안녕하세요 그루비한입니다. 어느덧 2025년도 마무리 되어가고 2026년이 다가오고 있습니다.
오늘은 회사에서 2025년 한해를 돌아보고 2026년은 어떤 방향으로 나아갈지에 대한 시간을 가졌습니다. 역시 2026년은 Physical AI가 본격적으로 등장하고 미래 먹거리가 될 것으로 예상하고 방향성을 잡기로 했습니다.
저 역시도, 본격적이진 않지만 올 한해 동안 간단한 Robotics 프로젝트도 해보고 IsaacSIM이나 Gazebo 같은 시뮬레이터를 사용해보면서 Physical AI란 무엇인가?에 대해 관심을 갖기 시작했습니다.
그래서 오늘부터는 Robotics 관련된 논문들이나 개념들을 공부해서 공유해보려고 합니다. 특히 2026년에는 좀 더 본격적으로 블로그를 활용해보려고 하는만큼 저의 블로그도 많이 활성화되고 제 AI적인 이해도도 앞서나갈 수 있도록 도전해보겠습니다.
오늘 읽어볼 대망의 첫번째 로보틱스 논문은 OpenVLA: An Open-Source Vision-Language-Action Model입니다.

논문 링크: arxiv
현재 로봇 공학 분야에는 대규모의 비전 및 언어 데이터와 다양한 로봇 플랫폼이 존재합니다. 하지만 이를 아우르는 강력하고 범용적인(Robust & Generalize) VLA 모델은 부족한 실정입니다. 기존의 VLA 모델들은 대부분 소스코드가 공개되지 않은 폐쇄형(Closed) 모델인 경우가 많고, 새로운 환경이나 태스크에 맞춰 파인튜닝을 시도해도 실패하는 사례가 많았습니다.
이러한 한계를 극복하기 위해 등장한 모델이 바로 OpenVLA입니다. "파인튜닝이 용이하고 다양한 데이터로 학습된 오픈소스 VLA를 만들자"는 목표로 설계된 이 모델의 핵심 내용을 정리해 드립니다.
1. OpenVLA의 핵심 아키텍처 (Main Idea)
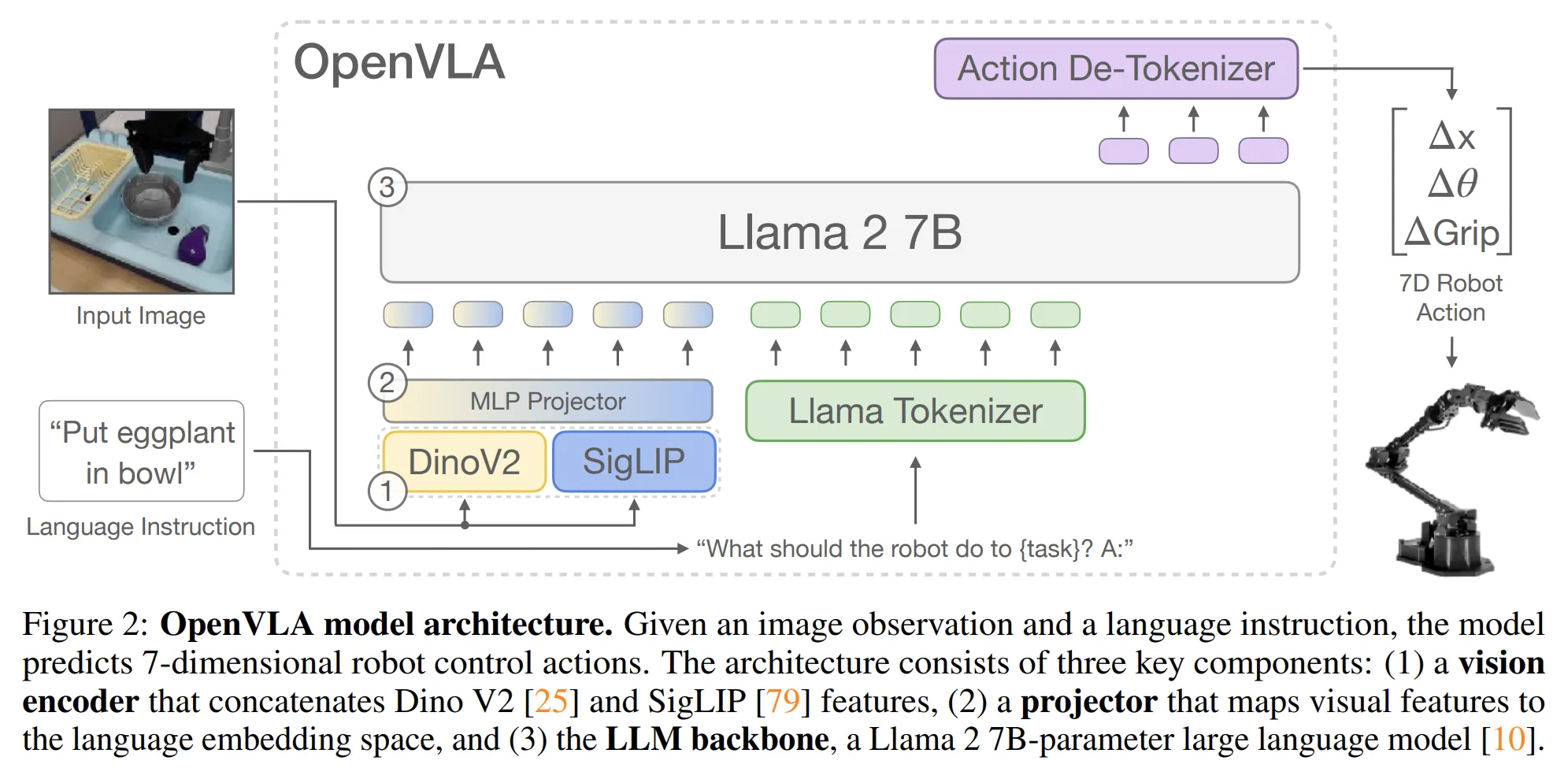 OpenVLA의 model architecture
OpenVLA의 model architecture
OpenVLA는 기본적으로 Prismatic-7B VLM을 기반으로 제작되었습니다. 이 모델은 Vision Encoder와 2-layer MLP 프로젝터, 그리고 Llama 2 Language Model로 구성되어 있습니다.
특히 주목할 점은 비전 인코더(Vision Encoder)의 구성입니다. OpenVLA는 SigLIP과 DINOv2라는 두 가지 인코더를 결합하여 사용합니다. 일반적으로는 CLIP이나 SigLIP 단독 인코더를 쓰는 경우가 많지만, OpenVLA는 DINOv2를 추가함으로써 시각적 특징의 공간 추론(Spatial Reasoning) 성능을 획기적으로 높였습니다. 입력된 이미지 패치는 두 인코더를 모두 통과한 뒤 채널 단위로 결합(Concatenate)되어 모델에 전달됩니다.
2. 학습 과정 및 데이터 전략
Action Discretization
로봇의 동작(Action)을 언어 모델이 예측하게 하려면, 동작 데이터를 토큰과 같은 이산적인 형태로 변환해야 합니다. OpenVLA는 RT-2의 방식을 참고하여 동작의 각 차원을 256개의 구간(Bin)으로 나누었습니다. 이때 각 구간의 너비는 학습 데이터의 1~99번째 분위수(Quantile)를 기준으로 설정하여 아웃라이어의 영향을 최소화했습니다.
또한, Llama 토크나이저의 여분 토큰이 부족한 문제를 해결하기 위해 가장 적게 사용되는 256개의 기존 토큰을 동작 토큰으로 덮어쓰는(Overwrite) 영리한 전략을 선택했습니다. 결과적으로 OpenVLA는 일반적인 LLM처럼 다음 토큰을 예측하는 방식으로 학습하며, Cross-Entropy Loss를 통해 동작을 평가하게 됩니다.
Training Data
범용성을 위해 Open X-Embodiment 데이터셋을 베이스로 하여 대규모의 다양한 로봇 데이터를 수집했습니다. 데이터 정제의 핵심 원칙은 두 가지였습니다.
-
모든 학습 데이터에 일관된 입력 및 출력 공간이 담길 것
-> 제3자 카메라 및 싱글 암 조작 데이터 선별 -
로봇의 종류, 태스크, 장면이 적절하게 섞일 것
-> Octo의 방식을 따라 데이터셋별 가중치 부여
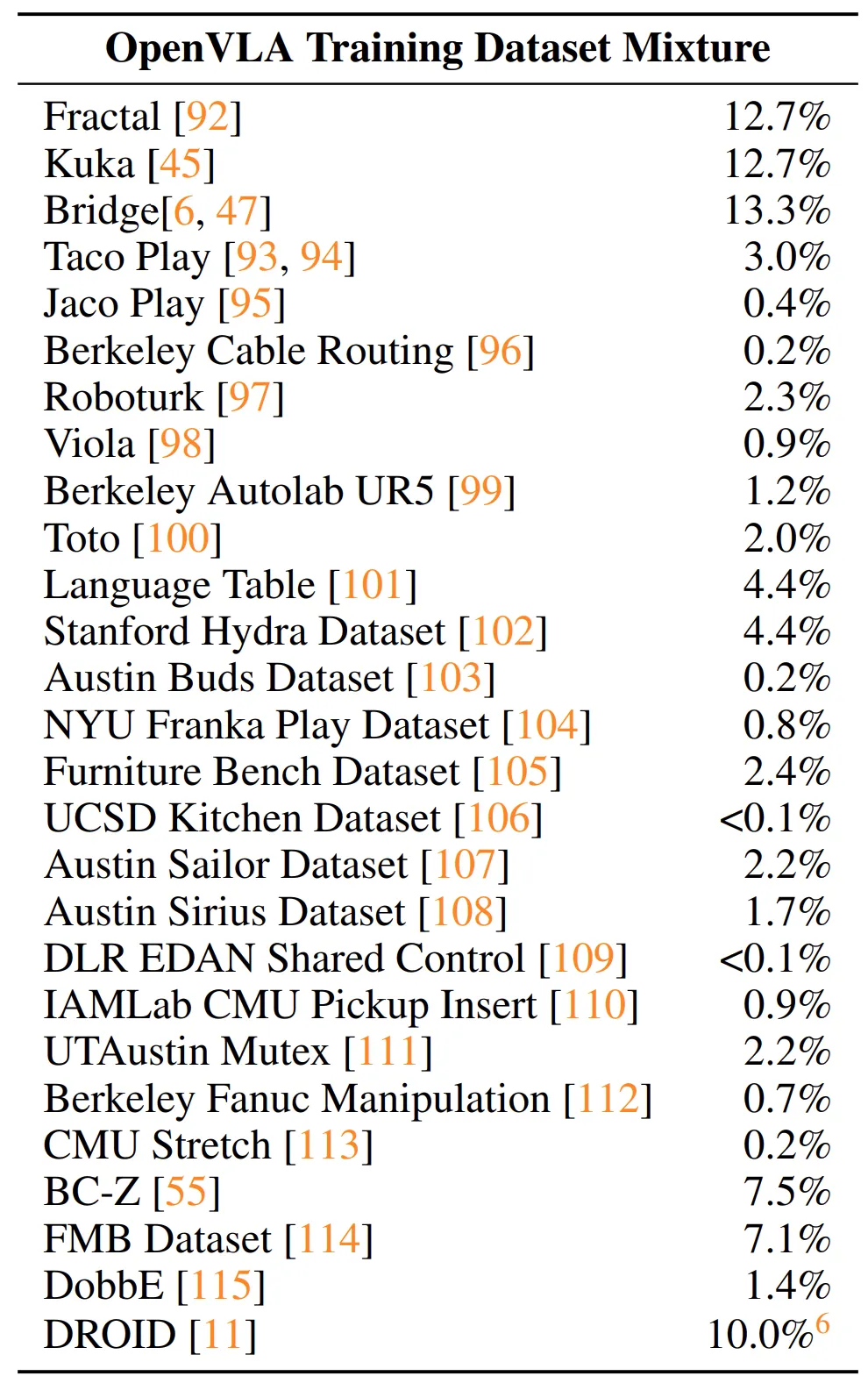 OpenVLA를 학습할 때 사용된 Dataset Mixture.
데이터셋별로 부여된 가중치가 오른쪽 %로 나타나있다.
OpenVLA를 학습할 때 사용된 Dataset Mixture.
데이터셋별로 부여된 가중치가 오른쪽 %로 나타나있다.
3. Design Decisions
저자들은 최적의 성능을 위해 다양한 실험을 진행하며 다음과 같은 결론을 얻었습니다.
-
VLM 백본: LLaVA보다 Prismatic이 약 10% 높은 성공률을 보였습니다. 이는 SigLIP-DINOv2 조합을 통한 향상된 공간 추론 능력 덕분입니다.
-
이미지 해상도: 384px와 224px를 비교했을 때, 고해상도는 연산 비용만 3배 늘어날 뿐 성능 향상은 미미했습니다. 따라서 224x224 px를 최종 사이즈로 채택했습니다.
-
비전 인코더 파인튜닝: 보통 비전 인코더는 고정(Freeze)해두지만, VLA 학습 시에는 비전 인코더도 함께 학습하는 것이 유리했습니다. 기존 백본이 놓치기 쉬운 세밀한 로봇 제어용 공간 디테일을 학습해야 하기 때문입니다.
-
학습 에폭: 일반적인 LLM과 달리 VLA는 에폭을 거듭할수록 정확도가 계속 높아지는 경향을 보였습니다. 이에 따라 총 27 에폭의 충분한 학습을 진행했습니다.
4. Experiment
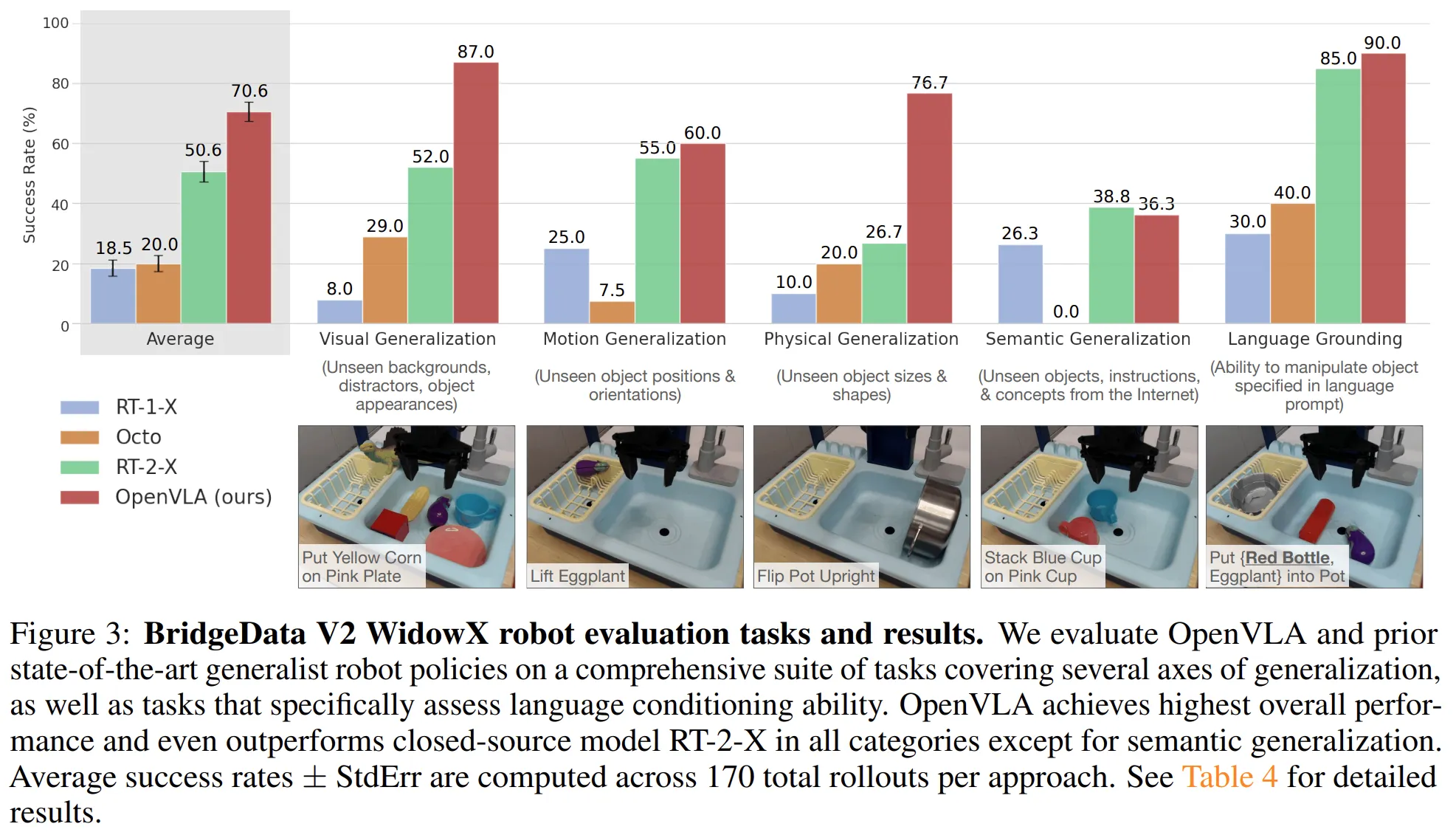 BridgeData V2로 WidowX robot을 학습해 실험한 결과. 다른 모델 대비 generalize 성능이 월등히 좋다.
BridgeData V2로 WidowX robot을 학습해 실험한 결과. 다른 모델 대비 generalize 성능이 월등히 좋다.
OpenVLA는 폐쇄형 모델인 RT-2-X 대비 7배 적은 파라미터를 가졌음에도 불구하고, 다양한 태스크에서 16.5% 향상된 성공률을 기록했습니다. 특히 OpenVLA는 RT-2와 비교했을 때, 시각적 일반화(Visual Generalization)와 물리적 일반화(Physical Generalization) 에서 압도적인 성과를 거두었습니다. RT-2 역시 범용성이 뛰어난 모델이지만, OpenVLA는 학습 과정에서 보지 못한 새로운 배경이나 물체, 그리고 물리적 환경 변화에서도 훨씬 더 안정적인 제어 능력을 보여주었습니다.
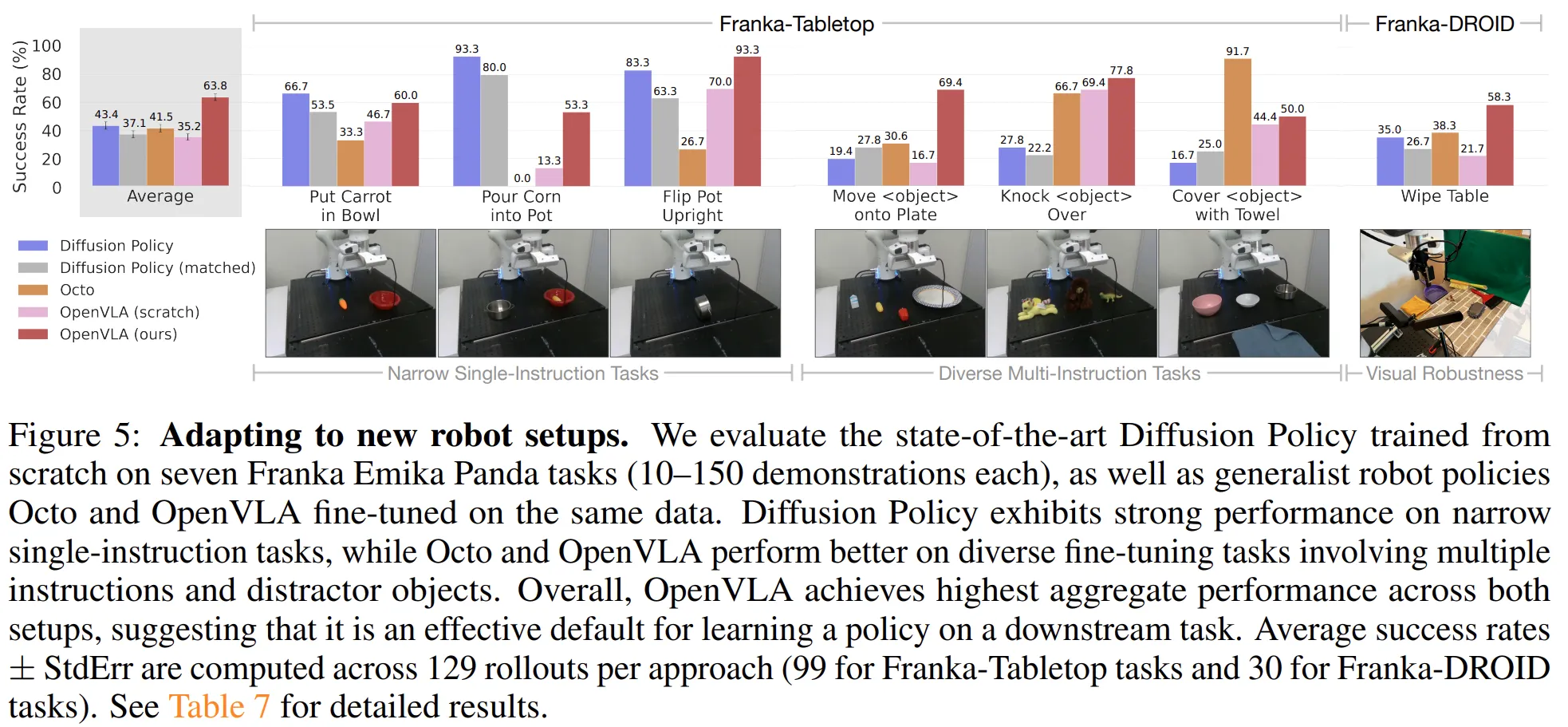 Finetuning을 수행한 결과를 비교한 실험.
Finetuning을 수행한 결과를 비교한 실험.
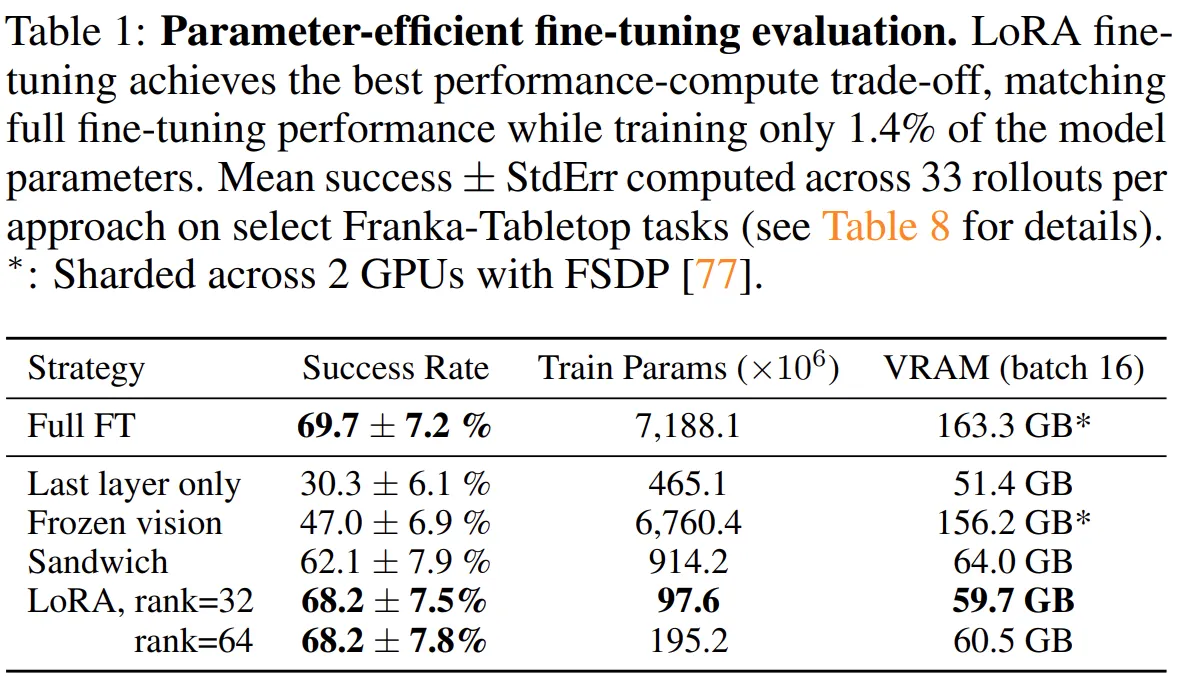 다양한 Efficient Finetuning 기법을 비교한 방법론. LoRA를 적용할 때 Full Finetuning과 유사한 결과를 낸다.
다양한 Efficient Finetuning 기법을 비교한 방법론. LoRA를 적용할 때 Full Finetuning과 유사한 결과를 낸다.
- LoRA(PEFT): 적은 파라미터 업데이트만으로도 전체 파인튜닝과 유사한 성능을 냅니다.
 다양한 Quantization을 시도한 결과와 다양한 GPU를 사용해 Inference 속도를 비교한 결과
다양한 Quantization을 시도한 결과와 다양한 GPU를 사용해 Inference 속도를 비교한 결과
- 양자화(Quantization): int4 양자화를 적용하면 성능 손실을 최소화하면서도 단 1장의 GPU에서 모델을 구동하고 파인튜닝할 수 있습니다.
5. Conclusion
OpenVLA는 VLA 모델을 오픈소스로 공개했을 뿐만 아니라, 실질적인 파인튜닝 기법들을 연구하여 VLA의 범용적 가치를 한 단계 높인 논문입니다. 단순히 거대한 모델을 만드는 것을 넘어, 연구자들이 실제로 활용 가능한 효율적인 경로를 제시했다는 점에서 큰 의미가 있습니다.
이후 지속적으로 발전하고 있는 RT-2나 Pi-0와 같은 모델들과 비교하며 읽어본다면 로봇 제어 AI의 흐름을 파악하는 데 큰 도움이 될 것입니다.
다음 논문은 RT-2로 돌아오겠습니다. 사실 RT-2는 OpenVLA보다 앞서서 발표된 논문이어서 순서 상 먼저 읽어야 했지만 첫 논문인 만큼 "대중픽"을 찾다보니 OpenVLA를 먼저 리뷰하게 되었습니다. 이 점은 이해주시기 바랍니다.
오늘도 긴 글 읽어주셔서 감사합니다.
