지난 시간의 How Models Work에 이어 공부해보도록 합시다.
근데 사실 이번 단원에서는 별 내용이 없긴 함
2. Basic Data Exploration
Using Pandas to Get Familiar With Your Data
import pandas as pd
melbourne_file_path='대충 파일 위치'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.describe()describe() 함수를 쓰면 각 컬럼들에 대해 다음 정보(count, mean, std, min, 25%, 50%, 75%, max)를 한 눈에 확인 할 수 있다.
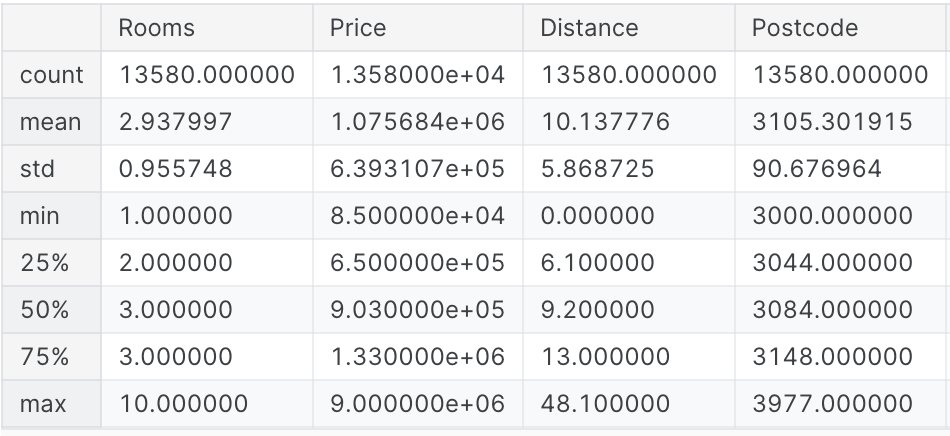
Interpreting Data Description
std: 표준 편차(Standard Deviation)mean: 평균값count: 데이터의 개수

Learning like Machine