
NAVERCONNECT 부스트 캠프 AI Tech
NLP 최종 프로젝트 법률 조언 웹 서비스 ‘LawBot ’ 팀 회고 |
|---|
Member 김주원_T5056, 강민재_T5005, 김태민_T5067, 신혁준_T5119 윤상원_T5131
1. 프로젝트 개요
1.1 프로젝트 주제
사용자가 채팅 웹을 통해 자신이 처한 법률적 상황을 제시 하면 , 입력에 대한 문맥을 AI 모델이 이해하여 가이드라인을 제시 하고 , 유사한 상황의 판례를 제공 하는 서비스
1.2 프로젝트 기획 의도 및 배경
- 기획 배경:

- 국제적으로 리걸 테크 산업은 매우 빠르게 발전하고 있으며, 국내에서도 관련된 서비스 수요가 크게 증가하고 있다. 2. 일반인들에게는 법률 용어 및 문장은 난해하여 해석하기 어려워 이해도가 낮은 편이다. 3. 진입 장벽도 높지만 비싼 변호사 상담비 때문에 법률적인 지식에 접근하기에 경제적인 부담도 상당히 크다.
-
해결 방안: 따라서 윤슬팀은 이러한 상황을 해결하기위해 법률 상황에 대해 이해하기 쉬운 가이드라인을 제시하고 , 관련된 유사판례 및 법률 조항을 제공함으로써 법의 장벽을 낮출 수 있는 가벼운 법률 상담 서비스를 제공하고자 한다.
1.3 기존 리걸 테크.서비스와의 프로그램의 차별점
| 개발사 | 리걸 테크 서비스 | 기능 |
|---|---|---|
| 로아팩토리 | 모두싸인 | 온라인 계약서 체결 서비스 |
| 헬프미 법률사무소 | 헬프미 | 변호사 찾기 , 지급명령 , 등기 , 상속 온라인 법률 서비스 |
| 로앤컴퍼니 | 로톡 | 변호사 +사례 검색 및 온라인 법률 상담 및 변호사 매칭 |
| 아미스쿠렉스 | 로폼 | 문서작성 , 변호사 상담 및 예약 |
| 보리움 법률사무소 | 머니백 | 가압류 신청 |
-
기존의 서비스 : 표에 제시된대로 변호사를 매칭시켜주거나 여전히 어려운 법률 검색만을 제공
-
LawBot 의 차별점: AI 모델을 이용하여 법률적인 분쟁 상황에 대한 유사판례를 찾아 주고 , 가벼운 가이드라인을 직접 생성해서 빠른 시간내에 User 에게 제공한다는 점에서 차이점이 있다.
1.4 기술 스택 & 개발 환경

2. 프로젝트 팀 구성 및 역할
| 이름 | 역할 |
|---|---|
| 강민재 | 데이터 탐색 , 대한법률구조공단 사이버 상담 웹사이트 QA 데이터 크롤링 모듈 구현 전처리 모듈 구현 , 데이터 파이프라인 구축 , 학습 데이 터셋 구축 |
| 김태민 | Project Manager , 노션 협업 기구 관리 (Kanban Board) + PR/ISSUE Template 등록 , UI/UX 개발 , 프로토타이핑 , 프론트엔드 구축 , LLM 모델 평가지표 개발 , 반응형 웹 페이지 제작 |
| 김주원 | LLM 모델 평가지표 개발 (PPL), BM25/Bert 유사도 기반 리트리버 개발 , LLM 모델 ( koalpaca,llama, kullm) 학습 및 인퍼런스 코드 구현 , LLM 모델 (koalpaca,llama, kullm) 파인튜닝 |
| 윤상원 | 답변 생성 API 구현 , pytest 기반 단위 테스트 구현 , self-hosted runner 를 이용한 CI 파이프라인 구축 , 로드 밸런싱 적용 , LLM의 프롬프트 엔지니어링 , FastAPI 기반 백엔드 서버 구축 , 모델 서버와 router 간 ssh 터널링 구축 , Airflow를 이용한 재학습 파이프라인 구축 , Auto Scaling을 통한 Failover |
| 신혁준 | 데이터 탐색 , 대한법률구조공단 법률상담사례 데이터 크롤링 모듈 구현 , 맞춤법 검사기 크롤러 모듈 구현 , 파이프라인 구축 , 학 습 데이터 셋 구축 |
3. 프로젝트 수행 절차 및 방법
- 최종 프로젝트는 짧은 4 주간의 개발기 간이 주어져따. 따라서 윤슬 팀은 최종 프로젝트를 구현하기 위해 애자일하게 문제를 접근하여 Top Down 방식으로 개발할 부분을 정리하 고 단계적으로 서비스를 고도화 를 진행했다.
3.1 협업 관련 Ground Rule
-
원활한 협업을 진행하기위해 Notion 과 Github 의 협업 Rule 을 정해 To do List 및 코드를 관리했습니다. 1. main branch Pull Request 관련 Rule
-
Level 단위 로 develop branch 에서 main 에 merge 한다
-
배포용 브랜치로 develop 에서 refactoring, bugfix 가 완료 된 상태에서 push 한다 .
-
main 브랜치로 merge 는 팀원 4 명 중 2 명이상 accept 한 경우 merge 를 진행한다 .
2. Develop branch Pull request 관련 Rule
- feature 에서 기능이 모듈화가 완료된 경우 (feat→refactor) Pull Request 를 진행한다 .
- feature branch 에서 develop branch 로 merge 를 진행할 때 conflict 가 생길 경우 관련한 캠퍼들이 해당 이슈를 해결한 다. (새로운 feature branch 를 사용 혹은 이전 feature branch 에서 내용 수정 )
- main 브랜치로 merge 는 팀원 4 명 중 2 명이상 accept 한 경우 merge 를 진행한다 .
3. feature Branch Commit 관련 Rule
- feature 브랜치는 develop branch 에서 feat-이슈번호/브랜치이름 형식으로 생성한다.
- ex) feat-12/crawler, feat-1/skeleton
- commit 메세지의 Header(변경내용)와 Footer(이슈번호)는 필수, Body는 선택사항
- header 의 prefix 는 feat , fix, docs , style , refactor , perf 사용
- 하나의 commit 은 코드의 유의미한 변화가 있는 최소 크기로 나누어서 올린다 .
4. 개발 관련 Rule
- 진행해야 하는 실험은 GitHub Issue에 등록한다 . 실험 진행 상황도 GitHub Issue에 등록
- 같은 디렉토리에서 작업하거나 같은 모듈을 작업해야 할 경우 , conflict가 발생하지 않도록 당사자들이 합의하여 합의된 내용을 해당 issue template 에 기술한다 .
- 진행중인 개발 내용은 노션의 Kanban Template 진행현황에 등록한다 .
5. 회의 관련 Ground Rule
- 전원이 진행하지 않는 Small 회의는 다양한 방식 (Zep, Google Meet, Zoom)으로 진행이 가능하나 회의가 끝났을 때는 끝났을 때 반드시 회의록에 기록해두고 , 다음 피어세션 때 협의 한 내용 , 아이디어 등을 공개한다 .
- 회의는 피어세션 시간에만 이루어지는 것을 원칙으로 한다.
- 10:00 ~ 15:00에도 안건 등록이 가능은 하지만 가급적 정해진 시간 내에 업로드 부탁드립니다 . 제안된 안건이 적을 경우 반영될 수 있지만 , 그렇지 않을 경우 다음 날에 논의하게 될 수도 있습니다 .
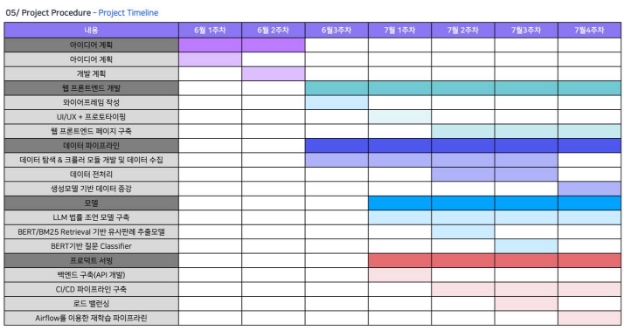
3.2 프로젝트 진행 Time line
- 프로젝트는 다음과 같은 순서로 진행되었으며, 서비스에 필요한기능들을 먼저 구현하고, 이후 프로젝트의
4. 프로젝트 수행 결과
-
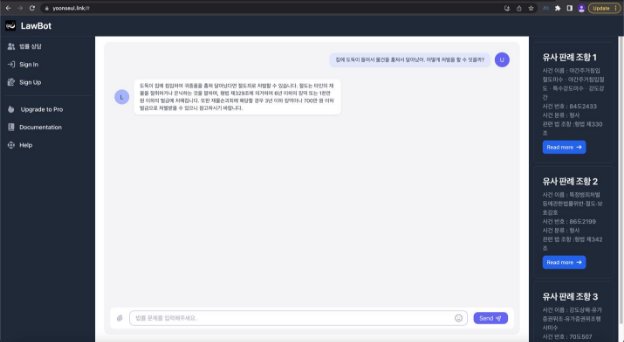
완성된 홈페이지 링크 : https://yoonseul.link
-
발표 링크 : https://www.youtube.com/watch?v=fgboxtWM4B4 - Github 링크 : https://github.com/boostcampaitech5/level3\_nlp\_finalproject-nlp-08
4.1 서비스 Use Case
- 웹 서버 접속
- 메시지 프롬프트 창에 자신이 처한 법률적인 상황 입력
- AI 모델이 상황 맥락을 이해하여 법적인 가이드라인을 메시지 형태로 제공
- 우측 사이드바에서 사용자가 입력한 상황과 비슷한 최대 3 가지의 유사 판례 제공
- 링크를 통해 법률 정보를 직접 확인 가능
4.2 Service Architec ture
네이버 커넥트 재단으로부터 제공받은 V100 서버 4 대를 모두 활용하기 위해 첫 설계 때부터 서비스 확장이 쉬운 마이크로 서비스 아키텍처를 고려했습니다 . 또한 서비스 간의 상호 의존도를 낮춰 서버에 장애가 발생할 경우 전체 서비스가 중단되는 것을 방지하고자 하여 위와 같이 웹 서버 , 모델 서버를 독립적으로 분리하고 API를 통해 서로 통신하는 구조로 설계했습니다 . 이를 통해 한 대의 V100 서버에 장애가 발생하더라도 나머지 서비스는 전혀 영향을 받지 않고 서비스를 제공할 수 있습니다 .
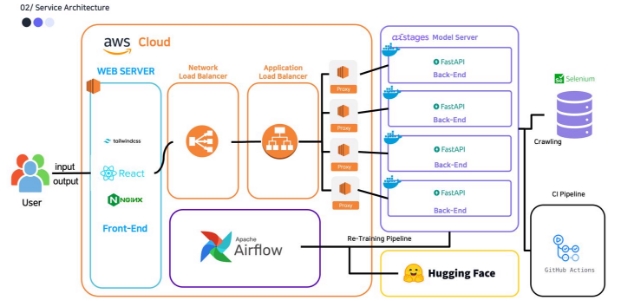
확장성있고, 효율성있는 서비스를 제공하기 위해 다음과 같은 시스템을 구현했다.
4.2.1 CI 파이프라인
-
구현 배경: 소스 코드를 작성하거나 수정할 때마다 어플리케이션의 모든 기능이 정상적으로 동작하는지 확인하는 것은 불가능에 가까웠 다. 그러나 , 문제를 뒤늦게 발견할수록 시간적인 비용이 더 많이 들었기 때문에 테스트 자동화가 필요했 다.
-
해결 방안: GitHub Actions 를 활용하여 develop 브랜치로 PR 이 발생할 때 사전에 구현한 pytest 기반의 단위 테스트가 실행되도록 CI 파이프라인을 구축 했다. 이번 프로젝트가 LLM 모델을 활용하기 때문에 GitHub 에서 제공하는 서버로 답변 생성 테스트를 진행하는 것에 한계가 있었기 때문에 V100 서버를 self -hosted runner 로 등록 하여 CI 파이프라인을 운영했 다.
-
기대효과: CI 파이프라인을 통해 매번 테스트를 진행해야 하는 번거로움을 해소하고 , 사전에 코드상의 문제를 파악하여 효율적으로 프로젝트를 진행할 수 있었다.
4.2.1 로드 밸런싱 적용
-
구현 배경: 모델이 하나의 답변을 생성하고 유사 판례를 찾아오는 데 약 20 초가 소요되기 때문에 다수의 이용자가 동시에 접속해 있는 경우 , 한 대의 서버로는 트래픽을 감당하기 어려웠 다.
-
해결 방안: 트래픽을 4 대의 V100 서버에 분산하기 위해 AWS 의 Elastic Load Balancing을 사용했 다. V100 서버 각각에 proxy 서버의 역할을 하는 EC2를 두고 , Application Load Balancer를 4 대의 proxy 서버와 연결하여 로드 밸런싱을 적용 했다. 이때 , Application Load Balancer는 고정 IP 주소를 지원하지 않기 때문에 Network Load Balancer 를 Application Load Balancer 의 앞 단에 배치하여 IP 주소를 고정했 다.
-
기대효과: 로드 밸런싱을 통해 기존 1 대의 모델 서버로 서비스를 운영했을 때보다 4 배 많은 트래 픽을 소화할 수 있었 다. 또한 Applcation Load Balancer의 기본 기능 중 하나인 health check 를 통해 모델 서버에 장애가 발생할 경우 , 해당 서버로 트래픽을 보내지 않음으로써 서버의 장애가 서비스의 장애로 이어지는 것을 방지 할 수 있었 다.
4.2.1 모델 학습 파이프라인
-
구현 배경: 매주 새롭게 추가되는 법률 상담 사례들을 데이터셋에 추가하여 주기적으로 모델을 다시 학습시키기 위해 Airflow 를 활용한 모델 학습 파이프라인을 구축했 다
-
해결 방안: 일주일마다 HuggingFace 저장소에 올라온 새로운 데이터셋을 가져와 모델에 입력 가능한 형태로 전처리한 뒤, HuggingFace 의 Trainer 로 모델 학습을 진행합니다 . 학습이 끝난 모델은 모델 서버에서 사용 가능하도록 HuggingFace 의 저장소에 업로드했다.
4.2.2 모델 학습 파이프라인
-
구현 배경: 비용 절감을 위해 하드웨어 성능이 낮은 EC2 인스턴스를 사용하다보니, 종종 웹 서버에 장애가 발생했다.
-
해결 방안: 이 문제를 해결하기 위해 웹 서버 그룹과 연결된 Application Load Balancer가 주기적인 health check 로 서버의 장애를 빠르게 파악하고 , Auto Scaling 기능을 통해 새로운 웹 서버를 장애가 발생한 웹 서버와 교체시켰 다.
-
기대효과: 웹 서버의 장애를 빠르게 Failover하여 안정적으로 서비스가 유지될 수 있도록 하였다.
4.3 Data Pipeline

데이터는 위와 같이 단계별로 나누어 목표를 설정하고 데이터를 탐색 , 수집 , EDA 및 전처리 , 생성모델을 통한 증강을 하여 학습데이터 셋을 구축하였 다.
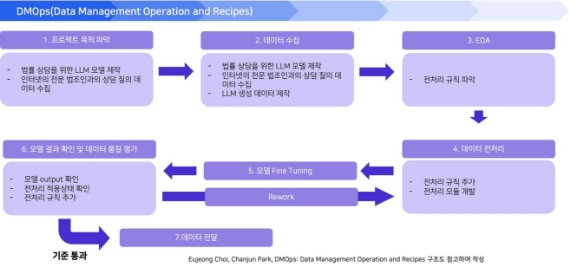
데이터 파이프라인을 순환 구조도로 도식화하여 DMOps 구조도로 나타내면 위와 같다. 4.3.1 학습 데이터셋
데이터를 탐색하여 크롤링 이전에 준비할 수 있는 데이터를 HuggingFace, AiHub, Github을 통해 확보하였고 , 부족한 법률 QA 데이터 는 크롤링 과 생성 모델(GPT)을 통해 학습 데이터를 추가로 확보하였다.
- 법률 QA 데이터
| 데이터셋 이름 | 데이터 개수 | 출처 |
|---|---|---|
| easylaw_kr | 2,195 |
|
| LegalQA | 1,830 | https://github.com/haven-jeon/LegalQA
|
| 대한법률구조공단의 법률상담사례 데이터 | 9,994 |
|
| 대한법률구조공단의 국내 사이버상담 데이터 | 2,463 | https://www.klac.or.kr/legalstruct/cyberConsultation.do |
| Open AI GPT증강 | 8,616 | - |
- 판례 데이터
| 데이터셋 이름 | 데이터 개수 | 출처 |
|---|---|---|
| 법률 /규정 (판결서 , 약관 등) 텍스트 분석 데이터 | 77,382 | Aihub |

4.3.2 EDA & 전처리
학습에서 의도하지 않는 편향된 데이터를 생성하지 않기위해 데이터를 Heuristic 하게 확인하는 EDA를 진행하였고 이를 기반으로 Hallucination 을 방지하거나 개인정보를 보호할 수 있는 전처리를 진행 했다.

4.2. 3 데이터 증강
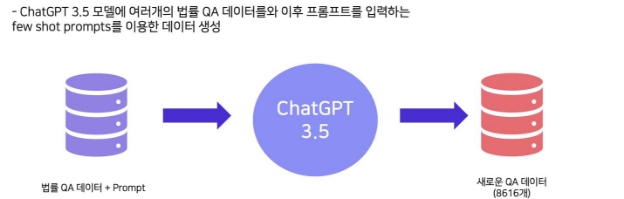
모델 성능을 더욱 개선하기 위하여 GPT 3.5 모델을 사용하여 8,616 개의 새로운 QA 데이터를 생성 했다. 데이터 생성 시 크롤링 데이터를 포함하여 few shot prompts 를 설계하여 사용 하여 데이터 증강을 진행했다.
4.5. 모델
Model Architecture
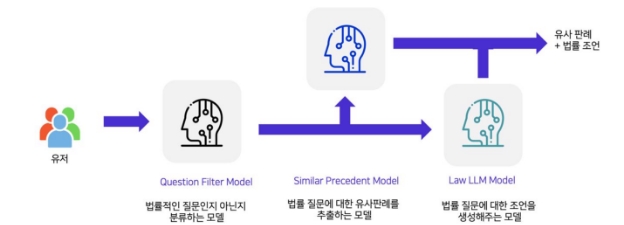
유저가 입력하면 모델에서는 Question Filtering 모델을 통해 법률적인 질문인지 아닌지 일차적으로 필터링한다. 이후 사용자가 입력한 질문이 법률적인 질문이라면 Similar Precedent Model 과 Law LLM Model 통해 유사판례 를 추출하고 법률 조언을 생성하여 제공한다.
4.5.2 Question Filtering Model
- 모델을 활용한 이유
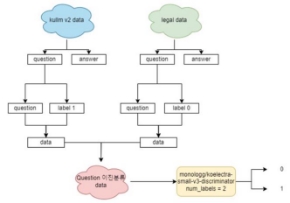
1. 법률 질문이 아닌 답변에 대답하지 않기 위해 활용했다. 2. 큰 LLM 모델을 사용하여 사전에 분류함으로써 법률질문이 아닌 데이터에 대한 Latency 를 줄이기 위해서 사용했다. (적은 GPU사용 )
- 학습 방법
학습 방식은 법률 질문을 0, 법률질문이 아닌 데이터를 1 로 라벨링 하려 이진 분류를 하도록 모델을 학습시켜 질문을 구분할 수 있도록 했다.
4.5. 3 Precedents Similarity Model
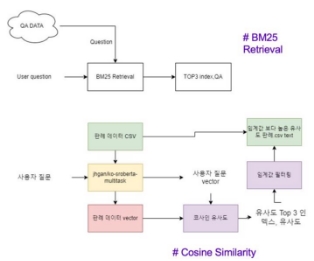
- 모델을 활용한 이유
Similar Precedent 모델은 사용자 법률 질문을 QA 데이터셋에서 유사한 질문을 추출하기 위해 sentence Bert 기반의 모델을 사용했 다.
- 학습 방법
모델은 사용자의 법률 질문과 유사한 qa 데이터 셋을 추출 한다. 이후 추출된 질문의 답변과 사용자의 입력을 concat 하여 판례 데이터셋에서 유사도가 높은 상위 판례데이터 세 개를 추출하여 사용자에게 유사한 판례로 제시 한다.
4.5.4 Law LLM Model
- 모델을 활용한 이유

법률 분쟁 상황의 경우 개인마다 매우 특수한 상황을 겪는 일이 대부분이기 때문에 일반화하기 어렵다. 따라서 Retrieval 을 사용한 기계 독해 같은 태스크로 문제를 해결하기 어려운 상황 이다. 따라서 LLM의 경우 기학습된 방대한 정보와 더불어 fine-tuning 에 사용한
법률 지식을 사용하여 다양하고 특수한 상황에 유연하게 대응하여 답변을 생성가능 하다고 판단하여 LLM 모델을 법률 조언을 생성하는 모델로 선택하여 개발하게 되었다.
- 학습 방법
1. 현재 훈련은 LoRA: Low-Rank Adaptation of Large Language Models 논문을 참고하여 전체 훈련 파라미터의 0.1% 만 Fine Tuning 하는 방식으로 학습
- 채팅 형식으로 학습된 모델에 법률 QA 데이터를 학습하여 모델을 구성
- bitsandbytes(4bit) : 32bit 에서 4bit 로 계산하여 모델의 크기 감소
- PEFT(Parameter -Efficient Fine-Tuning) : 기존의 원본 LLM 의 가중치를 동결 è각 레이어 마다의 추가 선형 레이어 (LoRA)를 삽입 è 이를 훈련 시켜 VRAM의 감소와 훈련 계산량의 감소로 모델을 Full Fine-Tuning 에 가까운 학습 가능
- 모든 파라미터를 학습하는 방식이 아니기에 기학습에 사용된 프롬프트를 그대로 학습에 사용 .
.
- 사용했던 프롬프트
KULLM: 아래는 작업을 설명하는 명령어입니다. 요청을 적절히 완료하는 응답을 작성하세요.\n\n### 명령어:\n{x['question']}\n\n### 응답:\n{x['answer']}
4.5. 5 평가지표
LLM 모델은 명확한 평가지표가 없어 직접 평가지표를 만들어 평가했 다. 평가지표를 만들 때 고려했던 부분은 도메인 특성상 법률적인 정확도가 중요하므로 법률적인 정확도와 언어의 자연스러 움 두가지 모두 평가할 수 있도록 metric 을 제작하여 평가했 다.
Dialogue Evaluation Metric

- Kullm 모델의 Dialogue Evaluation Metric 평가요소를 도메인에 맞게 변형하여 활용하였고 , 해당 지표를 직접 변호사에게 의뢰하여 답변을 평가했 다. 추가로 모든 모델들은 모델 A, B, C ... 등 모델 이름을 가리고 블라인드 평가를 진행했 으며, 명확한 평가지표를 만들기 위해 ChatGPT, BARD 모델과 함께 평가를 진행하였 습니다. 최종적으로 저희가 구축한 kfkas/legal-llama-2-ko-7b-Chat 모델이 가장 좋은 성능을 보였다.
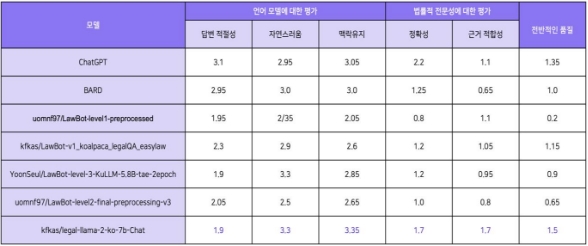
Perplexity
- 얼마나 생성모델이 법률적인 용어를 생성해내는지 평가하기 위해 Perplexity 평가지표를 활용하였습니다 . 낮을 수록 좋은 값을 나타내는 metric 인데 , 크롤링 데이터와 탐색한 데이터로 학습한 모델들이 대체로 높은 성능을 나타내는 경향을 보였 다.

5. 자체 평가 의견
5.1. 잘한 점
- 서비스에 필요한 우선순위를 두어 3 주간의 시간안에 목표했던 서비스 구현에 성공했 다.
- Airflow 를 이용한 학습 파이프라인을 구현하여 높은 수준의 MLOps 서비스를 구현할 수 있었 다.
- Kanban Board, Github 등 다양한 협업 툴을 효과적으로 사용하여 협업을 진행 했다.
- 트래픽 등 다양한 에러 상황을 가정 하고 구현하여 안정적인 서비스를 배포할 수 있었습니다 .
- 데이터를 눈으로 확인하며 규칙을 찾고 전처리를 만들며 데이터에 대한 인사이트를 기를 수 있었 다.
5.2 보완 및 개선 방향
5.2.1 개선 방안 서비스 측면
- 질문 히스토리 조회 기능 : 사용자가 이전에 질문했던 내용을 조회할 수 있는 기능을 추가할 예정입니다 . 이 기능을 위해서 DB 서버를 모델 서버와 분리하여 모든 모델 서버가 DB 서버에 접근할 수 있도록 아키텍처를 구성할 예정입니다 .
5.2.2 개선 방안 데이터 측면
- 멀티 쓰레드 데이터 파이프라인 : 멀티쓰레드를 이용한 데이터 크롤링 파이프라인을 구축한다면 보다 효율적으로 데이터를 구축할 수 있을 것 입니다 .
5.2.3 개선 방향 모델 측면
- RLHF: 실제 변호사가 직접 데이터를 만들어 점수를 평가하여야 보상모델을 만들고 RLHF를 이용하여 학습 시킨다면 성능을 개선할 수 있다고 생각합니다 .
- Full Finetuning Pretrained model: 대부분의 한국 Pretrained model 에는 한국법률이 추가되지 않았습니다 . 따라서 많은 Hallucination 과 정확하지 않은 답변을 출력하게 됩니다 . 따라서 보다 고성능의 GPU를 이용하여 model 을 처음부터 한국 법률을 포함시켜 훈련하게 될 경우 보다 높은 정확성을 달성 할 것이라고 생각합니다 .
- 파라미터의 한계 : 실제 서비스되는 대형 LLM의 경우 30B, 65B, 70B의 대규모 언어 모델로 서비스가 진행됩니다 . LLM의 특성상 모델 의 파라미터가 많을수록 보다 높은 정확성을 달성하게 되는데 현재 가진 GPU의 한계로 최대 12.8B 이며 인퍼런스의 경우 5.8B 를 사용할 수 밖에 없었습니다 . 보다 고성능 GPU를 사용하여 많은 파라미터를 가진 모델을 사용하게되면 성능이 향샹될 것입니다 .
- DPR: 현재로써는 프로젝트의 기간 상 유사판례를 가져올때 허깅페이스의 Pretrained 모델들을 사용하고 있습니다 . 법률로 DPR을 진행하여유사판례 , QA를 가져올 경우 보다 높은 유사도와 정확 도를 달성할 것이다 .
6. 참고 문헌 (References)
[1] Edward Hu, Yelong Shen, Phillip Wallis Zeyuan, Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen (2021), LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
NLP KLUE 프로젝트 (Relation Extraction Project Report) NLP-08 조 개인 회고
🧑💻 김태민 _T5067 캠퍼 ![ref3]
1. 나는 내 학습 목표를 달성하기 위해 무엇을 어떻게 했는가 ?
모델 파트를 맡음으로써 총 4 개의 모델·모듈을 구현하였다 . 판례를 가져오는 BERT, QA를 가져오는 BERT, BM25 그리고 사용자의 질문이 법적 질문인지 판단하는 필터링 BERT, KuLLM 기반 Legal-GPT, LLama2-ko 기반 법률 LLama 를 학습하고 구현하였다 . 비록 다른 조는 다 같이 모델을 구현하였지만 , 우리 조는 모두가 각각의 파트를 맡음으로써 혼자 모델을 구현하였는데 기존에 계획한 모든 기능을 구현하였다 . 기존의 부스트캠프는 LLM을 다루지 않아 한번 다루어 보고 싶었는데 단순 다음 토큰을 예측하는 LLM을 채팅형식으로 튜닝하여 직접 만들고 그걸 다시 법률로 튜닝하는 과정을 거쳐 LLM에 대해 심층적인 공부가 될 수 있었다 . 또한 4bit 의 양자화와 peft lora를 사용하여 대규모 모델들 을 튜닝하고 직접 훈련하고 만드는 과정을 경험하여 매우 소중하고 귀한 경험이었다.
2. 마주한 한계는 무엇이며 , 아쉬웠던 점은 무엇인가 ?
RLHF나 DPR을 적극 활용하지 못한 점이 아쉬웠다 . 각종 Retrieval 할 때 DPR을 활용하여 훈련하면 더 정확한 결과가 나온다는 것은 많이 입증되었지만 , LLM에 집중하다 보니 짧은 기간상 구현하지 못하였다 . 또한 RLHF를 법률 QA 데이터가 부족해 처음에는 활용 안 하려고 했지만 직접 일반화 된 Chat 모델을 만드는 과정을 겪으면서 RLHF를 해볼까 했지만 , 이를 구현하는 것은 시간이
너무 많이 들어 아쉬워서 각종 레포나 코드로만 돌려보았다 . 또한 Lang chain으로 멀티 턴을 구현하였지만 , 훈련한 LLM이 멀티 턴에 대해 매우 취약하다는 단점을 발견하여 멀티턴을 구현하지 못한게 아쉬웠다 .
3. 한계 /교훈을 바탕으로 다음 프로젝트에서 시도해보고 싶은 점은 무엇인가 ?
한계로써 다음에는 단순한 파인튜닝을 넘어 RLHF 을 활용 하며 멀티 턴에 대해 생각하며 튜닝을 진행하고 싶다 . 그리고 Lang chain 을 활용하여 직접적인 도큐먼트를 불러오는 등 다양한 방안을 활용하고 싶다 . 또한 CV를 주로 했던 입장으로써 이미지도 함께 입력받는 LLM인 LLaVA를 써서 보다 다양하고 멀티 모달적인 부분을 가져가고 싶다 .
2. 나는 어떤 방식으로 모델을 개선했는가 ?
모델은 기존에 KuLLM이 Chat 형식으로 튜닝된 것을 가져왔지만 최근 LLama-2 가 출시되면서 이를 직접 한국어 채팅 버전으로 만들어 허깅 페이스에서 많은 '좋아요 '와 다운로드 수를 기록하였다 . 또한 데이터적인 부분에 GPT데이터와 KoAlpaca 데이터를 도입하며 변호사의 평가에서 단순 법률 QA 데이터를 넣은 것보다 높은 점수를 기록하였다 . 모델을 직접적으로 수정한 부분은 LLama 를 썼다는 점이며 확실히 데이터에 의존성이 높은 것을 체크하여 필요한 데이터를 데이터 파트에 요청하였다는 점이다 .
3. 협업 과정에서 잘된점/아쉬웠던점은 어떤것이 있는가?
협업 과정에서 아쉬운 점은 전혀 없다 . 완벽한 분업이 이루어 졌으며 Git 을 완벽하게 활용하였다 . 프론트 1 명, 백 1 명, 모델 1 명, 데이터 2 명으로 분담으로 이루어진 게 다른 조들 보다 완성도 있는 프로젝트를 만들 수 있었던 원동력이라고 생각된다 .
NLP 최종 프로젝트 (Wrap -Up Report) 김태민 T5067


](https://huggingface.co/datasets/juicyjung/easylaw%5C_kr!%5B%5D(Aspose.Words.27c0a0b4-4c37-47f5-862b-a962a1a24291.015.png)){kind=link}
](https://github.com/haven-jeon/LegalQA!%5B%5D(Aspose.Words.27c0a0b4-4c37-47f5-862b-a962a1a24291.016.png)){kind=link}
](https://www.klac.or.kr/legalinfo/counsel.do!%5B%5D(Aspose.Words.27c0a0b4-4c37-47f5-862b-a962a1a24291.017.png)){kind=link}
잘 읽었습니다