👨🏫학습목표
오늘은 Dynamic programming의 방법 중 하나인 Value Interation에 대해 배워볼 예정이다.
👨🎓강의영상: https://www.youtube.com/watch?v=rC6xkxS_myY&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=8
1️⃣ Value Iteration
📕 지금까지 배운 내용 정리
우리는 Markov Decision Process의 문제를 해결하기 위해 Dynamic Programming을 사용할 수 있다. 이를 통해 Optimal policy 를 구할 수 있는데, 이때 Model-based라는 조건이 만족해야 한다. 즉 모델의 state transition probability와 reward에 대해 알아야 한다. Dynamic programming의 대표적인 방법이 Value Interation과 Policy Iteration이다.

🔷 Value Iteration
- Bellman Optimality Equation을 사용한다.
- Optimal state-value function 을 찾는 것이 핵심이다.
- 모든 state에서 위 식이 성립해야 한다.
- 그런데 모든 state에 대해 이 문제를 푸는 것이 너무 복잡하기 때문에, 근사치 를 사용한다.
- k번째까지 업데이트된 식.
- 계속 업데이트하면서 이 로 converge시킨다.
- 로 converge가 완료되면 위 수식을 이용하여 Optimal Policy를 구한다.
🔷 Backup 방법
🔻 Synchronous backups
- 모든 의 값을 구한 후 값으로 state value function을 업데이트한다.
🔻 Asynchronous backups
- 각 의 값을 구할 때마다 값을 업데이트한다.
🔷 Value Iteration의 한계
- Optimal value state function에 도달하기 전에, 각 state의 action이 어느 정도 고정된다. 따라서 Optimal policy를 구하는 과정 자체가 필요 이상의 연산을 수행하는 것이다.
- 연산량이 많다.
2️⃣ DP를 이용한 Value Iteration
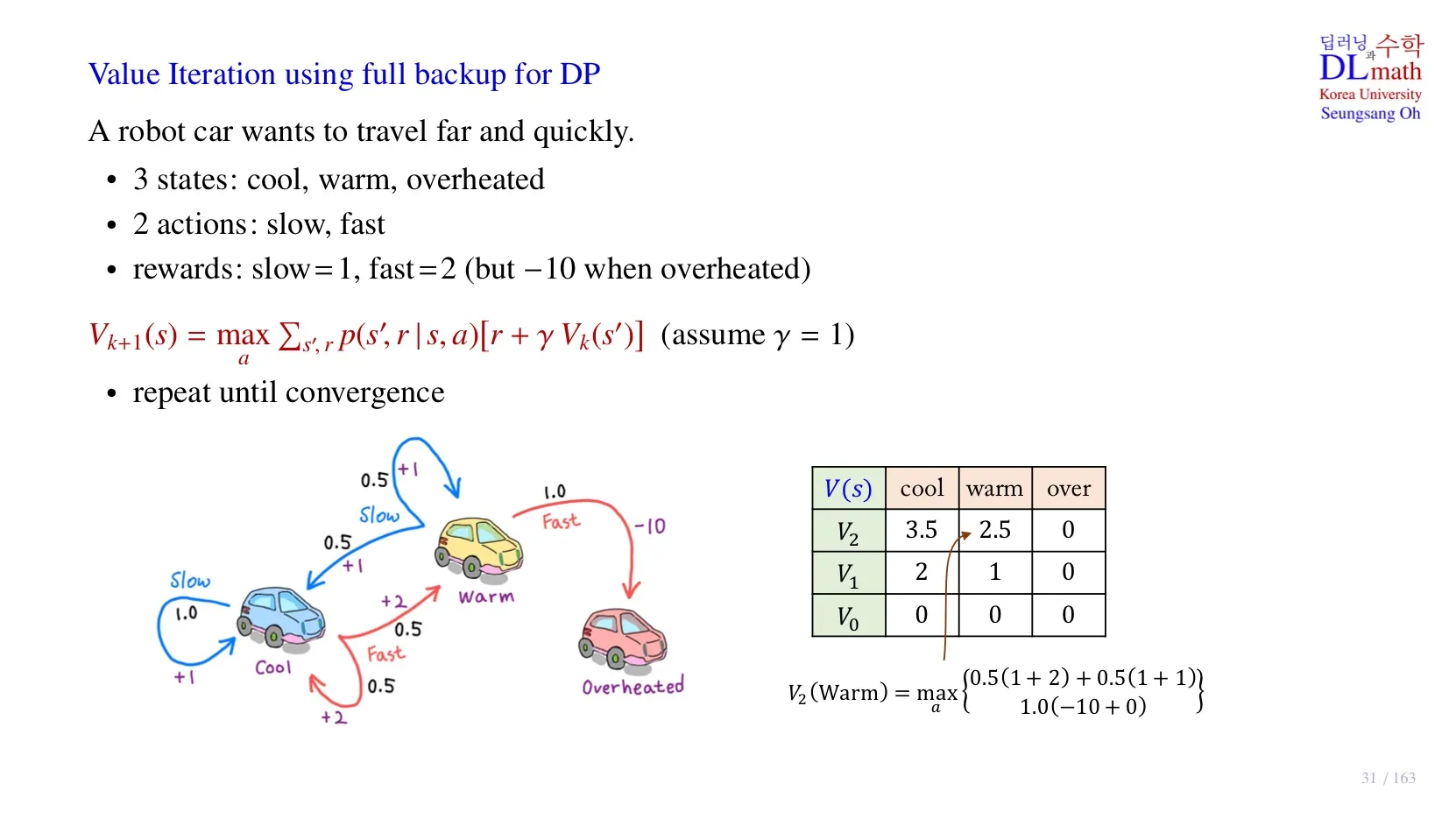
📌 기본 전제
- 로봇 자동차가 더 멀리 그리고 빨리 이동할 수 있도록 학습하는 것이 목적이다.
- State: 자동차 엔진의 상태, overheated는 엔진이 과열되서 이동할 수 없다.
- Action: slow, fast
- Model-based: state transition probability를 알고 있다.
🔷 Optimal state value function 구하기
- 시작 value function , 실제로는 random number를 사용해도 된다.
- Overheated는 자동차가 과열되서 사실상 움직일 수 없는 상태이다.
- 실제로 강화학습을 진행할 때도 학습의 종료지점인 terminal state의 value function은 0으로 고정하면 된다.
- 위 식에 따라 를 구하면 아래와 같다.
- 위 식에 따라 를 구하면 아래와 같다.
- 이러한 과정을 반복해서 특정값에 Converge하면 그 값을 로 한다.
3️⃣ Value Iteration의 pseudo code

Pseudo code란?
컴퓨터 프로그래밍의 동작이나 알고리즘을 인간이 사용하는 언어로 작성한 것이다. 프로그래밍 언어와 달리 정해진 문법이 존재하지 않는다.
4️⃣ Value Iteration in Grid World
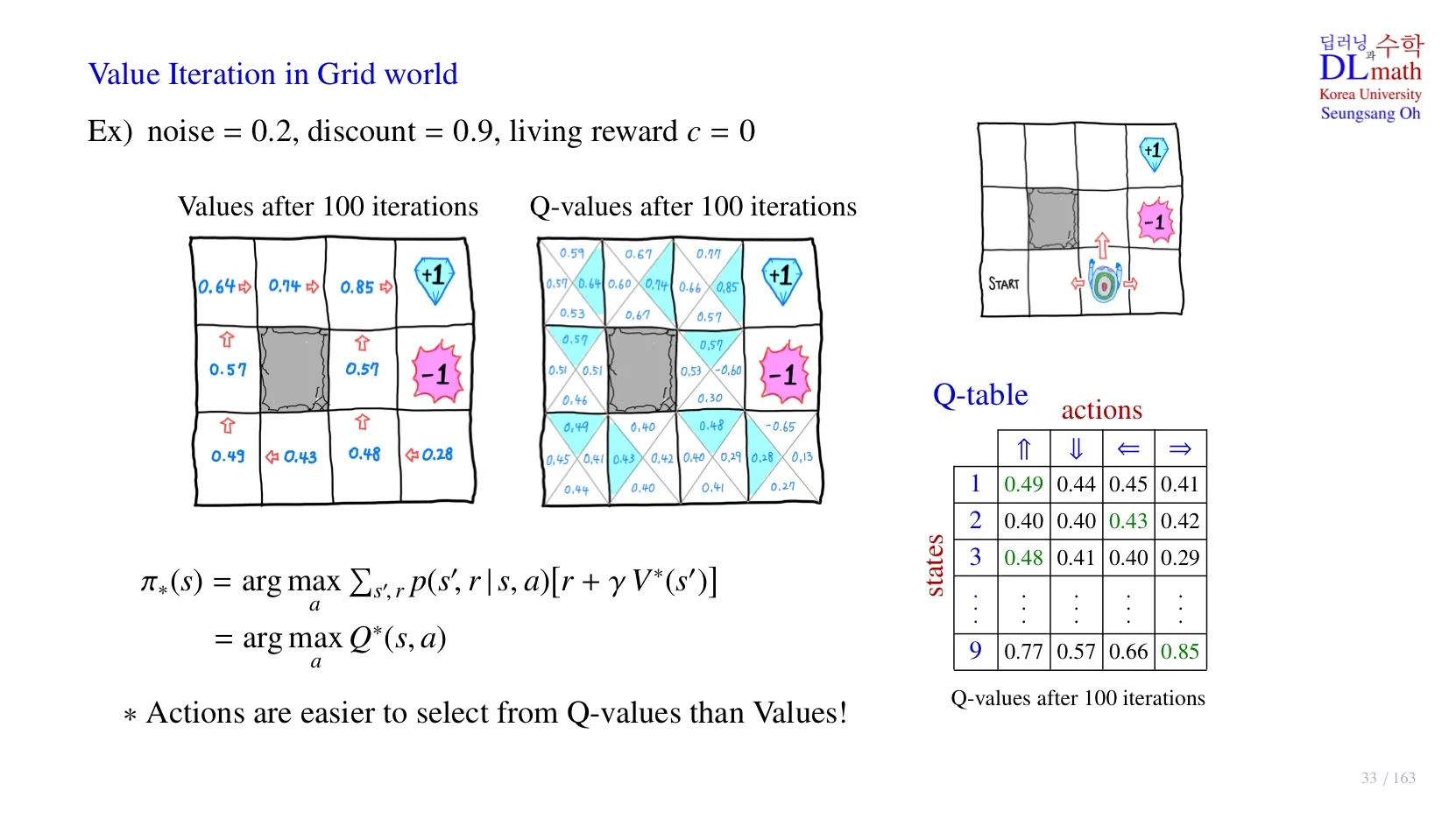
📌 기본 전제
- noise = 0.2이면, 예를 들어 north로 action을 취할 때, east나 west로 이동할 확률이 각각 0.1씩 존재한다.
- living reward c = 0, small negative reward = 0이다.
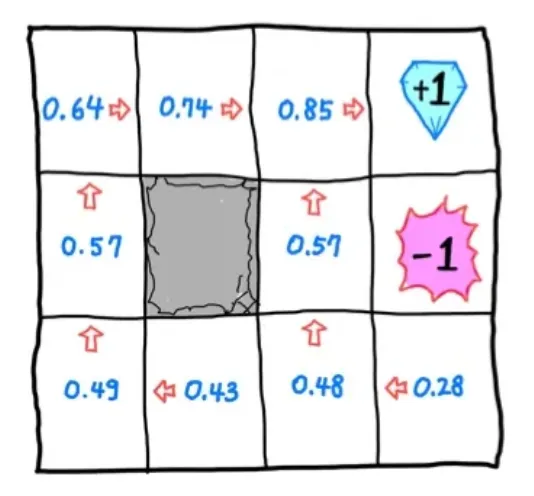
state에서 , 즉 를 의미한다.
각 state에서 해당 방향으로 action을 취했을 때 얻게 될 , 즉 를 의미한다.

- 수식을 통해 Optimal policy를 구하기 위해서 optimal state-value function나 optimal action-value function을 알아야 한다.
🔻 Optimal state value function
- optimal state-value function을 통해 Optimal policy를 구할 수 있다.
- transition probability 를 알아야 한다는 한계가 존재한다.
- 연산량이 복잡하다.
🔻 Optimal state value function
- optimal action-value function을 알면 연산이 훨씬 간단하다.
- transition probability 없이 연산이 가능하여 Reinforcement Learning에서 사용된다.
- 하지만 optimal action-value function을 알기 위해서는 각 state의 action value를 모두 알아야 한다는 단점이 존재한다.
5️⃣ 정리
🔷 8강에서 배운 내용은 아래와 같다.
- Value Interation에 대해 배웠다.
- Dynamic prgramming을 이용하여 Value Interation을 적용해보았다.
- Pseudo code로 Value Interation을 표현해보았다.
- Grid world에 Value Iteration을 적용해보았다.

I'm curious about AI