적대적 생성 신경망
VAE의 생성방식 : 입력 분포를 근사하는 과정에서 규제을 주며 데이터를 생성
GANs의 생성방식 : 생성된 데이터와 실제 데이터를 판별하고 속이는 과정을 거치며 생성 모델 개선
1. GANs 구조
- 데이터를 생성하는 생성모델과 데이터의 진위를 구별하는 판별모델
- 생성모델 : 임의의 노이즈를 입력으로 받아 생성된 데이터를 출력함.
- 판별모델 : 생성된 데이터를 입력으로 받아 실제 데이터인지 생성된 데이터인지를 출력함.
2. 학습 과정
- 임의의 초기 분포로부터 생성 모델이 데이터를 생성
- 판별 모델이 분류; 판별 모델 갱신
- 갱신된 판별 모델을 고정; 생성 모델 갱신
- 반복 과정을 거쳐 생성 모델은 판별 모델이 구별할 수 없는 수준의 데이터를 생성함.
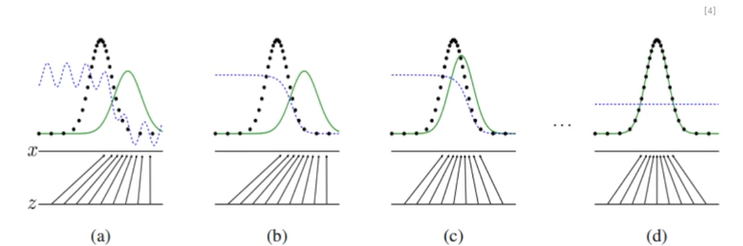
점차적으로 초록색 실선이 검정 점선으로 들어가게 되며, 파란색 점선이 top은 진짜로 bottom은 가짜로 판별 중이다. a - b - c - d로 가면서, 초록색 실선(생성자)의 방향은 파란색 점선(판별자)을 통해 학습하며 생성자는 초록색의 형태와 위치를 판별자에게서 1에 가깝게 판별하도록 학습하는 방식임. 생성자가 검정 점선에 일치하게 되면, 판별자는 더 판별되도록 학습하는 식임.
- 검정색 점선 : 입력 데이터의 분포
- 파란색 점선 : 판별 모델의 예측
- 초록색 실선 : 생성 모델의 분포
3. 목적함수
판별 모델

- 판별 모델 : 실제 데이터와 생성된 데이터를 정확하게 구별해야 하므로, 목적함수를 최대화함.
- 0과 1사이로 하기 위해 시그모이드를 사용함.
생성 모델

- 생성 모델 : 실제와 유사한 데이터를 생성하여 판별자를 속이므로, 목적함수를 최소화함.
4. 최적값
목적함수는 생성 데이터 분포와 실제 데이터 분포가 동일한 에서 최적임.
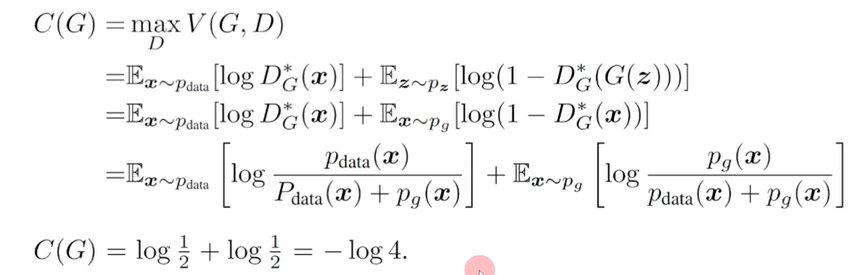
이는 -log 4로 수렴하게 됨.

이는 기울기 학습을 의미함.
현재 이 목적함수는 실제로 잘 동작이 안되는 문제점이 있음 -> 즉 기울기가 학습이 필요한 구간에서 더 평평한 기울기를 가지게 되어 backpropagation시에 더 약한 신호로 전달이 된다는 문제.

이를 해결하기 위해
1. 최적값 해결
- 판별 모델의 기울기를 조정하면 학습이 잘 이루어질 것은 즉 평평한 기울기를 가파르게 만드는 것으로
생성자 기준에서
판별 모델이 정답을 맞출 가능성을 최소화하는 것 대신, 틀릴 가능성을 최대화함.
기존 생성 모델의 기울기 하강 수식
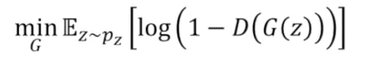
개선된 생성 모델의 기울기 상승
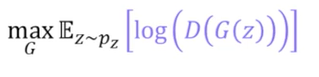
2. 문제점
- 모드 붕괴 현상으로 판별 모델을 속일 수 있는 일부 데이터만을 계속해서 생성하는 현상
- 이러한 문제를 해결하기 위해 목적함수를 다양한 손실함수로 일반화한 것이 f-GANs 논문
조건부 생성 모델
-
일반 생성 모델의 한계로 임의의 잠재 벡터로부터 데이터를 생성하기에 데이터를 잘 생성하지만, 그들의 의미는 제어할 수 없음.
-
따라서, 조건부 생성 모델의 필요로 생성 데이터의 의미 제어 방법을 통해 데이터 증강, 영상 편집등에 활용될 수 있으며, 특정 숫자만 생성 불가했던 기존 GANs에서 특정 숫자만 생성 가능하도록 할 수 있게 됨.
1. 조건부 생성 모델
- 임의의 잠재벡터 + 조건 정보를 추가하여 데이터를 생성함.

숫자 0을 생성하기 위한, 구체적인 조건부 벡터를 추가하여 데이터를 생성하는 식임.
2. 목적 함수
- 생성 모델에 입력되는 잠재벡터와 판별 모델에 입력되는 조건부 벡터가 추가된 형태임.
- 판별 모델이 입력받은 데이터가 실제 데이터와 유사하더라도 입력된 조건을 만족하지 않으면 0을 출력
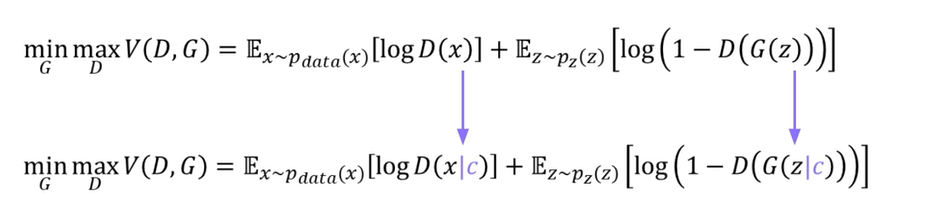
조건부 생성 모델을 활용한 다양한 영상 조작
- 이미지를 입력받아 원하는 이미지를 출력하는 것
- 조건부 생성 모델을 이용하여 원하는 이미지를 생성하는 방법들이 주로 이뤄짐.
이미지대 이미지 변환 : 전통적 접근
-
색상변환, 낮과 밤의 변환, 스케치 채색등의 변환
조건부 GANs 이전에는 각 task별 모델과 손실함수를 각각 정의해야 함. -
주어진 이미지를 회귀 모델을 통해 변환후, 타겟 이미지와 손실을 계산하여 개선하는 방식으로 L1손실 L2손실을 주로 활용함.
이는 사실 변환된 이미지를 생성하는 것인 아닌, 회귀 모델로 픽셀값을 예측하는 것으로 흐릿한 이미지가 만들어진다는 단점(평균, median 값을 예측하는데 한계가)이 있음.
Pix2Pix
- 쌍이 있는 이미지 변환 기술
- 이미지 쌍이 있는 조건부 생성 모델 기반의 이미지 대 이미지 변환 프레임워크를 제안함.
- 이미지를 특성별로 회귀 모형을 만드는 것이 아니라, 생성 모델이 변환된 이미지를 생성하는 것으로 변경.
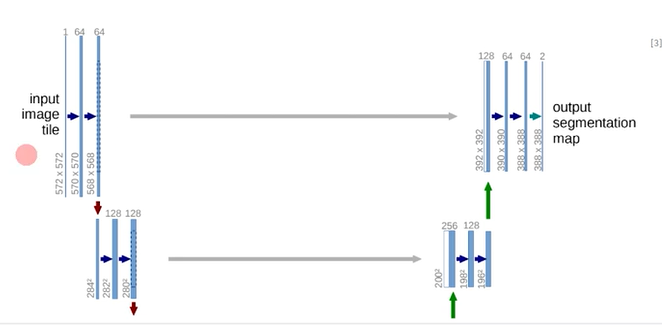
1. 생성 모델
- Pix2Pix의 생성 모델은 U-Net 기반의 생성 모델을 활용함. (더 좋은 이미지를 생성하게 됨)
- 인코더-디코더 구조에 skip connection을 추가하여, 이미지대 이미지 변환에서는 영상 세부 사항을 잘 유지하도록 하였음.
2. 판별 모델
- 저해상도 모델에 더 적합하므로, 고해상도를 위한 패치 기반의 판별 모델을 통해 PatchGANs의 판별 모델 구조를 활용함.
3. 손실함수
- 조건부 GANs의 손실함수 + 원본 이미지와의 유사성을 위한 L1정규화 항(정규화를 통해 더 잘 생성됨)을 추가함.

4. 한계점
- 데이터가 반드시 쌍으로 존재해야함, 데이터 확보가 어려워, 같은 위치의 다른계절, 같은 위치와 같은 자세이어야 한다는 점.
CycleGAN
- 기존 데이터의 쌍이 없는 데이터 셋이 훨씬 많기에 쌍이 없는 이미지 변환 기술임.
- 상호 변환이 가능하다는 것; 한국어 -> 영어 변환이 가능하다면, 영어 -> 한국어 변환도 가능해야함.
- 즉, 입력 이미지로 복원 가능한 정도까지만 이미지를 변환하도록 하여 원본 손실을 최소화함.

손실함수
- 실제 이미지와 생성된 이미지의 도메인이 동일하게 하는 손실함수를 활용함.
- 2개의 GAN모델이 필요함 즉, 4개의 네트워크(생성자 2, 판별자 2)
- 얼룩말(x) -> 말() ---> G (생성자 1), (판별자 1)
- 말(y) -> 얼룩말 () ---> F (생성자 2), (판별자 2)
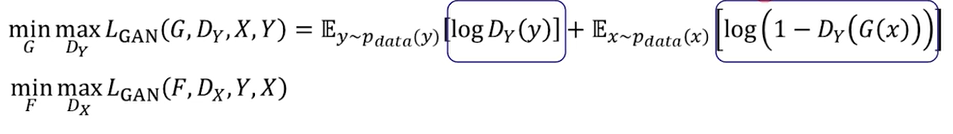
- 위의 수식처럼 GAN손실함수는 적용할 수 있음. F(생성자 2)에 대한 minmax에서는 로, 그 오른쪽 항은 로 변환됨.
추가로 Cycle Consistency를 위한 정규화 기반의 손실함수를 추가해야 함.
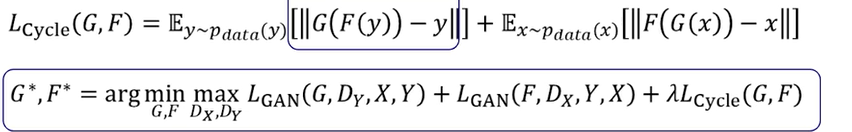
- 말 -> 얼룩말 -> 다시 말로 변환은 동일해야 함.
즉, y를 F를 통해 x로 만들고, 이를 다시 G()가 y가 되어야 함.
