
Data visualization
Bar Plot
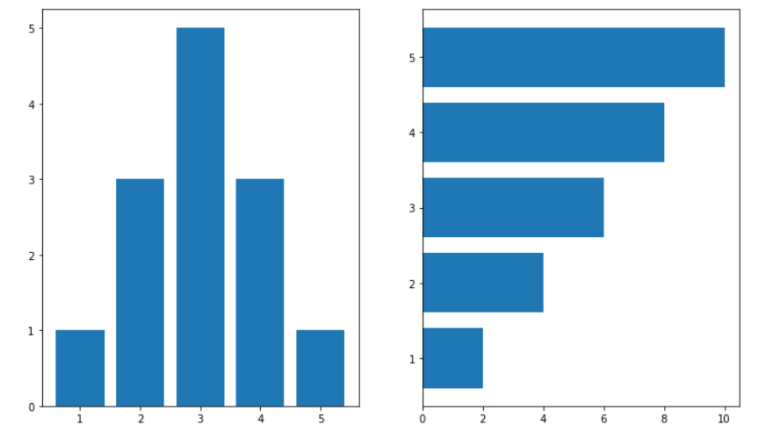
직사각형 막대를 이용하여 데이터의 값을 표현
주로 수직,수평으로 분류
수직
x값 : 범주 y값 : Value
import matplotlib.pyplot as plt
# 데이터
labels = ['A', 'B', 'C', 'D', 'E']
values = [10, 25, 20, 30, 15]
# 그래프 그리기
plt.bar(labels, values)
# 그래프 타이틀과 라벨 설정
plt.title('Vertical Bar Plot')
plt.xlabel('Categories')
plt.ylabel('Values')
# 그래프 보여주기
plt.show()수평
x값 : Value y값 : 범주
import matplotlib.pyplot as plt
# 데이터
labels = ['A', 'B', 'C', 'D', 'E']
values = [10, 25, 20, 30, 15]
# 그래프 그리기
plt.barh(labels, values)
# 그래프 타이틀과 라벨 설정
plt.title('Horizontal Bar Plot')
plt.xlabel('Values')
plt.ylabel('Categories')
# 그래프 보여주기
plt.show()Stacked Bar Plot
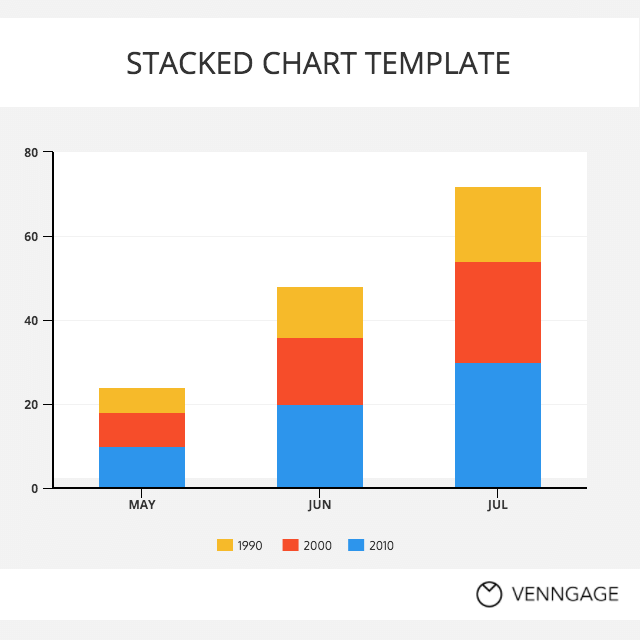
각 그룹을 표시하는데 stack하여 표현하는 Plot이다.
각 그룹의 순서는 항상 유지되어야 한다.
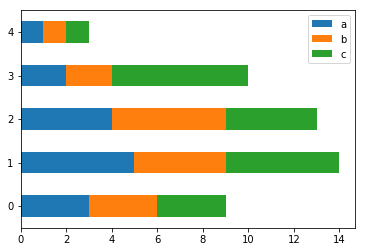
물론 이 또한 barh를 이용하여 아래 그림처럼 수평으로 만들수있다.
import numpy as np
data = np.array([[10, 20, 30], [20, 25, 10], [15, 30, 25], [5, 35, 40]])
import matplotlib.pyplot as plt
# 카테고리 이름
categories = ['Category A', 'Category B', 'Category C']
# 그룹 이름
groups = ['Group 1', 'Group 2', 'Group 3', 'Group 4']
# 그룹별 카테고리 값
values = data.T
# 막대그래프 그리기
fig, ax = plt.subplots()
ax.bar(groups, values[0], label=categories[0])
for i in range(1, len(categories)):
ax.bar(groups, values[i], bottom=values[:i].sum(axis=0), label=categories[i])
# 범례 추가
ax.legend()
# 축 레이블 추가
ax.set_ylabel('Value')
ax.set_xlabel('Group')
# 그래프 보여주기
plt.show()Grouped Bar Plot
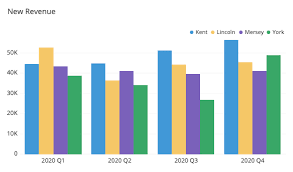
가장 유용한 Bar Plot으로 아래와 같이 표현된다.
import numpy as np
data = np.array([[10, 20, 30], [20, 25, 10], [15, 30, 25], [5, 35, 40]])
import matplotlib.pyplot as plt
# 카테고리 이름
categories = ['Category A', 'Category B', 'Category C']
# 그룹 이름
groups = ['Group 1', 'Group 2', 'Group 3', 'Group 4']
# 그룹별 카테고리 값
values = data.T
# 막대그래프 그리기
fig, ax = plt.subplots()
bar_width = 0.2
x = np.arange(len(groups))
ax.bar(x - bar_width, values[0], width=bar_width, label=categories[0])
for i in range(1, len(categories)):
ax.bar(x + i * bar_width - bar_width, values[i], width=bar_width, label=categories[i])
# 축 레이블 추가
ax.set_ylabel('Value')
ax.set_xlabel('Group')
# 그룹 이름 추가
ax.set_xticks(x)
ax.set_xticklabels(groups)
# 범례 추가
ax.legend()
# 그래프 보여주기
plt.show()부가정보
Bar 사이에 Gap 함수를 통하여 0으로 줄이면 히스토그램이 된다.
Line Plot
주로 시계열 데이터를 표현하는데 많이 사용되며 주로 그래프를 그린다.
주로 구별할수 있는 요소로는
색상,마커,선의종류로 각 선을 구분할수있다.
실시간 데이터는 Noise로 인해 smoothing로 추세를 확인 가능
단일 그래프
import numpy as np
x = np.arange(0, 10, 0.1)
y = np.sin(x)
import matplotlib.pyplot as plt
# 그래프 그리기
plt.plot(x, y)
# 축 레이블 추가
plt.xlabel('x')
plt.ylabel('y')
# 그래프 보여주기
plt.show()2중 그래프
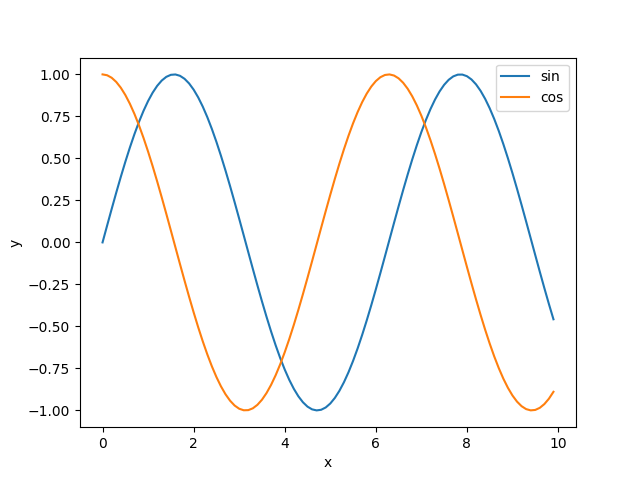
import numpy as np
x = np.arange(0, 10, 0.1)
y1 = np.sin(x)
y2 = np.cos(x)
import matplotlib.pyplot as plt
# 그래프 그리기
plt.plot(x, y1, label='sin')
plt.plot(x, y2, label='cos')
# 축 레이블 추가
plt.xlabel('x')
plt.ylabel('y')
# 범례 추가
plt.legend()
# 그래프 보여주기
plt.show()
유의 사항
x축의 간격이 규칙적이지 않으면 기울기의 정보가 왜곡된다. x축의 간격을 맞춰주는 작업이 요함
한 axes안에 2개의 축을 사용하는 작업은 피하는게 좋다.
Scatter Plot
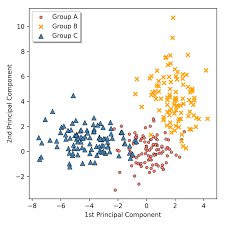
주로 점으로 표현되며 각 점은 각 데이터 1개이다. 이것을 통해 데이터 feature간의 관계,클러스터링, 값차이,이상치 등을 알 수 있다.
이 또한 색,마커,크기로 구별되며 특이사항으로
투명도,지터링,2차원 히스토그램,Contour plot로도 표현이 가능하다.
추세선
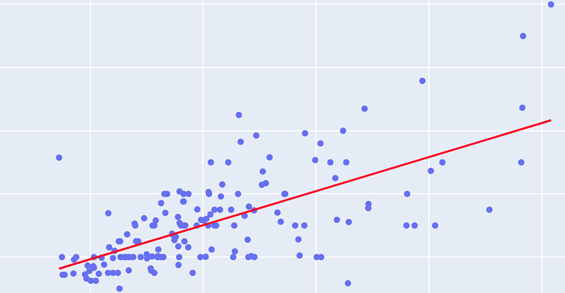
추세선을 그려 scatter의 패턴을 유추할수있다.
import numpy as np
x = np.array([1, 2, 3, 4, 5, 6])
y = np.array([2, 3, 5, 6, 8, 9])
import matplotlib.pyplot as plt
from scipy.stats import linregress
# 그래프 그리기
plt.scatter(x, y)
# 추세선 그리기
slope, intercept, r_value, p_value, std_err = linregress(x, y)
plt.plot(x, slope*x + intercept, color='r')
# 축 레이블 추가
plt.xlabel('x')
plt.ylabel('y')
# 그래프 보여주기
plt.show()Iris
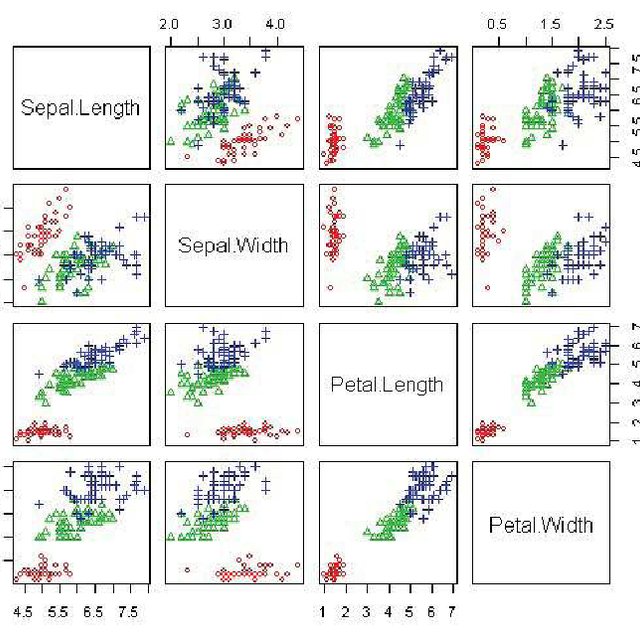
실제 iris 붗꽃 데이터 세트를 Scatter plot으로 표현할경우 위 그림처럼 표현된다.
회고
양이 너무 많다 논문리뷰에 너무 할게 많다보니 모든 기능을 명시하고 싶었지만 기본 기능만 명시하고 추가적인 기능은 이런게 있다는 것만 명시하고 필요할때마다 검색하여 사용하는 방식을 추구해야겠다고 생각이 들어 위와 같이 작성하였다.
