본 페이지는 layer를 깊게 쌓을 수 있게 영향을 준 ResNet(2015)에 대한 내용입니다.
1. ResNet 특징
깊어지는 layer와 함께 떠오르는 의문은 "과연 더 많은 레이어를 쌓는 것만큼 network의 성능은 좋아질까?" 입니다.
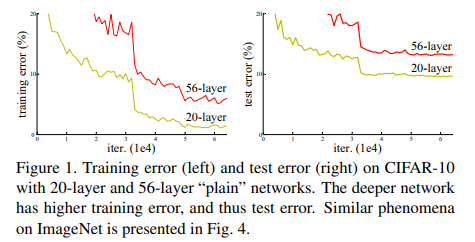
Fig1을 참고하면 56-layer가 20-layer보다 train error, test error 둘 다 낮음을 알 수 있습니다.
이 논문에서 깊게 다룰 문제는 Degradation Problem입니다. network가 깊어질수록 accuracy가 떨어지는 (성능이 저하되는) 문제입니다.
이 문제는 overfitting의 문제가 아니기 때문에 주목받습니다(오버피팅이면 깊은 layer의 train accuracy는 높고 test accuracy는 낮아야 하는데 이건 둘 다 낮습니다).
그래서 이 논문에서는 Deep residual learing framework 라는 개념을 도입합니다.
2. Residual Block
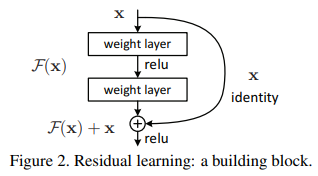
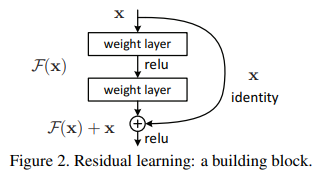
x 는 input인데 Model 인 F(x)라는 일련의 과정을 거치면서 자신(identity)인 x가 더해져서 output으로 F(x) + x 가 나오는 구조입니다.
이때 만약 x가 최적값을 찾은 상태라면. 즉, 목표 결과값 H(x)와 x 가 같은 상황이라면 H(x)= F(x)+x 식에서 F(x)를 0으로 향하도록 학습 하면 됩니다.
이러한 구조를 통해 Gradients Vanishing/Exploding 문제를 해결할 수 있었고 이에 따라 더 깊게 쌓으면서 지속적인 성능 향상을 확인할 수 있습니다.
3. 구조(Plain Network , Residual Network)
그림과 같이 살펴보겠습니다. 그림에서는 VGG net, Plain net, Residual net 을 비교하고 있습니다.

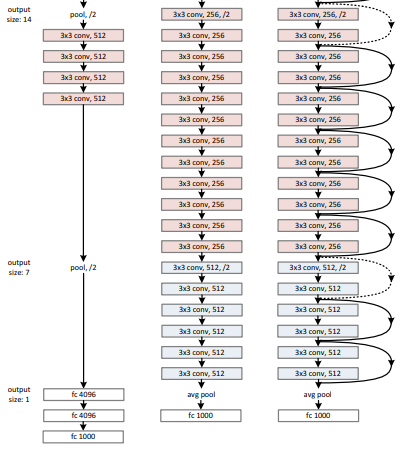
Plain Net
구조는 주로 VGGNet의 영향을 받았습니다.
Conv 연산의 Kernel size는 거의 3x3을 사용하였고 Down sampling 연산은 stride = 2를 설정하였습니다.
Residual Network
위에서 만든 Plain net을 기본 바탕으로 하지만 여기에 shortcut connection 개념을 도입합니다.
즉 input 과 output, x와 F 를 모두 같은 차원으로 만들어주는 것이 추가된 과정입니다.
'Shortcut Connection이란 같은 차원으로 나오는 것'
Shortcut connection의 결과와 기존 layer의 결과를 pixel별로 더하는 연산을 진행합니다.
성능 비교
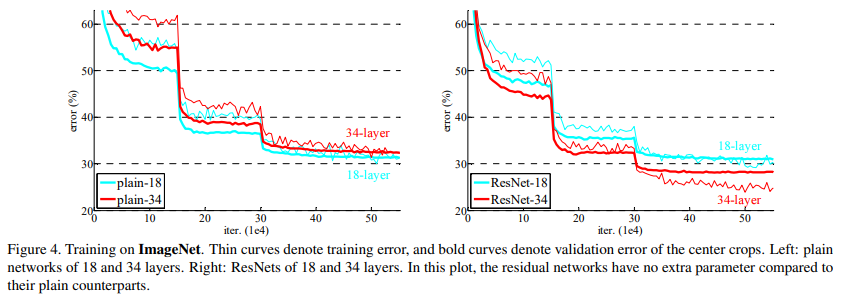
위의 이미지는 PlainNet과 ResNet 각각의 깊이별 training error를 그래프화 한 것입니다.
PlainNet은 깊이가 깊어지면서 train error가 높아지는 것을 확인할 수 있지만 ResNet은 깊이가 깊어져도 지속적인 성능 향상이 보입니다.
3. 상세구조
상세구조

상세 구조를 보시면 50, 101, 152-layer에반 BottleNeck 구조가 있는 걸 확인할 수 있습니다.
이때 bottleneck block에서 1x1 conv의 역할은 차원을 줄이고 늘리는 역할을 합니다.
파라미터
-
image resized 224 * 224
-
Batch normalization BN 사용
-
Initialize Weights
-
SGD, mini batch 256
-
Learning rate 0.1
-
Iteration 60 * 10^4
-
weight decay 0.0001, momentum 0.9
-
No dropout
4. 코드 구현
import torch.nn as nn
from torchsummary import summary
class BottleNeck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
self.relu = nn.ReLU()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
x = self.residual_function(x) + self.shortcut(x)
output = self.relu(x)
return output
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=1000):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.conv2_x(output)
x = self.conv3_x(output)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
output = self.fc(x)
return output
model = ResNet(BottleNeck, [3,4,6,3])
summary(model.cuda(), (3,224,224))