
Abstract
Masked attention Mask Transformer는 어떠한 image segmentation task에도 좋은 성능을 보이는 model architecture로서 개발 되었다. 특히 cross attention을 mask region으로 제약을 두어 localized feature만 추출하는 masked attention이 핵심이다. 이 모델을 통해 panoptic, instance, semantic segmentation에서 SOTA를 달성했다.
Introduction
현재 segmentation 모델들은 segmentation task의 종류에 따라서 SOTA segmentation architecture들이 각기 다르다. 저자는 task들에 관계 없이 모두 좋은 성능을 내는 universal architecture를 만들고자했다.
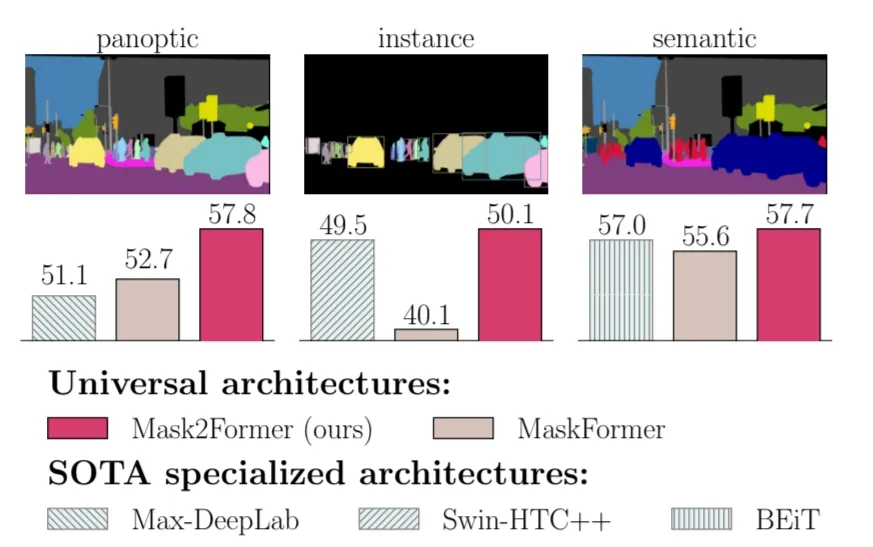
저자가 Masked-attention Mask Transformer를 통해 제안하는 universal image segmentation architecture는 이런 task specific model architecture들보다도 좋은 성능을 내면서 다양한 task에 활용 가능하다.
Masked-attention Mask Transformer
Mask2Former는 우선 MaskFormer의 구조에 따라 backbone, pixel decoder, Transformer decoder로 구성되어 있다.
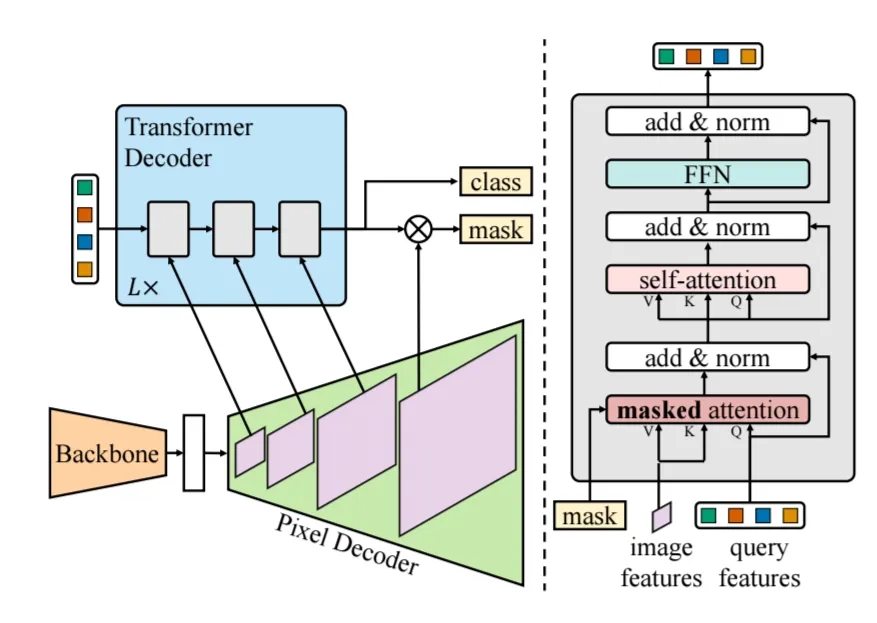
- backbone은 이미지로부터 low-resolution feature map을 추출합니다.
- pixel deocder는 image feature로부터 upsampling을 수행하며 high resolution의 per pixel embedding을 생성합니다.
- Traansformer decoder는 object query를 활용해 image feature들로부터 classification과 mask를 생성하기 위한 output query를 생성합니다.
Classification
MaskFormer architecture의 특징은 pixel 단위 classification이 아니라, masking을 통해 pixel을 우선 그룹화하고, 이 결과를 N개의 category로 classification하는 과정으로 segment가 이뤄진다는 것입니다.
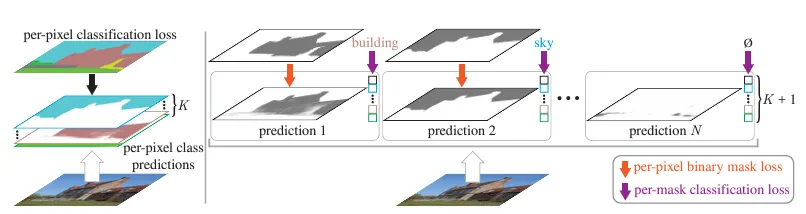 per pixel classification과 per mask classification의 차이
per pixel classification과 per mask classification의 차이
따라서 Mask2Former에서는 Transformer Decoder의 output으로 masking을 생성하고 이 mask를 분류하는 classification 연산을 차례로 수행하게 됩니다.
Transformer decoder with masked attention
기존의 Maskformer에서 가장 크게 변화된 부분은 Transformer decoder로 Masking을 활용한 cross attention인 masked attention과 self attention을 차례로 수행하게 됩니다. 이 때 Masking은 pixel단위 그룹을 생성해 해당 그룹에 대해서만 attention이 수행되도록 해당 pixel group에 대해 binary masking해줍니다.
또한 Pixel Decoder에서 upsampling을 통해 얻은 다양한 scale의 feature map을 Transformer decoder에서도 scale에 따라 차례로 활용하는 efficient multi-scale strategy를 활용하였으며, 이러한 구조를 L번 반복하는 round robin fashion 방식을 활용했습니다.
마지막으로 기존의 standard한 cross-attnetion transformer와 다르게 mask attention을 self attention보다 먼저 활용하는 구조로 변경하였습니다.
Masked attention
저자는 Image segmentation 분야에서 cross attention을 활용한 Transformer based model들의 수렴속도 문제를 해결하기 위해 Masked Attention을 고안하였습니다. Masked Attention은 기존의 cross attention에 masking을 축한 형태로 각 query별로 예측된 mask의 region에 대해서만 attention이 이뤄져 전체 image를 attention하는 것보다 빠르고, 효율적으로 query feature를 update할 수 있었습니다.
High Resolution features
High-resolution features는 small object를 에측하는데 특히 좋은 성능을 보여주지만, 많은 연산량을 필요로 합니다. 이를 해결하기 위해서 저자는 efficient multi-scale strategy를 활용했습니다. pixel decoder를 feature pyramid를 만들고, 각 feature 별로 하나의 transformer layer에 활용되도록 했습니다. 그리고 각 resolution 별로 sinusoidal position embedding과 learnable scale-level embedding을 활용했습니다.
Optimization improvements
추가적으로 성능 향상을 위해 아래와 같은 변경사항들을 적용하였습니다.
-
switch the order of self- and cross-attention(masked attention)
self-attention을 먼저 적용하는 것은 image에 대한 정보가 포함되지 않은 채 query feature를 업데이트하기 때문에 효율성 측면에서 불리했습니다.
-
make query features learnable
learnable query feature()를 supervised 방식으로 학습하여 초기 Masking()을 예측하게 하는 역할을 했으며, 이는 RPN과 비슷한 역할이라고 합니다.
-
remove dropout in decoder
Improving training efficiency
universal architecture를 학습하는 과정은 high resolution mask prediction을 해야하기 때문에 memory consumption이 커질 수 밖에 없습니다. 이를 해결하기 위해서 segmentation model의 예측값의 loss를 모두 계산하는 것이 아닌, 예측값에서 랜덤하게 point를 뽑아 mask loss를 연산하는 방법을 활용했습니다.
matching loss는 모든 prediction과 ground truth mask에서 일정하게 K개의 point를 뽑아 loss를 연산하였으며, Final loss에서는 importance sampling을 활용하였습니다. 이러한 학습 방식은 메모리 사용량을 3배 가까이 줄이는데 활용되었습니다.
Experiments
각 Segmentation Task에 대한 성능 비교 실험을 진행하며 하나의 meta architecture로 다양한 segmentation task에서 SOTA를 달성했다고 설명하고 있습니다.
Panoptic Segmentation
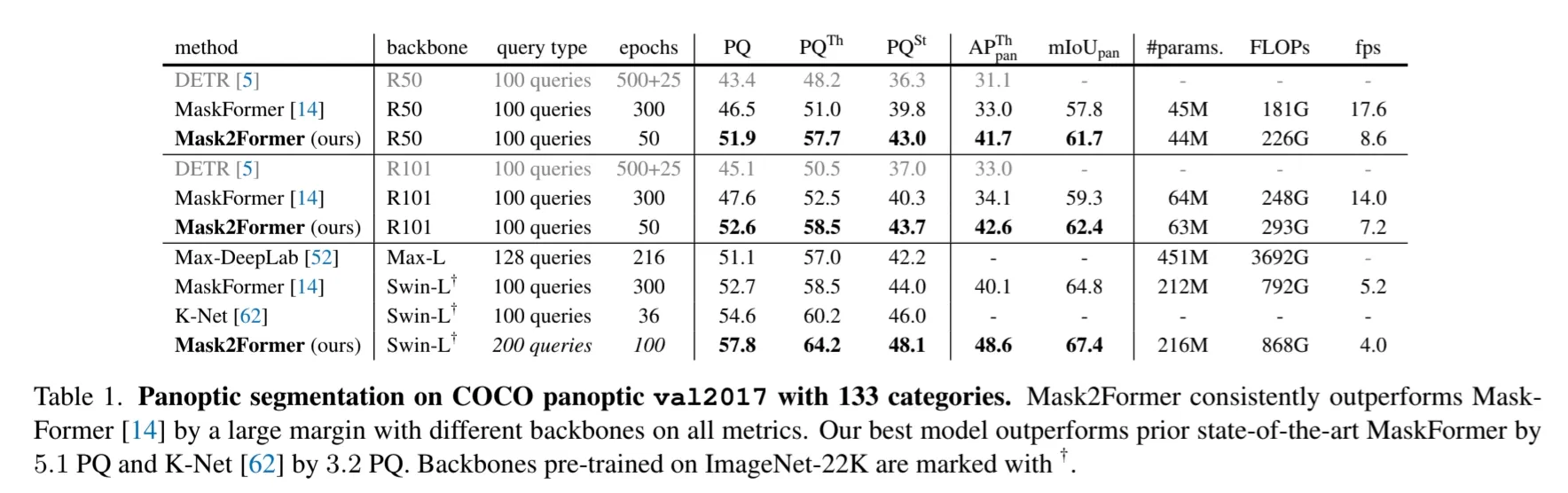
COCO Panoptic segmentation 데이터셋에서 기존 SOTA모델들보다 좋은 성능을 달성했다.
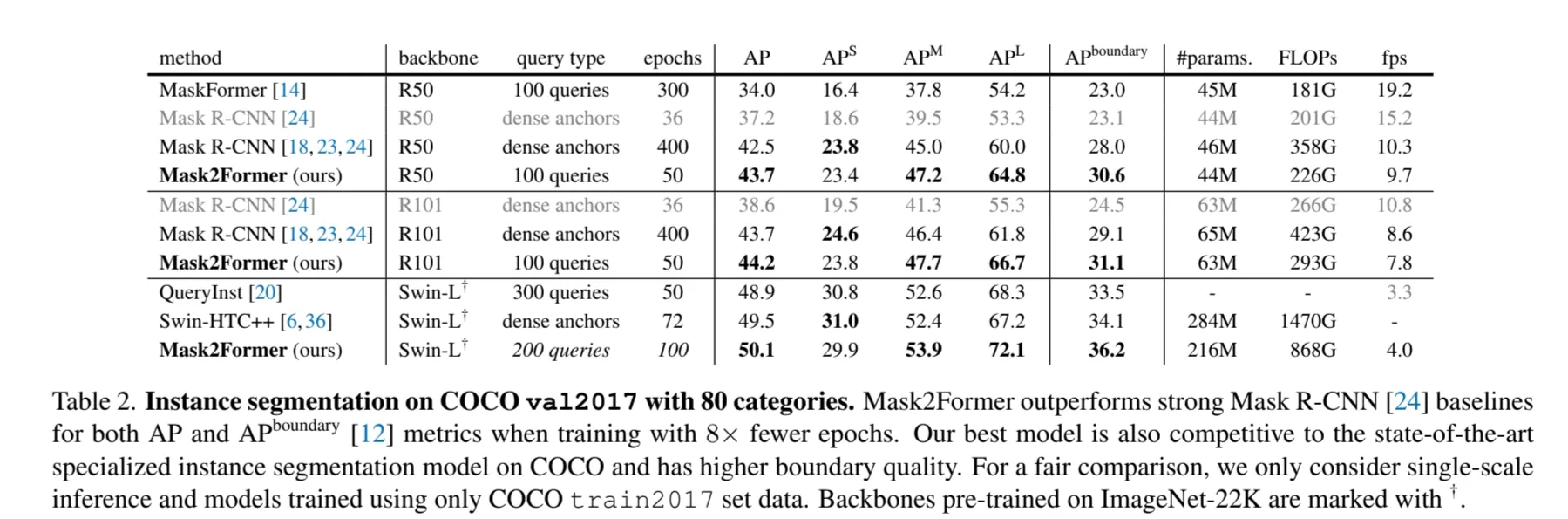
Instance Segmentation
COCO Instance segmentation 데이터셋에서 기존 SOTA모델들보다 좋은 성능을 달성했다.
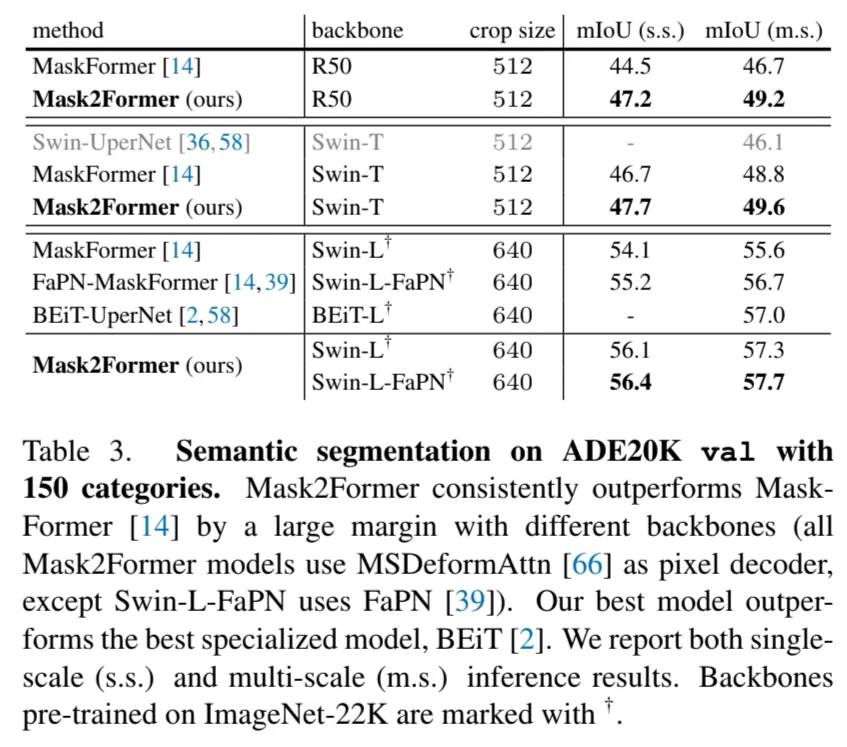
Semantic Segmentation
ADE20K semantic segmentation 데이터셋에서 기존 SOTA모델들보다 좋은 성능을 달성했다.
Conclusion
오늘은 2021년 발표된 Mask2Former 모델과 Masked-attention Mask Transformer for Universal Image Segmentation 논문에 대해 읽어봤습니다. 같은 Segmentation이라도 task에 따라서 차이가 있을텐데 하나의 Architecture 만으로 다양한 분야의 segmentation task에서 SOTA를 달성했다는 데 큰 의의가 있는 것 같습니다.
Reference
- Maskformer 논문: https://arxiv.org/pdf/2107.06278
- Mask2former 논문: https://arxiv.org/pdf/2112.01527
