Abstract
해결하고자 하는 문제
최소한의 모델링으로, visual inputs의 수나 camera poses에 구애받지 않고 일정하게 공간적 정보를 예측 (depth estimation, pose estimation) 할 수 있는 모델 개발
제안하는 방법론
하나의 트랜스포머(vanilla DINO encoder) 만을 사용하여 teacher-student training 방식으로 Depth Anything 2 보다 detail하고 generalize 함을 달성한다.
Main Idea
Formulation

이해를 돕기 위한 그림
카메라에 투영된 이미지의 픽셀(())를 통해 이 픽셀이 촬영된 실제 3D World의 한 지점을 (라고 한다면 그 계산과정은 다음과 같다
- 추가 설명
- : camera extrinsics (: 회전행렬, : 이동행렬)
- : camera intrinsics (카메라 픽셀과 투영된 지점을 연결하는 정보)
- : Depth
이 수식에서 저자는 카메라 파라미터 중 회전 행렬()에 대한 추정이 신경망 모델 입장에서 상당히 어려운 일이라고 평가합니다 (은 직교성 (이 되어야 함)이 필요)
그래서 논문에서는 위의 수식에서 을 사용하지 않는 대신 camera ray 을 사용하고자 합니다.
camera ray 은 카메라의 2d image의 한 픽셀 에서 촬영될 때 나오는 가상의 선을 의미하고 이것은 와 같이 표현할 수 있습니다.
여기서 는 카메라의 월드 좌표 상의 위치, 는 방향벡터 입니다.
그리고 이 방향벡터 는 다음과 같이 구해질 수 있습니다.
어떤 지점 p의 내부 카메라 파라미터()의 역투영 연산에 회전()을 통해 구할 수 있다는 의미입니다.
이런 의미를 가지고 위의 를 다시 정의해보면 다음과 같은 형태로 Depth()와 로 표현할 수 있습니다.
이러한 과정을 모든 포인트에서 한다면 point cloud인 가 만들어질 수 있겠죠. 그래서 논문에서는 와 를 추정하여 카메라 파라미터에 대한 정보 없이 를 추정하고자 했습니다. 그리고 이렇게 픽셀별로 와 를 나타낸 행렬을 라고 정의합니다.
- :
- :
최종적으로 를 예측하기 위해 필요한 정보는 과 가 되는 것이고, Model의 Archtecture의 두 final head가 각각을 예측함으로써 의 흐름이 만들어지게 됩니다.
Architecture
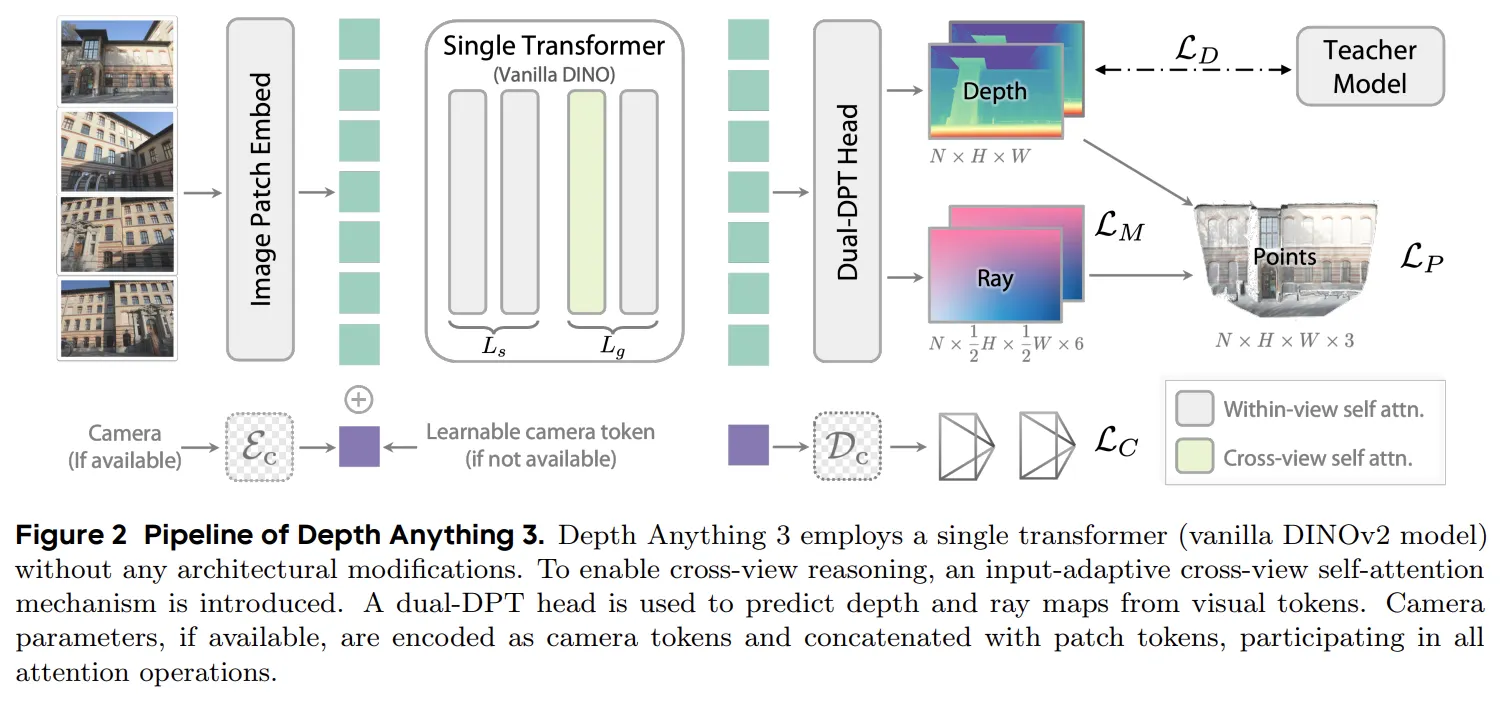
모델의 아키텍쳐는 위에서도 설명했고, 그림에서도 볼 수 있듯이 단일 Transformer 구조로 Backbone을 구성했고, 이후 동일한 Feature map을 가지고 Depth와 Ray 두개의 output을 위해 Dual-DPT Head를 사용했습니다.
Single transformer backbone
Backbone은 DINOv2와 같이 pretrained된 Vision Transfomer 기반의 Block들로 구성되어 있습니다. L개의 Block을 와 로 나누어 구성했는데, 는 self attention으로만 구성했고, 는 cross-view attention과 within-view attnetion을 번갈아 사용했습니다.
: input-adaptive self attention을 사용하여 input되는 image 수에 관계없이 input token들이 rearrange 되어 추가적인 구조적 변화 없이도 이미지가 여러장인 경우 cross-view reasoning이 가능했고, 한 장의 이미지만 input되는 경우에도 자연스럽게 monocular depth estimation을 수행할 수 있습니다.
: cross-view attention과 within view attention을 번갈아 수행하면서 모든 토큰들이 서로 적절한 관계를 유지하고 잘 fusion 되도록 유도해줍니다.
와 를 2:1 비율로 설정해 효율성과 성능 사이의 trade-off 문제에서 최적화 해주었습니다.
Camera condition injection
카메라 파라미터가 input과 관계 없이 모델은 depth와 ray에 대한 추측이 가능하도록 설계했습니다.
카메라 파라미터가 주어지는 경우 카메라 파라미터에 MLP를 통과시켜 token을 추가적으로 생성하고, 만일 주어지지 않는 경우 이 token을 learnable camera token으로 남겨두어 토큰이 카메라 정보를 예측해 담을 수 있도록 설계하였습니다.
이 카메라 파라미터 토큰은 모든 attention 과정에 함께 사용되며, 추가적인 geometric 문맥이나 일관된 placeholder역할을 한다고 합니다.
Dual DPT head
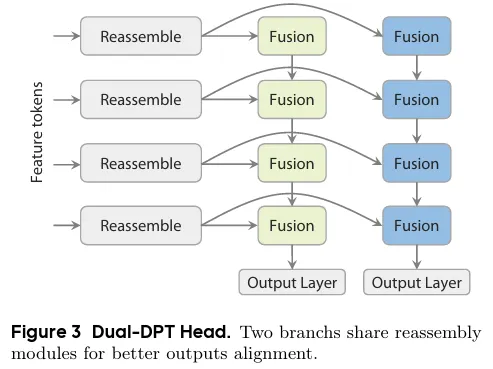
이 head는 모델의 가장 마지막 부분, Depth와 Ray로 나뉘어지는 output을 결정하는 모듈입니다. Backbone Transformer의 output인 Feature token들은 Reassemble module 을 통과한 뒤 각각의 서로 다른 Fusion layer로 나뉘어 들어가게 됩니다. 2개로 나뉜 fusion layer에서는 input된 모든 토큰들이 서로 융합되어 각각output인 Depth와 Ray를 예측합니다.
Depth 와 Ray의 서로 다른 값을 예측하는데 가장 마지막 부분만 다르고 나머지는 동일한 과정을 통과함으로써 두 개의 정보가 적절히 interaction 하면서 중복된 representation 처리 과정 없이 강력하면서도 효율적이었다고 합니다.
Training
Teacher-Student Learning

저자는 기존 real-world dataset의 poor quality 문제를 지적하면서 이 데이터셋으로 직접 학습하지 않고 teacher model로부터 생성된 high quality pseudo label을 사용하고자 했습니다. 이 teacher model은 양질의 synthetic dataset만으로 학습된 depth estimation model로, Depth Anything 2 모델을 기반으로 학습된 데이터양을 늘리고, output도 disparsity가 아닌 depth로 변환하여 Depth representation에 초점을 맞추도록 수정했습니다.
이렇게 데이터셋과 depth representation에 초점이 맞춰진 모델은 기하학적 왜곡이 적고 보다 현실적인 scene structure 능력을 보여 양질의 3D point cloud을 생성할 수 있었습니다.
그리고 이 Teacher 모델로부터 생성된 psuedo-depth map은 RANSAC least square을 통해 기존의 sparse 하고 noisy 한 real world dataset과 매칭되어 label detail을 향상시키고 geometric accuracy를 보존하는데 효과가 있습니다.
Training Objects
Depth Anything3 모델은 앞서 봤다시피 Depth와 Ray 2개의 output이 있기 때문에 각각 따로 Loss function을 갖습니다.
여기에, 만일 카메라 포즈 추정까지 포함된다면(obtion), 추정된 파라미터 와 실제 파라미터 간의 오차를 계산합니다.
그리고 논문에서는 2가지 Loss function을 추가적으로 사용합니다.
첫 번째는 이 모델에서 Depth와 Ray를 추정하는 궁극적인 목표, 즉 point map 를 얼마나 잘 예측했는지를 평가합니다. ( norm 사용)
두번째는 Depth의 gradient에 대한 penalty 를 추가합니다. 이 loss는 edge를 sharp 하게 유지하면서도 planar region을 부드럽게 만들어주는 역할을 합니다.
와 가 각각 depth map의 가로, 세로 변화량을 나타내기 때문에, 이 변화량이 얼마나 ground truth와 비슷한지를 통해 곡선을 부드럽게 유도해주는 역할을 하고 있습니다.
Result

point cloud 재현이나 depth map의 quality가 다른 3D vision task를 수행하는 모델들보다 우수한 성능을 보여준다.
Conclusion
point cloud 생성을 위해서 수식을 통해 문제를 간소화 하고,
이 간소화된 문제를 기반으로 모델도 간소화 하고,
데이터셋의 한계를 극복하기 위해서 teacher-student 구조의 pseudo labelling 전략을 수립한,
모델 개발 과정에서 발생하는 여러가지 한계를 참신한 아이디어를 기반으로 해결한 배울 것이 많은 논문이다.
읽으면서 많은 것을 배웠다. 이 모델과 이 Vision Task를 어떻게 현실에 녹여낼지 고민해야 할 때 이다.
