[FILIP](FINE-GRAINED INTERACTIVE LANGUAGE- IMAGE PRE-TRAINING)
1. 논문이 다루는 Task
Task: Vision-Language
- Input: Image, Text
- Output: Image Representation, Text Representation
2. 기존 연구 한계
2-1. Global features Contrastive Learning
기존의 CLIP, AlIGN의 같은 모델은 각 Encoder의 CLS 토큰을 사용하여 Contrastive Learning을 진행 하였다. 이는 전체적인 이미지와 텍스트의 연관성을 학습할 수 있지만 보다 세부적인 이미지 패치와 텍스트 토큰간의 세밀한 정보는 학습하기 어렵다고 주장하여 이를 학습할 수 있는 FINE-GRAINED CONTRASTIVE LEARNING을 제시한다.
3. 제안 방법론
3-1. Model Architecture
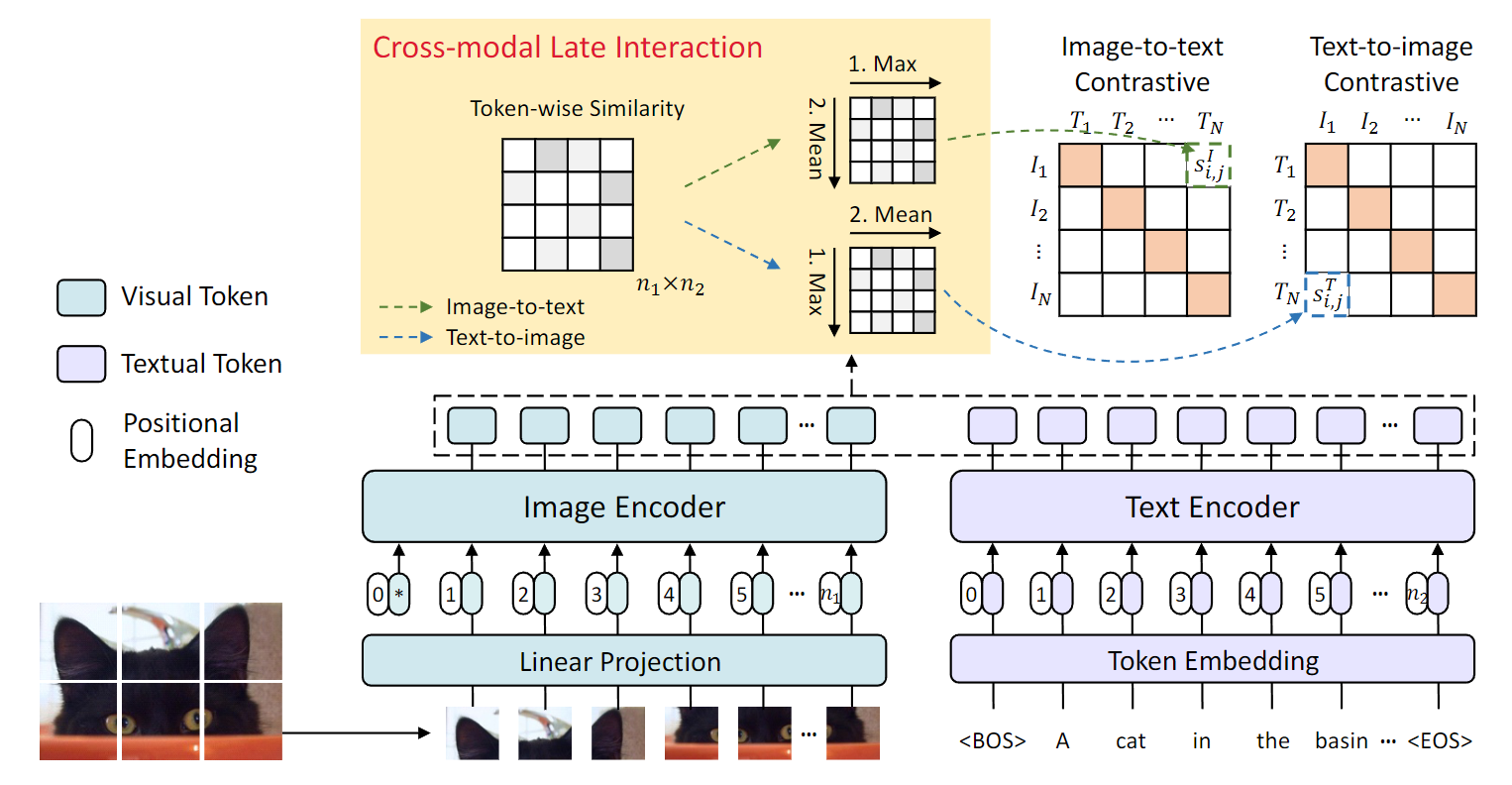
FILIP의 모델은 우선 각 토큰을 이용해야하기 때문에 Transformer 기반의 Image, Text Encoder만을 사용한다.
Image Encoder의 경우 ViT를 사용한다.
Text Encoder의 경우 일반적인 Transformer Encoder를 사용한다.
최종적인 Encoder의 Output들은 같은 경우 같은 차원의 선형으로 투영되며 L2로 정규화된다.
3-2. FINE-GRAINED CONTRASTIVE LEARNING
일반적인 Contrasitve representaion learning은 아래와 같이 정의 된다.
인코딩된 표현에 대해 연관성이 있는 샘플은 가깝게 그리고 연관이 없는 샘플에 대해서는 멀리 떨어지게 훈련된다.
각 훈련 배치 내에서의 개의 Image-Text Pair를 가져오게 될 경우 이미지를 기준으로 는 Positive Sample이고 의 경우 Negative Sample이다.
마찬가지로 Text의 기준에서도 위의 공식으로 정리가 된다.
이럴 경우 미니 배치내의 Total Loss는 위와 같이 정의가 가능하다.
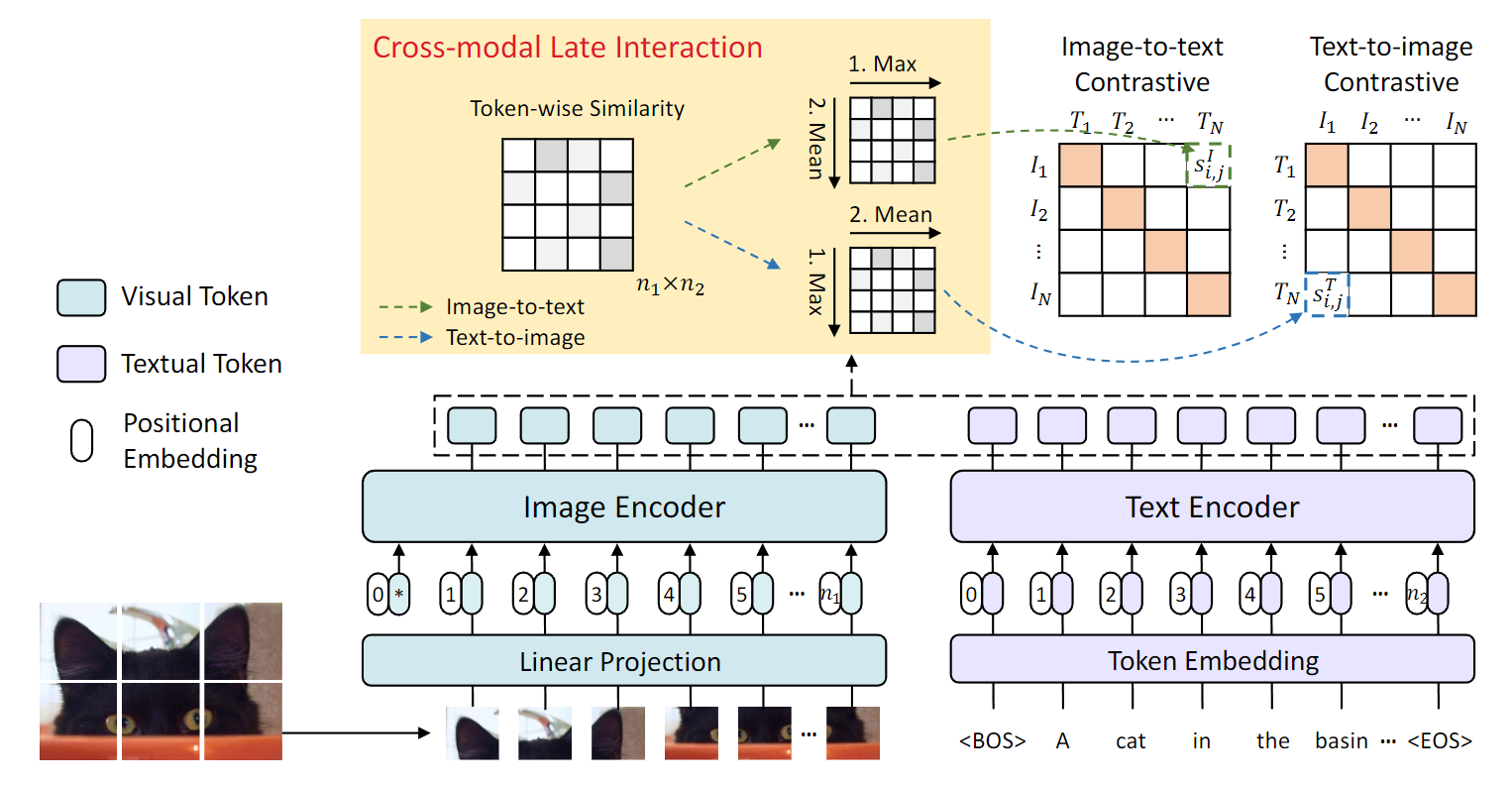
CROSS-MODAL LATE INTERACTION
결과적으로 CLIP은 ALIGH은 위와 같이 CLS token을 이용하여 계산하게 되는데.
하지만 위의 단점으로 포지셔널 인코딩에 적용되는 세밀한 word-patch alignment를 무시 한다는 점이다.
구체적으로 이러한 계산식은 은 Image patch의 갯수 는 패딩 되지 않은 텍스트 토큰이라고 가정할때 이와 같은 차원으로 구성된다.
위의 수식은 번째의 이미지 토큰을 기준으로 모든 텍스트 토큰과의 유사성을 계산후 가장 큰 유사도를 가지는 텍스트 토큰을 사용하게 된다.
추후 모든 이미지 토큰에 대해 각각 토큰에 맞는 최대 유사성을 구하고 이를 평균내어 Loss로 사용하게 된다.
Image에 대해 공식화를 하면 위와 같이 나오며 이때 이다.
텍스트의 경우 위와 같으며 동일하게 이다.
결과적으로 토큰별로 최대 유사성은 각 이미지 패치에 대해 가장 유사한 텍스트 토큰을 찾는것이며 텍스트 또한 마찬가지다
이를 Contrastive loss로 사용함으로써 이미지 패치와 텍스트 토큰 간의 fine-grained alignment을 학습하게 된다.
이때 이러한 계산이 메모리적으로 비효율적이기 때문에 임베딩 사이즈를 256으로 줄인다.
또한 최종 레이어의 경우 fp16으로 계산하며 이미지가 몇개의 대표적인 토큰으로 표현가능할 것이라고 믿어 각 모든 텍스트(각 이미지)중에서 토큰별 최대 유사성 점수가 가장 높은 25% 토큰만 사용하게 된다.
3-3. PROMPT ENSEMBLE AND TEMPLATES
-
텍스트 템플릿의 경우 “a photo of a {label}.”의 라벨을 사용한다.
-
논문에서는 “a photo of a {label}.”의 템플릿만 사용되지만 실험으로 여러 프롬프트를 앙상블 하여 사용하게 된다. 이때 앙상블의 기준은 각 프롬프트 템플릿에 대해 토큰별 유사성의 평균을 이용한다.
3-4. IMAGE AND TEXT AUGMENTATION
- AUGMENTATION의 경우 이미지 확대를 위해 AutoAugment를 사용하게 된다.
- 텍스트의 경우 Back Translation을 사용하게 된다.
3-4. PRE-TRAINING DATASET
-
CLIP 및 ALIGH은 각각 400M, 1800M으로 구성된 Image-Text Pair를 사용하였지만 FILIP는 300M으로 구성된 Image-Text로 구성된다.
-
또한 Conceptual Captions 3M(CC3M), Conceptual 12M(CC12M) 및 Yahoo Flickr Creative Commons 100M(YFCC100M)을 포함한 3개의 공개 데이터 세트 도 사용됩니다. 사전 훈련에는 약 3억 4천만 개의 이미지-텍스트 쌍이 사용된다.
4. 실험 및 결과
4-1. Zero-ShotImage Classification
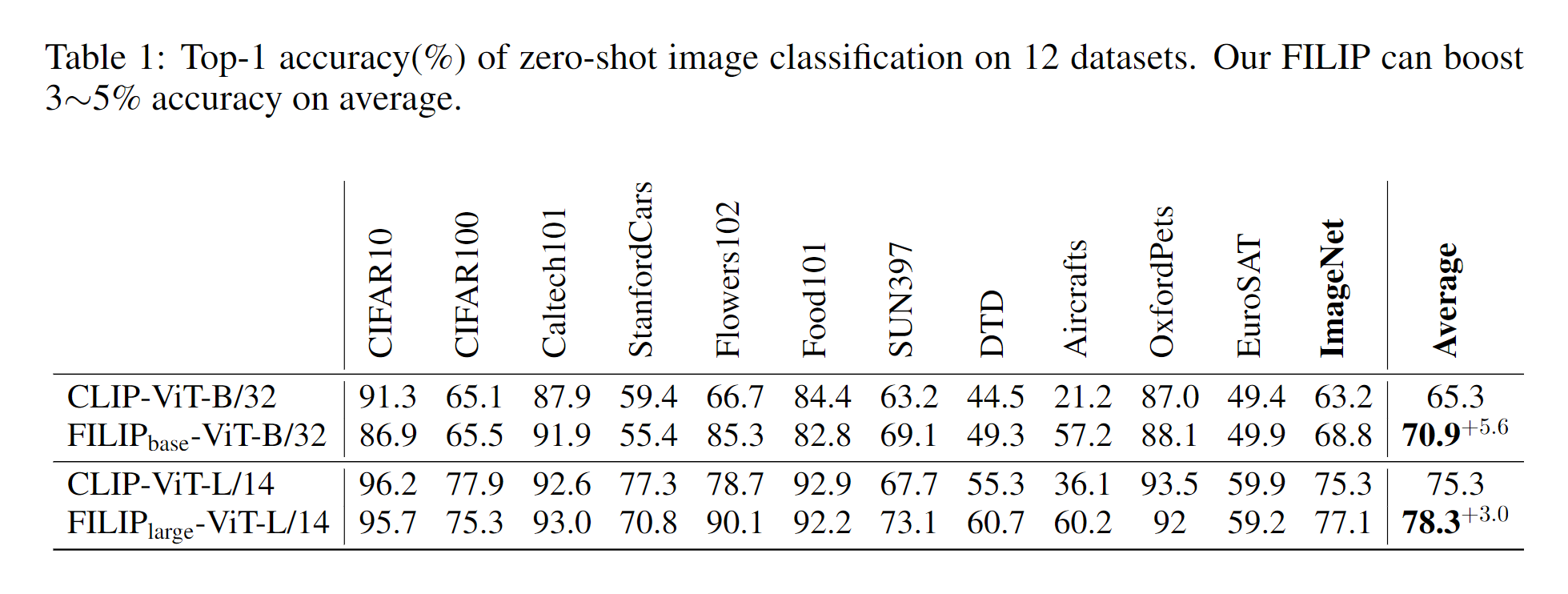
제로샷의 경우 더 작은 데이터 세트를 사용하였음에도 불구하고 CLIP보다 더 뛰어난 성능을 달성하였다.
4-2. IMAGE-TEXT RETRIEVAL
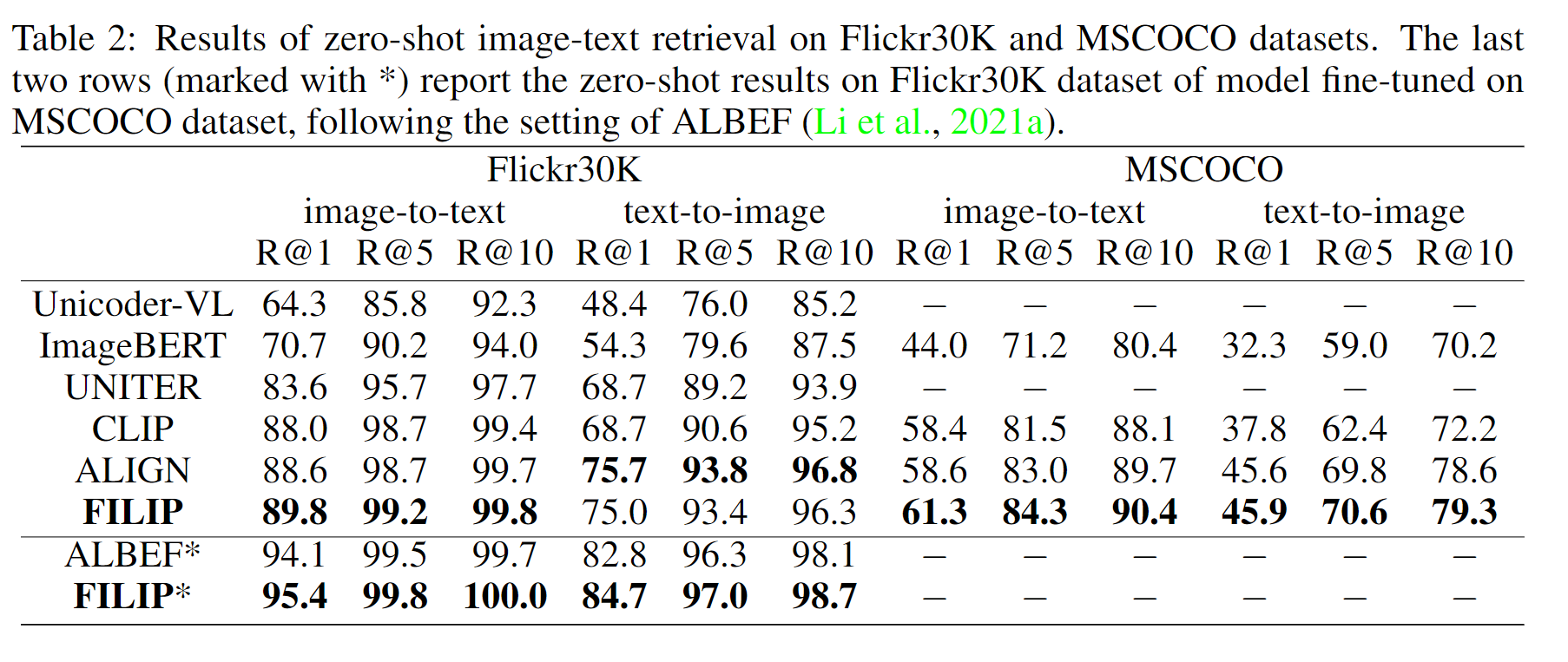
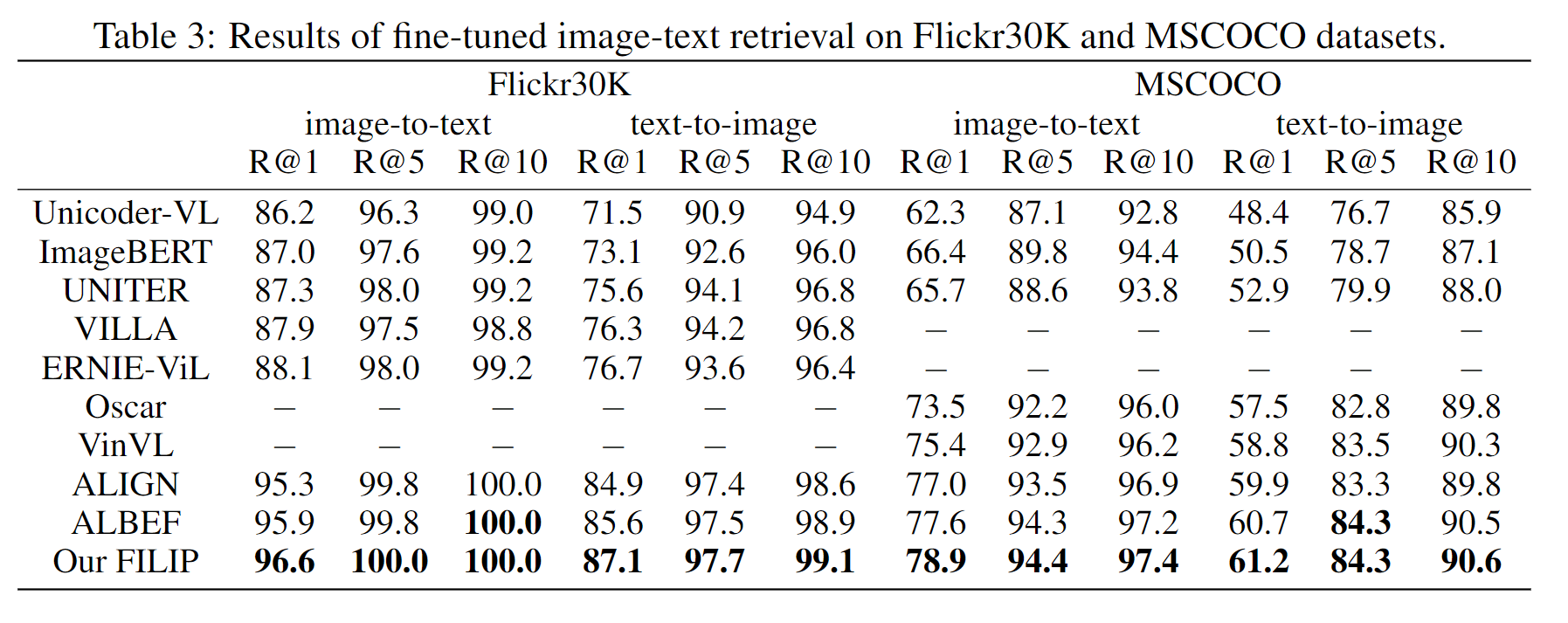
FILIP은 Flickr30K의 제로샷 텍스트-이미지 검색을 제외하고 Flickr30K 및 MSCOCO 데이터 세트의 모든 측정 항목에서 최첨단 성능을 달성하였으며 파인튜닝을 하였을때는 전부 SoTA를 달성하였다.
4-3. ABLATION STUDY
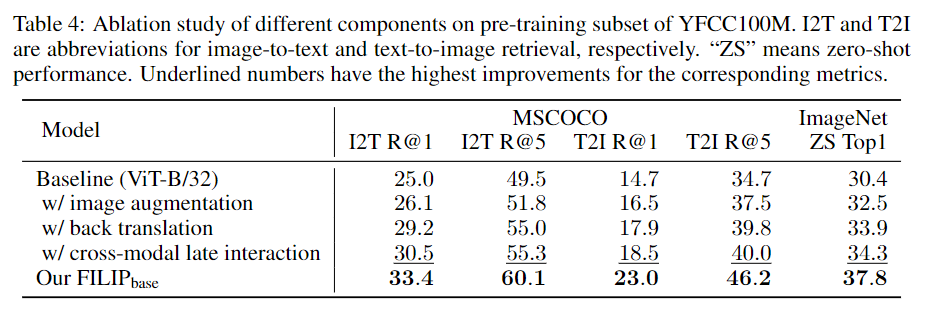
각종 어그멘테이션 기법과 CROSS-MODAL LATE INTERACTION기법을 제외하였을때다 모든 구성요소가 성능 증가에 기여했으며 CROSS-MODAL LATE INTERACTION의 경우 높은 성능 증가를 나타내었다.
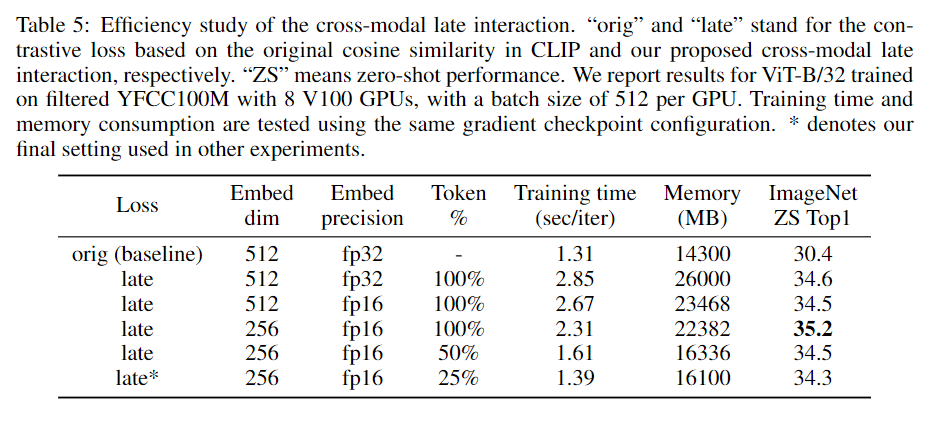
다양한 설정으로 훈련하였지만 신기하게 256 임베딩 사이즈가 제일 좋은 성능인것은 조금 특이하다.
4-4. VISUALIZATION OF FINE-GRAINED ALIGNMENT
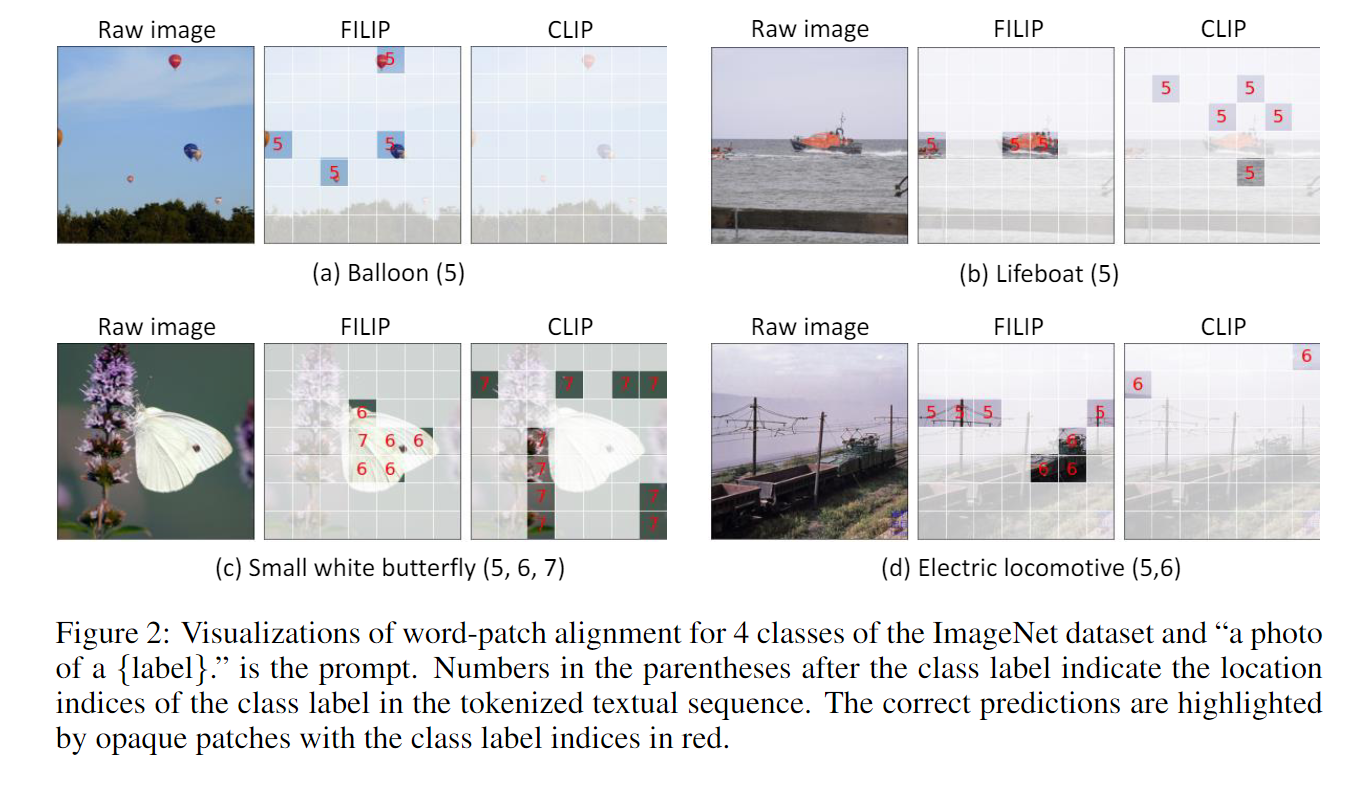
토큰별 유사성을 기반으로 각 패치의 대한 유사성을 확인하였다. CLIP은 유사성이 없는 반면 FILIP은 확인이 뚜렷하게 된다. Cross attention map과 유사하다.
8. Conclusion
토큰별 유사성을 이용해 보다 세분화된 Contrastive Learning을 진행하였다.
추후 MLM, MIM을 이용하여 보다 높은 성능을 달성 할 수 있을 것이라고 생각된다.
9. 회고
주말에 간략하게나마 작성해보았는데 코드 작성이 없는게 아쉬울 따름이다. 추가적으로 대부분 CLS 토큰을 써서 수행하는데 다른 토큰들을 활용하는 논문들은 없나? 해서 궁금증이 있었지만 어느정도 해결된 부분이라고 생각된다. 그래도 아직 초기 임베딩 차원을 활용한 것을 읽지 못해서 아쉽다. MIM은 확실히 활용히 필요하다고 생각된다. BEIT라도 읽어야겠다.
