이번에는 처음으로 머신러닝에 대한 모델 코드 작성을 배우는 시간임
학습 내용 다루기 전에 쓸 말이 없네
스마클 캐글 스터디 화이팅
Selecting Data for Modeling
Dataset에 변수가 너무 많아서 감당하기 힘들어요. 어떻게 보기 편하게 압축할 수 있나요?
먼저 직관적으로 몇 가지 변수를 선택하는 것부터 시작한다.
variables/columns를 선택하려면, Dataset의 모든 column 목록을 확인해야 한다.
이는 DataFrame의 columns를 사용하여 수행됨
import pandas as pd
melbourne_file_path = '대충 파일 경로'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns

이 Dataset에서는 결측값이 있다.
dropna() 는 결측값을 삭제, axis=0은 행을 지우고 axis=1은 열을 지움
melbourne_data = melbourne_data.dropna(axis=0)데이터의 하위 집합을 선택하는 방법에는 여러가지가 있다.
1. Dot notation : "Prediction Target(예측 타켓)" 을 선택하는 데 사용
2. Column list 로 선택하기 : Features 을 선택하는 데 사용
Selecting The Prediction Target
Dot notation으로 변수를 가져올 수 있다. 단일 열은 열이 하나만 있는 데이터프레임과 같은 '시리즈'로 저장된다.
Dot notation으로 예측할 열을 선택하는데, 이를 Prediction Target 이라고 한다.
규칙에 따라 예측 대상을 y 라고 한다.
다음은 집값(Price) 을 저장하는 코드
y = melbourne_data.PriceChoosing "Features"
모델에 입력되는 (나중에 사용되는) 열을 "Features" 라고 한다.
주택 가격을 결정하는 데 사용되는 열이 여기에 해당한다.
때에 따라 대상을 제외한 모든 열 이 Features 로 사용될 수 있음
(적은 수의 Features가 나을 떄도 있다.)
괄호 안에 Column name list를 제공하여 여러 기능을 선택
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Latitude', 'Longtitude']관례상 이 데이터를 X로 지정
X = melbourne_data[melbourne_features]이제 대충 데이터의 전체적인 모습을 확인해보자! 캐글 왈 데이터 사이언티스트의 중요한 덕목은 데이터를 훑어보는 것부터라고 한다... 자의적 해석이 들어감
X.describe()
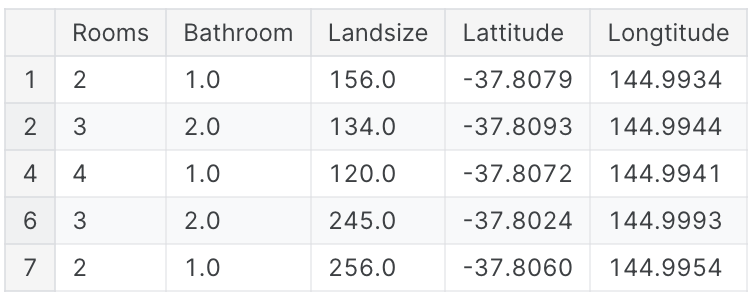
X.head()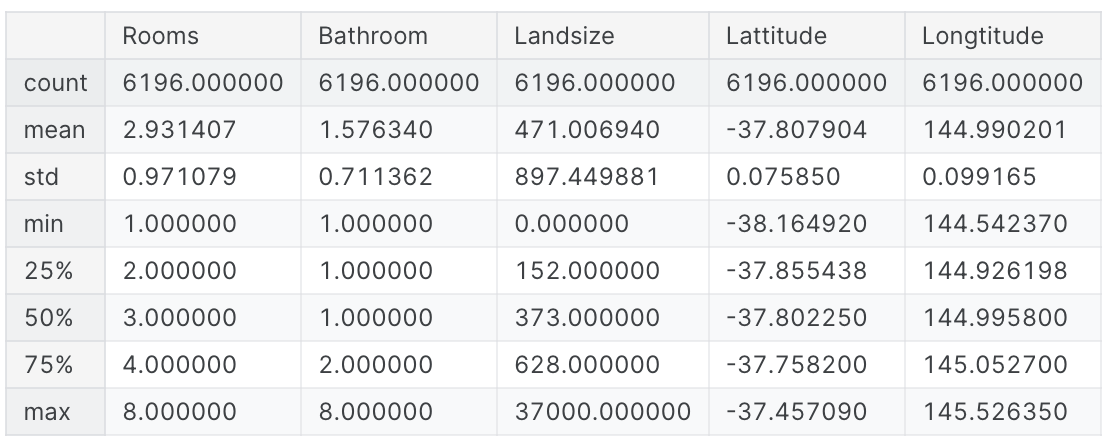
Building Your Model
모델 생성 시 scikit-learn 라이브러리를 사용 ('sklearn')
Scikit-learn 은 데이터 프레임에 일반적으로 저장되는 데이터 유형을 모델링하는 데 가장 널리 사용되는 라이브러리
모델 구축 단계는 다음과 같다!
- Define : Decision Tree 같은 모델과 모델의 매개변수를 지정한다.
- Fit : 제공된 데이터에서 패턴을 파악 (모델링의 핵심이라네요)
- Predict : 예측
- Evaluate : 모델의 예측이 얼마나 정확한지 확인한다.
다음은 scikit-learn으로 decision tree를 define하고 fitting하는 코드이다.
from sklearn.tree import DecisionTreeRegressor
melbourne_model = DecisionTreeRegressor(random_state=1)
melbourne_model.fit(X, y)random_state는 시드값을 지정해주는 parameter 이다.
대충 뭐.. 기억해냈길 바란다 미래의 이걸 보는 나야
그냥 대충 동일한 값을 실행할 때마다 넣으면 같은 실행 값을 얻을 수 있음
이제 모델을 완성했다!!!!
그럼 이제 예측의 작동을 첫 5행에서 확인해보자..
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))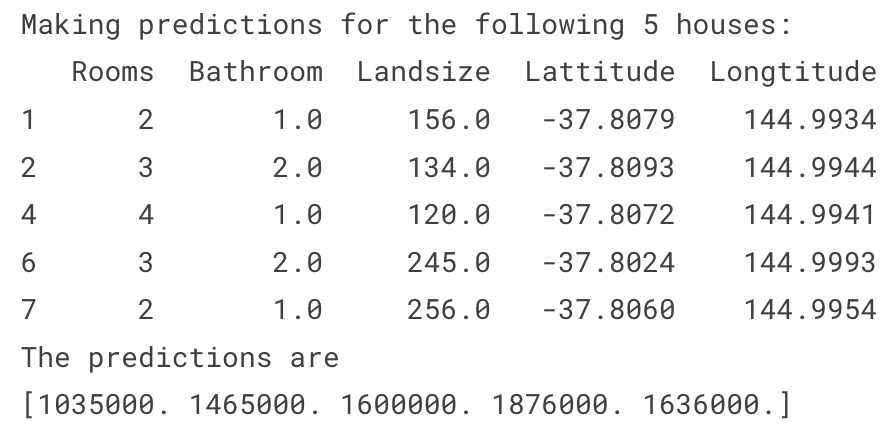
이렇다고 하네요~
