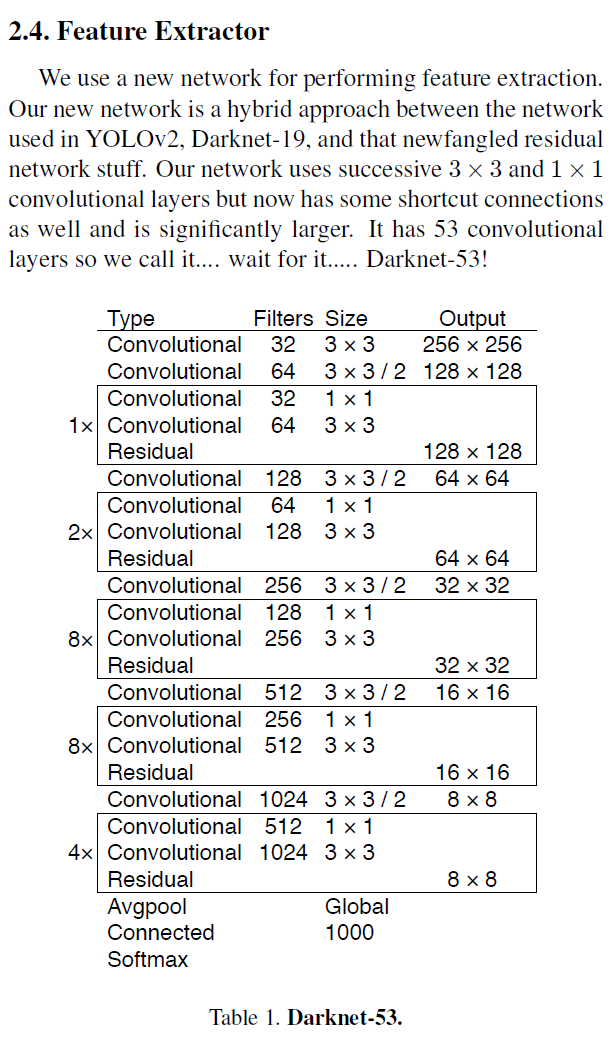 논문에 기재되어 있는 Yolo v3의 Backbone Net은
논문에 기재되어 있는 Yolo v3의 Backbone Net은 DarkNet-53인 것으로 확인된다.
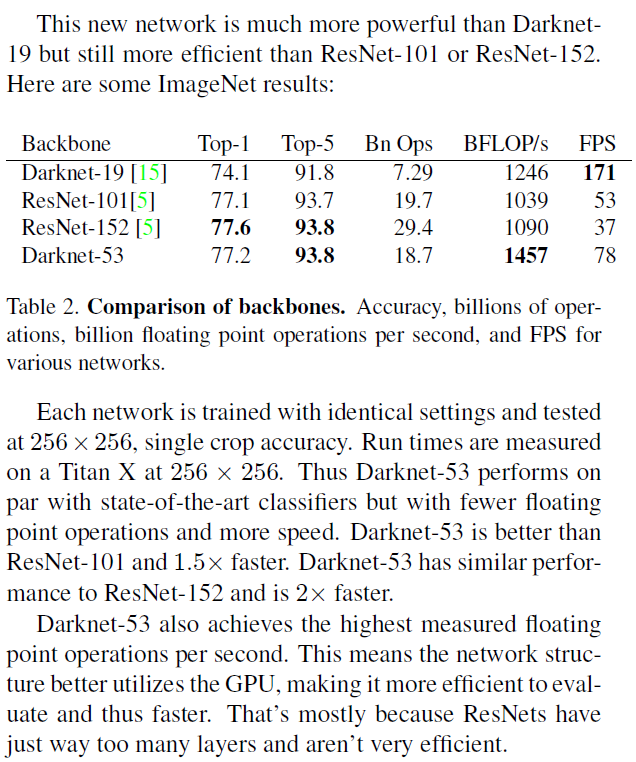 그리고
그리고 DarkNet-53의 성능을 Yolo-v2의 Backbone Net인 DarkNet-19와 두 네트워크와 같은 계열에 속하는 ResNet과의 성능평가를 수행한 결과를 같이 첨부했다.
그러나 이 DarkNet-53의 성능이 좋다는 것이 중요한 것이 아니라 다른 내용이 더 중요하다
바로 DarkNet-53은 ImageNet으로 사전학습이 수행되었으며, 이때 이미지의 전처리는 [3x256x256]으로 했다는 것이다.
뭐 어떻게 진행되었는지는 확인했으니
DarkNet-53의 모델 설계를 먼저 수행하자
2. DarkNet-53 모델 설계
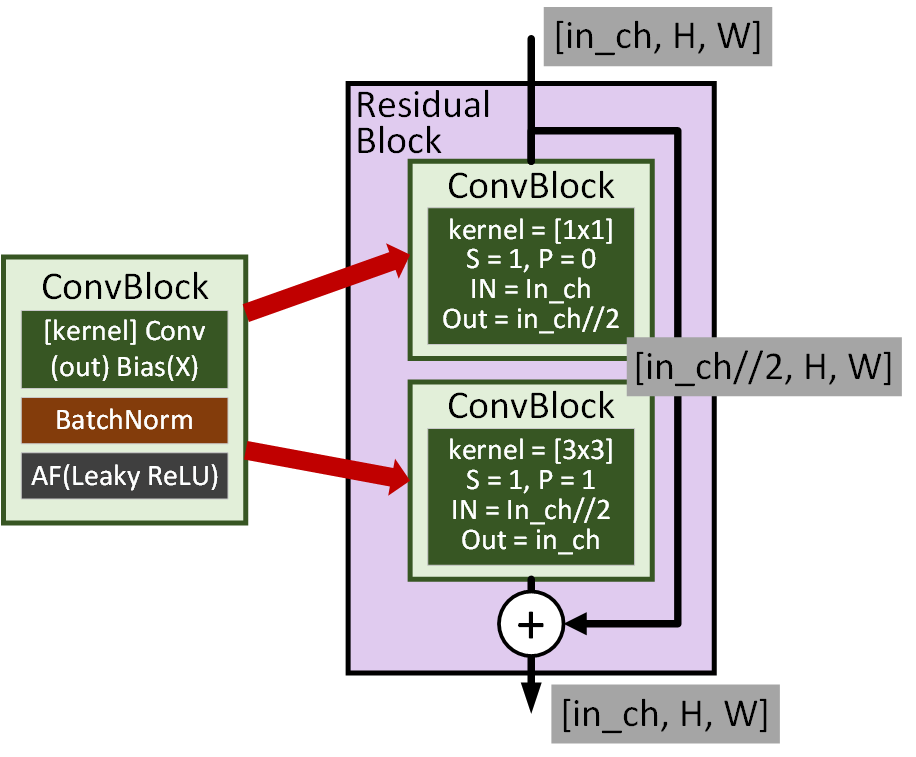 기본 블록의 경우 위 사진처럼 ConvBlock는
기본 블록의 경우 위 사진처럼 ConvBlock는
conv BN AF 순이며, 이때 AF는 Lealy ReLU를 사용했다.
그리고 해당 기본블록을 활용하여 Residual Block을 생성한다. 이 Residual Block은 내부에 ConvBlock이 2개가 존재하는데 앞단은 [1x1]커널로, 뒷단은 [3x3]커널이 붙어있는 구조이다.
이때 Residual Block의 입력, 출력, 중간단계의 Feature Map 차원이 어떻게 변화하는지를 유의하도록 하자
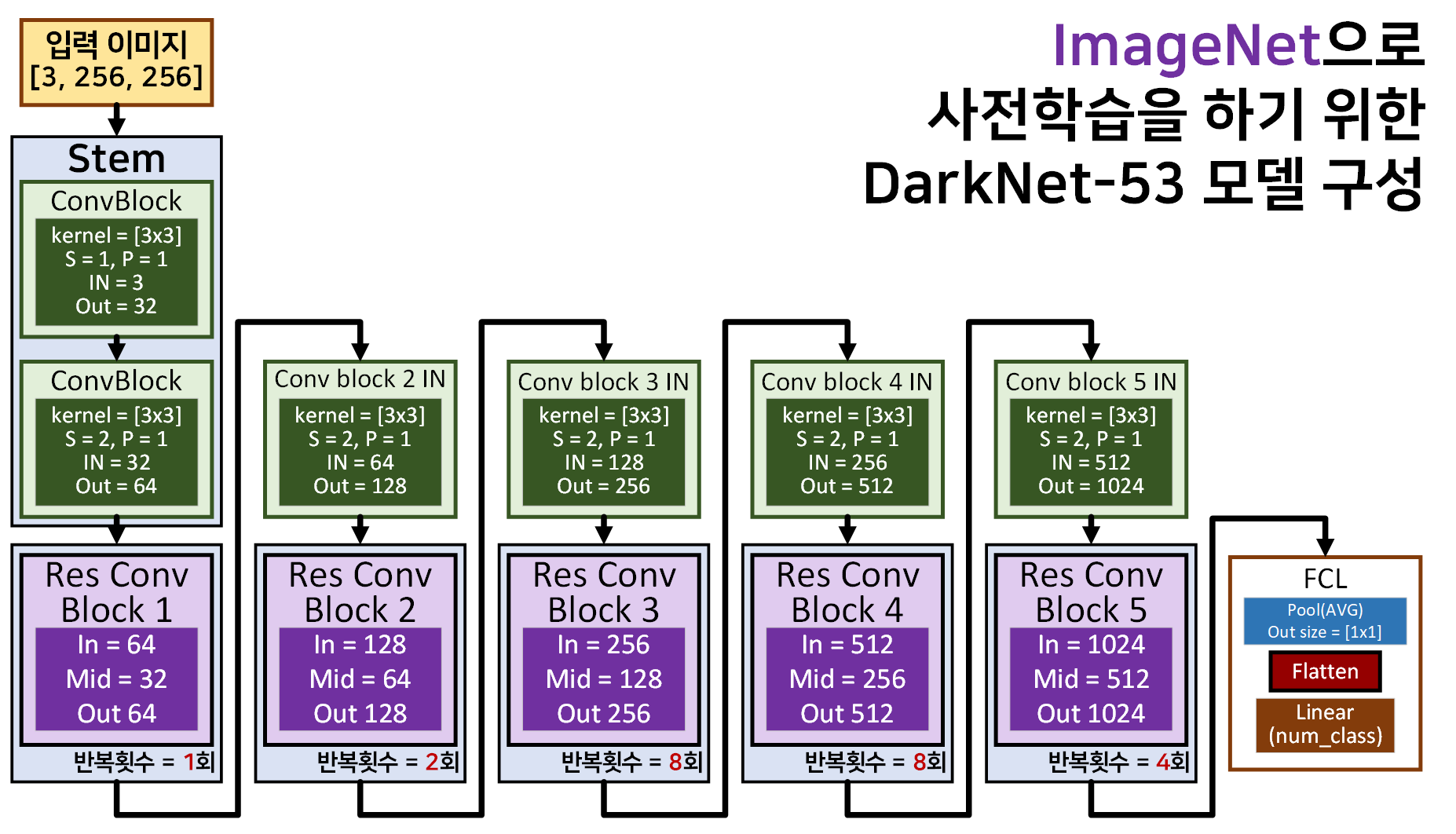 위 기본블록을 바탕으로
위 기본블록을 바탕으로 DarkNet-53을 도식화 한다면 위 사진과 같다.
참고로 위 블록 도식도는 ImageNet으로 사전학습을 수행하기 위한 구조임을 유의하자.
이후 Yolo v3API도입하는 과정에서 모델의 구조는 변하지 않지만 추가적인 작업이 발생하니 이 도식도를 기억해 두는 것이 좋다.
이제 위 도식도를 코드로 구현하도록 하겠다.
import torch
import torch.nn as nnclass BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
#conv2의 default stride=1, padding=0임을 잊지말자
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.LeakyReLU(0.1, inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return xclass Residual_block(nn.Module):
def __init__(self, in_channels, **kwargs):
super(Residual_block, self).__init__()
self.conv1 = BasicConv2d(in_channels, in_channels // 2, kernel_size=1)
self.conv2 = BasicConv2d(in_channels // 2, in_channels, kernel_size=3, padding=1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out += identity
return outclass Darknet53(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(Darknet53, self).__init__()
self.stem = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size=3, stride=1, padding=1),
BasicConv2d(32, 64, kernel_size=3, stride=2, padding=1)
)
self.res_conv_1 = self._make_layer(64, 1)
self.conv_2_in = BasicConv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.res_conv_2 = self._make_layer(128, 2)
self.conv_3_in = BasicConv2d(128, 256, kernel_size=3, stride=2, padding=1)
self.res_conv_3 = self._make_layer(256, 8)
self.conv_4_in = BasicConv2d(256, 512, kernel_size=3, stride=2, padding=1)
self.res_conv_4 = self._make_layer(512, 8)
self.conv_5_in = BasicConv2d(512, 1024, kernel_size=3, stride=2, padding=1)
self.res_conv_5 = self._make_layer(1024, 4)
self.fc = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, num_classes)
)
def _make_layer(self, in_channels, num_blocks):
layers = []
for _ in range(num_blocks):
layers.append(Residual_block(in_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.stem(x)
x = self.res_conv_1(x)
x = self.conv_2_in(x)
x = self.res_conv_2(x)
x = self.conv_3_in(x)
x = self.res_conv_3(x)
x = self.conv_4_in(x)
x = self.res_conv_4(x)
x = self.conv_5_in(x)
x = self.res_conv_5(x)
x = self.fc(x)
return x위 설계도를 바탕으로 모델을 인스턴스화 하고
요약본을 출력하도록 하자.
from torchinfo import summary#모델의 요약정보 출력
model = Darknet53()
summary(model, input_size=(1, 3, 256, 256), device='cpu')이전포스트에서는
from torchsummary import summary
model = Darknet53()
summary(model, input_size=(3, 256, 256), device='cpu')을 사용했으나 이제부터는 torchinfo를 사용을 하려 한다.
이유는 출력형식의 차이가 있어서인데
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Darknet53 [1, 1000] --
├─Sequential: 1-1 [1, 64, 128, 128] --
│ └─BasicConv2d: 2-1 [1, 32, 256, 256] --
│ │ └─Conv2d: 3-1 [1, 32, 256, 256] 864
│ │ └─BatchNorm2d: 3-2 [1, 32, 256, 256] 64
│ │ └─LeakyReLU: 3-3 [1, 32, 256, 256] --
│ └─BasicConv2d: 2-2 [1, 64, 128, 128] --
│ │ └─Conv2d: 3-4 [1, 64, 128, 128] 18,432
│ │ └─BatchNorm2d: 3-5 [1, 64, 128, 128] 128
│ │ └─LeakyReLU: 3-6 [1, 64, 128, 128] --
├─Sequential: 1-2 [1, 64, 128, 128] --
│ └─Residual_block: 2-3 [1, 64, 128, 128] --
│ │ └─BasicConv2d: 3-7 [1, 32, 128, 128] 2,112
│ │ └─BasicConv2d: 3-8 [1, 64, 128, 128] 18,560
├─BasicConv2d: 1-3 [1, 128, 64, 64] --
│ └─Conv2d: 2-4 [1, 128, 64, 64] 73,728
│ └─BatchNorm2d: 2-5 [1, 128, 64, 64] 256
│ └─LeakyReLU: 2-6 [1, 128, 64, 64] --
├─Sequential: 1-4 [1, 128, 64, 64] --
│ └─Residual_block: 2-7 [1, 128, 64, 64] --
│ │ └─BasicConv2d: 3-9 [1, 64, 64, 64] 8,320
│ │ └─BasicConv2d: 3-10 [1, 128, 64, 64] 73,984
│ └─Residual_block: 2-8 [1, 128, 64, 64] --
│ │ └─BasicConv2d: 3-11 [1, 64, 64, 64] 8,320
│ │ └─BasicConv2d: 3-12 [1, 128, 64, 64] 73,984
├─BasicConv2d: 1-5 [1, 256, 32, 32] --
│ └─Conv2d: 2-9 [1, 256, 32, 32] 294,912
│ └─BatchNorm2d: 2-10 [1, 256, 32, 32] 512
│ └─LeakyReLU: 2-11 [1, 256, 32, 32] --
├─Sequential: 1-6 [1, 256, 32, 32] --
│ └─Residual_block: 2-12 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-13 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-14 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-13 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-15 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-16 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-14 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-17 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-18 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-15 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-19 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-20 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-16 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-21 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-22 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-17 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-23 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-24 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-18 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-25 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-26 [1, 256, 32, 32] 295,424
│ └─Residual_block: 2-19 [1, 256, 32, 32] --
│ │ └─BasicConv2d: 3-27 [1, 128, 32, 32] 33,024
│ │ └─BasicConv2d: 3-28 [1, 256, 32, 32] 295,424
├─BasicConv2d: 1-7 [1, 512, 16, 16] --
│ └─Conv2d: 2-20 [1, 512, 16, 16] 1,179,648
│ └─BatchNorm2d: 2-21 [1, 512, 16, 16] 1,024
│ └─LeakyReLU: 2-22 [1, 512, 16, 16] --
├─Sequential: 1-8 [1, 512, 16, 16] --
│ └─Residual_block: 2-23 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-29 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-30 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-24 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-31 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-32 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-25 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-33 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-34 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-26 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-35 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-36 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-27 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-37 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-38 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-28 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-39 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-40 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-29 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-41 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-42 [1, 512, 16, 16] 1,180,672
│ └─Residual_block: 2-30 [1, 512, 16, 16] --
│ │ └─BasicConv2d: 3-43 [1, 256, 16, 16] 131,584
│ │ └─BasicConv2d: 3-44 [1, 512, 16, 16] 1,180,672
├─BasicConv2d: 1-9 [1, 1024, 8, 8] --
│ └─Conv2d: 2-31 [1, 1024, 8, 8] 4,718,592
│ └─BatchNorm2d: 2-32 [1, 1024, 8, 8] 2,048
│ └─LeakyReLU: 2-33 [1, 1024, 8, 8] --
├─Sequential: 1-10 [1, 1024, 8, 8] --
│ └─Residual_block: 2-34 [1, 1024, 8, 8] --
│ │ └─BasicConv2d: 3-45 [1, 512, 8, 8] 525,312
│ │ └─BasicConv2d: 3-46 [1, 1024, 8, 8] 4,720,640
│ └─Residual_block: 2-35 [1, 1024, 8, 8] --
│ │ └─BasicConv2d: 3-47 [1, 512, 8, 8] 525,312
│ │ └─BasicConv2d: 3-48 [1, 1024, 8, 8] 4,720,640
│ └─Residual_block: 2-36 [1, 1024, 8, 8] --
│ │ └─BasicConv2d: 3-49 [1, 512, 8, 8] 525,312
│ │ └─BasicConv2d: 3-50 [1, 1024, 8, 8] 4,720,640
│ └─Residual_block: 2-37 [1, 1024, 8, 8] --
│ │ └─BasicConv2d: 3-51 [1, 512, 8, 8] 525,312
│ │ └─BasicConv2d: 3-52 [1, 1024, 8, 8] 4,720,640
├─Sequential: 1-11 [1, 1000] --
│ └─AdaptiveAvgPool2d: 2-38 [1, 1024, 1, 1] --
│ └─Flatten: 2-39 [1, 1024] --
│ └─Linear: 2-40 [1, 1000] 1,025,000
==========================================================================================
Total params: 41,609,928
Trainable params: 41,609,928
Non-trainable params: 0
Total mult-adds (G): 9.29
==========================================================================================
Input size (MB): 0.79
Forward/backward pass size (MB): 198.19
Params size (MB): 166.44
Estimated Total Size (MB): 365.42
==========================================================================================스크롤 압박이 있어서 붙여넣을까 고민했지만
역시 torchsummary보다 더 많은내용
특히 nn.Sequential로 묶음 처리한 block를
알기 어려웟었는데 이것까지 상세하게 출력되서
좀 더 많은 정보를 시각화하기 좋은 편이 있다.
아무튼 파라미터 개수는 4천만개로
아직까지는 로컬PC에서 버텨줄만한 네트워크임을 알 수 있다.
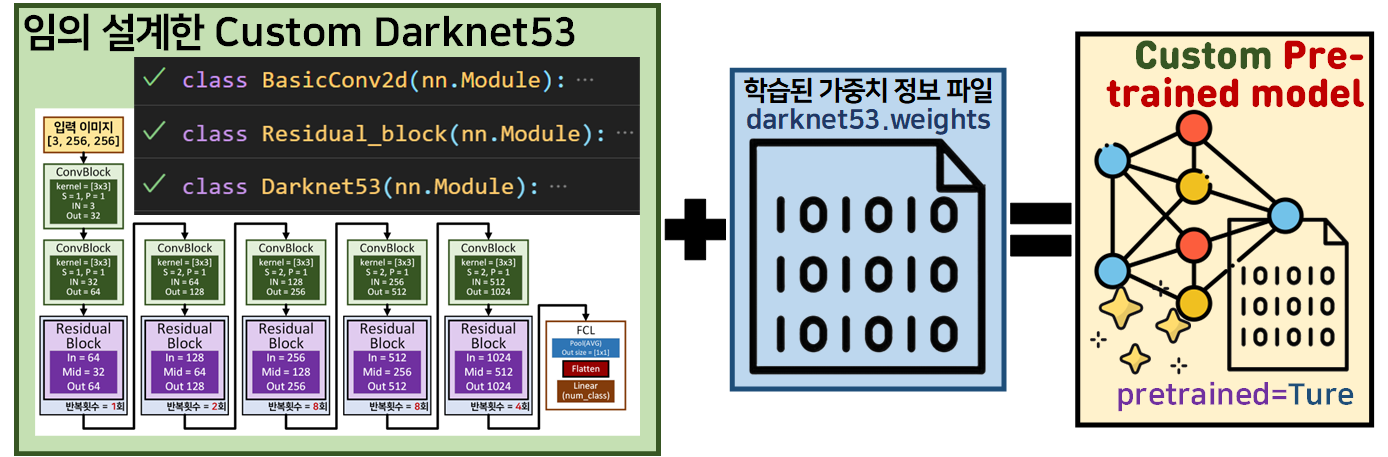
3. 사전학습 Darknet 53 다운로드
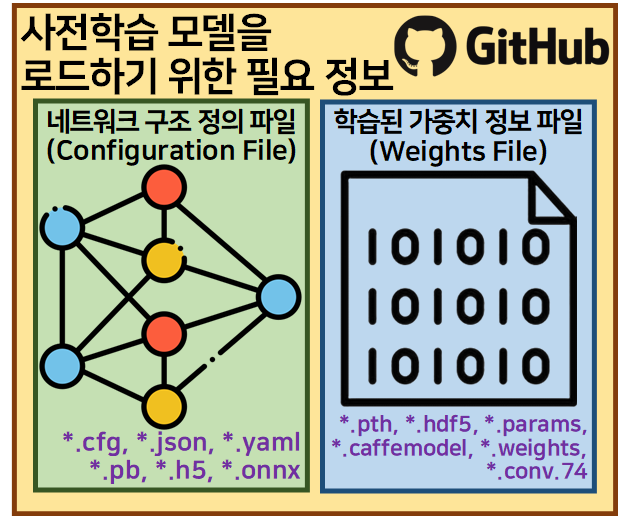 우선 외부 라이브러리(클라우드 서비스 플랫폼)를 통해 수집해야할 필수 항목으로는 위 사진처럼
우선 외부 라이브러리(클라우드 서비스 플랫폼)를 통해 수집해야할 필수 항목으로는 위 사진처럼
네트워크 구조 정의 파일, 학습된 가중치 정보 파일 두가지 파일이 필수적으로 필요하다.
각 파일의 확장자는 아직 하나로 통일되지 않은 편이기에 정말 다양한 확장자 형식으로 넷 상에서 돌아다니고 있는데
Yolo 시리즈는 Configuration File로는 *.cfg
Weights Files로는 *.weights, *.conv.74 확장자로 된 파일을 사용한다.
위 2개의 파일을 구하기 위해
Yolo 시리즈의 주 개발자 Joseph Redmon의 홈페이지 및
github 사이트를 참조하도록 하자
https://github.com/pjreddie/darknet
두 파일의 다운로드는 ImageNet Classification Pre-Trained Models 항목에 들어가면 다운이 가능하다.
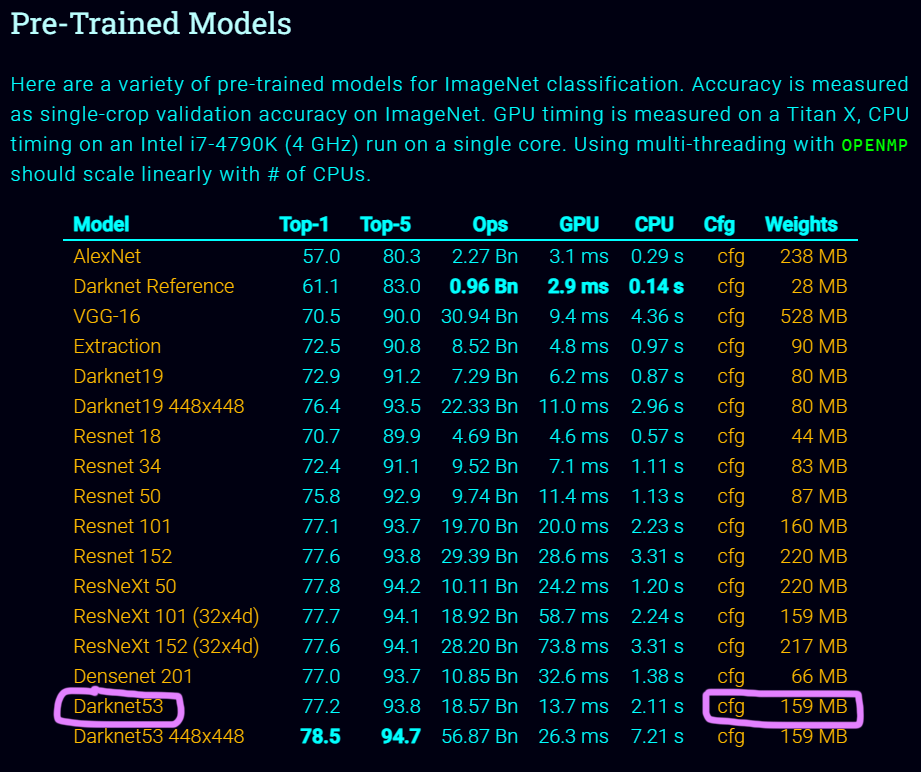
위 표시한 *.cfg, *.weight 파일을 각각 다운받은 뒤
이를 해석하면 된다.
다운받은 2개의 파일을 열람해보자
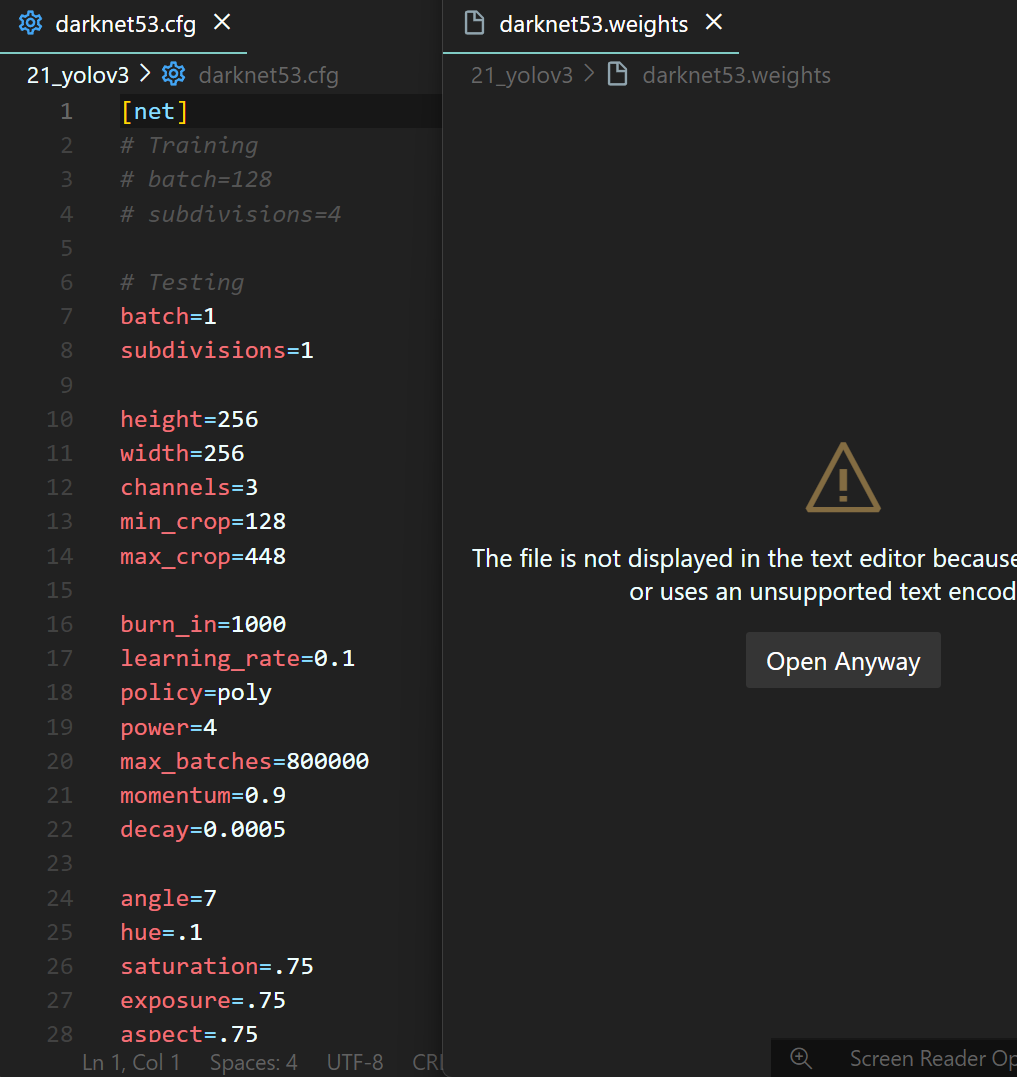
Configuration File : darknet.cfg는 열람이 가능하고
Weights Files : darknet53.weights는 바이너리 파일이니까 열리지는 않는다.
자 이제부터 머리가 아파오기 시작하는 작업을 수행해야 한다.
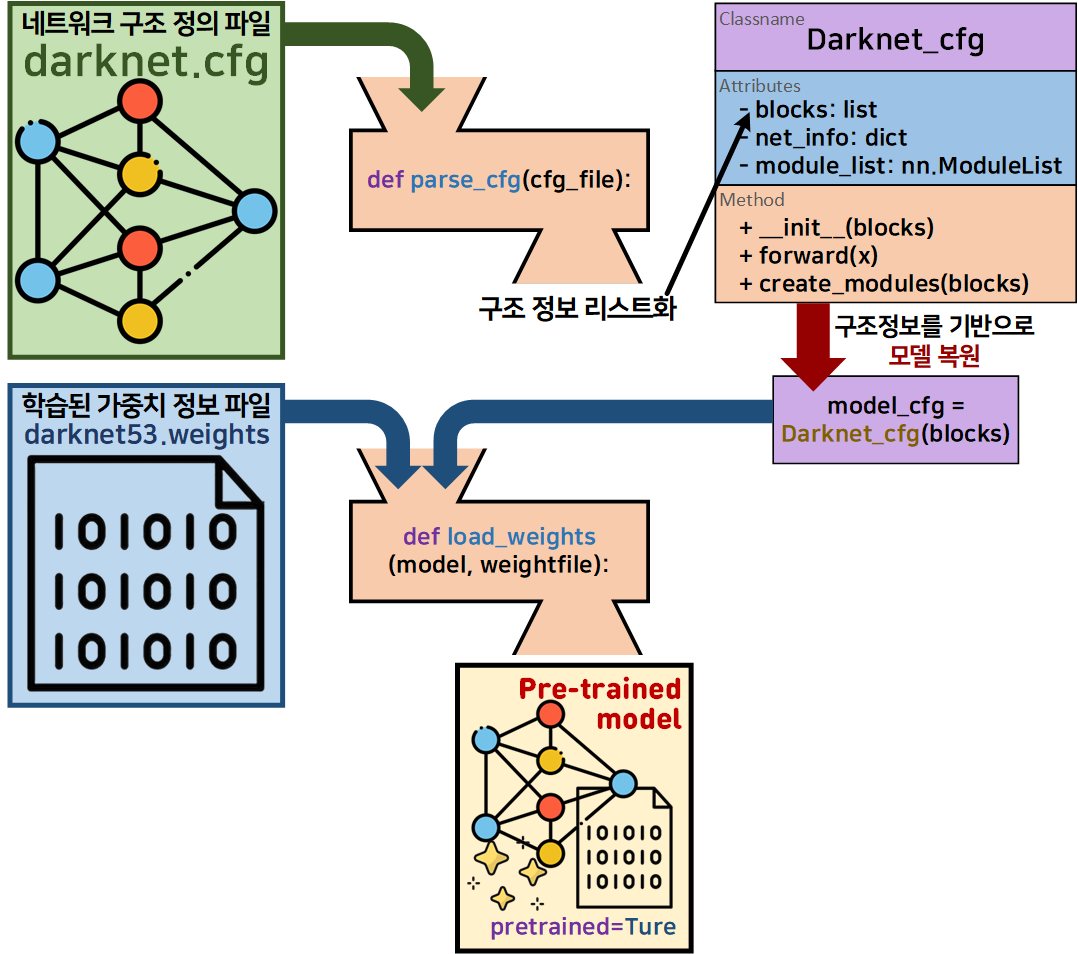 그림으로 표현한 저 작업을 해야한다.
그림으로 표현한 저 작업을 해야한다.

솔직히 저 함수랑, 클래스 설계는 Chat GTP가 다 해줬다.
진짜 그냥 '해줘' 하니까 코드 다 만들어줌

아무튼 Chat GPT가 만들어준 코드를 해석하는 시간을 가져보도록 할려 했는데
Chat GTP가 어디서 위 2개의 함수
parse_cfg, load_weights, 그리고 클래스 Darknet_cfg의 생성 원리에 대한 출처를 계속 캐물으니
https://github.com/ayooshkathuria/pytorch-yolo-v3/tree/master
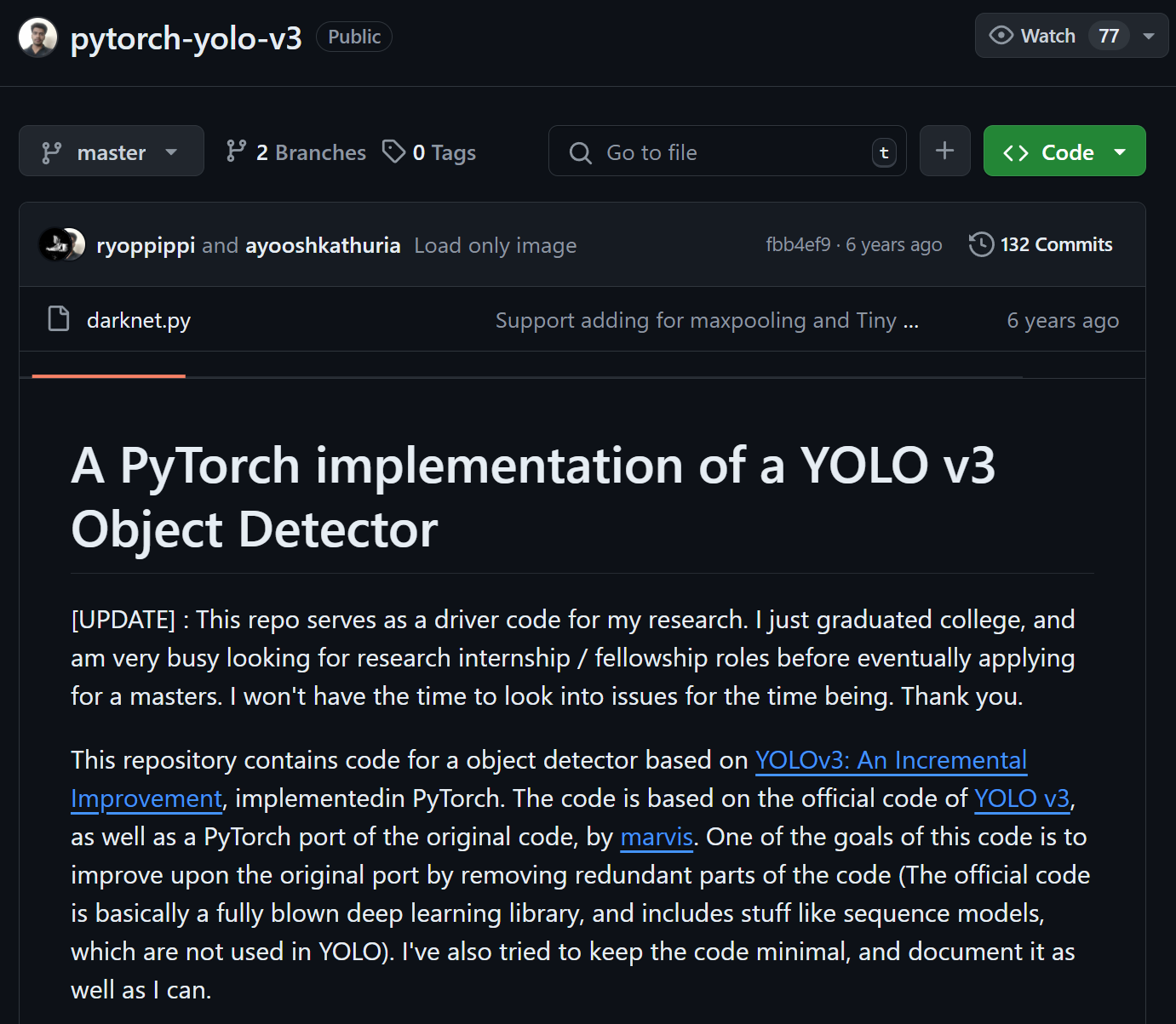 이 사이트에서 해당 함수들을 가져왔다고 실토를 했다.
이 사이트에서 해당 함수들을 가져왔다고 실토를 했다.
실제로 해당 git 저장소에 접속하여 darknet.py파일을 참조하면
이미지에 표기된 2개의 함수와, 1개 클래스와 코드가 거의 같은
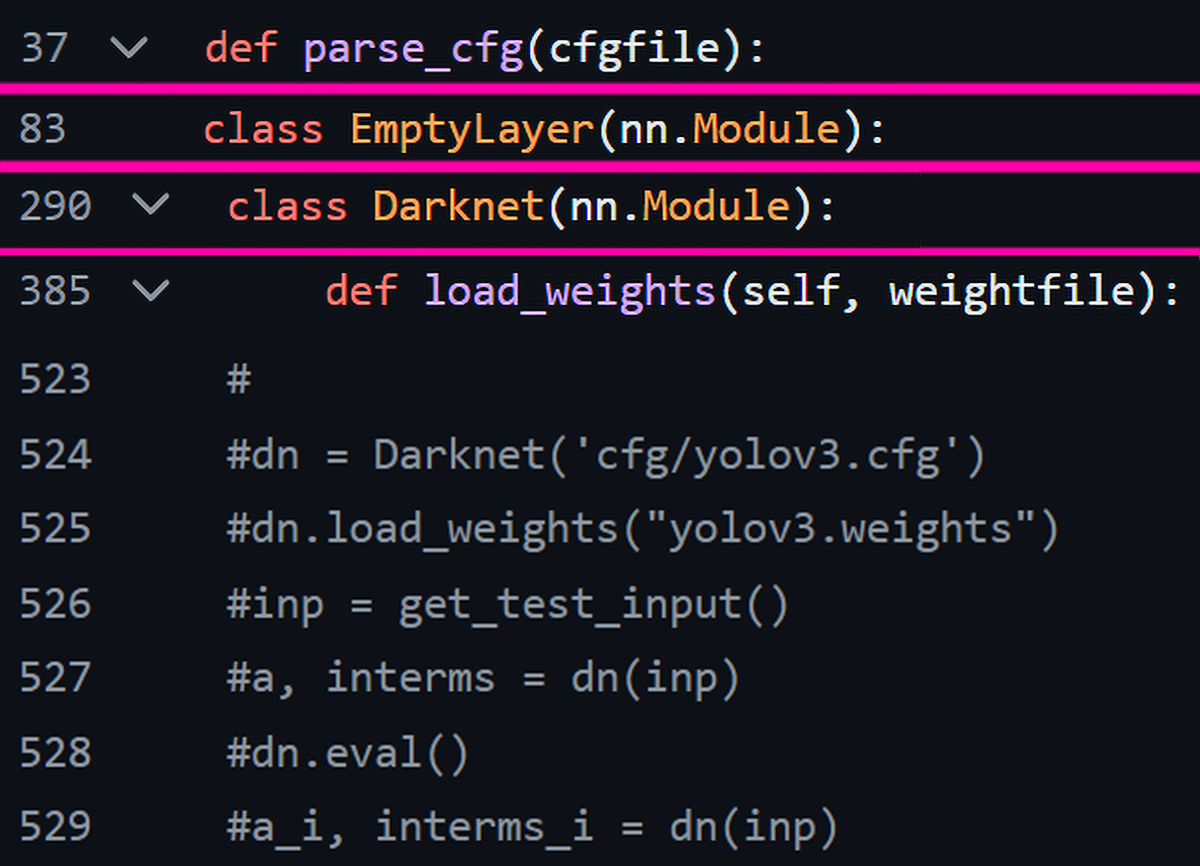
함수 및 클래스가 정의되어 있음을 확인할 수 있었다. (이 중 EmptyLayer은 Darknet 클래스의 하위 클래스라 보면 된다.)
Chat GPT는 해당 폴더의 함수를 거의 그대로 긁어와서 알려주기만 한 것이니 진짜 인간시대의 끝이 온 줄 알았다.
뭐.. 그래도 이거 찾는데 한세월을 걸렸을 텐데
쉽게 검색을 건너뛰었으니 안도의 한숨과 함께
각각의 코드를 첨부하도록 하겠다.
def parse_cfg(cfg_file):
with open(cfg_file, 'r') as file:
lines = file.read().split('\n')
lines = [x for x in lines if x and not x.startswith('#')]
lines = [x.rstrip().lstrip() for x in lines]
block = {}
blocks = []
for line in lines:
if line.startswith('['):
if block:
blocks.append(block)
block = {}
block['type'] = line[1:-1].rstrip()
else:
key, value = line.split('=')
block[key.rstrip()] = value.lstrip()
blocks.append(block)
return blocksclass EmptyLayer(nn.Module):
def forward(self, x):
return xclass Darknet_cfg(nn.Module):
def __init__(self, blocks):
super(Darknet_cfg, self).__init__()
self.blocks = blocks
self.net_info, self.module_list = self.create_modules(blocks)
def forward(self, x):
outputs = {}
for i, module in enumerate(self.module_list):
module_type = self.blocks[i + 1]['type']
if module_type in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_type == "route":
layers = [int(a) for a in self.blocks[i + 1]["layers"].split(',')]
if layers[0] > 0:
layers[0] = layers[0] - i
if len(layers) == 1:
x = outputs[i + layers[0]]
else:
if layers[1] > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)
elif module_type == "shortcut":
from_layer = int(self.blocks[i + 1]["from"])
x = outputs[i - 1] + outputs[i + from_layer]
outputs[i] = x
return x
def create_modules(self, blocks):
net_info = blocks[0]
module_list = nn.ModuleList()
prev_filters = 3
output_filters = []
for index, x in enumerate(blocks[1:]):
module = nn.Sequential()
if x['type'] == 'convolutional':
activation = x['activation']
try:
batch_normalize = int(x['batch_normalize'])
bias = False
except:
batch_normalize = 0
bias = True
filters = int(x['filters'])
padding = int(x['pad'])
kernel_size = int(x['size'])
stride = int(x['stride'])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias=bias)
module.add_module(f"conv_{index}", conv)
if batch_normalize:
bn = nn.BatchNorm2d(filters)
module.add_module(f"batch_norm_{index}", bn)
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace=True)
module.add_module(f"leaky_{index}", activn)
elif x['type'] == 'upsample':
stride = int(x['stride'])
upsample = nn.Upsample(scale_factor=stride, mode='bilinear', align_corners=True)
module.add_module(f"upsample_{index}", upsample)
elif x['type'] == 'route':
x['layers'] = x['layers'].split(',')
start = int(x['layers'][0])
try:
end = int(x['layers'][1])
except:
end = 0
if start > 0:
start = start - index
if end > 0:
end = end - index
route = EmptyLayer()
module.add_module(f"route_{index}", route)
if end < 0:
filters = output_filters[index + start] + output_filters[index + end]
else:
filters = output_filters[index + start]
elif x['type'] == 'shortcut':
shortcut = EmptyLayer()
module.add_module(f"shortcut_{index}", shortcut)
elif x['type'] == 'maxpool':
stride = int(x['stride'])
size = int(x['size'])
maxpool = nn.MaxPool2d(size, stride)
module.add_module(f"maxpool_{index}", maxpool)
prev_filters = filters
output_filters.append(filters)
module_list.append(module)
return net_info, module_listdef load_weights(model, weightfile):
fp = open(weightfile, 'rb')
header = np.fromfile(fp, dtype=np.int32, count=5)
model.header = torch.from_numpy(header)
model.seen = model.header[3]
weights = np.fromfile(fp, dtype=np.float32)
fp.close()
ptr = 0
for i, module in enumerate(model.module_list):
module_type = model.blocks[i + 1]["type"]
if module_type == "convolutional":
conv_layer = module[0]
# print(f"Loading weights for layer {i} of type {module_type}")
if "batch_normalize" in model.blocks[i + 1]:
bn_layer = module[1]
num_b = bn_layer.bias.numel()
# print(f"Batch norm layer: {num_b} biases, {num_b} weights, {num_b} running means, {num_b} running vars")
bn_b = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.bias)
bn_layer.bias.data.copy_(bn_b)
ptr += num_b
bn_w = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.weight)
bn_layer.weight.data.copy_(bn_w)
ptr += num_b
bn_rm = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.running_mean)
bn_layer.running_mean.data.copy_(bn_rm)
ptr += num_b
bn_rv = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.running_var)
bn_layer.running_var.data.copy_(bn_rv)
ptr += num_b
else:
num_b = conv_layer.bias.numel()
# print(f"Conv layer: {num_b} biases")
conv_b = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(conv_layer.bias)
conv_layer.bias.data.copy_(conv_b)
ptr += num_b
num_w = conv_layer.weight.numel()
# print(f"Conv layer: {num_w} weights")
conv_w = torch.from_numpy(weights[ptr:ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
if ptr >= len(weights):
print("Finished loading weights")
break아무튼 위 코드를 바탕으로 아래의 작업을 수행하면된다.
#Darknet53의 모델 설계정보를 파싱하는 함수
cfg_file = 'darknet53.cfg'
blocks = parse_cfg(cfg_file)
#파싱한 정보를 바탕으로 모델 복원하기
model_cfg = Darknet_cfg(blocks)
# 복원한 모델에 가중치 붙여넣기
weightfile = 'darknet53.weights'
load_weights(model_cfg, weightfile)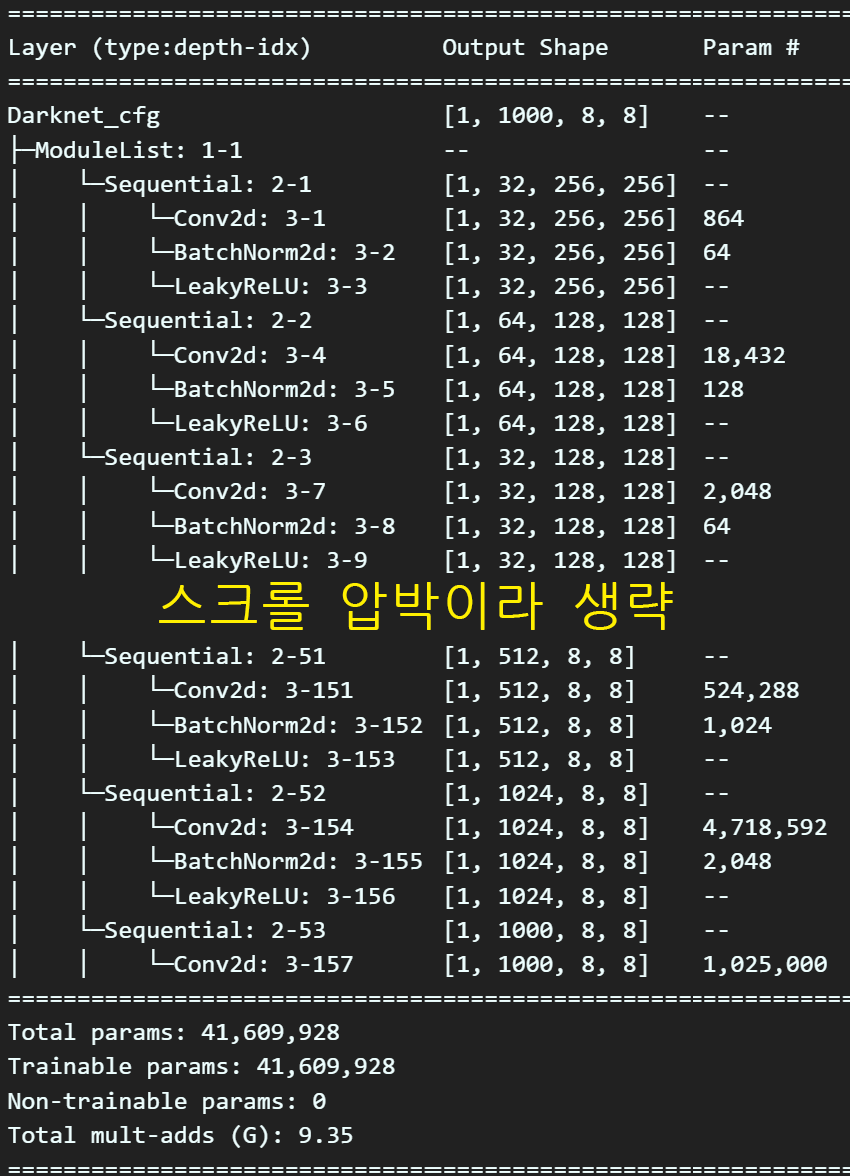
아무튼 위 코드를 순차적으로 수행하면 손쉽게
학습이 완료된 모델(Pre-trained model)
을 얻을 수 있다.
4. Pre-trained model 검증
학습이 완료된 모델(Pre-trained model)을 불러왔다고
끝내고 바로 넘어갈 것이 아니라 재대로 불러왔는지 확인을 해봐야 한다.
따라서 검증을 위해 이미지 분류 작업을 진행해 보고자 한다.
대상 파일은
인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (2) Inception-v3,v4 훈련/검증
인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (3) Intel Image Classification 추론하기
위 포스트에서 사용했던
https://www.kaggle.com/datasets/puneet6060/intel-image-classification/data
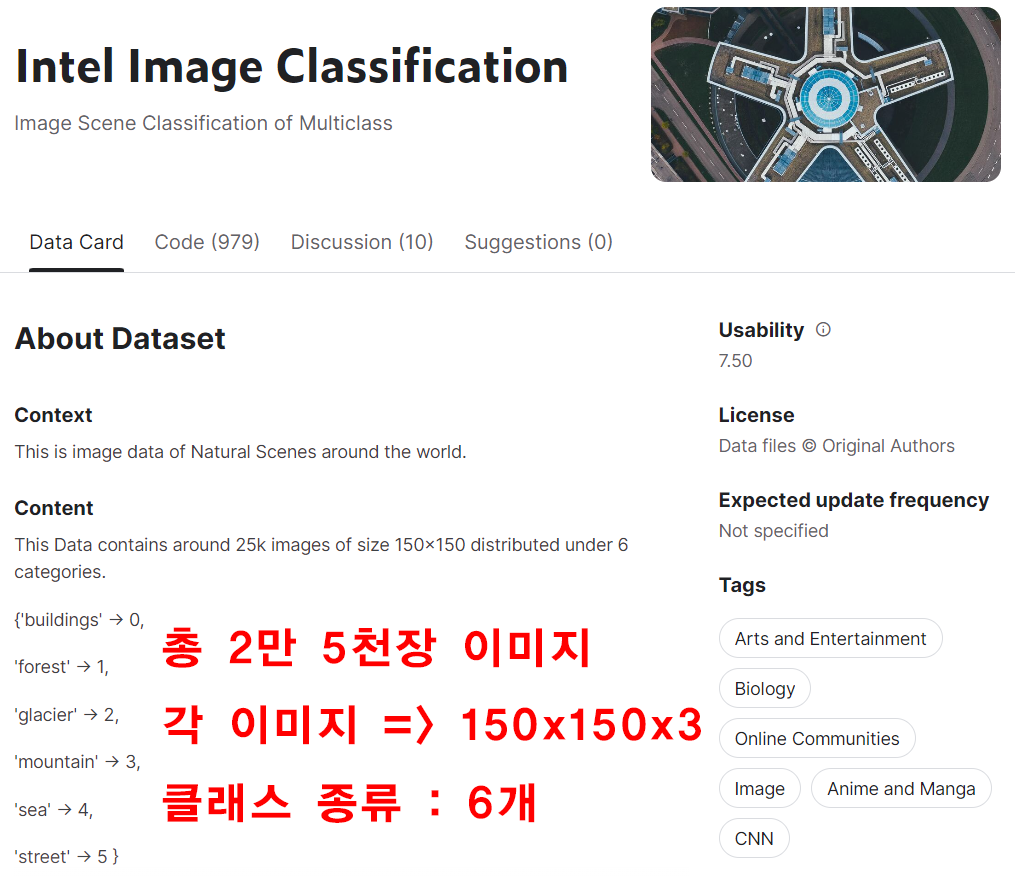 Intel Image Classification 데이터셋을 활용하고자 한다.
Intel Image Classification 데이터셋을 활용하고자 한다.
해당 데이터셋의 폴더 구성은 아래의 사진과 같으니 커스텀 데이터셋을 만들지 말고 ImageFolder 메서드를 활용하여 데이터셋을 정리하도록 하자.
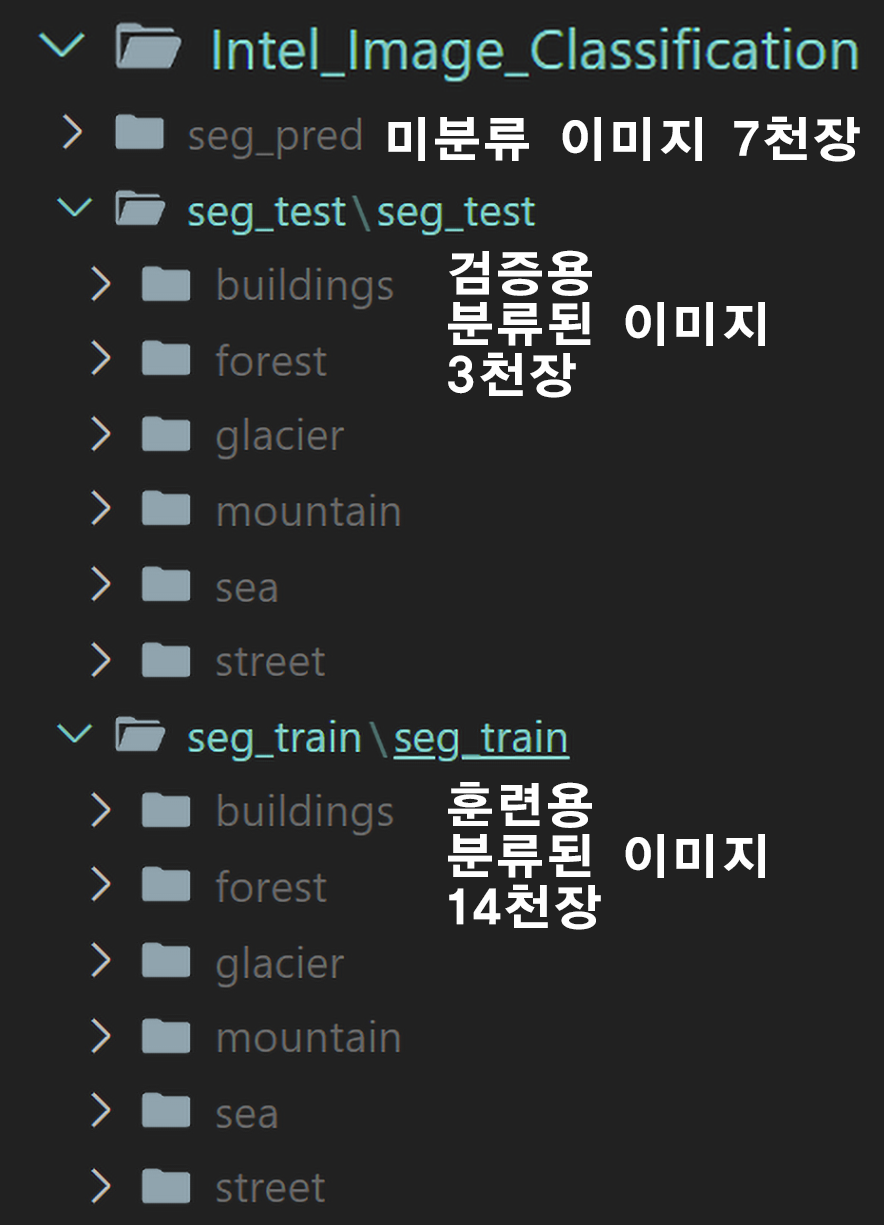
import os
from torchvision import datasets
root = '1/Intel_Image_Classification]폴더 경로'
img_dataset = {}
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'seg_train', 'seg_train'))
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'seg_test', 'seg_test'))데이터셋을 불러온 뒤에는 예의 바르게 Mean, Std를 연산해주자
#훈련 데이터셋의 mean, std를 구하기
from torch.utils.data import DataLoader
from torchvision.transforms import v2
from tqdm import tqdm
transforamtion = v2.Compose([
v2.Resize((224,224)), #VGG19용 input_img로 리사이징
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True)
#텐서 자료형변환 + [0~1]사이로 졍규화 해줘야함
])
img_dataset['train'].transform = transforamtion
dataloader = DataLoader(img_dataset['train'], batch_size=256, shuffle=False)
#GPU사용 가능여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#이미지의 총 개수 및 채널별 합계를 저장할 변수 초기화
mean = torch.zeros(3).to(device)
std = torch.zeros(3).to(device)
nb_sample = 0
#데이터셋을 순회하며 mean, std 계산
for images, _ in tqdm(dataloader):
images = images.to(device)
batch_samples = images.size(0) # 배치 내 이미지 수
# 차원 형태 = (batch_size, channel(3), H, W)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0)
std += images.std(2).sum(0)
nb_sample += batch_samples
mean /= nb_sample
std /= nb_sample
# mean과 std를 numpy 배열로 변환하여 소수점 4자리로 출력
mean_np = mean.cpu().numpy()
std_np = std.cpu().numpy()
print(f"Mean: {mean_np[0]:.4f}, {mean_np[1]:.4f}, {mean_np[2]:.4f}")
print(f"Std: {std_np[0]:.4f}, {std_np[1]:.4f}, {std_np[2]:.4f}")100%|██████████| 55/55 [00:22<00:00, 2.49it/s]
Mean: 0.4302, 0.4575, 0.4539
Std: 0.2246, 0.2237, 0.2326#정규화(mean, std)값을 구한 다음에는 GPU캐시 데이터 초기화를 해주자
torch.cuda.empty_cache()다음으로 간단한 전처리 방법론을 적용하여 dataloader까지 생성해주자
from torchvision.transforms import v2
# 데이터 로더 생성하기
intel_val = [[0.4302, 0.4575, 0.4539], [0.2246, 0.2237, 0.2326]]
transformation = v2.Compose([
v2.Resize((256, 256)), #DarkNet53의 입력 이미지 사이즈
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=intel_val[0], std=intel_val[1]) #데이터셋 표준화
])
# 전처리 방법론을 데이터셋에 적용하기
img_dataset['train'].transform = transformation
img_dataset['val'].transform = transformationfrom torch.utils.data import DataLoader
BATCH_SIZE = 96
train_loader = DataLoader(img_dataset['train'],
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(img_dataset['val'],
batch_size=BATCH_SIZE,
shuffle=False)4.1 데이터셋에 맞춘 Downstream Task 셋업
Intel Image Classification의 클래스는 6종이니 이것에 맞춰서 Downstream task 작업을 수행해야 한다.
작업 개요는 아래와 같다.
1) 마지막 레이어를 적절하게 6종의 클래스 분류가 가능하도록 변환시키는 전이학습
2) 모든 레이어를 학습 가능한 상태로 놓고 훈련/검증을 수행하는 미세조정
1) 전이학습 과정
먼저 마지막 레이어와 바로 그 직전 레이어를 확인해 보도록 하자
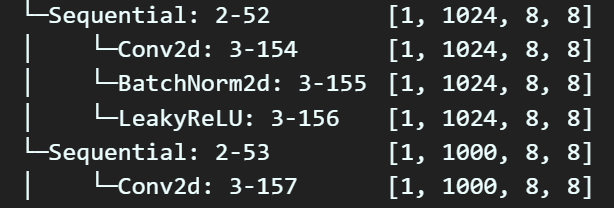
레이어의 정보는 torchinfo로도 확인이 가능하지만
print(model_cfg)명령어를 통해 해당 레이어에 접근 가능한 인자값이 무엇인지 확인해야 한다.
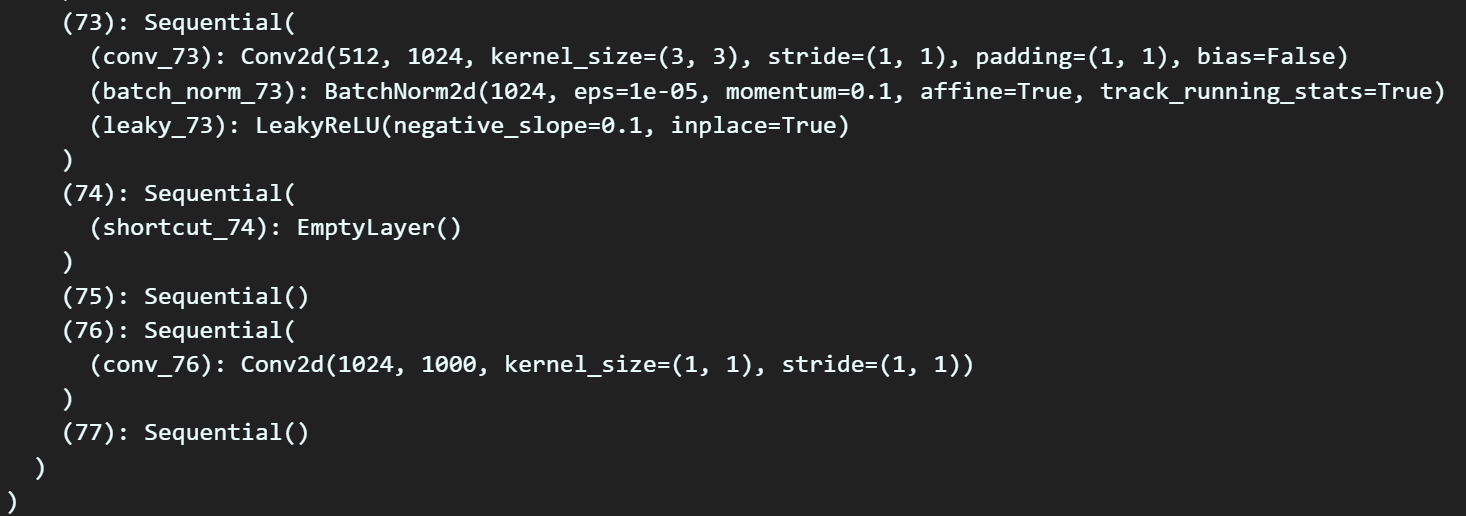
위 두 정보를 통해서
대략 마지막 76번째 레이어만 갈아끼우면 되는 것을 확인할 수 있다.
이 레이어를 갈아끼우는 작업을 아래의 코드를 통해 수행하도록 하자
model_cfg.module_list[76] = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 6) # Intel_Image_Classification 클래스 개수
)모델의 Classifier(Decision Layer)를 교체했다면 해당 교체작업이 재대로 수행되었는지도 확인을 해야 한다.
# 레이어 교체 후 다시 요약정보 출력
summary(model_cfg, input_size=(1, 3, 256, 256))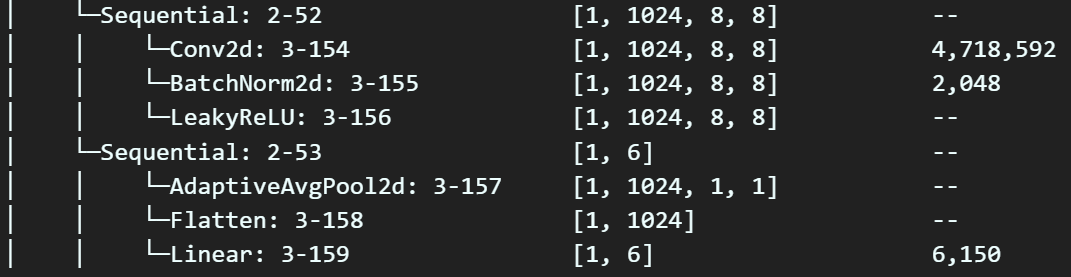 새로이 교체한 레이어가 직전 레이어와 재대로 차원을 맞춰가며 연결됨을 확인하였다.
새로이 교체한 레이어가 직전 레이어와 재대로 차원을 맞춰가며 연결됨을 확인하였다.
2) 미세조정 작업 수행
# 모든 레이어의 파라미터를 Trainable로 조정
for param in model_cfg.parameters():
param.requires_grad = True위 코드는 궂이 쳐줄 필요는 없지만 (모든 레이어는 기본 옵션이 requires_grad = True)
명시적으로 확인하기 위해 해당 코드를 기입한다.
4.2 Downstram Task 수행
이제 모델 GPU올리기 -> 하이퍼 파라미터 설정 -> 훈련/검증/실행/검토 를 수행하면 된다
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_cfg.to(device)import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model_cfg.parameters(), lr=1e-3, momentum=0.9)
scheduler = CosineAnnealingLR(optimizer, T_max=40, eta_min=1e-7)from tqdm import tqdm #훈련 진행상황 체크
#tqdm 시각화 도구 출력 사이즈 조절 변수
epoch_step = 3def model_train(model, data_loader,
loss_fn, optimizer_fn,
processing_device, epoch,
scheduler_fn=None,):
model.train() # 모델을 훈련 모드로 설정
global epoch_step
# loss와 accuracy를 계산하기 위한 임시 변수를 생성
run_size, run_loss, correct = 0, 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar:
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 이진분류 문제에서는 라벨의 차원축소 + float형 변환해야함
# label = label.to(processing_device).float().unsqueeze(1)
# 전사 과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
if scheduler_fn is not None:
# 스케줄러 업데이트
scheduler_fn.step()
# #argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
# 예측값 계산(이진분류용)
# preds = torch.sigmoid(output) > 0.5
# correct += preds.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
#tqdm bar에 추가 정보 기입
if (epoch + 1) % epoch_step == 0 or epoch == 0:
desc = (f"[훈련중]로스: {run_loss / run_size:.4f}, "
f"정확도: {correct / run_size:.4f}")
progress_bar.set_description(desc)
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracydef model_evaluate(model, data_loader, loss_fn,
processing_device, epoch):
model.eval() # 모델을 평가 모드로 전환 -> dropout 기능이 꺼진다
# batchnormalizetion 기능이 꺼진다.
global epoch_step
# gradient 업데이트를 방지해주자
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar: # 이때 사용되는 데이터는 평가용 데이터
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# # 이진분류 문제에서는 라벨의 차원축소 + float형 변환해야함
# label = label.to(processing_device).float().unsqueeze(1)
# 모델 출력
output = model(image)
# # 모델의 평가 결과 도출 부분
pred = output.argmax(dim=1) #예측값의 idx출력
correct += torch.sum(pred.eq(label)).item()
# 모델의 평가 결과(이진분류용)
# preds = torch.sigmoid(output) > 0.5
# correct += preds.eq(label).sum().item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy# 학습과 검증 손실 및 정확도를 저장할 리스트
cfg_his_loss, cfg_his_accuracy = [], []
num_epoch = 15
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = model_train(model_cfg, train_loader,
criterion, optimizer,
device, epoch,
scheduler_fn=scheduler)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = model_evaluate(model_cfg, test_loader,
criterion, device, epoch)
# 손실과 성능지표를 리스트에 저장
cfg_his_loss.append((train_loss, test_loss))
cfg_his_accuracy.append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d} ", end=' ')
print(f"훈련 로스: {train_loss:.4f}", end=' ')
print(f"훈련 정확도: {train_acc:.4f}")
print(f"검증 로스: {test_loss:.4f}", end=' ')
print(f"검증 정확도: {train_acc:.4f}")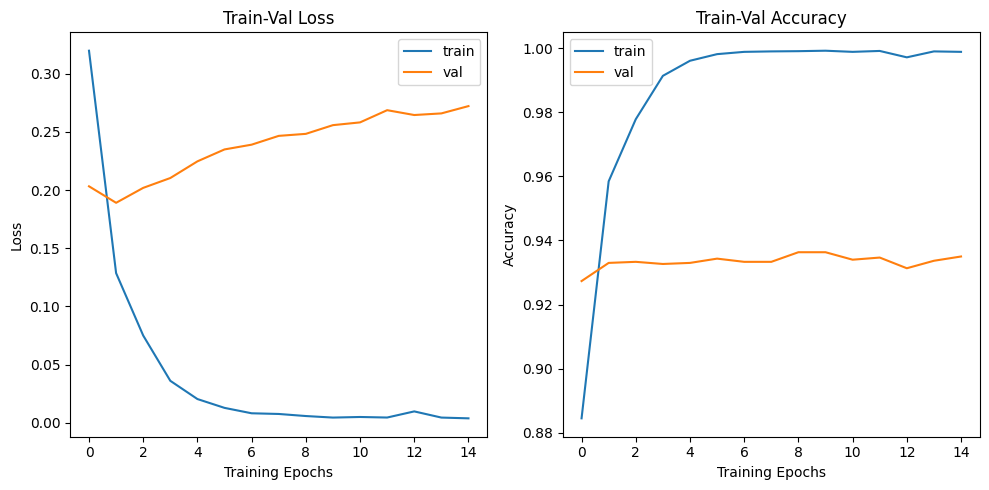 고작 15epoch에 바로 과적합이 나는 것을 보니
고작 15epoch에 바로 과적합이 나는 것을 보니
lr=1e-3해당 파라미터는 1/10배로 더 스케일 다운을 시켜야 할 것 같다.
5. 신규 모델에 학습된 가중치 입력
하지만 필자가 진정으로 하고 싶은 작업은 이것이다.
 이 작업을 해야
이 작업을 해야
나중에 Custom DarkNet53을 기반으로 향후 설계할
Yolo v3을 재대로 만들 수 있다.
custom_model = Darknet53()아까 따로 설계한 클래스에 맞춰서
커스텀 모델을 인스턴스화 한뒤
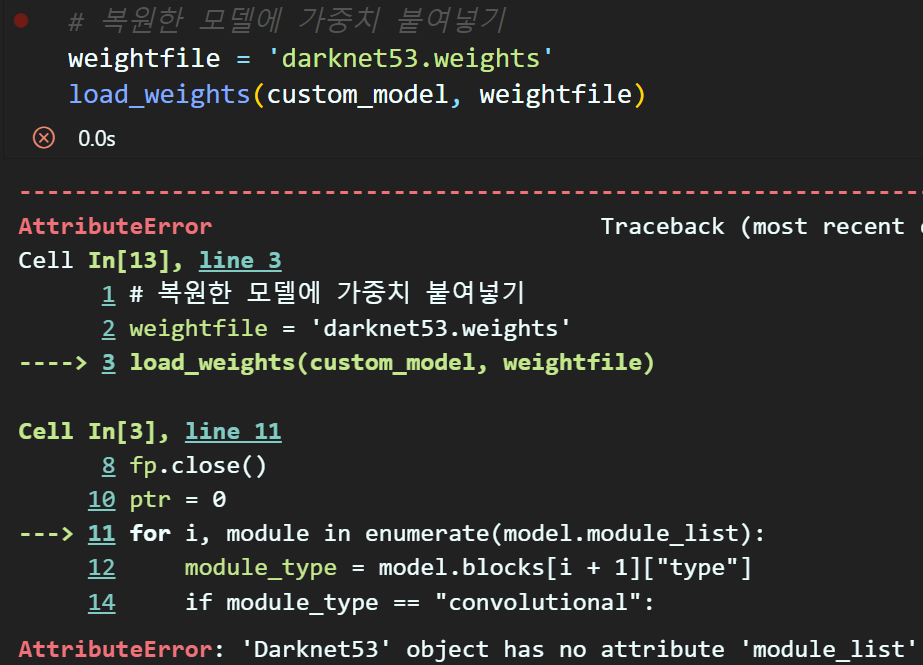
뭐든 쉽게되는거 참 없네....
Chat GTP한테 module_list와 같은 이름 검사는 건너뛰고, 레이어에 모델 파라미터를 삽입하는데
만약 삽입이 실패하면 그냥 건너뛰고 다음 레이어에 모델 파라미터를 삽입하라는 코드를 작성해 달라 하면
아래와 같은 코드가 작성된다.
def load_custom_net_weights(model, weightfile):
fp = open(weightfile, 'rb')
header = np.fromfile(fp, dtype=np.int32, count=5)
model.header = torch.from_numpy(header)
model.seen = model.header[3]
weights = np.fromfile(fp, dtype=np.float32)
fp.close()
print(f"Total weights size: {len(weights)}")
ptr = 0
def load_conv_bn(conv_layer, bn_layer, ptr, weights):
try:
num_b = bn_layer.bias.numel()
bn_b = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.bias)
bn_layer.bias.data.copy_(bn_b)
ptr += num_b
bn_w = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.weight)
bn_layer.weight.data.copy_(bn_w)
ptr += num_b
bn_rm = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.running_mean)
bn_layer.running_mean.data.copy_(bn_rm)
ptr += num_b
bn_rv = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(bn_layer.running_var)
bn_layer.running_var.data.copy_(bn_rv)
ptr += num_b
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr:ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
return ptr
except RuntimeError as e:
print(f"Skipping layer due to size mismatch: {e}")
return ptr
def load_conv(conv_layer, ptr, weights):
try:
num_b = conv_layer.bias.numel()
conv_b = torch.from_numpy(weights[ptr:ptr + num_b]).view_as(conv_layer.bias)
conv_layer.bias.data.copy_(conv_b)
ptr += num_b
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr:ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
return ptr
except RuntimeError as e:
print(f"Skipping layer due to size mismatch: {e}")
return ptr
for m in model.modules():
if isinstance(m, BasicConv2d):
if hasattr(m, 'bn'):
ptr = load_conv_bn(m.conv, m.bn, ptr, weights)
else:
ptr = load_conv(m.conv, ptr, weights)
elif isinstance(m, Residual_block):
for layer in [m.conv1, m.conv2]:
if hasattr(layer, 'bn'):
ptr = load_conv_bn(layer.conv, layer.bn, ptr, weights)
else:
ptr = load_conv(layer.conv, ptr, weights)
if ptr >= len(weights):
print("Finished loading weights")
break
print(f"Total weights loaded: {ptr}")코드 구성은 load_weights에서 몇개 이빨만 빠진 느낌으로 작성된다
# 새로 설계한 모델에 가중치 붙여넣기
weightfile = 'darknet53.weights'
load_custom_net_weights(custom_model, weightfile)Total weights size: 41645640
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 2911336
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 2380904
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 1850472
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 1320040
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 789608
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 259176
Skipping layer due to size mismatch: shape '[512, 1024, 1, 1]' is invalid for input of size 257128
Skipping layer due to size mismatch: shape '[1024, 512, 3, 3]' is invalid for input of size 253032
Total weights loaded: 41392608몇개 레이어가 건너뛰어지긴 했지만
이정도면 뭐 전이학습으로 충분히 처리 될 듯 하다.
#새로 생성한 모델 + 가중치 붙여넣기 성공에 대해 전이학습 수행
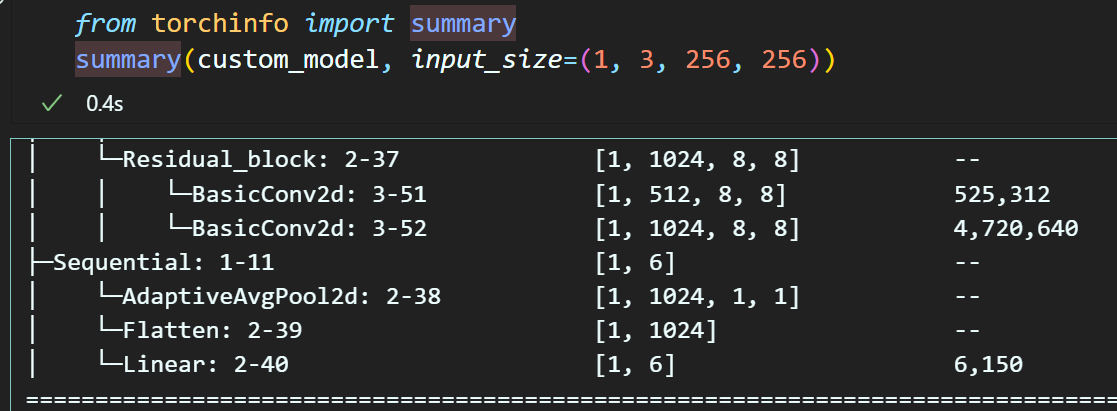
model.fc = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 6) # Intel_Image_Classification 클래스 개수
)
잘 갈아끼워진 듯 하니 바로 학습을 진행하자.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
custom_model.to(device)import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(custom_model.parameters(), lr=1e-3, momentum=0.9)
scheduler = CosineAnnealingLR(optimizer, T_max=25, eta_min=1e-8)몇개 레이어의 파라미터는 사전학습된 모델이 붙은 것이 아니니 lr=1e-3을 그대로 두고 진행한다.
# 학습과 검증 손실 및 정확도를 저장할 리스트
custom_net_his_loss, custom_net_his_accuracy = [], []
num_epoch = 15
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_acc = model_train(custom_model, train_loader,
criterion, optimizer,
device, epoch,
scheduler_fn=scheduler)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_acc = model_evaluate(custom_model, test_loader,
criterion, device, epoch)
# 손실과 성능지표를 리스트에 저장
custom_net_his_loss.append((train_loss, test_loss))
custom_net_his_accuracy.append((train_acc, test_acc))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d} ", end=' ')
print(f"훈련 로스: {train_loss:.4f}", end=' ')
print(f"훈련 정확도: {train_acc:.4f}")
print(f"검증 로스: {test_loss:.4f}", end=' ')
print(f"검증 정확도: {train_acc:.4f}")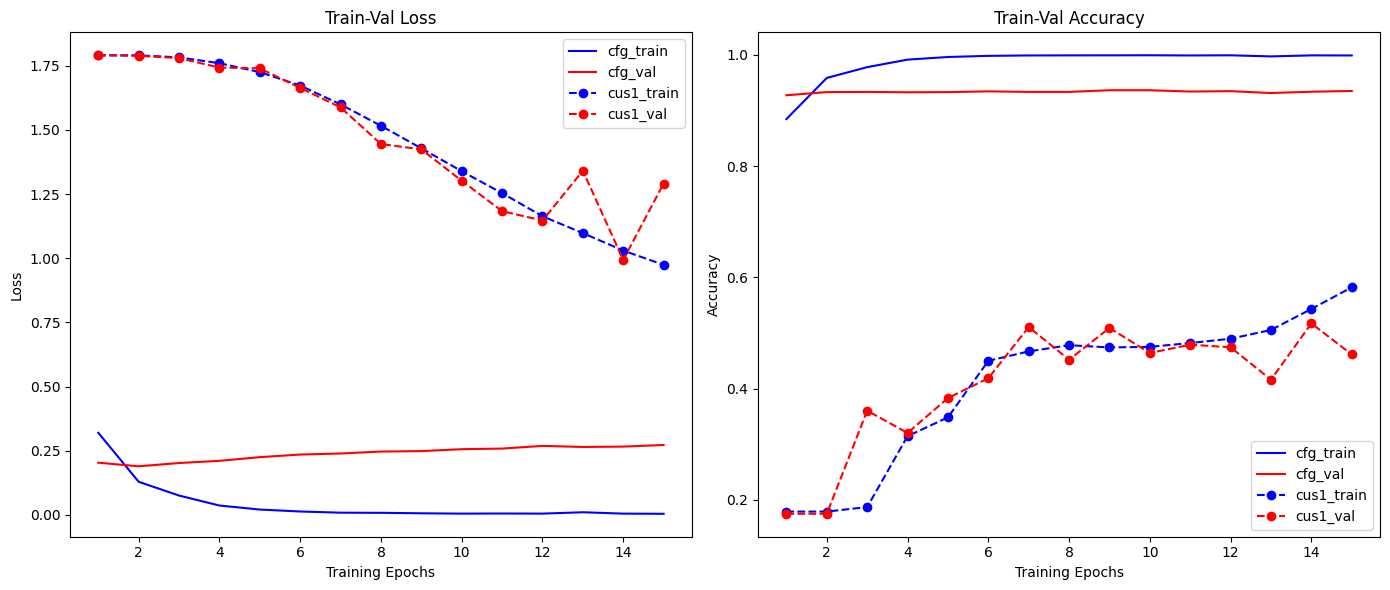
음... 사전 훈련된 CFG모델과
사전훈련 됫을 것이라 예상되는 커스텀 모델의
차이값이 굉장이 많이 나는 것을 보니
학습 가중치가 아주 재대로 잘못 붙었다는 것을
눈으로 확인할 수 있었다...
#Darknet53의 모델 설계정보를 파싱하는 함수
cfg_file = 'darknet53.cfg'
blocks = parse_cfg(cfg_file)
#파싱한 정보를 바탕으로 모델 복원하기
model_cfg = Darknet_cfg(blocks)
# 복원한 모델에 가중치 붙여넣기
weightfile = 'darknet53.weights'
load_weights(model_cfg, weightfile)실제로 위 코드로 복원한 CFG모델과
# 설계한 커스텀 모델
custom_model = Darknet53()
# 새로 설계한 모델에 가중치 붙여넣기
weightfile = 'darknet53.weights'
load_custom_net_weights(custom_model, weightfile)위 코드로 커스텀 모델에 억지로 가중치 파일을 붙여넣을 경우
각 레이어별로 붙은 가중치 정보를 비교했을 때
맨 앞단 레이어 몇개만 일치하고 나머지 레이어는 파라미터가 이상한 값이 붙어버려서 재대로 동작하지 않는 것을 확인할 수 있다.
def compare_model_parameters_by_layer(model1, model2):
params1 = list(model1.named_parameters())
params2 = list(model2.named_parameters())
print(f"cfg모델 층 개수: {len(params1)} 층")
print(f"cus모델 층 개수: {len(params2)} 층", end='\n\n')
if len(params1) != len(params2):
print("모델의 파라미터 개수가 일치하지 않습니다.")
return
for i, ((name1, param1), (name2, param2)) in enumerate(zip(params1, params2)):
if torch.equal(param1.data, param2.data):
print(f"{i:3d}번째 층: 파라미터 일치")
else:
print(f"{i:3d}번째 층: 파라미터 불일치")
print("모든 층의 파라미터 비교가 완료되었습니다.")
그럼 이 문제를 어떻게 해결해야 하는가...

그런데 잘 살펴보면
두 모델 다 파라미터가 있는 레이어의 개수는 158층이고
필자가 설계한 모델을 층별로 비교한 결과
이 158의 순번은 모두
covn BN AF
동일하게 설계됨을 확인했었다.
CFG 모델에 붙어있는 파라미터를 추출해서
Custom 모델에 붙여버리면 되는 것이 아닌가?

# cfg_model의 가중치를 추출하여 내가 정의한 커스텀 Darknet53 모델에 붙여넣기
def transfer_weights(cfg_model, custom_model):
cfg_params = list(cfg_model.named_parameters())
custom_params = list(custom_model.named_parameters())
for (name_cfg, param_cfg), (name_custom, param_custom) in zip(cfg_params, custom_params):
if param_cfg.data.shape == param_custom.data.shape:
param_custom.data = param_cfg.data.clone()
print(f"{name_cfg}의 레이어 파라미터를 {name_custom}로 전이")
else:
print(f"{name_cfg}레이어 파라미터를 {name_custom}에 붙여넣지 못함")transfer_weights(model_cfg, custom_model) 그림을 보면 말단 마지막 레이어 1개를 제외하고
그림을 보면 말단 마지막 레이어 1개를 제외하고
나머지 레이어는 모두 CFG모델에서 Custom모델로 레이어 파라미터가 재대로 전달 된 것을 확인할 수 있었다.
이제 재대로 가중치 정보가 Custom모델로 잘 전이가 됫는지
확인하기 위해 한번 더 Downstream Task를 수행하여 결과가 재대로 도출되는지 확인해보자
# 새로 생성한 모델 + CFG 모델의 파라미터를 붙여넣음
# 이로 인해 '사전학습이 재대로 완료된 커스텀 모델`으로 예상되는
# 모델에 대한 전이학습을 수행하도록 한다
#모델의 Classifier 부분 수정하기
custom_model.fc = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 6) # Intel_Image_Classification 클래스 개수device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
custom_model.to(device)import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
criterion = nn.CrossEntropyLoss()
# lr=1e-3에서는 과적합이 발생했으니 1/10으로 스케일 다운
optimizer = optim.SGD(custom_model.parameters(), lr=1e-4, momentum=0.9)
scheduler = CosineAnnealingLR(optimizer, T_max=25, eta_min=1e-8)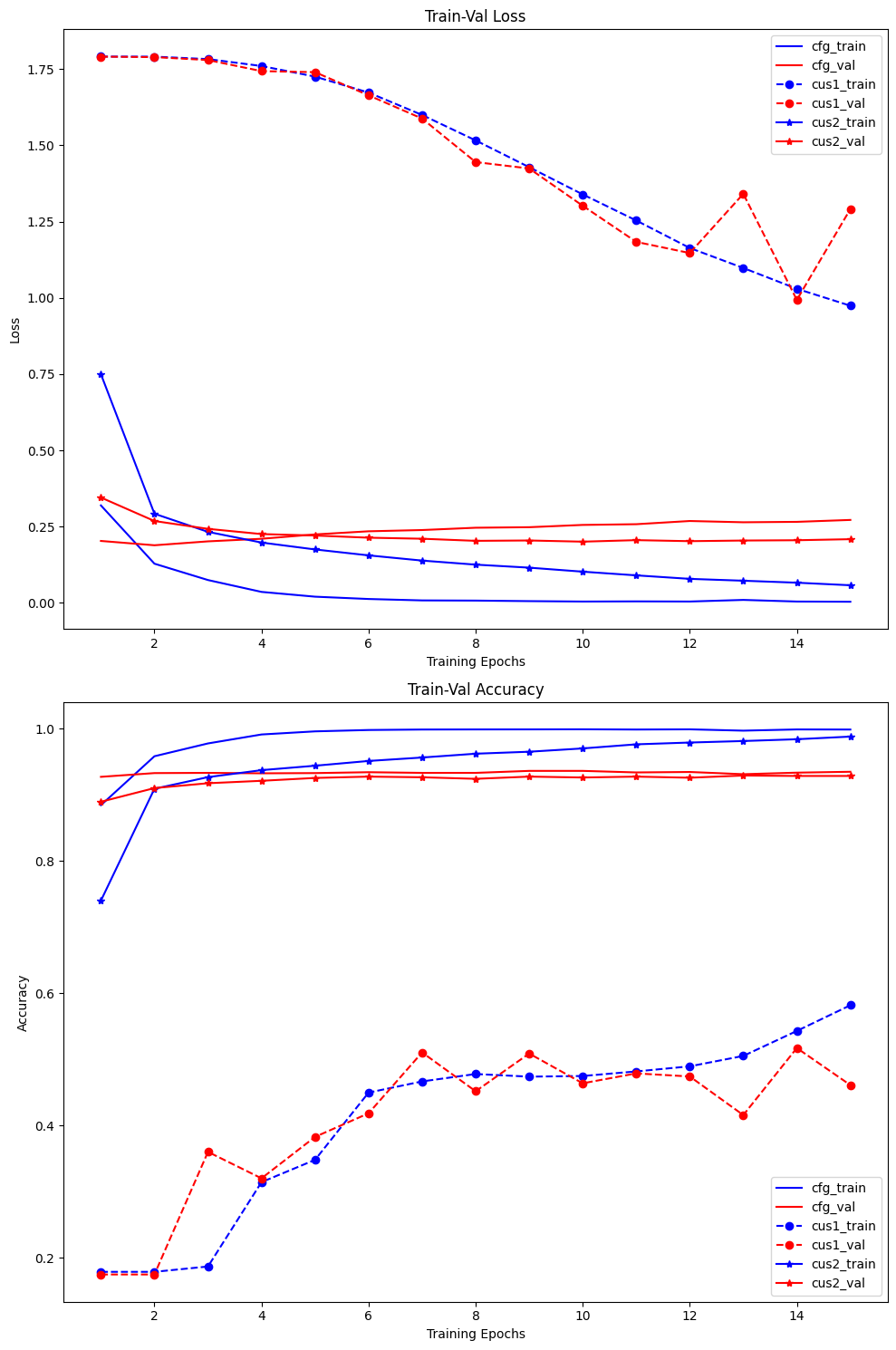 그래프를 분석하면 알 수 있겟지만
그래프를 분석하면 알 수 있겟지만 lr=1e-3에서 lr=1e-4으로 1/10 스케일 다운을 진행하니 이제 과적합 요소도 많이 억제된 것을 확인할 수 있다.
결론은 지금까지 한 일련의 모든 과정은 아래의 그림으로 요약할 수 있다.
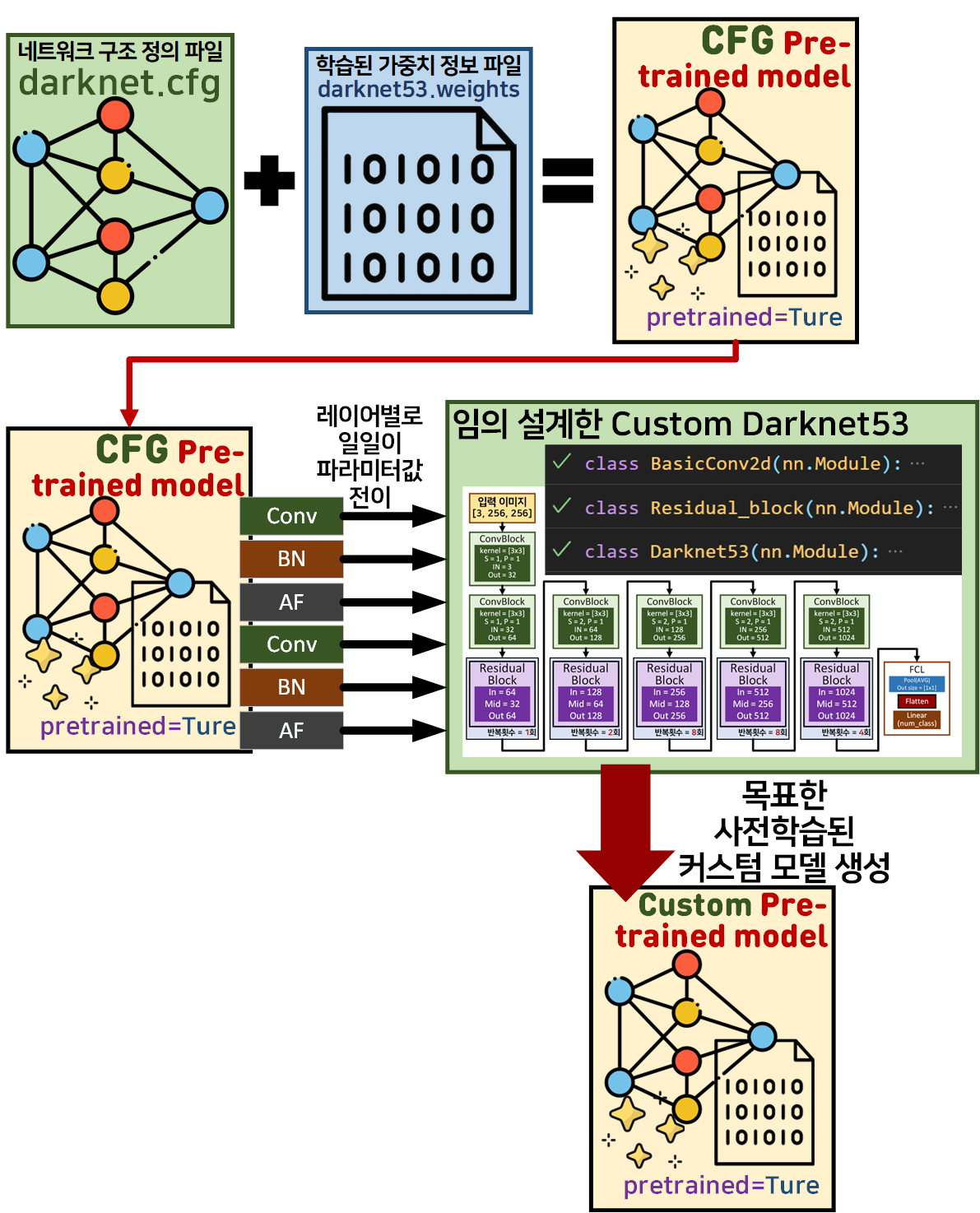 음..
음..
왜 이렇게 귀찮은 작업을 수행했느냐...
6. 포스트의 최종 결과물
#학습 완료된 모델 저장하기
MODEL_NAME='DarkNet53'
torch.save(custom_model.state_dict(), f'{MODEL_NAME}.pth')이 한줄을 위해서 라고 볼 수 있다.
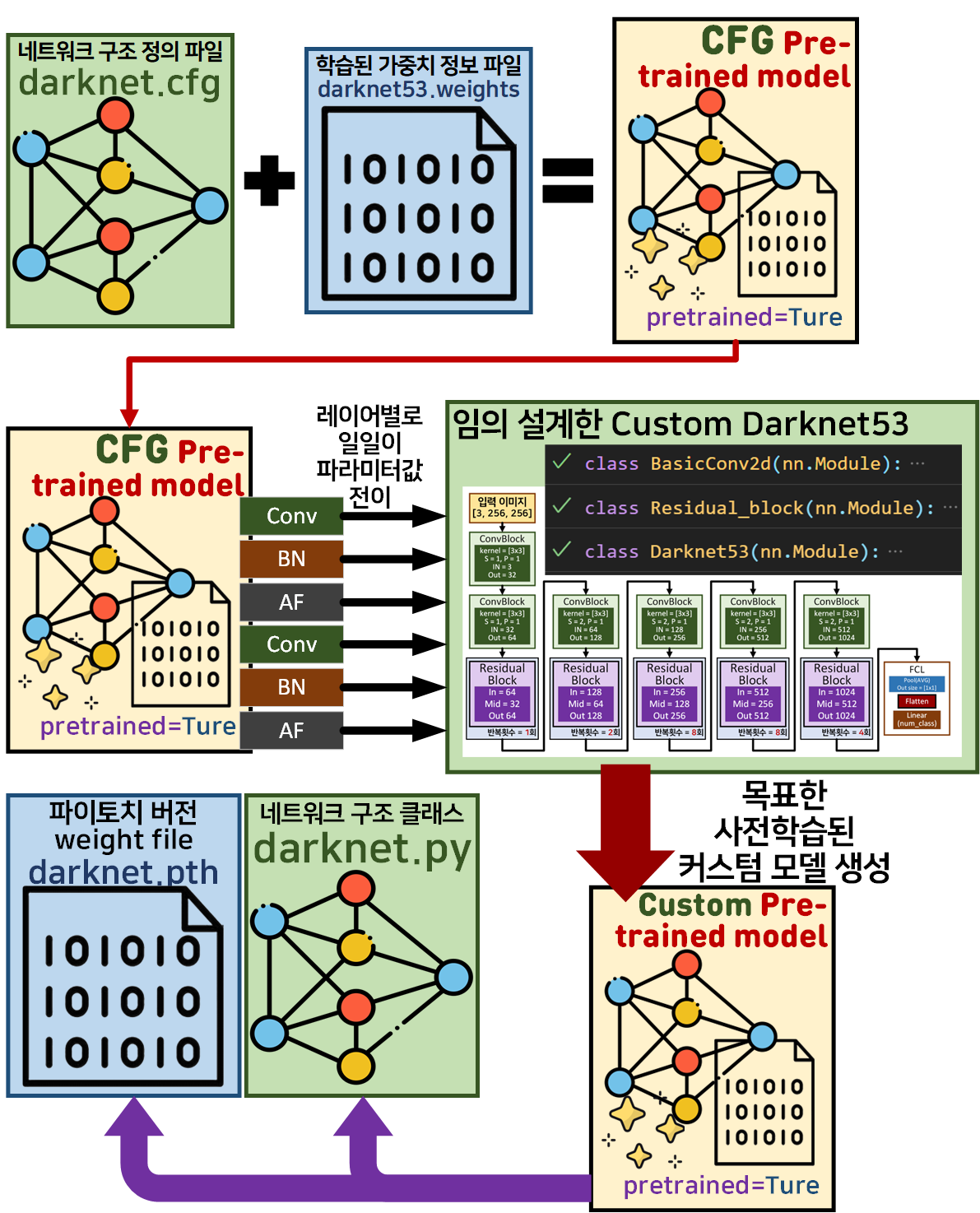
마지막 최종결과물인 darknet53.pth저 파일을 얻어내기 위해 이 긴 여정을 수행한것이다...
넷 상에서 얻어낸 darknet53.weights 파일은 파이토치의 가중치 파일 저장형식과 다른 방식으로 인코딩 되어 있기에
불가피하게 이 복잡한 과정을 거쳐서 가중치파일을 생성해냈다.
라고 보면 된다...

Q. 왜 Pre-Training을 수행하는 모델의 경우 옵티마이저를 Adam이나 RMSProp을 사용하지만
전이학습의 경우 대부분 SGD를 사용할까요?
