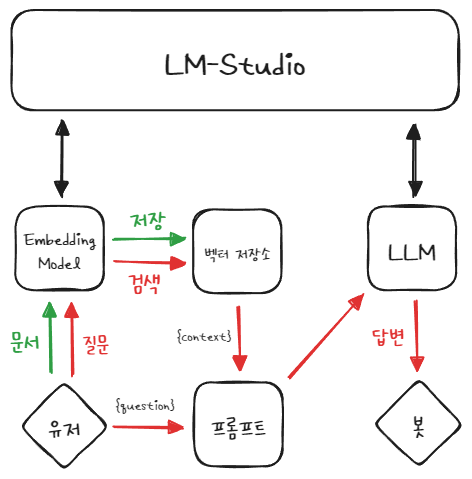
이 글에서는 LM Studio에서 로컬로 실행하는 LLM 서버를 기반으로 RAG를 구현해보고자 한다.
Streamlit 고찰
- 사용자가 액션을 취할 때마다 코드가 처음부터 끝까지 다시 실행 되는 것 같다.
- 사용자가 액션을 취할 때마다 llm, emb_model 등을 다시 가져오는 불상사가 존재.
- 다만 유지가 되는 것이 st.session_state 이라는 변수 인데 Dict 처럼 사용할 수 있다.
- 이 곳에 굳이 다시 불러올 필요가 없는 변수들을 여기에 담아서 사용했다.
# 언어모델
if 'llm' not in st.session_state:
with st.spinner("Loading LLM..."):
st.session_state['llm'] = ChatOpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio",
model="lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF",
temperature=0.1,
)
llm = st.session_state['llm']- 이 외에도 임베딩 모델, text_splitter, 체인, 채팅 이력 등등 위와 같이 처리했다.
- 문서 업로드는 업로드 시에는 바뀌어야 되므로 다른 방식으로 처리해야 한다.
- UI 적인 부분은 기본값으로 디자인이 정해져있는 듯하다.
- Streamlit Docs에서 필요한 UI나 기능을 쉽게 찾을 수 있다.
간단한 Streamlit 예제를 만들어서 사용해보니 코드 몇줄만으로 이정도 퀄리티의 웹페이지를 만들 수 있다는 것에 놀랍다.
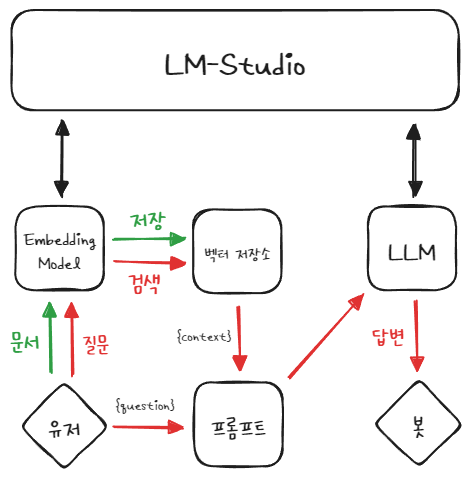
RAG 웹 챗봇 구성
- 웹 API : Streamlit
- LLM : lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF
- Embedding Model : nomic-ai/nomic-embed-text-v1.5-GGUF
- LLM, Embedding Model로 LM-Studio 로컬서버만 사용
- 이 외에 모델 다운로드, 프롬프트 다운로드 등등 없음
- TXT, PDF만 파일 업로드 지원
- 문서 청크사이즈 : 200, overlap : 50
- 벡터저장소 : FAISS, top_k : 10
- RAG용 체인, 대화용 체인
제작한 웹 페이지 리뷰
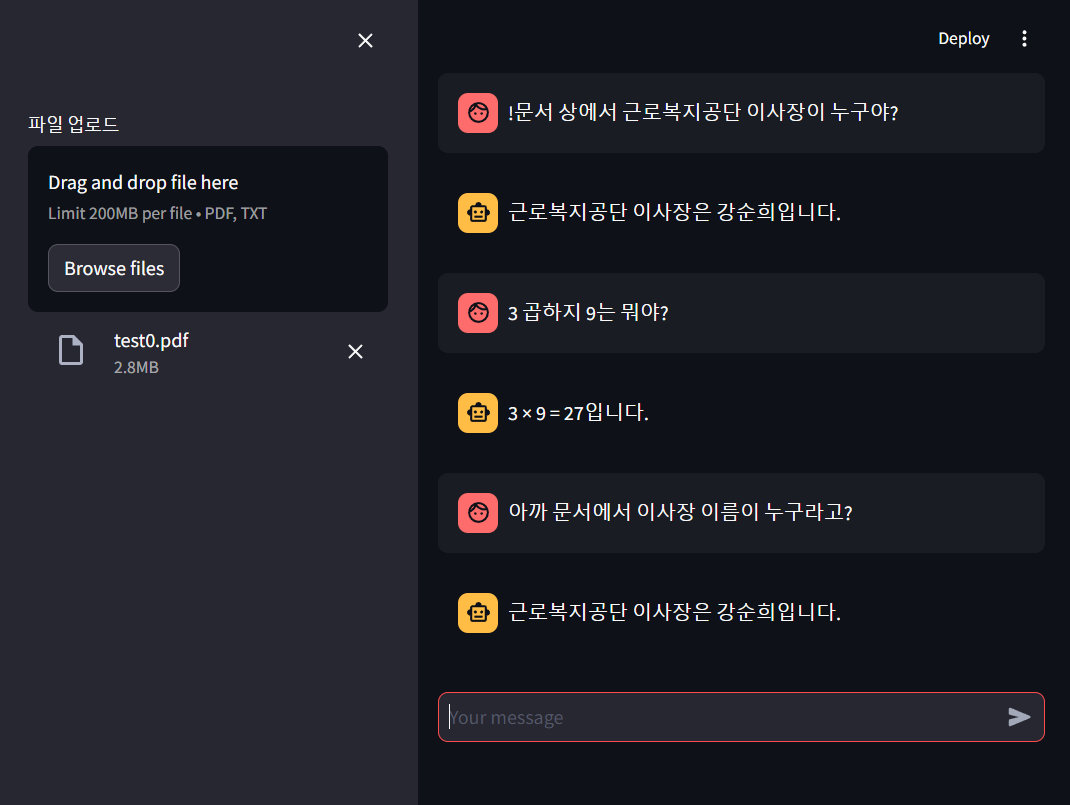
- streamlit run server.py로 실행후 처음 화면이다.
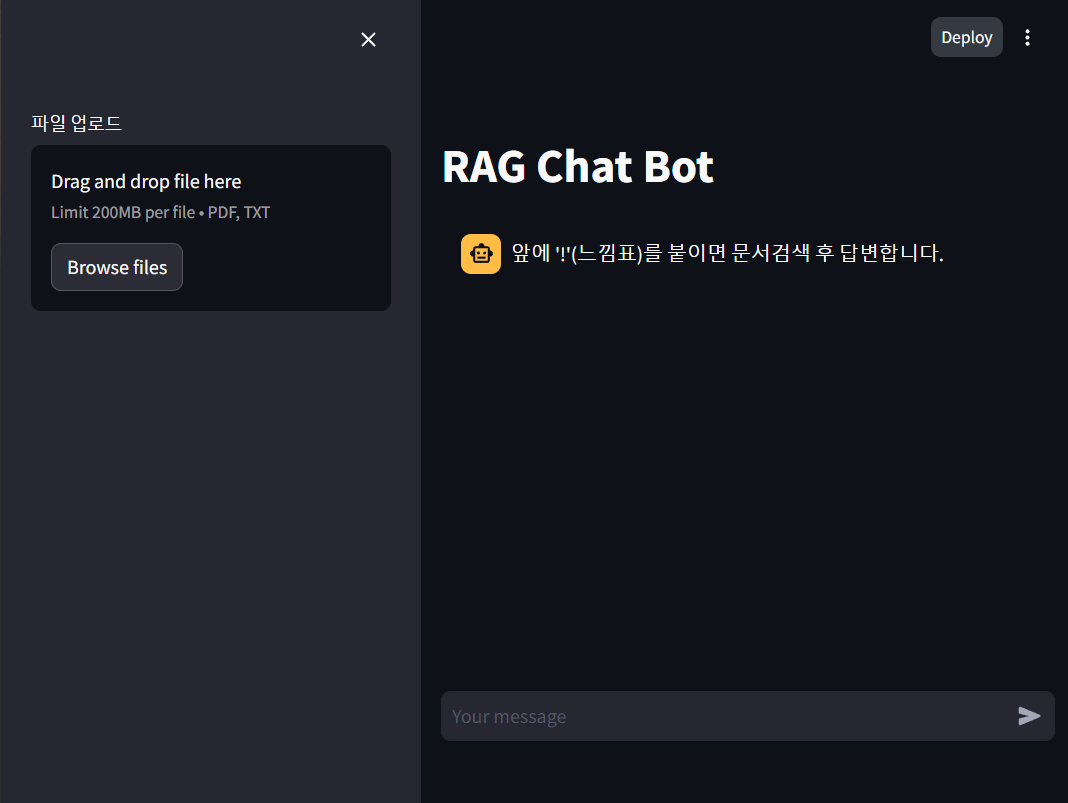
- 느낌표를 앞에 붙이고 질문하면 RAG용 체인으로 작동하여 검색하여 답변한다.
- 여기서 RAG용 체인은 이전대화 포함하지 않고 입력한다.
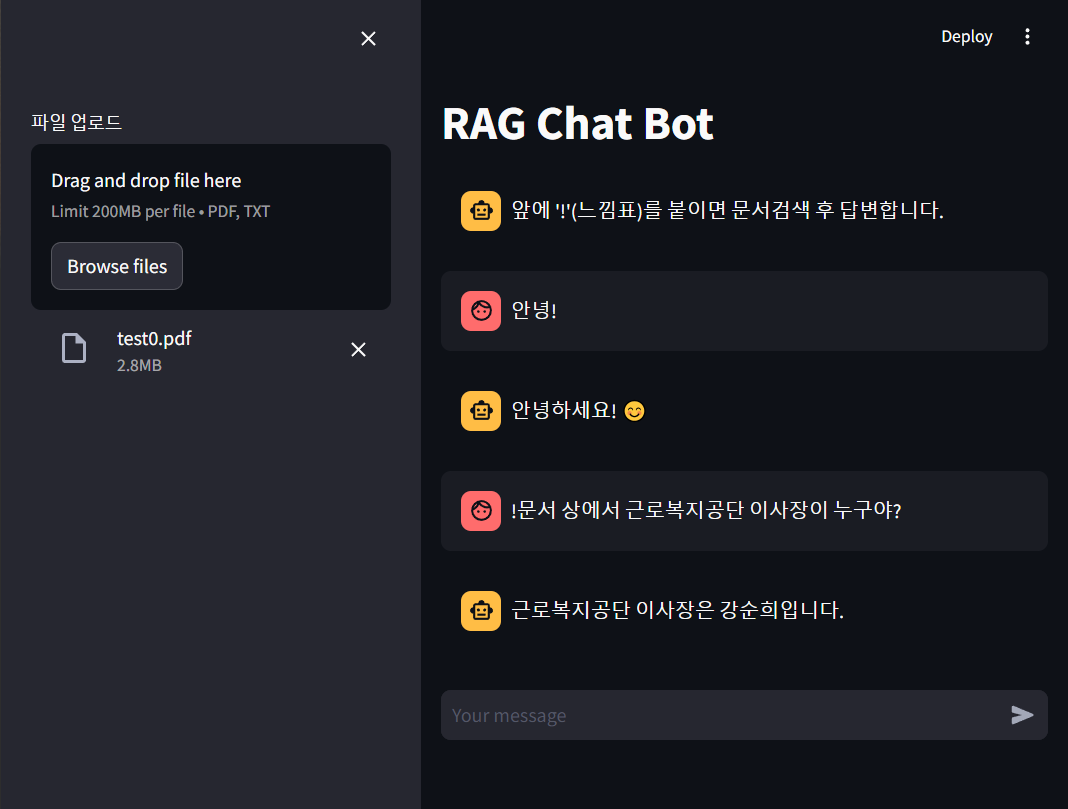
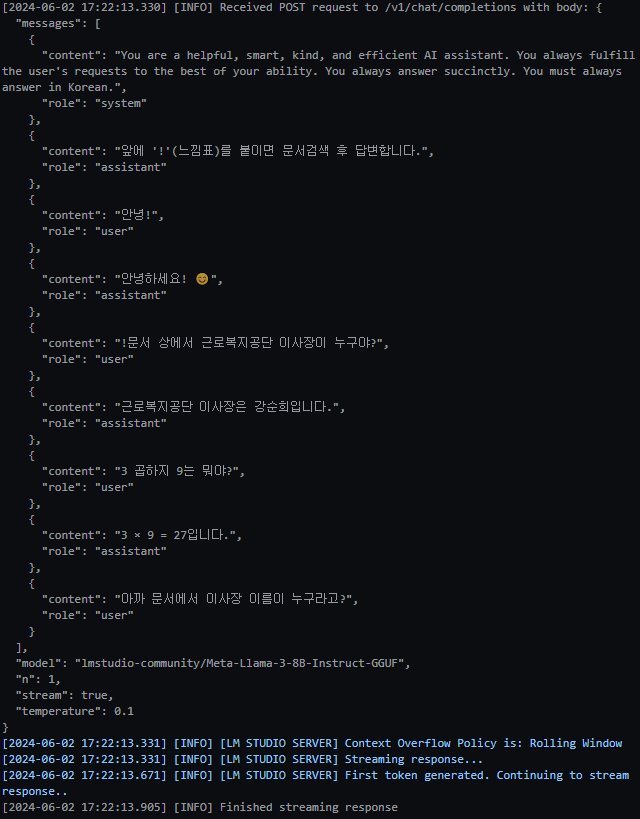
- 아래는 LM Studio 서버의 로그이다.
- 느낌표를 붙이지 않으면 대화용 체인으로 작동하여 이전대화 기록으로 포함하여 입력한다.
- 이전 RAG 답변 기록도 저장되어있기 때문에 관련 내용을 기억한다.
- 아래는 LM Studio 서버의 로그이다.
제작한 코드 리뷰
file -> retriever
- file 업로드시 실행되는 코드이다.
- 사용자 액션에 따라 코드들이 재실행 된다고 했는데,
st.cache_resource가 캐시 역할하기 때문에 같은 file이면 캐시에서 객체를 바로 불러온다. - 파일 확장자에 따라 TextLoader 또는 PyPDFLoader를 자동으로 선택한다.
# 파일 -> 벡터저장소
@st.cache_resource(show_spinner="Embedding file...")
def embed_file(file):
# 문서 불러오고 분할
with open("./temp", 'wb') as f:
f.write(file.read())
Loader = {'txt':TextLoader, 'pdf':PyPDFLoader}[file.name.split('.')[-1].lower()]
docs = Loader("./temp").load_and_split(text_splitter=text_splitter)
os.remove("./temp")
# 벡터화
vectorstore = FAISS.from_documents(docs, embedding=emb, distance_strategy=DistanceStrategy.COSINE)
retriever = vectorstore.as_retriever(search_kwargs={'k':10})
return retriever
# 파일 업로드 위젯
with st.sidebar:
file = st.file_uploader("파일 업로드", type=["pdf", "txt", ], )
if file: retriever = embed_file(file)채팅부분
- streamlit을 사용해보면서 백엔드와 프론트엔드가 합쳐진 코드를 만드는 느낌이었다.
- 아래 코드 부분이 채팅부분 전체라고 볼 수 있다.
- 채팅 이력은 ChatMessage을 st.session_state['messages']라는 리스트에 담아서 저장한다.
- 파일유무와 '!'에 따라 chain을 선택해서 실행한다.
# 채팅 내역 출력
for msg in st.session_state['messages']:
st.chat_message(msg.role).write(msg.content)
# 유저 입력
if user_input := st.chat_input():
st.session_state['messages'].append(ChatMessage(role='user', content=user_input))
st.chat_message('user').write(user_input)
if retrieve_flag := user_input[0] == '!': user_input = user_input[1:]
if file and retrieve_flag:
format_docs = lambda docs:"\n\n".join(doc.page_content for doc in docs)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| st.session_state['rag_chain']
)
chain_input = user_input
else:
chain = st.session_state['chat_chain']
chain_input = st.session_state['messages']
with st.chat_message('assistant'):
bot_out = st.empty()
msg = ''
for t in chain.stream(chain_input):
msg += t
bot_out.markdown(msg)
st.session_state['messages'].append(ChatMessage(role='assistant', content=msg))LM Studio를 이용한 RAG를 도전해보면서 LM Studio 임베딩을 사용하는 부분에서 막힐 줄 알았다.
산전수전이 많았지만 여러 사이트 참고해보고 여러번 직접 테스트를 해본 결과
LM Studio 로컬서버를 이용한 완전한 로컬 RAG 챗봇을 만들 수 있었다.

궁금했는데 너무 멋진 결과물 공유주셔서 감사합니다
참고하겠습니다