Hands-On ML Ch 3: Classification
Scikit-learn 에서 제공하는 MNIST 데이터셋은 이미 train set 가 잘 섞여있어서 fold 를 나누기 용이함.
Binary Classification
SGD classifier 를 이용하여 5인 숫자와 5가 아닌 숫자를 구별하는 binary classification 문제를 먼저 풀어보자.
기본적으로 chapter 2 에서 봤듯 아래와 같은 절차를 따른다.
- 데이터셋을 X (이미지), y (레이블) 로 분리하고 각각 train, test 셋으로 나눈다.
- 여기서는 5가 맞냐 아니냐만 구분하기 때문에 5라면 True, 5가 아니라면 False 인 두 가지의 클래스만 갖는다.
- SGDClassifier 로 train set 에 대해 fit 진행
- fit 된 모델로 테스트를 진행
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state = 42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict(X[:10])
## array([ True, False, False, False, False, False, False, False, False,False])KFold Cross Validation
위 binary classfication 의 일반화 성능을 알아보기 위해 CV를 진행하기로 한다. 아래와 같은 절차를 따른다.
- Fold 를 나눈다. scikit-learn 의 StratifiedKFold 같은 API 를 이용하여 데이터를 쉽게 나눌 수 있다.
- 각 loop 마다 train_fold 를 훈련시켜 모델을 피팅하고 test_fold 에 대해 점수를 계산한다.
- 위 과정을 fold 개수만큼 반복한다.
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits = 3, random_state = 42, shuffle = True)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))
## 0.9669
## 0.91625
## 0.96785또는 위 과정을 한번에 해주는 scikit-learn의 cross_val_score 를 사용할 수도 있다.
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv = 3, scoring = "accuracy")
## array([0.95035, 0.96035, 0.9604 ])그러나 사실 이 5분류기 예제는 데이터의 10%정도만 5가 존재하기 때문에 다 5가 아니라고 찍더라도 정확도 90% 이상을 낼 수 있다 (?!)
Metrics
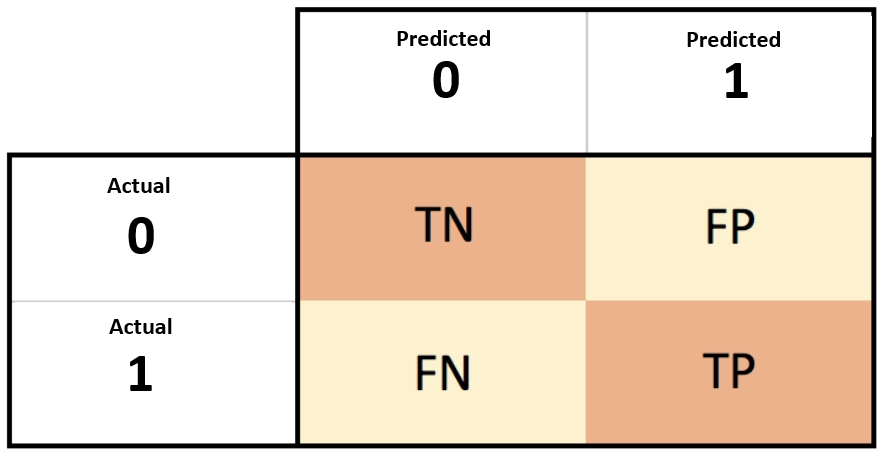
Confusion Matrix
이를 처음보면 어디가 FP이고 TP 인지 등을 상당히 헷갈릴 때가 많다. 게다가 누군가는 predicted class 와 actual class 를 뒤집어서 표를 만들 수도 있다. 아래만 기억하면 헷갈리지 않는다.
TRUE = 실제로 맞은것, FALSE = 실제로 틀린것
POSITIVE = 양성으로 예측, NEGATIVE = 음성으로 예측
이를 조합하면 FALSE POSITIVE = 실제로 틀렸는데 양성으로 예측한 것 이라고 쉽게 기억할 수 있다.
Recall and Precision
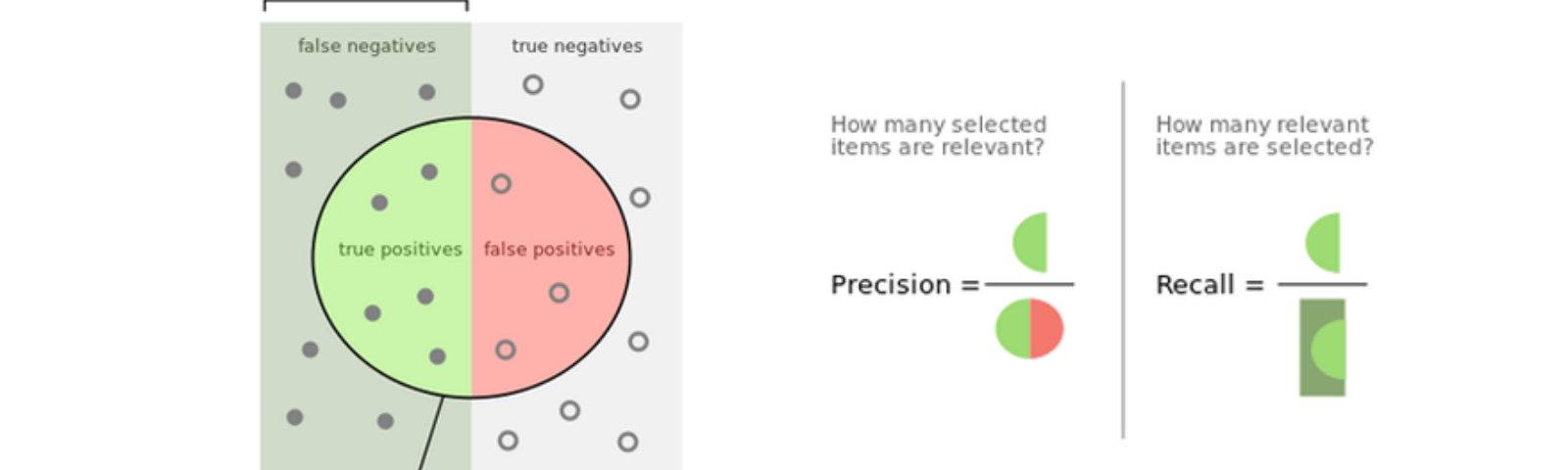
위 개념을 정상/불량에 빗대서 표현하면 좀 더 이해하기 쉽다. 불량이 positive, 정상이 negative 라고 가정한다.
Recall (= TPR, Sensitivity): 실제 불량중에 불량으로 맞힌 비율
Precision: 불량이라고 예측한 것 중에 실제로 불량인 비율
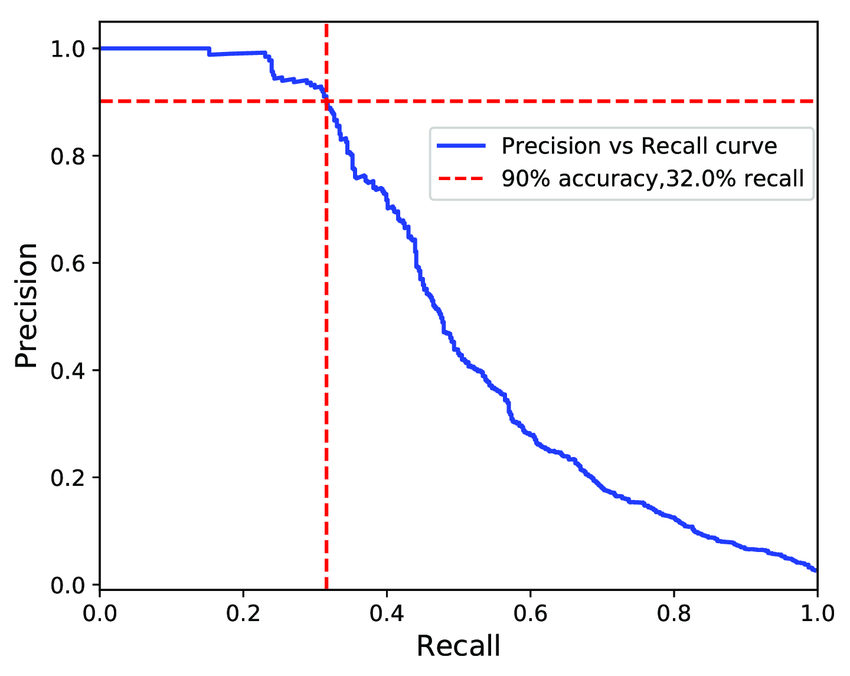
Recall 이 중요한지 Precision 이 중요한지는 프로젝트의 성격에 따라 다르다.
그보다 기억해야 할 것은, Recall 을 올리고자 하면 Precision 이 낮아지고 그의 반대의 경우도 마찬가지이다. 이를 Recall-Precision Tradeoff 라고 한다. 그렇기 때문에 둘이 적절히 좋은 값을 가질 수 있는 threshold 를 정하는 것이 중요하다.
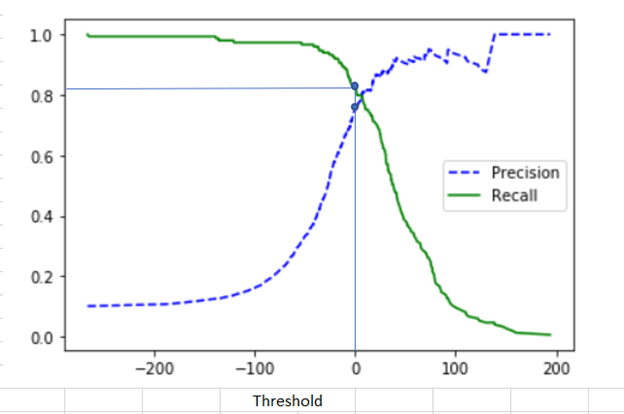
f1score: recall 과 precision 을 적절히 조합한 평균
ROC Curve (Receiver Operating Characteristic)
TPR versus FPR 을 그린 커브
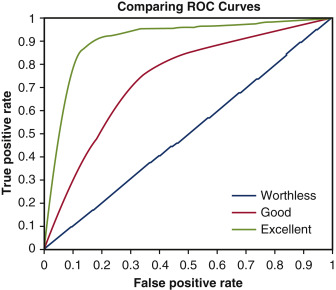
FPR 이 높다는 뜻은 오답이 많다는 뜻. 좋은 모델이란 오답을 적게 내면서 정답을 많이 맞추는 모델이므로 FPR 이 0에 가까워질수록 TPR 이 높은 curve 를 띄면 좋은 모델임.
좋은 모델일 수록 (FPR, TPR) = (0, 1) 에 수렴하는 모습을 보이므로 커브 아래의 면적을 계산하면 모델을 평가하는데에 지표로 삼을 수 있음. 면적이 높을수록 좋은 모델임. 실제로 면적을 계산하려면 integral 을 해야하기 때문에, scikit-learn 의 auc API 를 쓰는것이 매우 간편함
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import roc_auc_score
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv = 3, method = "decision_function")
roc_auc_score(y_train_5, y_scores)
# 0.9604938554008616Multiclass Classification
Multiclass Classifier: SGD, RandomForest, Naive Bayes
- 숫자 10개의 클래스를 한번에 넣어서 분류하는 방법으로 진행 가능. i.e. OvR (One-versus-Rest)
Binary Classifier: Logistic Regression, SVM
- 그러나 Binary 방법으로 multiclass classification 을 진행할 수도 있다.
- 예를 들면 5랑 1이랑 먼저 구분, 그 다음엔 5랑 2랑 구분, ... (총 10C2 조합 개수인 45번의 classification 이 필요하다)
- 이를 OvO (One-versus-One) 이라고 부름.
- multiclass 인데 SVM 을 사용하겠다면, scikit-learn 내부에서는 알아서 OvO 방법으로 진행해준다.
- 또는 아래와 같이 OvR Classifier 로 강제할 수 있다. 이 말은, 5 vs Rest 로 학습하여 5를 걸러내고 1 vs Rest 로 학습하여 1을 걸러내고 .... 와 같은 진행으로 10개의 classifier 를 생성하는 방법이라 볼 수 있다.
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC())
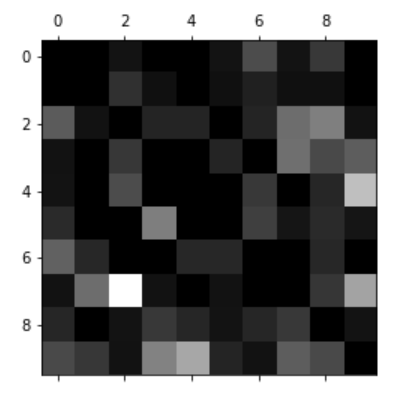
ovr_clf.fit(X_train, y_train)아래와 같이 confusion matrix 에 대해 시각화를 하면 어떤 클래스에 대해 특히 예측이 부정확한지 등을 알아낼 수 있다.
y_pred = ovr_clf.predict(X_test)
confmat = confusion_matrix(y_test, y_pred)
row_sums = confmat.sum(axis = 1, keepdims = True)
norm_mat = confmat/row_sums
np.fill_diagonal(norm_mat, 0)
plt.matshow(norm_mat, cmap = plt.cm.gray)
plt.show()아래 matrix 로 보았을땐 실제 7인 숫자를 2로 잘못 예측한 경우가 많음을 알 수 있다.
Multilabel Classification
하나의 input 에 대해 여러개의 label 을 정답으로 내어주는 시스템
MNIST 의 경우라면, 7이라는 숫자에 대해 (odd, larger_than_5) 라는 2개의 label 을 부여하여 학습을 진행할 수 있음.
실제 학습 환경에서는 각각의 레이블에 weight 를 두어서 학습할 수 있다. 예를 들어 해당 레이블을 가지는 이미지의 개수 등을 weight 로 설정할 수 있다.
Multioutput Classification
Multilabel Classification 에서 발전하여, 하나의 레이블이 여러개의 클래스를 가질 수 있는 경우
이를 32x32 이미지에 비유하면, 이미지는 총 32x32 개만큼의 레이블을 가지고 각 레이블은 (0~255) 의 값을 갖기 때문에 multiclass 라고 이해할 수 있다 (?)
