
쓰기 능력을 비교한 전편의 내용과 이어집니다.
이번 글에서는 읽기(탐색) 능력을 측정 해볼 것입니다.
먼저, 총 4종의 탐색(읽기)을 수행할 것입니다.
1. primary key column - 지정검색
2. unique key column - 지정검색
3. 일반 column - 지정검색
4. 복합 쿼리 탐색 (JOIN과 SUB QUERY 응용)
2개의 데이터베이스 모두가 PK, UNIQUE KEY에 대해서 자동으로 INDEX를 지정하기 때문에, 해당 부분에서 읽기속도가 압도적으로 빠른 것을 중점으로 보면 좋을 것 같습니다.
4번째의 복합 쿼리탐색은 테이블 안에 있는 모든 데이터를 조회하는 구조를 가지고 있기 때문에, 읽기 능력이 모자르다면 확실한 선형적 지표로 나올 것입니다.
1. 데이터 10,000개에서 읽기
1-1. Primary Key Column 탐색
PostgreSQL
SELECT
*
FROM
account
WHERE
id=5000;평균 0.0534ms (5회 측정 평균)
MariaDB
SELECT
*
FROM
account
WHERE
id=5000;평균 0.4988ms (5회 측정 평균)
PK Column는 자동으로 indexing이 적용됩니다.
1-2. Unique Key Column 탐색
PostgreSQL
SELECT
*
FROM
account
WHERE
mail='tennfin1@gmail.com5000';평균 0.0518ms (5회 측정 평균)
MariaDB
SELECT
*
FROM
account
WHERE
mail='tennfin1@gmail.com4999';평균 0.6264ms (5회 측정 평균)
unique key는 중복을 허용하지 않는 속성으로, 순서를 정하는 것이 가능합니다.
이로 인해 자동으로 인덱싱이 부여되므로, PK와 동일한 탐색속도를 가지게 됩니다.
1-3. 일반 column (non index) 탐색
PostgreSQL
SELECT
*
FROM
account
WHERE
longitude=??; //한 데이터의 임의 값평균 1.4726ms (5회 측정 평균)
MariaDB
SELECT
*
FROM
account
WHERE
longitude=??; //한 데이터의 임의 값평균 7.7902ms (5회 측정 평균)
1-4. 복합 탐색 (Subquery, Join)
해당 링크에서 사용했던 검색 기능을 복합 쿼리로 사용할 것입니다.
지금 보니 이때 짰던 쿼리가 GPT를 이용해서 짰더니 아주 개판이군요.
수정해서 다시 직접 짜도록 합시다.
PostgreSQL
SELECT
subquery.energy,
subquery.distance AS distance
FROM (
SELECT
b.energy,
((a.latitude - (SELECT latitude FROM account WHERE id = 5000))^2 +
(a.longitude - (SELECT longitude FROM account WHERE id = 5000))^2) as distance
FROM
account a
JOIN
refrigerator b
ON
a.id = b.account_id
ORDER BY
((a.latitude - (SELECT latitude FROM account WHERE id = 5000))^2 +
(a.longitude - (SELECT longitude FROM account WHERE id = 5000))^2)
LIMIT 100 OFFSET 0
) AS subquery
ORDER BY
subquery.energy;평균 12.259ms (5회 측정 평균)
MariaDB
SELECT
subquery.energy,
subquery.distance AS data
FROM (
SELECT
b.energy,
(POW(ABS(a.latitude - (SELECT latitude FROM account WHERE id = 5000)),2) +
POW(ABS(a.longitude - (SELECT longitude FROM account WHERE id = 5000)),2)) as distance
FROM
account a
JOIN
refrigerator b
ON
a.id = b.account_id
ORDER BY
(POW(ABS(a.latitude - (SELECT latitude FROM account WHERE id = 5000)),2) +
POW(ABS(a.longitude - (SELECT longitude FROM account WHERE id = 5000)),2))
LIMIT 100 OFFSET 0
) AS subquery
ORDER BY
subquery.energy;평균 24.7926ms (5회 측정 평균)
2. 데이터 100,000개에서 읽기
2-1. Primary Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.0652ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.608ms (5회 측정 평균)
PK Column는 자동으로 indexing이 적용됩니다.
2-2. Unique Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.0696ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.6084ms (5회 측정 평균)
2-3. 일반 column (non index) 탐색
PostgreSQL
쿼리문 동일
평균 15.902ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 44.3518ms (5회 측정 평균)
2-4. 복합 탐색 (Subquery, Join)
PostgreSQL
쿼리문 동일
평균 80.6824ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 122.0692ms (5회 측정 평균)
3. 데이터 1,000,000개에서 읽기
3-1. Primary Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.076ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.6824ms (5회 측정 평균)
PK Column는 자동으로 indexing이 적용됩니다.
3-2. Unique Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.0788ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.6526ms (5회 측정 평균)
3-3. 일반 column (non index) 탐색
PostgreSQL
쿼리문 동일
평균 54.6182ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 317.7674ms (5회 측정 평균)
3-4. 복합 탐색 (Subquery, Join)
PostgreSQL
쿼리문 동일
평균 378.4544ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 1566.7834ms (5회 측정 평균)
4. 데이터 1,000,000개에서 읽기
4-1. Primary Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.0832ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.636ms (5회 측정 평균)
PK Column는 자동으로 indexing이 적용됩니다.
4-2. Unique Key Column 탐색
PostgreSQL
쿼리문 동일
평균 0.0956ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 0.6678ms (5회 측정 평균)
4-3. 일반 column (non index) 탐색
PostgreSQL
쿼리문 동일
평균 257.2708ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 3243.1294ms (5회 측정 평균)
4-4. 복합 탐색 (Subquery, Join)
PostgreSQL
쿼리문 동일
평균 4517.0968ms (5회 측정 평균)
MariaDB
쿼리문 동일
평균 34153.286ms (5회 측정 평균)
5. 정리
x축: 전체 데이터의 크기
y축: 각 탐색에서의 레이턴시 (낮을 수록 좋음)
Indexing이 적용된 Column의 대한 탐색 (Primary Key, Unique Key)
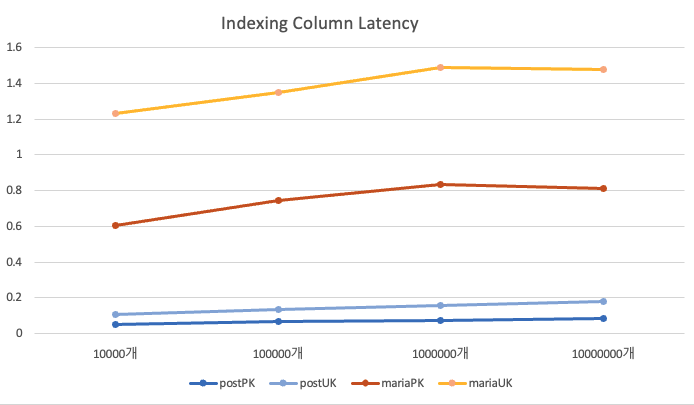
데이터 개수가 증가해도, indexing에 의해 실행시간은 O(log N)에 비례하기 때문에, 데이터셋이 10배씩 커져도 레이턴시는 로그함수에 비례해서 조금씩 증가할 것입니다.
전체적인 성능이 PostgreSQL이 압도적으로 뛰어난 모습을 보여주고 있지만, 1000만개 이후의 데이터에서는 PostgreSQL에서는 증가하지만, mariaDB에서는 그렇지 않은 모습을 보여주는데, 1억개의 데이터에서 측정을 해보면 더 좋을 것 같습니다.
Indexing이 비적용된 Column의 대한 탐색

indexing이 적용되지 않은 컬럼이기 때문에, 레이턴시가 선형적으로 증가하게 됩니다.
이를 보기 쉽게 표현하고자 y축의 데이터를 할당하는데 있어 Latency/DatasetCount 으로 표현하였습니다.
복합쿼리
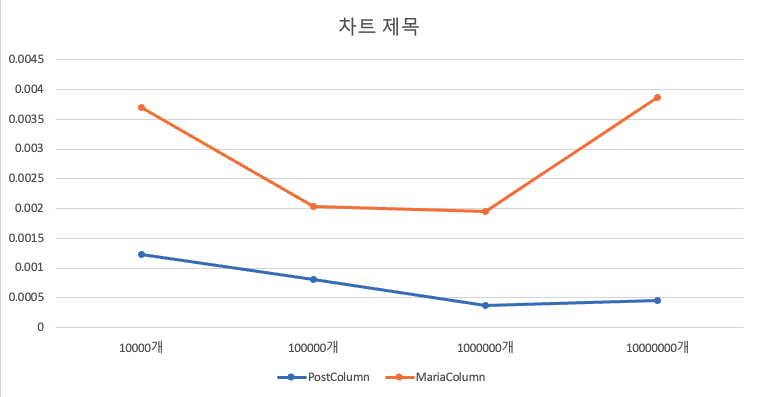
Join과 subqeury를 통해서 테이블 내 모든 데이터와 거리를 측정하고, 이를 정렬하여 뽑아낸 데이터기 때문에, 데이터 개수에 따라 레이턴시가 선형적으로 증가하게 됩니다.
이 또한 쉽게 표현하고자 y축의 데이터를 할당하는데 있어 Latency/DatasetCount로 표현하였습니다.
6. 추가실험
데이터셋이 1억개일 때를 추가실험해보면 더 좋을 것 같습니다.
금주 내로 진행해볼까 합니다.
7. 정리
전 구간에서, 모든 방식에서 읽기능력이 PostgreSQL이 MariaDB보다 우월한 모습을 볼 수 있었습니다.
더 말할 내용은 많지만, 인덱싱이라는 요소를 무시할 수 없기 때문에, 3번째 글에서 추가 언급하도록 하겠습니다.
