1. 문제정의
네이버 영화 리뷰 데이터셋
긍정과 부정 구분하기
긍정/부정 판단하는데 많이 영향을 끼치는 단어 시각화
bow말고 다른 토큰화방법 사용해보기
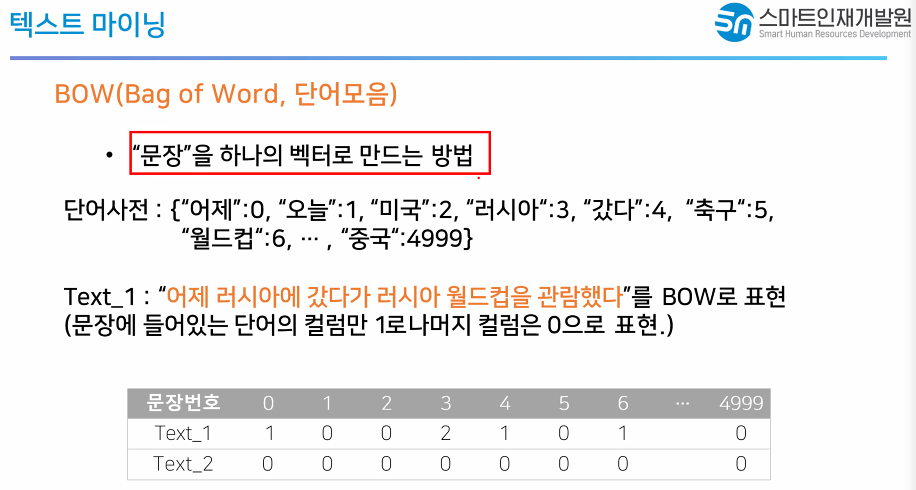
- Bow방법론에서는 가장 빈도가 높은 것이라는 단어가 가장 중요
2. 데이터 수집
import pandas as pd
text_train = pd.read_csv('./data/ratings_train.txt', delimiter = '\t')
text_test = pd.read_csv('./data/ratings_test.txt', delimiter = '\t')text_train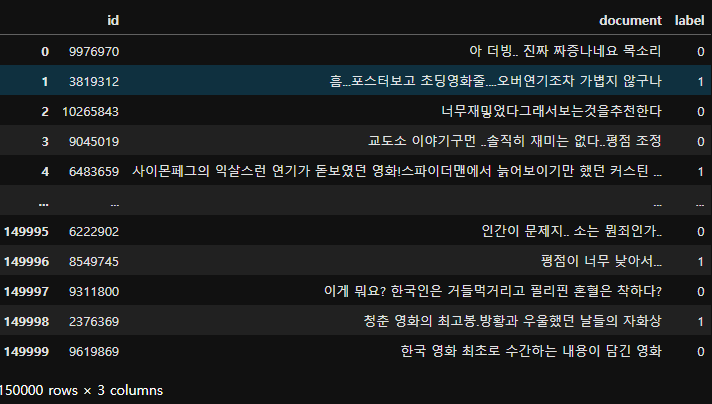
text_train.shape, text_test.shape((150000, 3), (50000, 3))
3. 데이터 전처리
text_train.info()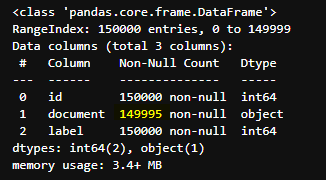
text_test.info()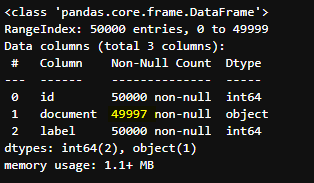
# train > 5개 결축치 삭제
# test > 3개의 결측치 삭제
# 결측치를 가지고있는 행을 삭제
text_train.dropna(inplace = True)
text_test.dropna(inplace = True)# 추가적인 전처리를 진행한다고 하면
# 정규표현식을 사용해서 한글만 남기기
text_train.info()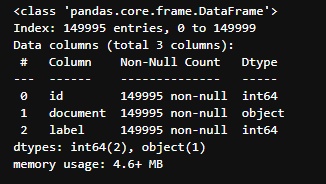
4. 탐색적 데이터 분석
X_train = text_train['document'][:10000]
y_train = text_train['label'][:10000]
X_test = text_test['document'][:2000]
y_test = text_test['label'][:2000]from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Kkmadef myTokenizer(text):
return kkma.nouns(text)bow_kkma = CountVectorizer(tokenizer = myTokenizer)
bow_kkma.fit(X_train) # 단어가전 구축X_train = bow_kkma.transform(X_train)
X_test = bow_kkma.transform(X_test)5. 모델 선택 (Logistic Regression)
from sklearn.linear_model import LogisticRegression6. 학습
lr = LogisticRegression()lr.fit(X_train, y_train)7. 평가
lr.score (X_train, y_train)lr.score(X_test, y_test)다른 토큰화 사용하기 - TFIDF
TF(Term frequency) : Tần suất xuất hiện của 1 từ trong 1 document.
IDF( Invert Document Frequency) : Dùng để đánh giá mức độ quan trọng của 1 từ trong văn bản. Khi tính tf múc độ quan trọng của các từ là như nhau. Tuy nhiên trong văn bản thường xuất hiện nhiều từ không quan trọng xuất hiện với tần suất cao:
TF(t, d) = (Số lần xuất hiện từ t) / (Tổng số từ)
TF-IDF(t, d, D) = TF(t, d) * IDF(t, D)
1. 전체에사 많이 나왔는가 > 각 문서에서 발생한 빈도
2. 문서에서 단어가 발생한 빈도 > 전체 문서중에서 해당 단어가 들어가있는 문서의 수 > 역수를 사용 > 적은 문서에서 발견될수록 가치있는 정보다
3. 1번값과 2번값을 곱해서 큰수가 나올수롯 중요한 단어__

from sklearn.feature_extraction.text import TfidfVectorizertfidf = TfidfVectorizer(tokenizer = myTokenizer)
X_train = text_train['document'][:10000]
X_test = text_test['document'][:2000]
tfidf.fit(X_train)
X_train = tfidf.transform(X_train)
X_test = tfidf.transform(X_test)lr = LogisticRegression()lr.fit(X_train, y_train)lr.score (X_train, y_train)lr.score(X_test, y_test)pipeline사용하기
from sklearn.pipeline import make_pipeline
pipe_model = make_pipeline(
TfidfVectorizer(tokenizer = myTokenizer),
LogisticRegression()
)
text_train = text_train['document'][:10000]
text_test = text_test['document'][:10000]
pipe_model.fit(text_train, y_train)
# 0: neg 1: pos
pipe_model.predict(['영화재미있어요'])
-> means positive comment
pipe_model.steps
tfidf = pipe_model.step[0][1]
logi = pipe_model.step[1][1]voca = tfidf.vocabulary_
df = pd.DataFrame([voca.keys(), voca.values()])
df = df.T
df_sorted = df.sort_values(by =1)
df_sorted['weight'] = logi.coef_[0]
df_sorted.sort_values(by = 'weight', inplace = True)
df_sorted.head()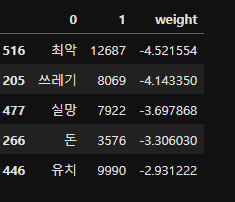
top20_df = pd.concat(
[
df_sorted.head(20),
df_sorted.tail(20)
]
)
top20_df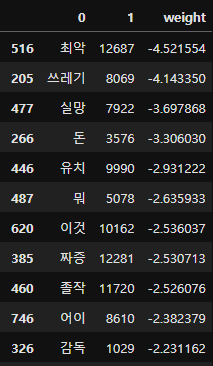

열심히 공부합시다! The best is yet to come! 💜