
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. Yolo v3
 Yolo v3의 저자 또한 이전 포스트에서 설명한 Yolo v1와 동일인인 Joseph Redmon이며, 그 사이에 Yolo v2(YOLO9000: Better, Faster, Stronger)이 존재한다.
Yolo v3의 저자 또한 이전 포스트에서 설명한 Yolo v1와 동일인인 Joseph Redmon이며, 그 사이에 Yolo v2(YOLO9000: Better, Faster, Stronger)이 존재한다.
이 중 Yolo v2는 Anchor box의 도입, 적합한 Anchor box를 생성하기 위해 k-means clustering 사용, 작은 객체를 더 효율적으로 탐색하기 위한 Fine-Grained Features 방법론의 적용과 같은 새로운 개념을 도입하였고
Yolo v3는 이를 더 다듬어서 k-means clustering을 도입하여 적합한 Anchro box의 생성을 5개에서 9개로 늘림,
크기별 객체 탐색을 효율화 하기 위해 Feature Pyramid Network적용, 클래스 탐지 성능 향상을 위해 Softmax - CrossEntropyLoss이 아닌 클래스 개개별로 Sigmod - Binary Cross-Entropy Loss(BLELoss)의 이진분류 문제로 class예측을 수행했다 라는 개선사항이 있다.
따라서 Yolo v1 에서 새로운 개념을 도입하여 성능을 향상시킨것이 Yolo v2라면, 이를 안정화 한것이 Yolo v3라 볼 수 있다.
이 중 필자는 이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (0) Yolo v3 사전 학습 모델 에서도 언급했다 싶이 Yolo v3를 구현하고자 하기에 Yolo v2에 대해서는 개념 언급 수준으로만 설명하고 넘어가고자 한다.
솔직히 Yolo v2 에서는 Hierarchical classification라는 방법론을 도입하여 9000가지 이상의 class를 탐지가 가능하다. 즉, 9000종 이상의 객체 종류를 구분하는 것이 가능하다 라고 주장하고 이를 논문의 제목명으로도 기재했지만
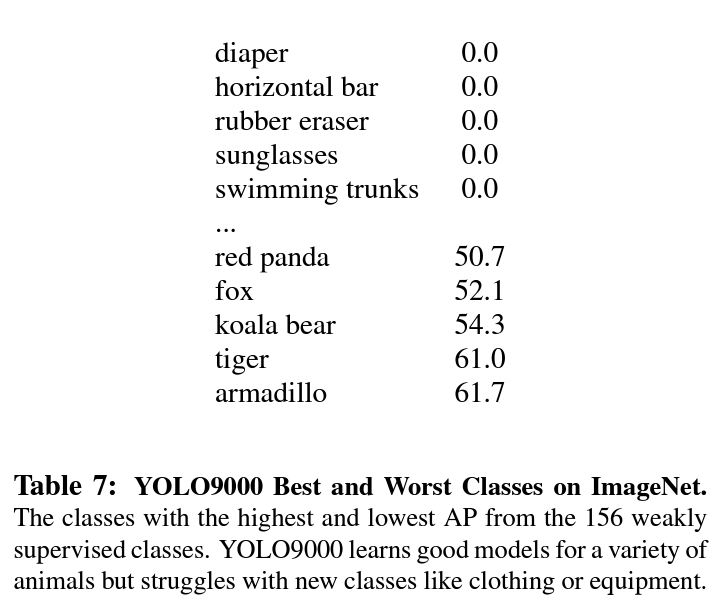 결과 표를 보면 알 수 있듯이 가장 잘 구분한 Classification성능도 60%를 간신히 넘기는 수준이기에 크게 의미있는 방법론이라 보기에는 어려움이 있다.
결과 표를 보면 알 수 있듯이 가장 잘 구분한 Classification성능도 60%를 간신히 넘기는 수준이기에 크게 의미있는 방법론이라 보기에는 어려움이 있다.
따라서 필자는 논문이 제시하는 Yolo v2 API가 자체적으로 불안정성이 있다 생각하며, Yolo v3은 "We made a bunch of little design changes"이란 서두로 Yolo v2 대비 약간의 개선을 이뤄냈다 설명하지만 오히려 이 부분이 API의 안정성 향상에 큰 기여를 했기에 해당 논문의 리뷰 및 코드구현을 수행하고자 한다.
1.1 v1 대비 v2, v3의 주요 개선사항
Yolo v1 대비 v2, v3의 주요 개선사항으로는
- Backbone에
Batchnormalization도입 : 이전 포스트인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (1) 모델 설계의
Yolo v1 Darknet의 기본 블록에는
class YoloConv(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(YoloConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bachnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.LeakyReLU(negative_slope=0.1)
def forward(self, x):
x = self.conv(x)
x = self.bachnorm(x)
x = self.relu(x)
return xself.bachnorm = nn.BatchNorm2d(out_channels)
와 같이 BN레이어가 포함되어 있지만 Yolo v1 논문이 발표되는 시점에는 해당 레이어가 포함되지 않은 채로 Darknet이 구현되었다.
하지만 Yolo v3, Yolo v2 모두 기본 블록에 BN이 포함되며,
이 중 Yolo v3는 Residual Block기법까지 도입하여 더 향상되고 깊은 Backbone을 사용한다.
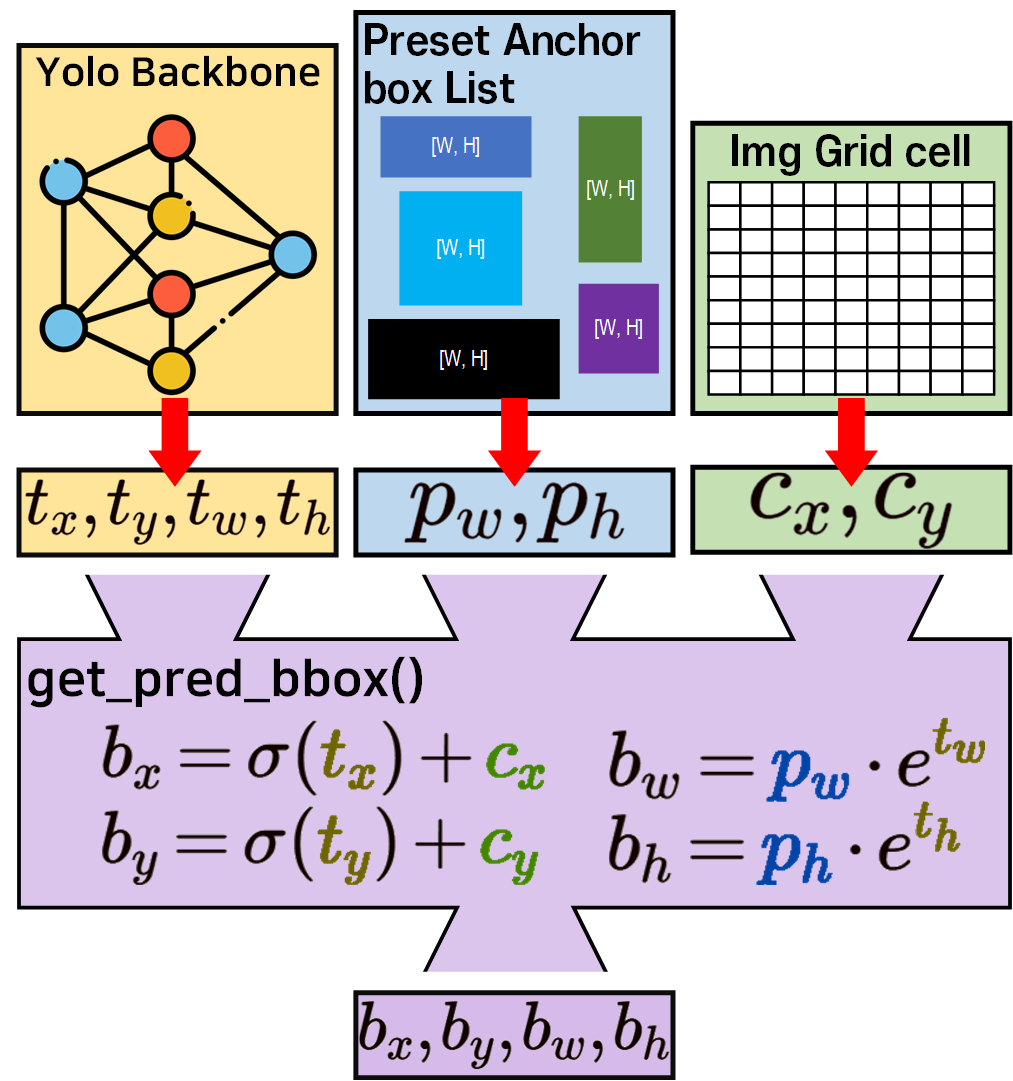
2. Anchor box의 도입 : Yolo v2부터 도입된 Anchor box와 해당 개념을 통하여 Pred B_Box를 예측하는 과정은 아래의 이미지를 통해 설명할 수 있다.
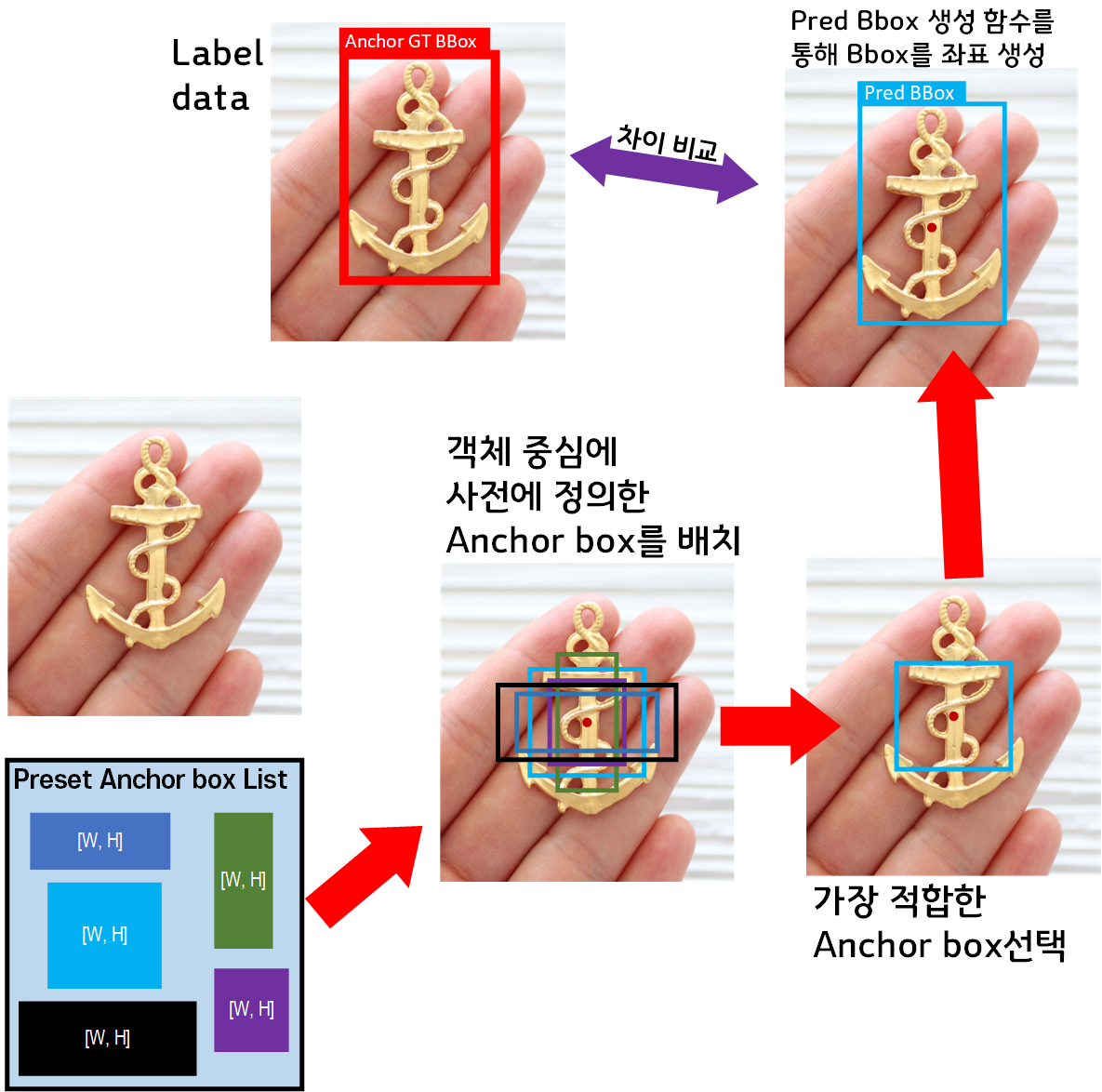
라벨 데이터는 Img, Anno 두가지 데이터로 나뉘고, Anno에는 GT BBox에 대한 좌표정보가 담겨 있음은 모두가 알 것이다.
Yolo v2는 Anno에서 GT BBox의 중심좌표점을 추출하는것은 v1과 동일하나, 이때 바로 Pred BBox를 예측하는 것이 아닌 사전에 정의된 Preset Anchorbox List가 존재한다.
이 Preset Anchorbox List에서 Anchor box 를 각각 꺼내어 객체에 붙여 본 뒤, 가장 적합한 Anchor box 만을 남기는 필터링 과정을 수행한다.
이후 Anchor box 에 변환 함수를 적용해 Pred BBox를 생성하고 이를 GT BBox와 비교하여 손실을 계산하는 식이다.
여기서 Yolo v2와 Yolo v3의 차이점은 사용되는 Preset Anchorbox List가 5개에서 9개로 더 늘어나서 다양한 객체크기에도 대응이 가능하다는 점이다.
3. K-means clustering : 2번 항목인 Anchor box에는 Preset Anchorbox List를 사전에 제작하는데, 이 Preset Anchorbox List를 만드는 근거가 필요하다

이 근거를 Yolo v2에서는 K-means clustering을 도입하여 Preset Anchorbox List의 크기정보를 생성했다.
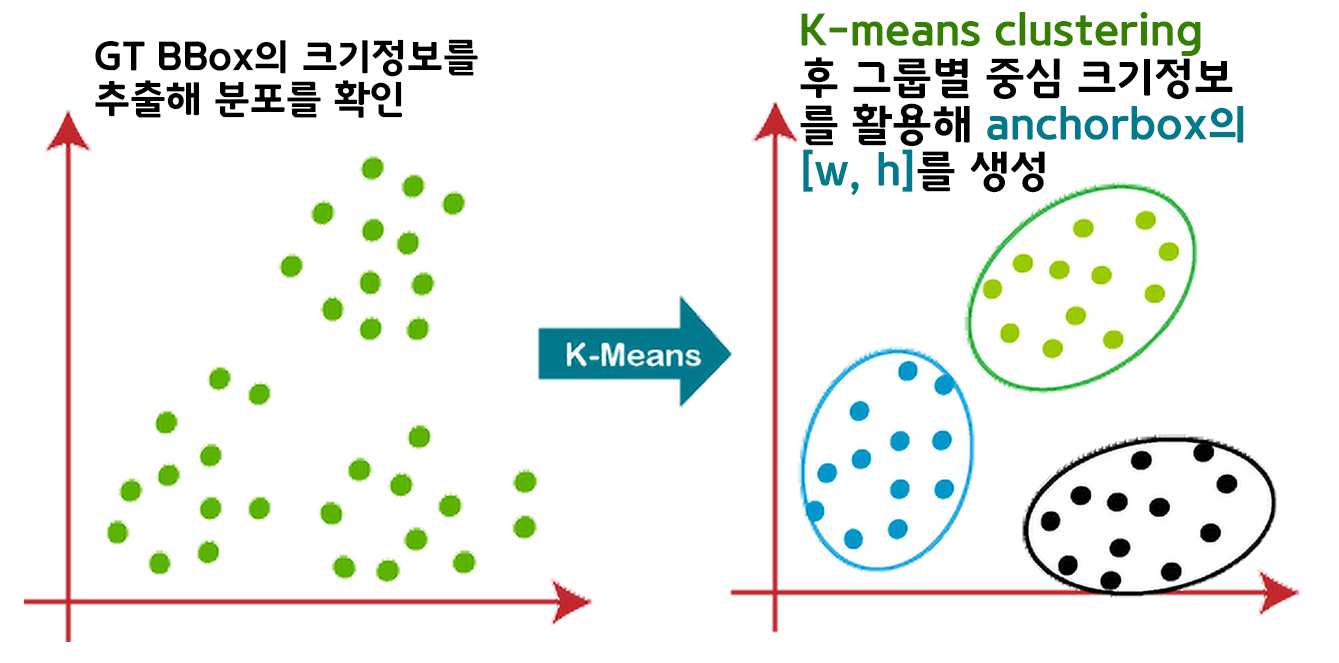
이때 Yolo v2는 Pascal VOC 2007, 2012데이터셋의 Anno 정보를 활용 K-means clustering 5개의 Preset Anchorbox List 생성
Yolo v3는 COCO 데이터셋의 Anno정보를 활용 9개의 Preset Anchorbox List 생성한 차이가 있다.

아무튼 각 버전별로 생성한 Anchor box의 [W, H]크기정보는 위 사진과 같다.
여기서 하나 이상한게 Yolo v2의 Preset Anchorbox List는 그 값의 범위가 1~11인데 반해
Yolo v3는 이건 누가 봐도 픽셀 사이즈의 [W, H]라는 것이 유추가 된다.
이것은 단위의 차이로, Yolo v2는 하나의 Grid cell에 대한 상대적인 크기로 Preset Anchorbox List를 생성했다면,
Yolo v3는 사용하는 이미지가 모두 [416, 416] 사이즈라 했을 때 사용되는 Anchor box의 [W, H]라 보면 된다.
따라서 Yolo v2의 기본 Grid cell 크기가 [32x32]이니 해당 값을 Yolo v2의 [W, H]에 곱해주면 Yolo v3의 Preset Anchorbox List와 같은 스케일로 변환하여 비교할 수 있다.
1.2 Anchor box -> Pred BBox 계산방법
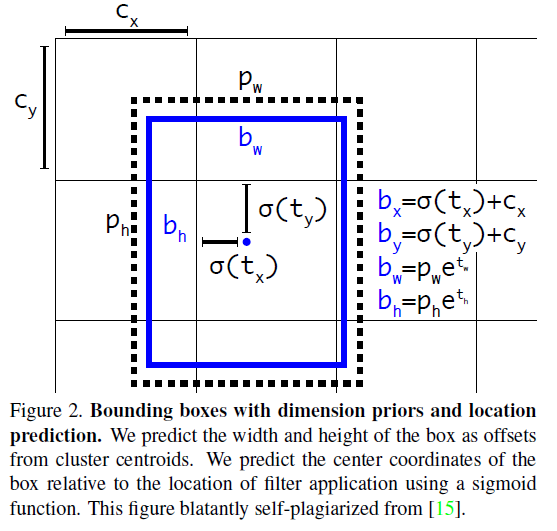 Yolo v2, Yolo v3모두 Anchor box로 부터 Pred BBox를 연산하는 수식은 위 사진으로 동일한 수식을 사용한다.
Yolo v2, Yolo v3모두 Anchor box로 부터 Pred BBox를 연산하는 수식은 위 사진으로 동일한 수식을 사용한다.
이게 수식만 봐서는 잘 이해가 안되니 그림으로 이해를 보조하도록 하겠다.
 이렇게 보면 수식이 이해가 안될 것이라 생각하지는 않는다.
이렇게 보면 수식이 이해가 안될 것이라 생각하지는 않는다.
Yolo의 모델과 Anchor box, 그리고 Yolo시리즈는 입력되는 이미지를 Grid cell로 분할 처리하니 각 Grid cell에 대한 좌표정보가 발생한다. 이것의 좌 상단 좌표가 이다.
1.2.1 get_pred_bbox 수식의 추가설명
논문에서 설명하는 그림이 잘 이해가 안가서 대충 얼머부리려다가 호되게 당해서 각잡고 다시 설명하려 한다.
우선 모델에서 출력되는
이 4개의 값은 모두 난수이라 생각하자.
-inf ~ inf 사이의 온갖 값이 다 된다고 보면 된다.
이것을 전제로 놓고 이미지에서 Grid cell의 인덱싱이 어떻게 되는지 확인하자.
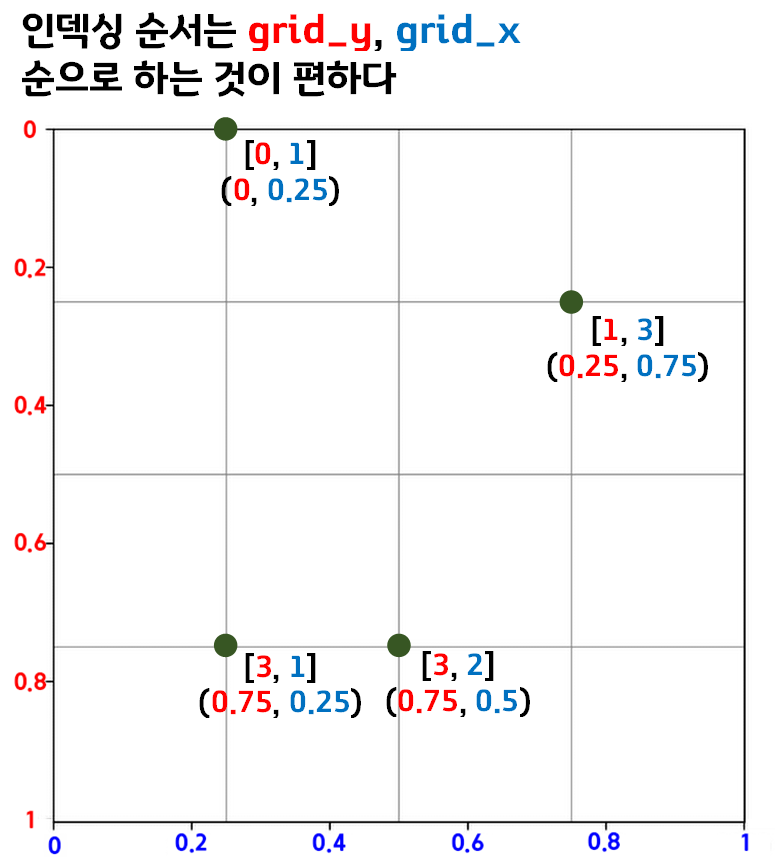
이미지를 정규 좌표평면
(width, height를 모두 [0~1]사이로 스케일링 한 좌표평면)
으로 놓고 볼 때 위 사진처럼 Grid cell의 인덱싱이 가능하다.
이때 순서를 [grid_idx_Y, grid_idx_X]순으로 익히는 것이 좋다.
tensor이나 numpy자료형 모두 저 순서데로 인덱싱하기에 저렇게 외워야 한다.
그리고 Y랑 X의 좌표가
어디가 0이고(어디가 시작인지?)
어디가 1인지(어디가 끝인지?)도 외워라
Y = Top:0, Down:1
X = Left:0, Right:1
걍 저렇게 쓴다... 참 헤깔리게...
그리고 여기서 [cy, cx], [by, bx], [tx, ty]의 관계를
아래의 그림으로 표현할 수 있다.
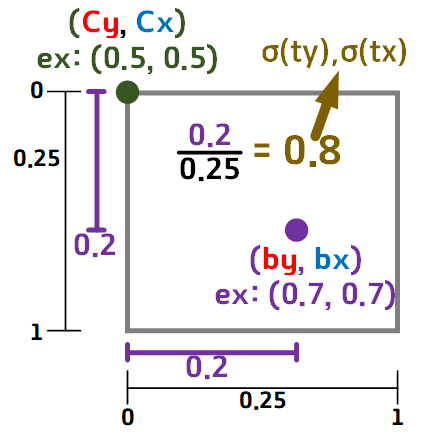
Grid cell의 좌 상단 좌표가 [cy, cx]로 놓았을 때
하나의 Grid cell 의 크기에 대하여 작은 정규 좌표평면을 만들고
이 작은 정규 좌표평면에서 [cy, cx] 와 [by, bx]의 차이값이 [(ty), (tx)]이 된다.
즉, [(ty), (tx)]는 [cy, cx] ~ [by, bx]의 상대적인 거리..
뭐 이정도로 해석이 가능할 것 같다.
진짜 더럽게 어렵게 좌표해석을 해놨다.
이걸 이해했으면
는 이해가 쉬울 것이다.
딱 이거인데 이 K라는 값 대신 e지수를 사용한 이유는
값이 무조건 양수
라는 장점이 있어서이다.
지수함수는 모든 x에 대해 y가 양수니.. 이 장점으로 쓴다
라고 보면 된다.
이렇게 좌표변환에 대한 이해가 사전에 있어야 한다.
2. v2 대비 v3의 개선사항
2.1 Bounding Box의 Loss측정 방식 변경
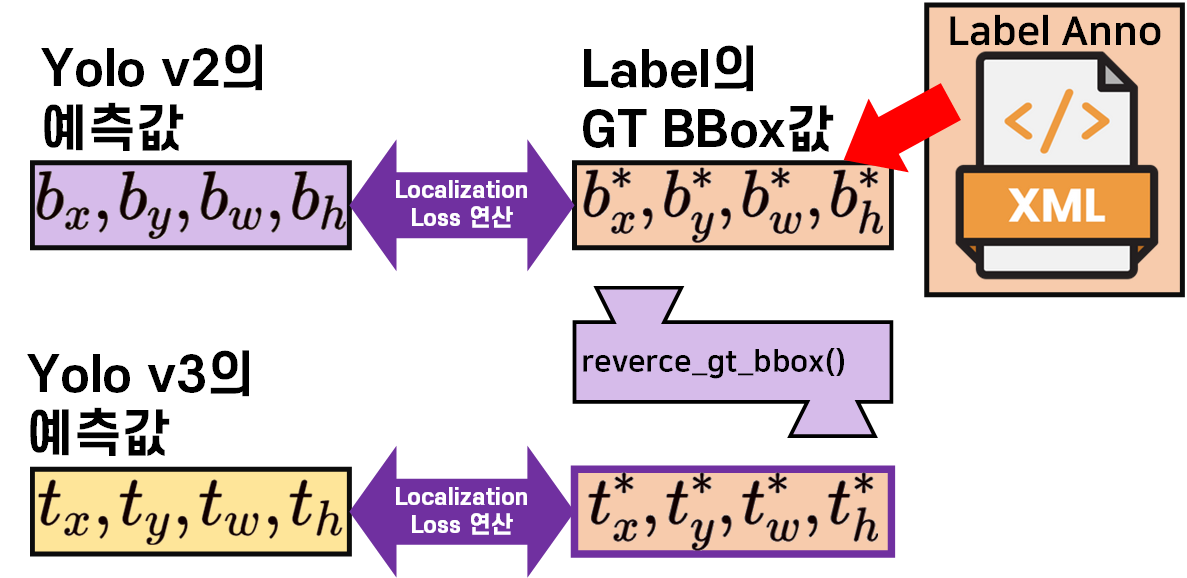 첫번째 변경사항은 위 사진으로 표현할 수 있듯이 Yolo v2의 Backbone에서 출력된 값이 이라면, 이를
첫번째 변경사항은 위 사진으로 표현할 수 있듯이 Yolo v2의 Backbone에서 출력된 값이 이라면, 이를 get_pred_bbox()함수를 통과시켜 를 생성한 뒤 이를 GT_BBox의 와 위치 손실 (Localization Loss)비교연산을 수행한다.
반대로 Yolo v3는 GT_BBox의 항목을 get_pred_bbox()와는 연산과정이 반대로 되어있는 reverce_gt_bbox()함수를 통과시켜 를 생성한 뒤 이를 Yolo v3 Backbone을 통과하여 얻은 예측값 와의 위치 손실 (Localization Loss)을 계산한다.
학습이 진행되면서 주요하게 변경되는 값은 Backbone의 출력값이라 할 수 있는 이니 해당 값에 대해 직접 위치 손실 (Localization Loss)을 계산하는 방식으로 변경한 것이 Yolo v3의 첫번째 개선사항이라 볼 수 있다.
2.2 Multi-class Prediction의 개선
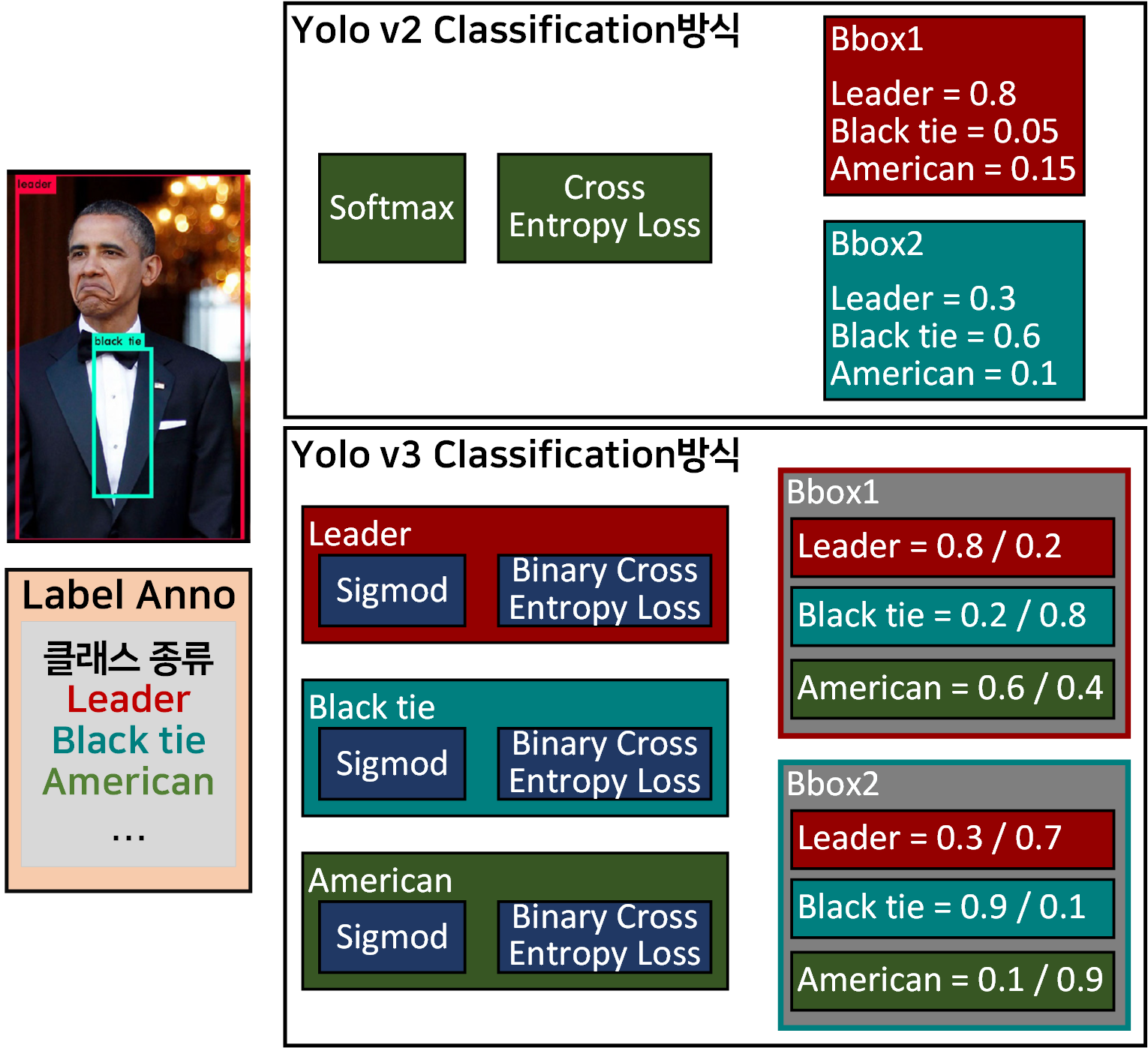 위 사진처럼 두개의 BBox가 겹친 것과 같은 복잡한 상황이 발생하는 경우 Yolo v2는 기존의 박식대로 Softmax Cross Entropy Loss를 연산하여 해당 BBox내 객체의 Class를 예측하는데 이때 중첩된 BBox의 정보가 서로 연관되어 Class 예측성능을 떨어트리는 경우가 발생할 수 있다.
위 사진처럼 두개의 BBox가 겹친 것과 같은 복잡한 상황이 발생하는 경우 Yolo v2는 기존의 박식대로 Softmax Cross Entropy Loss를 연산하여 해당 BBox내 객체의 Class를 예측하는데 이때 중첩된 BBox의 정보가 서로 연관되어 Class 예측성능을 떨어트리는 경우가 발생할 수 있다.
이를 Yolo v3에서는 각 라벨별로 독립된 Sigmod Binary Cross Entropy Loss를 수행하기에 BBox별로 독립된 class를 예측, 주변 정보로부터 Class예측에 영향을 끼치는 상황을 최소화 했다는 개선사항이 있다.
2.3 객체 크기에 강인한 객체 탐지방법론
Yolo v2와 Yolo v3 모두 객체를 탐지할 때 다양한 객체의 크기에 대해서도 좀 더 강인하게 탐지 결과를 도출 할 수 있는 새로운 방법론을 도입했다.
단, 이 방법론의 차이가 존재하며, Yolo v2는 크기가 작은 객체에 대한 탐지율이 높아졌다면, Yolo v3는 더 다양한 객체의 크기에도 강인하게 객체 탐지율이 높아진, 좀 더 개선된 성능을 낸다 볼 수 있다.
2.3.1 Yolo v2: Fine-Grained Features
Yolo v2는 입력 이미지를 [3, 416, 416]사이즈로 받고 여기에 13x13 gird cell으로 이미지를 분할하기에 모델에서 출력되는 output Feature는
[13x13xN]의 3차원 Tensor구조가 출력된다.

여기까지만 수행하면 Yolo v1의 Grid cell이 [7x7]이니 단순하게 Grid cell개수만 늘린 꼴이 된다.
Yolo v2에서는 사용한 Backbone의 Conv 레이어 중 중간 레이어에서 출력되는 Feature map을 추출한 뒤 이를 Reshape하고 말단의 Conv 레이어 출력 Feature map와 Concat 과정을 수행한다.
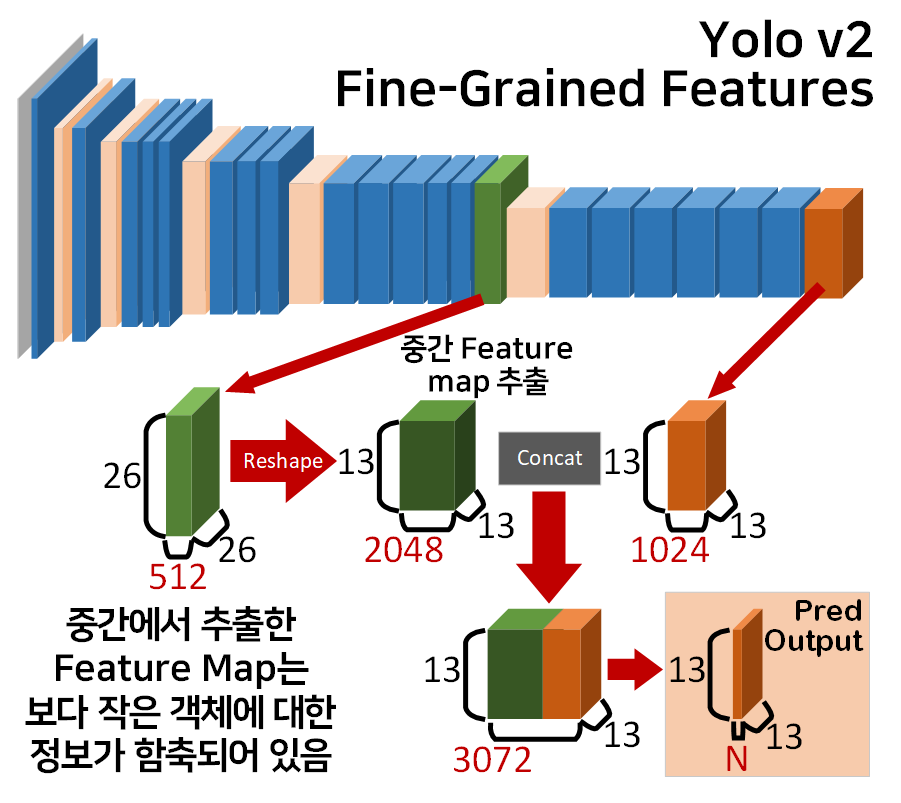 Yolo v2의 Backbone인
Yolo v2의 Backbone인 Darknet19의 구조를 기반으로 Fine-Grained Features를 설명하자면
위 사진처럼 중간에 [26x26x512]의 Feature Map을 추출한다.
해당 Feature Map는 말단에서 추출하는 Feature Map 대비
보다 작은 객체에 대한 정보이 함축되어 있는데
이를 말단 Feature Map와 Concat을 수행한 뒤 다시 Conv layer를 통과하여 최종 출력 Output Feature Map인 [13x13xN]을 만들어낸다.
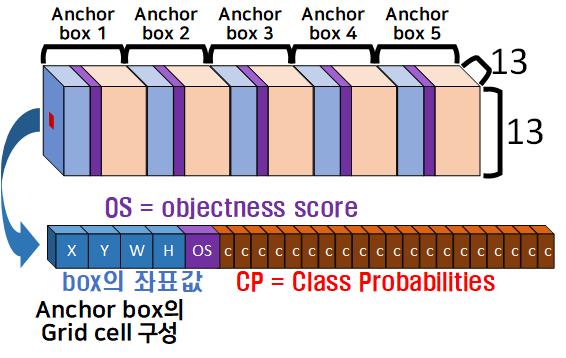
이제 [13x13xN]에서 [N]값에 대해 이야기 하자면 5개의 Anchor box가 연달아 붙어 있는 구조이고, 하나의 Anchor box는 BBox의 좌표값, OS, CP이렇게 3가지 값으로 구성되어 있다.
Yolo v2논문이 작성된 시점에서 해당 API의 성능 평가에 사용된 데이터셋은 PASCOL VOC 2007, 2012 이기에 CP = 20으로
(4 + 1 + 20) X 5 = 125 = N
가 된다.
2.3.2 Yolo v3: FPN(Feature Pyramid Network)
Yolo v3은 앞서 언급한 Yolo v2의 Fine-Grained Features기법을 좀 더 발전시켜서
Yolo v3를 Backbone, Neck, Head 3가지 구조로 정형화시켰으며, 이 중 Neck에 해당하는 구조가 FPN(Feature Pyramid Network)을 따르고 있다.
이렇게 이해할 수가 있다.
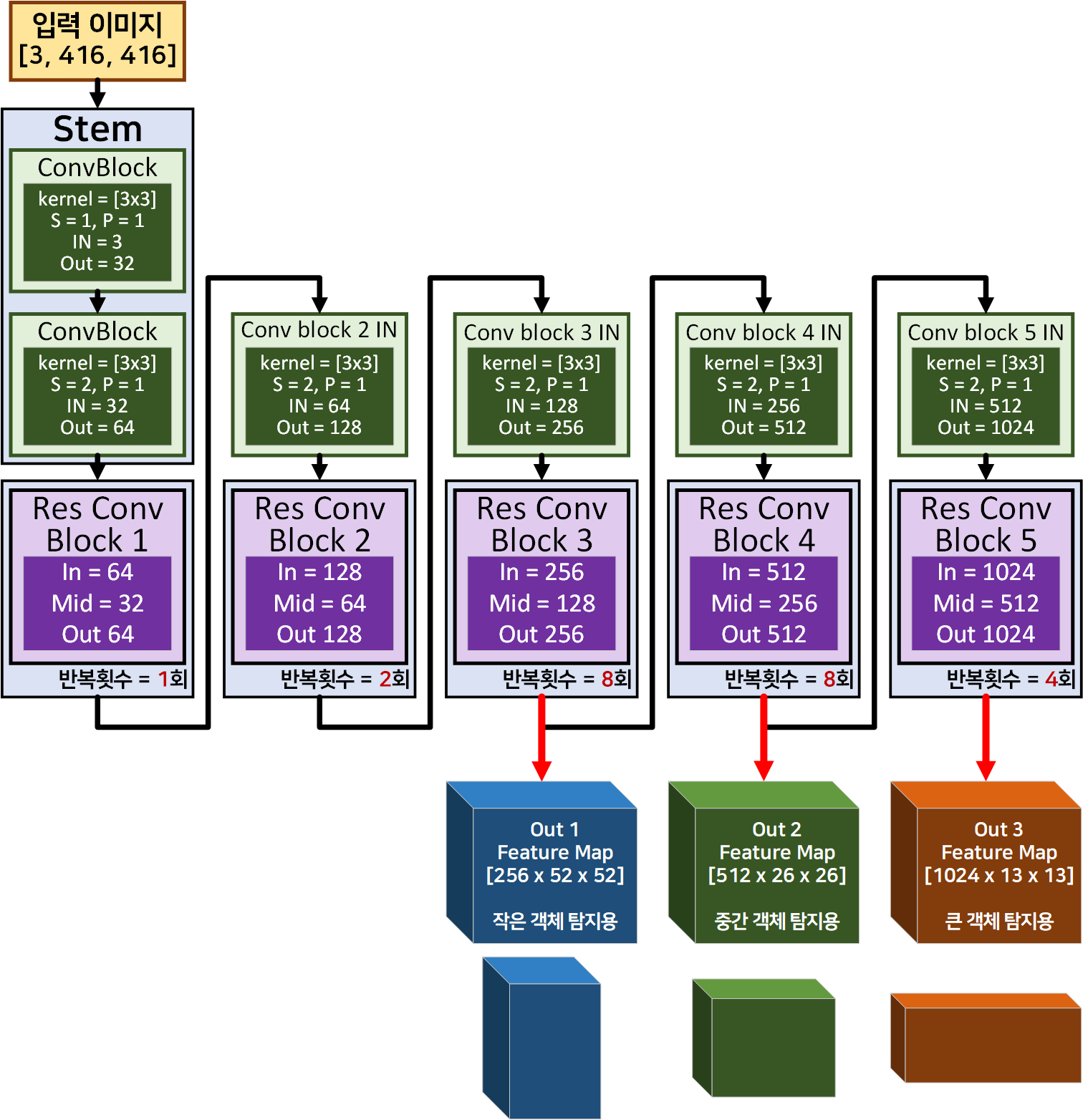 위 3가지 구조를 구현하기 위해서는 먼저 Backbone에 해당하는
위 3가지 구조를 구현하기 위해서는 먼저 Backbone에 해당하는 DarkNet53을 위 사진처럼 중간 Feature Map을 출력하는 형식으로 살짝 코드 변경을 해준다
(forward메서드만 코드변경을 수행하면 된다)
이 다음 Neck, Head가 붙어서 최종 Output Feature Map이 출력되는데 이는 아래의 그림과 같다.
 위 사진처럼 다양한 객체 탐지를 위해 네트워크의 깊이별 출력되는 Feature Map의 성향을 파악하고
위 사진처럼 다양한 객체 탐지를 위해 네트워크의 깊이별 출력되는 Feature Map의 성향을 파악하고
깊은 레이어의 출력 정보를 Upsample 후 얕은 레이어의 출력정보와 Concat하여
얕은 레이어에서 출력되는 Feature Map의 추상적 정보를 보상
얕은 레이어의 Feature Map정보도 효과적으로 목표하는 크기의 객체 탐지가 가능하게끔 보완하는 작업을 수행한다.
이 구조에 대해서는 잘 이해가 되지 않지만
아무튼.. 최종 출력물인 Head는 아래의 그림으로 표현 할 수 있다.
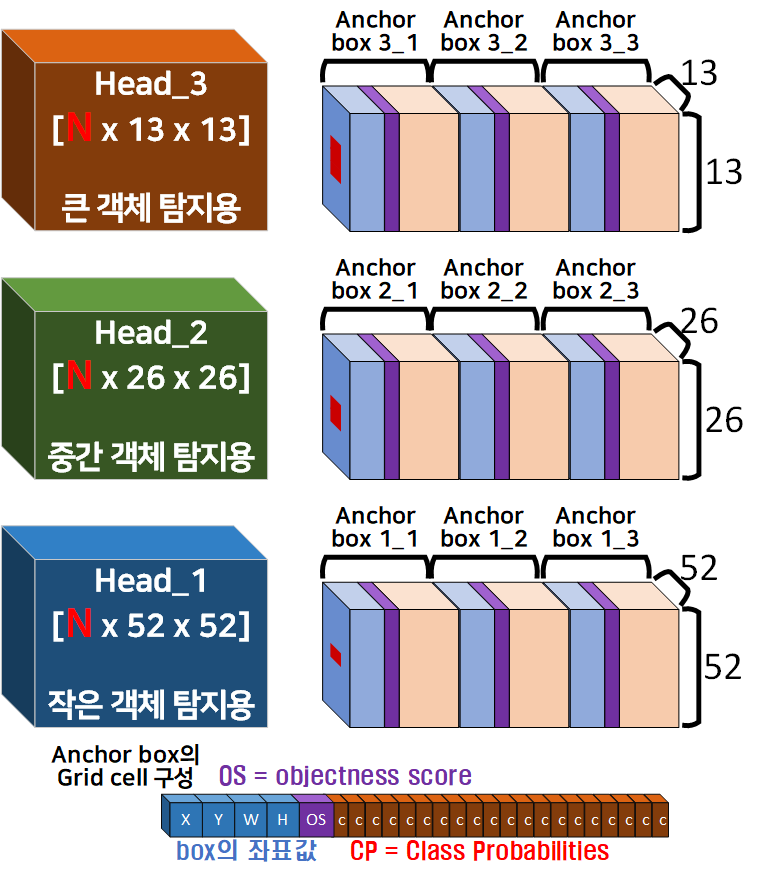
Yolo v3의 경우 COCO데이터셋을 기반으로 논문의 실험을 수행했기에
COCO데이터셋의 class종류 = 80
(4 + 1 + 80) X 5 = 255 = N
가 된다.
2.4 v1, v2, v3의 Objectness Score
v1, v2, v3 모두 해당 Grid cell에 객체가 존재하는지? 안 하는지? 에 대한 평가값으로
Objectness Score을 사용한다.
이 Objectness Score는 Yolo v1에서는 Confidence Score라 불렸던 개념이다.
이는 버전이 진행되면서 좀 더 명확한 표현으로 단어변경이 이뤄진 것이다.. 라고 보면 될 듯 하다.
아무튼 Objectness Score는 v1, v2에서 계산 방식은 IOU를 기반한 확률값을 설정했으나,
v3에서는 로지스틱 회귀를 기반으로 Objectness Score를 정의하는데 Yolo v2와 Yolo v3에 적용되는 OS, CP값은 향후 Loss Function을 연산할 때 두 값은 모두 BCE(Binary Cross Entropy)로 손실값을 계산하니 모두 계산 전 sigmoid로 스케일 처리를 해줘야 한다.
음.. 이론공부는 이정도로 하면 될것 같다.
 나름 설명을 적고있는거 같고 있긴 한데 뭐라 쓰고 있는건지 스스로가 이해가 안되고 흠...
나름 설명을 적고있는거 같고 있긴 한데 뭐라 쓰고 있는건지 스스로가 이해가 안되고 흠...
코드를 보자 코드를
