
안녕하세요. 오늘은 Super Resolution 모델에 Knowledge Distillation을 통해 경량화를 시도한 연구 중, 가장 최근에 이뤄진 것으로 보이는 Dynamic Contrastive Knowledge Distillation 논문을 리뷰해보겠습니다.
Introduction
본 논문은 Dynamic Contrastive Knowledge Distillation을 활용한 image restoration framework를 제안하고 있습니다.
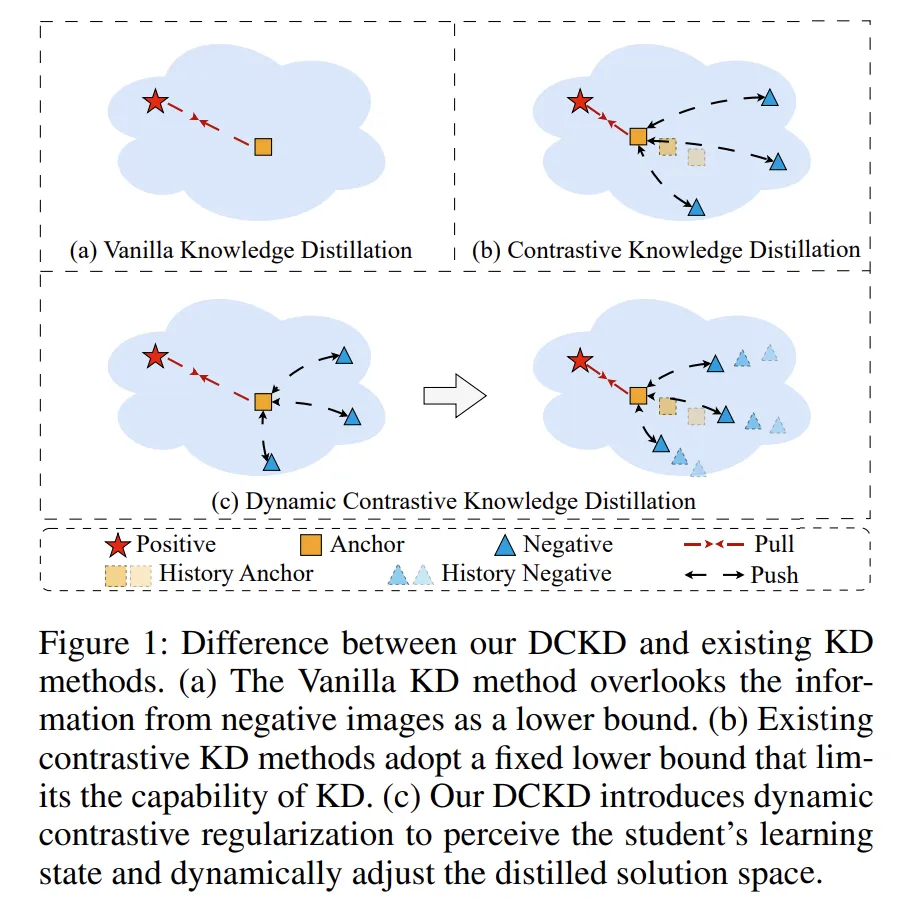 다양한 Knowledge Distillation 기법들과 DCKD
다양한 Knowledge Distillation 기법들과 DCKD
기존의 Knowledge Distillation이라고 하면 (a)와 같이 Teacher Network로부터 추출된 Positive Sample로 부터 지식을 증류받는 Vanilla Knowledge Distillation방식을 떠올리곤 한다. 그러나 이 Vanilla KD 방식은 Teacher의 출력값을 모방하지만 Teacher의 Feature map을 학습하지는 못하다는 단점이 있어 이를 극복하고자 Contrastive learning을 활용해 Teacher의 feature는 positive sample로 두고, 의도적으로 negative sample을 생성해 효과적으로 Student가 Teacher와 비슷한 특징을 가질 수 있도록 유도하는 Constrastive Knowledge Distillation으로 발전되었습니다.
본 논문에서는 이 Contrastive KD를 발전시켜 Negative Sample도 점차 Positive와 가깝게 생성하여 Student가 Teacher의 특징을 더 잘 표방할 수 있도록 유도하는 Dynamic Contrastive Knowledge Distillation을 제안합니다. 논문에서는 이 negative sample을 lower bound라고 표현하며 Student가 잘못된 방향으로 학습되지 않도록 규제(regularize)한다고 표현합니다.
또한 기존 Knowledge Distillation 모델들은 이미지를 통한 추론, 객체 인식 등 high level vision task 에서 좋은 성능을 보이기 위해 entire output distribution을 Student 모델에 증류하는 기법을 활용해 왔습니다. 그러나 Image Restoration은 low level vision task 로써 기존의 방식이 효과적이지 못했습니다. 이를 보완하기 위해 저자는 pixel wise image distribution information을 지식 증류하는 방법을 활용하기 위해 VQGAN의 codebook을 활용한 distribution mapping module(DMM)을 제안합니다.
본 논문의 Contribution은 아래와 같습니다.
- Dynamic Contrastive Distillation Framework를 제안하며 student model이 dynamic lower bound를 통해 solution space로의 효과적인 학습이 가능하도록 유도
- Distribution Mapping Module(DMM)을 통해 기존 KD 기법이 Image Restoration에 효과적이지 못했던 부분을 해결하고 새로운 방식의 information distillation이 가능했다.
- 논문을 통해 제안하는 DCKD framework를 통해 Image Supe-Resolution 뿐만 아니라 Deblurring, Deraining 등 다양한 Image Restoration task에 활용할 수 있다.
Methodology
본 논문은 크게 2가지의 파트로 나누어 모델을 소개합니다.
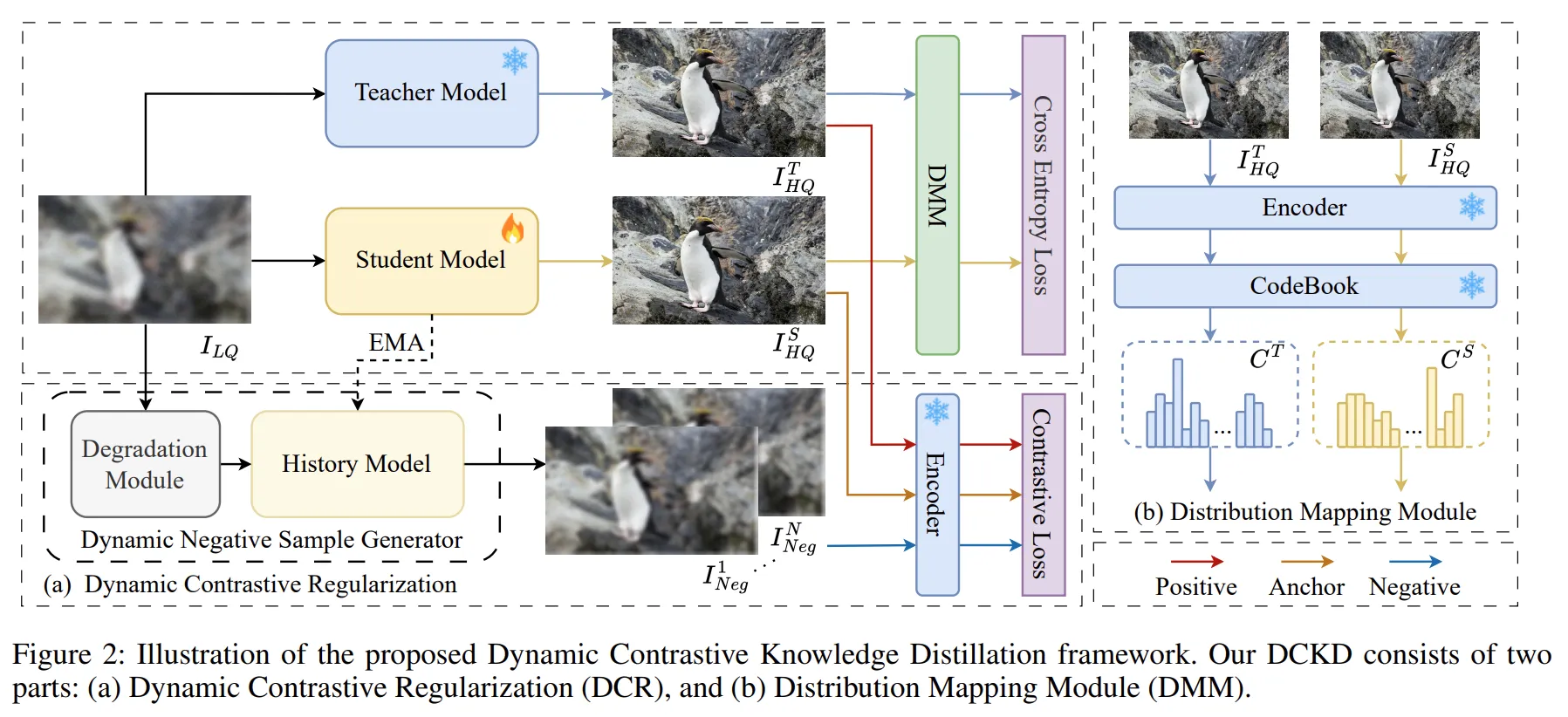
Dynamic Contrastive Regularization
저자는 Dynamic Contrastive Regularization을 통해서 아래와 같이 표현합니다.
Dynamic lower-bound constraint that progressively narrows the solution space, and can also be combined with enhanced upperbound approaches.
Lower bound가 Dynamic하게 움직이면서 Solution space를 좁힘으로써 Student Model이 Teacher Model의 특성을 더 잘 표방하도록 유도합니다.
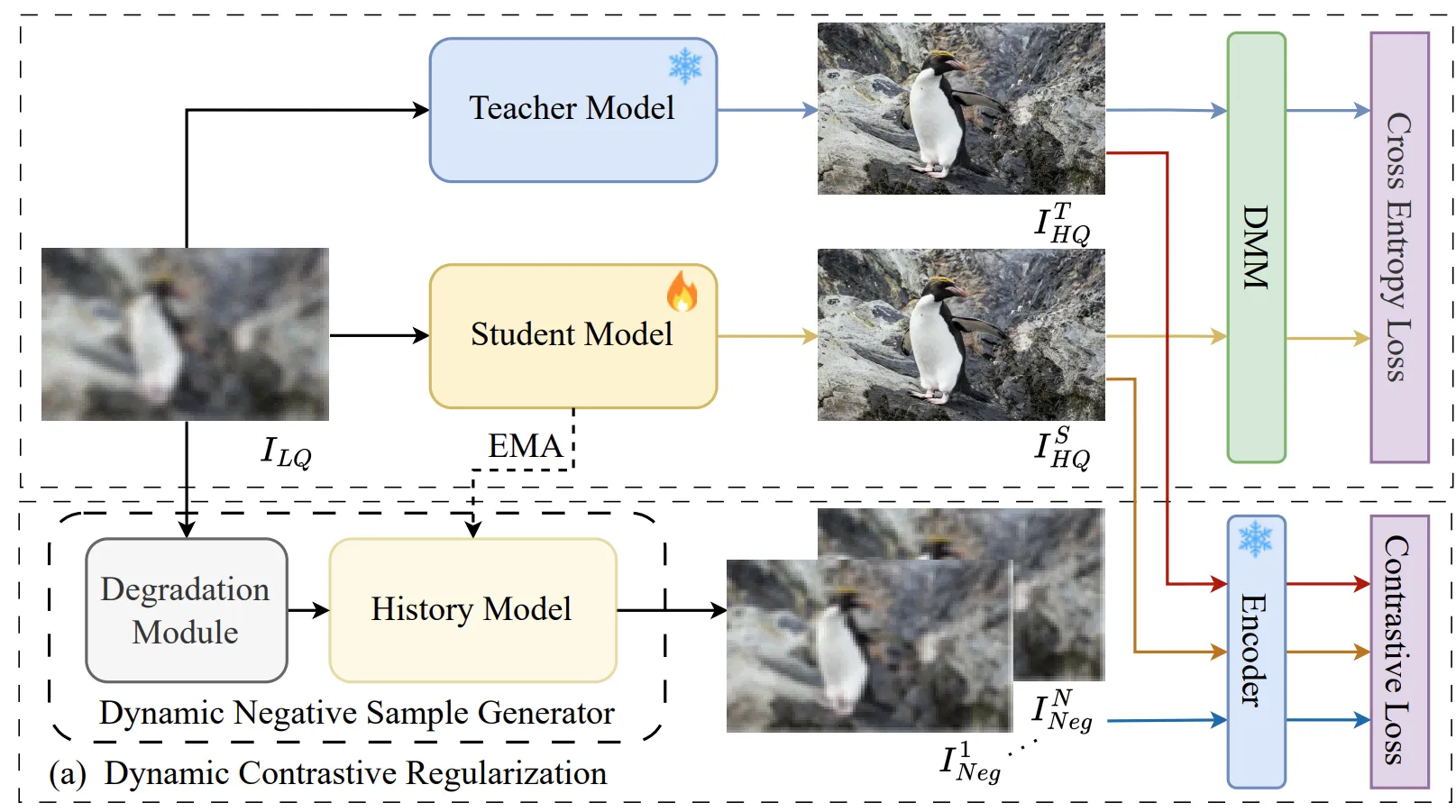 Dynamic Contrastive Regualarization Architecture
Dynamic Contrastive Regualarization Architecture
저자는 Lower bound를 만들기 위해 기존의 Low Quality의 이미지()에 의도적으로 Degradation을 통해 Noisy한 Low Quality 이미지()를 생성합니다. 그리고 이 이미지를 history model()이라고 하는 Student model 기반의 모델을 통해 Super Resolution을 수행합니다. 그러면 기존의 을 통해 SR을 수행한 에 비해 저품질의 Noisy한 SR 이미지()가 생성될 것 입니다. 저자는 이러한 N개의 이미지들을 Negative Sample 이미지()이라고 칭하며 모델이 반대방향으로 학습해야할 Lower Bound로 삼았습니다.
이때 Degradation Module은 N개의 sample에 대해 랜덤하게 노이즈를 추가합니다. 또한 를 통해 Negative sample을 생성하는 History Model()은 exponential moving average 방식으로 student model의 상태를 따라 업데이트 되며, 이러한 과정은 Lower Bound가 Dynamic하게 움직이며 Solution Space가 점차 좁아지는 효과가 있었습니다.
그리고 Solution space의 upper bound는 ground truth()이미지 뿐만 아니라 teacher model을 통해 생성한 High Quality의 SR이미지 ()를 Positive Image()로 활용했습니다.
위와 같이 설정된 solution space의 upper와 lower bound 이미지들과 Student Model의 SR output은 추후 설명할 VQGAN의 feature encoder를 거치게 되고, 인코더를 통해 생성된 각각의 feature map을 활용하여 Dynamic Contrastive Loss를 계산해 Student Model를 학습합니다.
Dynamic Contrastive Loss는 아래와 같습니다.
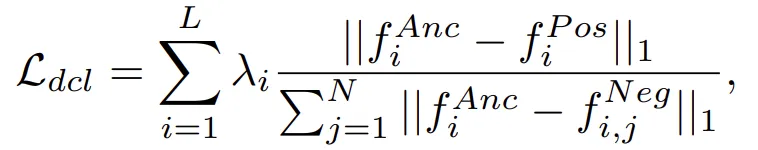
- : Student Model의 SR 이미지 feature
- : Teacher Model의 SR 이미지(Upper bound) feature
- : History Model의 SR 이미지(lower bound) feature
위의 식에 따라 Student Model은 Negative Feature 로부터 멀어지고, Positive Feature와는 점차 가까워지는 방향으로 학습하게 됩니다.
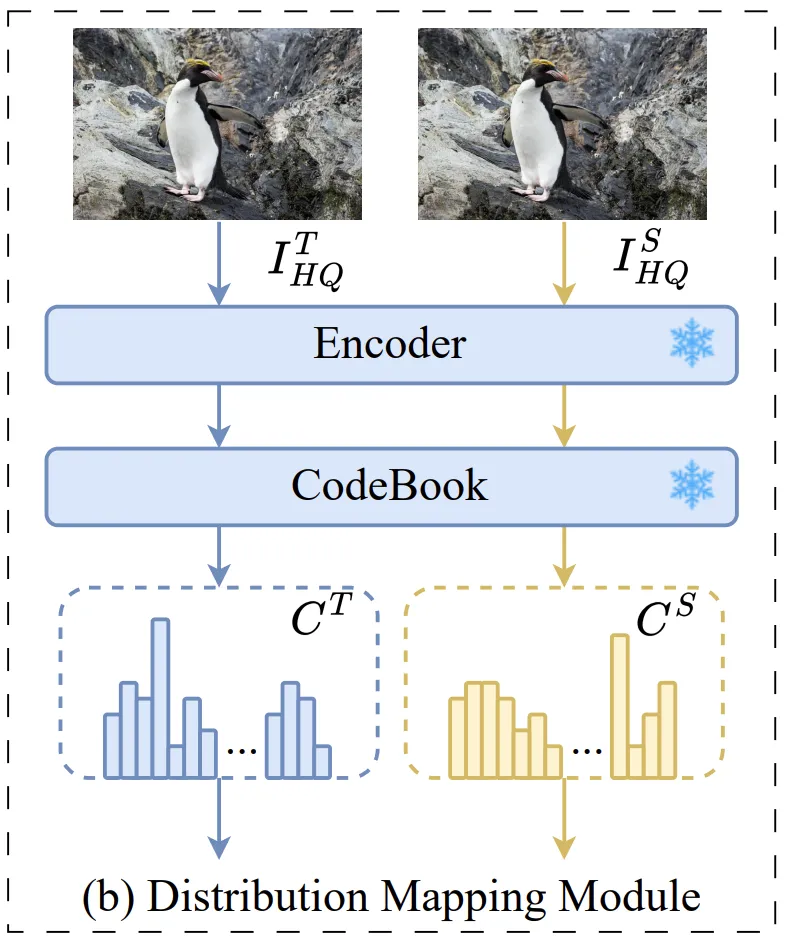
Distribution Mapping Module
 기존 KD의 Image-level distribution과 DMM의 Pixel-level Distribution
기존 KD의 Image-level distribution과 DMM의 Pixel-level Distribution
Distribution Mapping Module은 기존 KD 방법론들이 High level task에 맞춰 제안되어 Low level task에서는 잘 활용되지 못한 부분을 지적하며 이를 보완하기 위해 저자가 제안한 모듈입니다.
기존의 KD는 Student Model이 Teacher Model의 Image level 피쳐들의 distribution에 따라 학습되어 왔습니다. 그러나 이미지 전체에 대한 추론이 아닌 이미지의 지역적인 정보들이 중요한 low level task의 경우 이와 같은 학습 방법론은 의미가 없습니다. 따라서 논문에서는 Teacher Model의 Feature에서 픽셀 단위 distribution에 맞춰 Student Model이 학습될 수 있도록 유도하는 모듈인 Distribution Mapping Module을 제안한 것입니다.
 DMM Architecture
DMM Architecture
Distribution Mapping Module은 위에서 보는 것 처럼 이미지를 Encoder과 Codebook을 거쳐 Category distribution으로 변환합니다.
이 과정은 VQGAN에서 가져왔습니다. VQGAN의 Encoder와 Codebook을 그대로 활용하며, Codebook은 ImageNet을 통해 학습했습니다. 이 codebook()은 이미지 피쳐를 pixel-wised category distribution로 변환하는데 중요한 역할을 합니다.
Teacher 모델과 Student 모델의 Category distribution은 위의 식처럼 Feature와 codebook()의 벡터들 간의 L2 norm에 Softmax 연산을 통해 계산된 확률값들을 의미합니다. 이렇게 얻어낸 와 는 cross-entropy loss()로 연산됩니다.
Overall Loss
최종적으로 Student 모델이 학습하게 되는 loss는 앞서 언급한 과 를 포함하여, 기존 SR 모델의 가장 기본적인 loss인 와 Knowledge Distillation의 loss인 를 모두 결합해 이뤄진다.
- 와 :
최종적으로 학습에 활용되는 loss는 과 에 가중치가 포함된 아래와 같은 loss function을 갖습니다.
Experiments
Experimental Settings
Teacher Backbones
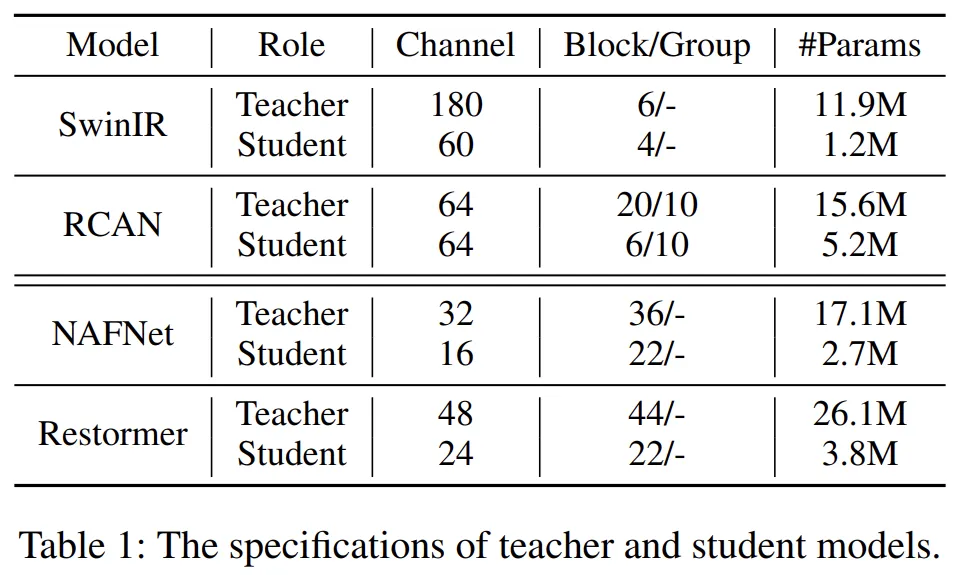
기본적으로는 Student 모델을 Teacher와 같은 모델 구조의 경량화된 모델로 구성해 실험에 활용한다. Image Super-Resolution 모델로는 SwinIR과 RCAN, Image Restoration 모델로는 NAFNet과 Restormer 모델을 실험에 활용했다.
 SuperResolution과 Image Restoration 실험에 활용된 Teacher, Student Model Pair
SuperResolution과 Image Restoration 실험에 활용된 Teacher, Student Model Pair
Datasets and Evaluation
학습 데이터셋: DIV2K (800 images)
평가지표: PSNR, SSIM
Results and Comparison
Image Super Resolution 실험결과만 정리합니다.

Image Super Resolution의 기존 KD 기법들인 MiPKD, FAKD에 비해 개선된 SR 성능을 보여줍니다. 특히 x4 행의 마지막 DCKD*은 DCKD 기법을 다른 KD 기법인 DUCK와 결합해 upper bound constraints를 개선시킨 모델인데, 이 기법을 활용하면 성능을 좀 더 향상시킬 수 있었다고 합니다.

실제 이미지와 비교해보아도 기존의 다른 KD SR 모델들과 비교했을 때 정량적, 정성적으로 우수한 SR 성능을 보여줍니다.
Conclusion
지금까지의 Knowledge Distillation이 high level Vision task에 특화되었다는 점에서 벗어나기 위해 DMM을 새롭게 제안하고 lower bound를 dynamic하게 만들어 solution space를 좁게 설정해 효과적인 KD가 가능하게 했던 저자들의 아이디어 돋보인 논문이었습니다. 이 논문을 잘 참고해 회사에서 수행하고자 하는 IR Image에 잘 적용해봐야겠습니다.
