학습내용
Up-sampling
원본의 sparse한 데이터를 만드는 것
- unpooling
- Nearest Neighbor : 데이터를 그대로 늘려서, 빈 구역에 채워넣는 것
- Bed of Nails : 빈 구역을 0으로 채워넣는 방법
- MaxUnpooling : 어느 position이 pool된 것인지를 알아두고, Bed of Nails 시에 해당 위치로 데이터를 위치시키는 방법
- Transpose convolution
- convolution matrix 생성 : zero padding을 포함해 재배치한 kernel matrix, 크기는 input matrix에 맞춤
- input matrix를 column vector로 flatten
- convolution matrix X input matrix = output
- 위의 식을 살펴보면, output과 convolution matrix를 알고있다고면 input matrix를 구할 수 있게됨.
- Transpose convolution X output = input
Object Detection
Multiple objects에서 각각의 object에 대해 Classification + Localization을 수행하는 것
-
RCNN
-
입력 이미지에 selectiva search 알고리즘을 적용하여 물체가 있을만한 박스 2천개를 추출
-
모든 박스를 227X227 크기로 resize
-
이미지넷 데이터를 통해 학습시켜놓은 CNN을 통과시켜 4096차원의 특징 벡터를 추출
-
추출된 벡터를 클래스마다 학습시켜놓은 SVM classifier를 통과
-
가장 물체를 잘 표현하는 박스찾기(Non-Maximum Supperssion)
-
바운딩 박스 리그레션을 적용하여 박스의 위치 조정
-
-
단점 : 학습이 여러 단계로 진행되어 많은 시간과 GPU 계산 용량이 요구됨.
-
Fast RCNN
RCNN의 단점을 해결한 모델이라고 볼 수 있음.
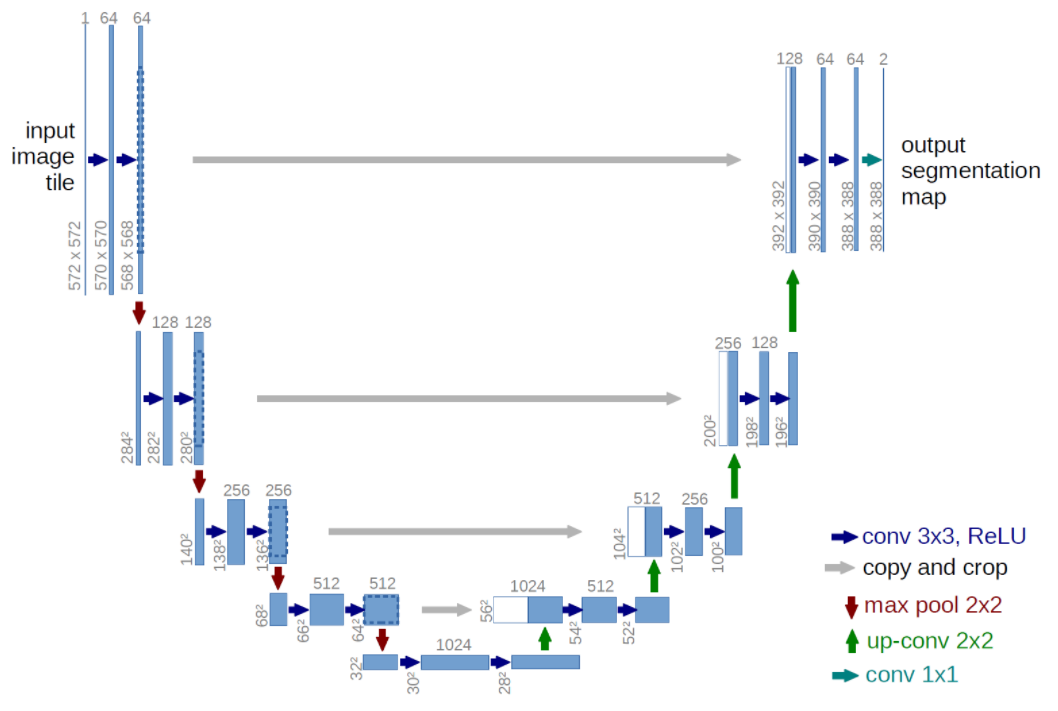
Image Segmentation
Object Detection과 유사하지만, 다른점은 object의 위치를 bounding box가 아닌 실제 edge로 찾는 것
- U net
Data Augmentation
형태와 모양 등을 변형하여 데이터를 증강시키는 방법
