이 페이지는 Deep Learning의 발전에 큰 영향을 준 AlexNet(2012)에 대한 내용입니다.
1. AlexNet의 특징
AlexNet은 2012년에 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 에서 우승을 차지한 아키텍처입니다.
이전의 모델인 LeNet-5에 여러가지 변화를 주어 대용량 데이터셋을 빠르게 학습시키고, overfitting은 방지하는 효과를 얻었습니다.
변화들은 다음과 같습니다.
- GPU를 사용해 병렬처리
- 큰 학습역량(a large learning capacity) 아키텍처
- fc layer에서 drop out 사용하여 overfitting 방지
2. 변화
2.1 GPU 병렬처리
LeNet5과 달리 AlexNet은 GPU를 사용해 병렬 처리를 진행한 점이 특징입니다. 다음 그림은 AlexNet을 이용해 각 GPU에서 학습된 필터맵입니다.

GPU 1에서는 비교적 색과 관련 없는 부분, GPU 2에선 색상과 관련된 정보를 독립적으로 학습중입니다. 이 다음 부분에 나오는 AlexNet의 아키텍처 이미지를 보시면 확인할 수 있습니다.
2.2 모델 구조 변화
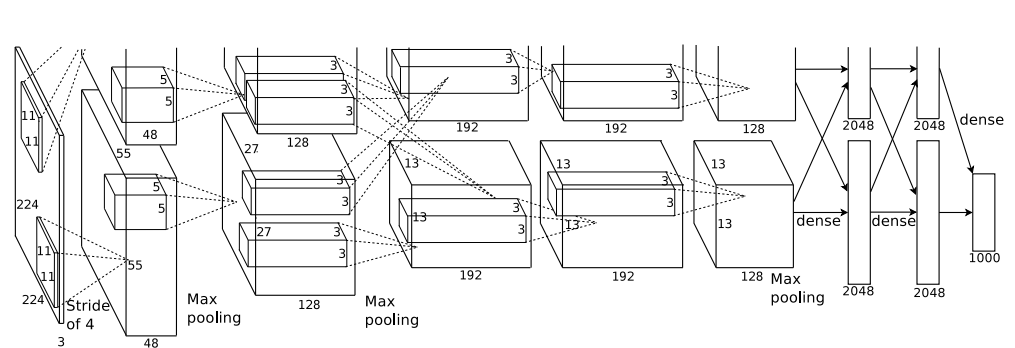
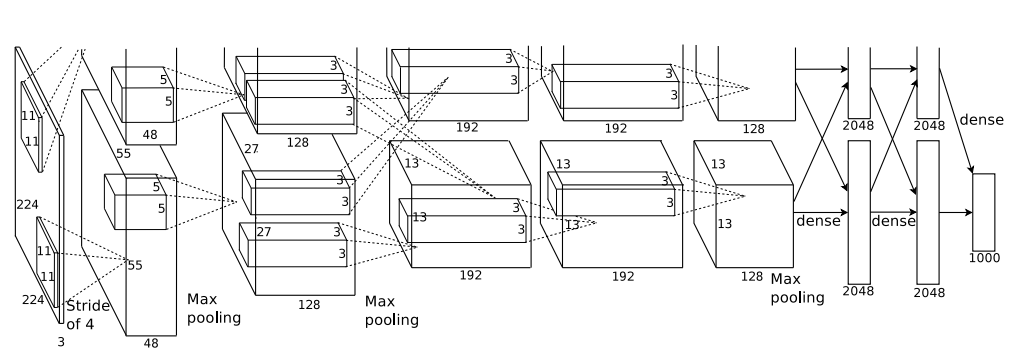
다음 사진은 AlexNet의 아키텍처입니다.
AlexNet은 기본적으로 5개의 CNN, 3개의 FC layer가 연결된 모델입니다. 활성화함수는 ReLU, pooling은 MaxPooling을 사용하였습니다.
ReLU 사용
이전까지는 tanh 함수를 사용했는데요, AlexNet은 ReLU함수를 사용했습니다.
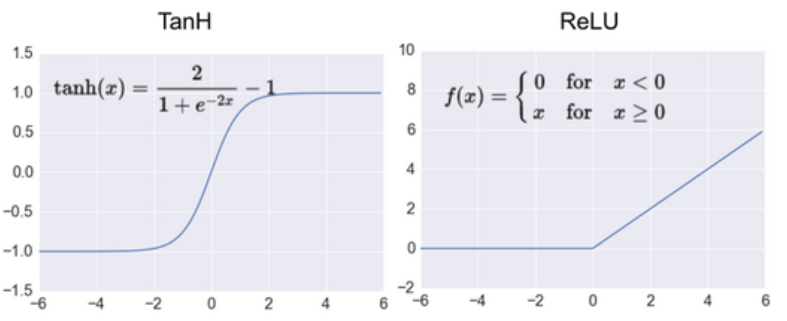
tanh 함수가 saturating function이기 때문에 non saturating한 ReLU보다 훨씬 느리다는 것이 논문의 주장입니다
Local Responce Normalization(LRN) 사용
LRN은 학습 과정에서 지역적인 현상을 약화하고, 좀 더 학습을 generalization(일반화) 하기 위해 고안되었습니다.
ReLU만으로도 충분한 학습이 되기도 하고 정규화가 필요 하지 않지만 추가적인 성능 향상을 위한 방법이 필요합니다.
local normalization을 통해 generalization을 더욱 더 확실히 할 수 있게 하였습니다.
Overlapping Pooling 사용
마지막으로 Pooling을 'Overlap(중첩)' 하여 사용한 것이 특징인데요, 기존과 어떻게 다른지 한 번 살펴보겠습니다.
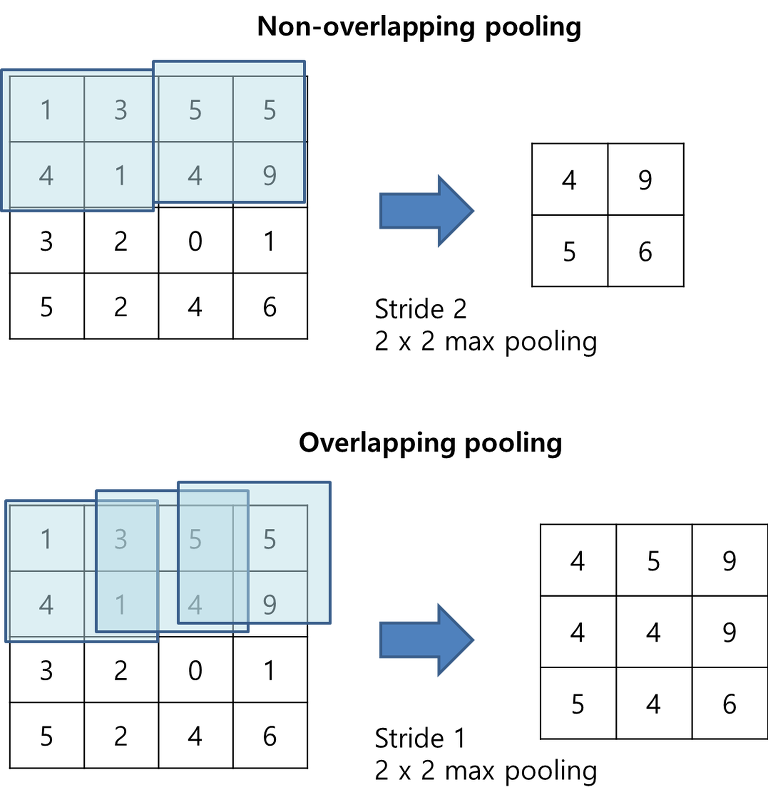
기존에는 위 그림의 상단처럼 Overlap 하지 않은 pooling을 사용했습니다.
하지만 본 논문에서는 stride를 조절하여 Overlappling pooling을 사용했습니다.
이는 기존의 방법보다 약간 더 overfitting의 해결에 효과적이라는 점을 error rates를 통해 제시합니다.
2.3 Drop out 사용
학습을 하면서 특정 feature에 대해서 과한 학습이 이루어져 다른 feature에 대해 제대로 학습 되지 못하는 경우가 발생합니다.
이러한 경우 overfitting으로 이어질 수 있습니다.
이를 방지하기 위해 무작위로 특정 feature를 비활성화 시켜 다른 feature들에 대해서 잘 학습 되도록 합니다.
본 논문에서는 Dropout 비율을 0.5로 하여 처음 두개의 FC Layer에 적용했습니다.
모델 구현
구조 특징
- Max pooling layer는 첫 번째 레이어와 두 번째 레이어 뒤에 적용되며 또한 다섯 번째 레이어 뒤에도 적용한다.
- ReLU 함수는 모든 Convolution Layer 뒤와 FC Layer 뒤에 온다.
최종 구조
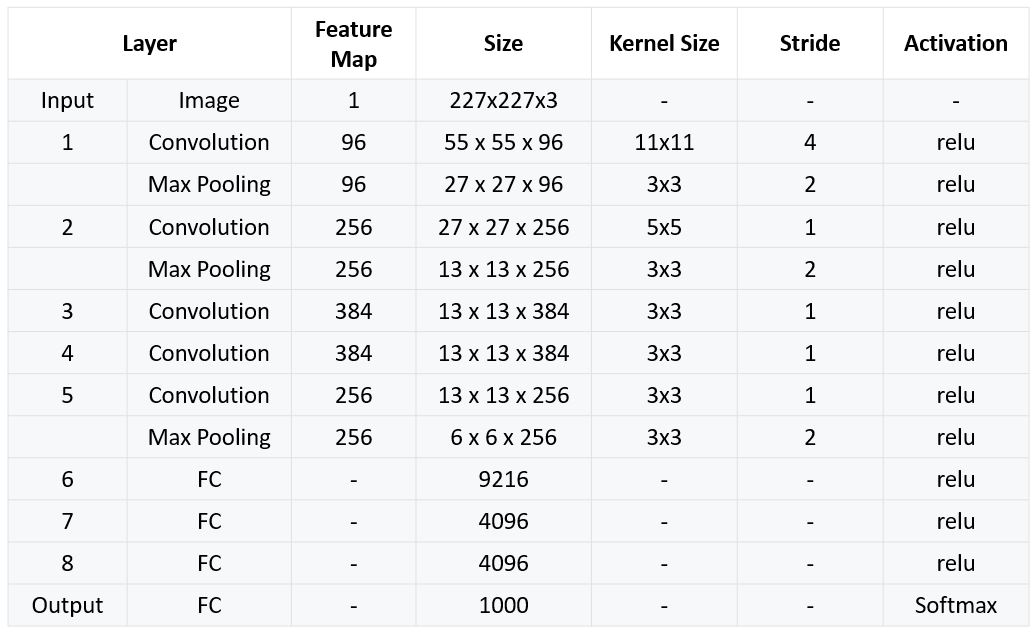
구현
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# input (227, 227, 3)
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
# input (55, 55, 96)
nn.MaxPool2d(kernel_size=3, stride=2),
)
# input (27, 27, 96)
self.layer2 = nn.Sequential(
nn.Conv2d(96, 256, 5, 1, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
# input (27, 27, 256)
nn.MaxPool2d(3, 2),
)
self.layer3 = nn.Sequential(
# input (13, 13, 256)
nn.Conv2d(256, 384, 3, 1, padding=1),
nn.ReLU(inplace=True),
)
self.layer4 = nn.Sequential(
# input(13, 13, 384)
nn.Conv2d(384, 256, 3, 1, padding=1),
nn.ReLU(inplace=True),
)
self.layer5 = nn.Sequential(
# input(13, 13, 256)
nn.Conv2d(256, 256, 3, 1, padding=1),
nn.ReLU(inplace=True),
# input(13, 13, 256)
nn.MaxPool2d(3, 2),
)
self.FClayer1 = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
)
self.FClayer2 = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
)
self.FClayer3 = nn.Sequential(
nn.Linear(4096, 1000),
)
def forward(self, x):
layer1 = self.layer1(x)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer5 = self.layer5(layer4)
pool = layer5.view(layer5.size(0), -1)
FClayer1 = self.FClayer1(pool)
FClayer2 = self.FClayer2(FClayer1)
output = self.FClayer3(FClayer2)
return output

비밀 댓글입니다.