
[LLaVA](Visual Instruction Tuning)
1. 논문이 다루는 Task
Task: Text Generation
- Input: Image, Text
- Output: Text
2. 기존 연구 한계
2-1. Text-Only
논문에서는 시작하자마자 인간은 다양한 신호로 세계를 관찰하고 있다는 점을 언급한다. 또한 최근에 나온 모델들인 Flamingo, BLIP-2 같은 모델은 비록 언어에 시각적 의미를 맵핑 시킬수는 있지만 그림을 설명하는 수준에서 그쳐 고정된 인터페이스만을 가져 비교적 제한적인점을 뽑고 있다.
하지만 LLM이 비약적으로 발전한 후 GPT-3, LLaMA, Alpaca, Vicuna등 많은 LLM이 나와 언어가 더 넓은 역할을 할수 있게 되었지만 오직 Text-Only라는 점을 짚는다.
3. GPT-assisted Visual Instruction Data Generation
우선적으로 멀티모달의 instruction 데이터를 구하기 위해 저자는 ChatGPT/GPT-4를 이용하기를 제안하였다.
3-1. Simple Genration
영어
- "Describe the image concisely."
- "Provide a brief description of the given image."
- "Offer a succinct explanation of the picture presented."
- "Summarize the visual content of the image."
- "Give a short and clear explanation of the subsequent image."
- "Share a concise interpretation of the image provided."
- "Present a compact description of the photo’s key features."
- "Relay a brief, clear account of the picture shown."
- "Render a clear and concise summary of the photo."
- "Write a terse but informative summary of the picture."
- "Create a compact narrative representing the image presented."
한국어
- "이미지를 간결하게 묘사하세요."
- "주어진 이미지에 대한 간략한 설명을 제공합니다."
- "제시된 그림에 대한 간결한 설명을 제공합니다."
- "이미지의 시각적 내용을 요약합니다."
- "다음 이미지에 대해 짧고 명확하게 설명해주세요."
- "제공된 이미지에 대한 간결한 해석을 공유합니다."
- "사진의 주요 특징에 대한 자세한 설명을 제시하세요."
- "보여진 그림에 대한 짧고 명확한 설명을 전달합니다."
- "사진에 대한 명확하고 간결한 요약을 렌더링합니다."
- "그 그림에 대해 간결하지만 유익한 요약본을 쓰시오."
- "제시된 이미지를 나타내는 컴팩트한 내러티브를 작성합니다."
이미지를 입력으로 주고 위와 같은 프롬프트를 사용하여 마치 이미지 캡셔닝처럼 데이터를 생성해내었다.
하지만 이것만으로는 이미지에 대해 깊은 이해가 부족하여 아래와 같은 방법으로 데이터를 생성하였다.
3-2. Instruction-following Generation

프롬프트 입력
- Captions : Text 전용인 GPT를 위해 이미지를 입력하지 않고 설명으로 준다. 이를 통해 시각적 개념을 추출합니다.
- Bounding boxes : 바운딩 박스를 사용하여 각 개념에 대한 위치와 정보를 알려줍니다.
Instruction-following Data Generation

위의 사진 예시와 같이 프롬프트를 지정하여 sample['context'] 에 넣어준다.
-
Conversation : 질문하고 답하는 일반적인 형식으로 주로 객체의 위치, 수, 유형, 상대위치 등 시각적 내용에 대한 다양한 질문을 한다.
-
Detailed description :

이미지에 대해 풍부하고 포괄적인 설명을 포함하기 위해 GPT-4에게 위와 같은 9가지 문항중 랜덤으로 사진에 대한 자세한 설명을 요청한다. -
complex reasoning : 시각적 콘텐츠 자체에 중점을 두어 이를 기반으로 심층적인 추론 질문을 한다.
논문의 저자들은 Conversation에서 58k, Detailed description에서 23k, complex reasoning에서 77k를 포함하여 158k의 이미지를 얻어 내었다. 이는 모두 github에 공개가 된 데이터 셋이다.
4. Visual Instruction Tuning
4-1. Architecture
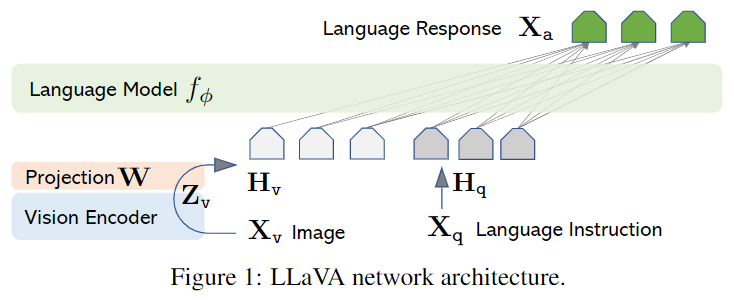
구조는 매우 간단하다. 논문에서는 LLaMA를 사용하며 CLIP visual encoder로 ViT-L/14를 사용한다. 이미지를 가 입력되면 이를 =로 통과시킨다. 이떄 는 CLIP이다. CLIP에서 나온 아웃풋을 단순히
위와 같이 통과시키는데 이때 임베딩 레이어의 차원과 동일한 차원으로 통과시킨후 그림과 같이 계산해준다.
논문에서는 이는 매우 단순한 방법이므로 Flamingo나 Q-foremer 그리고 BLIP-2와 같이 보다 crss-attention 같은 방법을 이용하여 정교한 방식 고려할 수 있다고 설명한다.
4-2. Training
각 이미지에 에 멀티턴 대화 가 있다고 가정하면 아래와 같이 를 만들어준다.
추후 실제로 프롬프트에 입력될때는

위와 같이 입력이 진행되게 된다. 이를 수식으로 나타내면 아래와 같다.
프롬프트 셋팅이 완료되면 LLaVA의 학습 총 2단계로 이루어진다.
Stage 1. Pre-training for Feature Alignment.

우선 시각적 개념의 적용과 학습의 효율성을 높히기 위해 CC3M의 데이터를 595K의 image-text pair로 필터링 시킨다. 이때 주로 위 사진과 같은 프롬프트 샘플들을 랜덤하게 샘플링 하여 instruction tuning을 우선 진행시킨다. 이때 우리가 정의한 word embedding 행렬과 차원을 맞추기 위한 를 제외하고 LLM,CLIP 모두 가중치를 frozen 시켜 만 마치 LoRA처럼 학습시킨다. 이로써 를 통과한 는 기존의 LLM의 word embedding과 정렬된다. 즉 는 visual token embedding 훈련시키는 것과 유사하다.
Stage 2. Fine-tuning End-to-End
Stage 1이 끝나면 다시 LLM과 CLIP의 가중치 frozen을 해제하고 만 frozen시킨 후 훈련을 시작한다. 이떄 저자들은 총 2개의 학습 방안을 제시하였다.
- Multimodal Chatbot : 위에서 수집한 158k의 고품질 데이터를 사용하여 Chatbot을 만듭니다. 이때 수집한 데이터중 1개는 멀티턴이고 나머진 싱글턴이므로 이를 훈련중에 고르게 샘플링하여 훈련시킵니다.
- Science QA : Science QA benchmark에서 고안한 방법으로 질문은 언어 또는 이미지로 이루어지며 모델은 이를 객관식으로 답을 선택하는 문제 입니다. 이는 싱글턴으로 구성되어야 하기 때문에 훈련 데이터를 싱글 턴으로 구성합니다.
5. 실험 및 결과
5-1. Multimodal Chatbot
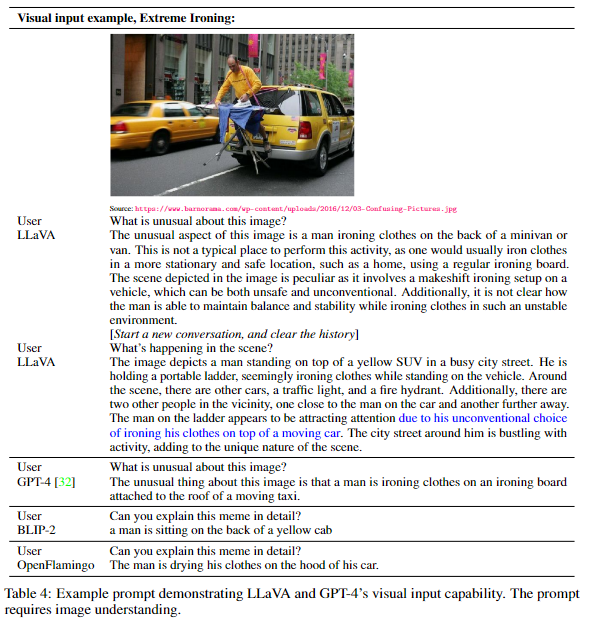
LLaVA의 이미지 이해와 대화 능력을 평가하기 위해 Multimoda Chatbot으로써의 성능을 평가한다. 비교를 위해GPT-4와 동일한 프롬프트와 응답을 인용하고 BLIP-2 및 OpenFlamingo와 비교한다.
비교결과 BLIP-2, OpenFlamingo는 이미지에 대해 설명하는 데 중점을 둔 반면 80k의 데이터를 사용하였음에도 GPT-4 비슷한 수준의 추론 능력을 보여준다.
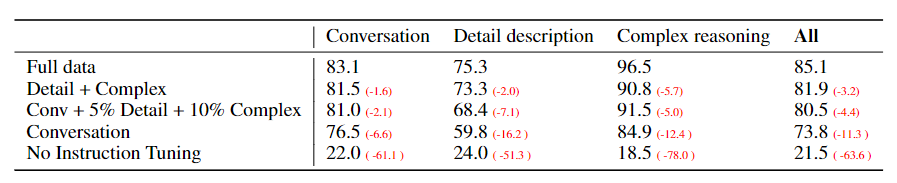

수집한 데이터의 비율을 다르게 하였을떄 GPT-4에 대해 정량 평가(Quantitative Evaluation)한다. COCO Val 2014 데이터셋에서 랜덤한 이미지 30개를 비교하여 각 이미지마다 짧은 질문, 세부 질문, 복잡한 추론 질문을 구성하여 총 90개로 평가하였다. 이떄 GPT-4에 들어가는 입력은 텍스트로 이미지 캡션과 바운딩 박스를 주었다.
5-2. ScienceQA
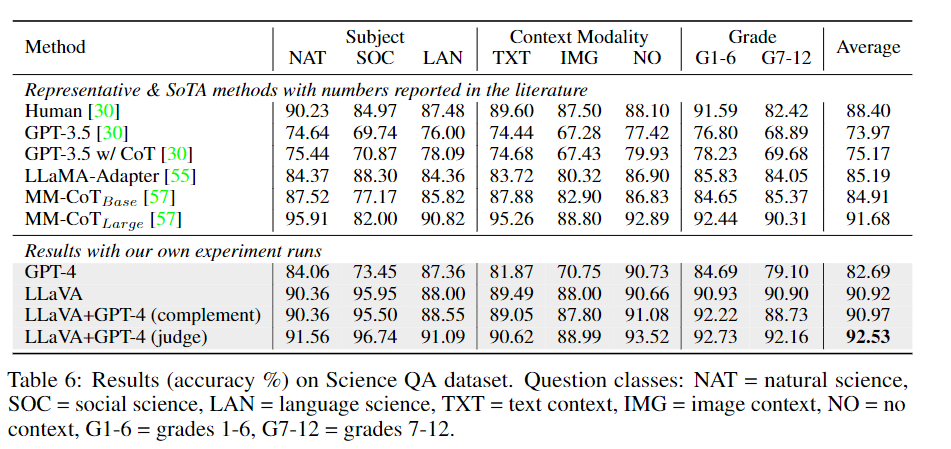
21k의 ScienceQA에 대해 객관식을 고르는 것처럼 평가하였다. GPT-3.5, LLaMA-Adapter, MM-CoT등과 사용하였따. SoTA(91.68%)에 근접한 90.92%로 성능을 내었다. 또한 LLM의 한계를 보기 위해 GPT-4에게 2-shot in-context-learing을 시켰을때 82.96%를 내었다.
추가로 저자는 GPT-4와 LLaVA를 앙상블로 사용하였다. 저자가 주장하길 GPT-4를 앙상블로 쓴 최초의 기법이라고 주장한다.
- GPT-4가 답변을 제공 하지 못할 경우 LLaVA의 답변을 사용하였따. 이떄는 90.97%의 정확도로 비슷한 성능을 나타내었다.
- GPT-4와 LLaVA가 서로 다른 답변을 내놓을때마다 두개의 결과를 바탕으로 GPT-4에게 다시 답변을 요청한다. 이럴경우 SoTA로 92.53%의 정확도를 보였다.
5-3 Ablations
ScienceQA를 대상으로 제한된 실험을 하였다.
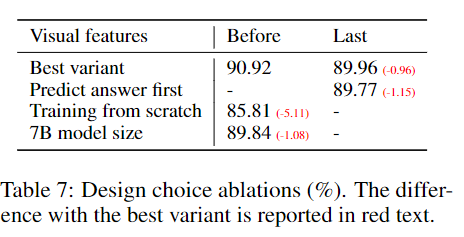
-
Visual features : visual features에 대해 Transformer의 마지막 레이어가 아닌 CLIP 의 마지막 레이어를 사용하였을때 89.96%로 0.96%더 낮다. 저자들은 마지막 레이어는 이미지에 대해 글로벌한 내용을 보며 이전의 레이어가 조금 더 디테일한 내용을 본다고 주장한다.
-
Chain-of-thoughts : CoT와 같은 first 추론 전략은 별로 좋지 않다고 주장한다.
-
Pre-training : Pre-training을 하지않고 바로 ScienceQA를 학습 시켰을떄는 85.81%로 떨어진다.
-
Model size : 모든 구성을 동일하게 유지시키고 13B->7B로 바꾸었을때 90.92% -> 89.84%로 감소하였다.
6. Discussions
이 논문은 언어전용 GPT-4를 이용해 시각적 명령어로 튜닝을 가능하게 하였다. 또한 language-image-instruction-following data를 생성하기 위한 방안을 제시하였으며 이를 통해 시각적 지시를 완료할수 있도록 가능하게 하게 하였다.
ScienceQA로 파인튜닝을 진행하였을때 SoTA를 달성하며 멀티모달 채팅에서 뛰어난 성능을 달성한다.
OCR같은 작업을 위해 좀 더 큰 데이터 셋을 사용하면 좋을거 같으며 멀티모달 채팅성능을 증가시키기 위해 language-image 데이터 셋(GLIP, GLGEN)을 사용하기를 권장한다.
SAM과 같은 다른 비전 모델을 LLaVA에 연결하여 멀티모달 GPT-4에 장착되지 않은 새로운 기능을 가지는 것도 흥미가 있다.
7. 회고
드이어 LLaVA를 끝냈다 LLaMA-2를 만들고 나서 멀티모달에 관심이 많아 LLM에 탑재되는 멀티모달을 리뷰해보았는데 나름 재밌는거 같다.
