👨🏫학습목표
오늘은 TRPO의 Minorization-Maximization algorithm과 KL Divergence constraint 식에 대해 배워볼 예정이다.
1️⃣ Trust Region Policy Optimization

📕 지난 시간에 배운 내용
🔻 DDPG의 한계
- Policy의 monotonic improvement가 보장되지 않는다.
🔻 TRPO의 극복 방법
- Minorization-Maximization algorithm
- Trust region
이번 시간에는 Minorization-Maximization algorithm을 통해 policy의 monotonic improvement가 어떻게 보장되는지 살펴볼 예정이다.
2️⃣ TRPO의 object function

📕 지난 시간에 배운 내용
🔻 TRPO의 object function
η(π)=Es0,a0,…[t=0∑∞γtr(st)]
- Expected return을 object function으로 사용한다.
🔻 Object function 계산 방법
η(π)=η(πold)+s∑ρπ(s)a∑π(a∣s)Aπold(s,a)
- New policy의 η(π)를 구하기 위해서 old policy η(πold)에 추가적인 부분을 더한다.
- 다만 ρπ(s)를 구하기 위해서 new policy π의 sample state를 수집해야 하는데, 아직까지 new policy를 구하는 과정이기 때문에 실제로 sample state를 수집할 수 없다.
3️⃣ Object function의 approximation

📕 지난 시간에 배운 내용
🔻 Local approximation
Lπold(π)=η(πold)+s∑ρπold(s)a∑π(a∣s)Aπold(s,a)
- Lπold(π): 근사한 Object function
- 기존 식의 ρπ(s)를 ρπold(s)으로 변환한 것을 확인할 수 있다.
🔻 Approximation의 특징
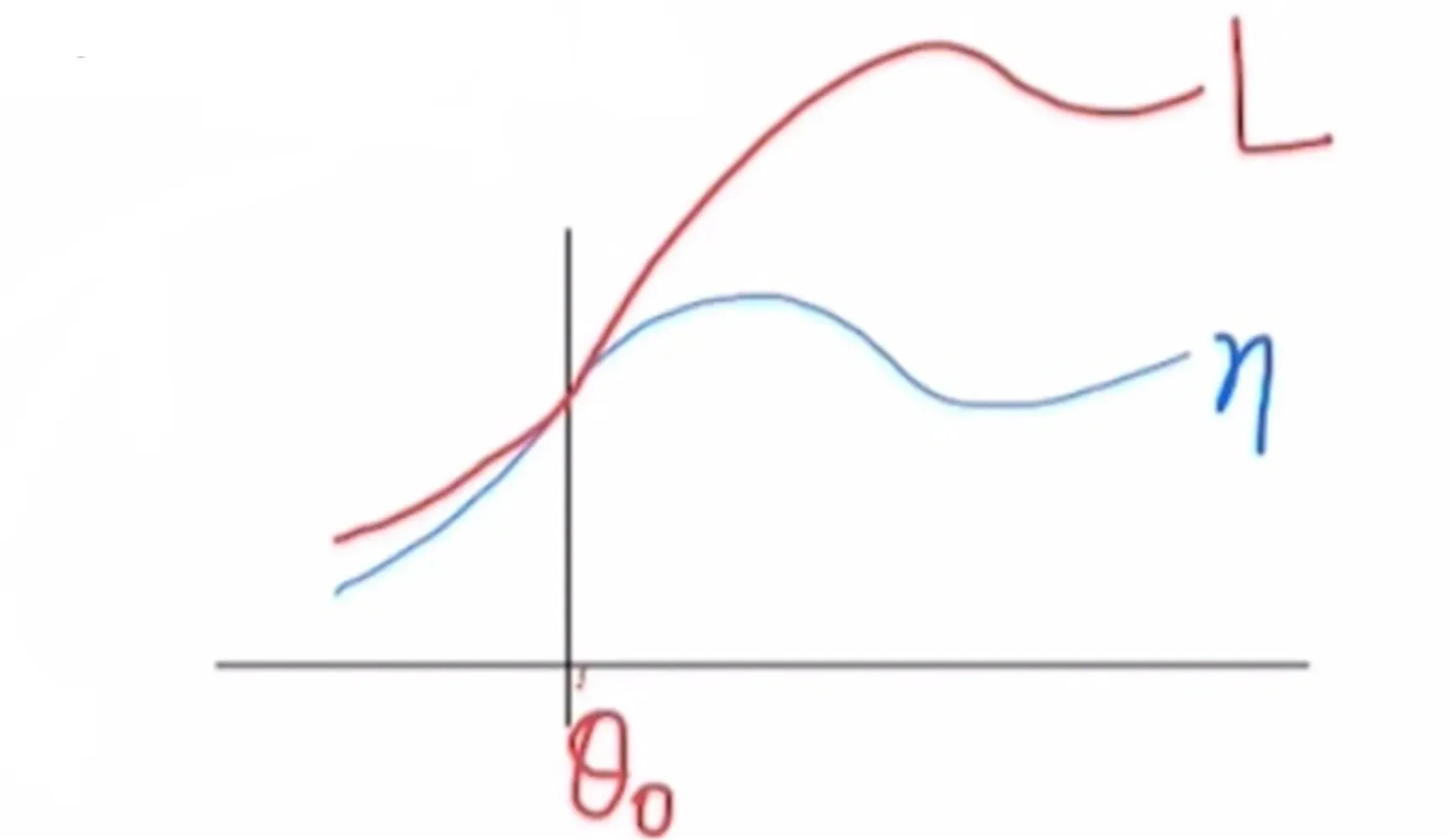
Lπθ0(πθ0)=η(πθ0) for any parameter value θ0.
∇θLπθ0(πθ0)∣θ=θ0=∇θη(πθ)∣θ=θ0 for any parameter value θ0.
- 위 두 식을 만족한다.
- Local한 영역에서 두 식에 유사하기 때문에 근사식이 improve되는 방향에서 기존의 식 역시 improve될 수 있음을 알 수 있다.
- 다만 근사한 영역의 크기를 알 수는 없기에 step size에 대한 정보는 알 수 없다.
🔻 Conservative policy iteration update
π(a∣s)=(1−α)πold(a∣s)+απ′(a∣s) where π′=argπmaxLπold(π)
- Conservative policy iteration update는 근사식 Lπold(π)을 최적화시킨 후 그 값을 Old policy πold에 일부만 반영하는 방법이다.
- Step size의 크기를 알 수 없기에 조금만 업데이트하는 방식이다.
- 해당 방식의 장점은 업데이트를 진행할 때 근사식이 lower bound를 가진다는 것이다.
η(π)≥Lπold(π)−(1−γ)22ϵγα2 where ϵ=smax∣Ea∼π′(a∣s)[Aπold(s,a)]∣
- 물론 성능이 개선된다는 보장은 없지만 lower bound를 통해 다양한 접근을 시도해볼 수 있다.
- 하지만 ϵ 값을 구하는 것은 쉽지 않다.
- 또한 mixture policy라는 개념 역시 아직까지 practical하게 적용하기는 쉽지 않다.
따라서 다음 단계에서는 approximation을 한번 더 진행할 예정이다.
4️⃣ Total Varinace Distance & KL Divergence

🔷 확률분포 사이의 거리

🔻 Total Variance distance
DTV(P,Q)=21∥P−Q∥1
- 확률 분포 차이의 면적을 의미한다.
- 2로 나눠주기 때문에 P>Q 인 영역만 고려해도 된다.
- 양쪽의 면접은 정확히 같다.
🔻 Kullback-Leibler divergence
DKL(P∣∣Q)=∫xp(x)logq(x)p(x)dx
-
p(x)와 q(x)가 유사해지면 q(x)p(x)≃1 가 된다.
-
그 결과 logq(x)p(x)≃0 이 된다.
-
또한 DKL(P∣∣Q)=DKL(Q∣∣P) 방향성을 가진다.
🔻 Approximation
🔸 기존의 식
η(π)≥Lπold(π)−(1−γ)22ϵγα2 where ϵ=smax∣Ea∼π′(a∣s)[Aπold(s,a)]∣
- α: Mixture policy를 생성할 때, 새로운 policy를 얼마나 반영할지 결정하는 파라미터
- π′=argmaxπLπold(π)
🔸 α 변환
α=smaxDTV(πold(⋅∣s)∣∣π(⋅∣s))
- α값을 Total Variation Distance로 대체한다.
- DTV: Total Variation distance
🔸 ϵ 변환
η(π)≥Lπold(π)−(1−γ)24ϵγα2 where ϵ=s,amax∣Aπold(s,a)∣
- ϵ 값 역시 바꾼다.
- 위 수식으로 변한다.
- π′을 사용하지 않는 것이 포인트이다.
🔸 KL-발산으로 변환
DKLmax(πold,π)=smaxDKL(πold(⋅∣s)∣∣π(⋅∣s))
η(π)≥Lπold(π)−CDKLmax(πold,π)where C=(1−γ)24ϵγ.
- 기존에 Total variance distance로 표현한 α를 KL-발산으로 바꾼다.
- DTV(p∣∣q)2≤DKL(p∣∣q) 부등호가 성립하기 때문이다.
🔷 Minorization-Maximization algorithm
η(π)≥Lπold(π)−CDKLmax(πold,π)where C=(1−γ)24ϵγ.
- Lower bound를 surrogate objective로 사용하면 policy가 monotonic하게 성능이 개선되는 것을 보장한다.
다음 페이지를 살펴본 후 다시 돌아와서 이야기해보도록 하겠다. MM algorithm을 TRPO에 적용하여 monotonic하게 improve되는 것을 확인한 후 다시 돌아오자.
🔷 Practical algorithm
- 앞서 살펴본 MM-algorithm의 이론적 내용을 기반으로 pratical한 algorithm을 만들어보자.
- πθ(a∣s): Policy를 의미한다.
- θ: Policy를 구현하는 파라미터를 의미한다.
- θold: Old policy를 구현하는 파라미터를 의미한다.
η(θ)≥Lθold(θ)−CDKLmax(θold,θ)
- η 를 업데이트하는 식을 위처럼 표현할 수 있다.
θmax[Lθold(θ)−CDKLmax(θold,θ)]
- Next policy θ를 구하기 위해서는 위 연산을 수행해야 한다.
- 하지만 해당 연산은 너무 많은 계산량이 필요한다.
- 따라서 TRPO는 많은 계산량을 필요로 한다.
5️⃣ Minorization-Maximization algorithm

🔷 MM algorithm
- Iterative method
- 3 step이 반복되는 구조이다.
🔻 1. Find a surrogate objective function Mi

-
Mi: Surrogative objective function
-
πi: Current policy
-
Mi는 Object function η(π)를 πi에서 approximate하는 함수이다.
-
Surrogative objetive function Mi는 Object function η(π)의 lower bound이다.
-
η(π)≥Mi
-
Surrogative objetive function Mi는 Optimize하기 쉬워야 한다.
-
TRPO에서는 Mi로 이차함수를 사용한다.
🔻 2. Find the optimal point πi+1

- Mi를 Maximize하는 optimal policy πi+1를 구한다.
- Mi(πi)≤Mi(πi+1)≤η(πi+1) 를 만족한다.
- 이러한 방식을 통해 monotomic improvement를 보장할 수 있다.
🔻 3. Find new surrogate objective function Mi+1

- 업데이트된 πi+1를 사용하여 Mi+1를 구한다.
🔻 Iteration
- Step 1~3을 반복하면 policy가 monotonic하게 improve된다.
- 궁극적으로 local 혹은 global optimal값에 도달한다.
6️⃣ MM algorithm 적용
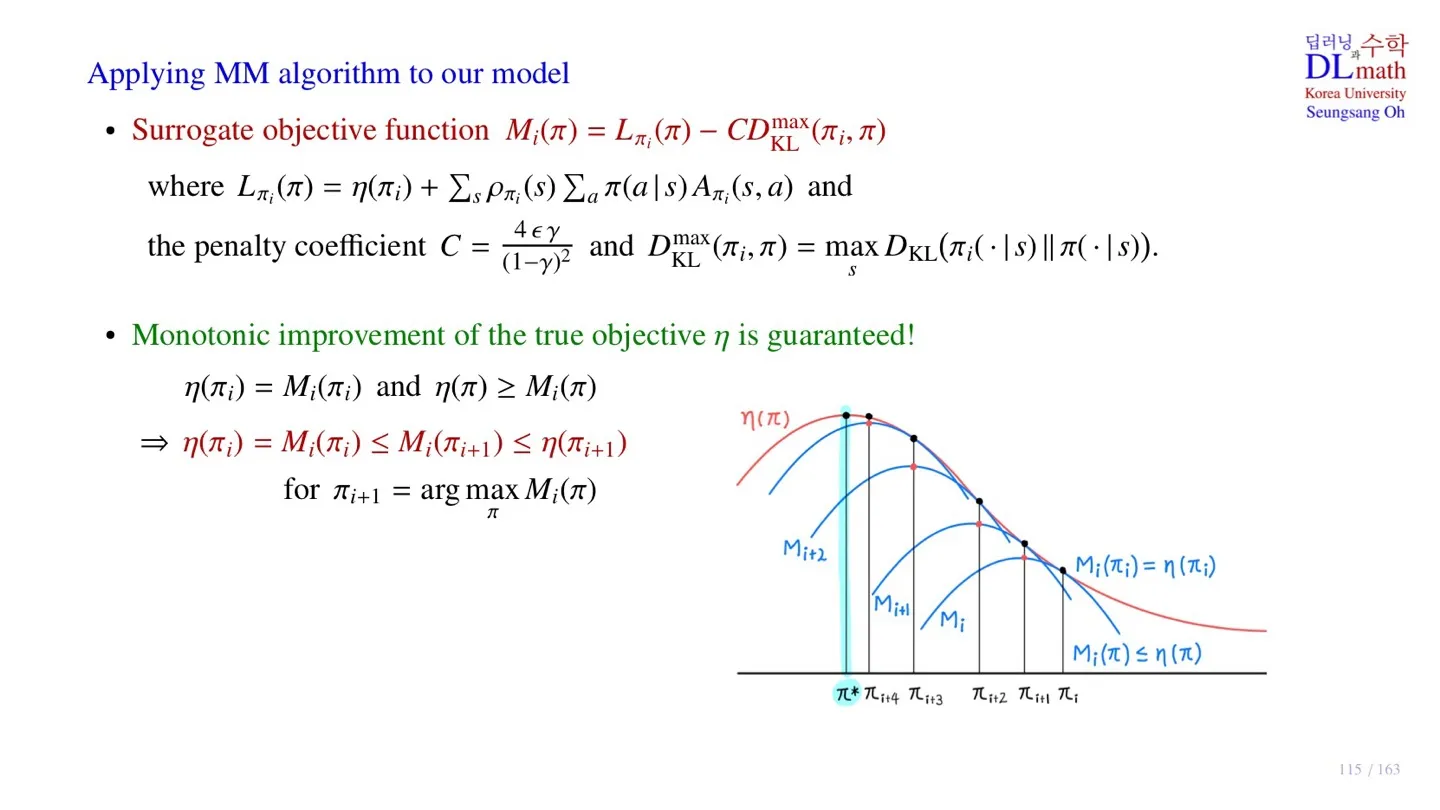
🔷 Surrogate objective function Mi(π)
η(π)≥Lπold(π)−CDKLmax(πold,π)
Mi(π)=Lπi(π)−CDKLmax(πi,π)
- 앞서 찾은 lower bound이다.
- πi를 통해 π를 찾는 과정이다.
🔻 Mi(π)를 surrogate objective function으로 사용할 수 있는 조건
- η(πi)=Mi(πi)
- η(π)≥Mi(π)
🔷 Monotonic improvement
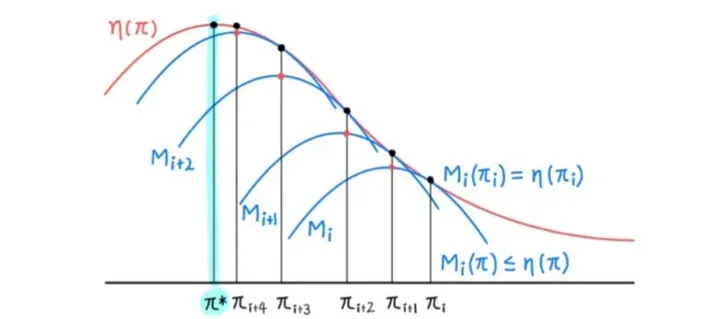
η(πi)=Mi(πi) and η(π)≥Mi(π)
⇒η(πi)=Mi(πi)≤Mi(πi+1)≤η(πi+1)for πi+1=argπmaxMi(π)
- True objective function η 가 monotonic하게 improve한다.
이제 앞서 살펴본 Minorization-Maximization algorithm으로 돌아가자.
7️⃣ Trust region

🔷 KL penalized objective
θmax[Lθold(θ)−CDKLmax(θold,θ)]
- Minorization-Maximization algorithm의 핵심은 surrogate object function을 maximize하는 policy를 찾는 것이었다.
- 위 식에서 CDKLmax(θold,θ)를 빼는 것은 penalty를 적용하는 것으로 해석할 수 있다.
- 이때 위 식을 KL penalized objective라고 한다.
🔷 KL penalized objective 변형
θmaxLθold(θ)subject toDKLmax(θold,θ)≤δ
- DKLmax(θold,θ)≤δ 를 KL constrained objective라고 한다.
- KL-발산 항으로 제약조건을 걸었다는 의미이다.
- MM-algorithm의 surogate object function을 위의 식으로 변형할 수 있다.
- 따라서 위 제약조건 하에서 Lθold(θ)의 maximize해주는 θ가 new policy이다.
🔻 변형 시 이점
- 기존의 식에서는 γ가 1에 가까워지면 상수 C의 값이 커져 step size의 크기를 줄여야 했다.
- KL penalized objective를 제약조건 식으로 변형할 경우 상수 C를 사용하는 대신, 제약조건의 범위를 δ로 조정할 수 있다.
- 이러한 방법을 Hard constraint라고 한다.
🔷 Constraint를 사용하는 것의 어려움
DKLmax(θold,θ)=smaxDKL(πold(⋅∣s)∣∣π(⋅∣s))≤δ
- 모든 state에 대해서 KL-발산 값이 δ보다 작아야 한다.
- State 값이 많기 때문에 많은 constraint가 있다.
- 따라서 이 조건을 만족하는 π를 찾는 것은 쉽지 않다.
- 특히 sample data만 사용하기 때문에 더 그렇다.
- 이러한 문제를 해결하기 위해 Heuristic approximation을 사용한다.
🔷 Heuristic approximation
🔸 기존 식
θmaxLθold(θ)subject toDKLmax(θold,θ)≤δ
🔸 Approximation 적용
θmaxLθold(θ)subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
- Max 함수 대신 Expectation 함수를 사용한다.
- 따라서 Expected KL divergence 를 사용한다.
- Expectation은 Monte carlo simulation에 따라 sample data를 통해 대체할 수 있다.
8️⃣ Monte Carlo simulation

🔷 Lθold(θ) 변형
🔸 변형 전
θmaxLθold(θ)subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
- Lπold(π)=η(πold)+∑sρπold(s)∑aπ(a∣s)Aπold(s,a)
- Lπold(π) 식을 변형할 수 있다.
🔸 변형 후
θmaxs∑ρθold(s)a∑πθ(a∣s)Aθold(s,a)subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
- 좌변의 식을 maximize하는 θ를 찾는 것이기 때문에 η(πold) 는 상수이다.
- 따라서 η(πold)는 제외한다.
- Constraint 식은 old policy에 대하여 expectation을 하는 것을 확인할 수 있다.
- Expectation은 sample data를 통해 구할 수 있다.
- Obeject function 부분은 변형이 조금 더 필요하다.
🔷 Object function 변형
θmaxs∑ρθold(s)a∑πθ(a∣s)Aθold(s,a)subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
🔻 1. Expectation 만들기
s∑ρθold(s)[…]by1−γ1Es∼ρθold[…]
s∈S∑ρπ(s)=t=0∑∞γts∈S∑P(St=s∣π)=t=0∑∞γt=1−γ1
- State visit frequency는 확률이 아니기 때문에 확률로 만들기 위해 1−γ 를 곱한다.
- 확률이 되었기 때문에 expectation으로 바꿀 수 있다.
🔻 2. Advantage function 변형
θmaxs∑ρθold(s)a∑πθ(a∣s)Aθold(s,a)subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
- 좌변의 Advantage function Aθold(s,a) 을 Q-value function Qθold로 바꿀 수 있다.
- State value function V(s)는 policy와 관계없기 때문에 상수 역할을 하기 때문이다.
- 물론 상수 차이에 따라 Maximun값은 바뀌지만, Maximize하는 θ는 바뀌지 않는다.
- Advantage function Aθold(s,a) 을 Q-value function Qθold로 바꾸는 것은 선택사항이다.
- TRPO에서는 Q-value function으로 바꾸지만, PPO에서는 바꾸지 않는다.
🔻 3. Expectation 만들기
a∑πθ(a∣s)Aθold(s,a)=Ea∼πθold[πθold(a∣s)πθ(a∣s)Aθold(s,a)]
- New policy에 대한 expectation을 취하면 sample data를 구할 수 없기 때문에 old policy로 expectation을 만들어야 한다.
- πθold(a∣s)πθ(a∣s): Importance sampling weight라고 한다.
🔸 Importance sampling weight
Ex∼p[f(x)]=Ex∼q[q(x)p(x)f(x)]≈N1n=1∑Nw(xn)f(xn) from xn∼q(x) where w(x)=q(x)p(x)
- Expectation을 구하고 싶지만 해당 확률분포가 다루기 어려울 경우 사용한다.
- 조금 더 다루기 쉬운 확률분포로 바꾼 후 Importance sampling weight를 곱한다.
- 다른 확률분포를 사용한 후 그 차이를 Importance sampling weight를 통해 보정한다.
🔷 Final optimization
θmaxEs∼ρθold,a∼πθold[πθold(a∣s)πθ(a∣s)Qθold(s,a)] subject to Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
-
앞에서 살펴봤던 3가지 변형을 적용한다.
-
Maximize하는 θ를 찾는 것이 목표이기 때문에 1−γ1 는 제거한다.
-
KL-Constraint 항은 동일한다.
-
최종적으로 Surrogate object function을 Constraint가 있는 object function으로 변형하였다.
-
Object function과 Constraint 식 모두 old policy에 대한 expectation이기 때문에 sample data를 수집하여 그 값을 구할 수 있다.
-
Q-value function Qθold은 Q-Network를 설계하여 구할 수 있다.
9️⃣ TRPO

🔷 Practical algorithm
θmaxEs∼ρθold,a∼πθold[πθold(a∣s)πθ(a∣s)Qθold(s,a)] subject to Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
🔻 Step 1 Sample data 수집하기
- Current policy를 사용하여 episode trajectory를 구한다.
- 해당 Sample data를 사용하여 Q-Network를 업데이트 할 수 있다.
- 그 후 업데이트한 Q-Network로 Q-value를 구할 수 있다.
🔻 Step 2 Expectation 값 구하기
- Sample data를 통해 Object function와 Constraint 식의 값을 구한다.
- 즉 Monte Carlo simulation을 통해 각각의 값을 구한다.
🔻 Step 3 Natural Policy Gradient
- Natural Policy Gradient를 사용하여 parameter θ를 업데이트 한다.
- Natural Policy Gradient는 Second order optimization이다.
- 이후 Conjugate gradient와 backtracking Line search 방식을 사용한다.
- 이에 대한 내용은 다음 수업 때 자세히 설명하도록 하겠다.
🔟 정리
🔷 28강에서 배운 내용은 아래와 같다.
- TRPO는 Conservative policy iteration update를 통해 lower bound를 만들었다.
- 다양한 approximation을 통해 KL Divergence constraint 식을 만들었다.
- Monte Carlo simulation을 적용하기 위해 old policy에 대한 expectation을 만들었다.
- Constraint 식을 만족하면 monotonic한 improve가 가능하다.
- Natural gradient policy를 통해 파라미터를 업데이트한다.
