[논문리뷰] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (DeepLabv3+)
논문리뷰(구현)

Semantic Segmentation 프로젝트를 진행중에, DeepLabv3+ 모델을 사용하게 되어 논문 정리를 하며 사용성을 높이고자합니다.
Introduction
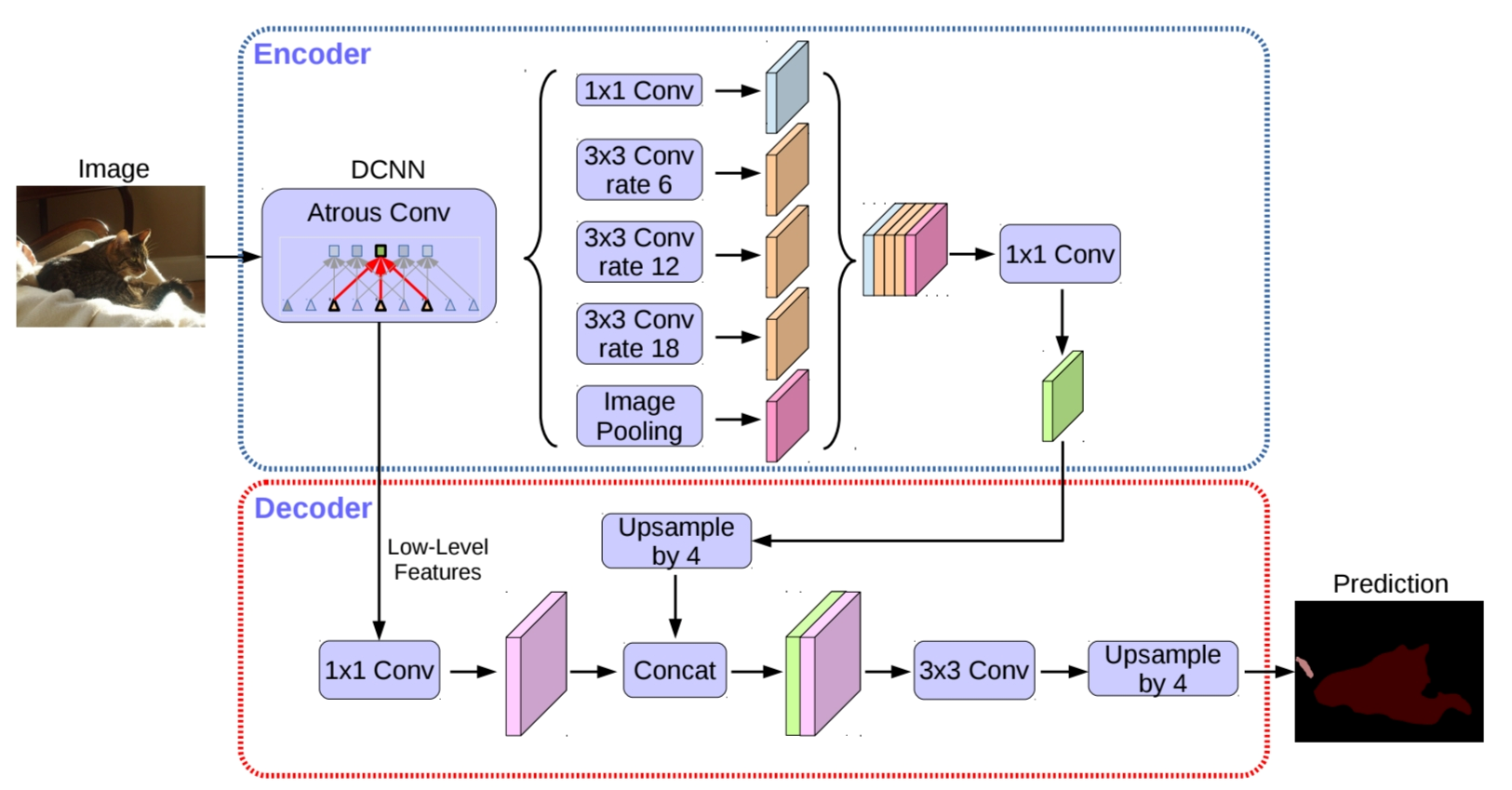
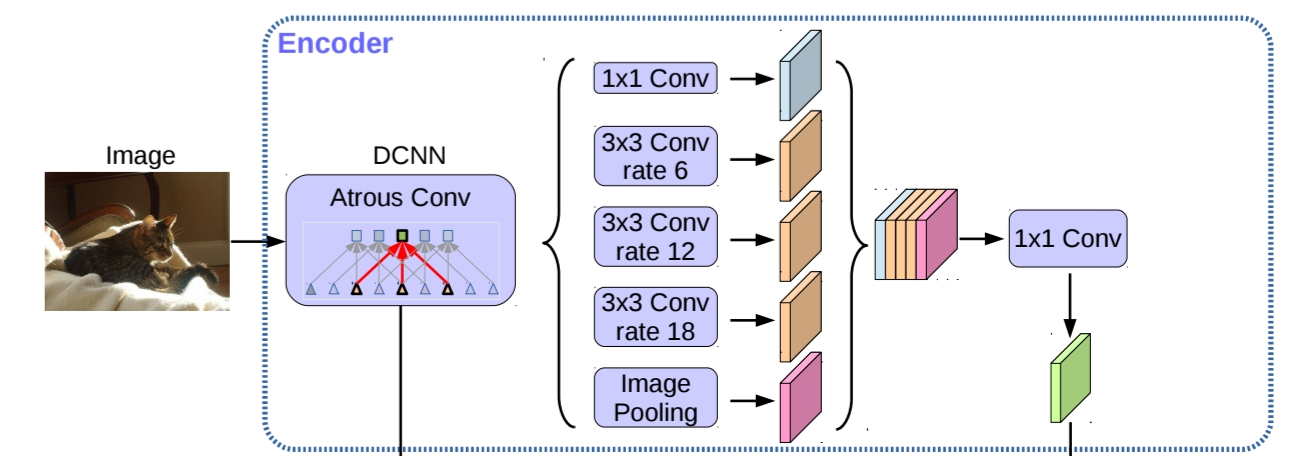
DeepLabv3+는 2가지 핵심 구조를 가지고 있습니다. 기존의 DeepLabv3에서 활용됐던 Atrous Spatial Pyramid Pooling(ASPP)과 Encoder-decoder 구조입니다. Atrous Spatial Pyramid Pooling(ASPP)은 pooling feature들로부터 contextual 정보를 가져올 수 있는 역할을 수행하고, Encoder Decoder 구조는 object boundary와 같은 세부적인 정보를 얻을 수 있다는 장점이 있습니다. ASPP가 전역적인 정보를 다루느라 놓치는 세부 정보들을 encoder-decoder 구조를 통해 보완할 수 있어 효과적이었다고 합니다.
또한 backbone으로 속도와 정확도 모두 발전시킨 depthwise separable convolution model인 Xception을 일부 수정해 활용하고, atrous separable convolution을 통해 효율적인 모델 아키텍처를 만들었습니다.
Methods
Xception
Xception은 image classification task에서 처음 소개된 모델로 빠른 속도가 장점인 모델입니다. 본 논문에서는 Xception을 encoder에 활용해 image의 중요한 정보들을 효율적으로 추출할 수 있었습니다.
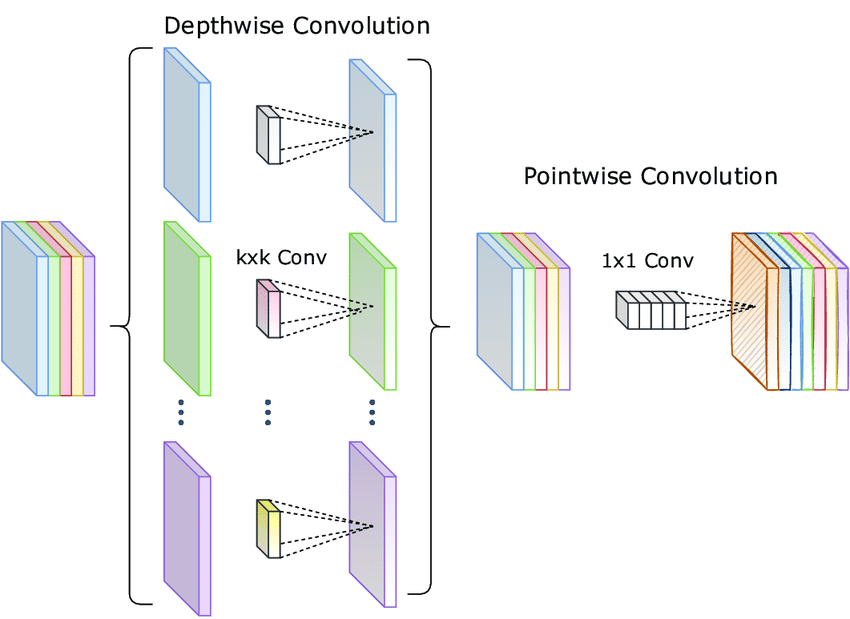
특히 논문에서는 이 과정을 Depthwise Separable Convolution 이라고 불렀습니다.
Depthwise Separable Convolution
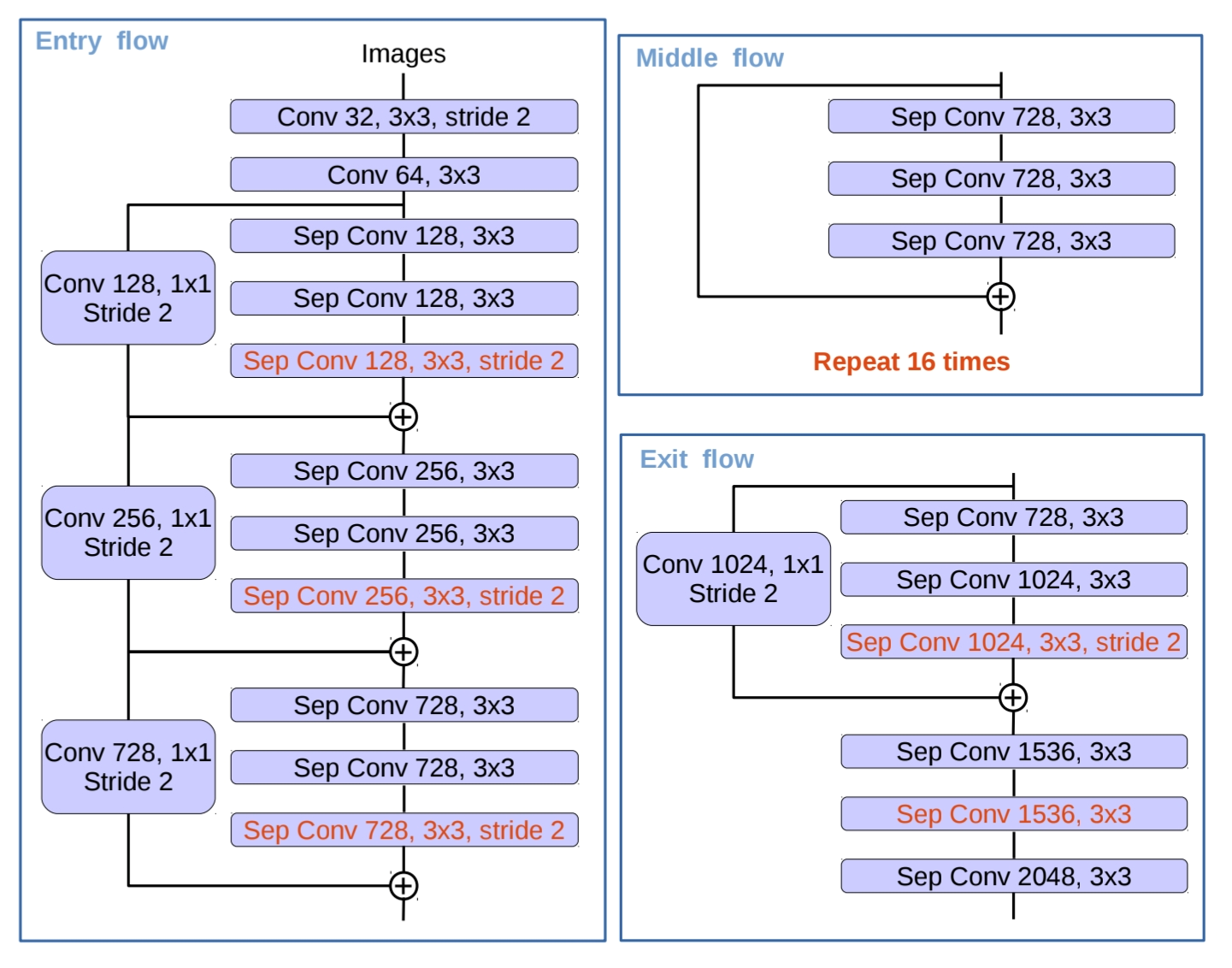
DeepLabV3+에서는 Xception에 3가지 변화를 주었습니다.
1. 더 깊은 구조의 Xception을 활용했습니다. 기존 8번의 Xception block이 반복 되는데, 이를 16번으로 늘렸습니다. (Middle flow 참고)
2. 모든 max pooling 연산을 depthwise separable convolution으로 대체했습니다. 이 부분에서 atrous separable convolution을 활용할 수 있었고, 효과적인 feature map추출이 가능했습니다.
3. 3*3 depthwise convolution 이후에 batch normalization과 ReLU를 추가해 안정적인 학습을 유도하였습니다.
Encoder-Decoder with Atrous Convolution
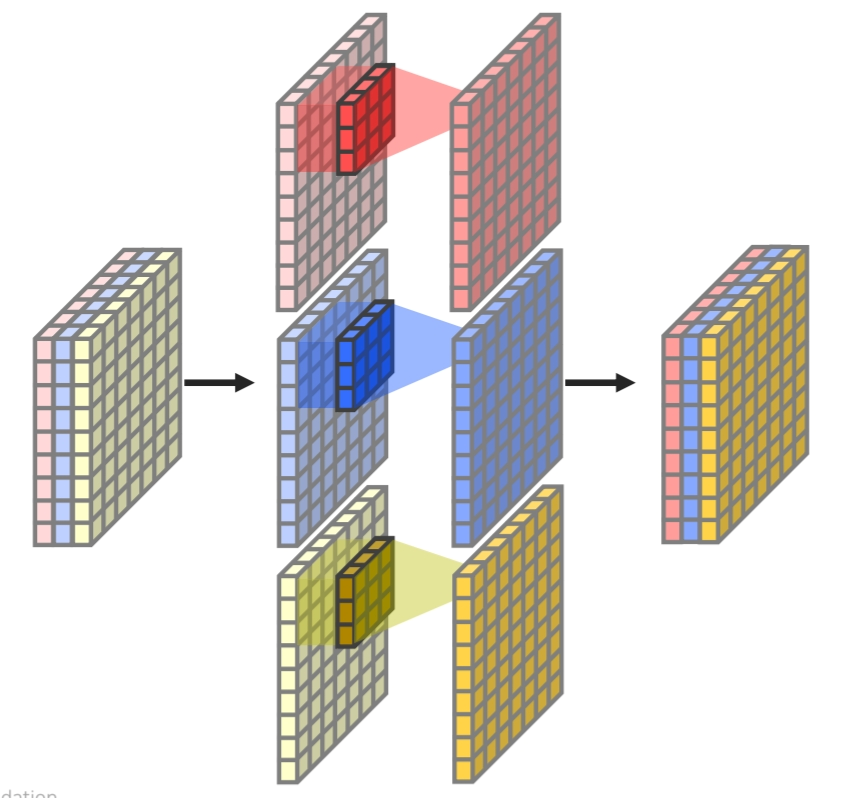
Atrous Convolution
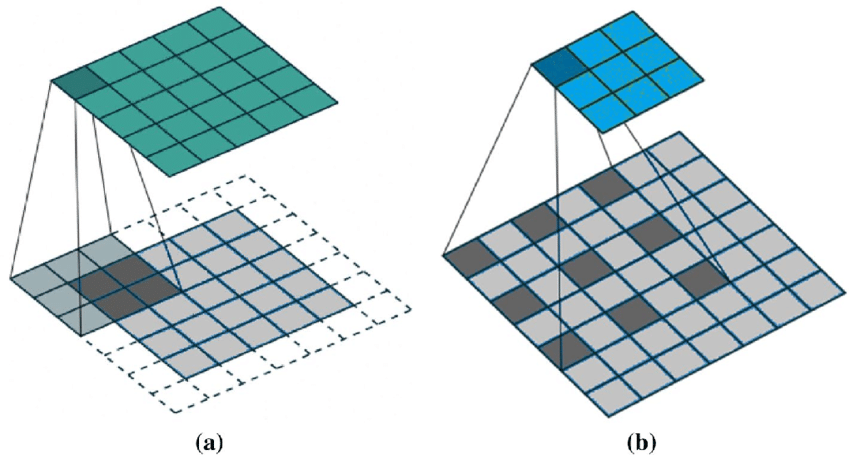
Atrous Convolution은 Delate convolution이라고도 불리며, 연속적인 픽셀의 convolution 연산이 아닌 중간 픽셀을 건너뛰며 convolution 연산을 진행해 넓은 receptive field를 가질 수 있는 convolution 연산입니다.
DeepLabv3 as encoder
Proposed decoder
Conclusion
ASPP와 Encoder-Decoder 구조를 활용해 Unet과 함께 대표적인 Semantic Segmentation Model인 DeepLabv3+를 알아보았습니다. Backbone으로 Xception을 활용하고, Atrous Spatial Convolution 활용의 의미를 알 수 있었던 논문이었습니다.
