
👨🏫학습목표
오늘은 Dynamic programming과 Reinforcement Learning의 차이와 Generalized Policy Iteration에 대해 배워볼 예정이다.
👨🎓강의영상: https://www.youtube.com/watch?v=NH3lKBzXBUA&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=10
1️⃣ DP vs RL
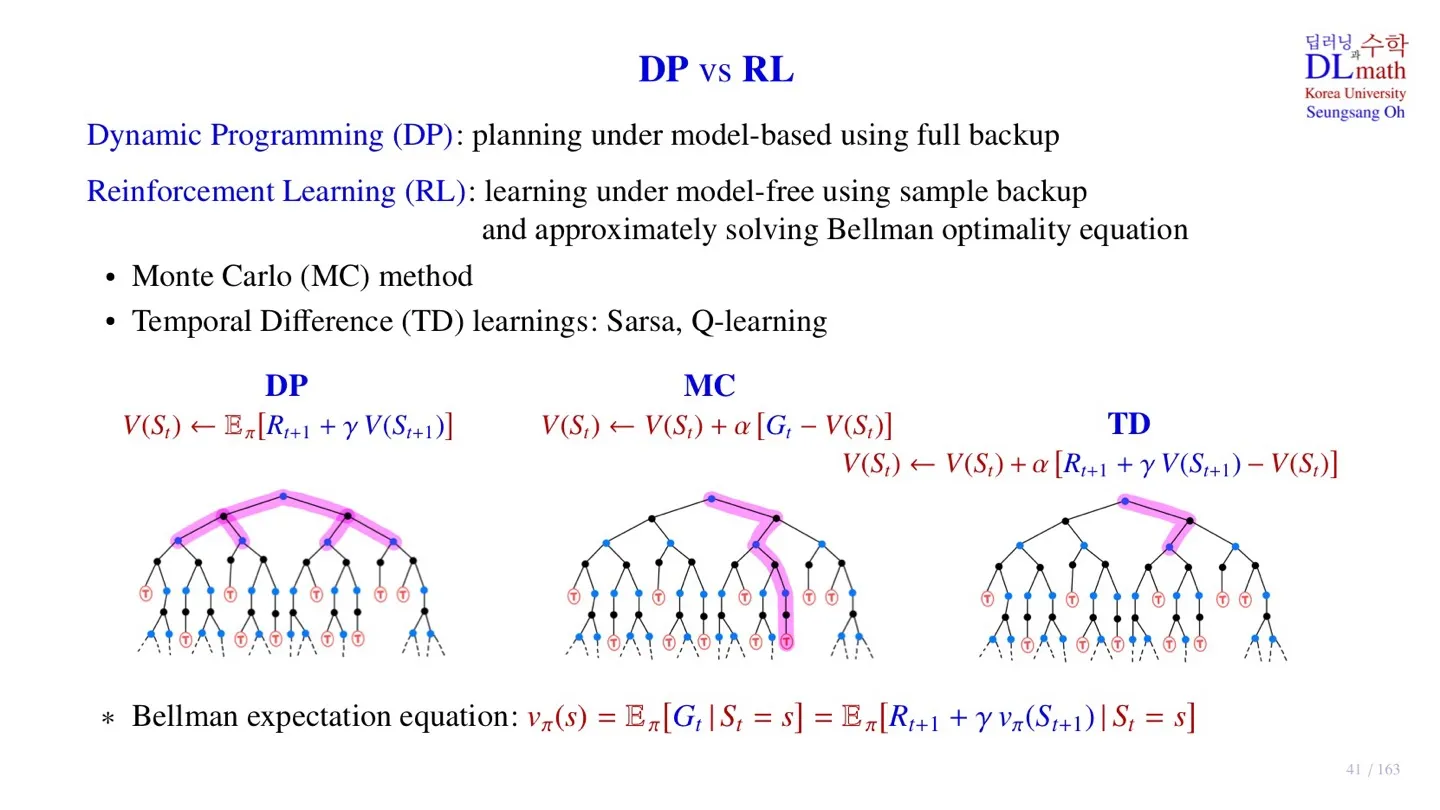
🔷 Dynamic programming
- Value-function table을 이용한다.
- Value-function table을 모든 state에 대해 계산한다.
- Planning: 모든 state를 효율적으로 계산하기 위한 방법
- Full backup: 각 state에서 이동할 수 있는 모든 state를 계산한다.
🔷 Reinforcement Learning
- Transition probability를 알 수 없다.
- 경험을 통해 알게 된 sample 데이터를 통해 학습한다.
- 특정한 state에서 action을 취했을 때 이어지는 다음 state에 대해서만 고려한다.
- sample 데이터를 통해 state-value function을 업데이트 한 **후, 해당 function을 통해 policy를 개선**한다.
- Reinforcement Learning은 sample을 통해 optimal policy를 추론하기 때문에 Bellman expectation equation을 완벽한 해는 아니다.
2️⃣ DP and RL

🔷 Dynamic programming
- 각 Iteration 마다 table의 모든 state에 대해 업데이트를 진행한다.
- 연산량이 많기 때문에 Q-function 대신 state-value function을 사용한다.
- Greedy policy Improvement를 사용한다.
🔷 Reinforcement Learning
- Sample data를 통해 Iteration 진행
- state-action pair를 sample data로 사용한다.
- 이러한 data를 통해 Q-table을 업데이트 한다.
- Dynamic Programming에서 Q-table을 업데이트한다면, 모든 state와 action의 경우를 고려하기 때문에 연산량이 굉장히 많을 것이다.
- Reinforcement Learning에서는 일부 value만 업데이트한다.
- Reinforcement Learning에서는 를 통해서 policy를 업데이트하기 때문에 transition probability 없이 연산 가능하다.
3️⃣ Generalized Policy Iteration
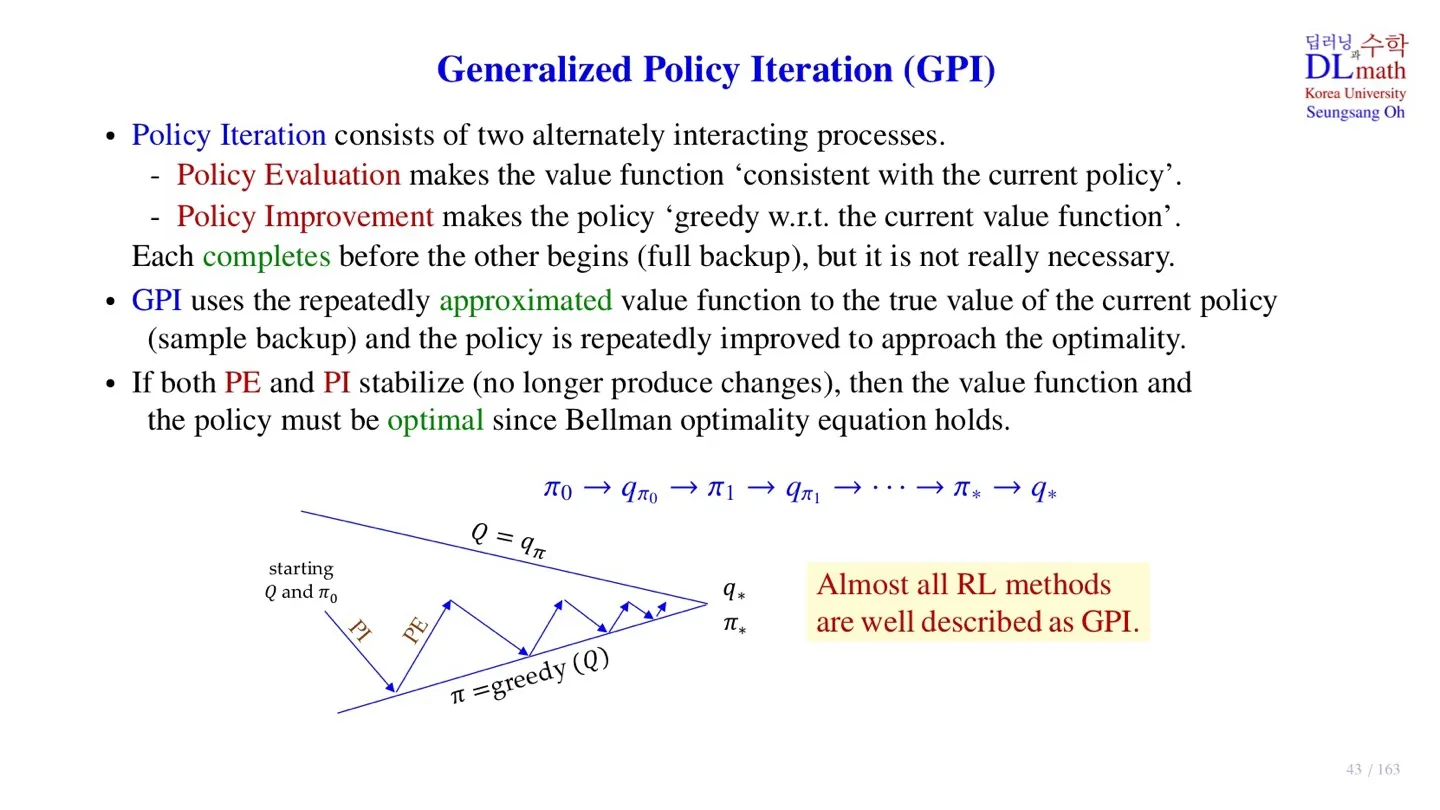
🔷 Policy Iteration
- Policy Evaluation: 현재 policy에서 value function이 수렴할 때까지 업데이트 한다.
- Policy Improvement: Evaluation을 통해 정해진 value값을 통해 policy를 업데이트 한다.
- state-value function은 완전히 수렴시키지 않아도 optimal policy를 구할 수 있다.
🔷 Generalized Policy Iteration (GPI)
- Sample data만 이용하여 state-value function을 업데이트 한다.
- 모든 data를 고려하는 것이 아니기 때문에 value function도 완전히 수렴하지는 않는다.
- policy evaluation과 policy Improvement가 수렴하면 optimal policy에 도달한 것이다.
4️⃣ 정리
🔷 10강에서 배운 내용은 아래와 같다.
- Dynamic Programming과 Reinforcement Learning의 차이에 대해 살펴보았다.
- Sample data만 고려하는 Policy Iteration, 즉 Generalized Policy Iteration (GPI)에 대해 살펴보았다.

I'm curious about AI