[ALBEF 논문 리뷰]Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Alethio-Intern_2023

[ALBEF](Align before Fuse: Vision and Language Representation Learning with Momentum Distillation)
1. 논문이 다루는 Task
Task: Vision-Language
- Input: Image, Text
- Output: Image-Text Retrieval, Visual Entailment, Visual Question Answering, Natural Language for Visual Reasoning
2. 기존 연구 한계
2-1. Rely on pre-trained object detectors to extract region-based image features
기존의 V+L의 모델(LXMERT, UNITER, OSCAR)은 사전 훈련된 디텍션 모델들이 들어 가 이미지 영역을 추출 하여 텍스트 토큰과 융합 시켰다. 이러한 디텍션의 모델은 훈련 속도의 감소와 높은 cost를 요구하였다. 또한 융합하는 과정에서 이미지는 pixel space이며 text는 단어나 문자의 시퀀스로 표현되어 위 모델들의 멀티모달 인코더가 이 정보들을 융합하는데 상당히 어려웠다 하지만 하지만 이러한 방법 대신 ITM(image-text matching)과 MLM(masked language modeling)을 제안하였다.
2-2. Noise Dataset
일반적으로 V+L 테스크의 데이터는 웹에서 수집되어 기존의 MLM과 같은 방식만으로는 모델이 Noise 데이터에 과적합 될 가능성이 존재한다. 이를 위해 논문에서는 Momentum Distillation이라는 방법을 제안하였다.
3. 제안 방법론
3-1. Model Architecture
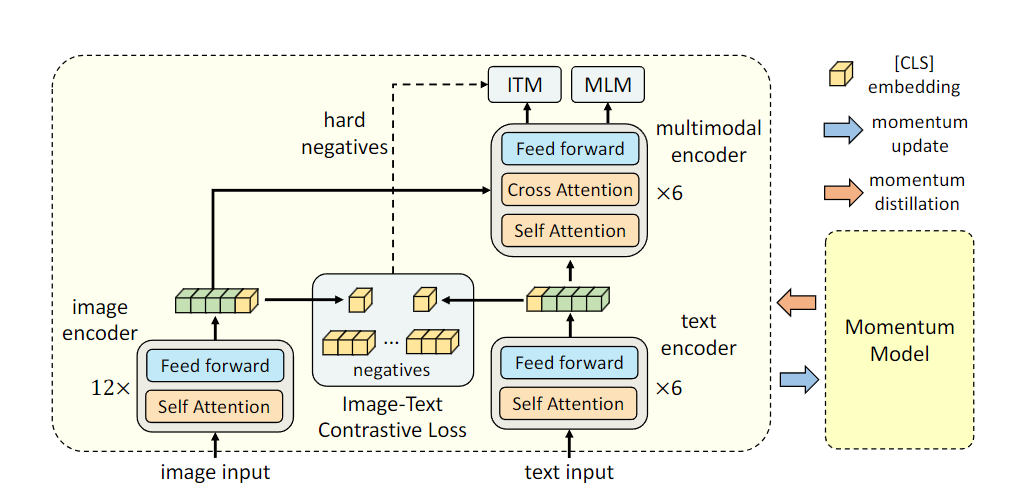
모델의 아키텍처로는 총 3가지의 유니모달로 구성된다.
- Image Encoder : 12층의 ViT-B/16을 사용하며 ImageNet-1k로 사전훈련된 가중치를 사용한다.
- Text Encoder : BERT의 1~6층까지의 인코더를 사용한다.
- Multimodal Encoder : Bert의 7~12층까지의 인코더를 사용한다.
이때 Multimodal Encoder의 경우 Image Encoder에서 나온 Representation과 Self Attention후의 Representation을 Cross Attention 하는 방식으로 정보를 Fuse하게 된다.
Loss는 총 3가지가 사용되며 간단하게 아래와 같다.
- Image Encoder와 Text Encoder의 Cls 토큰을 대상으로 Image-Text Contrastive Learning을 진행한다.
- Constrastive에서 진행한 Hard negatives samples을 대상으로 Image-Text Matching을 검사한다.
- MLM을 진행하여 마스킹된 Text 토큰을 예측하게 된다.
3-2. Image-Text Contrastive Learning
일반적인 Contrastive Learning과 동일하게 이미지와 텍스트의 유사성으로 평가를 진행하게 된다.
이때 각 인코더(Image, Text)의 나온 Cls 토큰의 표현을 256차원의 Linear Layer에 투영시켜 차원을 한번 변형하는 과정을 거치게 된다.
계산식은 아래와 같다.
이때 는 learnable parameter이다. 각각의 i2t와 t2i를 계산한 이유는 추후 Label에 대해 positive는 1, negative는 0으로 Hard한 Label을 주게 되는데 이는 CLIP 구현에 나온 것처럼 실제론 유사한(중복) 즉 비슷한 개념에 대해 설명하고 있어 실제로는 1이지만 0으로 Label을 주는것을 방지하기 위해 이처럼 계산하며 최종적인 Loss는 아래와 같이 설명된다.
3-3. Masked Language Modeling
MLM의 경우 BERT와 동일하게 15%를 Masking을 진행하며 토큰은 [MASK]로 대체한다. 이 또한 one-hot label로 구성된다.
3-4. Image-Text Matching
Image-Text Matching 같은 경우 Image-Text pair가 positive인지 negative 페어인지 계산하게 된다.
이를 위해 Multimodal Encoder의 출력을 FC레이어와 Softmax를 사용하여 두가지의 Class를 예측하게 된다.
하지만 이때 사용되는 Image-Text Pair는 Hard Negatives Pair로써 이는 서로 이미지와 텍스트가 실제로는 유사한 이미지를 공유하지만 세부적인 특성이 다른 샘플들을 의미한다.
구체적으로는 미니배치내의 Image를 기준으로 Negatives sample(text)에 대해서 가장 높은 유사도를 가지는 Text를 추출해 Hard Negatives Pair을 구성하며 Text도 같은 기준으로 추출하여 구성한다.
3-5. Pre-training Objective of ALBEF
위와 같이 총 3가지의 Loss를 더해서 사용하게 된다.
3-6. Momentum Distillation

웹에서 수집되는 데이터는 노이즈가 많다.
예를 들어 positive pair가 실제로는 크게 연관이 없을 수 있으며 negative pair는 실제로 많은 연관성이 존재할 수 있다.
또한 이미지에 비행기가 하늘을 날고 있는 것을 가르키는 소년이 있을때 텍스트가 하늘을 가르키는 소년이라고 표시되는등 이미지에 없는 단어나 실제로는 관련이 없는 노이즈가 많은 데이터가 존재 할수 있다. ITC에서는 이미지에 대해 positive보다 negative가 좀 더 이미지를 잘 설명할 수 있으며 MLM의 경우 이미지를 똑같이 설명하는 다른 좋은 단어들이 존재 할 가능성이 있다. 하지만 ont-hot label은 그런것을 모두 무시하며 labeling하기 때문에 문제가 많다고 주장한다.
이로 인해 Pseudo-targets을 만들어 학습을 진행하게 된다. 이때 모멘텀 모델의 경우 기존 학습된 모델(기존 ALBEF One-hot label로 학습된 모델)을 가져오며 이를 Target으로 EMA(Exponential Moving Average)를 사용하여 훈련시키게 된다. 이 의미는 아래에 더 자세히 설명하겠다.
ITC의 Loss를 아래와 같이 변형시킨다.
즉 Target soft하게 분포로 변경시킨다. 정확히는 s를 s'으로 변형시켜 분포를 예측하게 만들며 이때 분포를 예측하기 위해 KL Divergence을 사용하게 된다.
MLM의 경우도 마찬가지로 아래와 같이 수식을 변형시킨다.
실제 다운스크림 작업에는 둘다 사용하며 이때 = 0.4로 설정하였다.
4. A Mutual Information Maximization Perspective
뉴립스 논문에서 항상 등장하는 파트이다. 약간 이론적 부분을 증명하게 된다.
이 파트에서 말하고자 하는 부분은 ALBEF의 다양한 Loss가 어떻게 Mutual Information을 Maximization하는지에 대한 설명이다.
단순하게는 각각의 MLM, ITC등 다양한 방식으로 Image-Text에 대한 정보를 추출하여 Mutual Information Maximization을 진행하는데 이때 각각의 다른 방식을 여기서는 View(뷰)라고 설명하고 있다. 즉 MLM만 사용하는 것 보단 ITC와 함께 사용하는 것이 좋을 것이다. 여러 방면의 뷰의 정보를 조합하는 것이 더 좋다는 말이다.
논문에서는 위와같은 InfoNCE loss를 최소화 하는것이 MI를 Maximization하는 것과 같다고 주장한다.
4-1. ITC
one-hot으로 구성된 ITC Loss의 경우 아래와 같은 수식으로 다시 쓸수 있다.
결국 이미지에서 텍스트, 텍스트에서 이미지라는 두가지 뷰를 positive에서 Maximization한다.
4-2. MLM
MLM의 경우 이미지와 마스킹된 텍스트가 동시에 들어감으로써 이러한 뷰를 Maximization하며 수식을 아래와 같이 변형시킨다.
4-3. MoD
모멘텀의 경우도 마찬가지로 위의 식중 를 변형시키면 아래와 같다.
결국 모멘텀 모델은 기존 모델이 가지고 있던 뷰를 보다 넓은 뷰로 확장 시키는 역할을 하며 또한 마찬가지라고 주장한다..
5. Downstream V+L Tasks
5가지의 다운스트림을 진행한다. 이를위해 각각의 테스크의 맞게 모델을 변경하게 된다.
5-1. Image-Text Retrieval
-
Image로 Text를 검색하는 task와 Text로 이미지를 검색하는 task가 존재한다.
-
Flickr30K와 COCO 벤치마크를 사용하여 평가를 진행한다.
-
Pretrained의 경우 Flickr30K와 COCO로 finetuning을 진행한다.
-
Flickr30K의 Zero-shot의 경우 COCO 모델로 finetuning 된 것을 사용한다.
-
MLM을 제외한 ITC,ITM만을 loss로 사용하게된다.
5-2. Visual Entailment
-
Image와 Text의 관계라 entailment, neutral, contradictory인지 예측한다.
-
3 class classification 문제로 간주한다.
-
SNLI-VE5로 학습한다.
-
Multimodal encoder + MLP로 모델을 구성하여 분류한다.
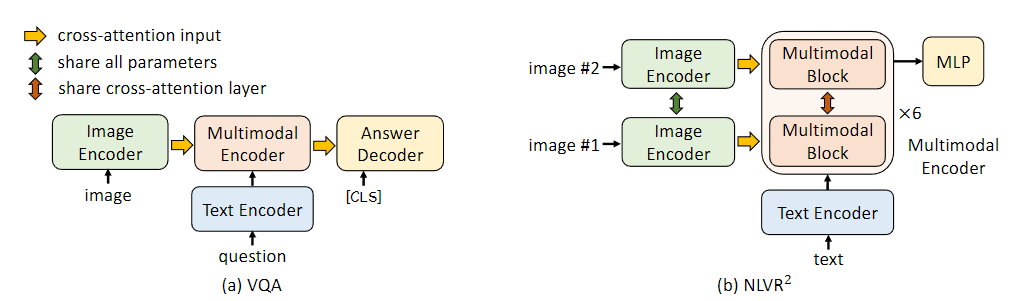
5-3. Visual Question Answering
-
Image와 Text question이 주어졌을때 모델이 답변을 예측하는 task
-
ALBEF는 VQA를 relevant answer generation 문제로 간주하였다.
-
transformer decoder(6 layers) 사용하여 답변을 생성하고 mutimodal encoder weight로 초기화하여 conditional language-modeling loss로 학습한다.
-
공정한 비교를 위해 인퍼런스 시 3192개의 답변만 생성하도록 제한한다.
5-4. Natural Language for Visual Reasoning
-
model이 pair of image를 보고 description을 예측한다.
-
각 이미지는 Multimodal block을 replicate하여 사용한다.
-
추가적인 pretraining을 수행하며, Text-assignment를 학습한다.
이미지 쌍과 텍스트가 주어졌을 때, 모델은 텍스르를 image1, image2, none에 할당 됨
3-class classification으로 풀이된다.
5-5. Visual Grounding
-
image와 관련된 text설명에 해당하는 image region에 localize해야한다.
-
bbox annotation이 없는 상황에서 weakly-supervised setting을 다룬다.
-
RefCOCO+로 실험하고 training 중에서는 Image text supervision을 사용하며 인퍼런스에서는 Grad-CAM을 확장하여 heatmap을 얻어 활용한다.
6. 실험 및 결과
6-1. Evaluation on the Proposed Methods
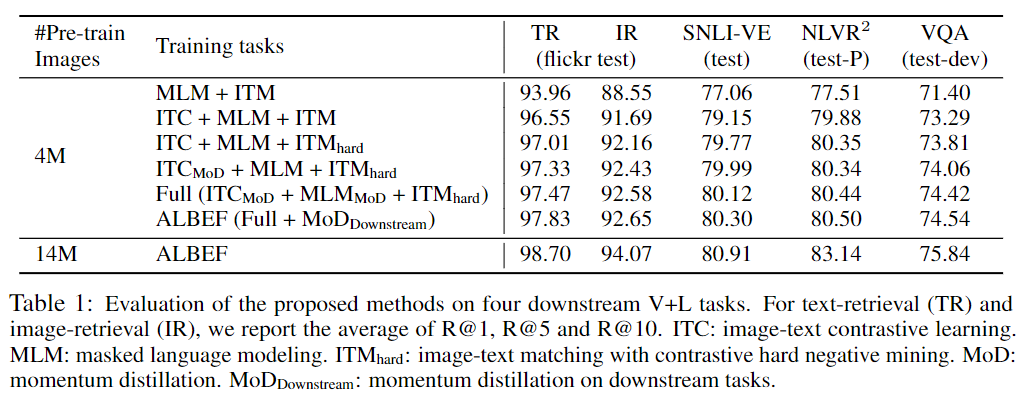
제안된 방법을 추가하였을때 성능이 오르는 것을 볼수 있지만 역시 데이터를 많이 넣어야 학습이 잘된다.
6-2. Evaluation on Image-Text Retrieval
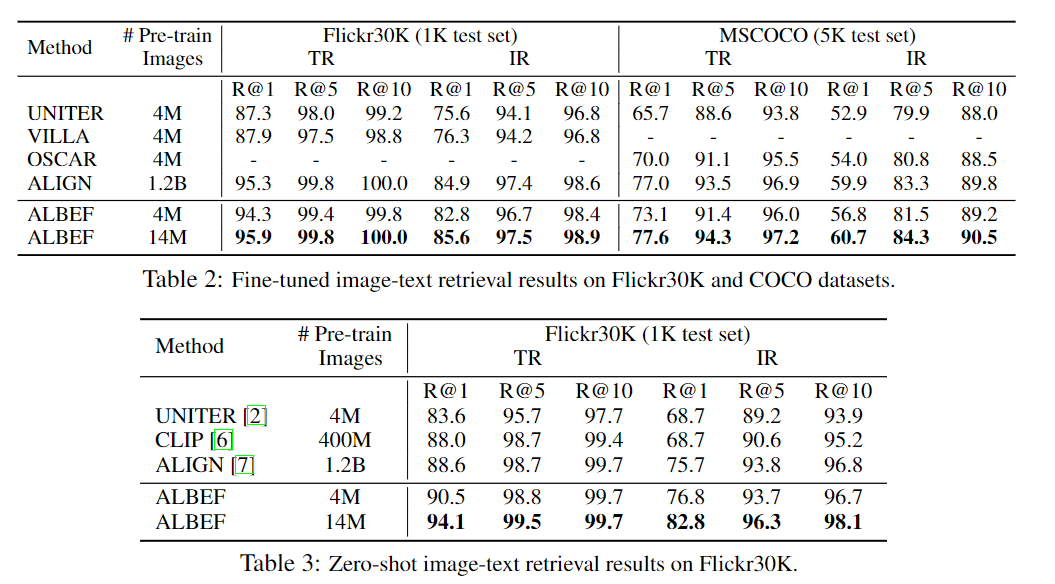
Retrieval의 경우에도 기존의 CLIP이나 ALIGN보다 많은 점수가 오른다. 이때 14M의 데이터를 투입하였을때 점수 향상이 큰것으로 보아 데이터를 더 학습시키면 더 오를 가능성을 시사하고 있다.
6-3. Evaluation on VQA, NLVR, and VE
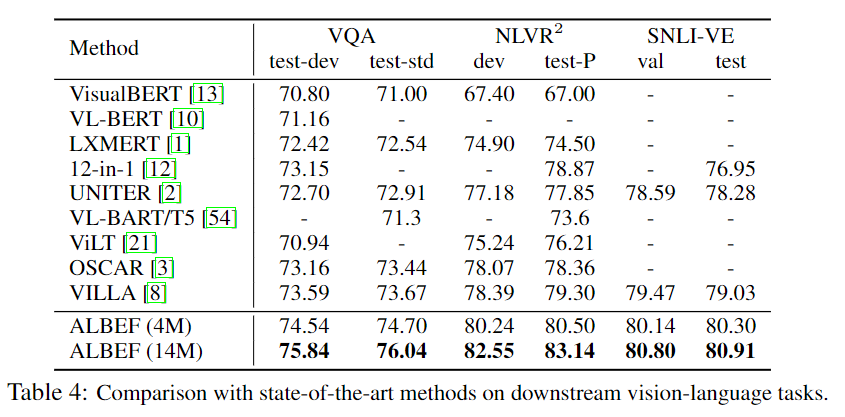
모든 부분에 SoTA를 달성하였다. 놀라운 점은 4M의 데이터만을 가지고도 이정도의 성능을 기록하였다. 놀라운 점으로는 디텍션 모델이 존재하지않아 인퍼런스의 속도가 VILLA에 비해 NLVR데이터에서 10배 정도 속도가 빠르다.
6-4. Evaluation on VQA, NLVR, and VE

itc의 경우 Image Encoder의 self attention map이며 itm의 경우 멀티모달의 cross attention map이다.
각 Figure 5 마다의 질문이 다른데 인간의 시각과 유사하게 관찰된다.
6-5. Ablation Study

k의 대해 크게 민감하진 않지만 had negatives가 없을시 성능이 감소하게 된다.
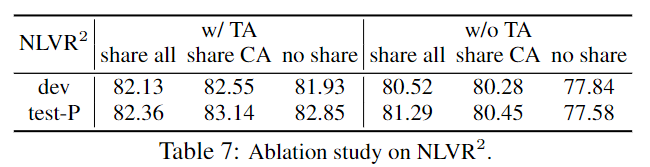
NLVR에 대해 Text-assignment이 있을때와 없을때 그리고 레이어의 가중치 공유에 대한 성능을 나타낸다.
7. Conclusion
-
새로운 V+L 모델인 ALBEF를 제안하였다.
-
각 단일 Encoder의 표현을 정렬 한 후 Multimodal Encoder에서 Fuse하는 방식을 채택하였다.
-
또한 MoD로 분포를 학습하여 기존의 놓친 부분을 학습하여 성능을 개선하였다.
-
Hard negative mining을 통하여 더 많은 정보를 포함 할수 있는 train sample을 찾아 ITM을 개선하였다.
-
ITC를 추가할때 성능이 비약적으로 향상 되었다.
8. 회고
요새 회사생활에 Diffusion을 하느라 정신이 없지만 그나마 재택근무로 돌려서 다행이다.
최근 고려대 교수님과 미팅을 하였는데 준비하기엔 현재 회사에 집중을 할수 없을 것 같아 나중으로 미루었다. 그 어느곳에서도 피해가 가면 안되기 때문이다.
멀티모달이 확실히 재미난 것 같다.
앞으로 멀티모달 논문을 읽을 시간이 있는지는 잘 모르겠지만 꾸준히 읽어야겠다.
