0. Data download
https://ai.stanford.edu/~amaas/data/sentiment/

앞축풀기 -> delete folder unsup 폴더 삭제
🍾🍷1. 문제정의
- 영화 리부 데이터셋을 활용해서 긍정과 부정을 구분해보자
- 긍정/부정 리부에서 자주 사용되는 단어를 확인해보자
2. 데이터 수집
Large movie dataset download 불러오기
# 여러개 파일을 한번에 읽어오는 함수
from sklearn.datasets import load_filestrain_data_url = 'data/aclImdb/train'
test_data_url = 'data/aclImdb/test'reviews_train = load_files(train_data_url, shuffle = True)
reviews_trainHàm shuffle() trong Python sắp xếp các item trong list một cách ngẫu nhiên
shuffle = true means items in list are arranged randomly
reviews_test = load_files(test_data_url, shuffle = True) reviews_test# to see in reviews train has how many columns and its name reviews_train.keys()


# b가 붙어있는 문자열 = 바이트 자료형
reviews_train['data'][0]
len(reviews_train['data'])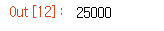
len(reviews_test['data'])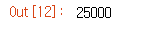
# 정답 데이터 비율 확인
import numpy as np
np.bincount (reviews_train['target'])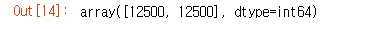
# 데이터의 갯수는 고르게 ㅂ분포해있는게 좋다
# 한쪽에 치우쳐젖 있으면 모델이 규칙을 잘 찾지 못함
reviews_train['target_names']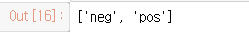
3. 데이터 전처리
br태그제거 (type자료형)# br tag is html tag not just a character so need to add b in front
reviews_train['data'][0].replace(b'<br />',b'')# 리스트 내포
# 리스트안에서 다양한 작업을 포함
text_train = [txt.replace(b'<br />',b'') for txt in reviews_train['data']]
text_test = [txt.replace(b'<br />',b'') for txt in reviews_test['data']]# train size: 5000, test size: 2000
text_train = text_train[:5000]
text_test = text_test[:2000]
y_train = reviews_train['target'][:5000]
y_test = reviews_test['target'][:2000]토큰화
띄어쓰기를 기준으로 데이터를 나누기
BOW 방법 = CountVectorizer
CountVectorizer được sử dụng để chuyển một văn bản nhất định thành một vectơ trên cơ sở tần suất (số lượng (count)) của mỗi từ xuất hiện trong toàn bộ văn bản
나온 단어의 갯수를 세어준다from sklearn.feature_extraction.text import CountVectorizermovie_bow = CountVectorizer() movie_bow.fit(text_train) x_train = movie_bow.transform(text_train) x_test = movie_bow.transform(text_test)4. 데이터 분석
생량
문장을 숫자로 바꾸는 과정에서 단어의 갯수를 세어준다
글자의 갯수를 숫자로 바꾸었기 때문에 통계적인 값이 크기 의미가 없다5. 모델 선택
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVCdt = DecisionTreeClassifier()
svm = LinearSVC()# 교차검증
# 여러 모델 사용햐보소 결과 좋은ㄴ모델 찾을ㄹ때 사용하기도 함
from sklearn.model_selection import cross_val_scorecross_val_score(dt,x_train, y_train, cv = 5).mean()cross_val_score(svm,x_train, y_train, cv = 5).mean()6. 학습
svm.fit(x_train, y_train)7. 예측 및 평가
- 영화 리부 데이터셋을 활용해서 긍정과 부정을 구분해보자
svm.score(x_train,y_train)svm.score(x_test,y_test)# 예측하기위한 데이터도 기존 전처리를 전부 진행해야함
# 1. 데이터 형식을 맞추기 위해서
# 2. 머신러닝 학습에 숫자데이터만 가능
# 3.기존 방밥이 아닌 다른 방법으로 전처리를 진래라면 데이터의 의미다 달라짐
reviews =['This movie is suck']# br태그 제거
text_pred = [txt.replace('<br />','') for txt in reviews]
text_pred
# bow > 토큰화하기
x_pred = movie_bow.transform(text_pred)svm.predict(x_pred)
0: neg 1: pos
긍정/부정 리부에서 자주 사용되는 단어를 확인해보자
# 단어별 가중치 # 0번부터 39243개 까지 차례대로 나열 word_weight = svm.coef_ len(word_weight[0])import pandas as pd # 단어사전을 번호 기준으로 정렬 df = pd.DataFrame([voca.keys(), voca.values()]) df = df.T # 행과 열 바꾸기 df.head()# 1이름을 갖는 열 (컬럼)을 기준으로 정렬 df_sorted = df.sort_values(by = 1) df_sorted.head()# 가중치 합치다 df_sorted['weight'] =word_weight[0] df_sorted# 1변 컬럼 기준으로 정렬했던 이유 = weight가 단어 번호오 정렬되어있기 떄문 # 단어별 가중치를 확인해야하기 떄문에 weight가준으로 재정렬 df_sorted.sort_values(by = 'weight', inplace = True)
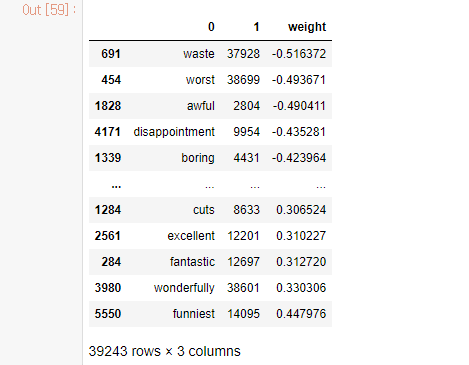
# 시각화해서 확인하기
top20_df = pd.concat(
[
df_sorted.head(20), df_sorted.tail(20)
])
top20_dfimport matplotlib.pyplot as pltplt.figure(figsize = (15,5))#그레프 크기 조절
plt.bar(top20_df[0], top20_df['weight'])
plt.xticks(rotation = 90)
plt.show()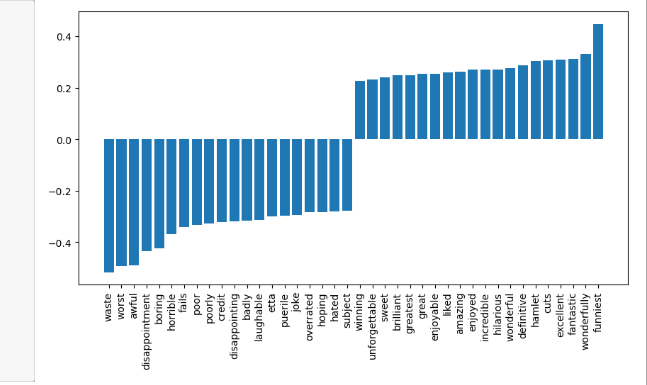

열심히 공부합시다! The best is yet to come! 💜