오늘은 평소보다 1시간 일찍 나와서 프로젝트1일 차 저녁부터 진행해본 웹 크롤링을 아침 약 40분 정도 진행해보다 우리 조가 진행할 프로젝트 모델링을 위한 aquerytool 을 보며 따라해보기를 시도 했다.
에이쿼리 툴 뿐만 아니라 모델링에 대해 취약점을 계속 발견해서 스스로 자신감이 많이 위축되었다는 느낌을 받았다.
일단 점심식사 전까지 될것만 같은 아니 되는 크롤링을 진행했다.
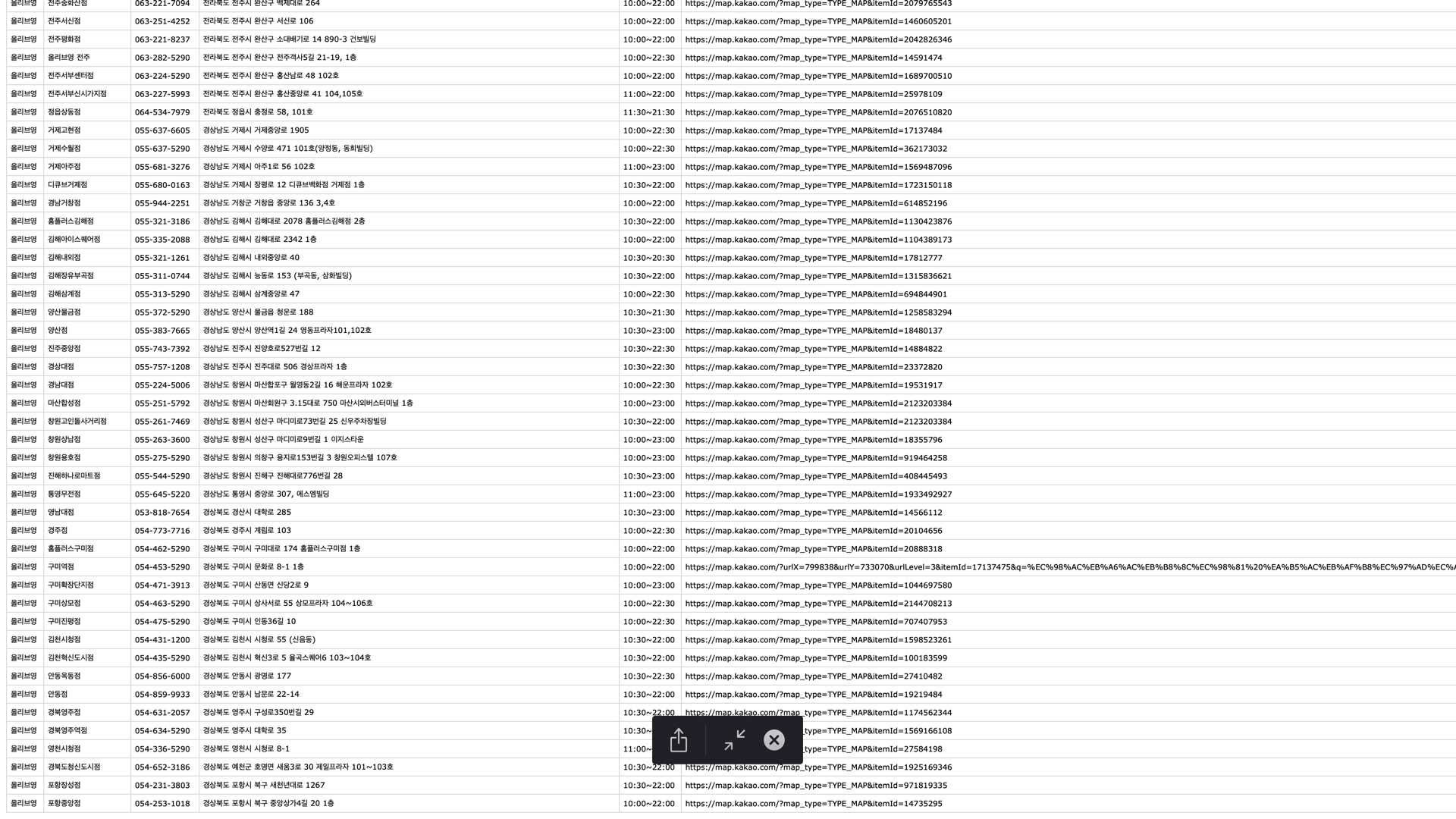
https://laka.co.kr/store/index.html
내가 크롤링 진행한 페이지는 STORE 파트에 있는 LAKA 코스메틱을 판매하는 매장들의 정보를 파싱하는 것이였다.
BeautifulSoup 으로 하면 금방이겠거니 이전 빌보드 TOP 100 에 적용했던 대로 코드를 작성해 보니 전혀 진행이 되지 않았었다.
조원분과 함께 이야기 나눈 내용은 Selenium 을 사용하여 파싱하는 것이였다.
Selenium 에 대해 들어는 봤지만 직접 만져보고 아 동적인 웹페이지를 마치 매크로 처럼 커서를 움직여가며 웹의 정보를 파싱해 올 수 있구나 라는 것을 하루 전 월요일에 알게 되었다.
스타벅스의 데이터를 크롤링 해오는 세션에서 였다.
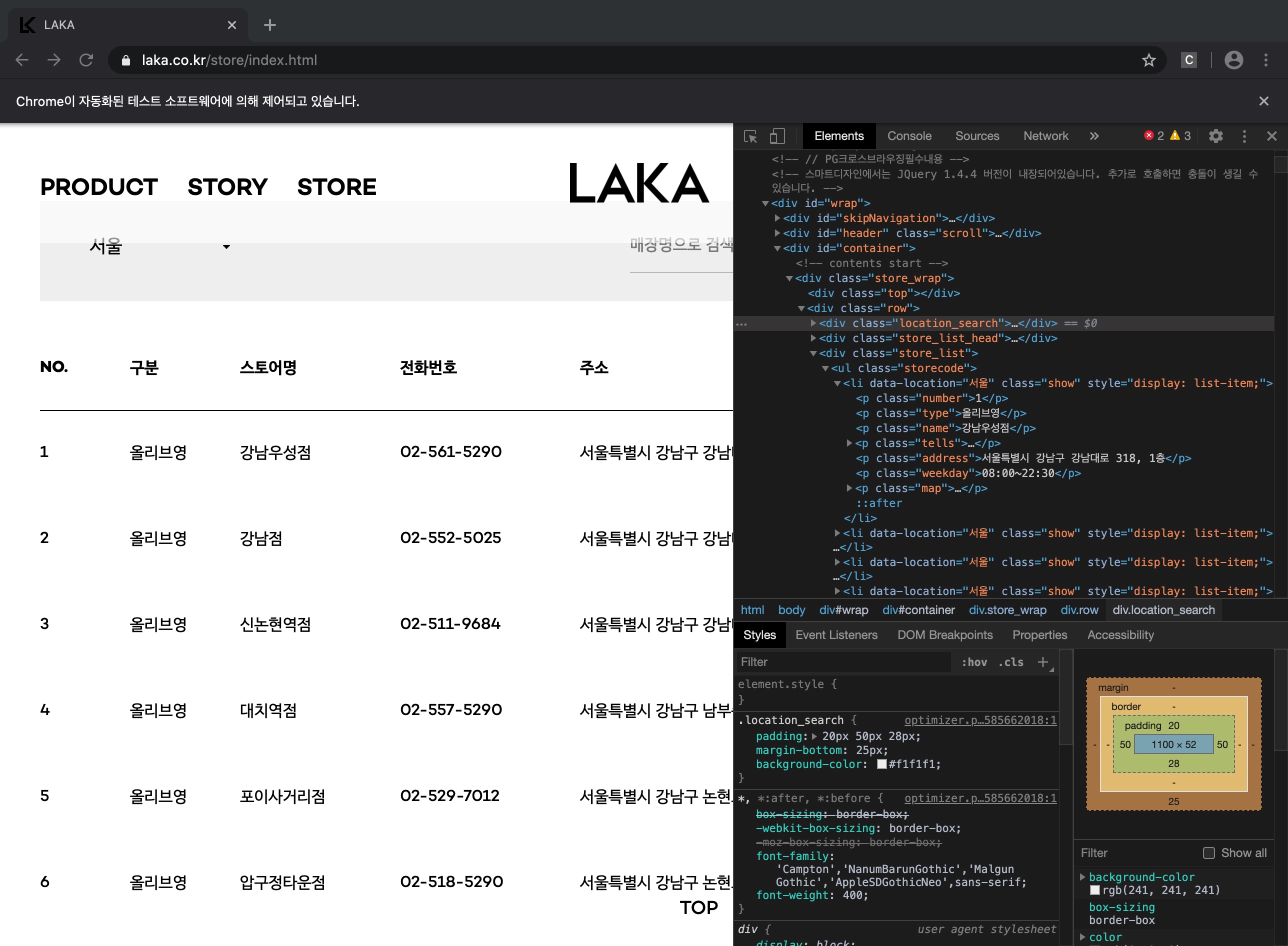
중간 중간 print 를 섞어 써 가면서 오류를 찾고 바로잡아 가는 과정을 거쳤는데, 크롬 개발자도구를 이용하여 접근하고자 하는 태그 부분을 클릭해 우클릭하여 copy selector 누르면 자동 복사가 된다.
맨 처음으로 파싱하려는 스토어명에 커서를 갖다 대고 해당하는 부분을 살펴 보니 아래와 같았다.
#container > div > div.row > div.store_list > ul > li:nth-child(1) > p.type
물론 나의 경우는 첫번째 child 의 요소만 가져올 것이 아니기 때문에 아래와 같이 적용했다.
#container > div > div.row > div.store_list > ul > li > p.type위의 코드로 두들겨보니 아래 빈 문자열이 잔뜩 나온다.
음 이것을 어떻게 지우나 찾아보다가 ( 아래 링크 참조 )
https://jinmay.github.io/2019/06/30/python/python-how-to-delete-empty-string-in-list/
list = ' '.join(list).split()의 코드를 적용해 보니까
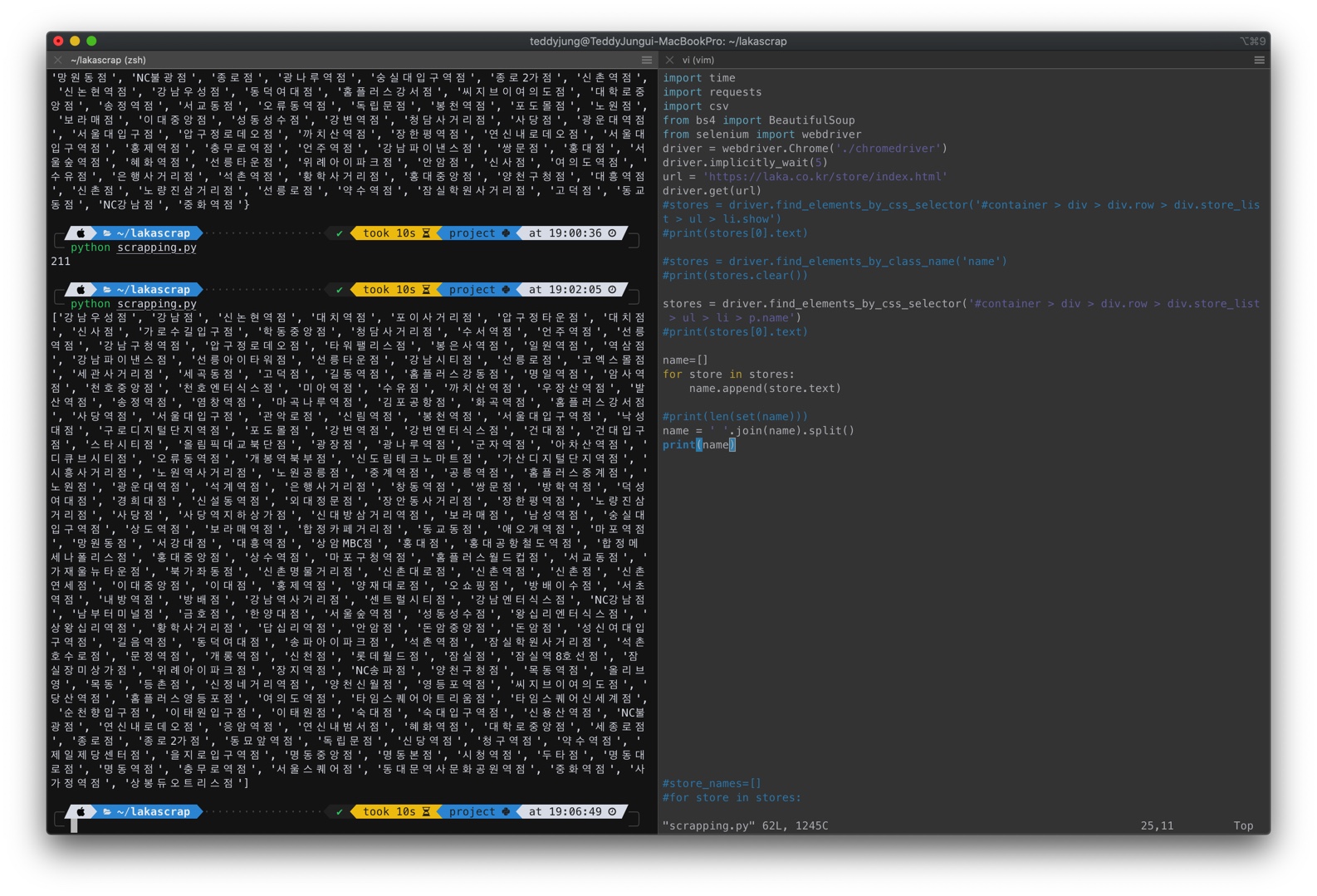
오호 빈 문자열이 더이상 출력되지 않는다.
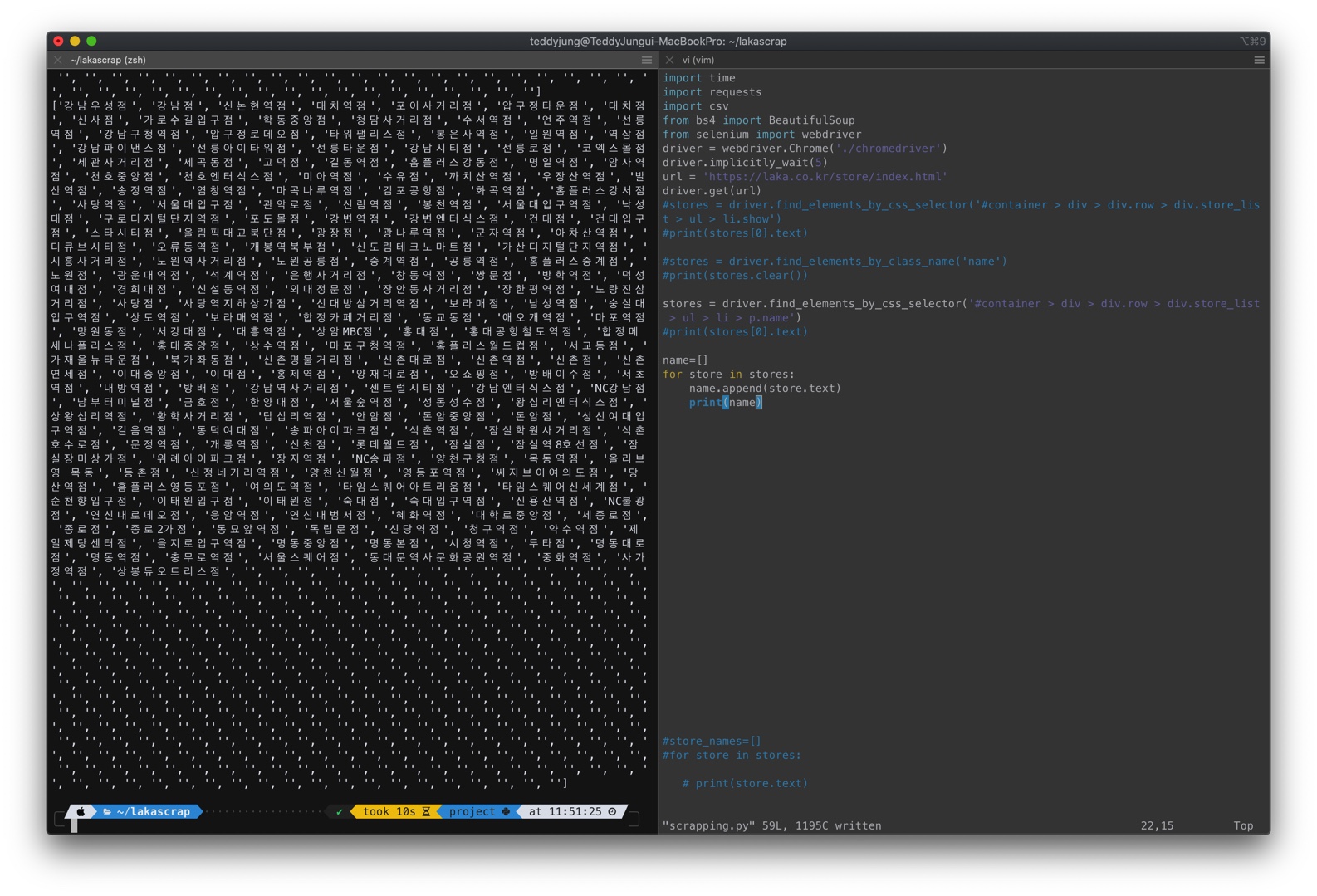
이에 나머지 요소들도 가져와 요소 한개씩 출력해가다가 이걸 코드를 짧게 하나로 합칠 수 있을 거같아서 시도하면서 멘토님께 질의를 드렸다. 일단 속도를 위해 지금 알아낸 방향대로 가고 나중에 리팩토링 해도 된다 하셔서 그대로 진행해 보기로 했다.
여기서 깨닫지 못했지만 크롤링을 금방 다 했구나 싶었다.
하지만 페이지를 처음 열면 서울의 매장 정보들이 디폴트로 나오고 전체, 서울, 경기, 인천, 부산, 대구, 광주 카테고리로 선택을 할 수 있다는 것을 알게 되었다.
그 뜻은 결국 전체 스토어 정보를 가져와야 한다는 것이였다.
여기서 또 하나 깨닫지 못한 것은 그 서울만의 스토어 정보를 파싱하는 것도 제대로 이루어지지 않았었다는 점이였다. 그리고 csv 파일로 만들어 눈으로 확인해 보니 내가 원한 모습이 아니였다.
내가 원한 모습은 행과 열이 구분이 되게 이루어진 모습이였다.

모두 진행하다가 csv 파일을 만들기 위해서는 아래 과정을 거쳐야 되는 것을 알게 되었다.
불과 어제 세션에서 진행한 내용을 그대로 적용해 보았다.
starbucks = [{
'name' : props[0],
'description' : props[1],
'image' : props[2]
} for props in zip(product_names,product_desc, product_images)] #zip메소드 인덱스가맞다는 보장하에서는 가공이쉬운 딕셔너리
with open('output.csv', 'w') as csvfile:
csvout = csv.DictWriter(csvfile, ['name','description','image'])
csvout.writeheader()
csvout.writerows(starbucks)위 부분에 대해서는 좀 더 심도 깊은 학습이 필요하다.
그리고 다시 실행. 서울 부분의 스토어명이 찍혀 나온다.(아직까지 틀린 점을 깨닫지 못했다)
셀레니움은 클릭하는 동작을 파이썬 코드로 구현해 줄 수 있다.
driver.find_element_by_css_selector('#container > div > div.row > div.location_search > div.location_filter > p > button').click()
driver.find_element_by_css_selector('#container > div > div.row > div.location_search > div.location_filter > ul > li:nth-child(1) > button').click()
디폴트가 '서울' 로 되어있는 버튼을 한번 클릭하고 다시 '전체' 라는 버튼을 누르도록 (총 2번 누르도록) 코드를 입력해 주었다.
그러나 최종 csv 파일을 확인해 보니까 스토어명이 밀려서 제대로 옆의 주소나 전화번호와 대응이 되지 않았다.
time.sleep 이라는 기능도 넣어줬다. 하지만 오류는 동일했다.
어디서 오류인지 눈으로 일일히 따져 봤는데 스토어명 중에 '올리브영 목동' 이라는 명칭이 있었다.
올리브영
목동이런 식으로 출력되어서 밀렸던 것이였다.
list = ' '.join(list).split() 이 코드를 잘 못 오용한 것이였다.
검색을 통해 기능을 알아보는 것도 좋지만 제대로 알고 사용해야 겠다고 느낀 순간이였다.
코드를 주석 처리하고 실행해보니 정상 동작하는 것을 확인 할 수 있었다.
전체 코드는 아래와 같다. 상당 부분 줄일 수 있을 듯한 코드의 냄새가 나는데 솔직히 좀 부끄럽기도 하다.
import time
import requests
import csv
import re
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(5)
url = 'https://laka.co.kr/store/index.html'
driver.get(url)
time.sleep(5)
driver.find_element_by_css_selector('#container > div > div.row > div.location_search > div.location_filter > p > button').click()
time.sleep(5)
driver.find_element_by_css_selector('#container > div > div.row > div.location_search > div.location_filter > ul > li:nth-child(1) > button').click()
stores_div = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.type')
stores_name = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.name')
stores_tel = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.tells > a')
stores_add = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.address')
stores_time = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.weekday')
stores_map = driver.find_elements_by_css_selector('#container > div > div.row > div.store_list > ul > li > p.map > a')
division=[]
for div in stores_div:
division.append(div.text)
#division = ' '.join(division).split()
name=[]
for store in stores_name:
name.append(store.text)
#
#print(name)
tel=[]
for num in stores_tel:
tel.append(num.text)
tel = ' '.join(tel).split()
#print(tel)
address=[]
for add in stores_add:
address.append(add.text)
#address = ' '.join(address).split()
#print(address)
opentime=[]
for time in stores_time:
opentime.append(time.text)
opentime = ' '.join(opentime).split()
#print(opentime)
location=[]
for loca in stores_map:
location.append(loca.get_attribute('href'))
#print(location)
storeinfo = [{
'division' : props[0],
'name' : props[1],
'tel' : props[2],
'address' : props[3],
'opentime' : props[4],
'location' : props[5]
} for props in zip(division, name, tel, address, opentime, location)]
with open('output.csv', 'w') as csvfile:
csvout = csv.DictWriter(csvfile, ['division','name','tel','address','opentime','location'])
csvout.writeheader()
csvout.writerows(storeinfo)