이 강의에서는 결측값을 다루는 법에 대해서 다룬다고 함.
시작합니다.
데이터에 결측값이 발생하는 경우는 여러가지가 있음
- A 2 bedroom house won't include a value for the size of third bedroom (침실이 2개인 집 데이터의 세번째 방의 크기)
- A survey respondent may choose not to share his income (수입을 공유하지 않기로한 사람의 설문)
scikit-learn을 포함한대부분의 머심 러닝 라이브러리는 결측값을 제거하지 않은 데이터를 다루려고 할 때 오류가 생긴다.
그래서 아래 전략들 중 하나를 택해야 함..
🧑💻Three Approaches
1) A Simple Option: Drop Columns with Missing Values
결측값이 있는 열을 아예 삭제해버리는 방법이다.

삭제된 열의 값의 대부분이 결측값이 아닌 한, 이 방법은 잠재적으로 유용한 많은 정보에 접근할 수 없게 된다.
그냥 비추한다는 뜻
2) A Better Option: Imputation(추론)
특정 숫자로 결측값을 채우는 방법이다.

대입된 값이 정확히 맞지는 않지만 열을 삭제해버리는 방법보다는 더 정확한 모델을 얻을 수 있음
3) An Extension To Imputation
추정은 일반적으로 잘 작동하나, 추정한 값은 데이터셋에서 수집되지 않은 실제 값보다 체계적으로 높거나 낮을 수 있음
또는 결측값이 있는 행이 다른 방식으로 고유할 수도 있음
어떤 값이 누락되었는지 고려하면 모델이 더 나은 예측을 할 수 있음
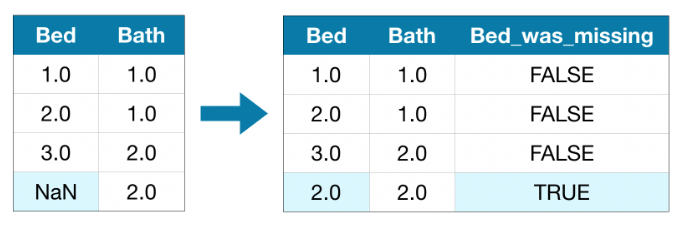
이 접근 방식에서는 결측값을 추론한다. 또한 원본 데이터셋에서 결측값이 있는 각 열에 대해 추정한 항목의 위치를 표시하는 새 열을 추가한다.
떄에 따라 결과가 개선될 수도, 도움이 안 될 수도 있다.
🤔Example
그럼 세가지 방법을 Melbourne Housing dataset을 통해 비교해볼까?
import pandas as pd
from sklearn.model_selection import train_test_split
data = pd.read_csv(filepath)
y = data.Price
melb_predictors = data.drop(['Price'], axis=1)
X = melb_predictors.select_dtypes(exclude['object'])
X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.0, test_size=0.2, random_state=0)from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mena_absolute_error
def score_dataset(X_train, X_val, y_train, y_val):
model = RandomForestRegressor(n_estimatiors=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_val)
return mean_absolute_error(y_val, preds)MAE를 반환하는 코드
Score form Approach 1 (Drop Columns with Missing Values)
cols_with_missing = [col for col in X_train.columns if X_trian[col].isnumm().any()]
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_datset(reduced_X_train, reduced_X_valid, y_train, y_valid))

Score from Approach 2 (Imputation)
SimpleImputer를 통해 누락된 값을 각 열의 평균값으로 대체
간단하지만 평균값을 채우는 것은 일반적으로 꽤 잘 수행됨
통계학자들이 회귀 대입과 같은 복잡한 방법도 써보고 했는데 일반적으로 추가적인 이점을 제공하지는 않음
from sklearn.imput import SimpleImputer
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_val = pd.DataFrame(my_imputer.transform(X_val))
imputed_X_train.columns = X_train.columns
imputed_X_val.columns = X_val.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_val, y_train, y_val))
MAE가 더 낮은 것을 볼 수 있음
Score from Approach 3 (An Extension to Imputaion)
결측값에 대입하는 동시에 어떤 값이 대입되었는지 추적
X_train_plus = X_train.copy()
X_valid_plus = X_val.copy()
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_val_plus[col + '_was_missing'] = X_val_plus[col].isnull()
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrane(my_imputer.fit_transform(X_train_plus))
imputed_X_val_plus = pd.DataFrame(my_imputer.transform(X_val_plus))
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_val_plus.columns = X_val_plus.columns
print("MAE from Approach 3 (An Extensions to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))

Approach 3보단 2가 약간 더 낮은 MAE를 보임
