
안녕하세요! 오늘은 2020년 구글에서 발표한 Vision Transformer(ViT)에 대해서 논문리뷰와 코드 구현을 해보겠습니다. 이 논문은 NLP 분야에서 강력한 성능으로 이젠 가장 대표적인 base module이 된 Transformer를 vision 분야에 접목시켜 각종 분문에서 SOTA를 달성한 모델인 ViT를 제안합니다.
Paper Review
본 논문의 저자는 NLP task에서 기준이 되어가고 있는 transformer architecture를 vision task에서 활용하고 싶었습니다. 그래서 CNN을 활용하기보다 image를 patch 단위로 잘라 pure transformer에 직접 적용할 수 있는 방법을 고안하였습니다.
Transformer를 vision에 활용한 본 모델은 충분히 pre-trained된 상황에서 여러 task에서 놀라운 결과를 가져왔다고 합니다. 과연 NLP에서 좋은 성능을 보였던 Transformer를 어떻게 vision 분야에서 활용할 수 있었는지 보도록 하겠습니다.
Method
이 모델은 Transformer의 구조를 대부분 따르고 있습니다. vision과 NLP의 가장 큰 차이점이라고 하면 NLP는 단어와 단어가 sequential하게 1D로 이어져 있지만 vision은 순서라곤 없는 2D 그 이상의 dimension을 가지고 있는 것입니다. 그래서 NLP분야의 sequence을 바탕으로 작동하는 Transformer의 architecture 특성상 vision에 활용하기에 제한사항이 있었습니다. 다음으로는 이 제한사항을 어떻게 해결했는지 ViT의 architecture를 보면서 설명하겠습니다.
Vision Transformer(ViT)
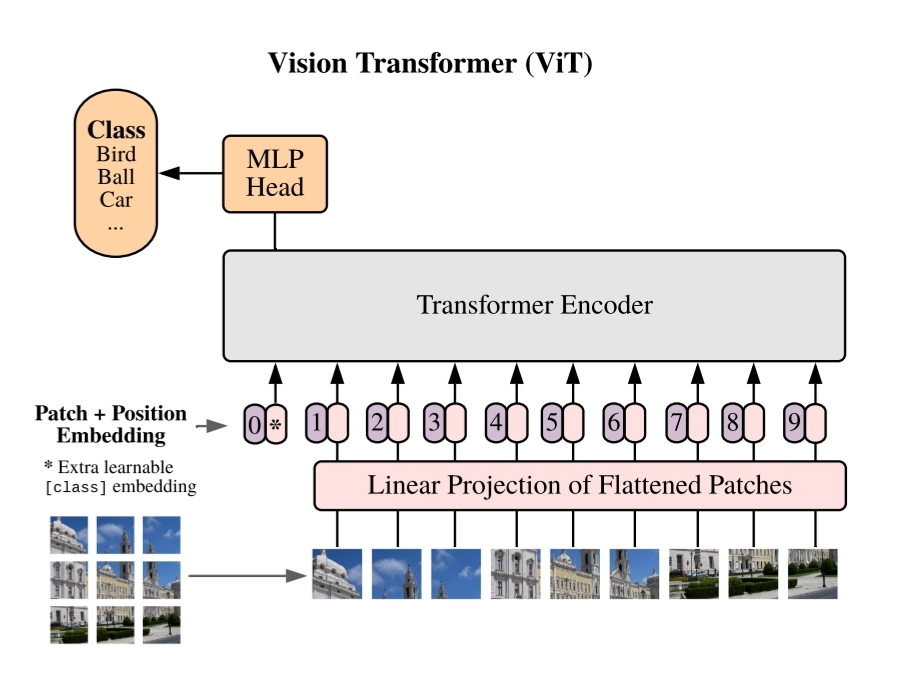
본 논문에서는 vision과 NLP에 의해 생기는 제한사항을 해결하고자 image를 position에 따라 patch로 나누어 일종의 Sequence를 강제로 만드는 방식을 사용했습니다.
patch를 만드는 방식은 간단합니다. 적당한 patch size를 정하고 image를 size에 맞춰 reshape 해주면 의 N개의 patch가 생성됩니다. 의 image를 로 reshape 하는 과정입니다.
논문에서는 Transformer의 input으로 활용될 image patch에 대한 Embedding으로 image 정보가 담긴 patch embedding과 위치 정보가 담긴 position embedding을 함께 활용했습니다. 또한 저자는 각 image의 patch sequence에 BERT의 [CLS] 토큰과 같은 역할을 하는 learnable token인 class token을 추가하여 Transformer가 반복되면서 image의 class에 대한 학습이 이어질 수 있도록 하였습니다. 전체적인 Transformer의 input()을 아래의 수식을 통해 알 수 있습니다.
: learnable한 class token
: p번째 image의 1번째 Patch Embedding
: Position Embedding
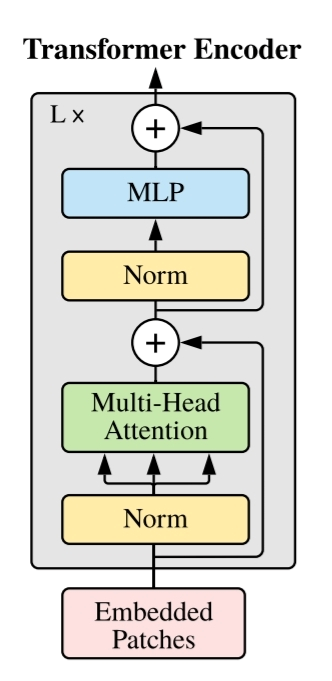
Tranformer 구조는 NLP에서의 Transformer와 크게 다르지 않습니다. Multi-Head Attention과 MLP, Layernorm, Residual connection 등이 그대로 활용되었으며, 이 Encoding Block을 L번 반복해서 전체적인 Transformer Encoder로써 활용됩니다. Transformer 과정을 수식으로 나타내면 아래와 같습니다.
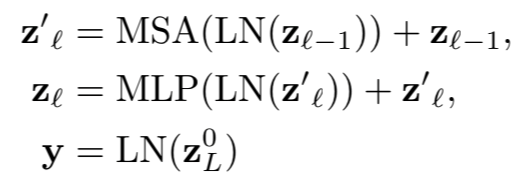
MSA: Multi-head Self Attention
MLP: Multi Layer Perceptron
y: z가 L번째 Transformer를 통과한 뒤 0번째 token(class token)
Transformer를 거친 y는 본 모델의 마지막 layer인 MLP head를 통해 최종적으로 classification 됩니다.
ViT의 특징
ViT의 특징으로 논문에서는 2가지 정도를 소개합니다.
- Inductive bias
- 논문에서는 CNN의 특징으로 locality, two-dimensional neighborhood structure, translation equivariance 가 있다고 설명합니다.
- 그러나 본 모델에서는 MLP가 locality, translation equivariance 하지만, self attention은 global합니다. two-dimensional neighborhood structure은 거의 존재하지 않습니다.
- 이처럼 저자는 본 모델이inductive bias가 거의 없어서 task-agnostic unified structure로 보는 관점을 가지고 있는 것 같습니다.
- Hybrid Architecture
- 본 모델은 hybrid model로써 CNN feature map으로부터 나온 patch를 input sequence로 활용할 수 있다고 합니다.
Fine-Tuning and Higher Resolution
Fine-Tuning
ViT는 large dataset으로 pre-train 하고, downsteam task에 대해서 fine-tuning하는 방식으로, 저자는 pre-trained prediction head 대신에 feed-forward layer()를 추가하였습니다.
Higher Resolution
논문에서는 ViT의 fine-tuning 과정에서 pre-train된 image보다 해상도가 높은 image가 input되는 경우에 생기는 문제점과 이에 대한 해결방법을 아래와 같이 설명합니다.
만일 pre-train된 image보다 fine-tuning에 필요한 image가 해상도가 상이할 경우, ViT는 Patch의 size를 조정하기 보다는 position embeddding에 2D interpolation을 추가하는 방법을 통해 이를 해결하도록 제안합니다.
Higher resolution을 가진 image는 기존의 다른 image과 동일한 patch size를 적용했을 때 상대적으로 긴 sequence의 patch들이 생성될 것입니다. 이 경우, 기존의 position embedding이 의미가 없어집니다. 따라서 본 논문에서는 2D interpolation을 통해 기존 patch들의 embedding은 유지하고, 그 사이에 추가되는 patch의 position embedding을 해주는 방식을 통해 이를 해결할 수 있습니다.
Code Review
전체적인 코드는 Github에 올려놓겠습니다. 본 포스트에서는 ViT Architecture에 대한 주요 부분의 코드만 설명합니다.
ViT를 구현하는 과정은 아래와 같습니다.
ViT Architecture
- Patch Embedding
- Multi-head Attention
- Transformer Encoder
- Classification MLP
ViT Architecture
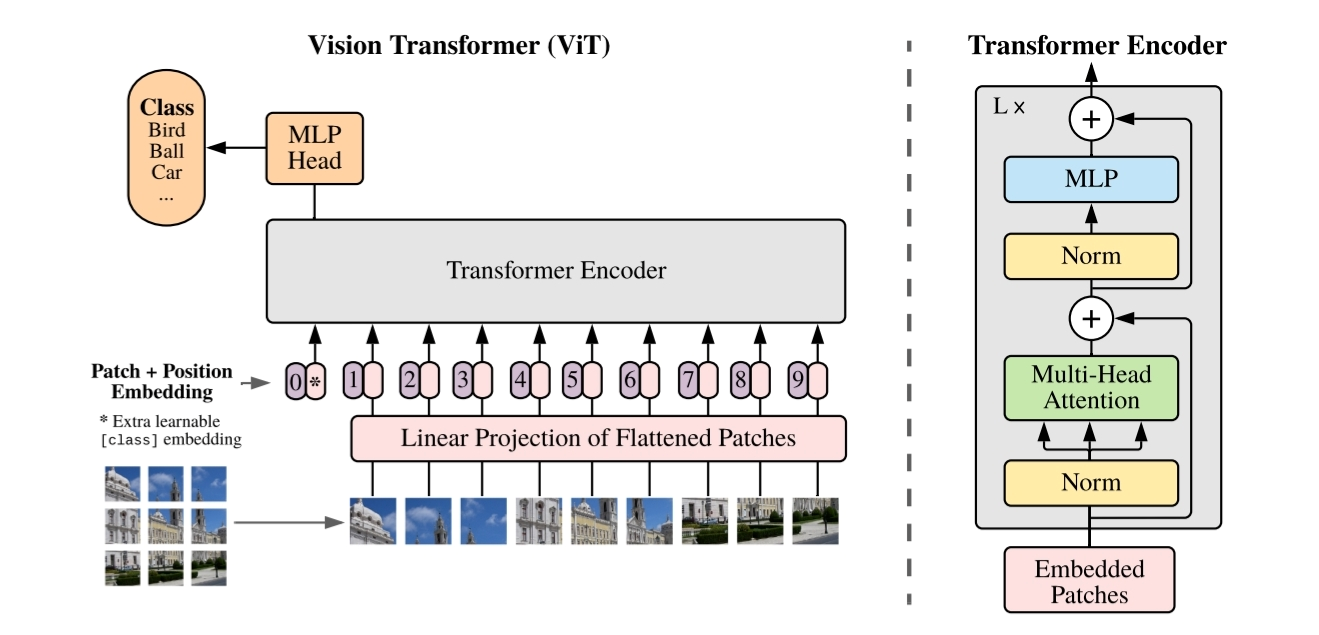
ViT의 전체적인 과정은 위와 같습니다. 본 코드리뷰에서는 여러가지 ViT 버전들 중 가장 기본적이며 가장 작은 모델인 ViT-Base를 구현하겠습니다. ViT-Base의 model variants는 아래와 같이 논문에 나와있습니다.

Patch Embedding

우선 첫번째로 image에서 patch를 생성하고 Embedding하는 과정부터 시작하겠습니다. Patch를 생성하는 과정은 크게 어렵지 않습니다. patch size를 지정한 뒤, image에 크기에 맞게 잘라주면 됩니다. 논문에서 제시한대로 image_size=224, patch size=16를 적용하면 patch는 14*14 총 196개의 patch가 생성됩니다. 그리고 ViT-Base에서는 Hidden Embedding dimension을 768로 지정하였기 때문에 Patch와 Position Embedding dimension을 768로 설정해줍니다. 이 때 Embedding을 Linear가 아닌 CNN으로 하는 이유는 저자의 코드리뷰에서 CNN을 활용한 projection이 더 좋은 성능을 가져왔기 때문입니다.
Patch Embedding 값에는 196개의 patch 뿐 아니라 앞서 설명한 class token이 추가되기 때문에 197개의 patch가 있는 것과 동일한 output을 갖게 됩니다.
class PatchEmbedding(nn.Module):
def __init__(self, in_features = 3, patch_size=16, emb_size=768):
super().__init__()
self.p = patch_size
self.c = in_features
self.e = emb_size
self.projection = nn.Conv2d(self.c,self.e,kernel_size = self.p, stride=self.p)
#stride=patch_size여야 patch 크기 별로 image가 나눠져서 의도한대로 embedding됩니다.
def forward(self,x):
b,c,h,w = x.shape
x = self.projection(x)
x = x.view(b, (h//self.p)*(w//self.p), (self.p*self.p*c)) #(batchsize,patch_num,embedding_size)
cls_tokens = nn.Parameter(torch.rand(b,1,self.e)).to(device) #cls token
x = torch.cat([cls_tokens,x],dim=1) #patch + cls_token
pos_emb = nn.Parameter(torch.rand(b, (h//self.p)*(w//self.p)+1, (self.p*self.p*c))).to(device) #pos emb
x = x+pos_emb
return xMulti-head Attention
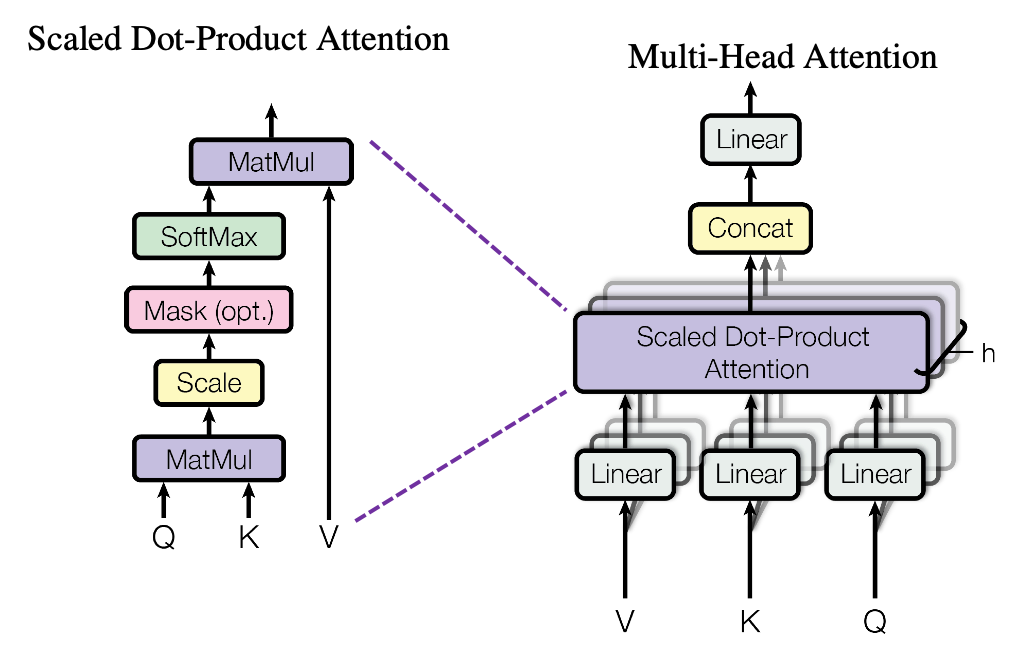
Transformer Block에서 가장 핵심이 되는 알고리즘은 Multi-head Attention입니다. Attention은 하나의 input에 대해 다른 input들의 정보들 중에 유용한 정보만을 output으로 추출한다는 데 큰 의미가 있습니다. 이런 attention의 head가 여러개라는 것은 각 input들을 병렬적으로 나누어 좀 더 세심하게 정보를 비교할 수 있다는 점에 있어 효과적입니다.
코드에서는 위의 Multi-head attention의 과정을 그대로 구현하였으며 multi-head에 대한 부분을 구현하기 위해 embedding 값을 8개의 head로 나누는 dimension을 새로 만들어 해당 dimension을 기준으로 attention 연산을 수행한 뒤 이를 다시 합쳐주는 과정을 진행하였습니다.
본 코드를 구현하면서는 torch의 einsum함수와 einops라는 개인적으로는 다소 생소한 tensor관련 모듈을 활용하였습니다. 모듈이 활용된지는 5년정도는 된 것 같은데 이제야 사용법을 알게되어 앞으로 조금 더 익숙해 질 필요가 있어보입니다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int=768, head_num: int=8, dropout: float=0):
super().__init__()
self.emb_size = emb_size
self.head_num = head_num
#self.qkv = nn.Linear(emb_size,emb_size*3)
self.query = nn.Linear(emb_size,emb_size)
self.key = nn.Linear(emb_size,emb_size)
self.value = nn.Linear(emb_size,emb_size)
self.scaling = (self.emb_size//self.head_num)**-0.5
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size,emb_size)
def forward(self,x: Tensor, mask: Tensor=None) :
#q,k,v를 linear projection 한 뒤 multi-head만큼 병렬적으로 나눠줌
queries = rearrange(self.query(x),'b n (h d) -> b h n d', h = self.head_num)
keys = rearrange(self.key(x),'b n (h d) -> b h n d', h = self.head_num)
values = rearrange(self.value(x),'b n (h d) -> b h n d', h = self.head_num)
#scaled dot-product attention
energy = torch.einsum('bhqd, bhkd -> bhqk', queries,keys)
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.masked_fill(~mask, fill_value)
att = F.softmax(energy*self.scaling,dim=-1)
att = self.att_drop(att)
out = torch.einsum('bhal, bhlv -> bhav', att, values)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.projection(out)
return outTransformer Encoder Block
Multi-head attention까지 구현했기 때문에 Transformer block 구현은 크게 어렵지 않다. 본 코드에서는 구현의 편의를 위해 Residual process, MLP(FeedForward)를 먼저 구현한 뒤, 이를 전체적으로 합쳐서 최종적인 Block 코드를 완성하였습니다.
class ResidualAdd(nn.Module):
def __init__(self,fn):
super().__init__()
self.fn = fn
def forward(self,x, **kwargs):
res = x
x = self.fn(x,**kwargs)
x += res
return xclass FeedForwardBlock(nn.Module):
def __init__(self,emb_size :int, expansion: int=4, drop_p: float=0):
super().__init__()
self.network = nn.Sequential(
nn.Linear(emb_size,emb_size*expansion),
nn.GELU(), #논문에서 GELU 제안
nn.Dropout(drop_p),
nn.Linear(emb_size*expansion,emb_size)
)
def forward(self,x):
return self.network(x)class Transformer_Encoder_Block(nn.Module):
def __init__(self,emb_size: int=768, drop_p: float=0, forward_expansion: int=4, forward_dropout: float=0, **kwargs):
super().__init__()
self.encoder = nn.Sequential(
ResidualAdd(nn.Sequential( #첫번째 Residual
nn.LayerNorm(emb_size), #LN
MultiHeadAttention(emb_size,**kwargs), #MSA
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(emb_size,expansion=forward_expansion,drop_p=forward_dropout), #MLP
nn.Dropout(drop_p)
))
)
def forward(self,x):
return self.encoder(x)Classification MLP
마지막으로 Patch를 기준으로 나눴던 image를 다시 모아 최종적인 Image에 대한 Classification을 하는 과정입니다. 각 Patch의 정보(embedding)을 평균하여 Image 전체의 embedding 값을 생성하고, 이를 이용해 Linear layer를 통해 classification이 이뤄집니다.
class Classification(nn.Module):
def __init__(self,emb_size,n_class):
super().__init__()
self.cls = nn.Sequential(
Reduce('b n e -> b e', reduction = 'mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_class)
)
def forward(self,x):
return self.cls(x)ViT
지금까지 구현하였던 ViT의 구성요소들을 모두 모아 ViT를 완성합니다. Transformer_Encoder은 Encoder Block을 12회 반복한 Architecture입니다. 전체적인 과정은 제 Github에 올려두겠습니다.
class ViT(nn.Sequential):
def __init__(self,
in_channels: int=3,
patch_size: int=16,
emb_size: int=768,
depth=12,
n_classes: int=10,
**kwargs
):
super().__init__(
PatchEmbedding(in_channels,patch_size,emb_size),
Transformer_Encoder(depth,**kwargs),
Classification(emb_size,n_classes)
)본 논문을 리뷰하고 코드를 구현해보면서 지금까지 Vision 쪽 공부만 하느라 Attention이나 Transformer와 같이 NLP에 많이 활용되는 알고리즘에 대한 이해가 부족했는데 이번 기회를 통해 공부할 수 있게 되었습니다. 앞으로도 Multi-Modal 관련 모델들도 리뷰해보면서 부족한 부분을 채워나가도록 하겠습니다.
Reference
[paper] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[code] https://github.com/FrancescoSaverioZuppichini/ViT/blob/main/README.ipynb
