Hands-on ML Ch 10: Neural Network
곱연산, 합연산을 수행하는 articial neuron 의 등장
Perceptron
입력과 출력이 어떤 숫자이고, 각각의 입력 연결은 가중치와 연관되어 있음.
가중치의 합을 계산하고 이에 step function 을 적용하여 결과를 출력.
각 TLU (threshold logic unit) 이 모든 입력층에 연결되어 있을 때 이를 Fully Connected Layer 라고 부름. (또는 Dense Layer)
퍼셉트론에 한 번에 한 개의 샘플이 주입되면 각 샘플에 대해 예측이 만들어지고, 잘못된 예측을 하는 모든 출력 뉴런에 대해 올바른 예측을 만들 수 있도록 입력에 연결된 가중치를 강화시킴.
Multi-layer Perceptron
Input Layer - Hidden Layer - Output Layer 의 구조. 모든 층은 다음 층과 fully connected.
- Forward Pass 는 각 layer 가 previous layer 의 output 을 계산하고 다음 layer 로 전달하는 것. Backprop 을 위해서 중간 계산값을 저장.
- Backpropagation 은 각 출력 연결이 최종 예측값에 대한 오차에 얼마나 기여하는지를 계산. 각 weight 에 대한 오차 gradient 를 측정하는 과정.
- 마지막으로 이 오차가 감소하도록 gradient descent 기법으로 weight 를 조정
Step function 을 sigmoid function 으로 바꾸어 gradient 가 계산되도록 수정.
from tensorflow import keras
import tensorflow as tf
model = keras.models.Sequential()
# 입력 이미지를 1d array 로 변환. 모델의 첫번째 층에 해당함.
model.add(kears.layers.Flatten(input_shape = [28, 28]))
# 뉴런 300개 짜리 hidden layer
model.add(keras.layers.Dense(300, activation = "relu"))
model.add(keras.layers.Dense(100, activation = "relu"))
# 뉴런 10개 짜리 hidden layer. Independent class 결과를 위해 softmax 함수 사용
model.add(keras.layers.Dense(10, activation = "softmax"))
# 만약에 one-hot vector 일 경우에는 그냥 "categorical_crossentropy"를 사용
model.compile(loss = "sparse_categorical_crossentropy",
optimizer = "sgd",
metrics = ["accuracy"])Wide and Deep Model
skip connection 이 있는 형태
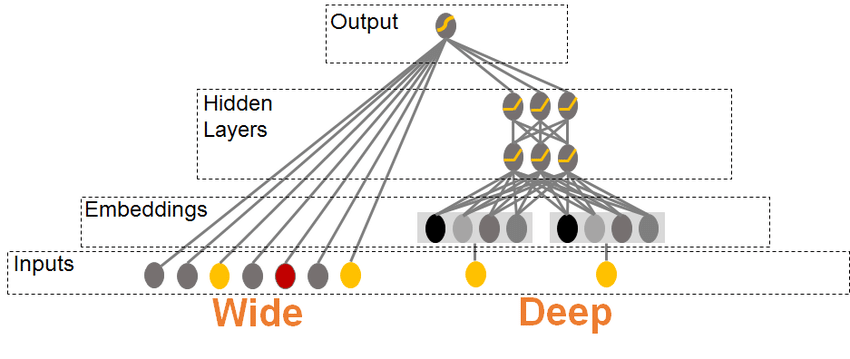
keras.Sequential 이 아닌 Class instance 로 만들어서 사용할 수도 있다.
class WideandDeepModel(keras.Model):
def __init__(self, units = 30, activation = "relu", **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation = activation)
self.hidden2 = keras.layers.Dense(units, activation = activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideandDeepModel()Hyperparameter Tuning
예를 들어, regression 모델을 만드는데 있어 num of layers 와 learning rate 등을 scikit-learn 에서 제공하는 Random Search 방법으로 찾을 수 있다.
# 먼저 model 을 구성하는 함수를 정의
def build_model(n_hidden = 1, n_neurons = 30, lr = 3e-3, input_shape = [8]):
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape = input_shape)
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation = "relu")
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(lr = lr)
model.compile(loss = "mse", optimizer = optimizer)
return model
# regression model 생성
keras_reg = keras.wrappers.scikit_learn.KerasRegressor(build_model)
# Random Search 진행하기
from scipy.stats import reciprocal
from sklearn.model_selection import RandomizedSearchCV
params = {
"n_hiddens": [0, 1, 2, 3],
"lr" = reciprocal(3e-4, 3e-2)
}
randomsrch = RandomizedSearchCV(keras_reg, prams, n_iter = 10, cv = 3)
randomsrch.fit(X_train, y_train, epochs = 100,
validation_data = (X_valid, y_valid), # cv 에는 사용하지 않으나 patience 측정에 사용
callbacks = [keras.callbacks.EarlyStopping(patience = 30)]
)
print(randomsrch.best_params_)
final_model = randomsrch.best_estimator_.modelTransfer Learning
일반적으로, hidden layer 들은 다음과 같이 학습한다.
- 아래쪽 층은 저수준의 구조를 모델링
- 중간층은 저수준의 구조를 연결해 중간 수준의 구조를 모델링
- 가장 위쪽 은닉층과 출력층은 중간 수준의 구조를 연결해 고수준의 구조를 모델링
새로운 신경망에서 처음 몇 개 층의 가중치와 편향을 난수로 초기화하는 대신 첫 번째 신경망의 층에 있는 가중치와 편향값으로 초기화 하는 것이 transfer learning 의 원리.
이런 방식은 대부분의 이미지에 나타나는 저수준 구조를 학습할 필요가 없음.
