There's a lot of non-numeric data out there. Here's how to use it for mahcine learning
여기서는 categorical data, 범주형 데이터에 대해서 다룰 건가 봄
😃Introduction
categorical variable은 한정된 수의 value들임
- 아침 식사 빈도가 어떻게 되는지에 대한 설문에서 옵션이 "먹지 않는다", "가끔 먹는다", "대부분 먹는다", "매일 먹는다" 일 경우, 이 데이터는
categorical data이다. - 만약 사람들이 어떤 차 브랜드를 가지고 있는지 묻는 설문에서 응답들은 "Honda", "Toyota", "Ford" 등이 있을 것이다. 이 것도
categorical data이다.
만약 전처리하지 않고 대부분의 머신 러닝 모델에 연결하려고 하면 오류가 발생함
그래서 여기서는 categorical data를 준비하는 데 사용할 수 있는 세 가지 접근 방식을 비교해보겠음
😗Three Approaches
1) Drop Categorical Variables
categorical data를 처리하는 가장 쉬운 방법은 단순히 데이터셋에서 변수를 제거하는 것
이 접근 방식은 열에 유용한 정보가 포함되지 않은 경우에만 잘 작동함
2) Ordinal Encoding
Ordinal Encoding은 각각 고유 값을 서로 다른 정수에 할당한다.

이 접근 방식은 카테고리의 순서를 가정한다.
"Never" (0) < "Rarely" (1) < "Most days" (2) < "Every day" (3)
순이다.
이 예제에서는 범주에 확실한 순위가 있기 때문에 이 가정이 합리적이다.
모든 categorical data 값에 명확한 순서가 있는 것은 아니지만, 우리는 이 것을 ordinal encoding 이라고 부른다.
트리 기반 모델(DecisionTree, RandomForest 등)의 경우 ordinal 변수에 ordinal encoding이 잘 작동할 것으로 기대할 수 있다.
3) One-Hot Encoding
원-핫 인코딩은 원본 데이터에서 가능한 각 값의 존재 여부를 나타내는 새로운 열을 생성함
이를 이해하기 위해 예제를 통해 살펴보자
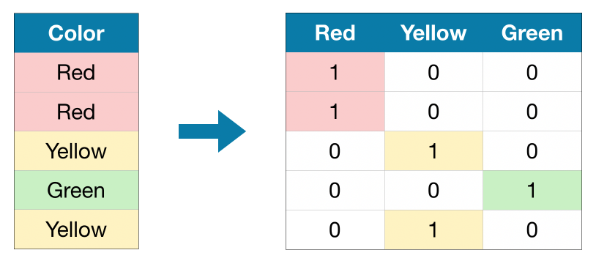
'colors' 는 세 가지 범주가 있는 categorical data (빨, 노, 초)
이 원-핫 인코딩은 원본 데이터 집합의 각 가능한 값에 대해 하나의 열과 하나의 행을 포함한다.
원래 값이 "red" 이면 "red" 열에 1을 넣고, "yellow"이면 "yellow" 열에 1을 넣는 식으로 인코딩
Ordinal Encoding과는 달리 One-Hot Encoding은 카테고리의 순서를 가정하지 않는다.
따라서 범주형 데이터에 명확한 순서가 없는 경우(예: "red"가 "yellow"보다 많지도 적지도 않은 경우) 이 접근 방식이 특히 효과적일 것으로 예상할 수 있다.
고유한 순위가 없는 categorical variables를 명목 변수라고 한다.
원-핫 인코딩은 일반적으로 categorical data의 값이 많은 경우 성능이 좋지 않다.
(일반적으로 15개 이상의 서로 다른 값을 갖는 변수에는 사용하지 않는다고 함)
그럼 예시 한번 보자..
🙀Example
이전과 마찬가지로 Melbourne Housing dataset 사용
import pandas as pd
from sklearn.model_selection import train_test_split
data = pd.read_csv(filepath)
# Separate target from predictors
y = data.Price
X = data.drop(['Price'], axis=1)
# Divide data into training and validation subsets
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
# 결측값 있는 열 지우기
cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()]
X_train_full.drop(cols_with_missing, axis=1, inplace=True)
X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# "Cardinality" means the number of unique values in a column
# Select categorical columns with relatively low cardinality (convenient but arbitrary)
low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and X_train_full[cname].dtype == "object"]
# Select numerical columns
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float32']]
# Keep selected columns only
my_cols = low_cardinality_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()그럼 데이터를 한번 살펴보자..
X_train.head()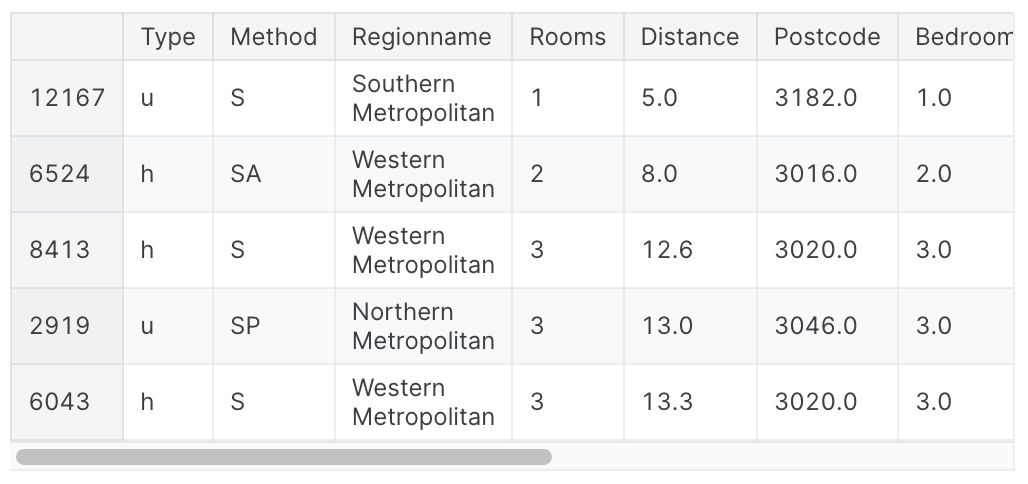
그 다음 training data에 대해 categorical variables의 리스트를 얻을 것이다.
각 열의 dtype을 확인해서 이를 수행할 수 있음
'object' dtype은 텍스트가 있음을 나타냄 (이론적으로 다른 것도 있을 수 있음)
이 데이터셋의 경우, 텍스트가 있는 열은 categorical variables를 나타냄
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
Define Function to Measure Quality of Each Approach
categorical data를 처리하는 세 가지 접근 방식을 비교하기 위해 score_dataset() 함수를 정의한다.
이 함수는 random forest 모델에서 평균 절대 오차(MAE)를 나타낸다.
from sklearn.ensemble import RandomForestRegressor
from sklearn. metrics import mean_absolute_error
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimator=100, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_vaild)
return mean_absolute_error(y_valid, preds)Score from Approach 1 (Drop Categorical Variables)
object 컬럼을 select_dtypes() 를 이용해 drop
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_trian, drop_X_valid, y_train, y_valid))
Score from Approach (Ordinal Encoding)
사이킷 런에는 Oridnal Encoding을 사용할 수 있는 OrdinalEncoder class가 존재한다.
categorical data를 반복하고 각 컬럼에서 개별적으로 적용한다.
from sklearn.preprocessing import OrdinalEncoder
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
이 코드에서는 각 고유 값을 다른 정수에 무작위로 할당
이는 사용자 지정 레이블을 제공하는 것보다 더 간단한 일반적 접근 방식이지만,
모든 서수 변수에 대해 더 나은 정보를 제공하는 레이블을 제공한다면 성능이 추가로 향상될 수 있다.
Score from Approach 3 (One-Hot Encoding)
원핫 인코딩을 위해 scikit-learn의 OneHotEncoder class를 사용한다.
이 클래스에는 여러 parameter가 존재
validation data에 학습 데이터에 표시되지 않은 클래스가 포함된 경우 오류를 방지하기 위해 handle_unknown='ignore' 를 설정하고, sparse=False 를 설정하면 인코딩 된 열이 sparse 행렬 대신 numpy 배열로 반환된다.
인코더를 사용하려면 원 핫 인코딩하려는 categorical data만 제공하면 된다.
예를 들어, train_data를 인코딩하려면 X_train[object_cols] 를 제공하면 된다.
(X_train[object_cols]에는 training set의 모든 categorical data가 포함)
from sklearn.preprocessing import OneHotEncoder
OH_encoder = OneHotEncoder(handle_unknown = 'ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_train = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
print("MAE from Approach 3 (One-Hot Encoding) :")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
🤔Which approach is best?
이 경우에는 접근1이 가장 별로이고, 접근 3에서 가장 좋은 MAE를 얻어냄
근데, 경우에 따라 다름
