[논문 리뷰] Efficient and Degradation-Adaptive Network for Real-World Image Super-Resolution
논문리뷰(구현)
안녕하세요! 오늘은 오랜만에 논문리뷰를 해보려 합니다. 요새 회사에서 온보딩 프로젝트로 Super Resolution 모델 개발 과제를 맡게되어 다양한 SuperResolution 관련 논문들을 읽어보고 있습니다. 그 중 오늘은 Real-World SuperResolution 모델 중 하나인 DASR에 대해서 알아보겠습니다.
Background
SuperResolution 이란?

SuperResolution(SR)은 저해상도 이미지를 고해상도로 변환시켜주는 모델입니다. 최근 유튜브 영상을 보다보면 과거 영상을 고해상도 영상으로 변환해 HD로 옛날 드라마를 보여주거나 하는 영상들을 볼 수 있습니다. 이렇듯 SuperResolution(SR)은 실생활에 유용하게 활용될 Vision Task 중 하나로, 저 역시 이미지 데이터를 다루다보면 화질이 좋지 않은 이미지들이 있는데, 이런 경우 SR을 활용해 고품질의 데이터를 확보할 수 있을 것이라 생각하고 있습니다.
SuperResolution의 발전사
가장 전통적인 방식은 Bilinear, Bicubic interpolation과 같은 보간법이 있습니다. 그러나 이런 보간법은 이미지 크기를 키우는 것만 가능했지 고주파 정보를 복원해내지는 못했습니다.
점차 딥러닝이 발전하면서 CNN을 활용한 SR 모델이 등장하기 시작했습니다. CNN을 활용한 최초의 SR모델은 SRCNN(2014) 이었습니다. 이미지를 업샘플링한 후 CNN을 적용해 고해상도 이미지를 생성하는 과정이 있었습니다. 그러다가 Sub-Pixel Shuffle 방식을 적용한 모델인 ESPCN(2016)이 등장해 기존 방식보다 계산량을 줄이고 성능을 개선할 수 있었습니다.
GAN과 같은 생성모델이 등장하면서 SR모델에도 적용되기도 하였습니다. 대표적으로 SRGAN(2017), ESRGAN(2018)이 있습니다. 이 때 SR의 대표적인 loss 중 하나로 인간의 시작적 품질을 기준으로 평가하는 Perceptual loss도 처음으로 도입되었습니다.
ViT의 등장으로 Transformer가 Vision에 활용되고 난 이후에는 SwinIR(2021), Restormer(2022)와 같은 Transformer 구조를 활용한 SR 기법이 발전했습니다. SwinIR은 현재까지도 대표적인 SR 모델로 뽑히고 있습니다.
최근에는 Diffusion Model을 활용한 생성 모델의 큰 발전으로 SR 모델에도 Diffusion을 적용한 SR3(2024)와 같은 모델 등 지속적으로 발전되고 있습니다.
SuperResolution의 다양한 연구 분야
Degradation-aware Super-Resolution
실제 저해상도 이미지는 단순 Bicubic 다운샘플링이 아닌 다양한 degradation을 포함하고 있습니다. 따라서 degradation modeling을 포함하는 연구 분야인 Blind SR이나 Real-world SR이 활발하게 발전하고 있습니다. 오늘 알아볼 DASR모델도 이와 같은 연구 방향을 따라간 모델입니다. (예: BSRGAN, Real-ESRGAN, DASR)
Lightweight & Fast SR
모바일/엣지 기기용으로 경량화 모델이 필요해 발전되고 있는 분야입니다. 대표적인 모델로는 Mobile-ESRGAN, FastSR, Real-Time SR 등이 있습니다.
DASR(Degradation Adapted Super Resolution) 논문 리뷰
Introduction
앞서 설명했다시피 Real-World SR은 실제 우리가 찍은, 찍었던 사진을 복원하는데 큰 의미가 있씁니다. Real-World SR이 필요한 이유는 저품질의 이미지가 단순히 해상도 축소만 있는 것이 아니기 때문입니다. 실제로는 blur, noise 등 다양한 요인들이 사진에 포함되기 때문에, 이런 부분을 모두 고려하면서 사진을 복원할 수 있는 모델의 필요성이 대두되었습니다.
저자는 DASR모델을 통해 효율적이면서, 효과적인 Real-World SR 모델을 제안하고자 하였습니다. 기존의 Real-World SR 모델들은 Low Quality가 심한 경우에만 효과적이어서 다양한 frequency를 갖고 있는 이미지에 유연하게 적응하지 못한다는 단점과, heavy backbone network에 의존하고 있어 on device로 활용되기에 불리하다는 점이 있었습니다.
저자는 이 두가지 단점을 보완하고자 다양한 degrade image에 적용가능한 degradation-adaptive pipeline과 다양한 degradation space에서 효과적으로 SR이 수행가능한 none-linear MoE network를 활용했습니다.
Model Arhcitecture
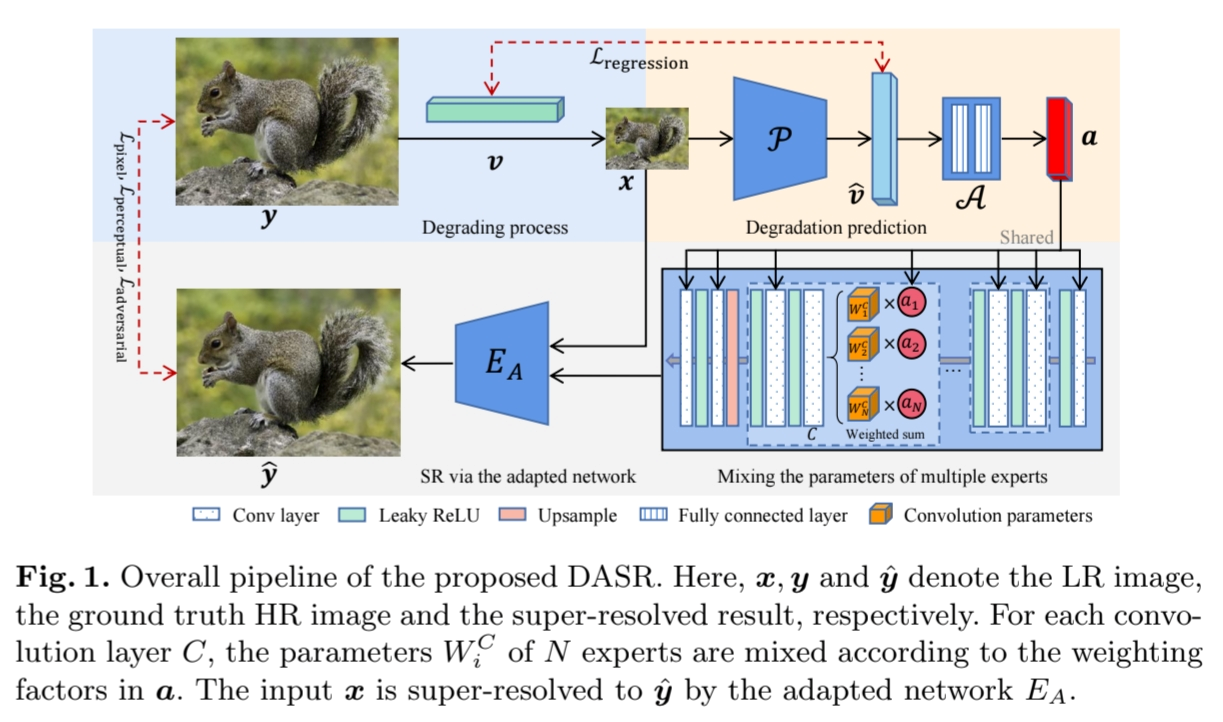
Degradation-Adaptive Super Resolution
모델은 저해상도 이미지()와 고해상도 이미지() 를 활용해 와 유사한 을 생성하는 것을 목표로 합니다.
이 과정에서 3개의 작은 모델들이 활용됩니다.
- 고해상도 이미지가 저해상도 이미지로 변환(->)되는 degradation parameter 를 예측하는 regression network
- 을 통해 예측한 degradation parmeter 으로부터 MoE의 가중치 행렬 를 추정하기 위한 tiny two fully-connect layer network
- input 를 고해상도로 변환하는 super-resolved 모델인 adapted network
Degradation prediction network
Low Resolution 이미지(LR) 와 High Resolution 이미지(HR) 간의 degradation parameter vector인 는 이미지 간의 degradation의 요인을 나타냅니다. 저자는 blurring, resizing, noise corruption, JPEG compression의 요인이 있다고 봤고, 4개의 요인으로 이미지가 degradation 되는 vector ()를 생성했습니다.
그리고 모듈 는 6개의 convolution layer로 이루어져 있으며 LR로부터 를 예측하는 task를 수행합니다. 이때 ground-truth 와 간의 -norm을 통해 모듈을 학습합니다.
Image Super-Resolution Network
모델이 다양한 degradation된 이미지들을 효과적으로 다루기 위해서는 다양한 degradation 단계에 대해 유연하게 SR이 이루어져야 합니다. 저자는 그러면서도 모델은 효율적이길 바랬습니다. 따라서 효율적이면서 유연함(model capacity)을 위해 non-linear mixture of experts(MoE)를 활용했습니다.
MoE는 N개의 convolution expert로 이루어져 있고, 이 expert는 각각 작은 SR network들입니다. 모든 expert는 같은 구조의 network이며 동일한 loss를 통해 학습합니다. 이러한 부분 덕분에 SR모델의 효율성을 유지할 수 있었습니다.
이러한 MoE는 다양한 degradation 환경을 각 expert 별로 나누어 특화된 degradation 환경에서 학습하여 해당 환경의 전문가(expert)가 되도록 유도됩니다.
Degradation을 통해 각 Expert의 가중치를 나누기 위해서 활용되는 것이 벡터이고, 이 벡터는 추정된 degradation parameter인 가 를 통해 생성된 결과물입니다. 따라서 는 one-hot vector로 입력 이미지의 degradation 정도에 따라 각 전문가의 기여도를 결정하게 됩니다.
따라서 가중치 벡터 와 MoE의 각 Expert의 Convolution layer의 결합으로 아래의 수식과 같이 각 입력 이미지에 맞게 최적의 가중합을 적용한 커널을 생성하게 됩니다. 특히 일반적인 MoE와 다르게 activation function을 활용해 비선형성을 강화했습니다.
이러한 과정을 통해 다양한 degradation된 LR에 대해 SR 적용이 가능했으며, 모델은 모두 작은 모델들로 이루어져 효율성도 확보할 수 있었습니다.
Conclusion
오늘은 MoE를 활용해 다양한 LR 이미지에 적응해 SR을 수행하는 모델인 DASR에 대해 알아보았습니다. 실생활에 적용을 위해 모델의 수용성을 높이면서 효율성까지 챙긴 것이 대단하다고 보여집니다.
내일은 Diffusion 모델을 활용한 SR3에 대해서 리뷰해보도록 하겠습니다.
