
안녕하세요. 그루비한입니다.
최근 로보틱스 분야의 핵심 과제는 다양한 환경과 태스크에서도 강건하게 동작하는 Generalist Robot Policy를 구축하는 것입니다. 본 포스팅에서는 인터넷 스케일의 세만틱 지식과 정교한 제어 능력을 결합하여 복잡한 조작 태스크를 성공적으로 수행한 모델에 대해 심층 분석합니다.
논문 링크: arxiv

1. Introduction: VLA의 한계와 의 지향점
기존의 Vision-Language-Action (VLA) 모델들은 대규모 데이터셋을 기반으로 어느 정도의 일반화 성능을 보여주었으나, 여전히 물리적 강건성(Robustness)과 복잡한 환경에서의 정교한 제어 능력에는 한계가 있었습니다. 특히, 단순한 텍스트 기반의 고수준 추론(High-level reasoning)을 넘어 로봇의 말단 장치(End-effector)를 위한 저수준 제어(Low-level control)를 어떻게 효율적으로 통합할 것인가가 주요 병목 지점이었습니다.
는 Pre-trained Vision-Language Model (VLM)에 Flow Matching 아키텍처를 융합하여 이 문제를 해결합니다. 이는 인터넷 스케일의 시각-언어 지식을 유지하면서도, Flow Matching을 통해 물리적 행동의 연속적인 분포를 정교하게 모델링함으로써 Zero-shot 일반화와 High-level instruction 수행 능력을 극대화한 범용 로봇 정책 모델입니다.
2. Background
2.1 Flow Matching

Flow Matching은 데이터의 분포를 학습하기 위해 Vector Field(벡터장)를 예측하는 생성 모델 방법론입니다. 기존 Diffusion 모델이 노이즈로부터 점진적인 디노이징 스텝을 거치며 분포를 찾아간다면, Flow Matching은 노이즈()에서 데이터()로 향하는 가장 효율적인 최단 경로(Vector Field)를 학습하는 데 집중합니다.
 벡터장(Vector Field)
벡터장(Vector Field)
- Probability Density Path (확률 경로): : 에서 까지 가는 동안 임의의 시점 t의 확률 분포
- Vector Field () : t시점에 가 움직여야 하는 속도와 방향
- Flow (): 벡터장을 시간 에 대해 적분하여 얻은 실제 데이터 포인트 의 이동 궤적.
Flow Matching의 핵심은 다음과 같은 상미분 방정식(ODE)을 통해 정의됩니다.
에서 활용하는 Conditional Flow Matching (CFM)은 특정 데이터 포인트 이 주어졌을 때, 노이즈 에서 로 향하는 최단 경로(직선 경로)를 설정합니다.
이 경로의 시간에 대한 미분값, 즉 시점 에서의 속도는 다음과 같이 단순한 상수가 됩니다.
학습 시 모델은 예측된 벡터장 와 실제 목표 벡터 사이의 차이를 최소화하는 방향으로 최적화됩니다.
이 방식은 수십 번의 스텝을 거치는 Diffusion에 비해 훨씬 적은 단계로도 정확한 행동 궤적을 생성할 수 있어, 실시간성이 중요한 로봇 제어에 매우 적합합니다.
2.2 Mixture of Experts (MoE)
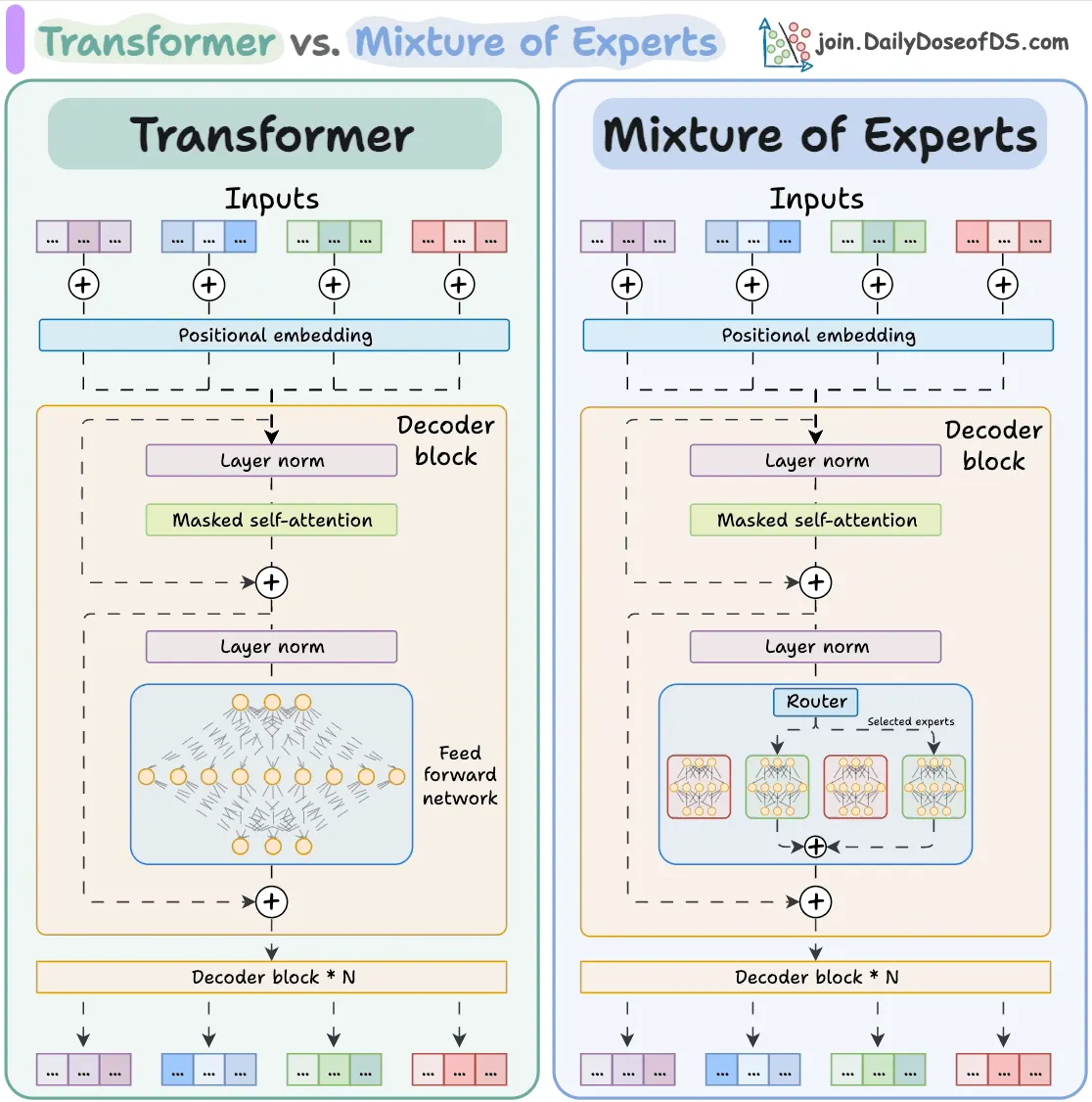 일반적인 Transformer와 mixture of expert를 활용한 transformer
일반적인 Transformer와 mixture of expert를 활용한 transformer
Mixture of Experts는 트랜스포머의 FFN(Feed-Forward Network) 레이어에 Router를 도입하여, 입력 토큰의 특성에 따라 특정 가중치(Expert)만을 활성화하는 구조입니다. 이는 모델의 파라미터 규모를 키우면서도 연산 효율성을 유지하고, 서로 다른 도메인(예: 언어 vs 행동)에 대한 전문성을 분리하여 학습하는 데 효과적입니다.
3. Main Idea
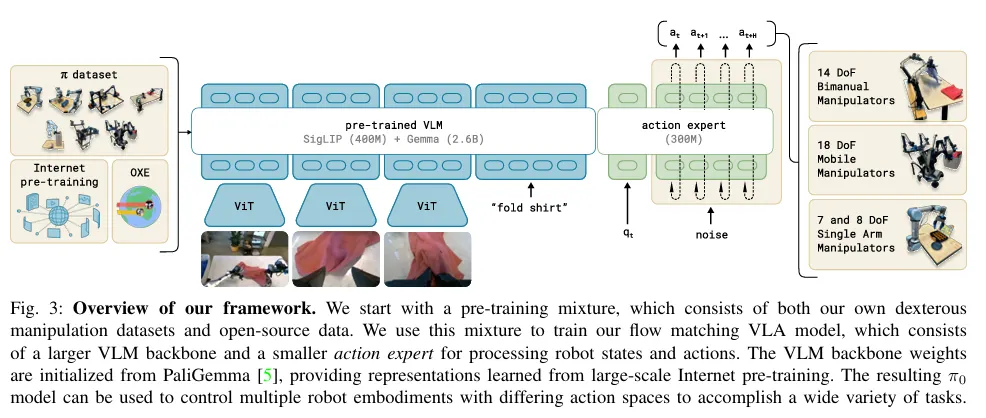 architecture
architecture
모델의 핵심 설계 사상은 Pre-trained VLM이 보유한 풍부한 인터넷 스케일 지식(Semantic Knowledge)을 온전히 보존하면서, 로봇 제어에 최적화된 Action Expert를 성공적으로 이식하는 데 있습니다. 이를 위해 저자들은 Flow Matching 기법을 도입하여 복잡한 행동 분포를 효과적으로 모델링했습니다.
3.1 Architecture: Transfusion 기반의 Dual-head 구조
는 PaliGemma를 백본으로 하며, Transfusion 아키텍처에서 영감을 받은 하이브리드 학습 방식을 채택했습니다. 단일 트랜스포머 디코더 내에서 출력의 성격에 따라 Loss Function을 이원화하여 학습합니다.
- Discrete Tokens (Language/Vision): 일반적인 VLM 태스크를 수행할 때는 기존과 동일하게 Cross-Entropy Loss를 사용합니다.
- Continuous Actions (Robotics): 로봇의 저수준 제어를 위한 Action 예측 시에는 Flow Matching Loss를 사용합니다.
이러한 구조적 특징은 Mixture of Experts(MoE)의 개념과 맞닿아 있습니다. 입력 데이터가 일반적인 시각-언어 문맥일 때는 텍스트 예측에 특화된 가중치를 활용하고, 로봇 제어와 관련된 시각 정보 및 상태 벡터가 입력될 때는 Action Expert라고 불리는 전용 가중치 셋을 활성화함으로써 두 도메인 간의 간섭을 최소화합니다.
3.2 Input/Output 및 데이터 표현
모델은 시점 에서의 관측값 를 입력받아, 이후 시점까지의 행동 시퀀스인 Action Chunk 를 예측합니다.
- Input (): 멀티뷰 카메라 이미지 , 언어 지시문 , 그리고 로봇의 조인트 상태 벡터 로 구성됩니다. 이미지와 상태 벡터는 각각의 인코더를 거쳐 언어 토큰과 정렬되도록 프로젝션됩니다.
- Output (): 형태의 연속적인 행동 분포 를 따르는 결과물입니다.
3.3 Flow Matching을 통한 Action Chunking
의 가장 혁신적인 지점은 Action Expert가 Flow Matching을 통해 학습되고 추론된다는 점입니다. 학습에 사용되는 Loss Function은 다음과 같습니다.
이 수식을 로보틱스 관점에서 해석하면 매우 흥미롭습니다.
-
벡터장()의 예측
모델은 현재 입력 와 플로우 상의 시점 에서의 분포 를 보고, 정답 행동 분포인 에 도달하기 위한 최적의 속도와 방향(최단 거리 벡터)을 예측하도록 학습됩니다. -
시간 개념의 분리 ( vs )
여기서 는 실제 로봇이 동작하는 물리적 시간(Real-world time)을 의미하며, 는 노이즈 분포()에서 실제 행동 분포()로 수렴해가는 생성 프로세스상의 시점(Flow-matching time)을 의미합니다.
Inference 과정에서는 학습된 벡터장 를 따라 ODE(상미분 방정식)를 풀며 행동을 도출합니다. 저자들은 실시간성을 확보하기 위해 를 10개의 스텝으로 나누어 수치 적분을 수행하며, 매 스텝마다 현재 위치 에서 (정답 행동) 방향으로 이동해야 할 벡터를 예측하며 Action Chunk를 완성해 나갑니다.
3.4 Action Expert의 Attention 메커니즘
Action Expert 내에서 행동 토큰들은 Bidirectional Attention Mask를 통해 처리됩니다.
기존의 인과적(Causal) 마스킹과 달리, 행동 토큰들은 앞서 입력된 시각/언어/상태 정보를 모두 참조할 수 있을 뿐만 아니라, 동일한 Action Chunk 내의 미래 시점 행동 토큰들과도 상호 참조(Self-attention)가 가능합니다. 이러한 전방위적 어텐션 구조는 Action Chunk 내부의 시간적 일관성을 확보하고, 전체적인 행동 궤적의 완성도를 높이는 데 결정적인 역할을 합니다.
4. Data Collection 및 Training Recipe
성능의 핵심은 아키텍처뿐만 아니라 고품질의 대규모 데이터셋과 이를 학습시키기 위한 정교한 전략에 있습니다.
4.1 Multi-stage Training
- Pre-training: 특정 태스크에 국한되지 않고 다양한 물리적 역량(Physical capability)을 습득하는 단계입니다. OXE, Bridge v2, DROID 등 공개 데이터셋과 더불어 자체 수집한 903M 타임스텝 규모의 대규모 데이터를 활용합니다.
- Post-training: 특정 다운스트림 태스크의 성공률을 높이기 위해 정제된 데이터를 사용하여 미세 조정하는 단계입니다. 이 과정을 통해 모델은 빨래 개기나 박스 조립과 같은 고난도 작업에서 전문성을 확보합니다.
4.2 Dataset 가공 및 Balancing
자체 수집 데이터셋은 Single-arm뿐만 아니라 Dual-arm 데이터를 포함하며, 복잡한 조작 시나리오를 다수 포함하고 있습니다. 특정 태스크(예: 빨래 개기)에 편향되는 것을 방지하기 위해 태스크-로봇 조합에 따른 가중치 조절( 스케일링)을 통해 데이터 분포를 최적화했습니다.
5. Result
Zero-shot
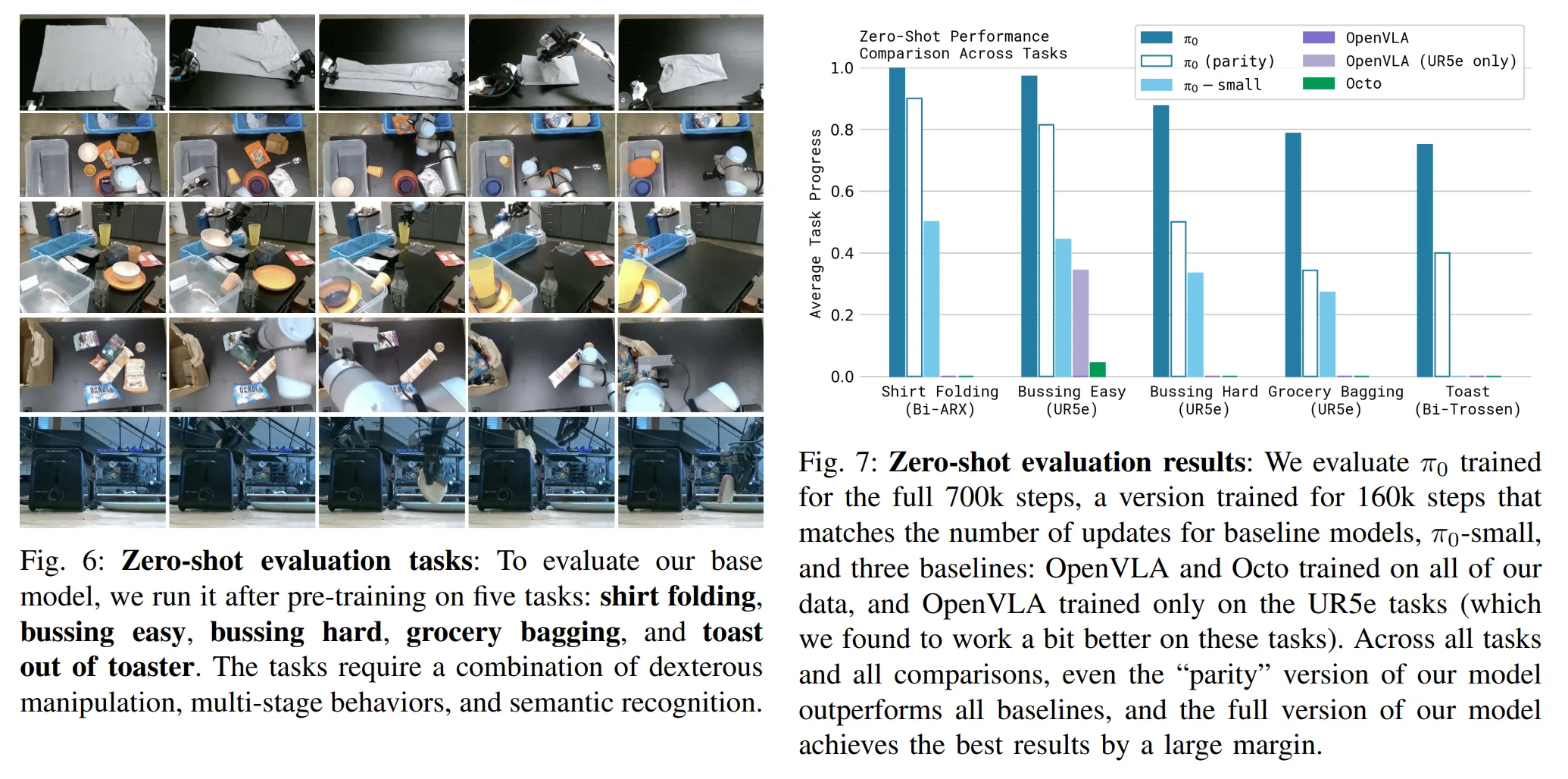
다양한 로봇들과 다양한 Task를 수행했음에도 Zero Shot 성능이 대부분 비슷한 것을 보면 상당히 일반화가 잘된 상태로 학습되었음을 알 수 있습니다.
Fine-tuning
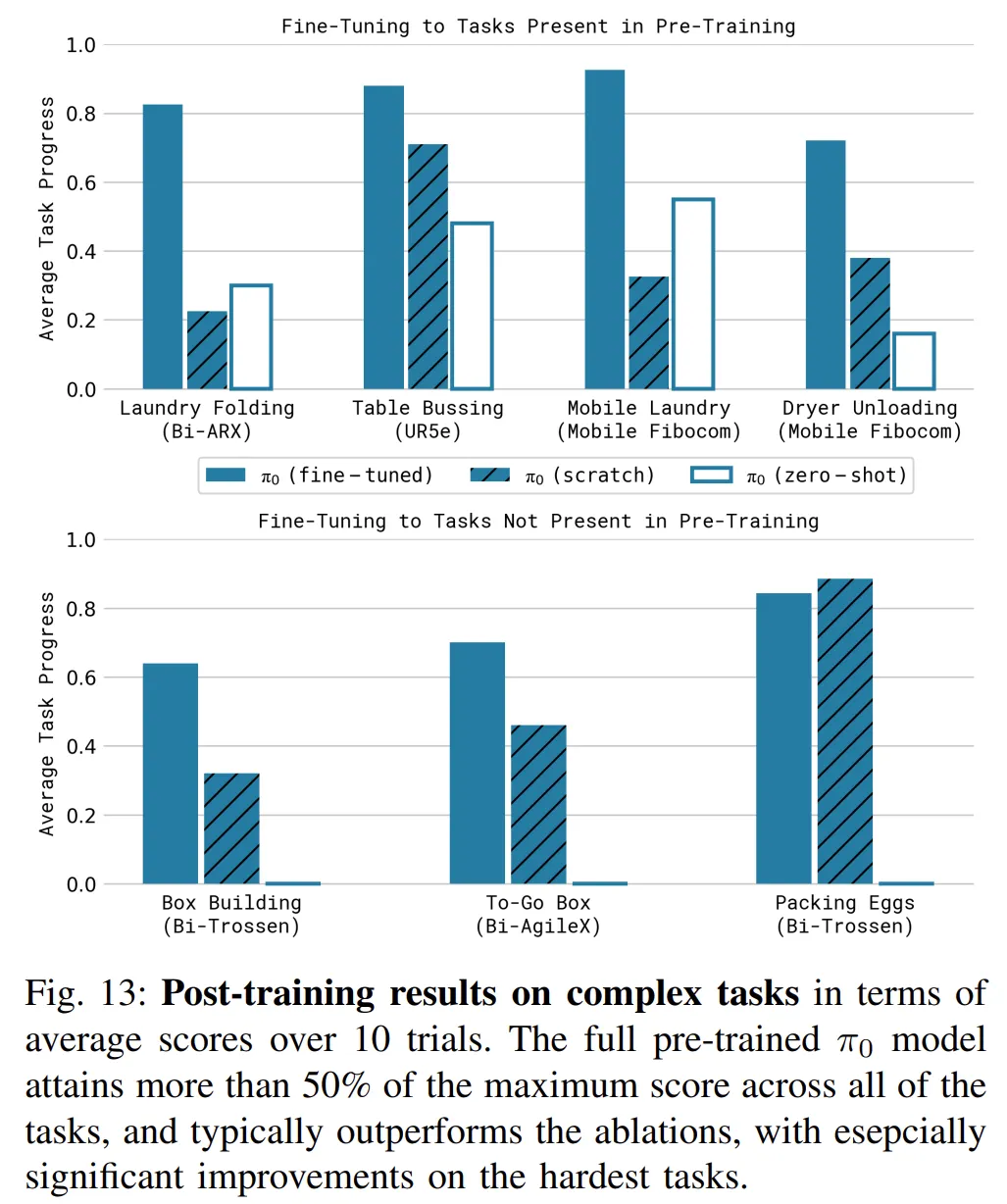
사전 학습에서 보지 못한 태스크라 할지라도, zero shot과 Scratch부터 학습한 모델 대비 finetuning을 수행한 뒤 압도적인 수렴 속도와 성공률을 기록했습니다.
Conclusion
는 이미지 생성 분야의 최신 기법인 Flow Matching과 LLM의 MoE, 그리고 대규모 VLM 지식을 로보틱스 도메인에 완벽하게 통합한 모델입니다. 이는 로봇 제어가 더 이상 고립된 분야가 아니며, 최신 Generative AI의 방법론이 Physics AI의 난제들을 해결하는 핵심 열쇠가 될 것임을 보여주는 중요한 이정표입니다.
고수준의 언어 지능과 저수준의 물리 제어를 단일 프레임워크 내에서 성공적으로 결합했다는 점에서, 는 진정한 의미의 범용 로봇 시대를 앞당기는 혁신적인 연구라고 평가할 수 있습니다.
