[논문 리뷰] RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Physical AI

안녕하세요. 그루비한입니다. 지난번에 예고한대로 오늘은 RT-2 논문을 리뷰해보도록 하겠습니다.
RT-2 논문은 Google Deepmind의 정말 많은 연구자들이 참여한 VLA라는 개념을 처음으로 제시한 논문입니다.

최근 인터넷 규모의 대규모 Vision-Language Dataset이 비약적으로 발전했지만, 이를 로봇의 실제 동작(Action)과 직접 연결하려는 시도는 여러 난관에 부딪혀 왔습니다. 기존 VLM을 로봇 제어에 활용하면 불필요한 텍스트 출력이나 프롬프트의 영향을 받기 쉽고, 로봇이 움직이기 위한 구체적인 제어값보다는 "무엇을 해야 하는가"에 대한 추상적인 답변에 그치는 경우가 많았기 때문입니다.
오늘 소개할 RT-2(Robotic Transformer 2)는 이러한 문제를 해결하고 로봇이 실제 물리 세계에서 동작할 수 있도록 VLA(Vision-Language-Action)라는 새로운 카테고리를 제시합니다.
1. Introduction: VLM에서 VLA로
저자들은 기존 VLM의 강력한 의미 추론 능력을 유지하면서도, 로봇의 Action Planning이 가능한 모델을 만들고자 했습니다. 이를 위해 로봇의 Action을 텍스트 임베딩에 맞게 변환하고, 입력된 이미지와 텍스트를 기반으로 로봇이 수행해야 할 Low-level Action을 직접 출력하도록 Fine-Tuning하는 방법론을 제안합니다.
2. Main Idea
이 논문의 저자는현재 상황의 이미지를 기반으로 텍스트로 입력되는 input을 robot이 수행하도록 하는 모델 VLA(Vision Language Action)이라는 카테고리를 새롭게 정의했습니다.
Pre-Trained Vision-Language Models
RT-2의 핵심 가설은 "이미 방대한 데이터로 학습된 VLM의 지능을 활용하여 로봇 제어 출력만 완성해내면 된다"는 것입니다. 이에 따라 PaLI-X와 PaLM-E라는 두 가지 대형 VLM을 기반으로 로봇 동작을 학습시켰습니다.
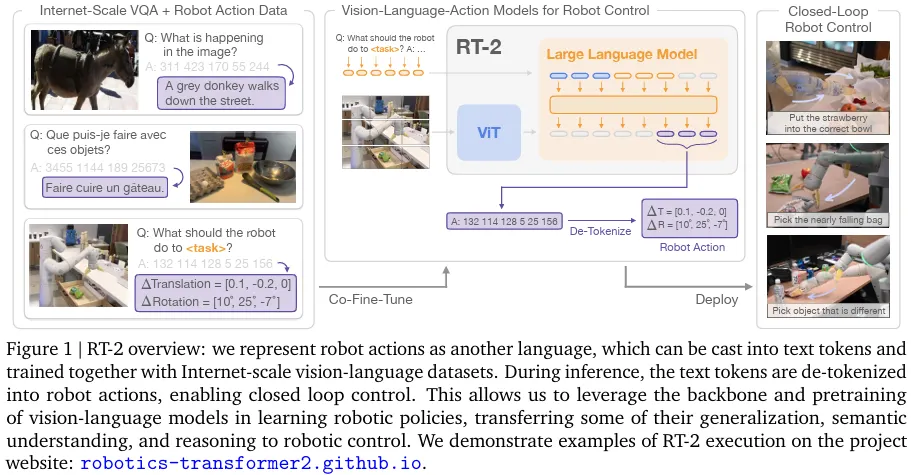 RT-2 Demo와 전체 Architecture
RT-2 Demo와 전체 Architecture
Action Tokenize: 동작을 언어로 번역하기
로봇의 동작을 VLM이 이해할 수 있는 형태로 바꾸는 과정은 매우 중요합니다. RT-2가 제어하는 6-DOF 로봇팔의 Action Space는 다음과 같이 8개의 요소로 구성됩니다.
- Positional: end-effector의 위치 (x, y, z)
- Rotational: end-effector의 각도 (roll, pitch, yaw)
- Gripper (열림/닫힘 정도)
- Termination Token: (작업 종료 여부)
저자들은 각 요소의 연속적인 값들을 256개의 구간으로 이산화(Discretization) 하여 정수로 변환했습니다. 결과적으로 로봇의 움직임은 8개의 숫자로 이루어진 하나의 문자열(Single String)로 표현되며, 이는 VLM의 토크나이저를 통해 토큰화됩니다. 예를 들어 숫자에 대한 표현이 없는 PaLM-E의 경우, 가장 적게 사용되는 토큰 256개를 Action 전용 토큰으로 교체하는 Symbol Tuning 방식을 사용했습니다.
Co-Fine-Tuning: 일반화의 핵심
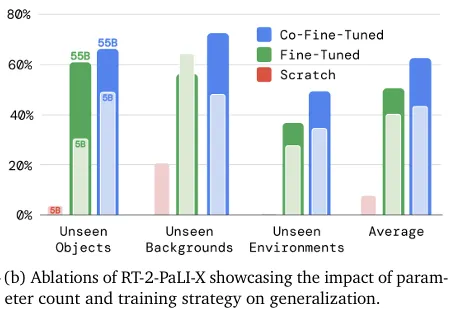 robot action dataset으로만 finetuning한 결과와 co-fine-tuned한 결과 비교 그래프.
robot action dataset으로만 finetuning한 결과와 co-fine-tuned한 결과 비교 그래프.
단순히 로봇 데이터만으로 파인튜닝을 하면 모델이 로봇 동작에만 매몰되어 VLM 본연의 일반화 성능을 잃을 수 있습니다. 이를 방지하기 위해 RT-2는 Web-scale data와 Robotic data를 동시에 학습하는 Co-Fine-Tuning 방식을 채택했습니다. 이 과정을 통해 모델이 너무 특정 동작에만 과적합되지 않고, 일반화된 시각-언어 지식을 유지할 수 있게 되었습니다.
Output Constraint
로그렇다면 앞서 우리는 RT-2에서 robot action의 output은 integer string으로 나온다고 읽었습니다. 그런데 Co-Fine-Tuning에서는 일반적인 web data도 학습했다고 하는데, 그럼 output 형식 역시 robot action과 일반적인 vlm task에서 달라져야 합니다. 저자들은 robot action으로 prompt가 주어지는 경우 유효한 action token만 output되도록 제한했고, 일반적인 vision language task의 경우 natural language output이 나올 수 있도록 허용하는 방식으로 두 task의 output 형식을 조절했습니다.
Real Time Inference
VLA는 사용자의 명령이 text로 주어지면 camera image로 시각적 정보를 확인하고 주어진 task를 action으로 움직여야 합니다. 이는 Inference 과정에서 delay를 최소화하는 것이 중요할텐데요, 이 논문을 작성한 Google Deepmind에서는 multi TPU cloud service를 활용해서 이를 realtime으로 처리할 수 있는 환경으로 만들었다고 합니다. 이런 환경을 통해 RT-2PaRL-X-55B model이라는 큰 모델도 1~3 Hz 주파수에서 처리되는 능력을 보였습니다.
3. Experiment
강력한 일반화(Generalization) 성능
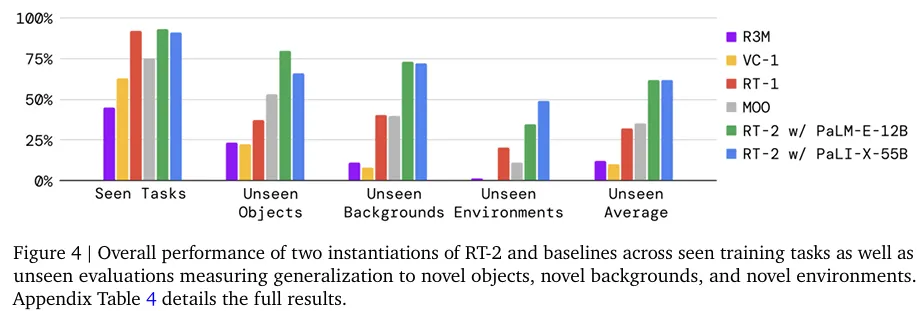
RT-2는 이미 학습된 데이터(Seen Task)에서는 기존 RT-1과 유사한 성능을 보였으나, 학습하지 않은 물체(Unseen Object)나 배경(Background)이 주어지는 환경에서는 압도적인 우위를 점했습니다. 이는 VLM의 대규모 지식이 로봇 제어에 성공적으로 전이되었음을 보여줍니다.
창발적 능력(Emergent Capability)
특히 놀라운 점은 로봇 데이터에는 없던 Semantic Reasoning(의미론적 추론) 능력이 동작에 나타났다는 것입니다.

위의 그림에서 왼쪽 첫번째 그림에서 "딸기를 올바른 그릇(correct bowl)에 담아라"라는 명령에 대해, 로봇은 'correct'라는 추상적인 단어를 이해하고 딸기를 과일들이 담긴 그릇으로 옮기는 행동을 보였습니다.
이는 기존 로봇 학습 방식으로는 불가능했던, 시각적 컨셉과 텍스트의 의미를 결합한 고도의 제어 능력입니다.
Chain of Thought(CoT) 적용

RT-2는 텍스트 프롬프트를 통해 Chain of Thought를 수행할 수도 있었습니다. 모델이 바로 행동을 출력하는 것이 아니라, 먼저 계획(Plan)을 세운 뒤 동작(Action)을 수행하는 일련의 과정을 출력함으로써 복잡한 태스크 수행 능력을 높였습니다.
4. Conclusion
RT-2는 로봇의 동작을 VLM의 토큰 체계로 편입시킴으로써, 사람이 사용하는 언어와 시각 정보를 로봇의 물리적 움직임과 완벽하게 결합했습니다. 이는 로봇이 사람의 명령을 텍스트만으로 이해하고 수행하는 시대를 연 뜻깊은 성과라고 생각합니다.
2023~2024년에는 RT-2가 VLA의 개념을 제시하고 Open-VLA가 VLA를 대중들에게 내세웠다면, 앞으로 2025년과 그 이후에 등장할 Pi-0와 같은 차세대 VLA 모델들이 Physics AI 시대를 어떻게 이끌어갔고 앞으로 어떻게 이끌어 갈지, 꾸준히 팔로우업 해볼 가치가 충분합니다.
