순열과 조합factorial()
순열
( n r ) = n P r = n ! ( n − r ) ! \binom{n}{r} \;=\;_nP_r\;=\;\frac{n!}{(n-r)!} ( r n ) = n P r = ( n − r ) ! n ! 조합
binomial()
( n r ) = n C r = n ! r ! ( n − r ) ! \binom{n}{r} \;=\;_nC_r\;=\;\frac{n!}{r!\,(n-r)!} ( r n ) = n C r = r ! ( n − r ) ! n ! 조건부확률
conditional probability P ( B ∣ A ) P(B\,|\,A) P ( B ∣ A )
베이즈 정리
Bayes' Theorem
사전확률 : P ( A ) P(A) P ( A ) A A A
사후확률 : P ( A ∣ B ) P(A\,|\,B) P ( A ∣ B ) B B B A A A "B B B A A A A A A B B B
기댓값/분산/표준편차
기댓값
expectation E ( X ) E(X) E ( X )
분산
variance V ( X ) V(X) V ( X ) E ( X 2 ) − E(X^2)- E ( X 2 ) −
표준편차
standard deviation 𝜎 = V ( X ) \sqrt{V(X)} V ( X )
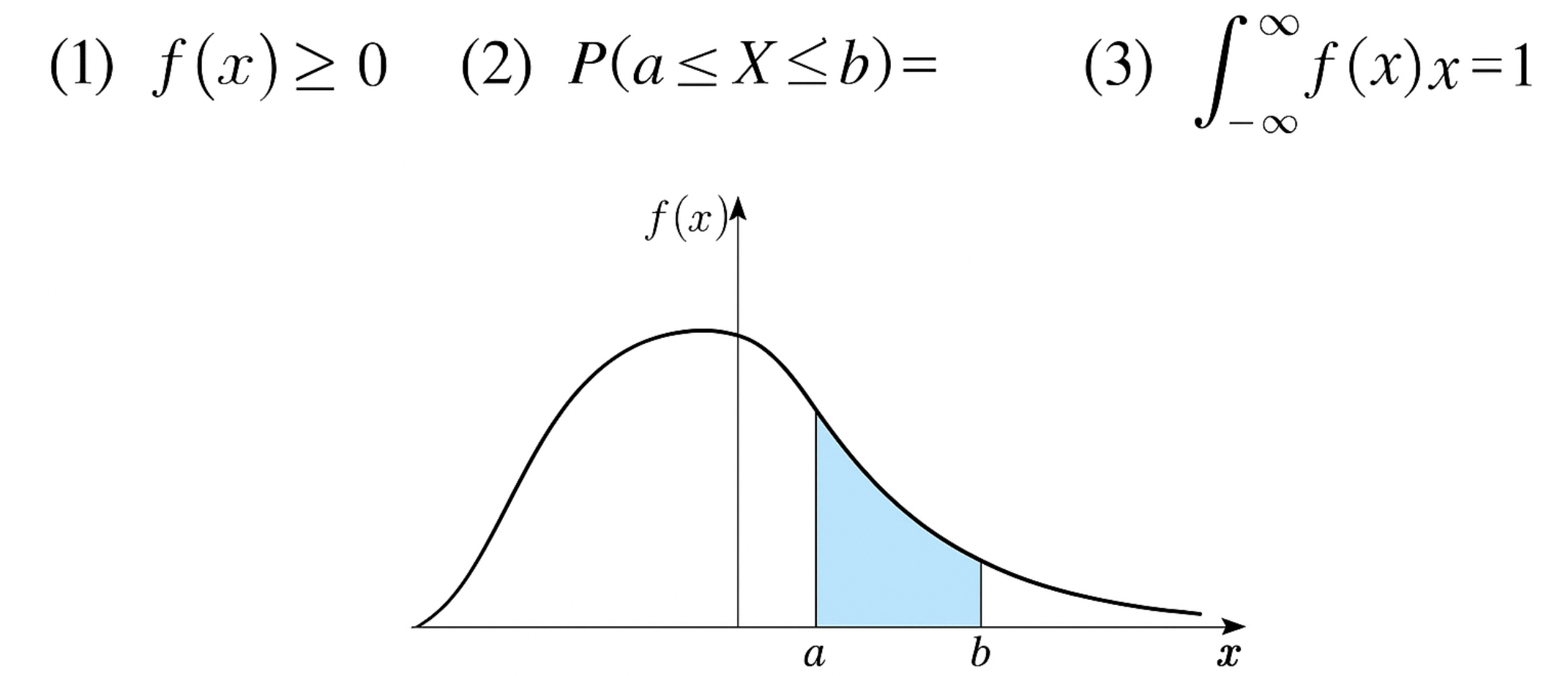
확률밀도함수(연속)
확률변수 X X X
E ( X ) = E(X) =\; E ( X ) = integral(x*f, x, 0, 1), (var('t'))
확률분포
이산 확률분포 - ∑ \sum ∑
연속 확률분포 - ∫ \int ∫
베르누이분포
Bernoulli distribution B ( 1 , p ) B(1,\,p) B ( 1 , p ) 1 회 시행한 확률변수 X X X ( 1 − p % ) (1-p\%) ( 1 − p % ) p % p\% p % X X X 베르누이 분포 를 따른다"고 하며, "X X X B ( 1 , p ) B(1,\,p) B ( 1 , p )
E ( X ) = p , V ( X ) = p ( 1 − p ) E(X) = p\,,\\V(X) = p(1-p) E ( X ) = p , V ( X ) = p ( 1 − p ) 확률분포 : P ( X = x ) = p x ( 1 − p ) 1 − x , x = 0 , 1 P(X=x)=p^x(1-p)^{1-x},\;\;\;x=0,1 P ( X = x ) = p x ( 1 − p ) 1 − x , x = 0 , 1
p = 1 / 6
P = [ p** t * ( 1 - p) ** ( 1 - t) for t in range ( 2 ) ]
print ( P)
이항분포와 포아송분포
이항분포(이산)
Binomial distribution B ( n , p ) B(n,\,p) B ( n , p )
P ( X = x ) = ( n x ) p x q n − x ( 단 , p + q = 1 , x = 0 , 1 , 2 , ⋯ , n ) P(X=x)=\binom{n}{x}p^xq^{n-x}\;\;\;(단,\;p+q=1,\;x=0,1,2,⋯,n) P ( X = x ) = ( x n ) p x q n − x ( 단 , p + q = 1 , x = 0 , 1 , 2 , ⋯ , n ) X ∼ B ( n , p ) X\,\sim\;B(n,p) X ∼ B ( n , p ) 포아송 분포(이산(
Poisson distribution P ( λ ) P(\lambda) P ( λ ) B ( n , p ) B(n,p) B ( n , p ) 평균 λ = n p 평균\;\lambda=np 평 균 λ = n p n p ≤ 5 np\le5 n p ≤ 5
lim n → ∞ B ( n , p ) = lim n → ∞ n C x p x ( 1 − p ) n − x = λ x x ! e − λ = e − λ λ x x ! = P ( λ ) \lim_{n\to\infin}{B(n,p)}=\lim_{n\to\infin}\,_nC_xp^x(1-p)^{n-x}=\frac{\lambda^x}{x!}e^{-\lambda}=\frac{e^{-\lambda}\lambda^x}{x!}=P(\lambda) n → ∞ lim B ( n , p ) = n → ∞ lim n C x p x ( 1 − p ) n − x = x ! λ x e − λ = x ! e − λ λ x = P ( λ ) 연속확률분포 - 균등분포
Uniform distribution U ( a , b ) U(a,b) U ( a , b ) P ( a ≤ X ≤ b ) = 1 P(a\le\,X\le\,b)=1 P ( a ≤ X ≤ b ) = 1 X ∼ U ( a , b ) X\sim\,U(a,b) X ∼ U ( a , b )
연속확률분포 - (표준)정규분포
Normal distribution N ( μ , σ 2 ) N(\mu, \sigma^2) N ( μ , σ 2 )
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 ( − ∞ < x < ∞ ) f(x)=\frac{1}{\sqrt{2\pi}\,\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\;(-\infin<x<\infin) f ( x ) = 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 ( − ∞ < x < ∞ ) 일 때,
X ∼ N ( μ , σ 2 ) . X\sim\,N(\mu,\sigma^2)\,. X ∼ N ( μ , σ 2 ) . Standard normal distribution N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
Z = X − μ σ , Z ∼ N ( 0 , 1 ) Z=\frac{X-\mu}{\sigma},\;\;\;\;Z\sim\,N(0,1) Z = σ X − μ , Z ∼ N ( 0 , 1 ) F ( z ) = P ( Z ≤ z ) = ∫ − ∞ z 1 2 π e − z 2 2 d z F(z)=P(Z\le\,z)=\int_{-\infin}^{z}\frac{1}{\sqrt{2\pi}}e^{-\frac{z^2}{2}}dz F ( z ) = P ( Z ≤ z ) = ∫ − ∞ z 2 π 1 e − 2 z 2 d z
f( z) = 1 / sqrt( 2 * pi) * e^ ( - z^ 2 / 2 )
print ( numerical_integral( f( z) , - 3 , 3 ) [ 0 ] )
print ( numerical_integral( f( z) , - 1 , 1.2 ) [ 0 ] ) 연속확률분포 - 지수분포
Exponential distribution G ( 1 , 1 / λ ) G(1, 1/\lambda) G ( 1 , 1 / λ ) 푸아송 분포를 따른다면 , ** 다음 사건이 일어날 때까지의 대기 시간 **은 지수분포를 따른다 고 한다.
f ( x ) = { λ e − λ x 0 < x < ∞ 0 x ≤ 0 f(x) = \begin{cases} \lambda e^{-\lambda x} & 0<x<\infin \\ 0 & x\le0 \end{cases} f ( x ) = { λ e − λ x 0 0 < x < ∞ x ≤ 0 \\
결합확률분포(이산)
Joint probability distribution : X X X Y Y Y p ( x i , y i ) p(x_i,y_i) p ( x i , y i )
결합밀도함수(연속)
Joint density function f ( x , y ) ≥ 0 f(x, y) \ge 0 f ( x , y ) ≥ 0
f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y , f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x f_X(x)=\int_{-\infin}^{\infin}f(x,y)dy,\;\; f_Y(y)=\int_{-\infin}^{\infin}f(x,y)dx f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y , f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x \\
공분산
Covariance
C o v ( X , Y ) = σ x y = E [ ( X − μ x ) ( Y − μ y ) ] = E ( X Y ) − μ x μ y Cov(X,Y)=\sigma_{xy}=E[(X-\mu_x)(Y-\mu_y)]=E(XY)-\mu_x\mu_y C o v ( X , Y ) = σ x y = E [ ( X − μ x ) ( Y − μ y ) ] = E ( X Y ) − μ x μ y 상관계수
Correlation C o r r ( X , Y ) = ρ Corr(X,Y) = \rho C o r r ( X , Y ) = ρ
X , Y : f ( x , y ) = x + y , 0 < x < 1 , 0 < y < 1 일때 , C o v ( X , Y ) 와 C o r r ( X , Y ) 는 ? X, Y : f(x,y) = x+y,\;\;0<x<1,\;\;0<y<1일 때,\;Cov(X,Y)와\;Corr(X,Y)는? X , Y : f ( x , y ) = x + y , 0 < x < 1 , 0 < y < 1 일 때 , C o v ( X , Y ) 와 C o r r ( X , Y ) 는 ? var( 'x,y' )
f( x, y) = x+ y
f_X( x) = integral( f( x, y) , y, 0 , 1 )
f_Y( y) = integral( f( x, y) , x, 0 , 1 )
EX = integral( x* f_X( x) , x, 0 , 1 )
EY = integral( y* f_Y( y) , y, 0 , 1 )
EXY = integral( integral( x* y* f( x, y) , x, 0 , 1 ) , y, 0 , 1 )
Cov = EXY - EX* EY
print ( f'Cov[X,Y] = { Cov} ' )
VX = integral( x^ 2 * f_X( x) , x, 0 , 1 ) - EX^ 2
YX = integral( y^ 2 * f_Y( y) , y, 0 , 1 ) - EY^ 2
Corr = Cov / ( sqrt( VX) * sqrt( VY) )
print ( f'Corr[X,Y] = { Corr} ' ) 공분산행렬
Covariance matrix V a r [ x ] = Σ Var[x] = \Sigma V a r [ x ] = Σ
주성분 분석(PCA)
Principal Component Analysis : 차원 축소 기법 중 하나