기간: 25.01.07 ~ 25.07.04
25.01.22 : github / streamlit / 웹 크롤링 / mysql
25.01.22 일일 회고록
학습내용
- GitHub 리마인드
- Branch, Commit, Merge 학습
- 어제 만들었던
웹 크롤링 + streamlitDevelop
-
웹 크롤링하여 얻은 댓글들을 Streamlit으로 페이지에 출력
-
웹 크롤링하여 얻은 댓글들을 데이터베이스(DB)에 저장
- DB 생성 및 ERD 작성
- 네이트판 크롤링을 기반으로 데이터베이스 설계 및 ERD 작성.
- BeautifulSoup 실험
beautifulsoup.ipynb에서 크롤링 테스트 후crawling_final.py생성.
- Streamlit 페이지 구현
- 크롤링 결과 리스트를 Streamlit 페이지에 출력.
- DB 저장 구현
- 댓글 데이터를 데이터베이스에 저장하는 기능 개발.
- DB 생성 및 ERD 작성
1. GitHub 리마인드
- Branch, Commit, Merge 학습
-
새로운 레파지토리 생성하여 git clone 진행

-
최초의 main 브런치 확인 (github)
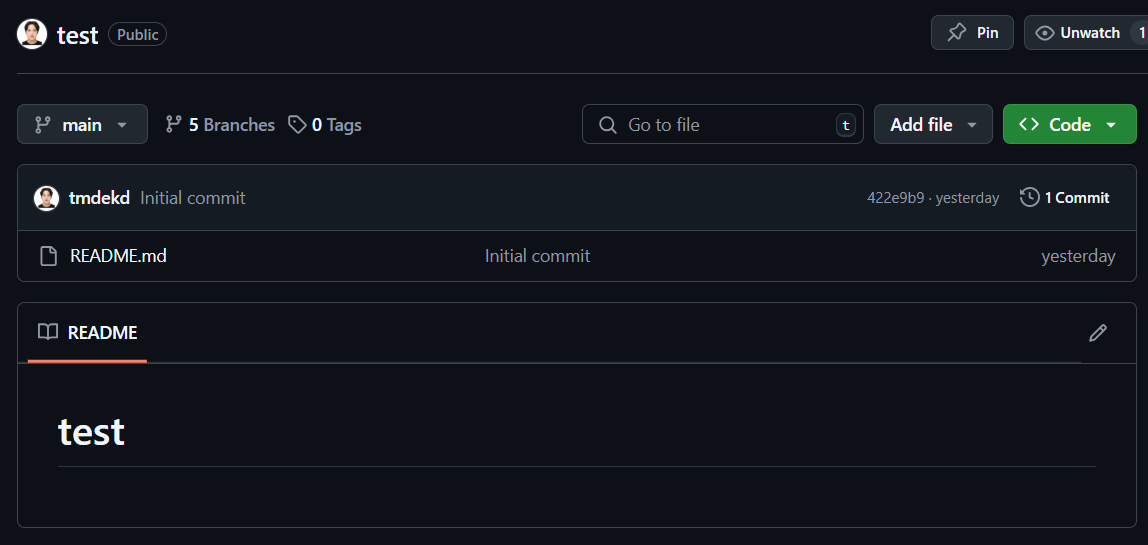
-
최초의 main 브런치 확인 (vscode)
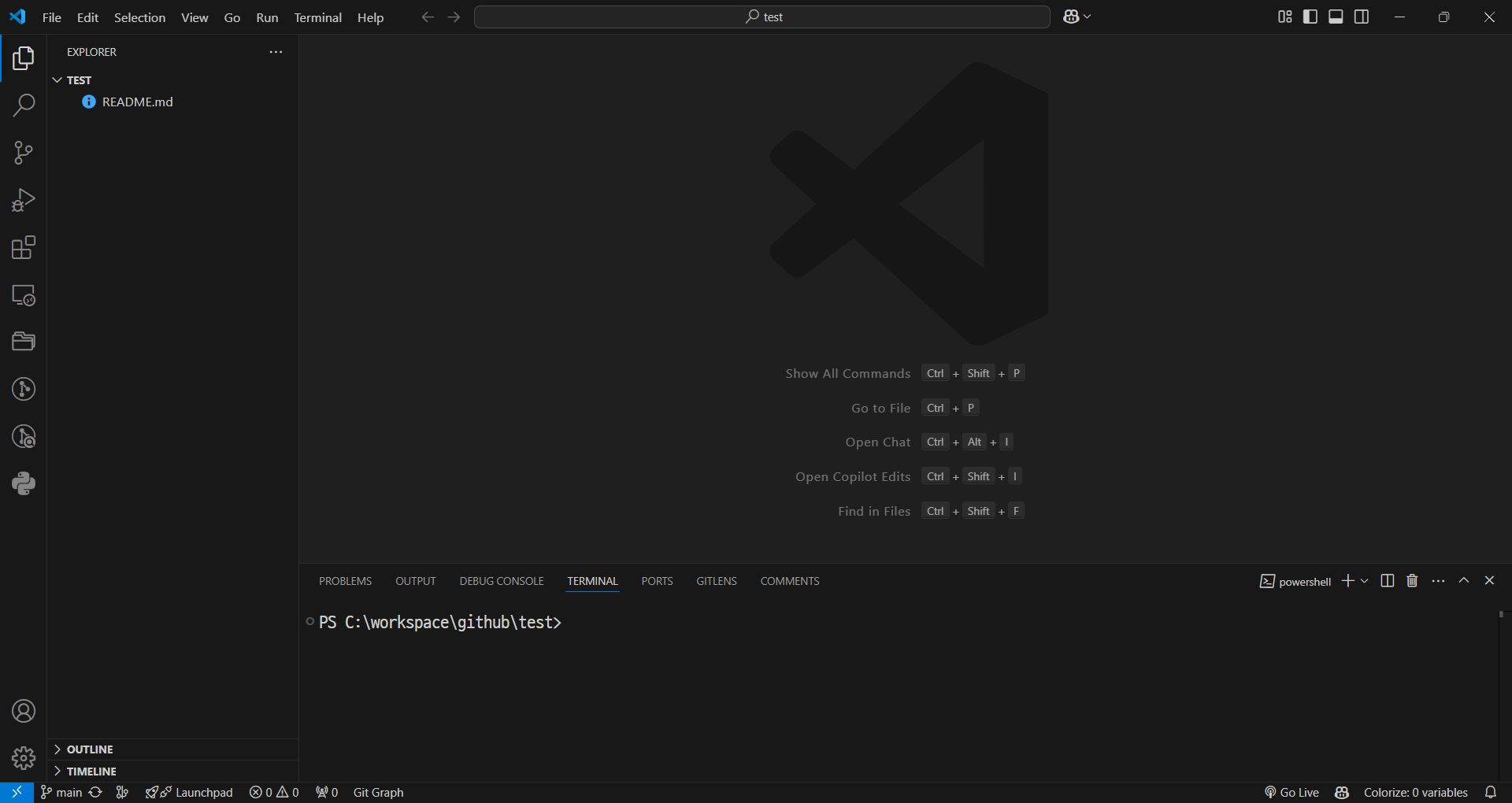
-
기능 1,2,3 브런치
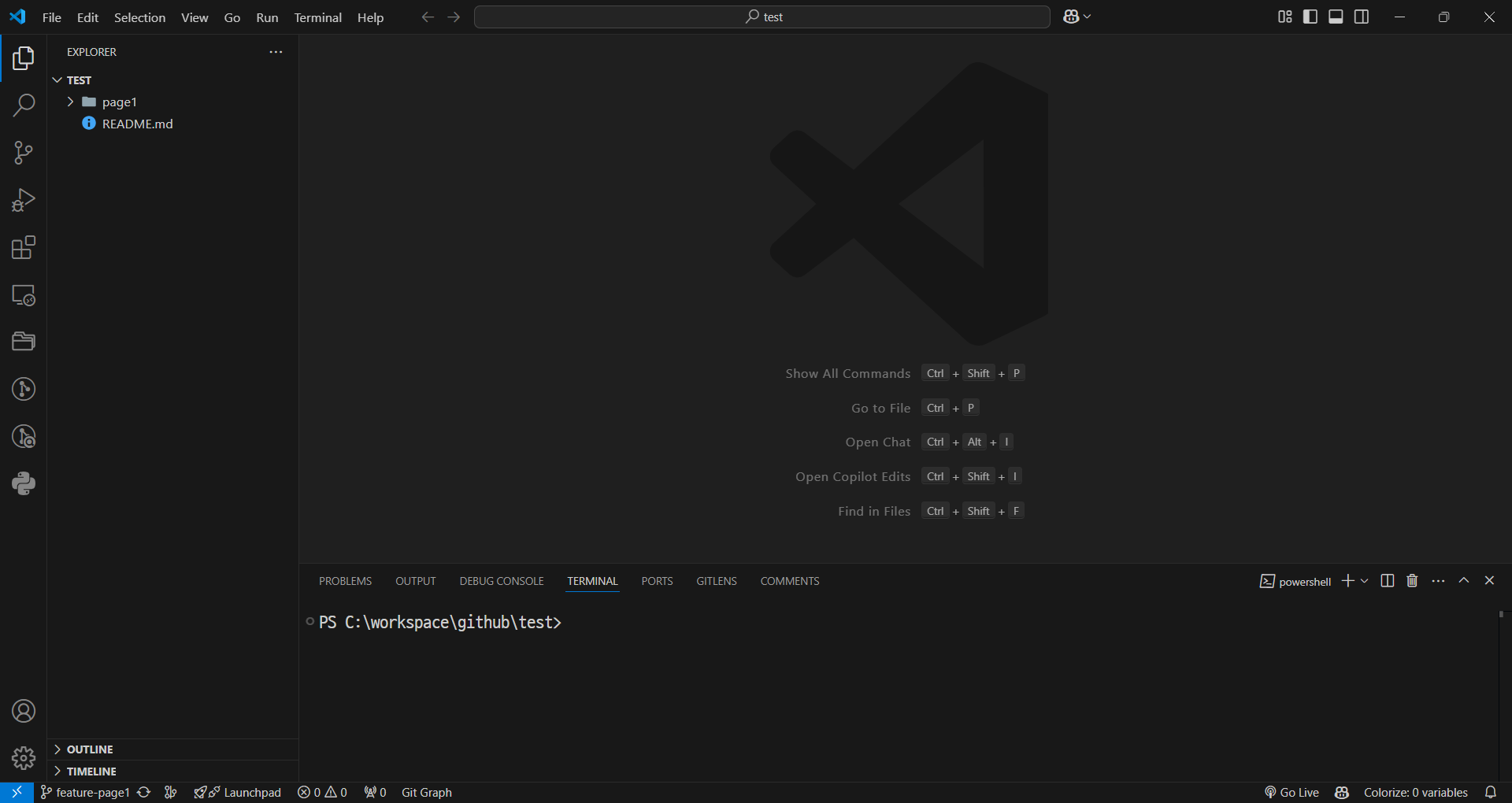
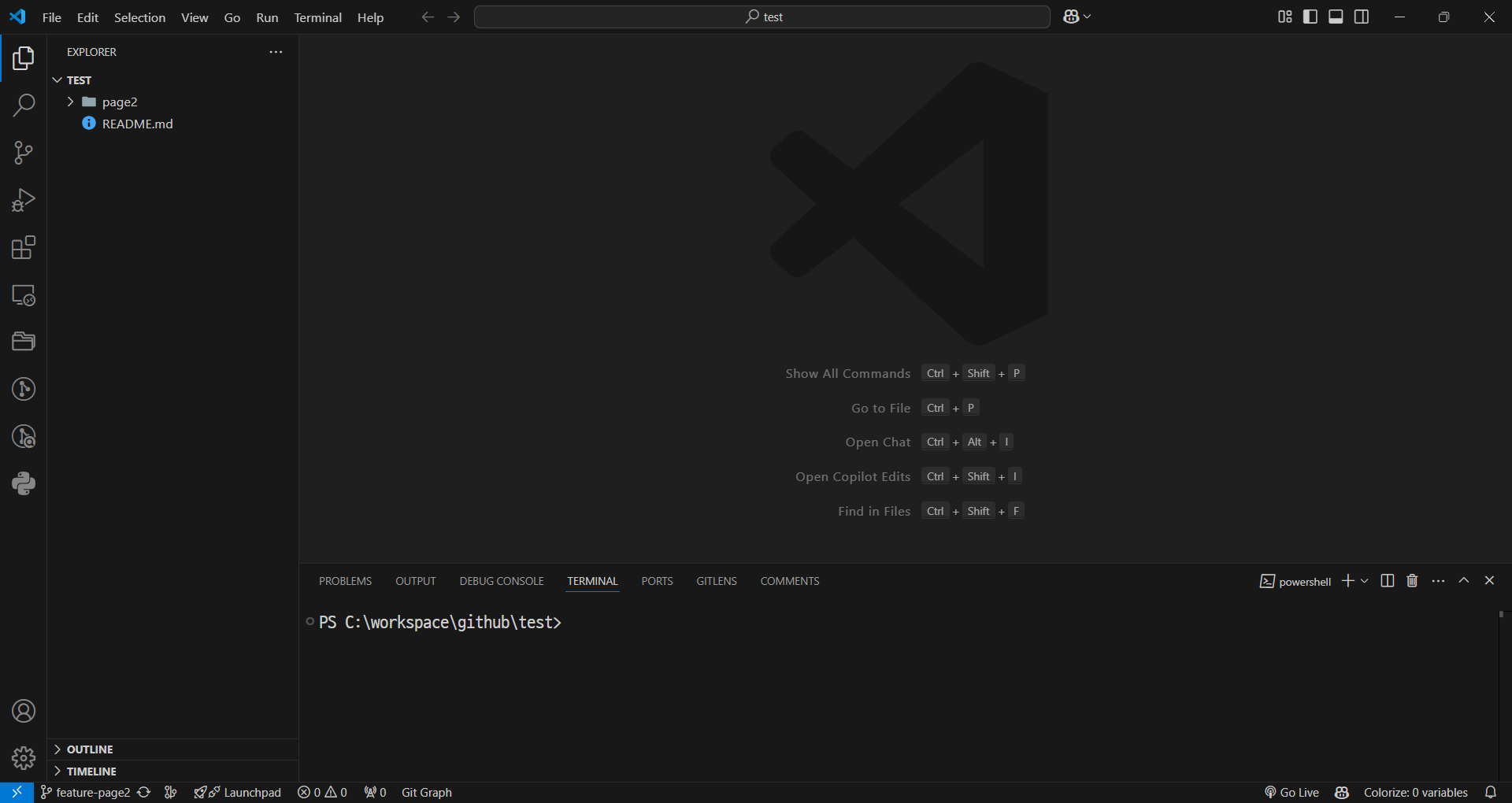
-
commit 진행
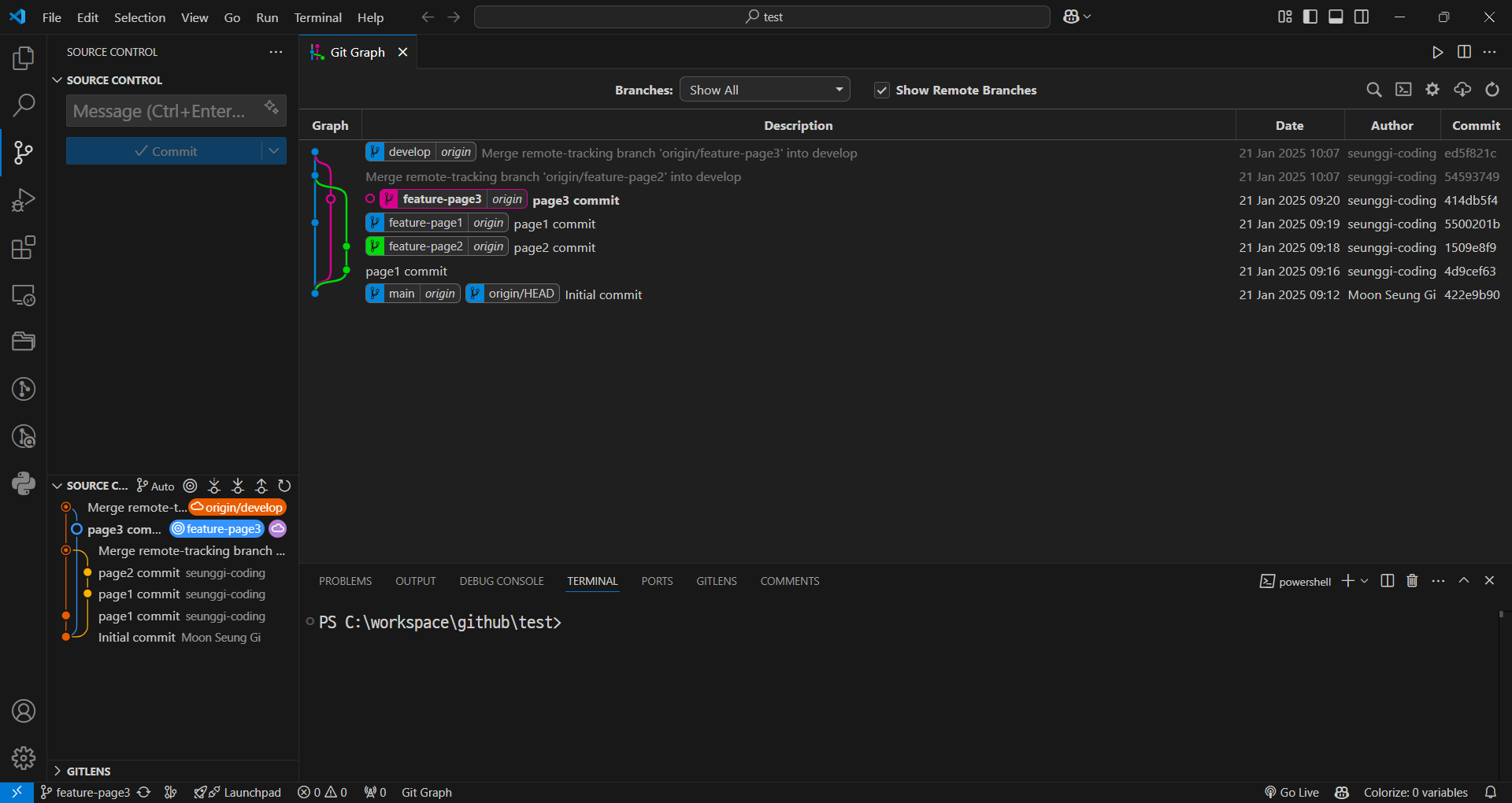
-
이후, develop 브런치에 merge를 진행하면 최종 화면은 다음과 같다.
-
2. 어제 만들었던 웹 크롤링 + streamlit Develop
- 웹 크롤링하여 얻은 댓글들을 Streamlit으로 페이지에 출력
- crawling을 하기 위한 crawling.py
import requests
from bs4 import BeautifulSoup as bs
def do_crawling_of_nate(comment_id:str) -> str:
# url = "https://pann.nate.com/talk/350939697"
url = f"https://pann.nate.com/talk/{comment_id}"
header = {
# "User-Agent"와 "Refererer"은 chrome에서 개발자 도구 -> Network -> Headers에서 확인 가능
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
"Refererer" : "https://pann.nate.com/"
}
response = requests.get(url=url, headers=header)
return response
def get_comments(comment_id:str) -> list:
response = do_crawling_of_nate(comment_id)
if response.status_code >= 400:
print("오류입니다!")
return
beautiful_text = bs(response.text, "html.parser")
dd_list = beautiful_text.find_all("dd", class_="usertxt")
return [
dd.get_text().replace("\n", "").strip()
for dd in dd_list
]- streamlit으로 form을 작성하여 네이트판 id를 작성하여 해당 게시글의 댓글을 가져올 수 있도록 main.py 작성
# 크롤링 해서 결과를 보여주는 웹 페이지
import streamlit as st
from common.crawling import get_comments
st.title("크롤링 한번 해볼까?")
# 네이트 판 ID 예시 : 350939697
with st.form("my_form"):
nate_pan_id = st.text_input("네이트 판 ID를 입력하세요.")
form_submit = st.form_submit_button("크롤링 시작합니다.")
if form_submit and nate_pan_id is not None:
msg = get_comments(nate_pan_id)
st.write(msg)- 결과 화면
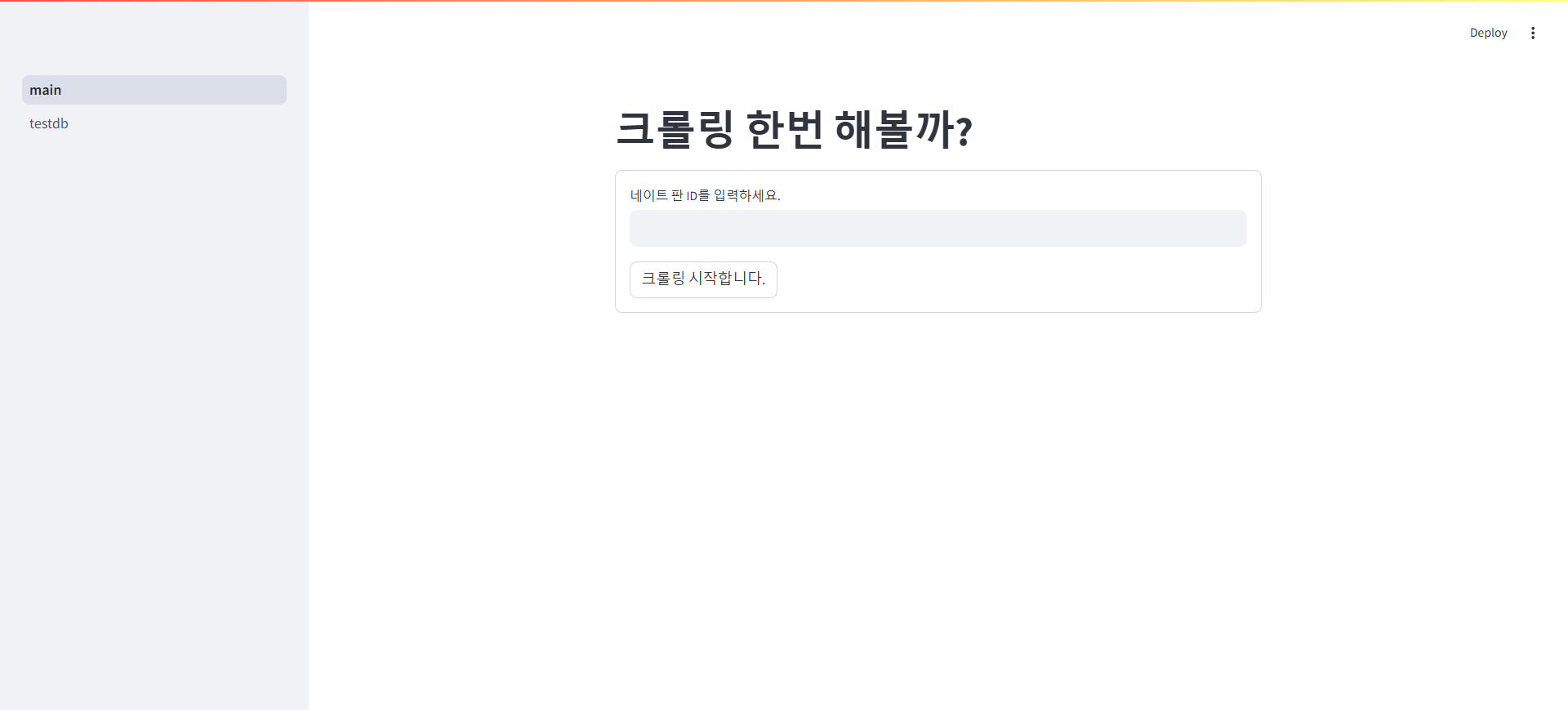

- 웹 크롤링하여 얻은 댓글들을 데이터베이스(DB)에 저장
- DB 생성 및 ERD 작성
-
네이트판 크롤링을 기반으로 데이터베이스 설계 및 ERD 작성.
- DB 생성 및 테이블 생성
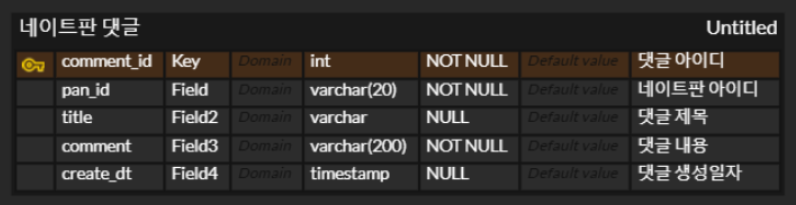
-- 'nate_pan_comments' 테이블을 생성 (이미 존재하면 생성하지 않음) CREATE TABLE IF NOT EXISTS nate_pan_comments ( pan_id VARCHAR(20) NOT NULL COMMENT '네이트판 아이디', create_dt TIMESTAMP COMMENT '댓글 생성일자', title VARCHAR(20) NULL COMMENT '댓글 제목', comment VARCHAR(200) NOT NULL COMMENT '댓글 내용', PRIMARY KEY(pan_id, create_dt) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='네이트판 댓글'; -
ERD 작성
-
-
BeautifulSoup 실험
-
beautifulsoup.ipynb에서 크롤링 테스트 후crawling_final.py생성.beautifulsoup.ipynb
# beautiful_text dl_list = beautiful_text.find_all("dl", class_="cmt_item") # 댓글 리스트에서 title만 가져오기 dl_list[0].find(class_="nameui").get_text() # 댓글 리스트에서 작성 시간만 가져오기 dl_list[0].find_next("i").get_text() # 댓글 리스트에서 댓글 가져오기 dl_list[0].find("dd", class_="usertxt").get_text() # 댓글 리스트에서 댓글 안의 내용만 가져오기 dl_list[0].find("dd", class_="usertxt").get_text().replace("\n", "").strip() from datetime import datetime # 댓글 생성일자 형변환 print(datetime.strptime(dl_list[0].find_next("i").get_text(), "%Y.%m.%d %H:%M"))
crawling_final.py
import requests from bs4 import BeautifulSoup as bs from datetime import datetime def do_crawling_of_nate(comment_id:str) -> str: # url = "https://pann.nate.com/talk/350939697" url = f"https://pann.nate.com/talk/{comment_id}" header = { # "User-Agent"와 "Refererer"은 chrome에서 개발자 도구 -> Network -> Headers에서 확인 가능 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36", "Refererer" : "https://pann.nate.com/" } response = requests.get(url=url, headers=header) return response def get_comments(comment_id:str) -> list: response = do_crawling_of_nate(comment_id) if response.status_code >= 400: print("오류입니다!") return beautiful_text = bs(response.text, "html.parser") # 댓글 리스트 가져오기 comment_list = beautiful_text.find_all("dl", class_="cmt_item") return [ { # beautifulsoup.ipynb 참고 # 댓글 제목 'title': comment.find(class_="nameui").get_text().strip(), # 댓글 내용 'comment': comment.find("dd", class_="usertxt").get_text().replace("\n", "").strip(), # 댓글 생성일자 형변환 'create_dt' : datetime.strptime(comment.find_next("i").get_text(), "%Y.%m.%d %H:%M") } for comment in comment_list ]
-
-
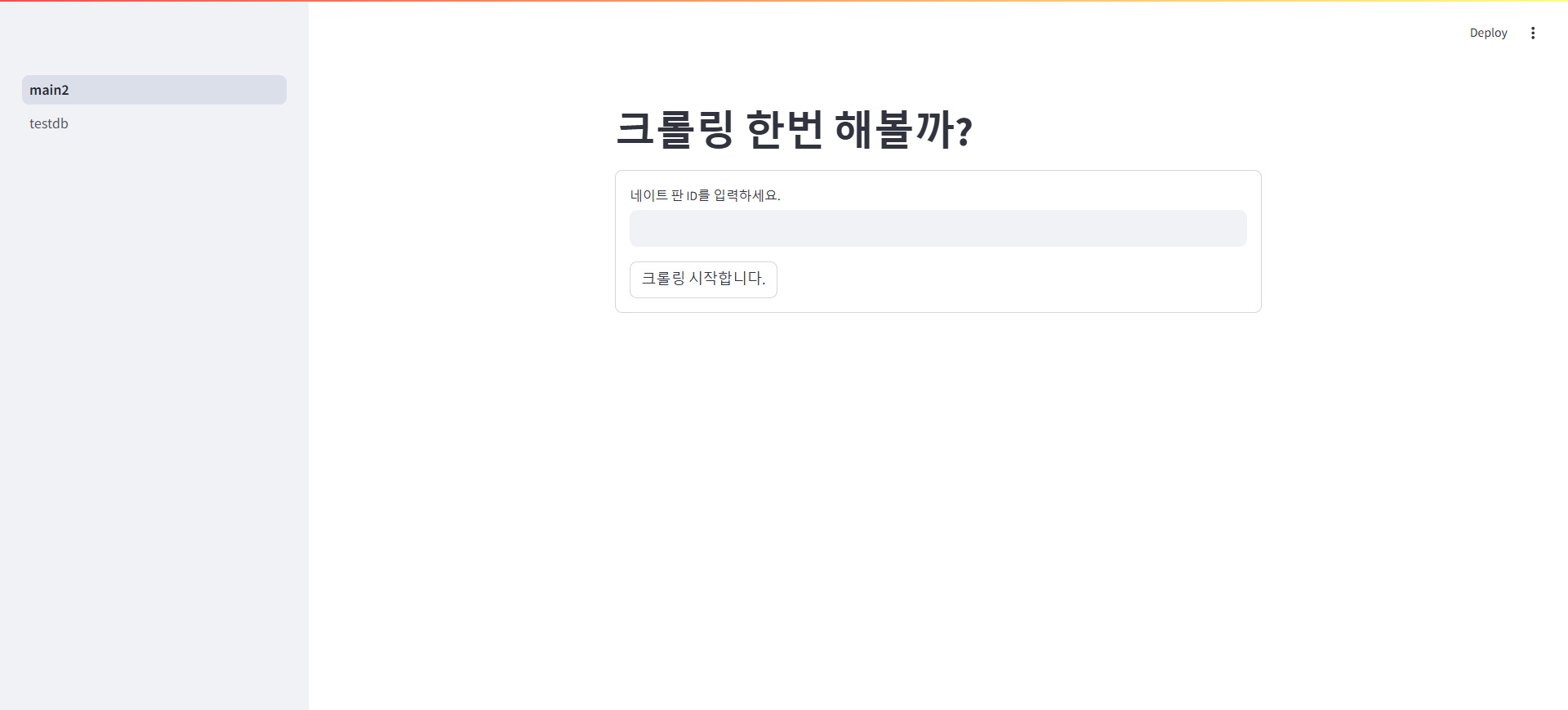
Streamlit 페이지 구현
- 크롤링 결과 리스트를 Streamlit 페이지에 출력.
# 크롤링 해서 결과를 DB에 저장 import streamlit as st from common.crawling2 import get_comments st.title("크롤링 한번 해볼까?") # 네이트 판 ID 예시 : 350939697 with st.form("my_form"): nate_pan_id = st.text_input("네이트 판 ID를 입력하세요.") form_submit = st.form_submit_button("크롤링 시작합니다.") if form_submit and nate_pan_id is not None: msg = get_comments(nate_pan_id) st.write(msg)- 실행 화면

-
DB 저장 구현
-
댓글 데이터를 데이터베이스에 저장하는 기능 개발.
database.py: 데이터베이스와 상호작용하여 데이터를 삽입(insert)하는 기능
import logging import streamlit as st from sqlalchemy import text from .sql_constant import INSERT_SQLs # Streamlit의 캐시 기능을 사용하여 데이터베이스 연결 객체를 재사용하기 위한 함수. @st.cache_resource def get_connector(): """ 데이터베이스 연결 객체를 생성하고 반환합니다. - "mydb"라는 이름의 데이터베이스에 연결합니다. - SQL 타입의 연결을 사용하며, autocommit 옵션을 활성화하여 자동으로 커밋합니다. """ return st.connection( "mydb", # 데이터베이스 이름 type="sql", # 연결 타입: SQL autocommit=True # 자동 커밋 활성화 ) # 데이터를 데이터베이스에 삽입하는 함수. # 주어진 SQL 템플릿과 데이터를 사용하여 데이터베이스에 삽입을 시도하고, # 실패한 데이터를 반환합니다. def insert_query(sql_constant: INSERT_SQLs, datas: list) -> list: """ 데이터를 데이터베이스에 삽입합니다. - SQL 템플릿(`sql_constant`)과 데이터 리스트(`datas`)를 받아 데이터베이스에 삽입을 시도합니다. - 삽입 실패한 데이터는 리스트(`list_error`)에 저장하여 반환합니다. 매개변수: - sql_constant: SQL 템플릿을 정의한 `INSERT_SQLs` Enum 값. - datas: 삽입할 데이터 리스트. 각 데이터는 딕셔너리 형태로 구성됩니다. 반환값: - list_error: 삽입에 실패한 데이터 리스트. """ # 데이터베이스 연결 객체 가져오기 conn = get_connector() # 삽입 실패 데이터를 저장할 리스트 list_error = [] # 전체 데이터 개수 로깅 logging.info(f"[insert_query] len(datas): {len(datas)}") # 데이터를 순회하며 데이터베이스 삽입 시도 for idx, data in enumerate(datas): try: # 현재 데이터의 인덱스 로깅 logging.info(f"[insert_query] len(datas)[idx]: {idx}") # SQL 템플릿을 데이터에 맞게 포맷 insert_sql = sql_constant.value[1].format( pan_id=data['pan_id'], # 게시글 ID title=data['title'], # 댓글 작성자 이름 comment=data['comment'], # 댓글 내용 create_dt=data['create_dt'] # 댓글 작성 날짜 ) # 포맷된 SQL 쿼리 실행 conn.connect().execute(text(insert_sql)) except Exception as e: # 삽입 실패 시 해당 데이터를 list_error에 추가 list_error.append(data) # 삽입 실패 데이터를 반환 return list_errorsql_constant.py: 데이터베이스에 삽입할 SQL 쿼리 템플릿을 정의하는 상수 클래스(enum.Enum)를 포함
import enum # 열거형(Enum)을 정의하기 위해 Python 표준 라이브러리 사용. # 데이터베이스 삽입 SQL 쿼리를 관리하기 위한 열거형 클래스 정의. class INSERT_SQLs(enum.Enum): """ 데이터베이스에 데이터를 삽입하기 위한 SQL 템플릿을 정의하는 열거형 클래스. - 각 항목은 고유 ID(enum.auto()), SQL 쿼리 템플릿, 그리고 설명으로 구성됩니다. """ # 네이트 판 댓글 데이터를 저장하는 SQL 템플릿 정의. NATE_PAN_COMMENTS = ( enum.auto(), # 열거형 항목에 자동으로 고유 ID 부여. """ insert nate_pan_comments (pan_id, create_dt, title, comment) values('{pan_id}', '{create_dt}', '{title}', '{comment}'); """, # SQL 템플릿: 댓글 데이터를 데이터베이스 테이블에 삽입. "댓글 데이터 저장" # SQL 템플릿에 대한 설명. )crawling.py: 네이트 판에서 특정 게시글의 댓글 데이터를 크롤링하여 리스트 형태로 반환
import requests # HTTP 요청을 보내기 위해 사용하는 라이브러리. from datetime import datetime # 날짜와 시간 데이터를 처리하기 위해 사용하는 라이브러리. from bs4 import BeautifulSoup as bs # HTML 파싱을 위한 BeautifulSoup 라이브러리. # 네이트 판 특정 게시글의 HTML 데이터를 요청하여 가져오는 함수. def do_crawling_of_nate(comment_id: str): """ 네이트 판 게시글의 HTML 데이터를 가져옵니다. 매개변수: - comment_id: 네이트 판 게시글 ID (str). 반환값: - HTTP 응답 객체 (requests.Response). 작동 방식: - 지정된 게시글 ID를 URL에 삽입하여 완성된 URL로 GET 요청을 보냅니다. - 요청 시 Referer와 User-Agent 헤더를 포함하여 크롤링이 차단되지 않도록 설정합니다. """ # 네이트 판 게시글 URL 생성 url = f"https://pann.nate.com/talk/{comment_id}" # HTTP 요청 헤더 설정 header = { "Referer": "https://pann.nate.com/", # 요청 출처를 네이트 판으로 지정. "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36" # User-Agent를 통해 일반 브라우저로 요청하는 것처럼 설정. } # URL에 대해 GET 요청을 보내고 응답 반환 response = requests.get(url=url, headers=header) return response # 네이트 판 게시글의 댓글 데이터를 크롤링하여 리스트 형태로 반환하는 함수. def get_comments(comment_id: str) -> list: """ 네이트 판 게시글의 댓글 데이터를 가져옵니다. 매개변수: - comment_id: 네이트 판 게시글 ID (str). 반환값: - 댓글 데이터를 담은 딕셔너리의 리스트. 각 댓글은 pan_id, title, comment, create_dt를 포함. - 오류 발생 시 None 반환. 작동 방식: - `do_crawling_of_nate` 함수로 HTML 데이터를 가져옵니다. - BeautifulSoup으로 HTML을 파싱하여 댓글 데이터를 추출합니다. - 댓글 데이터는 딕셔너리 형태로 구성됩니다. """ # HTML 데이터를 가져오기 response = do_crawling_of_nate(comment_id) # 요청이 실패한 경우 if response.status_code >= 400: print("오류에요 ㅠㅠ") # 오류 메시지 출력 return # BeautifulSoup로 HTML 파싱 beautiful_text = bs(response.text, "html.parser") # 댓글 리스트 추출: <dl> 태그 중 class="cmt_item" 요소를 모두 가져옴 comment_list = beautiful_text.find_all("dl", class_="cmt_item") # 각 댓글 데이터를 딕셔너리로 변환하여 리스트로 반환 return [ { 'pan_id': comment_id, # 게시글 ID # 댓글 작성자의 이름 또는 닉네임 'title': comment.find(class_="nameui").get_text().strip(), # 댓글 내용 'comment': comment.find("dd", class_="usertxt").get_text().replace("\n", "").strip(), # 댓글 작성 날짜 및 시간 'create_dt': datetime.strptime(comment.find("i").get_text().strip(), '%Y.%m.%d %H:%M') } for comment in comment_list # 모든 댓글 요소를 순회하며 데이터 추출 ]main.py: Streamlit 애플리케이션을 통해 사용자가 입력한 네이트 판 게시글 ID로 댓글 데이터를 크롤링하고, 이를 데이터베이스에 저장
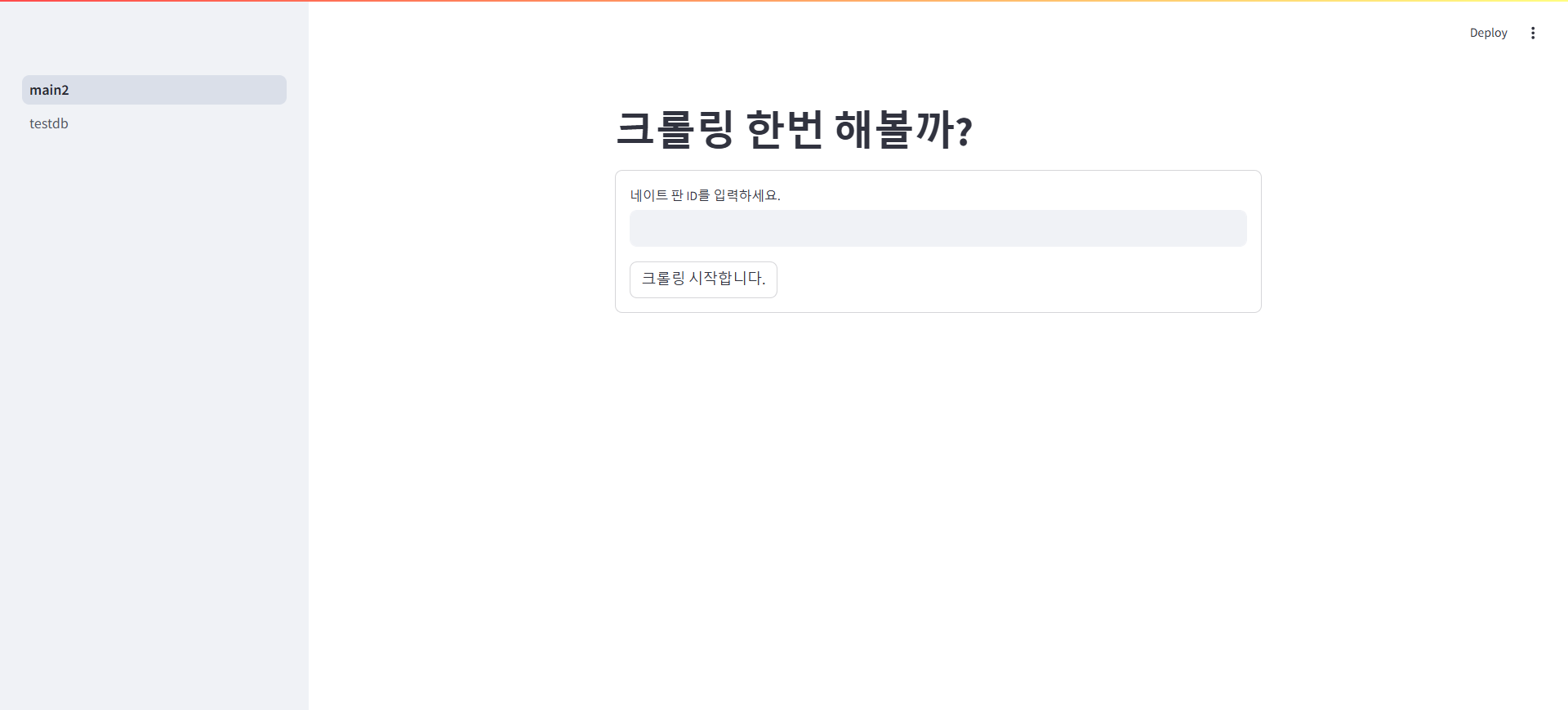
import logging # 애플리케이션의 동작 정보를 기록하기 위한 모듈. logging.basicConfig(level=logging.INFO) # 로깅 레벨을 INFO로 설정하여 일반 정보를 기록. import streamlit as st # Streamlit을 사용해 웹 애플리케이션을 제작하기 위한 모듈. # 크롤링 함수와 데이터베이스 삽입 관련 모듈 가져오기. from common.crawling_final import get_comments # 네이트 판 댓글 크롤링 함수. from common.database import insert_query # 데이터베이스 삽입 함수. from common.sql_constant import INSERT_SQLs # SQL 템플릿을 관리하는 열거형. # Streamlit 애플리케이션 제목 설정 st.title("크롤링 한번 해볼까?") # 페이지 상단에 제목 표시. # 사용자 입력 폼 생성 # 네이트 판 ID를 입력받기 위한 폼을 정의. # 폼 안에 텍스트 입력 필드와 버튼 포함. with st.form("my_form"): # 사용자가 입력할 네이트 판 게시글 ID nate_pan_id = st.text_input("네이트 판 아이디 작성해주세요.") # 폼 제출 버튼 form_submit = st.form_submit_button("크롤링 시작합니다.") # 폼이 제출되었고, 사용자가 네이트 판 ID를 입력한 경우 실행. if form_submit and nate_pan_id is not None: # 입력받은 네이트 판 ID를 사용해 댓글 데이터를 크롤링. comments = get_comments(nate_pan_id) # 크롤링한 데이터를 데이터베이스에 삽입. list_error = insert_query(INSERT_SQLs.NATE_PAN_COMMENTS, comments) # 데이터베이스 삽입 결과에 따라 메시지 출력. if not list_error: # 삽입 실패 데이터가 없는 경우 st.write("저장성공") # 성공 메시지 출력. else: # 삽입 실패 데이터가 있는 경우 st.write(list_error) # 실패한 데이터 리스트 출력.-
실행 화면

- db 저장 확인
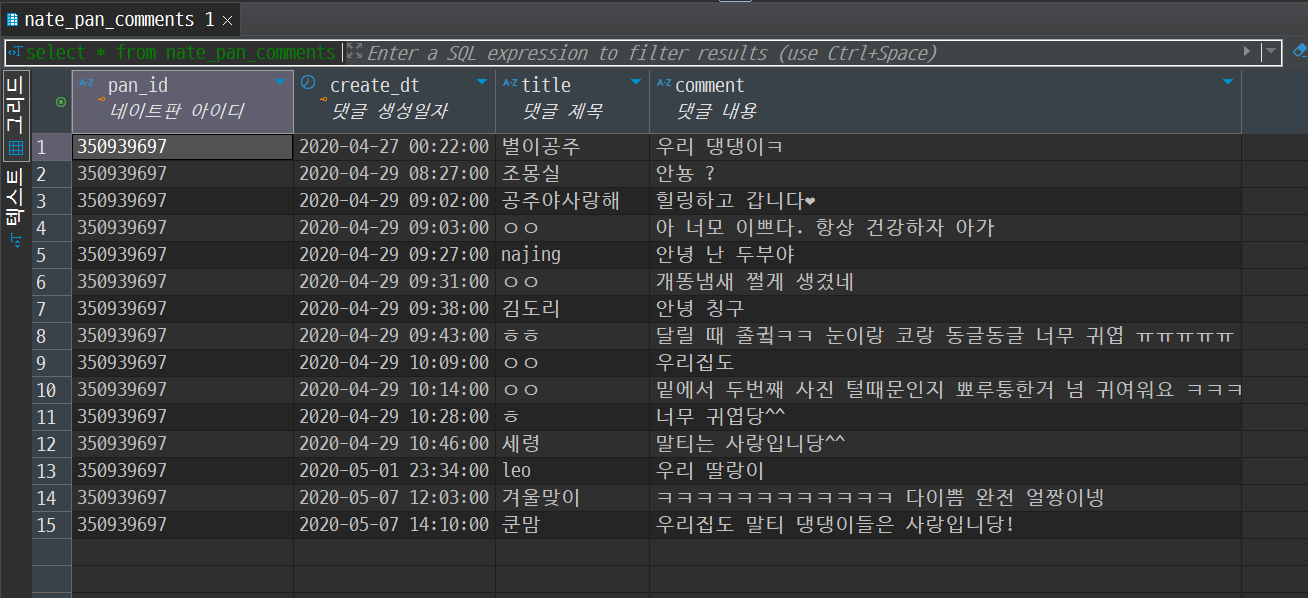
- db 저장 확인
-
느낀 점
- 요즘 아침에 쉽게 일어나지 못하는 걸 생각하면 6개월이라는 기간이 쉽지 않겠다는 생각을 했다.
- 부족한 체력을 채우기 위해 꾸준히 운동을 다니려 노력하겠다.
부족한 점
- GPT를 사용하지 않고, 구현하려고 노력을 할 것이다.
- 22일 어제 프로그래머스 PCCE 시험을 봤는데 그닥 만족스럽지 않았다. 그래도 전공자로써 800~900이 나오기를 기대했는데 그 정도의 실력도 되지 않음에 아쉬웠지만, 노력하면 다음달에는 할 수 있을 것이다.
이렇게 열한 번째 회고록을 작성해 보았다. 날마다 정해놓은 계획대로 움직이고, 공부하는 것이 어렵다는 것을 오늘도 느꼈고, 어제 다 작성하지 못한 블로그 작성을 완료하였다. 오늘 23일부터 내일 24일까지는 단위 프로젝트 마무리로 인해 따로 복습의 일일 회고록은 없을 예정이다.

AI 모델을 개발하여 이를 활용한 서비스를 개발하고 운영하는 개발자가 되기 위해 꾸준히 노력하겠습니다!