Vision Transformer(2021) 논문 리뷰
이 페이지는 NLP분야에만 적용되던 transformer를 Computer Vision에 적용한Vision Transformer(ViT, 2021)에 관한 내용입니다.
1. Introduction
트랜스포머(Transformer) 구조는 등장 이래로 사실상 자연어 처리 분야의 표준으로 자리잡았는데, 컴퓨터 비전 분야에서 트랜스포머 아키텍쳐의 적용은 한정적이였습니다.
비전 분야에서, 어텐션(attention)은 컨볼루션 네트워크(CNNs)와 함께 적용되거나, 컨볼루션 네트워크의 전체적 구조는 유지하면서 특정 컴포넌츠만을 대체하는 데 사용되었습니다.
본 논문에서는 이러한 컨볼루션 네트워크 의존이 필수가 아니며, pure transformer를 image patches의 시퀀스에 다이렉트하게 적용하는 것이 이미지 분류 태스크에서 상당히 좋은 성능을 낸다는 것을 입증합니다.
Transformer는 데이터가 적은 경우에는 ResNet보다 성능이 떨어지는 특징을 보였지만 데이터가 충분한 경우에는 ResNet보다 성능이 높은 결과를 보입니다.
2. Vision Transformer(ViT) Method
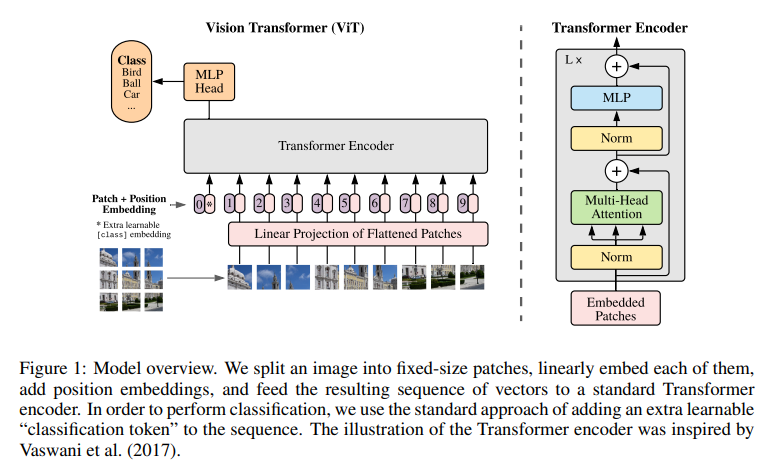
작동 과정을 요약해보자면 다음과 같습니다.
-
ViT 모델은 입력 이미지를 패치 단위로 자릅니다. 논문에서 제시한 그림에서는 패치를 9개로 자른 것을 확인할 수 있습니다.
-
위치 정보를 포함하도록 Positional Embedding을 더해줍니다.
-
Class 정보를 포함하는 [CLS] 토큰을 제일 첫부분(0번)에 추가합니다. (CLS token은 Learnable)
-
Patch를 Flatten하는 Linear Projection을 진행합니다.
-
Flattened patch를 Transformer encoder의 input으로 넣습니다.
-
Transformer encoder를 거쳐 나오는 [CLS] 토큰의 값을 MLP Head에 넣어서 Class를 예측합니다.
2.1 Embedding for Transformer
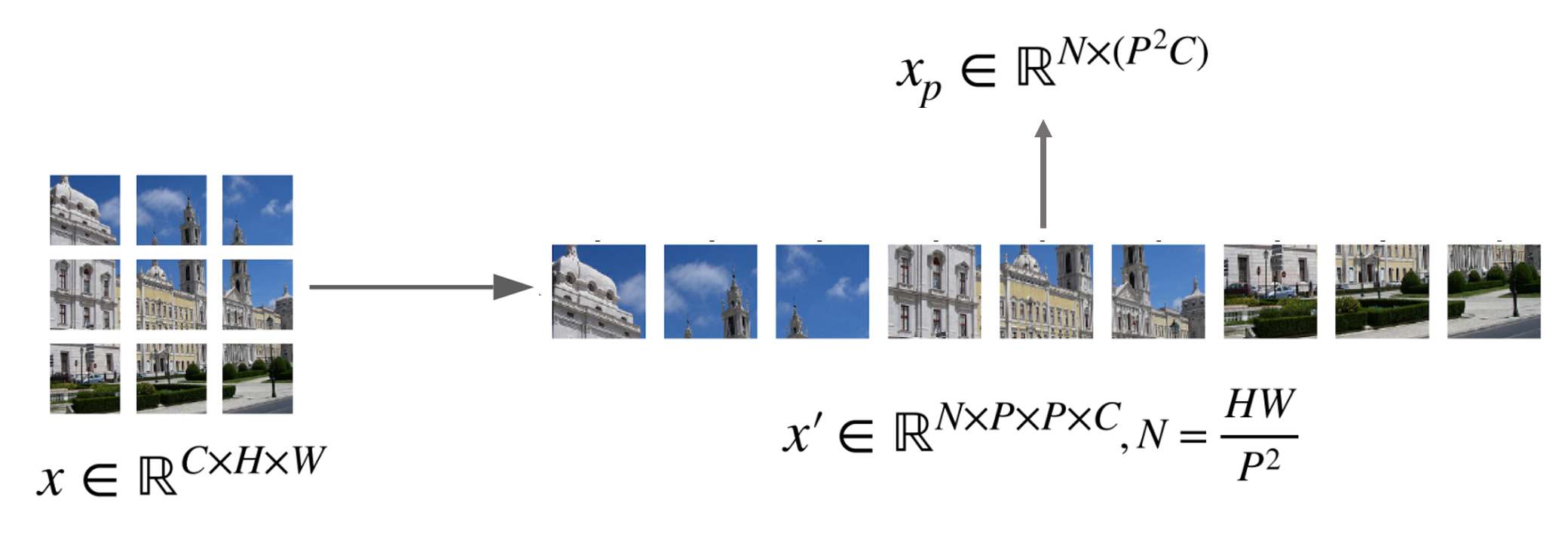
이미지는 2D이기 때문에 2D이미지를 1차원으로 변환하기 위한 작업(Patch Embedding)을 합니다.
여기서 (H,W)는 원본 이미지의 해상도(resolution), C는 채널의 수, (P,P)는 각 이미지 패치의 해상도,
는 최종 패치의 수로, 아래 사진과 같이 트랜스포머의 효과적인 입력 시퀀스 길이가 됩니다.
그 이후에는 앞에서 생성한 를 Embedding 하기 위하여 행렬 E와 연산을 합니다.
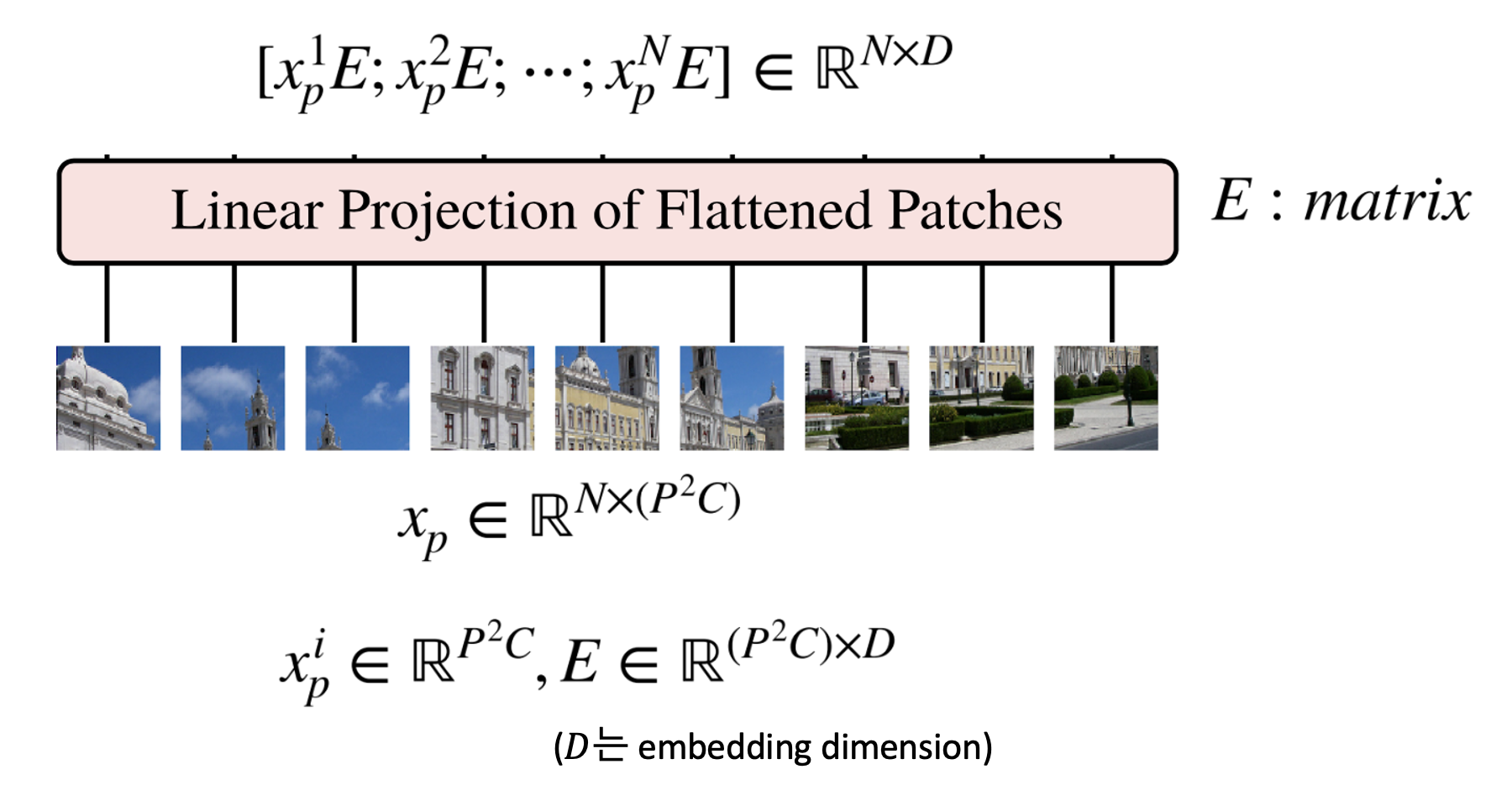
E의 shape은 가 된다. 는 embedding dimension으로 크기의 벡터를 D로 변경하겠다는 의미입니다.
따라서, 의 shape은 , 의 shape은 으로 곱 연산을 하면 (N,D)의 크기를 가지게 됩니다.
배치 사이즈까지 고려하면 의 크기를 가지는 텐서가 됩니다.
추가적으로 자연어 처리 분야에서 BERT라는 모델에서 사용되는 [Class] 토큰과 비슷하게 Input Embedding 맨 앞에 [Class] Patch를 넣어 줍니다.
2.2 Positional Embedding

Embedding한 결과에 클래스 토큰을 위 그림과 같이 추가합니다. 그러면 크기의 행렬이 크기가 됩니다.
클래스 토큰은 학습 가능한 파라미터를 입력해 주어야 합니다.
마지막으로 Positional Encoding을 추가하기 위하여
크기의 행렬을 더해주면 입력 값 준비가 마무리 됩니다.
2.3 Transformer Encoder
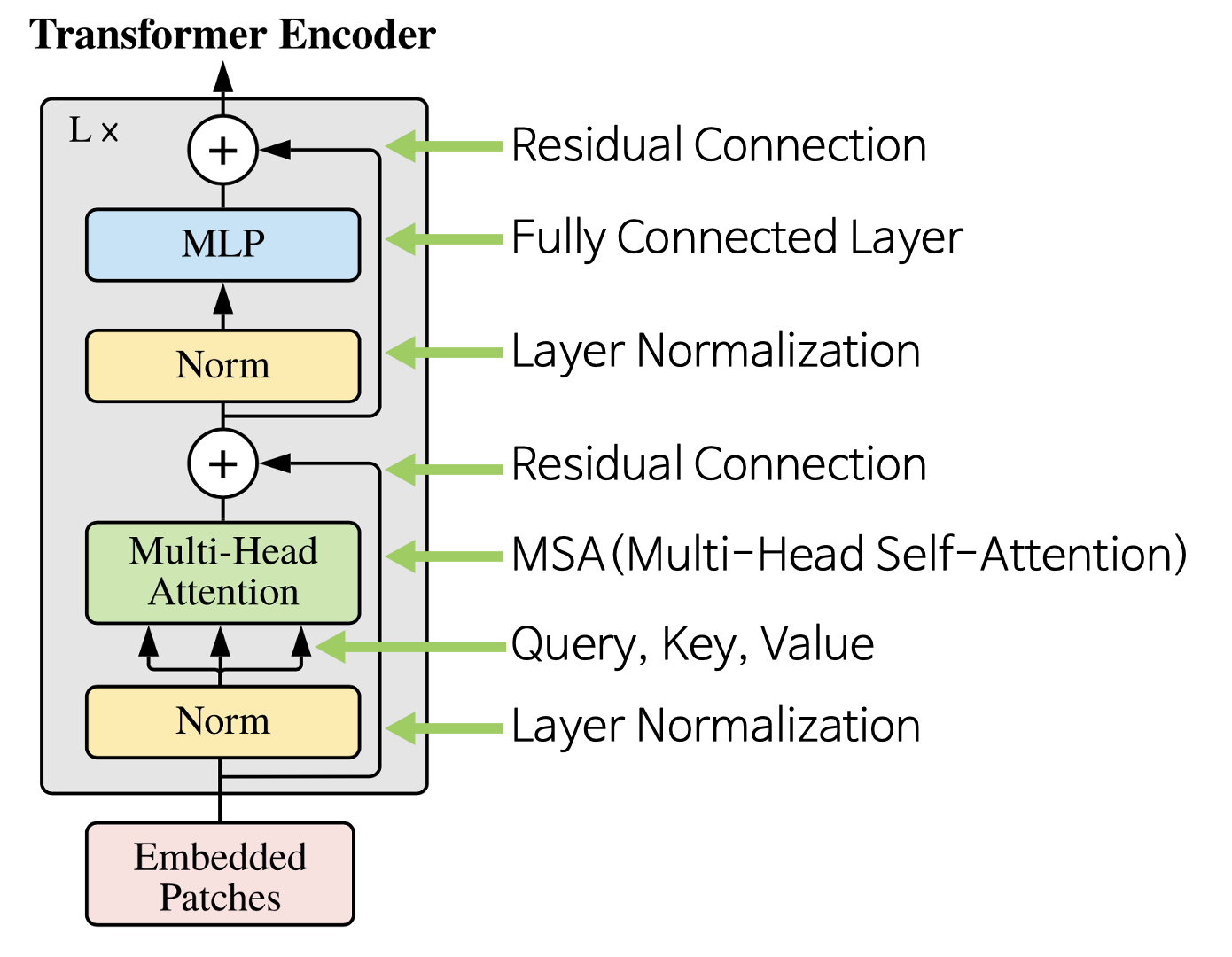
-
Transformer의 Encoder는 L번 반복하기 위해 입력과 출력의 크기가 같도록 유지한다.
-
Vision Transformer에서 사용된 아키텍쳐는 기존의 Transformer Encoder와 조금 다르지만 큰 맥락은 유지한다.
-
기존의 Transformer Encoder에서는 MSA를 먼저 진행한 다음 LayerNorm을 진행하지만 ViT에서는 순서가 바뀌어 있는 것을 알 수 있다.
-
입력값 에서 시작하여 번 반복 시 이 최종 Encoder의 출력이 된다.
이 구조를 전부 종합해보면 다음과 같은 수식이 나옵니다
2.3 inductive bias
Inductive Bias는 학습에 사용되지 않은 데이터에 대해서 어떤 것에 대해 예측할 때 정확한 예측을 위해 사용하는 추가적인 가정입니다.
Transformer에서 대표적으로 제시한 Translation Equivariance와 Locality는 다음과 같습니다.
-
Translation Equivariance : Computer Vision에서 어떠한 객체를 검출하고자 할 때 해당 객체의 위치가 달라져도 동일하게 검출할 수 있도록 하는 것이다.
-
Locality : 말 그대로 지역성이라는 개념으로 이미지 내에서 정보는 특정 지역에 담겨져 있으며 이 지역적인 특징을 담기 위해서 CNN에서는 여러 크기의 필터를 통해 지역적인 정보를 담는다.

위의 그림에서과 같이 고양이의 위치가 변하여도 Classification에서는 똑같이 고양이라고 분류해야합니다.
이를 "translation invariance" 라고 합니다.
그렇다면 ViT에서는 위와 같은 Inductive Bias가 왜 부족하다고 하는 것일까요?
우선 CNN의 필터가 Sliding Window처럼 이미지의 모든 영역을 스캔하는 방식과 비슷하게 작동하는 것과는 다르게
ViT는 이미지를 패치로 나누어 작동하며 MLP는 한 패치 내부에서만 Fully Connected형식으로 작동하기 때문입니다.
2.4 Hybrid Architecture
Image Patch의 대안으로, CNN의 Feature Map의 Sequence를 사용할 수 있다는 의미입니다.
-
CNN의 Feature는 Spatial scale가 1x1이 될 수 있음
-
CNN으로 Feature추출 → Flatten → Eq.1의 Embedding Projection () 적용
3. Experiments
3.1 모델 비교
비교 대상
-
BiT
-
Noisy Student - Semi-Supervised Learning을 적용한 Large EfficientNet
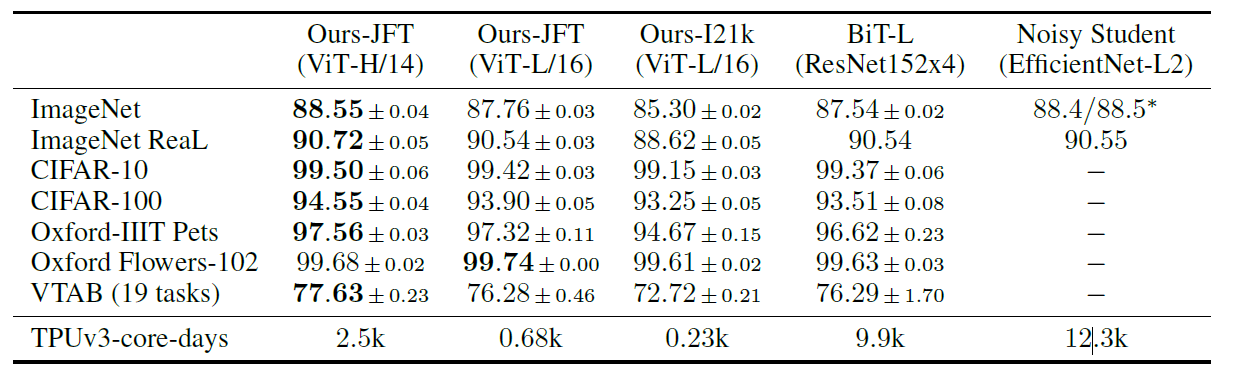
비교 결과
- JFT로 사전 학습 후, 각 데이터 셋에 Transfer Learning 진행
-
사전학습 시 데이터 셋이 클수록 ViT 좋음
-
사전학습시 데이터 셋이 작으면 좋지 않음
3.2 Scaling Study
Transformer, Hybrid, BiT의 모델 크기 실험 → Transfer Learnig 실험
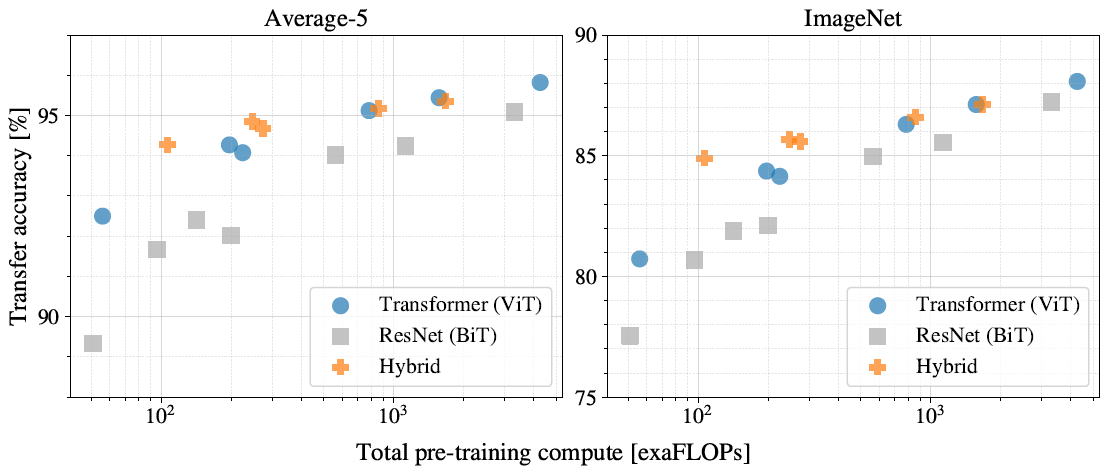
- ViT의 성능이 아직 포화(Saturate) 되지 않음 → 성능이 더 좋아질 수 있음
3.3 Self-Supervision
NLP Task에서 수행되는 Self-supervision 학습 방법을 시도
- 예를 들어, BERT는 Input을 Masking후, Masking 한 단어를 올바르게 예측하도록 학습(Self-Supervised Learning)
Vision Self-Supervision 결과
-
ViT-B/16 모델은 79.9 % 정확도를 보여 우수함
-
Supervied Learning 방식보다는 낮음
