
안녕하세요 그루비한입니다. 오늘 읽어볼 논문은 12월에 발표되어 따끈따끈한 논문인 Multi-View Foundation Models 입니다.

논문링크: arXiv
그동안 2D Foundation Model에 대한 연구는 비약적으로 발전해 왔으나, 3D 분야는 상대적으로 발전이 더뎠습니다. 특히 가장 큰 문제 중 하나는 동일한 물체를 서로 다른 뷰(view)에서 촬영했을 때, 같은 지점(point)임에도 불구하고 서로 다른 피처(feature) 값을 갖게 된다는 점입니다.
오늘 소개할 논문은 Adapter라는 효율적인 구조를 통해 기존 2D 트랜스포머 기반 모델을 3D-aware 파운데이션 모델로 변환하여, 동일 지점에 대해 일관된 피처를 추출하는 방법론을 제안합니다.
1. Introduction: 왜 3D-Aware 모델이 필요한가?
기존 2D 파운데이션 모델들은 인터넷 규모의 방대한 2D 이미지로 학습되었지만, 다음과 같은 한계가 있었습니다.
- 3D Awareness 부족: 공간적인 특징을 이해하는 능력이 결여되어 있습니다.
- 데이터 부족: 3D 데이터는 2D에 비해 훨씬 복잡하고 멀티모달적이며, 대규모 데이터셋 확보가 어려워 사전 학습(Pre-train)이 힘듭니다.
- 비용 문제: 최근 각광받는 NeRF나 Gaussian Splatting 같은 2D-Lifting 기법은 연산 비용이 매우 높고 대량의 학습에 적용하기엔 한계가 있습니다.
본 논문은 2D 파운데이션 모델의 강력한 표현력(Representation Power)은 그대로 유지하면서, 공간적 특징을 추가로 학습할 수 있는 구조를 제안했습니다. 핵심은 Multi-view Adapter입니다. 이 방식은 NeRF 계열과 달리 인퍼런스 시간을 획기적으로 줄여 Low Latency를 달성했으며, 3D Representation의 Consistency(일관성)를 훌륭하게 유지합니다.
2. Main Idea
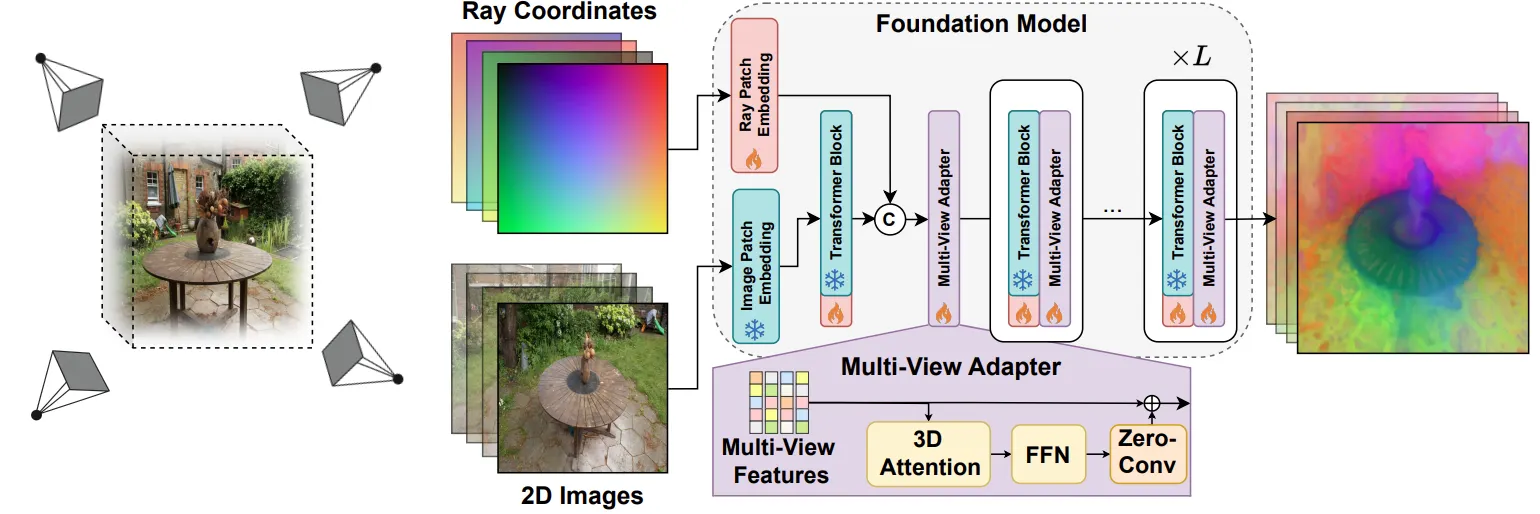
Multi-View Adapter
본 논문의 저자는 DINOv2와 같은 2D 파운데이션 모델이 보유한 방대한 사전 학습 정보를 온전히 보존하고자, 별도의 3D Representation를 생성하는 대신 Multi-View Adapter를 삽입하는 방식을 채택했습니다. 이 어댑터는 기존 트랜스포머 블록의 뒤에 위치하여, 서로 다른 시점(View)으로부터 도출된 Feature들 간의 Cross-view feature communication을 수행합니다. 이때 상대적인 카메라 포즈에서 얻은 Geometric context을 활용하여 다각도의 이미지를 정교하게 결합합니다.
구조적으로는 각 이미지가 먼저 트랜스포머 블록을 개별적으로 통과한 후, Spatial adapter에 입력되어 여러 시점의 정보가 혼합된 통합 특징 맵을 생성하는 흐름을 가집니다. 학습 전략 측면에서는 기존 파운데이션 모델의 파라미터 보존을 위해 트랜스포머 블록에는 LoRA를 적용하였으며, 새로운 공간 정보 학습을 담당하는 Multi View Adapter는 Full Fine-tuning을 진행하여 효율성과 성능을 동시에 확보했습니다.
Ray Coordinates & Plucker Embedding
또한, 픽셀 단위의 정밀한 기하학적 단서를 제공하기 위해 Ray Coordinates를 활용합니다. 각 픽셀의 광선 정보(origin, direction)는 기준 카메라 포즈에 대한 상대적 포즈로 계산되며, 이를 플러커 임베딩(Plücker embedding)을 통해 피쳐 맵과 동일한 사이즈의 맵을 갖게된다.
이렇게 생성된 임베딩 값은 첫 번째 트랜스포머 블록 직후의 특징 맵과 Channel-wise concatenate됩니다. 이러한 설계를 통해 모델은 서로 다른 관측 시점 사이에서도 Geometric correspondence을 명확하게 추론할 수 있는 능력을 갖추게 됩니다.
3. Multi-View Consistency Training
서로 다른 시점에서 관측된 동일 지점의 Feature 값을 비교할 때, 단순히 L2 Norm과 같은 거리 기반 지표를 사용하는 것은 한계가 있습니다. 이러한 단순 비교 방식은 모델이 모든 지점의 특징을 유사하게 만들어버리는 Feature collapse 현상을 초래할 위험이 크기 때문입니다.
이를 해결하기 위해 저자는 공간적 관계와 3D 방향성 정보를 보존하면서도 기하학적으로 일관된 특징 표현을 학습할 수 있도록 유도하는 Geometry-aware dense loss를 제안했습니다.
해당 손실 함수의 작동 원리는 다음과 같은 단계로 구성됩니다.
- 유사도 맵(Similarity Map) 산출: 시점의 특정 지점() 와 시점 내의 모든 포인트()들 간의 유사도를 계산하여 맵을 생성합니다.
- 확률 분포 변환: 계산된 유사도 맵에 Softmax를 적용하여 이를 확률 분포로 변환합니다.
- 매칭 점 추정: 변환된 확률 분포 위에서 SoftArgMax 연산을 수행함으로써, 시점의 지점과 대응되는 시점의 매칭점 의 위치 추정치를 도출합니다.
- 오차 계산 및 학습: 도출된 추정치와 실제 정답(Ground Truth) 사이의 차이를 계산하여, 동일한 특징점끼리는 피처 맵상의 유사도가 극대화되도록 모델을 학습시킵니다.
사전 학습된 지식 보존을 위한 규제 항(Regularization)
하지만 단순히 위의 기하학적 손실 함수만 사용하여 학습할 경우, 기존에 잘 구축된 2D 파운데이션 모델의 풍부한 Feature representation이 훼손될 수 있는 또 다른 문제에 직면하게 됩니다.
저자들은 사전 학습된 2D 지능과 새롭게 학습되는 3D 일관성 사이의 간극을 효과적으로 좁히고, 원본 특징 공간(Original feature space)을 안정적으로 유지하기 위해 다음과 같은 규제 항(Regularize term)을 추가했습니다.

여기서 는 원본 특징(Original feature)을, 는 어댑터에 의해 변형된 특징(Adapted feature)을 의미합니다. 이 두 값 사이의 유사성을 규제 항으로 강제함으로써, 모델이 기하학적 정보 학습에만 치우쳐 기존의 중요한 semantic 정보를 잃어버리는 것을 방지합니다.
4. Result: 압도적인 일관성
Feature Similarity
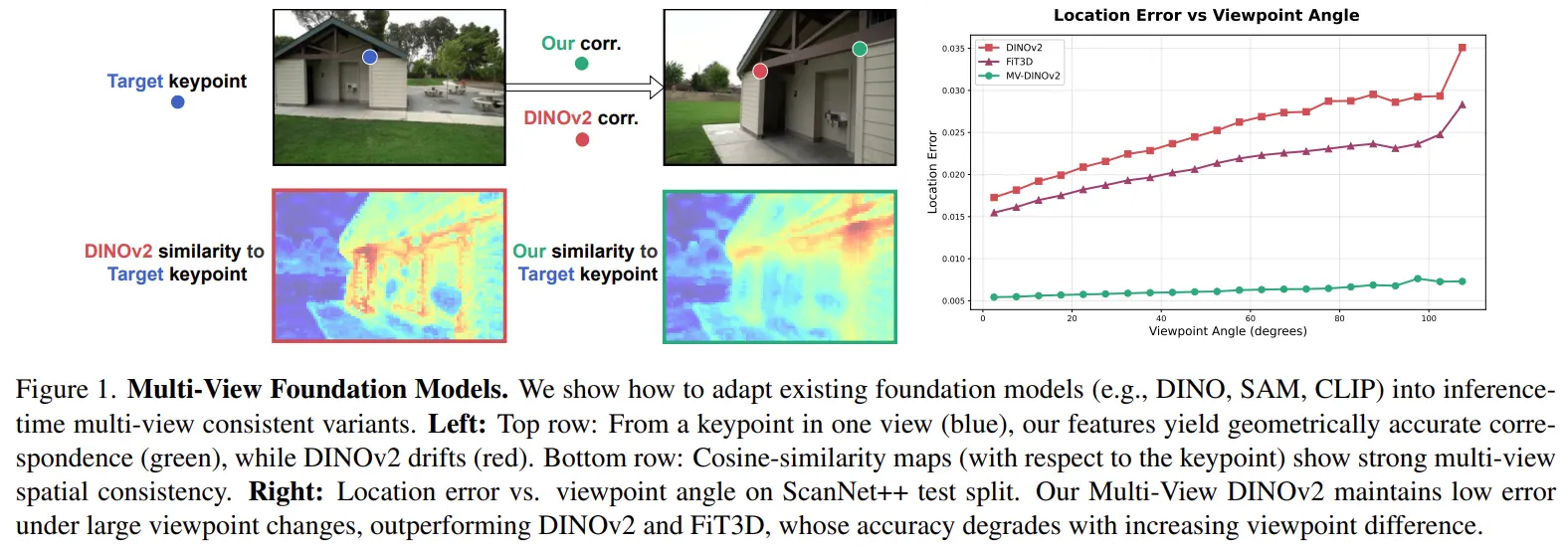
DINOv2 기반임에도 불구하고, 시점 변화에 따른 유사도 탐색 능력이 기존 모델 대비 크게 향상되었습니다.
Surface Normal Estimation
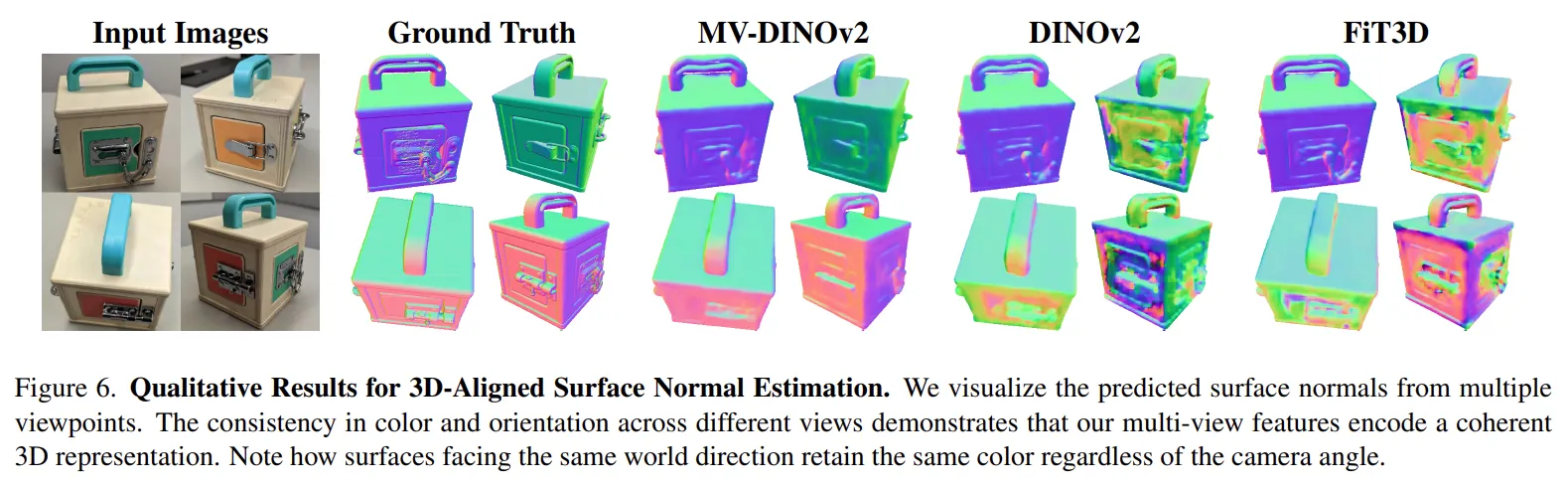
동일 평면에서 색상 변화가 있어도 면의 방향을 일정하게 추정하는 성능이 뛰어납니다. 그에 반면 일반적인 DINOv2나 FiT3D는 면의 방향에 노이즈가 많이 껴있는 것을 볼 수 있습니다.
Multi View Segmentation

SAM(Segment Anything Model)과 비교했을 때 일관성이 돋보입니다. 예를 들어, 굴삭기의 앞부분을 선택했을 때 SAM은 시점이 바뀌면 다른 부분을 집는 경우가 많지만, 이 모델은 Multi-view Alignment를 통해 동일한 부분을 정확히 추출해냅니다.
5. Conclusion
Multi-View Tracking을 연구하는 입장에서 이 논문은 매우 혁신적입니다. 거대한 파운데이션 모델을 처음부터 다시 학습하지 않고도, Adapter 하나만으로 2D를 3D로 확장할 수 있다는 아이디어가 놀랍습니다. 이 모델의 방법론을 실제 연구에 어떻게 적용할 수 있을지 지속적으로 고민해 볼 가치가 충분합니다.
