내용이 길어서 3부작으로 나눴습니다.
그냥 토이프로젝트인데, 사실 이 실험에는 많은 오류가 존재하고 이를 작성자도 인지하고 있습니다. 이를 발견하여 댓글을 달아서 멋진 개발자가 되어봅시다. 우리.
1. 계기
기업에서 사용하는 관계형 DB로 가장 점유율이 높은 브랜드는 ORACLE입니다.
그러나, 개인적으로 개발을 공부하는 학생들에게 가장 인기가 많은 데이터베이스를 꼽자면 MySQL과, PostgreSQL이 있을 것입니다.
저는 MySQL과 동일하나, 라이센스 문제로부터 자유로운 MariaDB를 사용했는데, MariaDB와 PostgreSQL의 성능에 어떤 차이가 존재하는지 궁금해서 구글링을 했습니다.
해당 부분의 이론에 대해서는 개인 기술블로그가 아닌, 믿을 만한 사이트에서 제공하는 가이드라인을 읽어보았습니다.
저는 이제 이를 단순히 이해하는 것에 그치지 않고, 체감을 해보고 싶었습니다.
성능을 테스트도 안해보고 글로만 작성한게 구글링에 널렸기 때문에
이에 대해서 제가 기존에 했던 프로젝트의 데이터베이스 구조를 활용하여 체감 가능한 실험을 진행해보고자 합니다.
2. 이론 지식

위의 가이드라인 링크에서 비교 자료를 확인할 수 있는데, 간단하게 설명하겠습니다.
카테고리 : 이름입니다.
데이터베이스 기술 : 사용하는 데이터베이스가 어떠한 기술을 기반으로 하는지 아는 것은 중요한 일이지만, 이해에는 도움이 되어도 '체감'에 있어 주요한 부분이 아닙니다.
기능 : postgreSQL만 지원하는 기능을 찾아보는 것을 목표로 하겠습니다.
데이터 유형 : postgreSQL에서 여러가지 자료형을 지원합니다.
ACID 규정 준수 : ACID란 쿼리 (데이터베이스) 트랜잭션이 얼마나 안전하게 수행되는지에 대한 이야기입니다.
인덱스 : 지원하는 인덱스(검색) 기술이 다른 것으로 확인됩니다.
성능 : MySQL이 읽기는 뛰어나나, 쓰기는 PostgreSQL이 더 좋습니다.
초보자 지원 : PostgreSQL이 더 시작하기 어렵습니다.
3. 목표
사용성과 성능을 체감하기 위해, 다음과 같은 목표를 세웠습니다.
- PostgreSQL만 지원하는 기능(함수) 찾아보기
- 1만개, 10만개, 100만개의 데이터에서 쓰기, 읽기를 수행하며 성능을 비교하기
2-1. 서브쿼리와 조인을 적극적으로 활용한 복합쿼리의 수행시간도 측정해보기
2-2. 모든 컬럼에 대해서 인덱싱이 적용됐는지 여러가지 컬럼을 기준으로 검색해보기
2-3. 인덱스 기술이 다른 것을 체감해보기
로 수행하도록 하겠습니다.
4. 데이터베이스 테이블 생성하기
간단하게 계정테이블이랑 하위 테이블인 냉장고테이블을 생성하였습니다.
PostgreSQL
CREATE TABLE
account (
id SERIAL PRIMARY KEY,
mail VARCHAR(100),
pw VARCHAR(32),
nickname VARCHAR(32),
longitude DOUBLE PRECISION,
latitude DOUBLE PRECISION);
CREATE TABLE
refrigerator (
id SERIAL PRIMARY KEY,
account_id SERIAL REFERENCES account(id),
energy REAL,
co2 REAL,
model_name VARCHAR(50));
MariaDB(MySQL)
CREATE TABLE
account (
id INT AUTO_INCREMENT PRIMARY KEY,
mail VARCHAR(100),
pw VARCHAR(32),
nickname VARCHAR(32),
longitude DOUBLE,
latitude DOUBLE
);
CREATE TABLE
refrigerator (
id INT AUTO_INCREMENT PRIMARY KEY,
account_id INT,
energy FLOAT,
co2 FLOAT,
model_name VARCHAR(50),
FOREIGN KEY (account_id) REFERENCES account(id)
);
4-1. 데이터 10,000개 쓰기
4-1-1. 기본 쓰기
PostgreSQL
postgreSQL부터 데이터를 넣어봅시다.
INSERT INTO
account (mail,
pw,
nickname,
longitude,
latitude)
SELECT
CONCAT('tennfin1@gmail.com', id),
'1234',
'hyoseok',
-180 + RANDOM() * 360,
-90 + RANDOM() * 180
FROM generate_series(1, 10000) AS id;1만개의 데이터를 생성하기 위해서 작성하였고, 메일은 숫자 배열을 생성하여 뒤에 값을 붙였습니다.
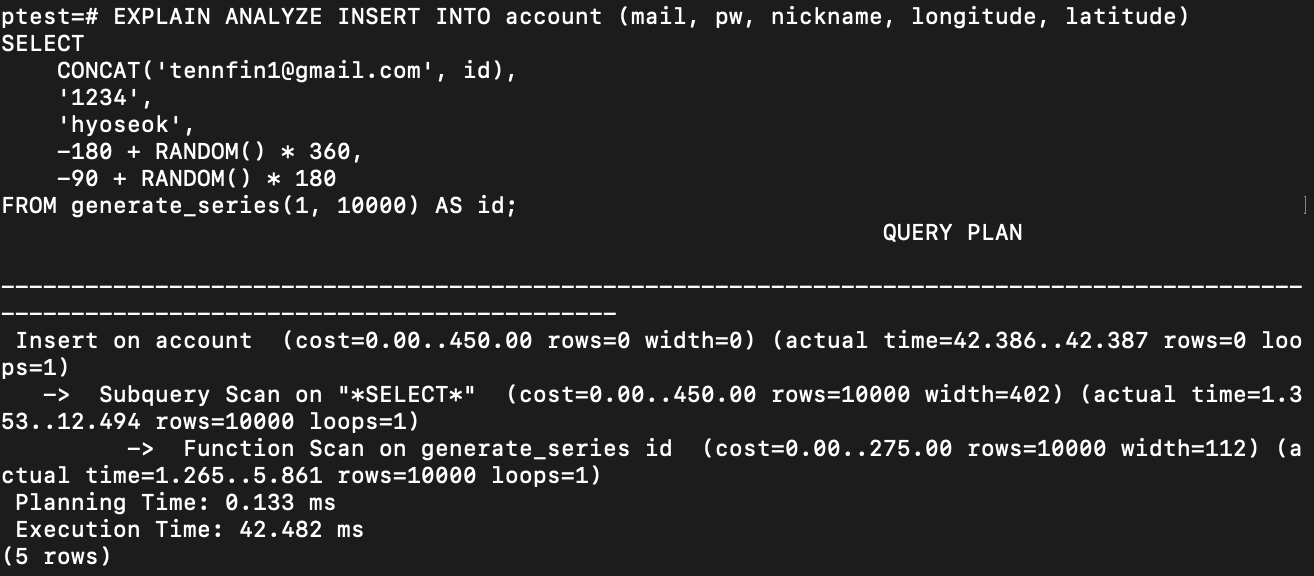
40.4536 (5회 평균 실행시간)
4-1-2. Q. 여기서 mail 컬럼에 unique 지정을 하면 쿼리 속도에 영향을 미칠까?
unique 컬럼은 데이터에서 한 번 넣을 때마다 무결성 체크를 해야하는데, 이를 위해서는 기존에 데이터베이스에 존재하는 데이터에서 searching을 해보는데, indexing이 되어 있다면 log N에 수행이 가능합니다.(B+tree 구조기 때문에)
N개의 데이터를 넣었기 때문에 최종적으로는 N log N의 시간복잡도가 발생할 수 밖에 없습니다. 즉, 시간이 더 걸릴 것이라는게 제 의견입니다.
테이블을 삭제 후, 다시 생성하고 (동일 환경 만들기 위해서) 다음 쿼리 입력
ALTER TABLE account ADD CONSTRAINT unique_mail UNIQUE (mail);그리고 동일한 insert쿼리와 함께 분석을 실행하면
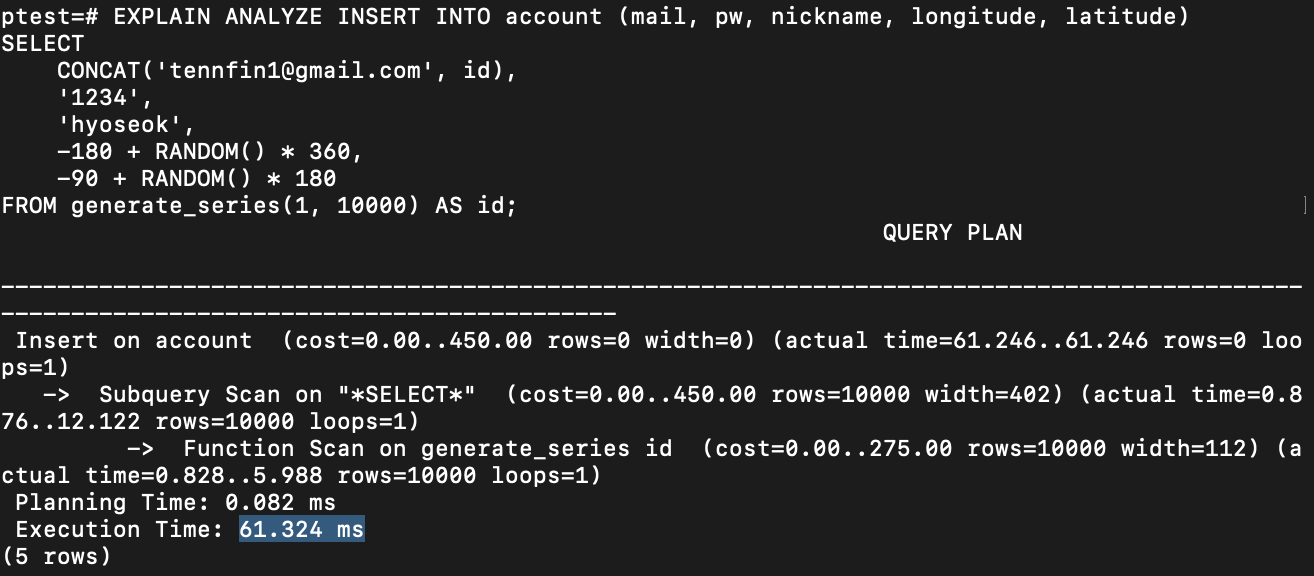
58.6546ms이 걸리며, 확실하게 시간이 증가됨을 볼 수 있습니다. (5회 평균 실행시간)
MariaDB
테이블을 생성하는 쿼리문은 postgreSQL과 동일합니다.
CREATE TABLE account (
id INT AUTO_INCREMENT PRIMARY KEY,
mail VARCHAR(100),
pw VARCHAR(32),
nickname VARCHAR(32),
longitude DOUBLE,
latitude DOUBLE
);다만, 메일 뒤에 숫자배열을 생성해서 순서대로 붙여주기 위해서 사용한 함수인, generate_series(min,max)가 사용이 불가능한데, 해당 기능을 구현하기 위한 다양한 방법론이 존재하지만, 저는 GPT의 힘을 빌려서 ㅎㅎ;;
CREATE TABLE account (
id INT AUTO_INCREMENT PRIMARY KEY,
mail VARCHAR(100),
pw VARCHAR(32),
nickname VARCHAR(32),
longitude DOUBLE,
latitude DOUBLE
);
INSERT INTO account (mail, pw, nickname, longitude, latitude)
SELECT
CONCAT('tennfin1@gmail.com', seq.n),
'1234',
'hyoseok',
-180 + RAND() * 360,
-90 + RAND() * 180
FROM (
SELECT (a.N + b.N * 10 + c.N * 100 + d.N * 1000) AS n
FROM (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS a
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS b
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS c
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS d
LIMIT 10000
) AS seq;(어려워 보이지만, 단순하고 길기만 한 쿼리문입니다.
게다가, 이러한 부분은 모듈화된 부분이 아니기 때문에, 좋지 못한 쿼리라 볼 수 있습니다.)
이러한 부분이 postgreSQL은 지원하지만, mariaDB는 지원하지 않는 많은 기능들 중 하나로 보여집니다.
42.848ms의 시간이 소요 되었습니다. (5회 평균 실행시간)
PostgreSQL때와 동일하게 unique로 설정하고 insert 쿼리문을 다시 수행해보겠습니다.
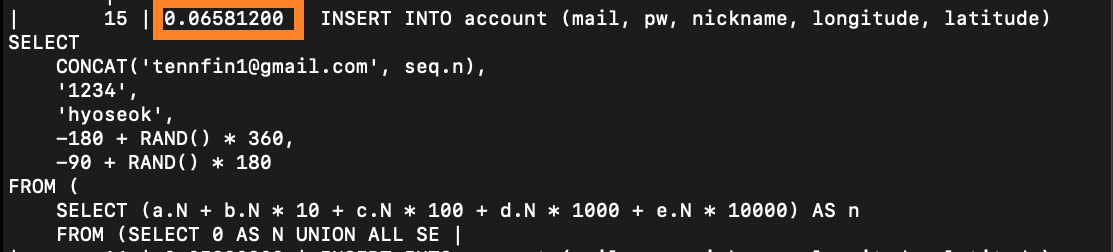
60.6266ms의 시간이 소요 되었습니다. (5회 평균은 실행시간)
4-1-3. 데이터 10,000개 쓰기(foreign key 적용된 하위 테이블)
테이블 구조 상, 해당 테이블의 컬럼에서는 unique를 요구하지 않기 때문에, (unique의 효과는 위에서 이미 언급한 바 있음) unique를 이번에는 설정하지 않고 데이터를 삽입해보겠습니다.
또한, 데이터 참조가 1대1 대응이 아니기 때문에 로직상으로는 account_id를 랜덤으로 할당해주는 것이 맞지만, 각각의 랜덤함수가 실행시간에 영향을 미칠 수 있다고 생각하여 숫자열을 생성하여 1대1 대응이 되도록 하였습니다.
PostgreSQL
INSERT INTO refrigerator
(account_id, energy, co2, model_name)
SELECT
row_number() OVER (),
random() * 200,
random() * 100,
'refre' || row_number() OVER ()
FROM generate_series(1, 10000);평균 82.9008ms (5회 평균 실행시간)
MariaDB
INSERT INTO refrigerator
(account_id, energy, co2, model_name)
SELECT
seq.n + 1,
RAND() * 200,
RAND() * 100,
CONCAT('refre', seq.n)
FROM (
SELECT (a.N + b.N * 10 + c.N * 100 + d.N * 1000) AS n
FROM (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) AS a
CROSS JOIN (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) AS b
CROSS JOIN (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) AS c
CROSS JOIN (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) AS d
) AS seq LIMIT 10000;평균 53.4408ms (5회 평균 실행시간)
4-2. 데이터 100,000개 쓰기
쿼리문은 생략하도록 하겠습니다. (동일함)
4-1-1. 기본 쓰기
PostgreSQL
평균 402.3464ms (5회 평균 실행시간)
MariaDB
평균 184.8344ms (5회 평균 실행시간)
4-1-2. unique key column 포함 쓰기
PostgreSQL
평균 698.6042ms (5회 평균 실행시간)
MariaDB
평균 299.0358ms (5회 평균 실행시간)
4-1-3. foreign key column 포함 쓰기
PostgreSQL
평균 733.618ms (5회 평균 실행시간)
MariaDB
평균 264.081ms (5회 평균 실행시간)
4-3. 데이터 1,000,000개 쓰기
쿼리문은 생략하도록 하겠습니다. (동일함)
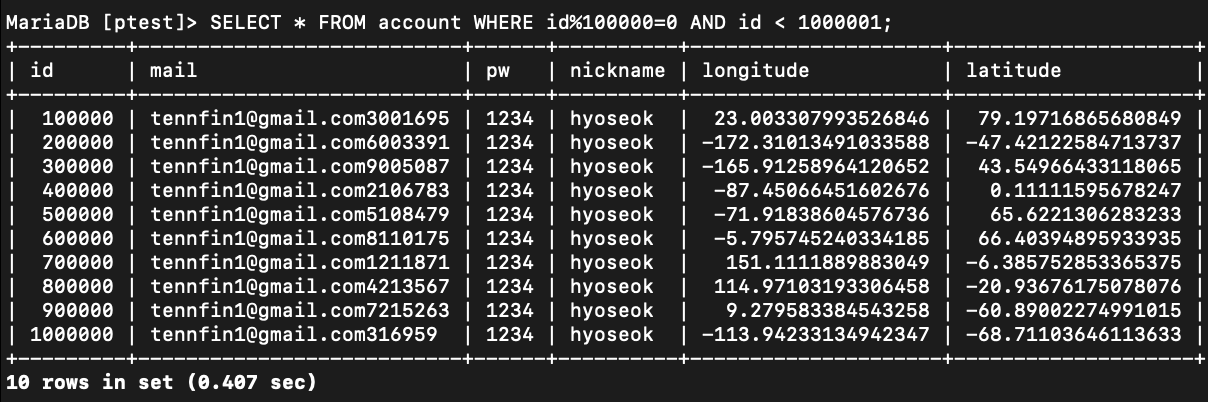
100만개의 데이터를 MariaDB에 삽입하는 과정에서 약간의 문제가 발생하였습니다.
account 테이블에서 id컬럼은 1씩 auto increment하게 증가해야하지만, 10만번째 데이터 이후에는 급격히 껑충 뛰고, 엉키는 일이 발생하였습니다.
해당 부분은 성능을 측정하는데 큰 문제는 되지 않으나(unique 걸어본 결과, 값이 겹치진 않음) PostgreSQL에서는 발생하지 않는 문제였기 때문에 MariaDB에서 조금 아쉬운 점이었습니다.
4-1-1. 기본 쓰기
PostgreSQL
평균 4409.5364ms (5회 평균 실행시간)
MariaDB
평균 1564.8138ms (5회 평균 실행시간)
4-1-2. unique key column 포함 쓰기
PostgreSQL
평균 7489.8004ms (5회 평균 실행시간)
MariaDB
평균 2900.3322ms (5회 평균 실행시간)
4-1-3. foreign key column 포함 쓰기
PostgreSQL
평균 7137.0542s (5회 평균 실행시간)
MariaDB
평균 2757.705 (5회 평균 실행시간)
4-3. 데이터 10,000,000개 쓰기
쿼리문은 생략하도록 하겠습니다. (동일함)
100만개에서 발생한 auto_increment와 동일 문제 발생
4-1-1. 기본 쓰기
PostgreSQL
평균 45973.807ms (5회 평균 실행시간)
MariaDB
평균 17019.8826 (5회 평균 실행시간)
4-1-2. unique key column 포함 쓰기
PostgreSQL
평균 70901.7796ms (5회 평균 실행시간)
MariaDB
평균 33219.9976ms (5회 평균 실행시간)
4-1-3. foreign key column 포함 쓰기
PostgreSQL
평균 86936.0918 (5회 평균 실행시간)
MariaDB
평균 31976.1034 (5회 평균 실행시간)
5. 정리
정확한 수치보다는, 전체적인 경향과 변화양상에 집중하였습니다.
-
전체적인 쓰기 능력은 데이터 크기를 불문하고, MariaDB가 더 뛰어난 모습을 보여줬습니다.
-
Unique Key나, Foreign Key를 포함한 테이블에 데이터를 작성할 때, 실행시간이 늘어나긴 했지만, 대부분 선형적인 증가에서 멈추었습니다. 즉, 제약조건을 추가해도 쓰기 시간에 있어 극단적인 시간복잡도의 변화를 초래하지 않습니다 . (시간에 상수계수만 곱해지는 느낌)
-
쓰기에 종류에 불문하고, 데이터의 양이 많아지더라도 계수가 크게 변화하지 않는 것으로 보아 MariaDB가 계속 쓰기 성능은 뛰어날 것입니다.
-
1만개가량에서 속도가 비슷한 수준으로 계측이 되는데, 이와 비슷하거나, 더 작은 규모에서는 PostgreSQL이 조금 더 빠르게 계측될 수 있습니다.
쓰기시간에 대한 그래프입니다.
푸른계열은 Postgres, 붉은 계열은 MariaDB입니다.
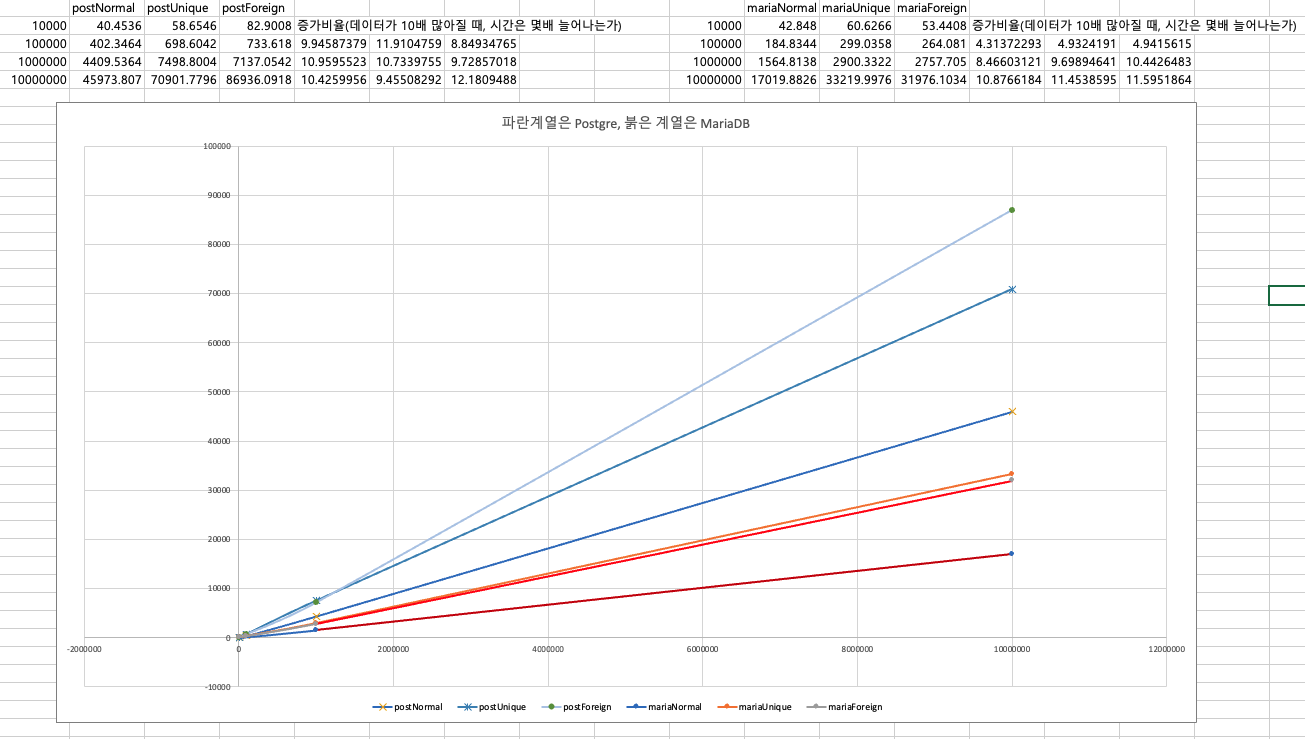
100만개 이하의 데이터셋은 결과를 관찰하기 어려우니, x축의 간극은 통일하고, y축의 크기를 데이터셋의 크기로 나누겠습니다.
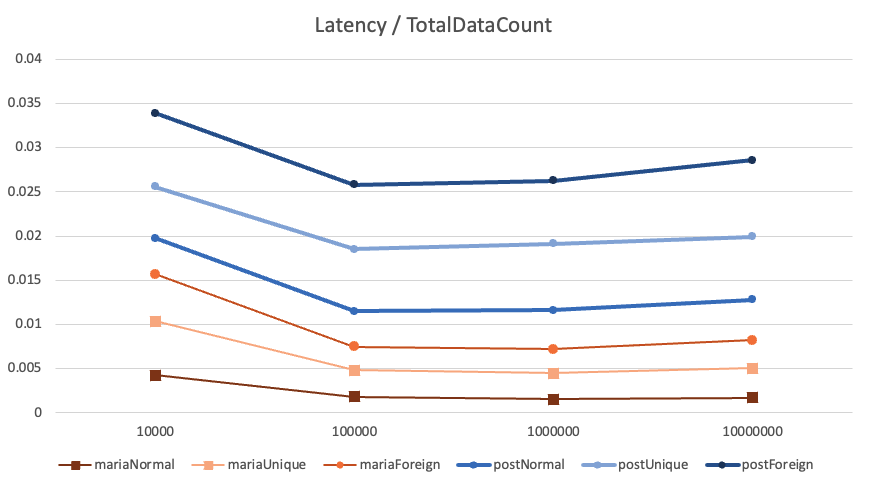
PostgreSQL보다 MariaDB가 더 뛰어난 모습입니다.
그래프가 감소했다가, 다시 증가하는 모습을 보이고 있습니다.
Q1. 적은 데이터 구간에서 왜 단위 개수당 입력시간이 증가했는가?
- 전처리 등, 한번의 쿼리를 실행하는데 고정적으로 드는 레이턴시 비용(시간)이 존재하는데,
이를 데이터 개수로 나눈것이 해당 그래프의 y축 데이터이므로, 데이터가 적을 수록 값(레이턴시/개수)가 크게 나오기 때문인 것 같습니다.
Q2. 많은 데이터 구간에서 왜 다시 단위 개수당 입력시간이 반등하는가?, 왜 1번보다 작게 반등하는가?
- 한 개의 데이터를 입력하는데 드는 시간적 비용은 O(Log N)에 비례합니다. N이 증가할 수록 데이터가 커지게 됩니다.
다만, 데이터가 10배 커지면 Q1에서 언급한 고정 레이턴시는 상대적으로 10배씩 줄어들지만, 입력 레이턴시는 Log 함수에 비례하기 때문에 증감폭이 더 작은 것으로 추정됩니다.
6. 추가의견
-
성능 차이가 발생하는 주요 원인에 대해서 :
아마 생성되는 테이블의 구조가 프로그래밍 적으로 완전히 동일하지 않은 것이 주요원인인 것 같지는 않습니다. Unique Key, Primary Key 부분에 대해서 일치시켰기 때문에 Indexing과 관련된 것은 최대한 맞춰주었기 때문입니다. -
결과의 주요 인과요소는 무엇이라 생각하는가? :
-
데이터베이스 성능
서로 다른 두 중류의 데이터베이스에 동일한 테이블을 각각 배정한다해도, 이를 동작시키고 성능을 발생시키는 부분은 엄연히 차이가 존재합니다. 즉, 정말로 데이터베이스의 자체적인 성능이 주요인과요소가 될 수도 있습니다. -
쿼리의 동작방식
쿼리를 작성한 방식 또한 무시할 수 없습니다. 같은 데이터를 작성하는 쿼리문이지만,
PostgreSQL에서는 기본적으로 지원하는 함수를 통해 수열을 생성하는 쿼리를 작성하였고,
MariaDB에서는 해당 함수가 존재하지 않아 직접 구현하여 쿼리를 작성하였기 때문입니다.
'만들어내는 결과는 같지만, 동작하는 방식이 다르다는 점'은 충분히 성능에 영향을 미치는 부분입니다.
근데 생각해보니 1000만개 넣는 실행시간을 측정하는게 아니라, 1000만개 있는 상태에서 하나 넣을 때 실행시간을 비교하는게 맞는거 같은데.... 추가실험... 해야겠지?
7. 추가쿼리
그럼 1000만개 일때 하나 넣어보고, 10만개일 때 데이터 하나씩만 넣어봅시다.
아마 indexing이 되어있기 때문에 삽입할 위치를 searching하는 시간이 O(log N)이라 얼마 안 걸릴 것입니다.
하나씩 넣어보기
1000만개일 때 하나 삽입
PostgreSQL
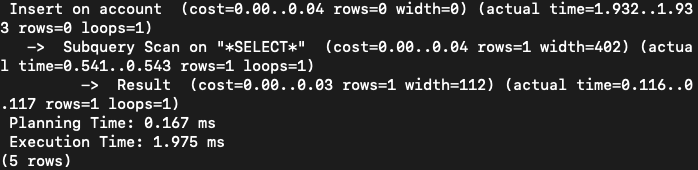
MariaDB

위는 msec, 아래는 sec이므로, mariaDB가 약 1.5ms로 선형적으로 좀 더 빠릅니다. (위의 결과에서 선형적으로 더 뛰어났던 것과 비슷합니다.)
10만개일 때 하나 삽입
PostgreSQL
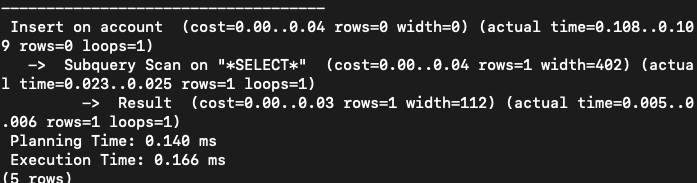
MariaDB
데이터 크기가 적어서 그런지 postgreSLQ의 쓰기 속도가 더 빠른 의외의 결과가 나왔습니다.
이를 통해 새로운 해석에 도달할 수 있습니다.
-
데이터가 많아질 수록 MariaDB가 쓰기 능력이 더 뛰어남에는 변화가 없습니다. (적은 데이터 개수에서의 단일삽입 능력은 PostgreSQL이 좀 더 우세할 수 있음)
-
복수삽입을 위해 PostgreSQL에서 사용하는 함수에 오버헤드가 존재하는 것으로 추정됩니다. 이 때문에 데이터 개수가 적은 구간에서는 PostgreSQL이 단일삽입 속도가 우세함에도 불구하고, 전체삽입속도는 MariaDB보다 느렸다는 결과가 나왔다 생각합니다.**
그런데.... 진짜로 함수 오버헤드가 크게 발생할까?
함수 오버헤드가 크다고 예상은 했지만, 실제로는 그럴 지 아무도 모릅니다.
MariaDB에는 해당 함수가 없어서 Join을 통해 수행하였는데, 이는 역으로 PostgreSQL에서 실행 가능한 쿼리입니다.
EXPLAIN ANALYZE INSERT INTO account (mail,pw, nickname, longitude, latitude)
SELECT
CONCAT('tennfin1@gmail.com', seq.n),
'1234',
'hyoseok',
-180 + RANDOM() * 360,
-90 + RANDOM() * 180
FROM (
SELECT (a.N + b.N * 10 + c.N * 100 + d.N * 1000 + e.N * 10000) AS n
FROM (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS a
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS b
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS c
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS d
CROSS JOIN (SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS e
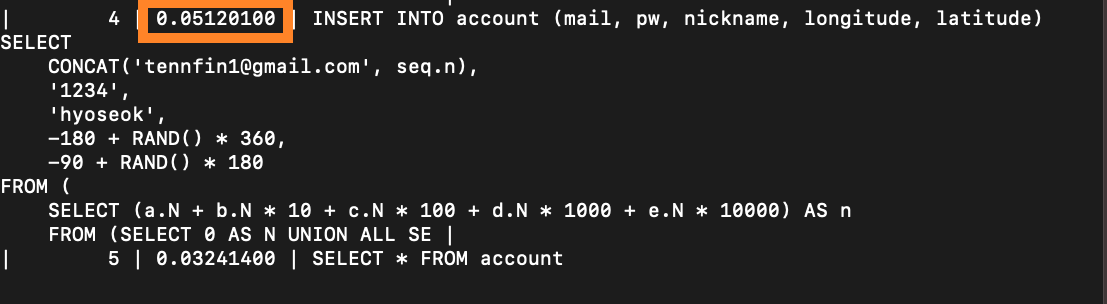
) AS seq;RAND()함수만 RANDOM()으로 변경해줍시다.


660ms 정도의 레이턴시가 나왔는데, 함수를 쓴 PostgreSQL에서 평균 698, 최소 655에 최대 782가 나왔기 때문에, 함수의 오버헤드로 인한 레이턴시는 크지 않은 것 같습니다. (쿼리 하단에 존재하는 SELECT 함수가 PostgreSQL이 더 구려서 그럴 수도 있는게 아니냐할 수도 있는데, 다음 글에서 확인하면 읽기능력이 PostgreSQL이 더 뛰어난 것으로 나왔기 때문에 그렇지는 않을 것입니다.)
자체적인 쓰기 능력이 MariaDB가 조금 더 뛰어난 것 같네요.
이상입니다.
2부에서 뵙겠습니다.
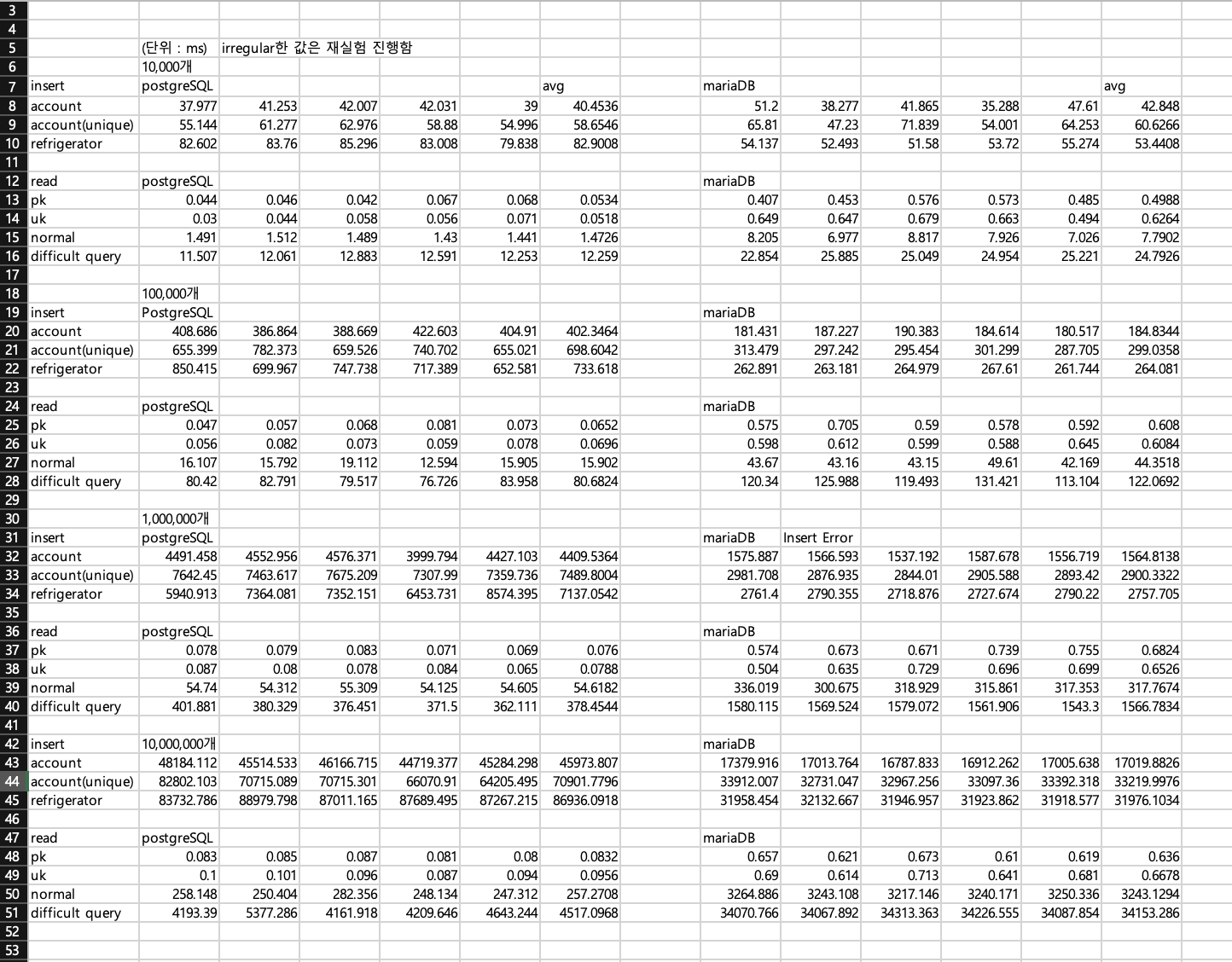
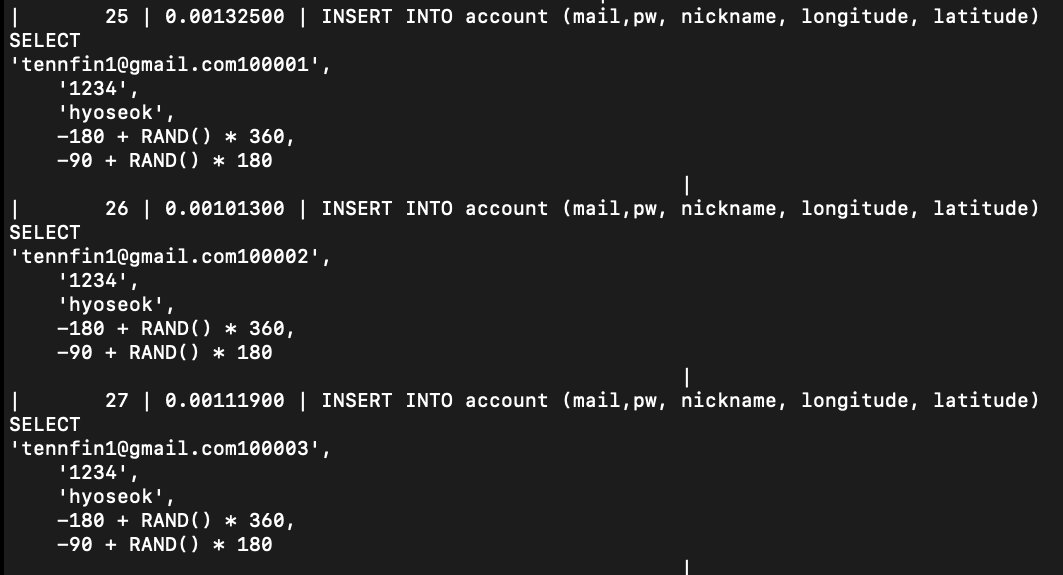
다음은 전체 실행시간 표입니다. 참고하시면 좋을 것 같습니다.